【図解】8行で機械学習【Python】
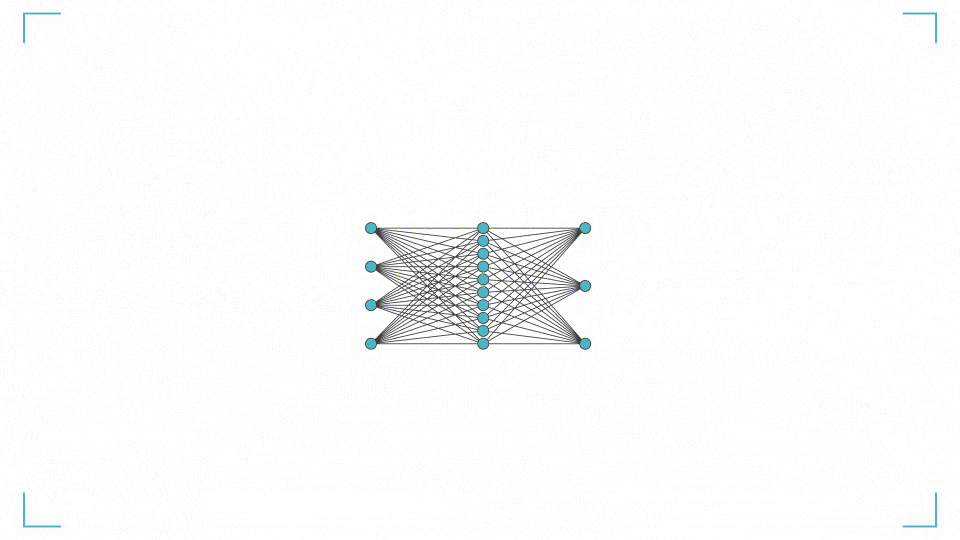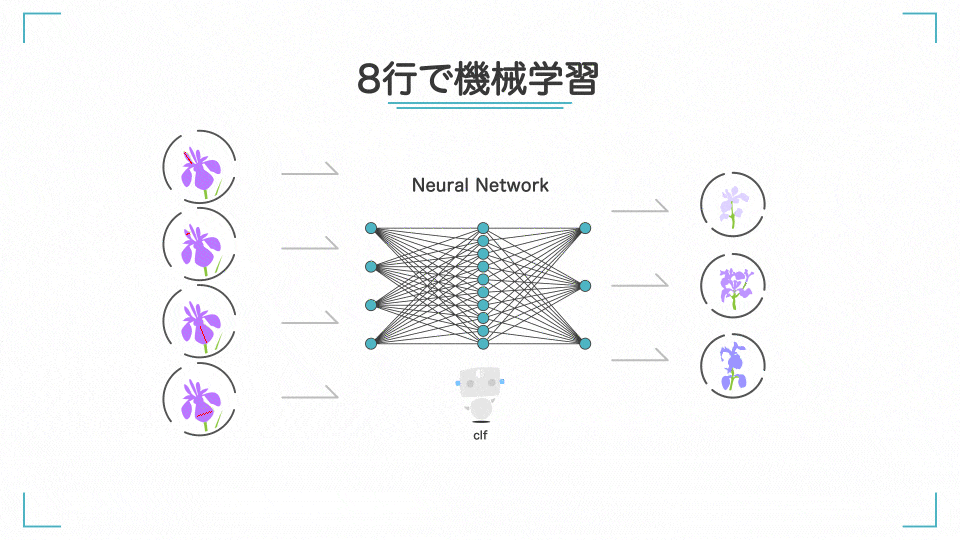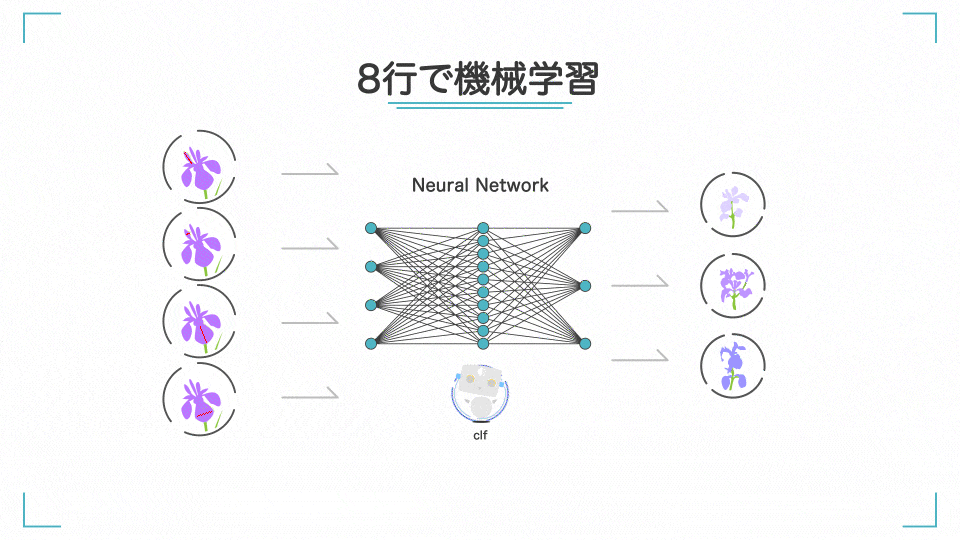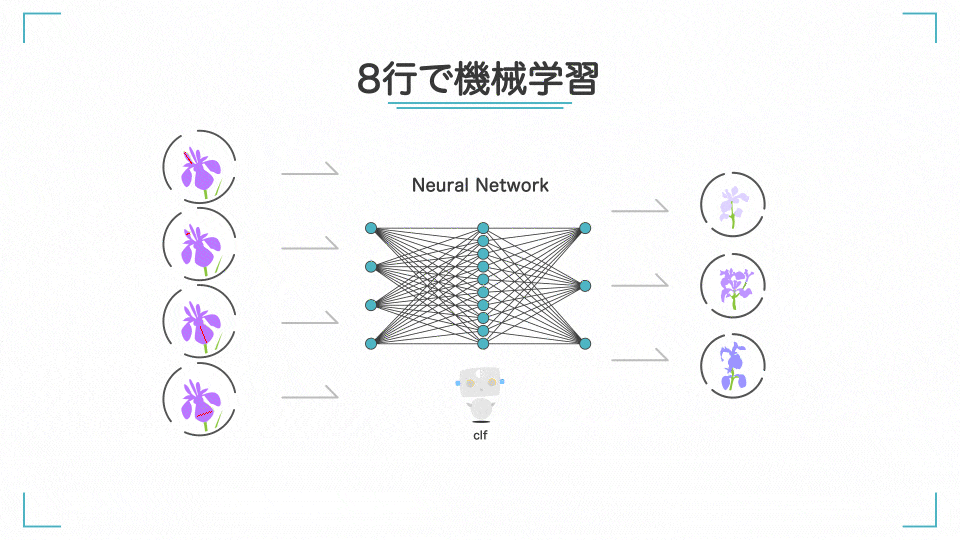
分類 AI は 8 行で作れます。
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neural_network import MLPClassifier
iris = datasets.load_iris()
data_train, data_test, target_train, target_test = train_test_split(iris.data, iris.target)
clf = MLPClassifier()
clf.fit(data_train, target_train)
print(clf.score(data_test, target_test))
0.9736842105263158
作れました。
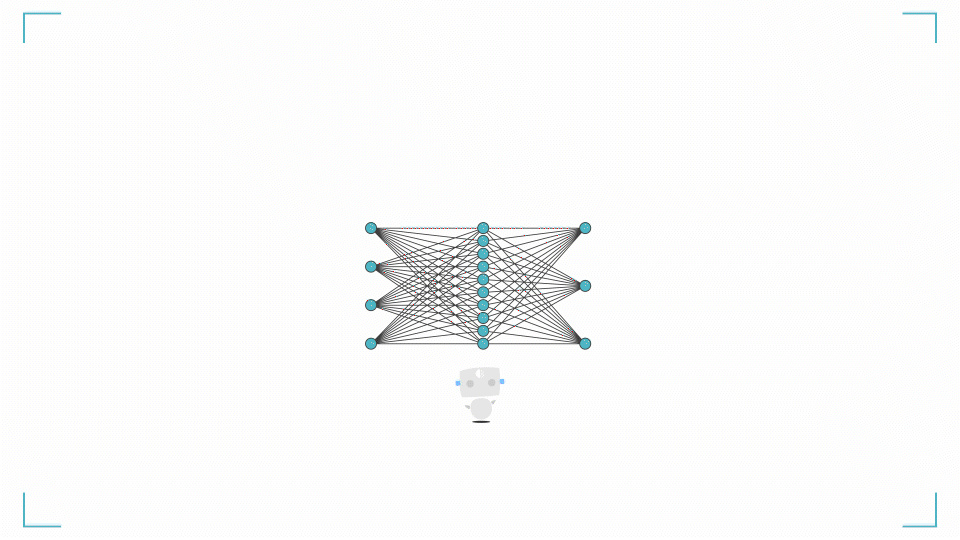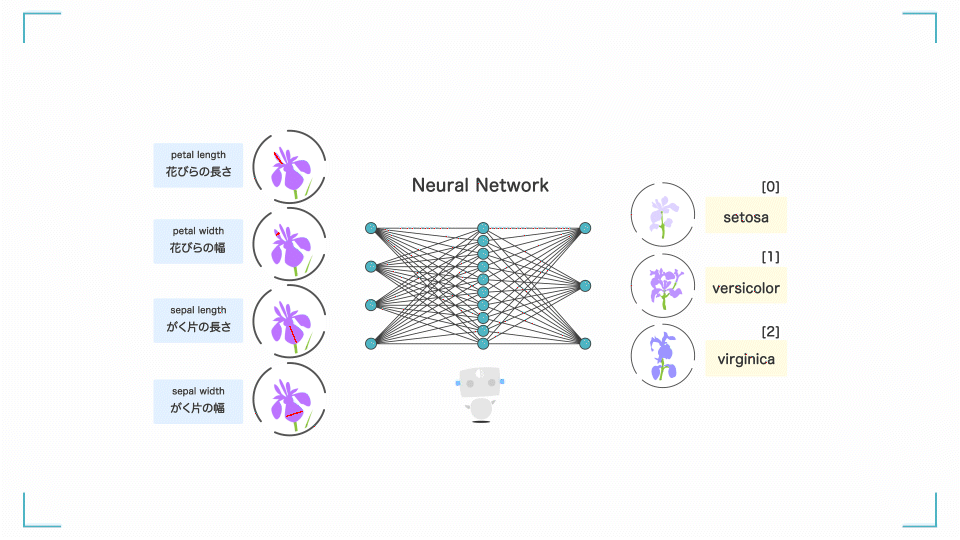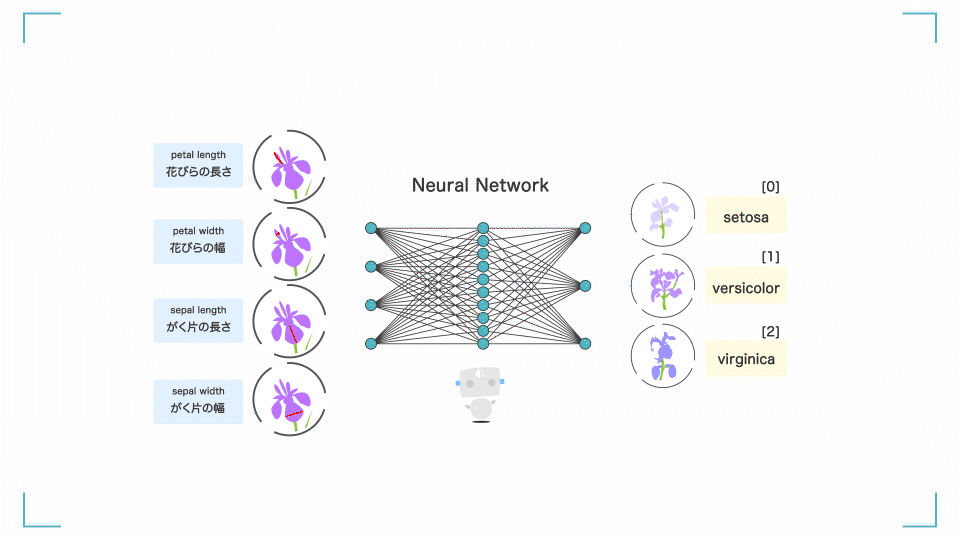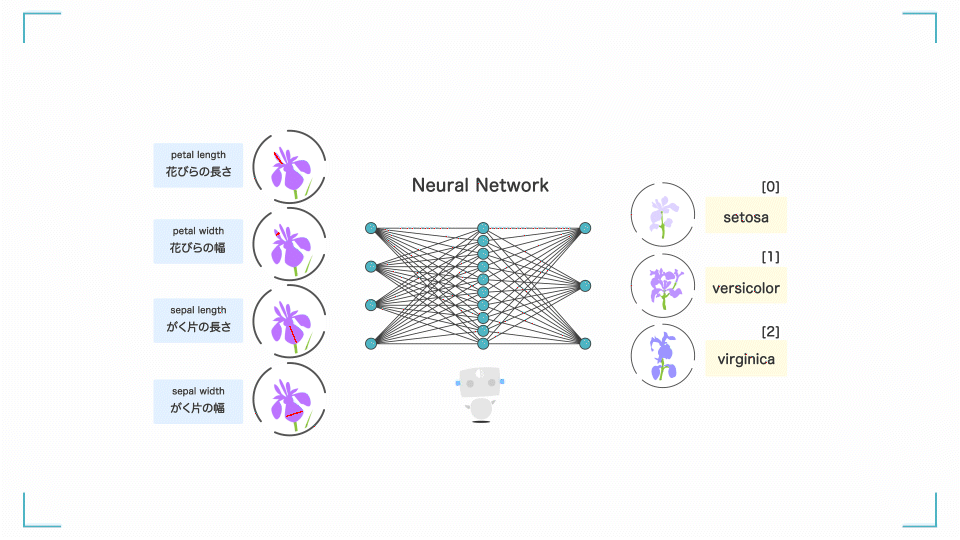
この AI は、アヤメというお花を分類する AI です。花びらの長さなどの 4 つの情報 を AI に渡すと、3 種類のどれに当てはまるかを当ててくれます。97.4%の精度で勝手に分類してくれています。すごい。
