はじめに
株式会社neoAIのリサーチ部門で,AIリサーチャーとして所属している,東京大学松尾・岩澤研究室の山下佳威です.
今回は,Meta社により提供されている大規模言語モデル(Large-Language Model:LLM)のひとつのLlama-3.1-70Bを,Megatron-LMとGCPのクラウドコンピューティングリソースを用いて,日本語データセットを用いて継続事前学習を行う方法について解説します.
Megatron-LMとは
Megatron-LMとは,NVIDIAが開発した大規模言語モデル向けのトレーニングフレームワークであり,GPT, BERT, T5などのTransformerベースのモデルを効率的に学習するために設計されています.
Megatron-LMを用いることで,数百億から数兆のパラメータを持つLLMを,効率的に学習させることができます.主な特色として
- マルチノード,マルチGPU学習を利用した分散学習が行える
- GPUやCPUのリソースを効率的に利用することで高速な学習が行える
という特徴があります.
環境構築
今回はGoogle Cloud Platformで利用できるGoogle Compute Engine(GCE)を利用してマルチノード学習を行います.使用するGPUは, 1ノード毎に8GPU,8ノードを使用し,計8x8=64台のNVIDIA A100 80GBを利用して学習を行います.
インスタンスの立ち上げ
GCEのコンソール画面から,CREATE INSTANCE ボタンを押すことで,インスタンスの作成画面を開くことができます.まず,インスタンスの名前をつけますが,管理のしやすさの観点から,インスタンス間で名前を統一し,最後にindexを振ると管理しやすいかもしれません
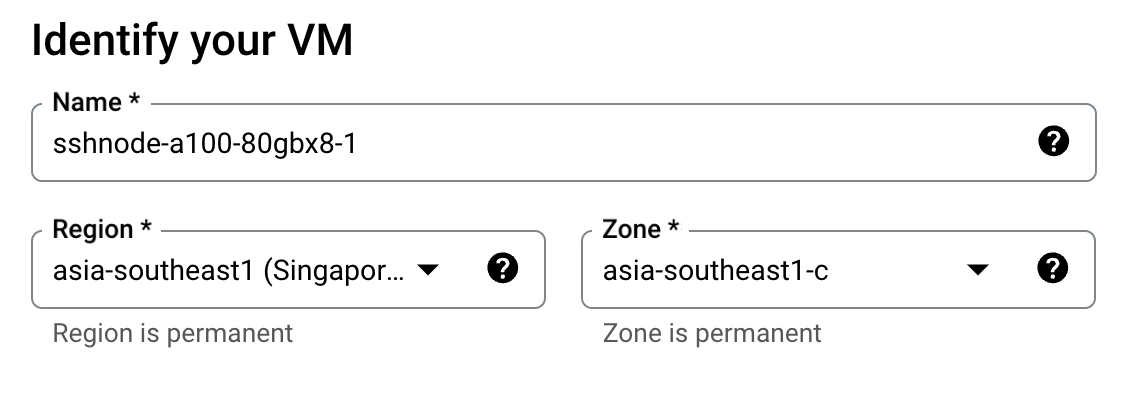
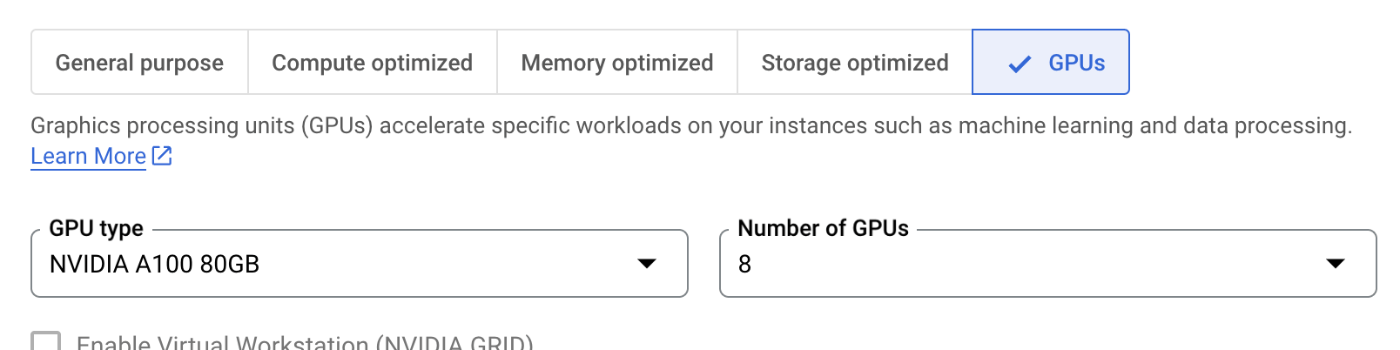
そして,machine configurationのセクションにおいて,GPUsでGPUの種類とその数を選択します
OS and Storageのセクションで,OSのImageと,Boot Storageのサイズを選択できます.今回は以下のように設定しました

次に,NetworkingのセクションでgVNICインターフェースの使用を選択します.

