はじめに
こんにちは.株式会社neoAIの研究開発組織 (neoAI Research) / 東京都立大学の板井孝樹です.
昨今LLM based Agentの開発が盛んですが,実ユースケースへの応用においては多角的な評価が必要となります.そもそも"良いAgent"がどのような評価観点が求められるのかを知ることで,良い開発・価値提供が実現可能だと考えます.
本記事では,まずLLM Agentに求められる要素能力に関する評価観点についてまとめます.そしてこれらの要素能力を包括して遂行する必要のあるタスクに関する評価指標についてもまとめます.特に昨今のビッグテックのリリース時によく用いられる評価指標をベースに調査を行いました.
LLM Agentの評価指標のサーベイに関する先行の取り組みとして,Yehudaiらの"Survey on Evaluation of LLM-based Agents"が挙げられます.こちらはよくまとまっていたので参考にさせていただきました.
Agentの要素能力に関する評価
Agentの基本的な能力・構成要素は下記の通りです.本記事の前によりAgentに関する概要的な情報をお求めの場合は,過去に板井が執筆した「LLM Agentの技術的な外観を理解する」や弊社大槻が執筆した「2024年ビッグテックのAI Agent動向まとめ」の記事にもまとめているので,こちらも併せてご覧ください.
| 能力 | 説明 |
|---|---|
| Planning / Reasoning | Agentが目標を達成するために適切な行動を計画・選択する能力. |
| Reflection | 過去の行動や計画を振り返り,それらをもとに自身の戦略や計画を洗練させる能力.内省的なフィードバックを通じて,学習および適応能力を強化し,タスク遂行の効率性や精度を向上させる役割を担うことが目的. |
| Tool Use | 外部Toolと連携する能力. |
| Memory | 環境から得た情報を保存し,将来の行動に活用するための要素.Transformerのコンテキストウィンドウ内の入力に相当する短期記憶(Short-term memory)と,外部のベクトルストレージに保存され,必要に応じて素早く検索・取得可能な情報である長期記憶 (Long-term memory)に分けられている. |
| Profile | Agentが特定の役割を引き受けるための基本設定でデモグラ等の基本情報,パーソナリティ,社会的関係性などが定義される.一般にPromptingにより組み込まれ,LLMの振る舞いに影響を与えるモジュール. |
Planning / Reasoning
LLMが論理的な中間ステップをいくつか実行して多段階推論を行うことで,単一ステップでは導き出せない解決策に到達可能です.複雑化するタスクをAgentが遂行するためにまずはタスク計画を立てたり,状況を踏まえて次の行動をロジカルに決定するなどの能力が求められます.これらの評価に関しては,様々な領域で体系的に評価するベンチマークが提案されています.昨今OpenAIやQwenなどの各社からreasoningモデルが続々と公開されていますが,ベンチマークも多く開発が盛んな分野であると言えます.
Yehudaiらはreasoning能力を評価するためのベンチマークとして,以下のようなものを挙げています.
| 分野 | ベンチマーク |
|---|---|
| 数学的推論 | GSM8K,MATH,AQUA-RAT |
| 多段階質問応答 | HotpotQA,StrategyQA,MultiRC |
| 科学的推論 | ARC |
| 論理的推論 | FOLIO |
| 制約充足パズル | Game of 24 |
| 日常的常識 | MUSR |
| 挑戦的推論タスク | BIG-Bench Hard |
本説では,Planning能力に関する主要なベンチマークについて,いくつかピックアップして紹介します.
HotpotQA (EMNLP 2018)
HotpotQAは,単純な知識検索だけでなくマルチホップ推論(複数の文書から情報を結合する能力)を評価するためのデータセットであり,2018年に提案されて以来,複雑な質問応答タスクの標準的なベンチマークされています.ベンチマークの設定は,DistractorとFull Wikiの2つに分かれています.Distractorは,各問題に対して正解の段落2つと,質問をクエリとして取得したビッグラムtf-idf上位8つの"ノイズ"段落を混ぜた10段落をモデルに与える設定で,段落のシャッフルありでモデルはこの中らか回答と根拠を選択するというものです.Full WikiではWikipediaの最初の段落集合から,inverted-index+tf-idf によって上位10段落を絞り込み,その中から回答を選択するという設定です.
含まれる質問タイプとしては下記の4つが挙げられます.
Type I
全体の42%を占め,ブリッジエンティティを推論して2つ目のホップ質問を完成させる問題.下記の例では,段落Aで「Buddy Hield が大会MVPに選ばれた」と読み取り,段落Bで彼が所属するチーム名を補足的に引く,という2ステップ推論を行う.
「2015年ダイヤモンドヘッド・クラシックのMVPに選ばれた選手は,どのチームでプレーしていますか?」
Comparison
全体の27%を占め,2つのエンティティを比較する問題.下記の例ではそれぞれのバンド記事からメンバー数を抽出し,数値を比較することを行う.
「LostAlone と Guster は同じメンバー数でしたか?」
Type II
全体の15%を占め,複数の属性をチェックして回答エンティティを特定する問題.下記の例では,段落Aでピッツバーグ・パイレーツ元選手の一覧を読み取り,段落Bで該当選手の愛称"コブラ"を確認することで対象を特定する.
「ピッツバーグ・パイレーツの元メンバーで,『コブラ』というニックネームの選手は誰ですか?」
Type III
全体の6%を占め,ブリッジエンティティを通じて質問中のエンティティの属性を推論する問題.下記の例では,段落Aで「第28海兵航空管制群」の所属基地名を取り出し,段落Bでその基地が所在する都市名を推論する.
「第28海兵航空管制群(Marine Air Control Group 28)はどの都市に所在していますか?」
Folio (EMNLP 2024)
LLMの複雑な論理的推論能力を評価するためのベンチマークで,1,430の例(ユニークな結論)と,それぞれの結論の妥当性について演繹的に推論するために使用できる487セットの前提からなるデータセットです.論文で紹介されている例を日本語化して下記に示します.
少しややこしいですが,前提4と5から,ジェームズは他の人よりもパフォーマンスが良くないと推論でき,ぜんてい3を合わせると,ジェームズは日常業務を効率的に処理していないことがわかります.前提2から,ジェームズは時間管理が得意ではないと推論できます.故に結論Bは偽であると考えられます.また結論Aは運動習慣に関する十分な情報がないので不明,Cは「p→q」という論理形式(pが「ジェームズのパフォーマンスが他の人より良くない」,qが「ジェームズは毎週運動をし,時間管理が得意である」)で,pは真だがqは偽であることが推論できるため,この条件文全体は偽となります.
前提:
1. 時間管理が得意な従業員の中には,毎週運動をしない人もいる.
2. 時間管理が得意な従業員は全員,日常業務を効率的に処理する.
3. 日常業務を効率的に処理する従業員は全員,他の人よりもパフォーマンスが良い.
4. 他の人よりもパフォーマンスが良い従業員は全員,昇進の機会がより多い.
5. ジェームズには昇進の機会がより多くない.
結論:
A. ジェームズは毎週運動をする.→ 不明
B. ジェームズは毎週運動をし,時間管理が得意である.→ 偽
C. ジェームズのパフォーマンスが他の人より良くないなら,ジェームズは毎週運動をし,時間管理が得意である.→ 偽
BIG-Bench Hard
DeepMindの研究者らの提案するベンチマークで,23の多様なタスクで構成され,複雑な推論スキルの評価を行います.多段階推論以外にもlong contextや思考ステップがかなり必要となる高い思考負荷をかけるものなどが含まれているのが特徴的です.