今回は初学者向けに、このプログラム内で何が起こっているのかを解説します。
この AI には、実はいろんなパラメータが設定できます。パラメータを変えると、結果も変わってきます。カスタマイズして、自分だけの AI を作りましょう。とっても楽しいです。
Python の基礎を本にまとめています。併せてご覧いただけるととても嬉しいです ↓ DeepLearning の基礎を本にまとめています。手に取って頂けるととても喜びます ↓
みなさんの理解が一歩でも進めば嬉しいです。
Created by NekoAllergy
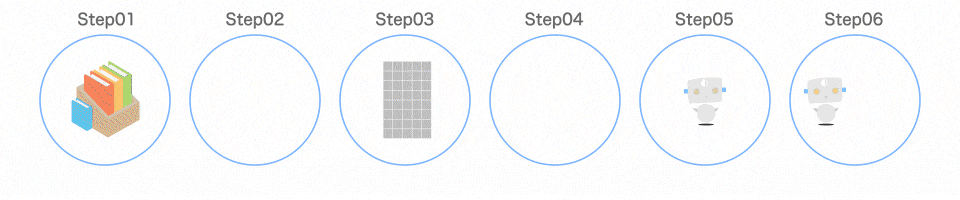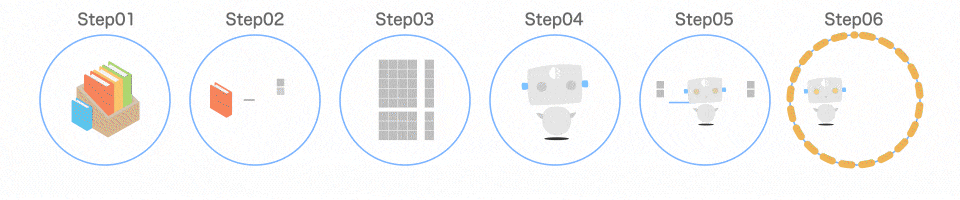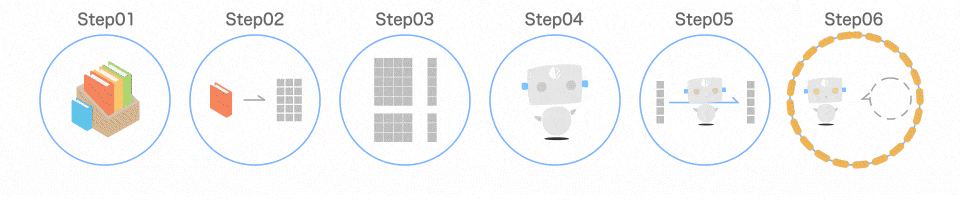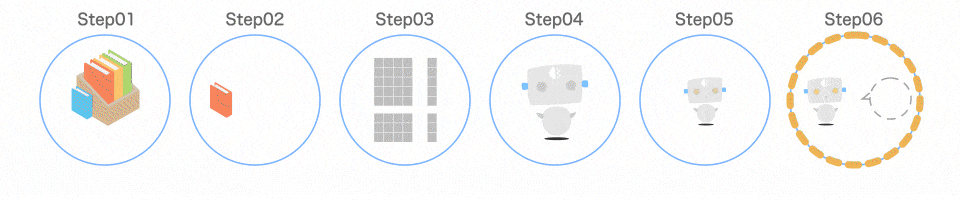
プログラムの全体像
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neural_network import MLPClassifier
iris = datasets.load_iris()
data_train, data_test, target_train, target_test = train_test_split(iris.data, iris.target)
clf = MLPClassifier()
clf.fit(data_train, target_train)
print(clf.score(data_test, target_test))
0.9736842105263158