gVNICインターフェースを導入することで,通信パフォーマンスが向上することが期待されます.
また,advancedセクションにおいて,Metadataに以下の要素を追加することで,インスタンス初回起動時に求められるNVIDIA Driverのinstallを自動的に行うことができます

全8ノードをセットアップできたら,全て起動し,ログインできることを確認してください
ネットワークストレージの準備
GCPのストレージについて
GCEにおいて利用できるストレージには,Cloud Storage(GCS),Persistent Disk, FileStoreの3種類があり,それぞれに特性や推奨される利用シーンの違いがあります.
マルチノード学習においては,全てのノードから,プログラムやデータセット,モデルのcheckpointにアクセスできることが求められるため,関係するファイル群はすべて共有ストレージに配置することが効率的です.
今回は,データセットやモデルのcheckpointを,大量の非構造化データに適していており,アーカイブやバックアップにも適しているGCSを使用し,pythonの仮想環境や,Megatron-LMなどのプログラムファイルを高いthroughputと低いlatencyを特性とするFileStoreを使用します.
GCSとFileStoreの速度の違いについては,以下の記事が参考になります.
GCSとFileStoreのセットアップ
まずは,Google Cloudのコンソールにおいて,GCSのbucketと,FileStoreのインスタンスを作成します.両者とも,通信速度と,料金の観点から,上記のGPUインスタンスで選択したregionとなるべく近いところを選択することをお勧めします.
そして,以下の様にして,各インスタンス間で,絶対パスが変わらないように,マウントポイントを作成します
mkdir /home/$(whoami)/gcs
mkdir /home/$(whoami)/filestore
FileStoreのマウント
FileStoreは,通常のNFS通り,
sudo mount {filestore_IP}:{share_point} /home/$(whoami)/filestore
のような形で行うことができます.FileStoreのIPアドレスとshare_pointは,コンソールのFileStoreのインスタンスの詳細画面から確認することができます
GCSのマウント
GCSに接続するためには,サービスアカウントキーのjsonファイルを作成する必要があリます.
上のリンクの手順に従って,キーファイルをdownloadしたのちに,マウントしたfilestore内のいずれかにscpでjsonファイルを送信もしくは,Copy and Pasteでjsonファイルの中身を移してください.
そして,以下のコマンドでマウントを実行できます
gcsfuse --key-file {key-file-name}.json {bucket_name} "/home/$(whoami)/gcs"
マルチノードジョブの実行確認
今回,マルチノードのジョブ実行に,OpenMPIのmpirunコマンドを使用します.mpirunを用いたジョブ実行においては,一つのノードをマスターノードと定めて,そのマスタノードから,他のノードにsshで接続をすることで,ノード間の通信初期化を行うため,password freeでssh接続が行えることが必要となります.
まず,一つのノード(インスタンスの命名時に振ったindexが一番小さいものとか)を,マスターノードと定めて,そのノードでssh-keygenコマンドを用いて,鍵ペアを作成します.この際,キー名を変更したり,パスフレーズを設定しないようにしてください.
次に,マスターノードで下のコマンドを実行します.
ssh-keygen
cp -r ~/.ssh/id_rsa* /home/$(whoami)/filestore/keys/
そして,マスターノード以外の各ノードにおいて,以下のコマンドを実行します
cp -r /home/$(whoami)/filestore/keys/id_rsa* ~/.ssh/
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
chmod -R 600 ~/.ssh/
そして,マスターノード上から他の全てのノードに対して実際にssh接続を試行します
ssh {slave_node_name}
次にhostfileを以下の様に作成します
<instance_name_1> slots=8
<instance_name_2> slots=8
<instance_name_3> slots=8
...
slotsは,各ノードのGPU数を表します.
