【図解】AI時代に必須!統計学の全体像をざっくり把握する

AI が流行ってますね
最近、「ディープラーニング」「ビッグデータ」「AI」という話題をよく耳にします。
なんかいろんなことができて、すごく便利みたいです。
これらの技術は 統計学という学問がベース となっています。統計学は、実はいろいろな場面で使われていて、私たちの知らないところで、人類の生活を豊かにしてくれます。

統計学はディープラーニングの基礎
今回は、統計学の全体像 について解説します。これからの AI 時代を生き抜かなくてはならない今こそ、統計学を学ぶべきです。
Python の基礎を本にまとめています。併せてご覧いただけるととても嬉しいです ↓ DeepLearning の基礎を本にまとめています。手に取って頂けるととても喜びます ↓
皆さんの理解が一歩でも進むと嬉しいです。
Created by NekoAllergy
統計学って何?

統計学とは たくさんのデータについての考え方
統計学とは、たくさんのデータについての考え方 をまとめた学問です。
詳しくは、下記の記事で図解しています。まずは下記の記事をご覧いただくと、理解がより深まります。
とても可能性に溢れている学問だと思います。
Created by NekoAllergy
統計学オーバービュー
統計学の全体像をみてみます。
この内容は、皆さんが統計学について学習する際の大枠となればいいと考えています。用語の意味や使い方を調べる時にも、全体像が頭に入っていた方がやりやすいです。全てを理解しようとせず、ざっくり全体を把握していただければと思います。
用語の解説は最小限にしています。分かりやすさ重視なので厳密な定義とは異なる場合があります。ご了承ください。
統計学の大分類

統計学の大分類
統計学は 2 つに分類することができます。
| 分類 | 説明 | |
|---|---|---|
| 1 | 記述統計 | 分かりにくいデータを、分かりやすく変換して、特徴を理解するための手法 |
| 2 | 推測統計 | サンプルから全体データを予測する手法、今のデータから未来を予測する手法 |
※研究者によって分類の考え方は異なります
1. 記述統計(きじゅつとうけい)まとめ
記述統計には、ざっくり以下のような項目があります。
- 代表値(平均値・中央値・最頻値)
- 散布度(四分位数、四分位範囲(四分位偏差)、標準偏差、分散)
- 度数分布表とヒストグラム
- 標準化(Z-score、T-score)
- 相関(共分散、正の相関/負の相関/無相関、相関図、相関係数)
2. 推測統計(すいそくとうけい)まとめ
推測統計には、ざっくり以下のような項目があります。
- 確率(独立な試行、条件付き確率)
- 標本調査(母集団、標本、全数調査、無作為抽出、標本の大きさ、乱数)
- 母平均、母分散、標本平均、標本分散/不偏分散
- 推定(点推定、区間推定)
- 検定(Z 検定、F 検定、t 検定、カイ二乗検定)(帰無仮説、対立仮説)
1 つずつ解説します。
代表値
だいひょうち

代表値 3 つ
代表値(だいひょうち)とは、たくさんのデータについてを、ざっくり 1 つの数値を使って表すことです。全体的な性質を 1 つの数値で判断できます。
有名な代表値は 3 つあります。特によく使うのが平均ですね。
| 有名な代表値 | 説明 | |
|---|---|---|
| 1 | 平均値 | 全部足して割る |
| 2 | 中央値 | 小さい順に並べた真ん中 |
| 3 | 最頻値 | 一番多く出てきた数 |

場合に応じて適切な代表値を選ぶ
【補足】実は平均にも 3 種類ある
平均の計算方法は 3 種類あります。詳しくは調べてみてください。
- 算術平均(さんじゅつへいきん)
- 幾何平均(きかへいきん)
- 調和平均(ちょうわへいきん)
また、別枠で加重平均(かじゅうへいきん)ってのもあります。
散布度
さんぷど