結果をみると、97.4%の精度が出ていることが分かります。
このプログラムは必要最低限のコードだけで書いています。それにしても、たった数行で AI が作れてしまうのはすごいです。
1 つずつ解説します
Step01 ライブラリを読み込む

プログラムの手順
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neural_network import MLPClassifier
3 つのライブラリを読み込んでいます。
Step02 学習データを読み込む
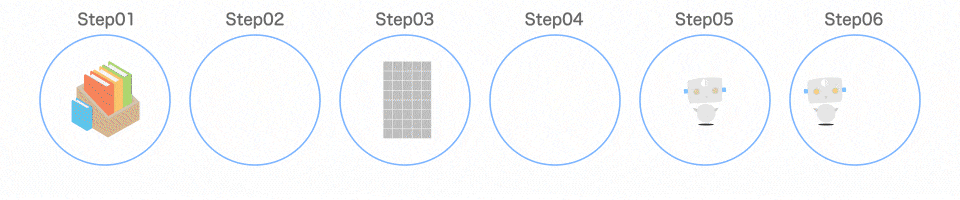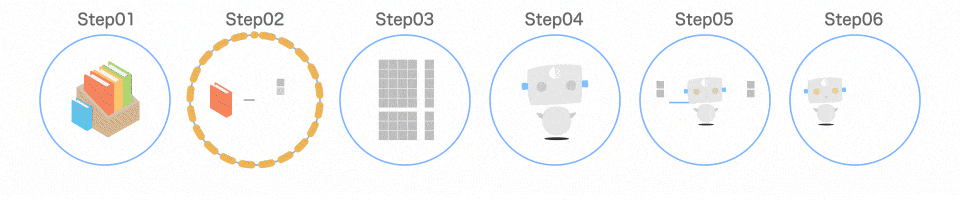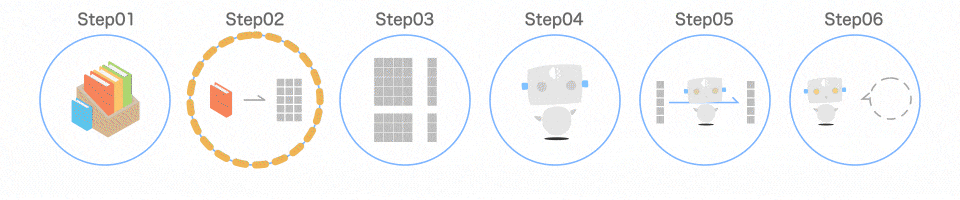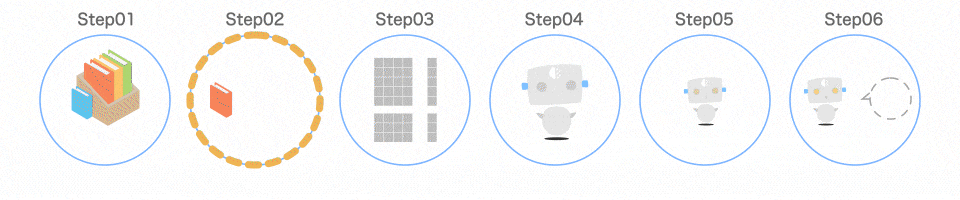
プログラムの手順
iris = datasets.load_iris()
まずは、データを用意します。
datasetsの中の load_〇〇関数を使うことで、用意されているサンプルデータセットを取り出すことができます。
今回は、datasets.load_iris()を使うことで、Iris(アイリス)というデータセットを取り出します。全てのデータはirisという変数に格納されます。
[補足]サンプルデータは他に何が使える?
下記の 7 つのサンプルを自由に使うことができます。
| データセット名 | データ数 | 特徴の数 | 回帰/分類 | |
|---|---|---|---|---|
| 01 | boston | 506 | 13 | 回帰 |
| 02 | iris | 150 | 4 | 分類(3) |
