AWS DynamoDBについてチュートリアルで学習してみた
DynamoDBとは
AWSが提供する、キー値ストア型のフルマネージド型NoSQLデータベースサービスです。
NoSQLデータベースとは
リレーショナルデータベースとは異なる非構造化データや大量のデータを柔軟に格納・処理するためのデータベースの一種です。従来のリレーショナルデータベースシステム(RDBMS)のように複数のテーブルを相互に結合する機能を提供していません。
大量のデータを高速に処理する必要がある場合に向いているので、ソーシャルメディア、eコマース、コンテンツ管理システム、ビッグデータ分析などに使用されます。
データの一貫性よりも可用性とスケーラビリティを目的として、結果整合性などの緩やかな整合性モデルを採用していることが多いです。DynamoDBもデフォルトでは、読み取り操作を結果整合性を提供してします。
結果整合性
書き込み操作が完了してからわずかな時間が経過した後にデータを読み取る場合、その読み取りがまだ古いデータを返す可能性があることを意味しており、ユーザからのアクセスが多い箇所やリアルタイム性が重視される場面で使用されます。
ちなみに、通常は数百ミリ秒以内に全てのコピーが最新の状態に更新され、読み取りは最新のデータを反映するようになります。
強力な整合性のある読み込み(強整合性)
可用性よりもデータの一貫性を目的としているので、データの信頼性が求められるユーザ情報の更新や支払い処理などの場面で使用されます。
DynamoDBでは、get、query、scan操作などに対するConsistentReadパラメータをtrueに設定した場合に利用できます。
最新データを返しますが、データを取得するのに必要なRCUが2倍になるため、料金も2倍かかります。
データ型
S は文字列 (String)
N は数値 (Number)
B はバイナリ (Binary)
BOOL はブール値 (Boolean)
NULL は null 値
M はマップ (Map)
L はリスト (List)
SS は文字列のセット (String Set)
NS は数値のセット (Number Set)
BS はバイナリのセット (Binary Set)
使用例
const item = {
name: { S: req.body.name },
};
await dynamoDBClient.send(
new PutItemCommand({
TableName: 'test',
Item: item,
})
);
RCU
RCU(Read Capacity Units)は、DynamoDBテーブルから読み取ることができるデータアイテムの数を表します。
1つのRCUは、1秒間に最大で4KBのデータを読み取ることができます。この値は、DynamoDBテーブルの読み取りスループットを定義します。例えば、RCUが100であれば、1秒間に100つのデータアイテムを1つのテーブルから読み取ることができます。
WCU
WCU(Write Capacity Units)は、DynamoDBテーブルに書き込むことができるデータアイテムの数を表します。
1つのWCUは、1秒間に最大で1KBのデータを書き込むことができます。この値は、DynamoDBテーブルの書き込みスループットを定義します。例えば、WCUが50であれば、1秒間に50つのデータアイテムを1つのテーブルに書き込むことができます。
可用性(Availability)
システムが正常に動作し、利用可能な状態にある時間の割合を示します。
可用性が高いシステムは、ユーザーが必要なときに常にサービスにアクセスできることを保証します。
高可用性を実現するためには、システムの冗長性、障害対応能力、負荷分散、自動フェイルオーバーなどの機能が重要です。
スケーラビリティ
システムが負荷の増加に対して柔軟に対応し、性能を維持または向上させる能力を指します。
スケーラビリティが高いシステムは、ユーザー数やデータ量が増加しても安定したパフォーマンスを提供できます。
垂直スケーリング(Vertical Scaling)と水平スケーリング(Horizontal Scaling)の2つの方法があります。
垂直スケーリング
単一のマシンやリソースの能力を増やすことでスケーリングを実現します。
水平スケーリング
複数のマシンやノードを追加して負荷を分散することでスケーリングを実現します。
NoSQLの種類
キー値ストア型
下記は、主キーと値のペアが格納されたキー値ストア型のデータベースを表しています。
1つの主キーに1つの値のペアを関連付ける単純な構造です。
| 主キー | 値 |
|---|---|
| 1 | バナナ |
| 2 | りんご |
| 3 | オレンジ |
パーティションキー
パーティションキーは主キー(プライマリキー)の一部です。
ソートキー:オプション
オプションで設定することができ、アイテムをソートするために使用されます。
ソートキーはパーティションキーと組み合わせることで複合主キーを形成します。
主キー(プライマリキー)
DynamoDBでは、パーティションキーとソートキー(オプション)の組み合わせです。
パーティションキーとソートキー(オプション)の組み合わせた場合には、複合主キーと呼ばれます。
チュートリアル
DynamoDBをコンソールからNoSQLテーブルを作成およびクエリを実行してみます。
チュートリアル一覧
カテゴリは未設定の属性ですが、下記のような構造になります。
| artist(パーティションキー) | songTitle(ソートキー) | category(その他の属性) |
|---|---|---|
| No One You Know | My Dog Spot | Text |
| The Acme Band | Look Out, World | Text |
NoSQLテーブルの作成
テーブルの作成を選択、
テーブル名には、Music
パーティションキーは、artist
ソートキーにsongTitleと入力してください。