散布度は 5 つ
散布度(さんぷど)とは、 データがどれくらいバラついているか を表した指標です。
平均などの代表値だけではデータ全体の性質をうまく説明できません。代表値に加えて、散らばり具合が分かれば、全体をもっとイメージしやすいです。
| 有名な散布度 | 説明 | ||
|---|---|---|---|
| 1 | 範囲 | 最大値から最小値を引く | シンプルで分かり易いが、外れ値に弱い |
| 2 | 四分位範囲&四分位偏差 | 小さい順に並べて4等分する位置にある値 | 外れ値の影響を受けないが、全てのデータが使われていない |
| 3 | 平均偏差 | 平均からの差(絶対値)の合計 | 全てのデータを使っているが、絶対値の計算は時間がかかってしまう |
| 4 | 分散 | 偏差の 2 乗を全て足す | 絶対値は使わないが、2 乗されているので分かりにくい |
| 5 | 標準偏差 | 分散の平方根 | 結構いい |
【補足】偏差(へんさ)って?
偏差とは、平均からどれくらい離れているか という数です。
たとえば、[1, 2, 3, 4, 5]というデータの平均は 3 です。
各値から平均の 3 を引くと、偏差と呼ばれます。
データ = [1, 2, 3, 4, 5]
平均 = 3
偏差 = [1-3, 2-3, 3-3, 4-3, 5-3] = [-2, -1, 0, 1, 2]
偏差は、すべて足すと必ず 0 になるという性質があります。
度数分布表とヒストグラム
どすうぶんぷひょう ひすとぐらむ

度数分布表とヒストグラム
度数分布表(どすうぶんぷひょう)とヒストグラムを使うことで、データをより分かりやすい形にすることができます。
どの区間にデータが集まっているのかが視覚的に分かりやすくすることができます。バラツキも見ることができます。
| 説明 | ||
|---|---|---|
| 1 | 度数分布表 | データをある幅ごとに区切って、その区間にデータが何個ずつあるかをまとめた表 |
| 2 | ヒストグラム | 度数分布表を棒グラフで表現したグラフ |
【補足】度数(どすう)とは?
その範囲にあるデータの数です。
たとえば、あなたが作った商品が、何歳の人に特にウケているのかを調べることができます。
標準化
ひょうじゅんか

標準化
標準化(ひょうじゅんか)とは、データをきれいに整えることです。データを整えることで、比較がしやすくなります。学校のテストでよく聞いた「偏差値」は、この標準化の考え方が使われています。
| 標準化の種類 | 説明 | |
|---|---|---|
| 1 | Z-score | 平均 0, 標準偏差 1 に整える |
| 2 | T-score | 平均 50, 標準偏差 10 に整える(いわゆる偏差値ってやつ) |
相関関係
そうかんかんけい

相関関係
相関関係(そうかんかんけい)は、2 つの関係を見つける手法です。身長が高い人は体重が重いはず、理科の点数が高い人は数学も得意なはず、といったような関係を数値を使ってしっかりと表すことができます。
| 相関の用語 | 説明 | |
|---|---|---|
| 1 | 相関係数(そうかんけいすう) | 関係の強さを表した数値。-1.0〜+1.0 の値で表す。 |
| 2 | 強い相関 | 相関係数が ±0.7 以上 |
| 3 | 弱い相関 | 相関係数が ±0.4 以下 |
| 4 | 無相関 | 相関係数が 0 付近 |
たとえば?
あるスーパーでは、お客が買った品物の相関関係を調べたそうです。結果を見ると、オムツを買った人はビールも一緒に買う傾向があったため、あえて並べて陳列したら売り上げが上昇したという結果もあるそうです。
まったく関係がないように思われる事柄でも、統計学を使うことで、その相関を数値で導き出すことができます。
相関の注意点
相関係数が高くても関係がなかったり、相関係数が 0 でも何らかの関係がある場合があります。
散布図を書いて、データの規則性やばらつき具合を確認してみることが大切です。
ここから先は推測統計
確率
かくりつ