マスターノードから,次のコマンドを実行し,全ノードのhostnameが確認できれば成功です
mpirun -np 8 --npernode 1 --hostfile {path_to_hostfile} hostname
以降の作業は,基本的にマスターノード上で行ってください
ノード間通信の最適化
FastSocketをインストールすることで,NCCLパフォーマンスが向上します.
Fast Socketは以下のコマンドを実行することで,インストールできます
#!/bin/bash
echo "deb https://packages.cloud.google.com/apt google-fast-socket main" | sudo tee /etc/apt/sources.list.d/google-fast-socket.list
curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
sudo apt update && sudo apt install google-fast-socket
ただ,このスクリプトを全ノードで手動で行うのは煩雑なため,このスクリプトをスクリプトファイルとしてまとめ,mpirunを用いて実行することで一回の実行で全ノードでinstallできます
mpirun -np 8 --npernode 1 --hostfile {path_to_hostfile} script.sh
学習の準備
python仮想環境構築
まず,Megatron-LMをFileStore内にcloneします.
git clone https://github.com/NVIDIA/Megatron-LM.git
そして,pythonの仮想環境構築のためにpyenvを利用します
git clone https://github.com/pyenv/pyenv.git /home/$(whoami)/filestore/.pyenv
echo 'export PYENV_ROOT="/home/$(whoami)/filestore/.pyenv"' >> ~/.bashrc
echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bashrc
echo 'eval "$(pyenv init -)"' >> ~/.bashrc
そして,pythonの仮想環境をsetupします.
pyenv install 3.10
pyenv global 3.10
python --version
python -m venv .venv
source .venv/bin/activate
以下に示すrequirements.txtに従って,packageをinstallします
requirements.txt
accelerate==1.0.0
annotated-types==0.7.0
cachetools==5.5.0
certifi==2024.8.30
charset-normalizer==3.3.2
click==8.1.7
cmake==3.30.4
colorama==0.4.6
docker-pycreds==0.4.0
einops==0.8.0
filelock==3.16.1
flash-attn==2.5.8
fsspec==2024.9.0
gitdb==4.0.11
GitPython==3.1.43
huggingface-hub==0.25.1
idna==3.10
importlib_metadata==8.5.0
Jinja2==3.1.4
joblib==1.4.2
MarkupSafe==2.1.5
mpmath==1.3.0
networkx==3.3
ninja==1.11.1.1
numpy==1.23.5
nvidia-cublas-cu12==12.1.3.1
nvidia-cuda-cupti-cu12==12.1.105
nvidia-cuda-nvrtc-cu12==12.1.105
nvidia-cuda-runtime-cu12==12.1.105
nvidia-cudnn-cu12==9.1.0.70
nvidia-cufft-cu12==11.0.2.54
nvidia-curand-cu12==10.3.2.106
nvidia-cusolver-cu12==11.4.5.107
nvidia-cusparse-cu12==12.1.0.106
nvidia-ml-py==12.535.161
nvidia-nccl-cu12==2.20.5
nvidia-nvjitlink-cu12==12.6.77
nvidia-nvtx-cu12==12.1.105
nvitop==1.3.2
packaging==24.1
pillow==10.4.0
platformdirs==4.3.6
protobuf==5.28.2
psutil==6.0.0
pybind11==2.13.6
pydantic==2.9.2
pydantic_core==2.23.4
python-config==0.1.2
PyYAML==6.0.2
regex==2024.9.11
regrex==1.3
requests==2.32.3
safetensors==0.4.5
scikit-learn==1.5.2
scipy==1.14.1
sentencepiece==0.2.0
sentry-sdk==2.15.0
setproctitle==1.3.3
six==1.16.0
smmap==5.0.1
sympy==1.13.3
termcolor==2.4.0
threadpoolctl==3.5.0
tokenizers==0.20.0
torch==2.4.1
torchaudio==2.4.1
torchvision==0.19.1
tqdm==4.66.5
transformers==4.45.1
triton==3.0.0
typing_extensions==4.12.2
urllib3==2.2.3
wandb==0.18.3
zipp==3.20.2
pip install -r requirements.txt
Megatron-LM内の,megatron/core/datasets/Makefileが以下の用になっていると思います
CXXFLAGS += -O3 -Wall -shared -std=c++11 -fPIC -fdiagnostics-color
CPPFLAGS += $(shell python3 -m pybind11 --includes)
LIBNAME = helpers
LIBEXT = $(shell /home/$(whoami)/nfs/.pyenv/shims/python3-config --extension-suffix)
default: $(LIBNAME)$(LIBEXT)
%$(LIBEXT): %.cpp
$(CXX) $(CXXFLAGS) $(CPPFLAGS) $< -o $@
このLIBEXTの,python3-configのパスを適宜修正した上で,makeコマンドを実行し,ビルドを実行してください
Apexのinstall
次に,NVIDIA Apexをinstallします 公式のREADMEによれば,
git clone https://github.com/NVIDIA/apex
cd apex
# if pip >= 23.1 (ref: https://pip.pypa.io/en/stable/news/#v23-1) which supports multiple `--config-settings` with the same key...