| 03 | diabetes | 442 | 10 | 回帰 |
| 04 | digits | 1797 | 64 | 分類(10) |
| 05 | linnerud | 20 | 3 | 回帰 |
| 06 | wine | 178 | 13 | 分類(3) |
| 07 | breast_cancer | 569 | 30 | 分類(2) |
[例]
boston = datasets.load_bostonのように書くことで、使えるようになります。
sklearn.datasets では、他にもいろんなサンプルデータを使うことができます。
詳しくは、こちらをご覧ください
Step03 データを分ける
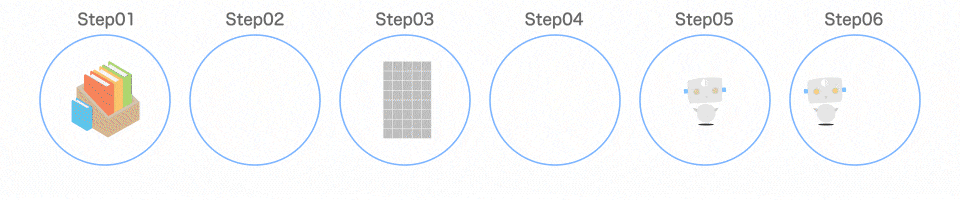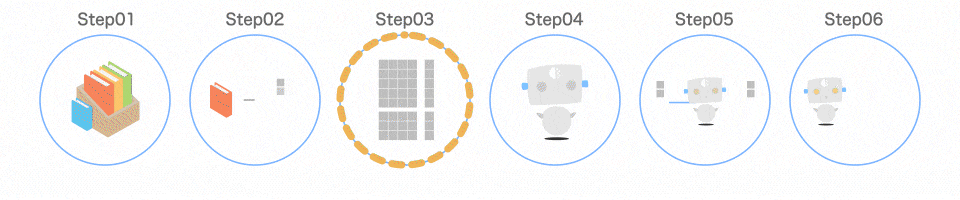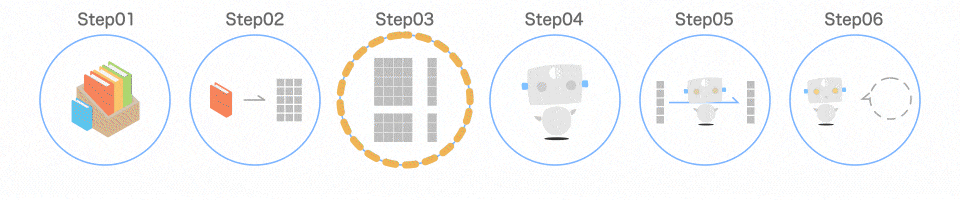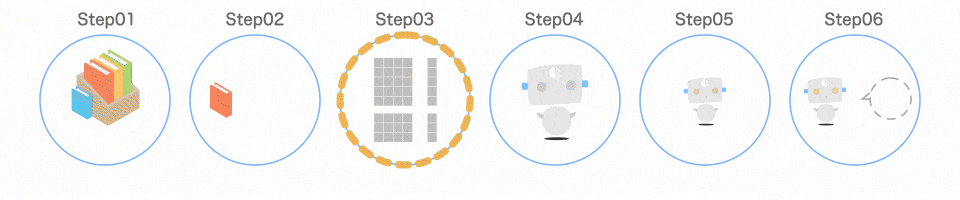
プログラムの手順
data_train, data_test, target_train, target_test = train_test_split(iris.data, iris.target)
取り出したデータを、扱いやすいように分けます。
以下のようなイメージです。

train_test_split()のイメージ
train_test_split()を使うと、この分ける作業を 1 行で済ませることができます。引数として渡すのは、iris.dataとiris.targetです。
| 渡すデータ | ||
|---|---|---|
| 1 | iris.data |
モデルの学習に使う「データ」です。 |