確率
確率(かくりつ)とは、ある事柄がどれくらい起こるのかを表した数値です。宝くじなどで馴染みがあると思います。
専門用語が多い&考えなきゃいけないことが多い という点で苦手意識がある方もいるかもしれません。確率は統計学には必須でベースとなる考え方なので、基本は理解しておきましょう。
| 確率の用語 | 説明 | (例)サイコロを 1 回振ると? | |
|---|---|---|---|
| 1 | 事象 | 起こりうる事柄 | 偶数の出た目 (2,4,6) |
| 2 | 全事象 | 起こりうる全ての結果の集合 | 全ての出る目 (1,2,3,4,5,6) |
| 3 | 空事象 | 起こりえない事柄 | 7 以上の出た目 (7 とか 8 とか) |
| 4 | 標本点 | 起こりうる個々の結果 | 出た目のどれか 1 つ (3 とか) |
| 5 | 標本空間 | 起こりうる全ての結果の集合 (全事象と同じ) |
全ての出る目 (1,2,3,4,5,6) |
| 確率の用語 | 説明 | (例)サイコロを 1 回振ると? | |
|---|---|---|---|
| 1 | 和事象 | 事象 A と事象 B のどちらかが起こる事象 | 奇数もしくは 3 以下 |
| 2 | 積事象 | 事象 A と事象 B が同時に起こる事象 | 奇数かつ 3 以下 |
| 確率の用語 | 説明 (例) | ポイント | |
|---|---|---|---|
| 1 | 順列 | 異なる 5 個から 3 個選んで一列に並べるとき、全部で何通り? | 順番が大事 |
| 2 | 組み合わせ | 異なる 5 個から 3 個選ぶ組み合わせは全部で何通り? | 順番は関係ない |
標本調査
ひょうほんちょうさ ぼしゅうだん ひょうほん

標本調査
日本人全体の特徴を調べるためには、日本人全員にアンケートを取るしかありません。しかし、時間と労力がめっちゃかかるので、やりたくないです。
統計の考え方を使うと、数人の結果から日本人全体の特徴を推測することができます。
テレビの視聴率や内閣支持率などでこの考え方が使われています。
| 標本調査 | 説明 | |
|---|---|---|
| 1 | 母集団(ぼしゅうだん) | 全部のデータ。調べたい全てのデータ。 (日本の総人口など) |
| 2 | 標本(ひょうほん、サンプル) | 全部のデータからランダムに選んだサンプル。 (日本人 10,000 人など) |
| 標本調査 | 説明 | |
|---|---|---|
| 1 | 母平均(ぼへいきん) | 母集団の平均 |
| 2 | 母分散(ぼぶんさん) | 母集団の分散 |
| 3 | 標本平均(ひょうほんへいきん) | 標本の平均 |
| 4 | 標本分散 (ひょうほんぶんさん) | 標本の分散 |
| 5 | 不偏分散 (ふへんぶんさん) | 標本から考えた 母集団の分散の推測値 |
推定
すいてい