23のタスクの評価観点の詳細
| タスク名 | 評価観点 | 説明 |
|---|---|---|
| BoardgameQA | 演繹的推論,その場での学習 | 矛盾する可能性のあるルールと優先順位から結論を導き出す多段階推論を要求する |
| Boolean Expressions | 論理的推論,多段階推論 | 文章や数式が含まれる複雑な論理式の真偽値を判定する |
| Buggy Tables | データ構造,バグの説明からの復元 | 破損したテーブルをバグの説明から復元し,条件付きクエリに回答する |
| Causal Understanding | 因果判断,論理的推論 | 必要条件や十分条件など,因果関係の様々な側面を理解する |
| DisambiguationQA | 常識的理解,言語知識 | 長文中の曖昧な代名詞の参照先を特定する |
| Dyck Languages | データ構造,推論トレースのエラー発見 | かっこの閉じ方に関する推論中の最初の誤りを特定する |
| Geometric Shapes | 空間的推論,幾何学的理解 | SVGコマンドで描かれる複数の図形を特定し,紛らわしい要素を扱う |
| Hyperbaton | 帰納的推論,強い先入観との対立 | 例から形容詞の新しい順序を推論し,英語とは異なる順序を適用する |
| Linguini | 帰納的推論,言語知識 | 新しい言語についての例から規則を学び適用する |
| Movie Recommendation | 知識を通じた推論 | 映画セットの全体的な好ましさを予測する |
| Multistep Arithmetic | その場での学習,多段階推論 | 新しい算術演算子とその組み合わせをその場で学び,長い式を評価する |
| NYCC | ユーモア理解,常識的理解 | ニューヨーカー漫画のキャプションから最も面白いものを選ぶ |
| Object Counting | 長文処理,複数の対象物の特定 | 長いリストから特定タイプのオブジェクトを数える |
| Object Properties | 時系列追跡,長距離依存性 | 複数の更新を経て変化するオブジェクトの性質を追跡する |
| SARC Triples | 常識的理解,皮肉の理解 | Redditの投稿/返信ペアの皮肉度を判断する |
| Shuffled Objects | 時系列追跡,長文処理 | 複数の交換操作を経たオブジェクトの最終位置を追跡する |
| Spatial Reasoning | 空間的理解,多段階推論 | 複雑なパターン上の移動を追跡し,最終位置のオブジェクトを特定する |
| SportQA | 知識集約型推論,複合的推論 | スポーツに関する複合的な質問に回答する |
| Temporal Sequences | 時間的理解,制約充足 | 複数のカレンダーから最適な会議時間を見つける |
| Time Arithmetic | 時間的推論,複合的理解 | 日付と時間に関する複合的な算術計算を行う |
| Web of Lies | 論理的推論,多段階推論 | 人々の真実性に関する言明から論理的結論を導く |
| Word Sorting | アルゴリズム適用,推論トレースのエラー発見 | 新しいアルファベット順でのソートや,ソートのエラーを見つける |
| Zebra Puzzles | 制約充足,多段階推論 | 様々な論理的制約から推論してパズルを解く |
Reflection
Self-Reflectionに関する代表的なベンチマークとして下記が挙げられます.
LLM-Evolve
LLM-EvolveではMMLUなどの一般的なベンチマークを用いて,LLMが過去の経験からフィードバック付きの過去のクエリを収集,文脈内学習を行うことで,時間と共にパフォーマンスを向上させる能力を評価するベンチマークです.
これまでのベンチマークでは,各問題が独立同一分布(i.i.d.:independent and identically distributed)であることを指摘しており,すなわち前の問題での経験が次の問題の解決に活かされるという視点がありませんでした.著者らは既存の確立されたベンチマーク(MMLU,GSM8K,AgentBenchなど)を基盤として,それらの評価設定を変更することで,LLMの進化的学習能力を評価可能にしました.
ベンチマークの構成は下記の通りです.
- デモンストレーションメモリ
\mathcal{D} \mathcal{D} = \{(x_i^{llm}, y_i^{llm}, f_i)\} - 検索モジュール
r_\phi - フィードバック機構:
f_i \in \{True, False\}
これらを下記の手順で評価を繰り返します.
- Round 0 (通常の評価):
y^{lm} = p_\theta(x, \{x_i^{demo}, y_i^{demo}\}) - メモリ構築: 正答のみをメモリに保存
(x_i^{llm}, y_i^{llm}, f_i=True) \rightarrow \mathcal{D} - 検索: 新問題
x - 進化的評価(Round 1+):
y^{LLM-Evolve} = p_\theta(x, \{x_i^{llm}, y_i^{llm}\})
i \in \text{topk-min}_{x_j^{llm} \in \mathcal{D}, f_j^{llm}=True} \{||r_\phi(x) - r_\phi(x_j^{llm})||_2\} - 評価と繰り返し: 正答を
\mathcal{D}
Reflection-Bench
LLM-EvolveではLLMの進化的学習的な能力を評価するためのベンチマークでしたが,Reflection-Benchは認知科学的な視点から下記の7点を検証しています.
| 評価観点 | 説明 |
|---|---|
| A. perception | 予想外の信号を検出する能力.特定のトピックに関する7つの短い文章と,文脈から外れる1つのランダムな文(デビアント刺激)を含むプロンプトをAIに与え,「簡単なコメントをする」という指示を行う. |
| B. memory | 過去の決定プロセスを想起する能力.いくつかの文字(E, F, G, Hなど)からなる固定シーケンスをAIに1つずつ送信し,現在の文字がn(論文ではn=2)ステップ前の文字と同じかどうかを判断させる. |
| C. belief updating | 新しい証拠に基づいて信念を変える能力.40回の試行からなるタスクで,AIには2つの選択肢が提示され,選んだ選択肢に対する報酬がベルヌーイ分布からサンプリングされる.最初,左右の選択肢の報酬確率はpと1-pですが,21回目の試行で予告なく反転される. |
| D. decision-making | 変化する環境で柔軟に決定を行う能力.AIには1枚のテストカード(例:「緑の三角形4つ」)の説明が提示され,マッチングルールを告げられずに4つの選択肢からターゲットカードとマッチするものを選ばせる. |
| E. prediction | 外部状態や行動の結果を予測する能力.各試行でAIには現在の天気とセンサー状態([0,1]または[1,0])が提示され,翌日の天気を予測する.次の試行では,AIは前回の実際の天気(今回の現在の天気)とセンサー状態の情報を与えられ,再び予測を行う. |
| F. counterfactual thinking | 選択しなかった代替案について考える能力.AIには4つのカードデッキが提示され,初期選択を行う.選択に対する利得と損失が計算された後,AIは「時間を巻き戻す」機会を与えられ,初期選択を維持するか変更するかの第二の選択を行う. |
| G. meta-reflection | 反射プロセス自体について反省する能力.報酬確率がn試行ごとに定期的に反転する,Probabilistic Reversal Learning Task(確率的反転学習タスク)を行う.報酬確率が1に設定され,AIがルール反転のパターンを認識できているかどうかを判断する.反転試行でも報酬を獲得できれば成功となる. |

Tool Use
Tool Useの能力は下記のようなサブタスクから構成されていると考えられます.これらを明示的または暗黙的に評価する様々なベンチマークが提案されています.