| 2 | iris.target |
データの「正解ラベル」です。答えが入っています。 |
このデータを、機械学習では下記のように 4 つに分けます。
| 作られるデータ | ||
|---|---|---|
| 1 | data_train |
モデルの訓練に使う「訓練データ」です。 |
| 2 | data_test |
モデルの評価に使う「テストデータ」です。 |
| 3 | target_train |
訓練データの「正解ラベル」です。答えが入っています。 |
| 4 | target_test |
テストデータの「正解ラベル」です。答えが入っています。 |
※訓練データは 学習データとも呼ばれます。
これでデータが用意できました。
Step04 モデルを作る
プログラムの手順
clf = MLPClassifier()
いよいよ機械学習モデルを作っていきます。
[補足] モデルってなに?

モデルとは
機械学習ではまず、どんな モデル を作るか、を考えます。
モデルとは、入力値をもとに、中でいろいろな計算をして、出力値を導いてくれる 箱 のことです。このモデルが、最終的に AI と呼ばれるものになります。
[補足] たとえば?
たとえば、ネコの画像を入力すると、「これはネコです」と出力してくれる箱も立派なモデルです。
また、【AI の枠組み】や【AI がどんな形をしているか】や【AI の中でどんな計算をするか】を指してモデルと呼ぶこもあります。
[補足] モデルはどうやって作るの?
モデルを作るときは、【学習 STEP】⇒【評価 STEP】の流れで進めていきます。

モデルを作るときの順序
今回はアヤメの花を分類する分類AIが作りたいです。そこで、MLPClassifier()という、ニューラルネットワークの分類モデルを使います。