推定
推定(すいてい)とは、一部の標本(サンプル)から全体を推測する手法です。標本の平均から母集団の平均を求めたり、標本の分散から母集団の分散を求めたりすることができます。
| 推定の種類 | 説明 | |
|---|---|---|
| 1 | 点推定 | 標本データから、未知の母集団のデータを考える |
| 2 | 区間推定 | 標本データから、未知の母集団のデータがどこの範囲に収まるかを考える |
テレビの視聴率でこの考え方が使われています。
見えていないデータを 100%正確に予測することはできません。そこで、区間推定では、信頼度(しんらいど)という考え方を使います。
たとえば、視聴率では?
たとえば、テレビの視聴率では、「サンプルを調べた感じ、視聴率はだいたい 13%〜15%くらいだったよ。この結果は 95%くらい信用していいよ(信頼度 95%)」という感じで使います。
【補足】サンプル数が増えると...?
サンプルの数を増やすと、信頼度を高くすることができます。(実際には、信頼区間をせまくすると表現します。)
ただ、サンプル数を 100 倍に増やしても、誤差は 1/10 にしかならないので、あまり意味ないです。
調査の手間と結果のバランスを考える必要があります。
検定
けんてい
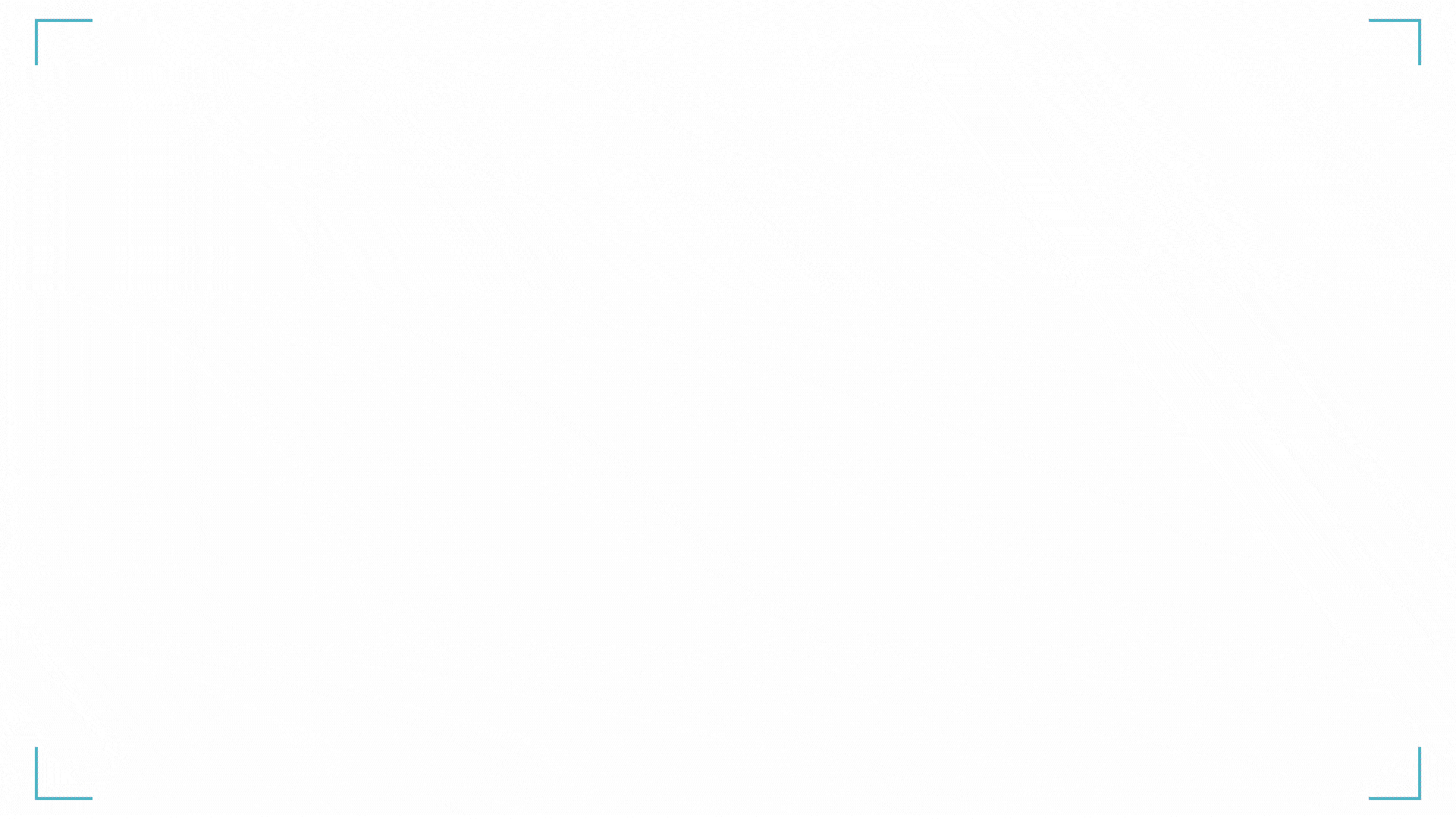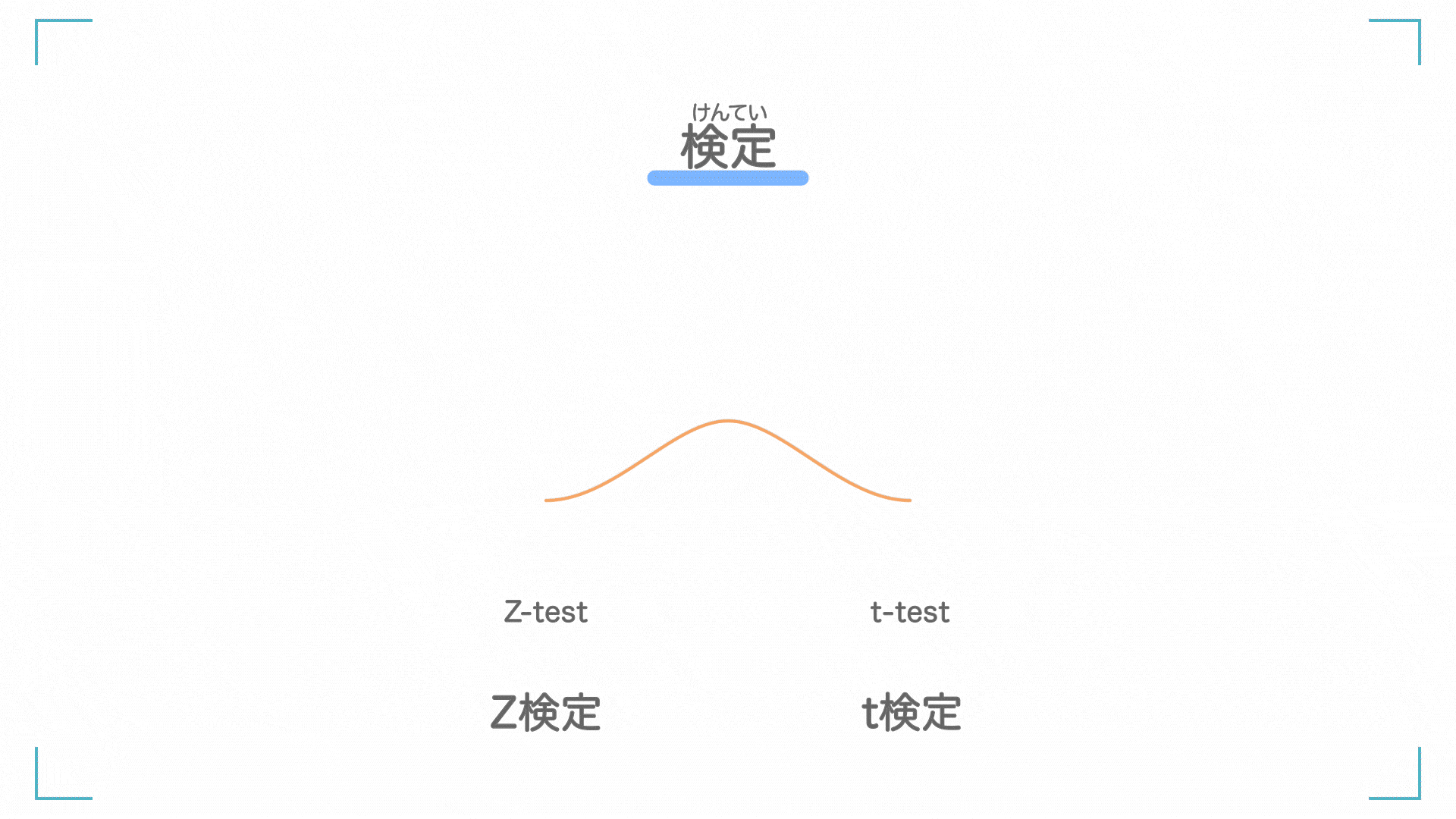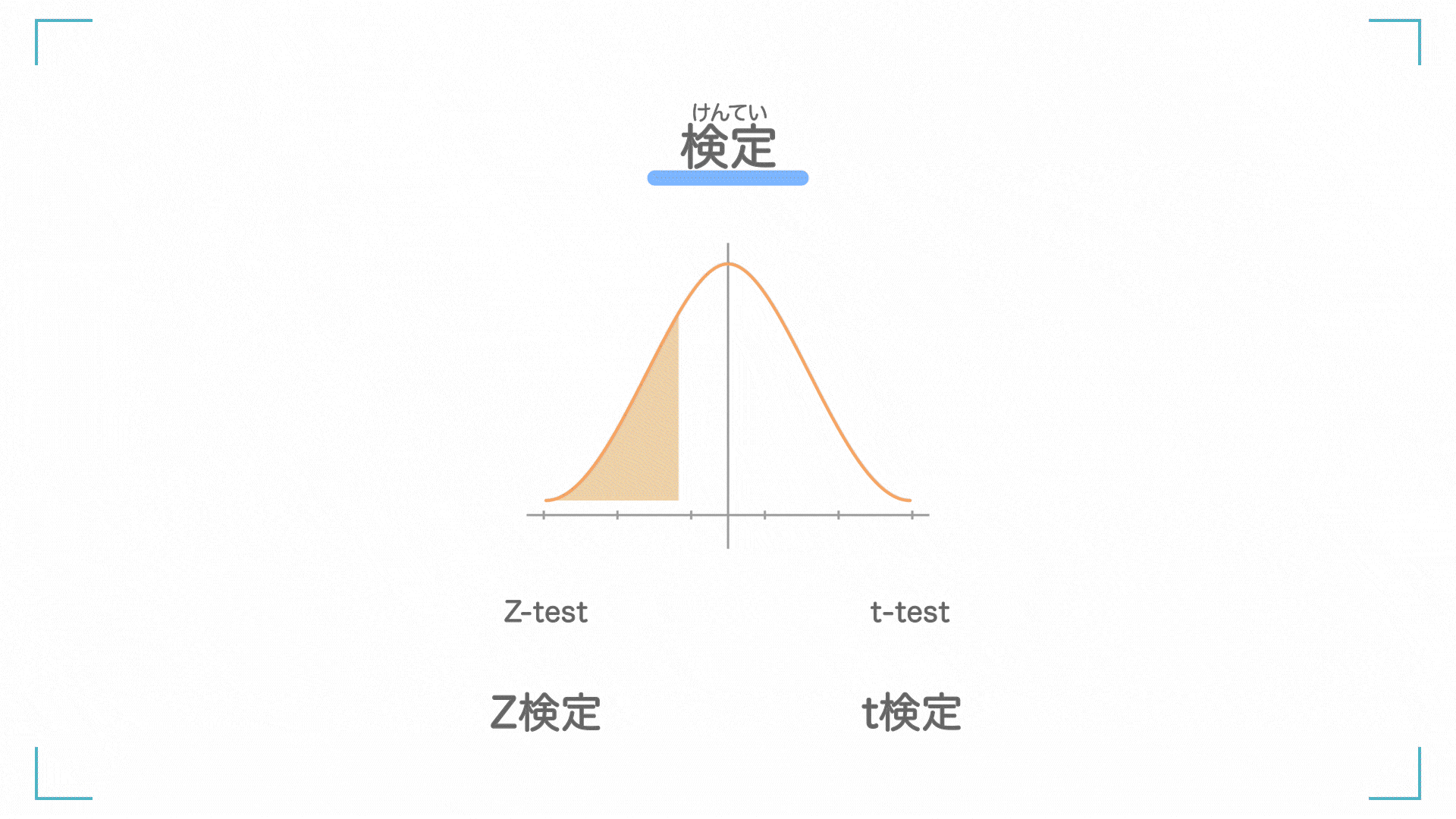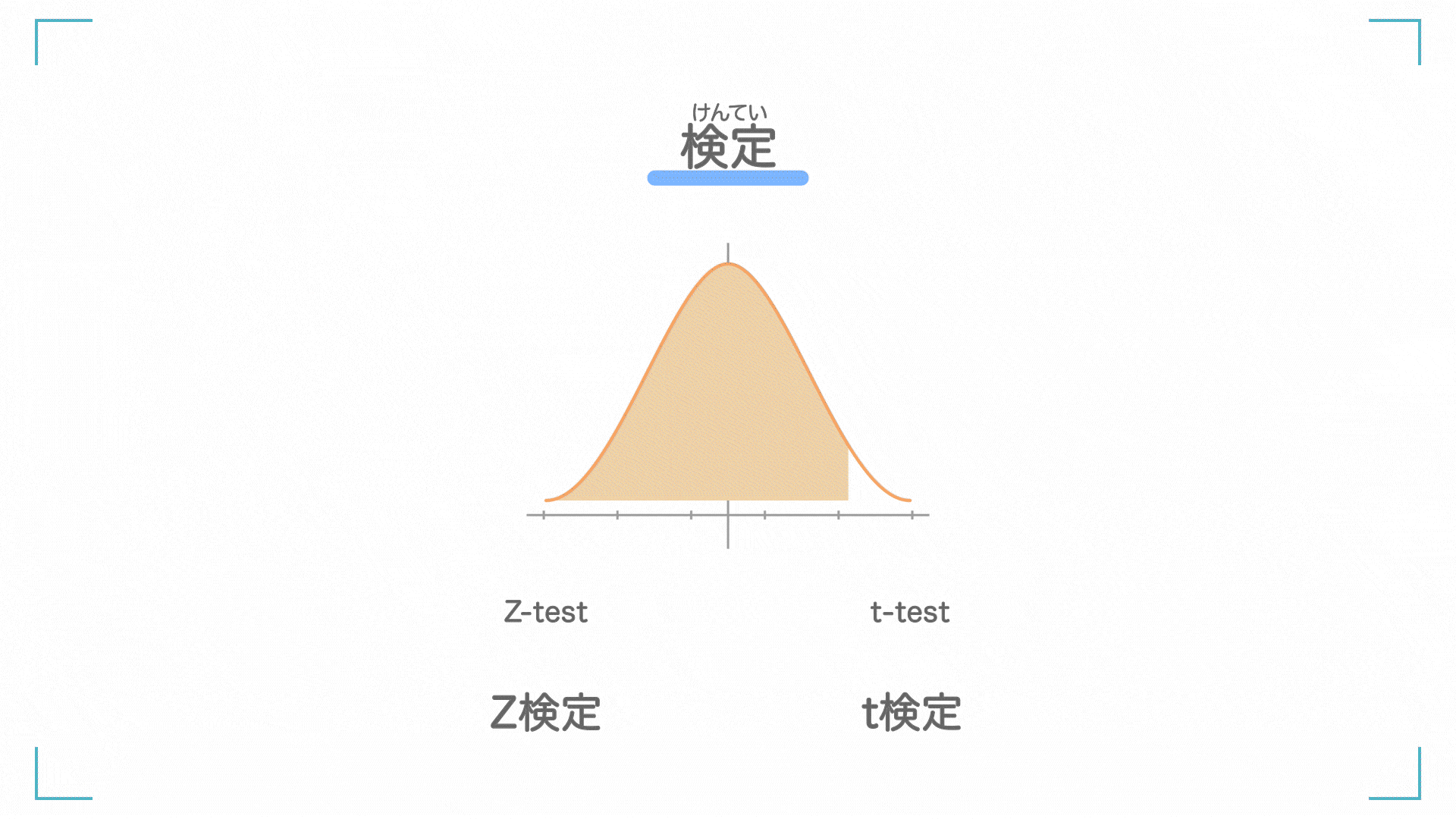
検定