- ユーザの要求からToolの呼び出しが必要かどうかの判断
- 最適なToolの決定
- ユーザー入力などから必要な引数を抽出し,Toolに渡す形式へ整理
- Toolの出力をもとに適切なOutputを生成
研究の初期段階に提案された主要なベンチマークとしては,ToolBenchやAPIBenchなどが挙げられます.これらは比較的単純なシングルターンの対話に焦点を当てて上記のサブタスクを評価するアプローチをとっています.さらに最近ではBFCL V3やToolSandboxなどの,より複雑なマルチターンの対話を通じてTool Useの能力を評価するベンチマークも提案されています.
ToolBench
ToolBenchは,RapidAPI(実世界のAPIホスティングプラットフォーム)から収集された16,464のRESTful APIを基盤としています.これらのAPIはSNS,EC,天気予報など49の広範なカテゴリをカバーしています.データセット構築のために,ChatGPTを用いてこれらのAPIに対する多様なinstructionが自動生成して作成されており,生成された指示文は,単一tool call以外にも,同一カテゴリ内の複数のtool使用,特定コレクションに属する複数toolの使用といった多様なユースケースに対応できるよう設計となっています.
また,論文ではReActやCoTといったアプローチが誤ったActionを連鎖的に引き起こす可能性を指摘しており,その代替としてDFSDT(Decision Forest Search with Dynamic Pruning)という決定木ベースの探索アプローチを提案しています.このアプローチでは,各ステップで思考を行い,使用するAPIとパラメータを決定し,Toolからの結果(tool_results)を得た後,複数の推論パスを評価します.そして,最も有望なパスを選択するか,既存のノードを破棄して新たなノードを展開するかを決定します.DFSDTを用いて生成されたtrajectoryの一部は,評価ベンチマークのQAデータとしても活用されています.
API Bench
APIドキュメントを与えられたLLMが適切なAPIコードを生成できるかを評価するタスクで,Python, JavaScript, Javaで実行が可能です. 評価指標としては下記を用いています.
- 実行成功率 (Execution Success Rate): 生成されたコードが正常に実行できるか
- 機能達成率 (Functionality Achievement Rate): コードが要求された機能を達成できるか
Berkeley Function Calling Leaderboard V3 (BFCL V3)
シングルターンとマルチターンの両方を対象としたベンチマークで,ユーザーが最初に曖昧なクエリを投げかけ,モデルはユーザーとの対話を通じて必要な情報を引き出しながら,最終的に適切な関数を呼び出す能力が評価されます.
評価指標はターンの種類によって異なります.シングルターン評価では,選択された関数名と引数が正解ASTと一致するかを確認する「AST評価」,関数を実際に実行して返り値の一致を検証する「Exec評価」,そして不要または無関係な関数を呼び出していないかを判定する「Relevance」の3つの観点から評価されます.
一方,マルチターン評価では,「最終的なシステム状態が正しいか」を検証する「State-based評価」と,正解として定義された「必須最小呼び出しセット」がモデルの呼び出し列に含まれているかを確認する「Subset-matched Response-based評価」の両条件を満たすかどうかが評価されます.つまり,適切な状態に到達しつつ,必要なルートを通過したかどうかが重要視されているベンチマークといえます.
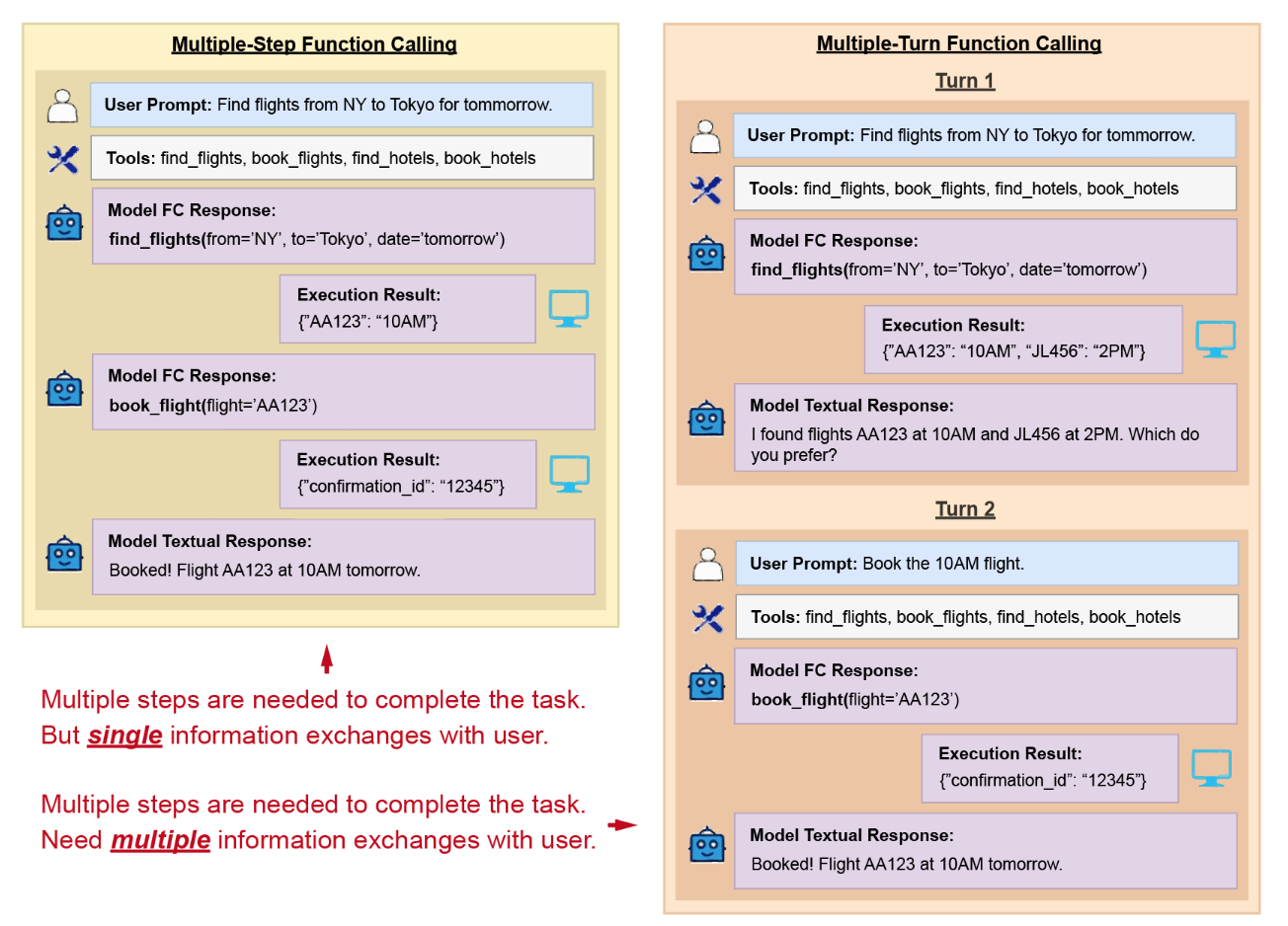
ToolSandbox
ToolSandboxはAppleが提供するベンチマークで,実世界へのインタラクションを想定した評価指標となっています.