[補足] MLPClassifier って何?
MLPClassifier は以下のような意味です
- MLP =多層パーセプトロン(MultiLayer Perceptron)
- Classifier =分類器
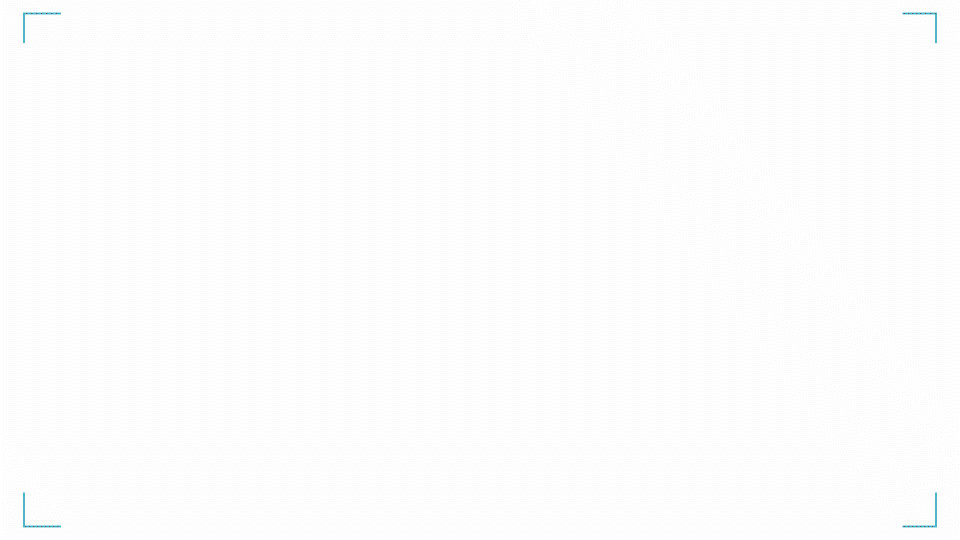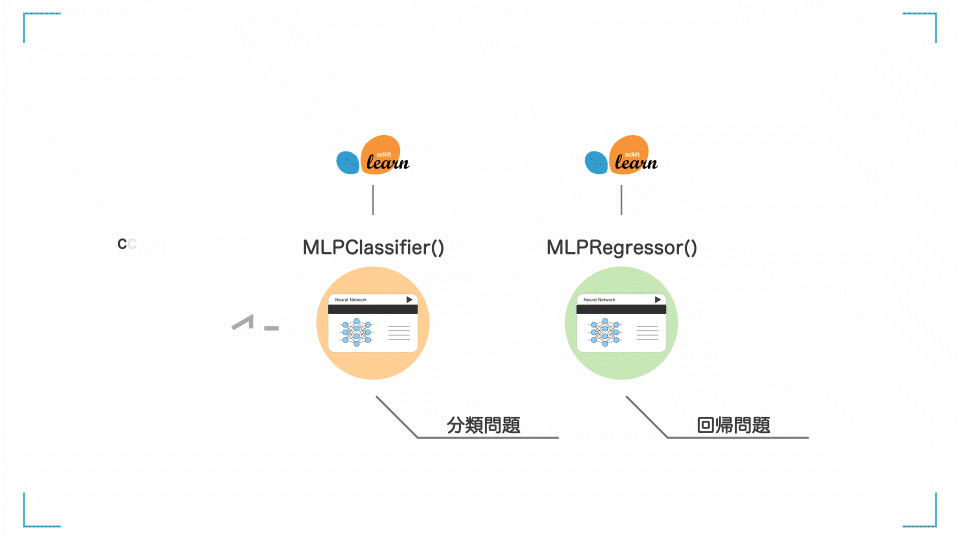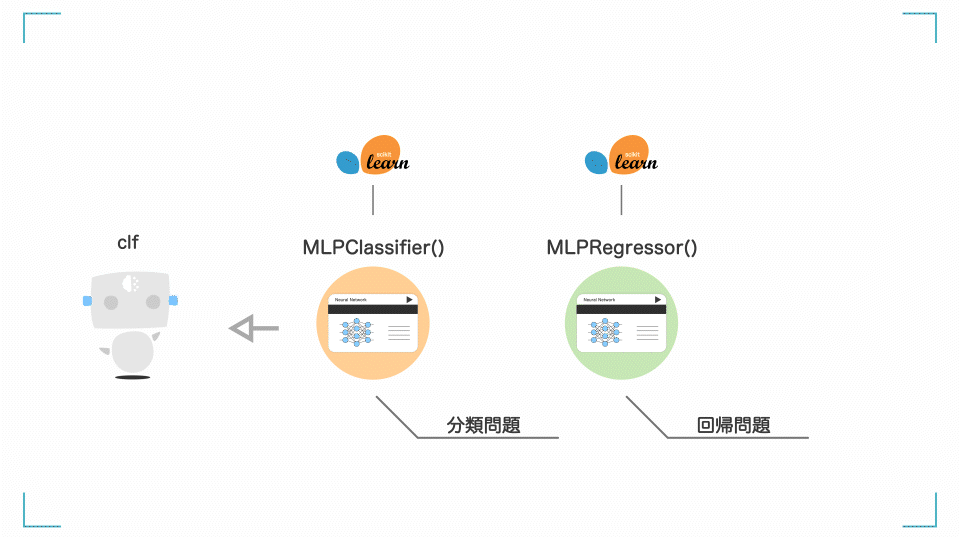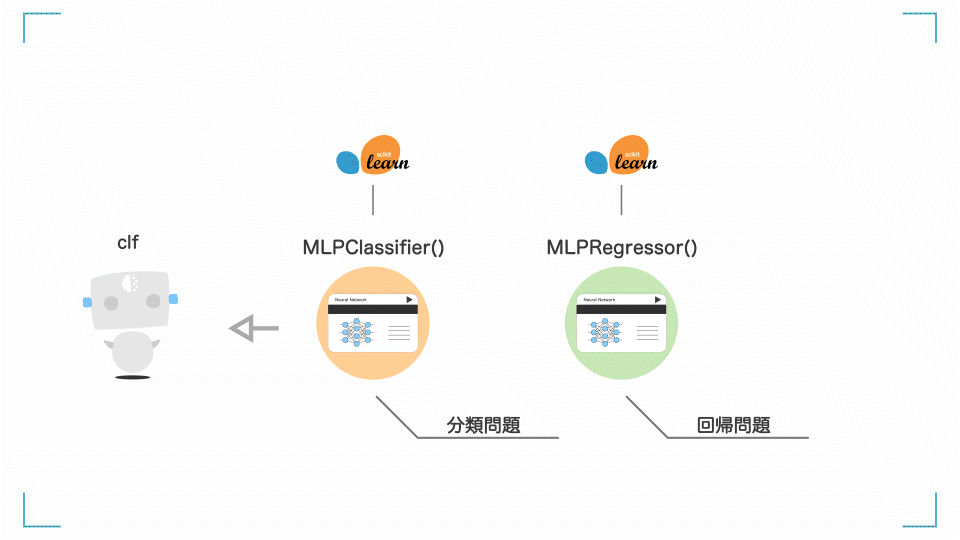
今回は分類問題なので、MLPClassifier を使う。回帰問題の場合は MLPRegressor を使う。
[補足] ニューラルネットワークって何?
ニューラルネットワークを簡単に説明します。入力層に学習データ(ここではアヤメの情報)を入力すると、入力層 → 中間層 → 出力層を通りながら勝手にいろいろ計算をします。
何回も計算(学習)することで正解ラベル(ここではアヤメの品種 0,1,2)との誤差を小さくしていき、最終的に良い感じの予測結果が出力層に出てくるというアルゴリズムです。
ニューラルネットワークとは?
ニューラルネットワークをもっと詳しく知りたい方は、初心者向けの記事と動画を上げていますので、よければご覧ください。
📄文字で見たい方はこちら
🎥動画で見たい方はこちら

clfという名前でニューラルネットワークのモデルの枠組みを作成
clf = MLPClassifier()
clf = MLPClassifier()とすることで、clfという名前でニューラルネットワークのモデルの枠組みを作成します。このclfが AI(機械学習モデル)そのものになります。
[補足] clf って何?