下記をそれぞれ選択して、
テーブル設定 > 設定をカスタマイズ
テーブルクラス > DynamoDB 標準
読み込み/書き込みキャパシティーの設定 > キャパシティーモード > プロビジョンド

下にスクロースしてテーブルの作成を選択してください。

Musicテーブルが作成されたことを確認してください。

データの追加
テーブルを選択して、項目を探索を選択、

項目を作成を選択、
artist属性に、No One You Know、
songTitle属性にCall Me Todayと入力したら、項目を作成を押してください。

さらに下記のデータを追加してください。
Artist: No One You Know、songTitle: My Dog Spot
Artist: No One You Know、songTitle: Somewhere Down The Road
Artist: The Acme Band、songTitle: Still in Love
Artist: The Acme Band、songTitle: Look Out, World
クエリの実行
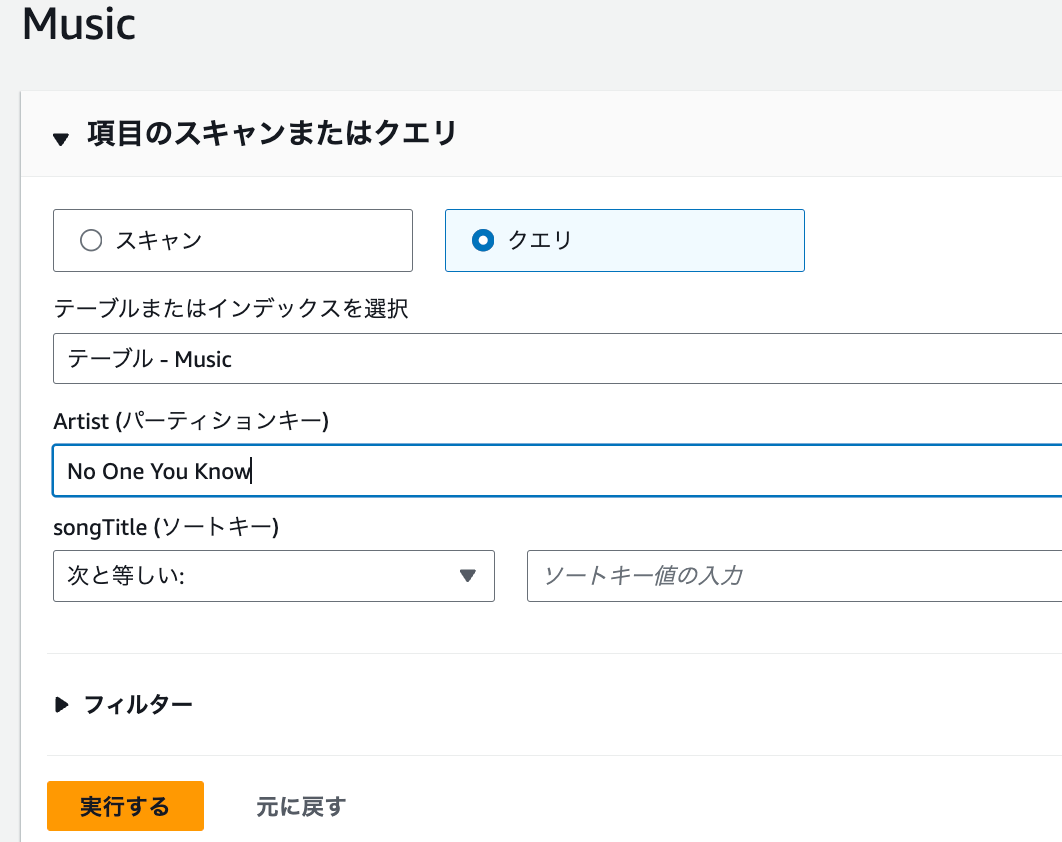
項目のスキャンまたはクエリを選択、