特徴的なのが,実世界の状態に依存し,それを変更できるToolが含まれている点です.例えば,メッセージを送信する前に携帯サービスがオンになっているかを確認するなど,モデルが暗黙的な状態の依存関係を追跡する必要があるタスクが設計されています.BFCLやAPI-Bankが単発のTool callと静的な評価に留まるのに対し,ToolSandboxは複数Toolの依存関係,途中経過の部分評価,ユーザーとのインタラクションを組み込んでおり,実運用に近い難易度を再現しているといえます.
Memory
(LLM Agentの開発をしていて,目立たないが実はMemory機能がとても重要だと実感しています.)AgentのMemory機構の評価方法については,下記の4つに大別することができます.それぞれの具体については後述しますが,まずは概要をまとめます.
| 評価観点 | 説明 |
|---|---|
| 文書理解と要約 | Agentがlong-contextを理解して関連情報を抽出,要約する能力.コンテキスト長の制限を超えた情報をどのように処理し,長期的な情報を保持できるかを測るもの. |
| 記憶強化型Agent評価 | メモリ機構を実装したAgent評価に焦点を当てており,異なるメモリアーキテクチャがAgentのパフォーマンスにどう影響を与えるか比較するための指標. |
| エピソード記憶評価 | エピソード記憶とは具体的な経験や出来事を時空間的contextとともに記録する能力を指します.重要な過去のインタラクションの詳細を覚えておき,それを将来の対話に活用する能力を評価するものなどが当てはまる. |
| 生涯学習 | 時間と共に流れるデータに対する継続的な学習と適応能力を評価する.Agentの活用においては静的な一回限りのタスクよりも継続的なインタラクションを通じた長期的なサポートが求められるため,いわゆる生涯学習能力をどれだけ備えているかを測る指標と言える.具体例をあげると,カスタマーサポートで問題解決の過程で以前の会話から学習したり,教育分野で学習者の理解に合わせて内容を調整するなどを指す. |
文書理解と要約
ここではReadAgentを紹介します.DeepMindの研究者らが提案した人間の読解プロセスを模倣するAgentとして,少し前にバズっていました. 既存のLLMは明示的なコンテキスト長の制限を持っており,さらに長い入力を与えると性能が劣化することがわかっています.人間が長文を読む際には要点(gist)を記憶しつつ,必要に応じて原文を再参照する手順を踏み,効率的に理解を深めています.そこで提案手法では下記を行います.
- エピソード分割: 長文を「自然な区切り」(段落間など)で複数のエピソード(ページ)に分割
- 要点圧縮: 各エピソードを短い「gist(要点)文」に圧縮し,ページ番号付きで記憶
- 対話的再参照: タスク(例:質問応答)の際,まずgistのみで答えを試み,必要なら「どのページを再読するか」をモデルに選択させ,原文ページを読み込ませて最終的に回答を生成
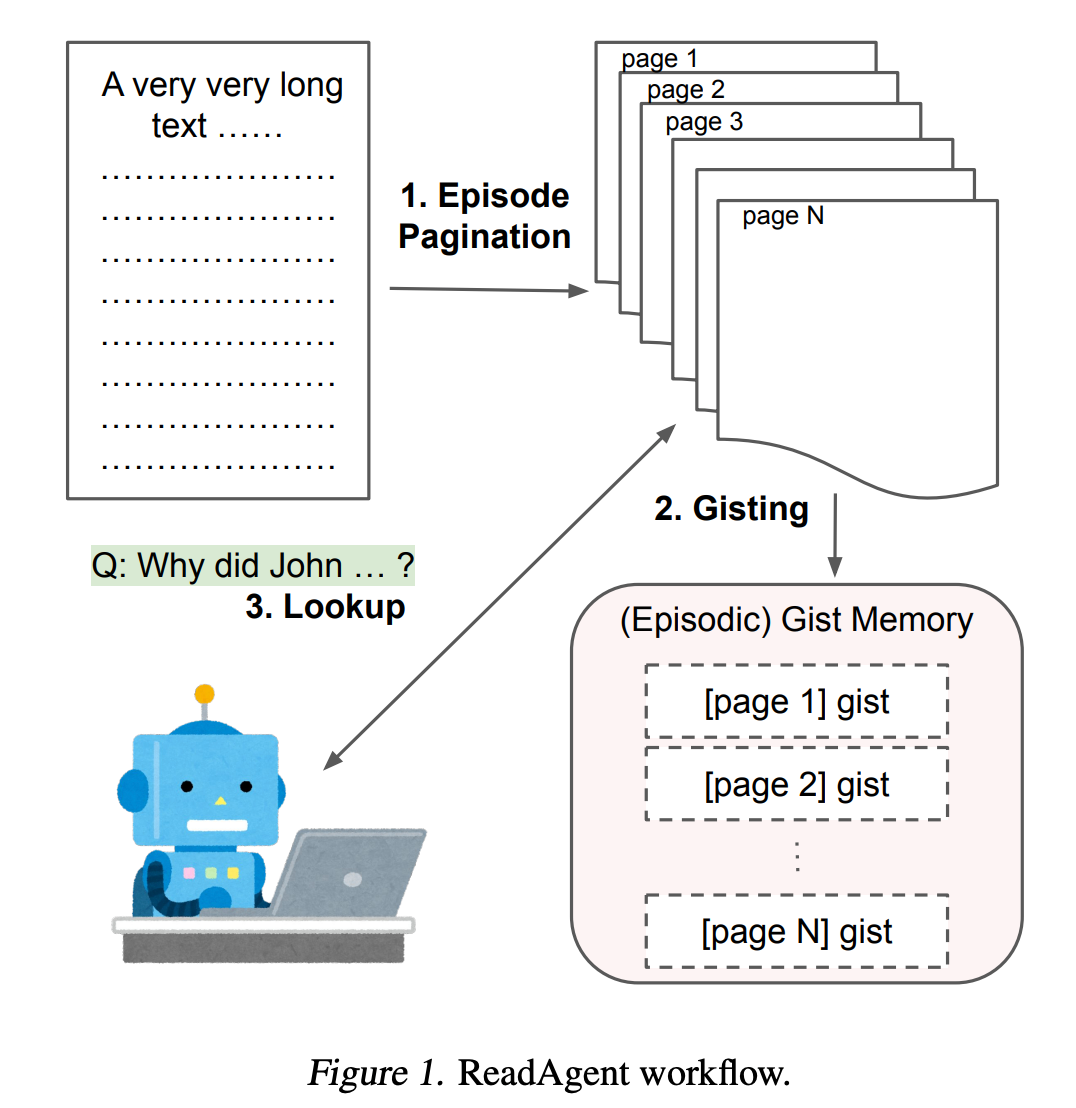
このReadAgentの評価実験で用いられたベンチマークが下記の通りです.
- NarrativeQA: 物語テキストの長い文脈からの質問応答能力を評価
- QMSum: クエリベースの会議要約タスク
記憶強化型Agentの評価
記憶強化を行うMemoryアーキテクチャを導入したAgentとして代表的なものとしてはA-MemとMemGPTが挙げられます.
A-Mem(Agentic Memory)
ノートという単位で記憶を保持するアーキテクチャで下記の構造となっています.

- ノート構築:
- 各記憶を構造化されたノートとして保存
- 内容,タイムスタンプに加え,キーワード,タグ,コンテキスト説明などを自動生成
- このノートがどんどんMemory(Retrieval DB)に追加されていく
- リンク生成
- 新しくノートが追加されるたびに既存のノートとの関連性を自動で分析し,意味的に関連するノートのリンクがリンクされ知識グラフができる
- 記憶の進化
- 新規でノートを追加するだけでなく,既存のノートの表現も新しい情報に基づいて更新される.