pip install -v --disable-pip-version-check --no-cache-dir --no-build-isolation --config-settings "--build-option=--cpp_ext" --config-settings "--build-option=--cuda_ext" ./
# otherwise
pip install -v --disable-pip-version-check --no-cache-dir --no-build-isolation --global-option="--cpp_ext" --global-option="--cuda_ext" ./
でinstallできます.
TransformerEngineのinstall
最後に,Transformer Engineをinstallします. 公式のREADMEに従い,
pip install git+https://github.com/NVIDIA/TransformerEngine.git@stable
でinstallできますが,
stable版には上記のcommitが取り入れられておらず,checkpointの保存時にerrorを起こす場合があるので,手動で,このcommitを反映させておきましょう
また,TransformerEngine系のプログラムにおいて,libnv系のファイルがシンボリックリンクではないといったエラーが出る場合があります.その際は,mpirunなどを使って,以下のスクリプトを実行しておきましょう.
#!/bin/bash
sudo rm /lib/libnvinfer_vc_plugin.so.8
sudo ln -s /lib/libnvinfer_vc_plugin.so.8.6.1 /lib/libnvinfer_vc_plugin.so.8
sudo rm /lib/libnvinfer_dispatch.so.8
sudo ln -s /lib/libnvinfer_dispatch.so.8.6.1 /lib/libnvinfer_dispatch.so.8
sudo rm /lib/libnvinfer_plugin.so.8
sudo ln -s /lib/libnvinfer_plugin.so.8.6.1 /lib/libnvinfer_plugin.so.8
sudo rm /lib/libnvonnxparser.so.8
sudo ln -s /lib/libnvonnxparser.so.8.6.1 /lib/libnvonnxparser.so.8
sudo rm /lib/libnvparsers.so.8
sudo ln -s /lib/libnvparsers.so.8.6.1 /lib/libnvparsers.so.8
sudo rm /lib/libnvinfer.so.8
sudo ln -s /lib/libnvinfer.so.8.6.1 /lib/libnvinfer.so.8
sudo rm /lib/libnvinfer_lean.so.8
sudo ln -s /lib/libnvinfer_lean.so.8.6.1 /lib/libnvinfer_lean.so.8
チェックポイントの変換
Megatron-LMでは,Tensor Parallel, Pipeline Parallelといったモデル並列技術を利用することによる,大規模なモデルの学習を可能としています.そのために,Megatron-LMでは前もって,学習時に設定するTensor Parallelサイズと,Pipeline Parallelサイズ用にモデルのcheckpointを変換する必要があります.
オリジナルのcheckpointのdownload
オリジナルのcheckpointをダウンロードするために,HuggingFaceのリポジトリにアクセスします.Llama-3.1-70Bを利用するには,アクセス権を取得する必要があるため,リポジトリの申請欄から申請を行ってください(すぐに許可が降りると思います)
HuggingFaceのアカウントメニューから,Tokenを発行し,以下のコマンドと発行したTokenを使ってログインします.