clf は Classifier(分類器)の略です。
名前はclfじゃなくても良いですが、一般的に分類モデルはclfと名付けます。
[補足] インスタンス化
AI エンジニアが使う難しい言葉で言うと、clf = MLPClassifier()の 1 行で インスタンス化 をしています。分からなくても大丈夫です。
分類モデルclfを作ることができました。
しかし、これだけではclfはまだ何もできません。AI とは言えない、ただの箱です。
次の Step で モデルの学習 を行います。
Step05 モデルを学習させる
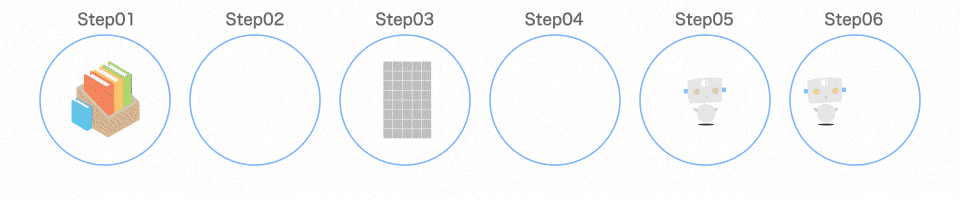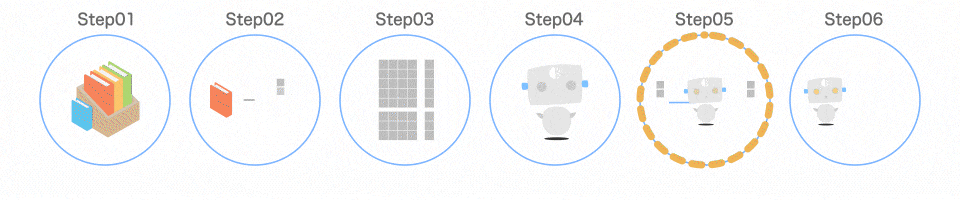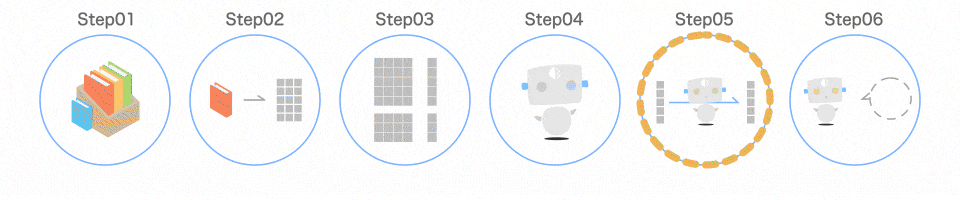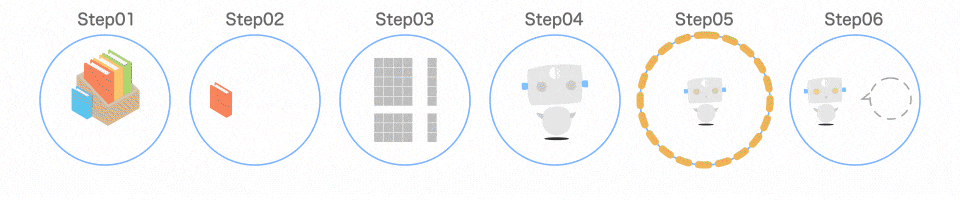
プログラムの手順
clf.fit(data_train, target_train)
7 行目でモデルを学習させています。
学習には、fit()というメソッドを使います。

学習の様子
fit()に渡すデータは、先ほど作った data_trainとtarget_trainです。
fit()に渡すデータ |
||
|---|---|---|
| 1 | data_train |
モデルの訓練に使う「訓練データ」です。 |
| 2 | target_train |
訓練データの「正解ラベル」です。答えが入っています。 |
clf.fit(data_train, target_train)の 1 行で学習が完了します。モデルが導き出した結果と、本当の答えであるtarget_trainを比較することで、どんどん賢くなっていきます。
ただの箱だったclfが、AI に進化しました。
次の Step で モデルの精度を確認してみましょう。
Step06 モデルの精度を確認する
プログラムの手順
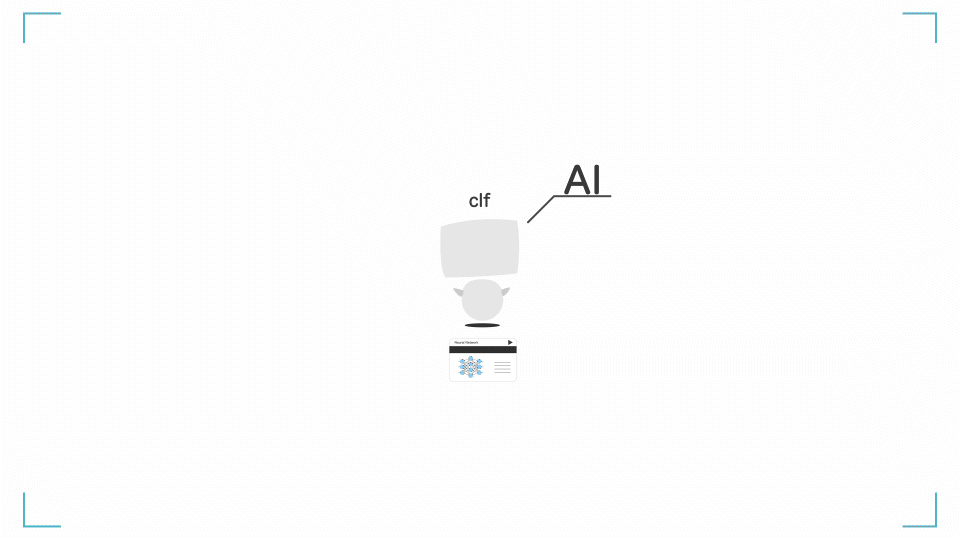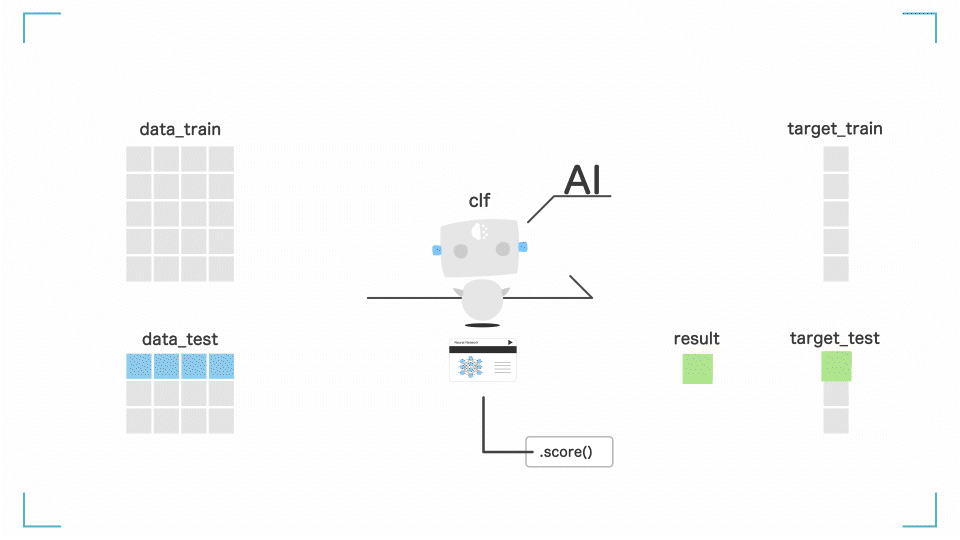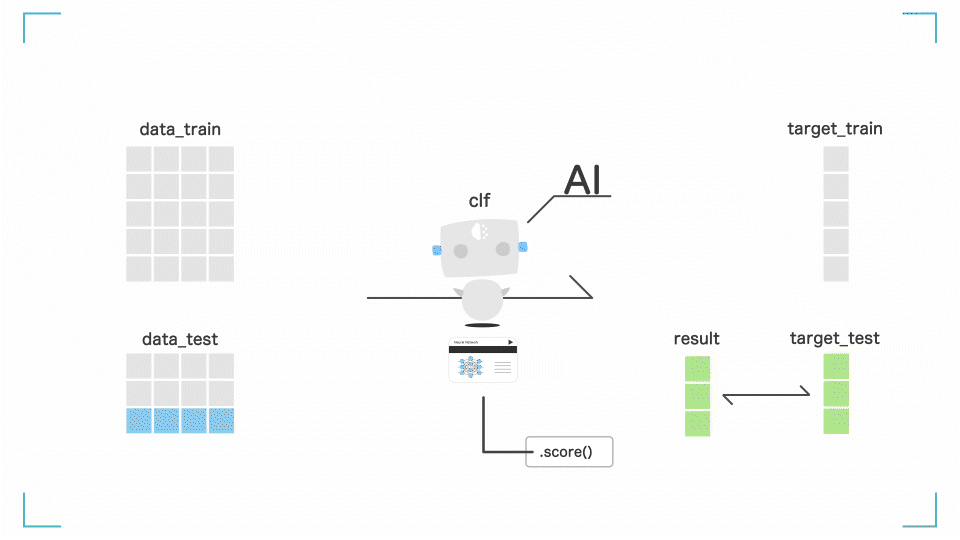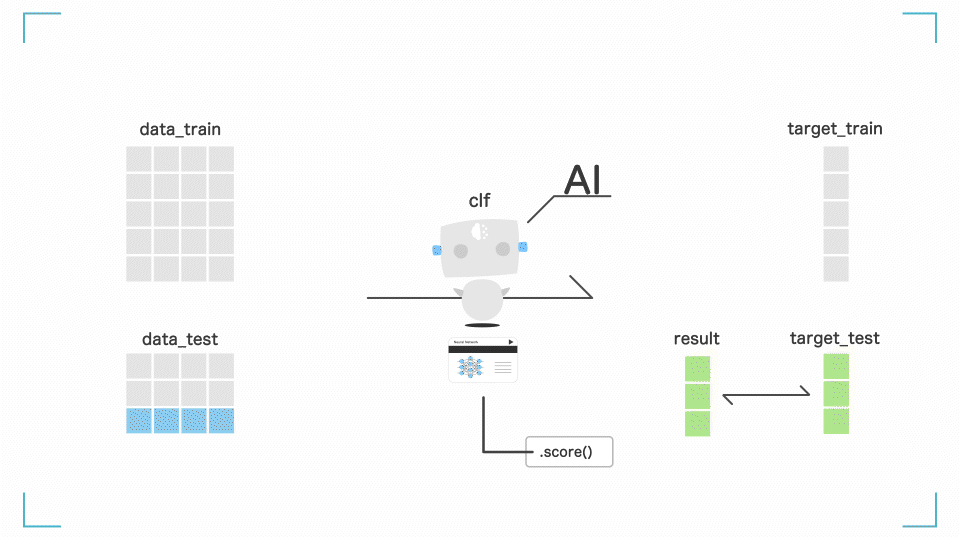