A-Memの評価にはLoCoMo(Evaluating Very Long-Term Conversational Memory of LLM Agents)が用いられています.LoCoMoは,LLM Agentが長期的な会話を通じて記憶をどのように活用するかを評価するためのベンチマークであり,以下のような特徴があります.
- 平均約300ターン,9,000トークンを含み,最大35セッションからなる会話データを含む(従来の6倍多いターン数と4倍多いセッション数に分散)
- 下記の3つのタスクからなる
- 質問応答タスク - 以前の対話ターンから情報を思い出す能力を測定
- イベント要約タスク - 時間的・因果的なダイナミクスの理解を評価
- マルチモーダル対話生成タスク - 会話履歴に基づいた応答生成を評価
MemGPT
A-Memは知識の構造化と進化に発想を置いた研究でしたが,MemGPTはLLMの有限なcontextをOSの仮想メモリとして捉えて無限のコンテキスト体験を実現することをモチベーションにした研究です.仮想のcontext管理としてLLMが自分のメモリ階層(メインメモリと外部記憶)を自律的に操作します.またOSライクな設計であるため,LLMが自動で関係する情報を呼び出したり保存したりできる「関数呼び出し機能」を用いることができます.コンテキストが満杯になると警告が出され,LLMが不要な情報を保存し,新しい情報を取り込むようなページアウト機能なども提案されているのが面白いポイントです.
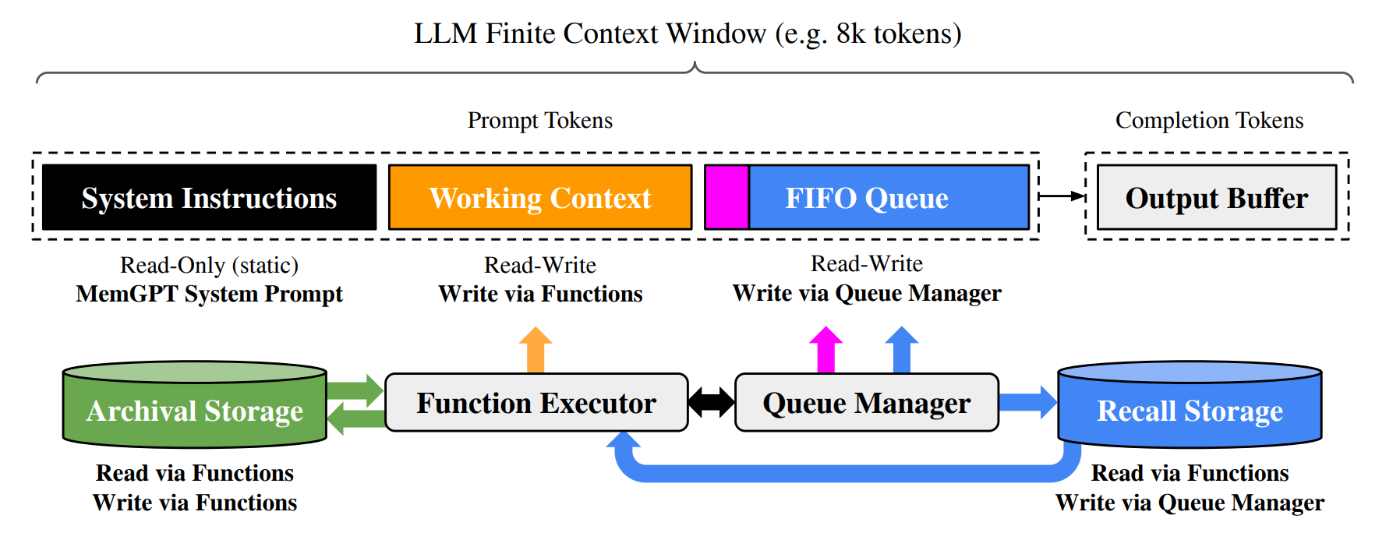
MemGPTでは NaturalQuestions-Open(NQ-Open)を用いて,文書分析能力,特にマルチドキュメント質問応答の性能を評価しています.
エピソード記憶評価・生涯学習
単なる情報検索能力だけでなく,生きた経験を意味のある形で記録し,活用できるかというAgentの「経験知」を測定する重要な観点と言えます.本記事ではいわゆるAgentの長期記憶という観点でまとめます.
エピソード記憶や生涯学習の評価に関する取り組みとしては,LongMemEvalやEpisodic Memories Generation and Evaluation Benchmark for Large Language Modelsなどが挙げられます.これらの取り組みをまとめるとAgentの長期記憶の主要な評価観点は以下であると考えられました.
| 評価観点 | 説明 |
|---|---|
| context認識能力 | 記憶が単なる情報の断片でなく.特定の時間や場所,状況に関連づけられているか.Yehudaiらはこれらを,「いつ」その情報を取得したかを追跡し,時間的順序を維持できるかという時間的マーケティング,情報が獲得された文脈を保持できるか状況的バインティンづとしてまとめている. |
| 詳細の保持能力 | 具体的な詳細(名前,数値,仕様など)を保持かという情報の粒度,原情報の意味や内容を歪めることなく保持できるかという忠実性,情報の重要な側面を漏れなく記憶できるかという完全性が求められる. |
| 時間的一貫性 | 過去の会話や行動の時系列を正確に維持し,矛盾なく参照できる能力.出来事や対話の順序を正確に記録し,再現できるかという時系列の保持,時間的に先行する出来事と後続の出来事の関係性を把握しているかに関する因果関係の理解などが挙げられる. |
| 情報統合能力 | 複数のエピソードや情報源から収集した知識を結合し,新たな洞察や解決策を生み出す能力を指す.複数の別々の対話や経験から学んだ情報を関連づけられるかというクロスエピソード学習,断片的な情報を意味のある全体像に統合できるかという知識統合が重要な観点となる. |
| 記憶の検索能力 | 現在のコンテキストに基づいて関連する過去の記憶を効率的に検索・活用する能力. |
| プライバシーとセキュリティの考慮 | エピソード記憶評価では,センシティブな情報の扱いに関する能力も評価される.プライバシーが必要な情報を適切に忘却または隔離可能か,状況に応じて記憶へのアクセスを制御できるかなどの観点が挙げられる. |
| 長期vs短期のバランス | 限られたcontext windowの中で,短期的に重要な情報と長期的に価値のある情報をどうバランスさせるかという観点.メモリ使用量と検索速度のトレードオフなどもここに含まれる. |
Profile
LLM Agentが特定の役割(Profile / Persona / Role)をどれだけ忠実に維持・活用できるかを評価するための主要なベンチマークをまとめます.Profileの評価指標は軽く調べただけでもかなりの数存在しており,その中でも主要と思われるものをいくつかピックアップしました.
Profileの能力評価においても動的または静的なベンチマークが提案されているようで,静的なものだとRoleLLM,,CharacterEvalなどが挙げられます.これらは固定のテストセットを用いており,再現性に長けている点が利点です.動的なものだと,DMT-RoleBenchなどが挙げられます.これらはテストケースが実行ごとに生成されるため,実運用に近い状況での頑健性を評価するのに適しています.