huggingface-cli login
そして,適当なGCS内のディレクトリ内にdownloadを行います
huggingface-cli download --repo-type=model meta-llama/Llama-3.1-70B --localdir={somewhere_in_gcs} --max-workers=64
Megatron-LM形式に変換
そして,ダウンロードしてきたHF形式のCheckpointを,特定のTP Size, PP SizeでのMegatronLM形式のCheckpointに以下のスクリプトでconvertします
#!/bin/bash
# distributed settings
TENSOR_PARALLEL_SIZE=8 # fixed
PIPELINE_PARALLEL_SIZE=2
# model config
HF_FORMAT_DIR={the directory where the HF format checkpoint is saved}
MEGATRON_FORMAT_DIR={the directory where the conveted checkpoint should be saved}/megatron_tp${TENSOR_PARALLEL_SIZE}_pp${PIPELINE_PARALLEL_SIZE}
mkdir -p ${MEGATRON_FORMAT_DIR}
# tokenizer config
TOKENIZER_MODEL="meta-llama/Llama-3.1-70B"
cd {Megatron-LM Root Dir}
python tools/checkpoint/convert.py \
--bf16 \
--model-type GPT \
--loader llama_mistral \
--saver mcore \
--target-tensor-parallel-size ${TENSOR_PARALLEL_SIZE} \
--target-pipeline-parallel-size ${PIPELINE_PARALLEL_SIZE} \
--checkpoint-type hf \
--load-dir ${HF_FORMAT_DIR} \
--save-dir ${MEGATRON_FORMAT_DIR} \
--tokenizer-model ${TOKENIZER_MODEL} \
--model-size llama3-70B \
ここで,Megatron-LMのDocumentによれば,Llama-3.1 70BのTPは,8にすることが推奨されています.
Datasetの前処理
今回は,約342B Tokenほどの日本語の事前学習用データセットを構築し,学習を行いました.
datasetは,jsonl.gz形式のファイルの集まりであることを前提とします.
datasetが配置されているディレクトリから,以下のコマンドを用いて,全ての"jsonl.gz"ファイルのパスを出力します
find {absolute_data_root_path} -type f -name "*.jsonl.gz" > data_paths.txt
そして,以下のコマンドを利用して,dataの前処理を行います
#!/bin/bash
# テキストファイルのパス
FILE_PATHS="data_paths.txt"
BASE_PATH={the dataset root path}
OUTPUT_ROOT={the directory where the processed data should be saved}
mkdir -p $OUTPUT_ROOT
# ファイルが存在するか確認
if [ ! -f "$FILE_PATHS" ]; then
echo "$FILE_PATHS ファイルが見つかりません。"
exit 1
fi
# テキストファイルを一行ずつ読み込み
while IFS= read -r path; do
# 空行を無視
if [ -z "$path" ]; then
continue
fi
relative_path=$(realpath --relative-to="$BASE_PATH" "$path")
output_prefix="${OUTPUT_ROOT}${relative_path}"
output_dir=$(dirname $output_prefix)
mkdir -p $output_dir
# Pythonスクリプトを実行し、ファイルパスを渡す
python tools/preprocess_data.py --input "$path" --output-prefix $output_prefix --tokenizer-type HuggingFaceTokenizer --tokenizer-model meta-llama/Llama-3.1-70B --append-eod --workers 64
sleep 1
done < "$FILE_PATHS"
このpreprocessのスクリプトを実行すると,data fileごとにbinファイルとidxファイルが生成されます.
学習
現状のMegatron-LMは,mpirunランチャーを用いた実行に直接対応していないため,対応させるための変更を行います.
megatron/training/arguments.pyの,parse_args関数内の,return文の直前に,以下のセクションを挿入します.
if args.use_mpi:
global_rank = int(os.getenv('OMPI_COMM_WORLD_RANK', 0))
local_rank = int(os.getenv('OMPI_COMM_WORLD_LOCAL_RANK', 0))
world_size = int(os.getenv('OMPI_COMM_WORLD_SIZE', 1))
os.environ['RANK'] = str(global_rank)
os.environ['LOCAL_RANK'] = str(local_rank)
os.environ['WORLD_SIZE'] = str(world_size)
args.rank = int(os.getenv('RANK', '0'))
args.world_size = int(os.getenv("WORLD_SIZE", '1'))
args.local_rank = local_rank
また,_add_distributed_args関数内に,以下のセンテンスを挿入してください
group.add_argument('--use-mpi',action='store_true', help="when using mpirun, set this argument")
そして,以下のスクリプトが学習スクリプトとなります.