検定(けんてい)とは、「それってこうなんじゃない?」という仮説を立てて、それが本当に正しいかを判定する手法です。
たとえば、「東京で 2 週間連続で雪が降った」という事実があったとします。これが、「そんなこと普通に起きることだよ」となるのか「いや、これは滅多に起きない。だから偶然起こったものだ」となるのかを数値で出すことができます。
偶然かそうでないかを、主観で物事を判断せず、客観的な数値によって判断することができて、とても便利です。
検定にはいくつか種類があります。詳しくは調べてみてください。
| 推定の種類 | 説明 | |
|---|---|---|
| 1 | Z 検定 | 母分散が分かっているときに使う |
| 2 | t 検定 | 母分散が分かっていないときに使う |
| 3 | F 検定 | データの分散が等しいかを確認する |
まとめ
今回は統計学の概要を紹介しました。
統計学は、ディープラーニングのベースの考え方になっていて、これからの AI 時代を生き抜くために必須の知識だと思います。
統計学が分かると、機械学習の内容がスムーズに入ってきます。
皆さんの理解が一歩でも進んだのなら嬉しいです。
フォロー ♻️、いいね 👍、サポート 🐱 お願いします。とっても嬉しいです。
機械学習をもっと詳しく
Python の基礎を本にまとめています。併せてご覧いただけるととても嬉しいです ↓ DeepLearning の基礎を本にまとめています。手に取って頂けるととても喜びます ↓

ねこアレルギーの AI
YouTube で機械学習について発信しています。お時間ある方は覗いていただけると喜びます。
Created by NekoAllergy
Discussion