静的Benchmark
RoleBench (RoleLLM)
- 100種類のキャラクター(en: 95, zh: 5),168,093 件の対話サンプルを含む大規模なベンチマーク
- キャラクターごとにRole Profile(説明文+キャッチフレーズ+構造化対話)をもとに,一般的な指示(General-purpose instructions)と役割特化型の問い(Role-specific questions)を生成し,それぞれに対する応答データを収集
以下の複数ステップでLLMのロールプレイ能力を評価します.
- 評価はROUGE-Lでモデルがどれだけ参照回答と一致するかを測る自動評価,LLM as judgeで知識捕捉・正確性・話法模倣を評価する方法,が提案されており,論文内では人手での主観評価も実施している.
- 評価観点である知識捕捉・正確性・話法模倣についてもう少し掘り下げると,下記の通り.
評価観点 説明 知識捕捉(Knowledge Capture) Agentが特定のロールに関連する知識や情報をどれだけ正確に把握し,活用できるかを評価する尺度.専門的な用語や概念の理解,分野固有の知識の応用能力が含まれる. 正確性 (Accuracy) Agentが提供する情報や回答がどれだけ事実に基づいており,誤りがないかを評価する尺度.適切な情報源の引用,事実と意見の区別,偏りのない情報提供が含まれる. 話法模倣(Speech Imitation) Agentが特定のロールに期待される話し方,文体,専門用語の使用などをどれだけ自然に再現できるかを評価する尺度.語彙選択,文章構造,会話スタイルの一貫性が含まれる.
CharacterEval
会話能力,ペルソナの一貫性,ロールプレイングの魅力度,パーソナリティバックテスト(要するにMBTI)の4つの次元で,下記の13の評価指標があります.また評価方法がLLM as judgeも検証自体は行われていますが,CharacterRMという評価のための報酬モデルを用いている点も面白いベンチマークです.
まず評価観点をまとめると下記の通りです.
会話能力(Conversational Ability)
| 評価観点 | 説明 |
|---|---|
| 流暢さ(Fluency) | 応答の文法的正確さを測定.読みやすく,明らかな文法エラーがないかを評価 |
| 一貫性(Coherency) | 応答とコンテキストのトピック関連性を評価.ユーザーが特定のトピックについて質問した場合,Agentは無関係な応答ではなくそのトピックに従って応答すべき |
| 整合性(Consistency) | 会話中のAgentの安定性を評価.Agentの応答が前のターンでの自身の応答と矛盾していないかを確認 |
キャラクターの一貫性(Character Consistency)
| 評価観点 | 説明 |
|---|---|
| 知識露出(Knowledge-Exposure) | 応答の情報量を評価.Agentがその応答で知識を反映しているか,その後の知識表現能力評価のための基礎となる |
| 知識正確性(Knowledge-Accuracy) | 表示された知識がキャラクターと一致するかを評価.Agentがキャラクターのプロフィールからの知識に基づいて正確に応答を生成できるかを目指す |
| 知識の幻覚(Knowledge-Hallucination) | ロールプレイ対話における幻覚を評価.ユーザー体験を向上させるため,Agentはキャラクターのアイデンティティと一致し,未知の知識に関するクエリに応答するのを避けるべき |
| ペルソナ行動(Persona-Behavior) | キャラクターの行動の一貫性を評価.括弧内で説明される細かい行動,表情,トーンなどがキャラクターのペルソナと一致しているか |
| ペルソナ発話(Persona-Utterance) | キャラクターの話し方の一貫性を評価.Agentの発言がキャラクター固有の表現習慣に合致しているか |
ロールプレイングの魅力(Role-playing Attractiveness)
| 評価観点 | 説明 |
|---|---|
| 人間らしさ(Human-Likeness) | Agentがより人間らしいペルソナを示す能力を評価.機械的・感情のない応答ではなく,自然で人間らしい反応を示すべき |
| コミュニケーションスキル(Communication Skills) | コミュニケーション能力(EQ)を評価.ユーザーは強いコミュニケーションスキルを持つAgentとより積極的に関わる傾向がある |
| 表現の多様性(Expression Diversity) | 行動と発言における表現の豊かさと多様性を評価.Agentはキャラクターの豊かな表現能力を会話で表現し,より没入感のある体験を提供すべき |
| 共感性(Empathy) | 共感を表現する能力を評価.Agentの主な役割は感情カウンセラーではないが,共感性を示すことでユーザーにとってより温かく親しみやすい会話パートナーになれると解釈 |
パーソナリティバックテスト(Personality Back-Testing)
| 評価観点 | 説明 |
|---|---|
| MBTI正確性(MBTI Accuracy) | キャラクターの既知のMBTIタイプとAgentが回答したMBTI評価の一致度を測定.Agentがキャラクターの基本的なパーソナリティ特性と価値観を正確に体現できるかを評価 |
CharacterRM
Baichuan2-13B-baseをベースに,主観的な評価指標を自動的に評価するための特化モデルとして学習しています.論文では,GPT4のLLM as judgeも検証されていますが,人間の判断との相関係数0.362~0.385程度と低く,課題として捉えてRMのFTをするに至ったようです.確かに評価時に主観的な色が強い,Agentの振る舞いの評価を汎用LLM自体が行うのはまだ困難だと考えられます.
- 人手アノテーションでさまざまなモデルの応答に対して5段階評価を実施し,ロールプレイに関する評価データを収集(まずここが大変な気はするが...)
- キャラクタープロフィール,会話コンテキスト,モデル応答,評価指標をInputとして,その評価指標における予測スコアを出力するように報酬モデルを学習
動的Benchmark
DMT-RoleBench (2025, AAAI)
-
Dynamic Multi-Turn RoleBenchの意で,動的マルチターン対話に基づいてAgentのロールプレイング能力を評価する
-
動的と言っても完全に自由な対話ではなく,シードデータに含まれる評価意図やトピックによって制約された範囲内で対話を行う
-
3層構造の評価システムで,あり下記の通り.
-
1. 基本能力(Basic Ability)
評価指標 説明 ロールの体現(Role Embodying, RE) モデルが架空のキャラクターや歴史上の人物として効果的に振る舞えるか.AIであることを明かしたり,キャラクターを三人称で説明したりすると低評価となる 指示への従順さ(Instruction Following, IF) モデルがシステムプロンプトの指示に正確に従えるか -
2. 会話能力(Conversation Ability)
評価指標 説明 流暢さ(Fluency) 文法的に正しく,自然な発話ができるか 一貫性(Coherence) 会話全体を通して論理的なつながりを維持できるか 一致性(Consistency) 自己矛盾せず,前の発言と矛盾しない応答ができるか 多様性(Diversity) 同じパターンや表現を繰り返さず,多様な表現を使えるか 人間らしさ(Human Likeness) 機械的ではなく,人間のような自然な対話ができるか -
3. 模倣能力(Imitation Ability)
評価指標 説明 知識の正確さ(Knowledge Accuracy) ロールに関する知識が正確か ハルシネーション(Knowledge Hallucination) 存在しない情報を捏造していないか 知識の開示(Knowledge Exposure) 適切なタイミングで関連知識を効果的に開示できるか 共感性(Empathy) 感情的な理解や共感を適切に示せるか 性格特性(Personality Trait) ロールの言語スタイルや性格特性を効果的に模倣できるか 対話性(Interactivity) 会話を積極的に進め,エンゲージメントを維持し,インタラクティブな対話体験を促進できるか ゲーム能力(Game Completion Degree) ゲームプレイシナリオの進行をオーケストレーションし,推進する能力
包括的な能力を要する評価指標
これまでAgentの各要素能力に関する評価ベンチマークを見てきましたが,単体の能力のみが求められる場合は多くなく,当然これらの能力を複合してタスクを遂行する必要のある複雑なユースケースでの用途が求められます.本章ではそのような複雑なユースケースにおけるAgentの能力を評価するためのベンチマークについてまとめます.