train.sh
#!/bin/bash
export MASTER_ADDR=sshnode-a100-80gbx8-1
export MASTER_PORT=8888
export WANDB_API_KEY=<your_wandb_api_key>
export HUGGINGFACE_TOKEN=<your_huggingface_token>
export NUM_GPU_PER_NODE=8
source ~/.bashrc
export NUM_NODES=8
NUM_GPUS=$((${NUM_NODES} * ${NUM_GPU_PER_NODE}))
# model config
HIDDEN_SIZE=8192
FFN_HIDDEN_SIZE=28672 # intermediate size (HuggingFace)
NUM_LAYERS=80
NUM_HEADS=64
SEQ_LENGTH=8192
# distributed settings
TENSOR_PARALLEL_SIZE=8 # fixed
PIPELINE_PARALLEL_SIZE=2
DATA_PARALLEL_SIZE=$((${NUM_GPUS} / (${TENSOR_PARALLEL_SIZE} * ${PIPELINE_PARALLEL_SIZE})))
# training config
MICRO_BATCH_SIZE=1
GLOBAL_BATCH_SIZE=1024
TRAIN_STEPS=25000
LR=1e-4
MIN_LR=3.3e-6
LR_WARMUP_STEPS=1000
WEIGHT_DECAY=0.1
GRAD_CLIP=1
# model config
TOKENIZER_MODEL=meta-llama/Meta-Llama-3.1-70B
CHECKPOINT_DIR={the path where the converted checkpoint is saved}/Llama-3-1-70b-megatron_tp${TENSOR_PARALLEL_SIZE}_pp${PIPELINE_PARALLEL_SIZE}
CHECKPOINT_SAVE_DIR={the path where the checkpoint should be saved }Meta-Llama-3.1-70B_Megatron-LM_tp${TENSOR_PARALLEL_SIZE}_pp${PIPELINE_PARALLEL_SIZE}
mkdir -p ${CHECKPOINT_SAVE_DIR}
# data config
DATASET_DIR={the processed dataset root}
### DATASETS ver.2024/10/07 ###
DATA_PATH=""
# pretrain text
DATA_PATH="${DATA_PATH} 1 ${DATASET_DIR}/pretrain_datasets/data_1"
DATA_PATH="${DATA_PATH} 1 ${DATASET_DIR}/pretrain_datasets/data_2"
DATA_PATH="${DATA_PATH} 1 ${DATASET_DIR}/pretrain_datasets/data_3"
# job name
JOB_NAME="Llama-3.1-70B_Inst-Pretrain-${NODE_TYPE}-${NUM_NODES}node-${NUM_GPUS}gpu-${SEQ_LENGTH}s-DP=${DATA_PARALLEL_SIZE}-TP=${TENSOR_PARALLEL_SIZE}-PP=${PIPELINE_PARALLEL_SIZE}-BS=${GLOBAL_BATCH_SIZE}-LR=${LR}-MINLR=${MIN_LR}-WARMUP=${LR_WARMUP_STEPS}-WD=${WEIGHT_DECAY}-GC=${GRAD_CLIP}"
# --norm-epsilon 1e-5 : conifg.json (RMS norm)
# checkpoint load
if [ -f "${CHECKPOINT_SAVE_DIR}/latest_checkpointed_iteration.txt" ]; then
# resume training
CHECKPOINT_ARGS="--load ${CHECKPOINT_SAVE_DIR}"
else
# first training
CHECKPOINT_ARGS="--load ${CHECKPOINT_DIR} --no-load-rng --no-load-optim"
fi
# GPU
echo "The CHECKPOINT ARG is: ${CHECKPOINT_ARGS}"
export WORLD_SIZE=$NUM_GPUS
export CUDA_DEVICE_MAX_CONNECTIONS=1
export WORKING_DIR=$(pwd)
export PYENV_ROOT=$HOME/nfs/.pyenv
export PATH=$PATH:$PYENV_ROOT/bin
# run
mpirun -np $WORLD_SIZE --hostfile {path_to_hostfile} \
--npernode $NUM_GPU_PER_NODE \
-x MASTER_ADDR=$MASTER_ADDR \
-x MASTER_PORT=$MASTER_PORT \
-x CUDA_DEVICE_MAX_CONNECTIONS=1 \
-x WANDB_API_KEY=$WANDB_API_KEY \
-x HUGGINGFACE_TOKEN=$HUGGINGFACE_TOKEN \
-x LD_LIBRARY_PATH \