クエリを選択、artist (パーティションキー)にNo One You Knowと入力したら、
実行するを押してください。
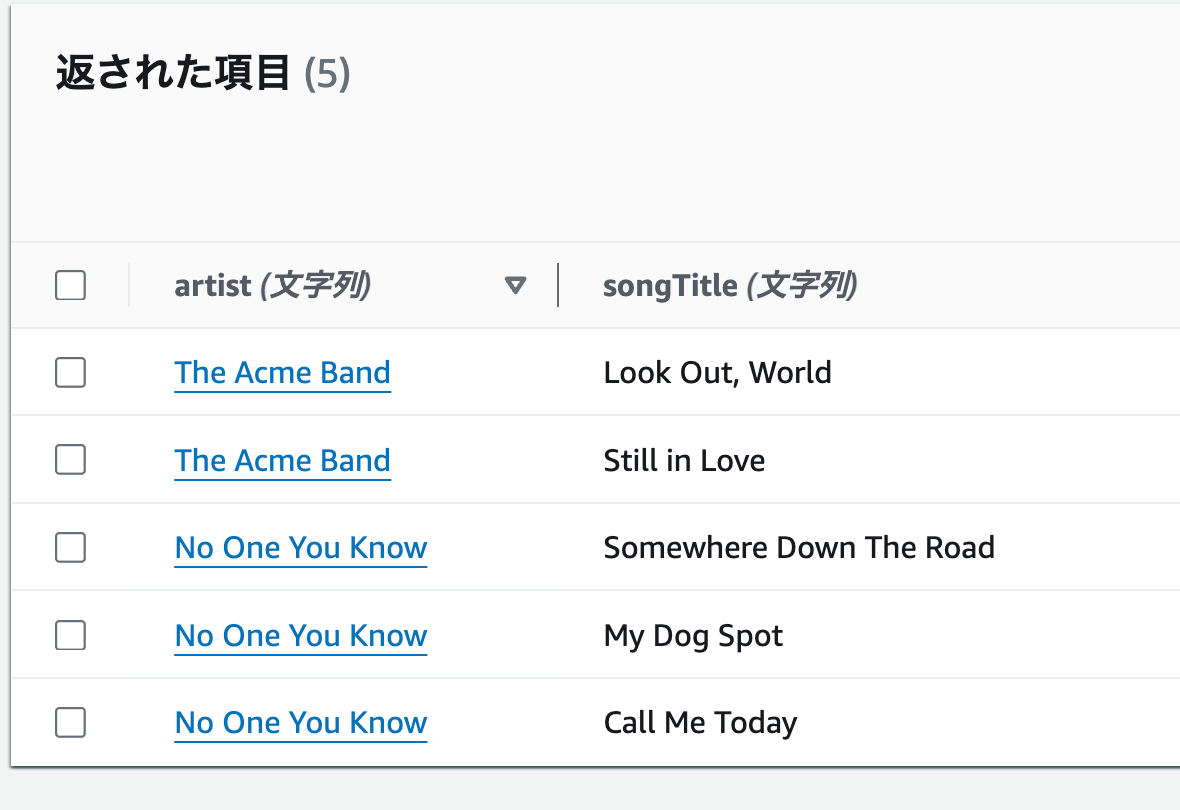
artist (パーティションキー)がNo One You Knowのすべての曲が表示されます。
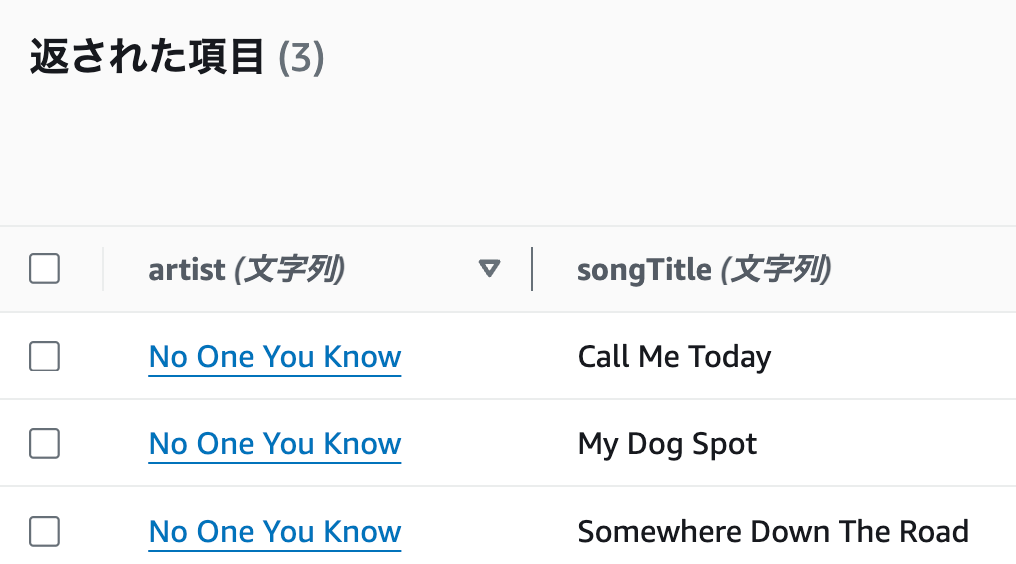
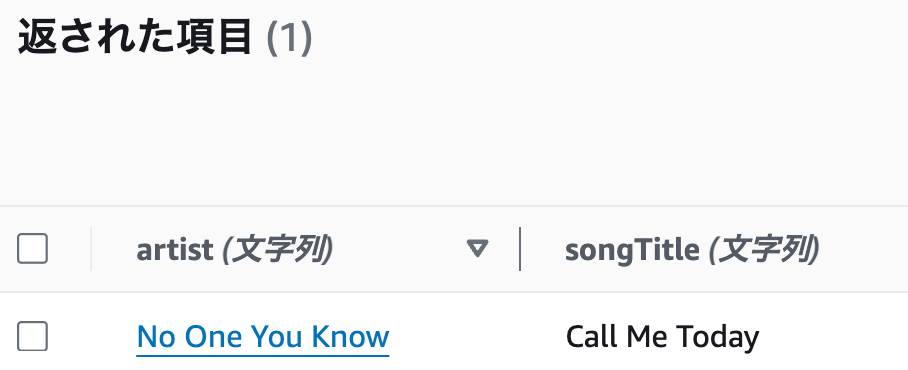
songTitle (ソートキー)にCall Me Todayを追加して、実行するを押してください。