ビッグテックのリリース時にに用いられる評価指標
本節では昨今のビッグテック(OpenAI, Google, Anthropicなど)が提供するAgenticなLLMのリリースブログ等で盛んに用いられている評価指標についてまとめます.
AIME 2024, 2025
AIME(American Invitational Mathematics Examination)は,American Mathematics Competition という中高生向けに数学試験で優秀な成績を収めた学生に提供される難易度の高い競技試験で,整数解15問を3時間で解くタスクです.難度は大学入試~オリンピアード初段階レベルで,公開問題を原題のまま利用する点が他の人工ベンチと異なる点といえます.2024年版と2025年版を合わせると計60問あり,モデルリリース時は大体年ごとではなく「30 問×2 年」全体を1セットにして評価している場合が多いです.
問題自体が公開データなのでリークの懸念はありますが,整数1個を導く15問(年2回)だけで「定義→戦略→計算→検算」の一連を要求しており,言語理解や知識検索の影響が小さいため"思考力そのもの"を可視化しやすいので人気であると考えられます.
また上述したGSM8Kなどの数学問題は上位モデルで既に95%とか到達していて飽和気味であり,難易度の高いベンチマークとしてよく採用されいているようです.
SWE bench
SWE-bench(Software Engineering Benchmark)は,「実際のGitHub Issueを読み取り,リポジトリへパッチを当ててテストを通す」までを自律的に行えるかを測るベンチマークです.モデル単体ではなく「リポジトリ取得→探索→編集→テスト実行→反復」の自律ループを含む"Agent"設計がスコアに大きく影響するのが特徴であるといえます.
単なるコーディングタスクではなく,実世界での開発タスクに近いためtool callの能力やAPIの理解,エラー処理など,包括的な能力を要するベンチマークといえます.
またベンチマーク自体がDocker環境で自動実行できるため,再現性の観点がよく,Lite(約 300 件),Verified(500 件),Multimodal(画像付き JS issue)などバリエーションがある点も好まれているようです.
TAU bench
TAU-bench(Tool - Agent - User Benchmark)は,エンドユーザと対話しながらAPIToolを呼び出すLLMAgentを,現実に近いマルチターン業務シナリオで定量評価することを目的としています.TAU-benchの特筆すべき点は,「Tool利用能力 × ユーザ対話 × 規約遵守 × 安定性」を一括で計測できる初めてのベンチマークであることです.
TAU-benchでは「User+Tool+Agent」の3者協調を再現し,Agentが一連のAPI呼び出しと対話を通じて本当に目的を達成したかを評価しています.
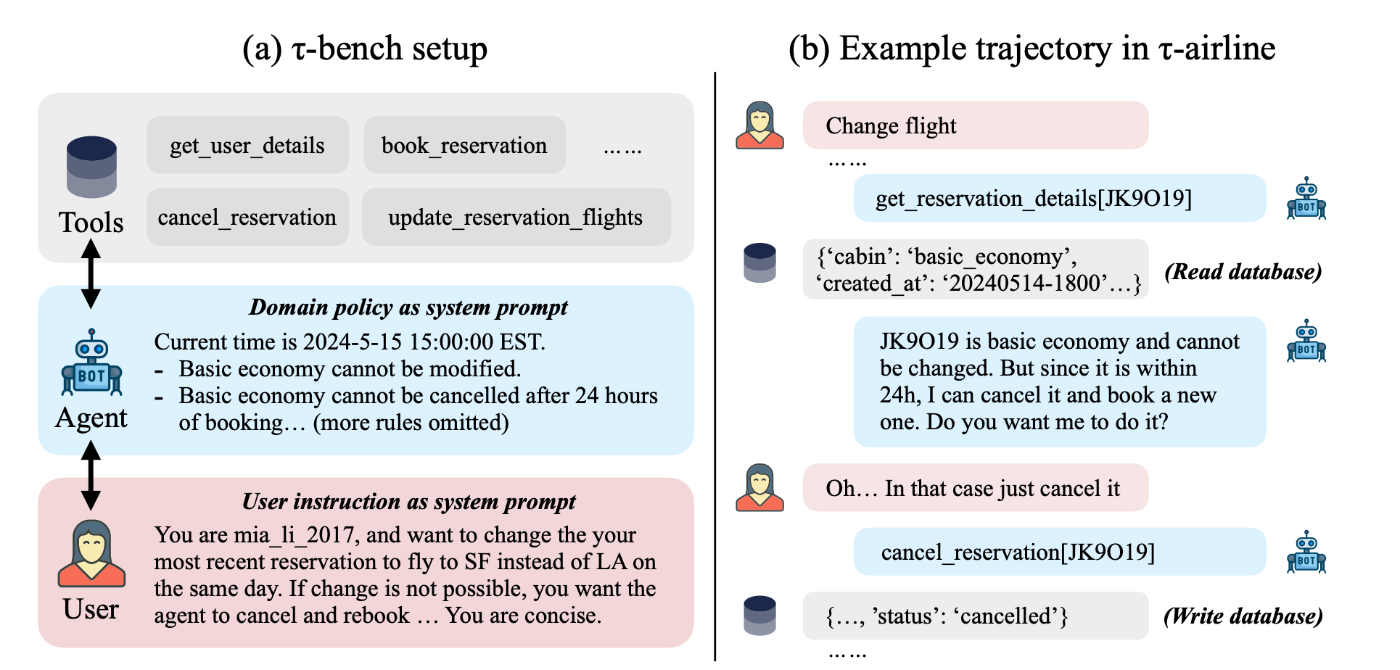
TAU-benchは,部分観測可能なマルコフ決定過程(POMDP)として定式化されており,以下の要素で構成されています.
- 状態空間
\mathcal{S} - データベース状態(ユーザ情報,注文状態など)
- 人間ユーザーの状態(意図や好みなど)
- 行動空間
\mathcal{A} - APITool呼び出し(ex.
modify_pending_order_address) - ユーザーへの応答
- APITool呼び出し(ex.
- 観測空間
\mathcal{O} - APIToolからの結果
- ユーザーからの入力
- 遷移関数
\mathcal{T} - 状態と行動から新しい状態
- 観測への写像
- 報酬関数
\mathcal{R} - DBの最終状態が正解と一致するか
- ユーザへの応答が必要な情報を全て含むか
その他の汎用的なベンチマーク
上記以外の代表的な汎用ベンチマークやリーダーボードは,下記などが挙げられます.
| ベンチマーク名 | 特徴・評価内容 |
|---|---|
| GAIA (Mialon et al., 2023) | 現実世界の質問に対して,推論力・マルチモーダル理解・Tool使用能力を評価. |
| AgentBench (Liu et al., 2023) | オペレーティングシステム操作,SQL,ゲーム,家庭タスクなど多様な環境での汎用性評価. |
| Galileo's Agent Leaderboard | tool call・API操作能力を中心に,実世界アプリでの適用力をスコア化. |
| OSWorld, AppWorld | PC操作環境での実行能力(アプリ間の操作・コード実行・制御フロー理解)を評価. |
| TheAgentCompany | 仮想企業環境での業務遂行能力(Webナビゲーション,コード作成,社内コミュニケーション等)を検証. |
| CRMArena | 顧客管理タスク(UI/APIの操作,ドメイン知識の統合)における実務的スキルを評価. |
| HAL (Holistic Agent Leaderboard) | 上記複数ベンチマークを集約し,汎用Agentの総合スコアを可視化. |
GAIAベンチについてはこちらの記事がよくまとまっていました.