-x NCCL_P2P_LEVEL=NVL \
-bind-to none -map-by slot \
-mca pml ob1 -mca btl ^openib \
bash -c "ulimit -n 100000 && cd {megatron_root} \
&& source {venv_root}/bin/activate && \
python pretrain_gpt.py \
--tensor-model-parallel-size ${TENSOR_PARALLEL_SIZE} \
--pipeline-model-parallel-size ${PIPELINE_PARALLEL_SIZE} \
--sequence-parallel \
--use-distributed-optimizer \
--num-layers ${NUM_LAYERS} \
--hidden-size ${HIDDEN_SIZE} \
--ffn-hidden-size ${FFN_HIDDEN_SIZE} \
--num-attention-heads ${NUM_HEADS} \
--seq-length ${SEQ_LENGTH} \
--max-position-embeddings ${SEQ_LENGTH} \
--micro-batch-size ${MICRO_BATCH_SIZE} \
--global-batch-size ${GLOBAL_BATCH_SIZE} \
--train-iters ${TRAIN_STEPS} \
--tokenizer-type HuggingFaceTokenizer \
--tokenizer-model ${TOKENIZER_MODEL} \
--use-checkpoint-args \
${CHECKPOINT_ARGS} \
--save ${CHECKPOINT_SAVE_DIR} \
--data-path ${DATA_PATH} \
--split 949,50,1 \
--distributed-backend nccl \
--init-method-std 0.02 \
--lr ${LR} \
--min-lr ${MIN_LR} \
--lr-decay-style cosine \
--weight-decay ${WEIGHT_DECAY} \
--clip-grad ${GRAD_CLIP} \
--lr-warmup-iters ${LR_WARMUP_STEPS} \
--optimizer adam \
--adam-beta1 0.9 \
--adam-beta2 0.95 \
--log-interval 1 \
--save-interval 10 \
--eval-interval 100 \
--eval-iters 10 \
--bf16 \
--untie-embeddings-and-output-weights \
--use-rotary-position-embeddings \
--normalization RMSNorm \
--norm-epsilon 1e-6 \
--no-position-embedding \
--no-masked-softmax-fusion \
--attention-dropout 0.0 \
--hidden-dropout 0.0 \
--swiglu \
--use-flash-attn \
--recompute-activations \
--recompute-granularity "selective" \
--num-workers 1 \
--use-mpi \
--distributed-timeout-minutes 600 \
--log-params-norm \
--log-throughput \
--wandb-exp-name ${JOB_NAME} \
--wandb-project "Llama-3.1-70B-inst-pretrain" \
--no-async-tensor-model-parallel-allreduce"
この学習スクリプト内の,
### DATASETS ver.2024/10/07 ###
DATA_PATH=""
# pretrain text
DATA_PATH="${DATA_PATH} 1 ${DATASET_DIR}/pretrain_datasets/data_1"
DATA_PATH="${DATA_PATH} 1 ${DATASET_DIR}/pretrain_datasets/data_2"
DATA_PATH="${DATA_PATH} 1 ${DATASET_DIR}/pretrain_datasets/data_3"
では,前処理によって生成された,binとidxファイルのペアから,拡張子を抜いたパスを指定します.また,パスの前に指定している1という数字は,それぞれのデータの混合比率を表しています.
このシェルスクリプトを利用して学習を行うことができます
train.sh > output.log 2> error.log
学習が進めば,次のようにloss curveを確認できると思います

最後に
こちらのテックブログは、画像生成やLLM開発などを通して、社内の技術力を先導しているneoAIの研究組織「neoAI Research」メンバーで執筆しています。
「未来を創る生成AIの先駆者になろう」
neoAIでは最先端技術を駆使するプロフェッショナル集団として、業務効率化を超えて社会に新たな価値を創出していきます。あなたの好奇心と可能性を、neoAIで開花させてみませんか?
【現在採用強化中です!】
・AIエンジニア/PM職
・Biz Dev
・自社プロダクトエンジニア職
・オープンポジション
【詳しい採用情報はこちらから!】

Discussion