artist (パーティションキー)がNo One You Know、
songTitle (ソートキー)にCall Me Todayのみ表示されると思います。
項目の削除
削除したい項目を選択し、アクション > 項目の削除を押してください。

選択した項目が削除されているか確認してください。

列(属性)の追加
アクション > 項目を作成
新しい属性の追加 > 型を選択してください。
全て入力し、項目を作成を押してください。
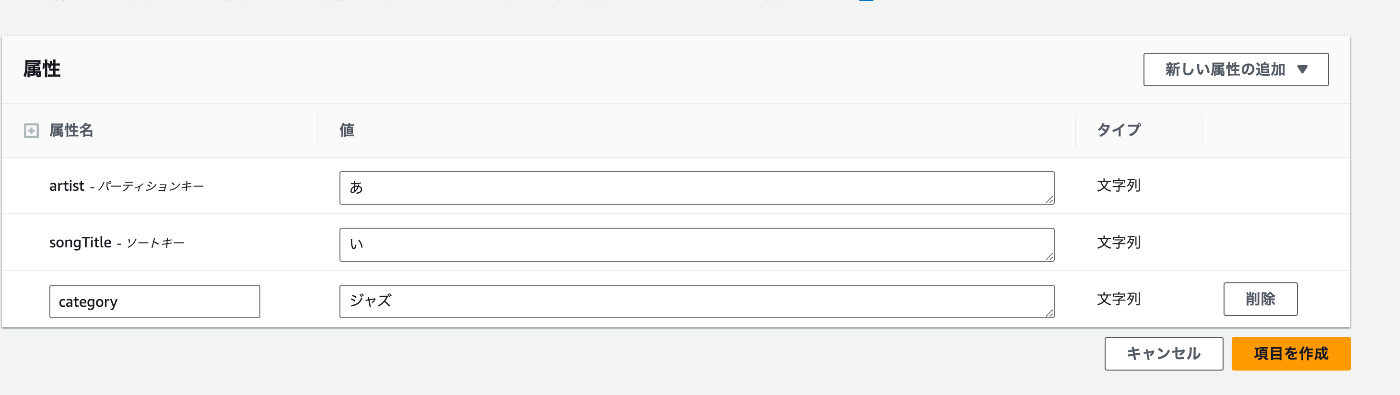
新しい列が追加されます。