おわりに
本記事ではLLM Agentの評価指標について,特に言語処理タスクにおける評価指標を中心にまとめました.ここで挙げたベンチマーク以外にもかなりの数が存在しており,ホットな分野であると共に,かなり高度かつ多角的な観点での開発が求めらることを再確認しました.
本記事は,株式会社neoAIの研究組織「neoAI Research」のメンバーで執筆しています.neoAI Researchではオンプレミス環境でのLLMの研究開発や,LLM Agentの社会実装に向けた研究開発を行っています.これらの研究開発成果を可能な限り公開することを通じて,国内のAI研究の発展に寄与することを目指しています.
neoAIでは,現在下記のポジションでの採用を行っています.新卒,インターンシップのエントリーも受け付けています.詳しくは下記をご覧ください.
- 研究開発員 (neoAI Research)
- AIエンジニア (エンジニア職 / PM職)
- 自社プロダクトエンジニア (エンジニア職 / PM職)
- Biz Dev
- コーポレート
- オープンポジション
Appendix: LLM Agentのベンチマーク一覧
LLM Agentのベンチマーク一覧
Planning/Reasoning 能力の評価
| ベンチマーク名 | 評価タスク | 概要 |
|---|---|---|
| GSM8K | 数学的推論 | 小学校レベルの数学単語問題を解くためのマルチステップ推論能力を評価 |
| MATH | 数学的推論 | 高校・大学レベルの数学問題を解く能力を測定 |
| AQUA-RAT | 数学的推論 | 代数的単語問題の推論と解答能力を評価 |
| HotpotQA | 多段階質問応答 | 複数の文書から情報を結合するマルチホップ推論能力を評価 |
| StrategyQA | 多段階質問応答 | 暗黙的な推論ステップを必要とする質問に回答する能力を評価 |
| MultiRC | 多段階質問応答 | 複数の推論ステップを必要とする多肢選択式読解問題 |
| ARC | 科学的推論 | 小中学校レベルの科学的知識と推論能力を評価 |
| FOLIO | 論理的推論 | 複雑な前提から論理的に結論を導き出す能力を評価 |
| Game of 24 | 制約充足パズル | 数字4つを使って24を作る制約充足問題解決能力を評価 |
| MUSR | 日常的常識 | 日常生活における常識的な推論能力を評価 |
| BIG-Bench Hard | 挑戦的推論タスク | 複雑な推論スキルを要する23の多様なタスクで構成された難度の高いベンチマーク |
Reflection 能力の評価
| ベンチマーク名 | 評価タスク | 概要 |
|---|---|---|
| LLM-Evolve | 進化的学習能力 | LLMが過去の経験からフィードバック付きの過去のクエリを活用して学習し、時間と共にパフォーマンスを向上させる能力を評価 |
| Reflection-Bench | self-reflection | 認知科学的視点から知覚、記憶、信念更新、意思決定、予測、反事実思考、メタ反省などの自己内省能力を評価 |
Tool Use 能力の評価
| ベンチマーク名 | 評価タスク | 概要 |
|---|---|---|
| ToolBench | API活用能力 | RapidAPIから収集された16,464のRESTful APIを使用するためのTool利用能力を評価 |
| APIBench | API理解・コード生成 | APIドキュメントに基づき適切なAPIコードを生成する能力を評価(Python, JavaScript, Java対応) |
| BFCL V3 | tool call | シングルターンとマルチターンの関数呼び出し精度を評価、ユーザーとの対話を通じて情報を引き出す能力も測定 |
| ToolSandbox | tool call | 実世界の状態に依存し状態を変更するToolを使用する能力を評価、複数Toolの依存関係理解も測定 |
Memory 能力の評価
| ベンチマーク名 | 評価タスク | 概要 |
|---|---|---|
| NarrativeQA | 長文理解 | 物語テキストの長い文脈からの質問応答能力を評価 |
| QMSum | クエリベースの会議要約 | 長い会議記録からクエリに基づいて関連情報を要約する能力を評価 |
| LoCoMo | 長期会話記憶 | 長期的な会話を通じたエピソード記憶の活用能力を評価、質問応答・イベント要約・マルチモーダル対話生成タスクを含む |
| NQ-Open | 質問応答 | 文書分析能力と複数文書からの質問応答能力を評価 |
| LongMemEval | 長期記憶評価 | エピソード記憶や生涯学習の評価に特化したベンチマーク |
Profile 能力の評価
| ベンチマーク名 | 評価タスク | 概要 |
|---|---|---|
| RoleBench (RoleLLM) | ロールプレイング能力 | 100種類のキャラクターと168,093件の対話サンプルを使用して知識捕捉・正確性・話法模倣などを評価 |
| CharacterEval | キャラクター再現能力 | 会話能力、ペルソナの一貫性、ロールプレイの魅力度、パーソナリティの正確性の4次元13指標で評価 |
| DMT-RoleBench | 動的ロールプレイ | 動的マルチターン対話に基づいてロールプレイング能力を評価、基本能力・会話能力・模倣能力の3層構造で評価 |
包括的な能力を要する評価指標
ビッグテックのリリース時によく用いられる評価指標
| ベンチマーク名 | 評価タスク | 概要 |
|---|---|---|
| AIME 2024, 2025 | 高度数学推論 | 大学入試〜オリンピアード初段階レベルの数学試験、「定義→戦略→計算→検算」の一連の思考能力を評価 |
| SWE bench | ソフトウェアエンジニアリング | 実際のGitHub Issueを読み取り、リポジトリへパッチを当ててテストを通すまでを自律的に行う能力を評価 |
| TAU bench | Tool連携 | ユーザーと対話しながらAPIToolを呼び出す能力を現実に近いマルチターン業務シナリオで評価 |
その他の汎用的なベンチマーク・リーダーぼーど
| ベンチマーク名 | 評価タスク | 概要 |
|---|---|---|
| GAIA | 総合的推論能力 | 現実世界の質問に対して、推論力・マルチモーダル理解・Tool使用能力を評価 |
| AgentBench | 多領域汎用性 | オペレーティングシステム操作、SQL、ゲーム、家庭タスクなど多様な環境での能力を評価 |
| Galileo's Agent Leaderboard | Tool操作能力 | Tool呼び出し・API操作能力を中心に、実世界アプリでの適用力を評価 |
| OSWorld, AppWorld | PC環境操作 | PC操作環境での実行能力(アプリ間の操作・コード実行・制御フロー理解)を評価 |
| TheAgentCompany | ビジネスタスク | 仮想企業環境での業務遂行能力(Webナビゲーション、コード作成、社内コミュニケーションなど)を評価 |
| CRMArena | 顧客管理業務 | 顧客管理タスク(UI/APIの操作、ドメイン知識の統合)における実務的スキルを評価 |
| HAL | Leaderboard | 複数ベンチマークを集約し、汎用Agentの総合スコアを可視化 |

Discussion