print(clf.score(data_test, target_test))
最後の行では モデルがどれだけ賢いかを確認しています。
評価の様子
clf.score()を使うことで、モデルの精度をみることができます。
このとき渡すのは、最初に作ったdata_testとtarget_testです。
score()に渡すデータ |
||
|---|---|---|
| 3 | data_test |
モデルの評価に使う「テストデータ」です。 |
| 4 | target_test |
テストデータの「正解ラベル」です。答えが入っています。 |
下記のように結果が帰ってきます。
0.9736842105263158
結果を見ると、97%ということがわかります。
アヤメの情報を 100 個見せたら、97 個は正しく勝手に分類してくれるということです。
すごいです。
もっと精度を上げたい!
とりあえず、AI を作ることができました。これで、アヤメを分類して!と突然言われても安心です。
その一方で、このモデルは精度 97%なので、100 個に 3 個は外してしまう可能性があります。
大量生産をする製造業などでは、不良率 3% は致命的な数値です。
clf = MLPClassifier() #モデルを定義している
clf.fit(data_train, target_train) #モデルを学習している
print(clf.score(data_test, target_test))#モデルの精度を出している
↑ 6, 7, 8 行目のコードを工夫することで、精度はもっと良くなります!
① パラメータを設定
② メソッドを実行
③ 属性を確認
という3つをマスターして、より精度の良い、信頼できる分類モデルを作りましょう。
①②③ の詳細は 今後の記事で解説します。
フォロー ♻️、いいね 👍、サポート 🐱 お願いします。とっても嬉しいです。
皆さんの理解が一歩でも進んだのなら嬉しいです。
機械学習をもっと詳しく
Python の基礎を本にまとめています。併せてご覧いただけるととても嬉しいです ↓ DeepLearning の基礎を本にまとめています。手に取って頂けるととても喜びます ↓

ねこアレルギーの AI
YouTube で機械学習について発信しています。お時間ある方は覗いていただけると喜びます。
Created by NekoAllergy
Discussion