DynamoDBを操作する方法
DynamoDBを操作する方法として、コンソール以外の方法は次のようなものがあります。
AWS CLI を使用する方法
例えば特定のテーブルからアイテムを取得することができます。
aws dynamodb scan --table-name <テーブル名>
今回の場合、以下のように表示されます。Sは文字列型を示しています。
ちなみに整数型はNです。
{
"Items": [
{
"artist": {
"S": "No One You Know"
},
"songTitle": {
"S": "My Dog Spot"
}
},
{
"artist": {
"S": "No One You Know"
},
"songTitle": {
"S": "Somewhere Down The Road"
}
},
{
"artist": {
"S": "The Acme Band"
},
"songTitle": {
"S": "Look Out, World"
}
},
{
"artist": {
"S": "The Acme Band"
},
"songTitle": {
"S": "Still in Love"
}
}
],
"Count": 4,
"ScannedCount": 4,
"ConsumedCapacity": null
}
先ほどのコマンドはテーブル内の全アイテムをスキャンして返しますが、大きなテーブルでは時間とコストがかかるため、次のように適切なオプションを使用して必要なデータのみを取得してください。
aws dynamodb scan \
--table-name <テーブル名> \
--filter-expression "artist = :artistName" \
--expression-attribute-values '{":artistName":{"S":"The Acme Band"}}'
:artistNameは、プレースホルダーで、クエリや式内で、後で具体的な値が置き換えられる場所を指しています。
--expression-attribute-values オプションは、プレースホルダー(:artistName`)に対応する値を指定しています。
すなわち、--filter-expressionと --expression-attribute-valuesで使用しているプレースホルダーの名前が一致している必要があります。
主キーは、プレースホルダーを使用しませんが、主キー以外の属性は属性名を記述する際にプレースホルダーを使用する必要があります。
先ほどと表示される内容が変わっていることを確認してください。
{
"Items": [
{
"artist": {
"S": "The Acme Band"
},
"songTitle": {
"S": "Look Out, World"
}
},
{
"artist": {
"S": "The Acme Band"
},
"songTitle": {
"S": "Still in Love"
}
}
],
"Count": 2,
"ScannedCount": 4,
"ConsumedCapacity": null
}
AWS SDK
下記を参考にしてください。(後で追記します。)
Amplify
Amplifyを使用している場合は、amplifyコマンドなどを使ってデータにアクセスDynamoDBのデータにクエリを実行することが可能だと思います。
Gen1の場合
Gen2の場合
CLI
GUIツール
下記を参考にしてください。
料金
次の2つのモードから選択します。モードによって料金の計算が異なります。
オンデマンドキャパシティーモード
柔軟性が高く、トラフィックの予測が難しい場合や急激なトラフィック変動が発生する場合に適しています。
主な特徴
シンプルな管理
キャパシティーの設定や管理が不要で、必要なときにシステムが自動的にスケーリングします。
急なトラフィック変動に対応
トラフィックの急激な変動に対しても、自動的に必要なキャパシティーを確保し、安定したパフォーマンスを提供します。
利用した分だけ料金が発生
実際に利用した分だけ料金が発生するため、無駄な支払いを最小限に抑えることができます。
プロビジョニング済みキャパシティーモード
事前に読み取り/書き込みキャパシティーユニットを設定することができます。
予測可能なトラフィックパターンの場合に適しています。
主な特徴
コスト管理
事前にキャパシティーを設定することで、予算内でサービスを管理しやすくなります。
パフォーマンスの安定性
予測可能なトラフィックに対して事前に十分なキャパシティーを確保することで、安定したパフォーマンスを提供できます。
リザーブドキャパシティー
プロビジョニング済みキャパシティーモードでは、長期間にわたってキャパシティーをリザーブして割引を受けることも可能です。
セカンダリインデックス
データベーステーブルの主キー以外の列に対する追加のインデックスです。
セカンダリインデックスを使用すると、テーブルのデータに対する追加の検索経路を作成できるので、特定のクエリパターンやアクセスパターンに対して、より高速で効率的なデータ検索が可能になります。
セカンダリインデックスには、2種類があります。
ローカルセカンダリインデックス(LSI)
元のテーブルのパーティションキーは同じで、ソートキーが異なります。
artist(パーティションキー)とsongTitle(ソートキー)の複合主キーを使用して検索していたものをartist(パーティションキー)とreleaseYear(追加のソートキー)を使用して検索できるということです。
| artist(パーティションキー) | songTitle(ソートキー) | category(その他の属性) | releaseYear(追加のソートキー) |
|---|---|---|---|
| No One You Know | My Dog Spot | Text | 2005 |
| The Acme Band | Look Out, World | Text | 2000 |
グローバルセカンダリインデックス(GSI)
元のテーブルのパーティションキーとは異なるキー構造を持ちます。
| artist(元のパーティションキー) | songTitle(元のソートキー) | category(GSIのパーティションキー) | releaseYear(GSIのソートキー) |
|---|---|---|---|
| No One You Know | My Dog Spot | Text | 2005 |
| The Acme Band | Look Out, World | Text | 2000 |
DAXクラスター
終わりに
何かありましたらお気軽にコメント等いただけると助かります。
ここまでお読みいただきありがとうございます🎉
Discussion