【AIメモ】GoogleのTPUがすごい

Google TPU がすごい。
TPU ってなに?
TPU は、Google が開発した機械学習のプロセッサです。
【補足】TPU は Tensor Processing Unit の略です
CPU や GPU と同じ流れです。
- CPU:Central Processing Unit
- GPU:Graphics Processing Unit
- TPU:Tensor Processing Unit

TPU を使うと、ディープラーニングを高速化できます。Google 自身も Google Photos などで TPU を使っています。私たちも GCP(Google Cloud Platform)から、TPU を使った機械学習をすることができます。
今回は、機械学習ユーザー必見の TPU について簡単に紹介します。イメージをざっくり紹介するので、実際の動きとは多少異なる点があります。ご了承ください。
皆さんの理解が一歩でも進むと嬉しいです。
ニューラルネットワークの基本を知りたい方は、こちら ↓ も併せてご覧ください。
Created by NekoAllergy
TPU の種類

左:TPU v2, 右:TPUv3
- 2015 年に、第 1 世代モデル「TPU v1」を発表、
- 2017 年に、第 2 世代モデル「TPU v2」を発表、
- 2018 年に、第 3 世代モデル「TPU v3」を発表、
- 2021 年 5 月 18 日、第 4 世代モデル「TPU v4」を発表しました。
年々バージョンアップしています。
どれくらいすごいのか
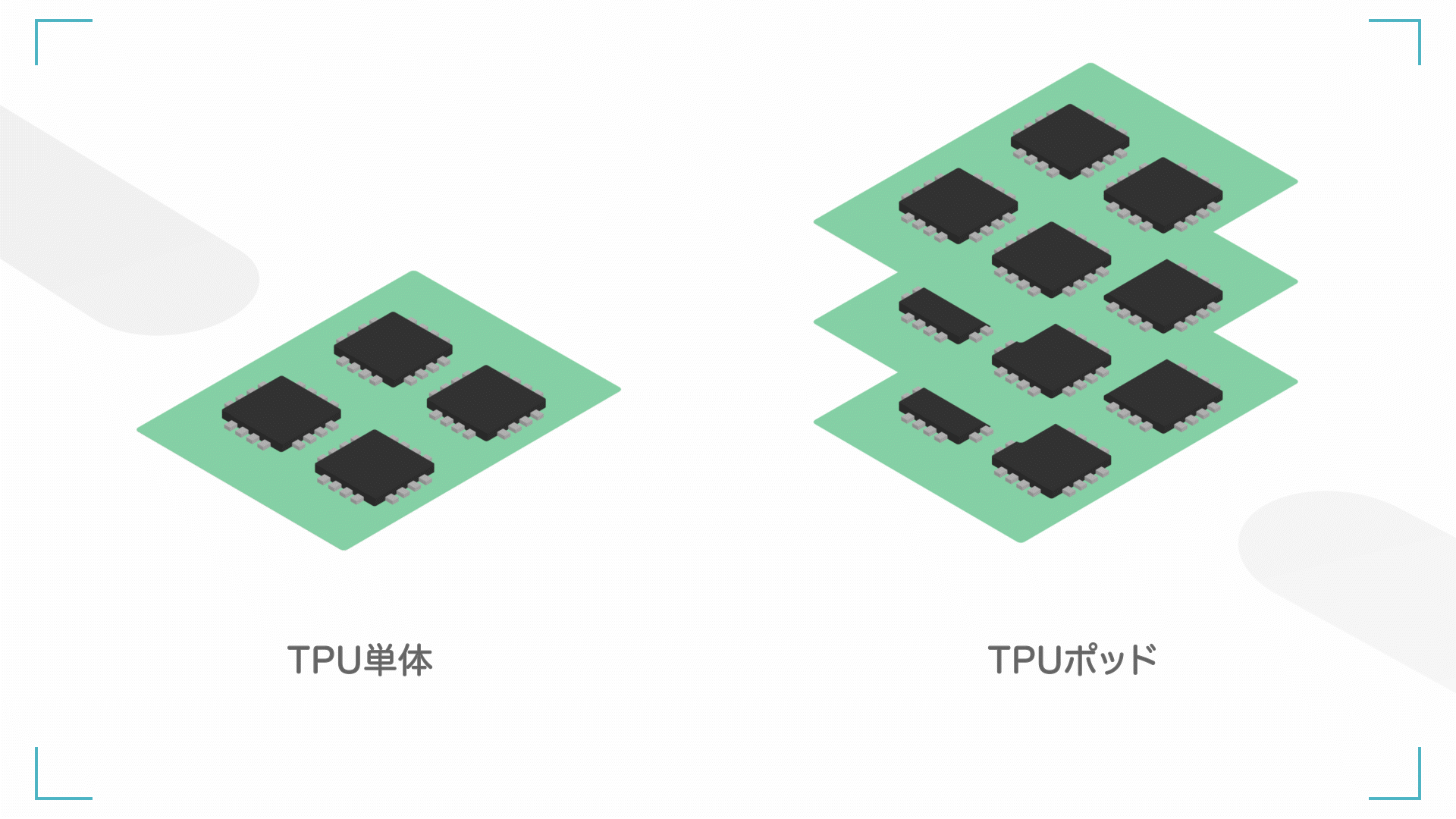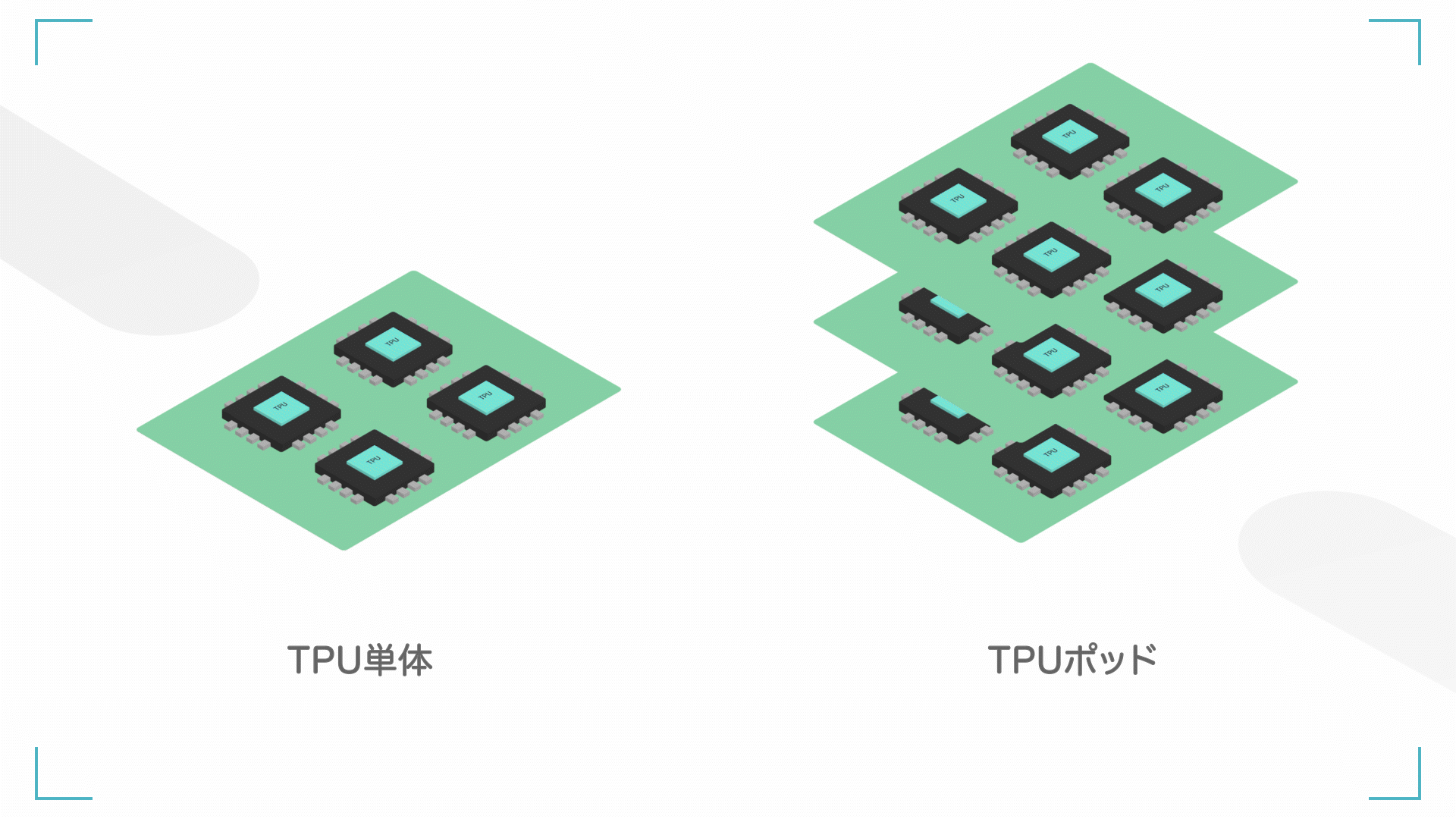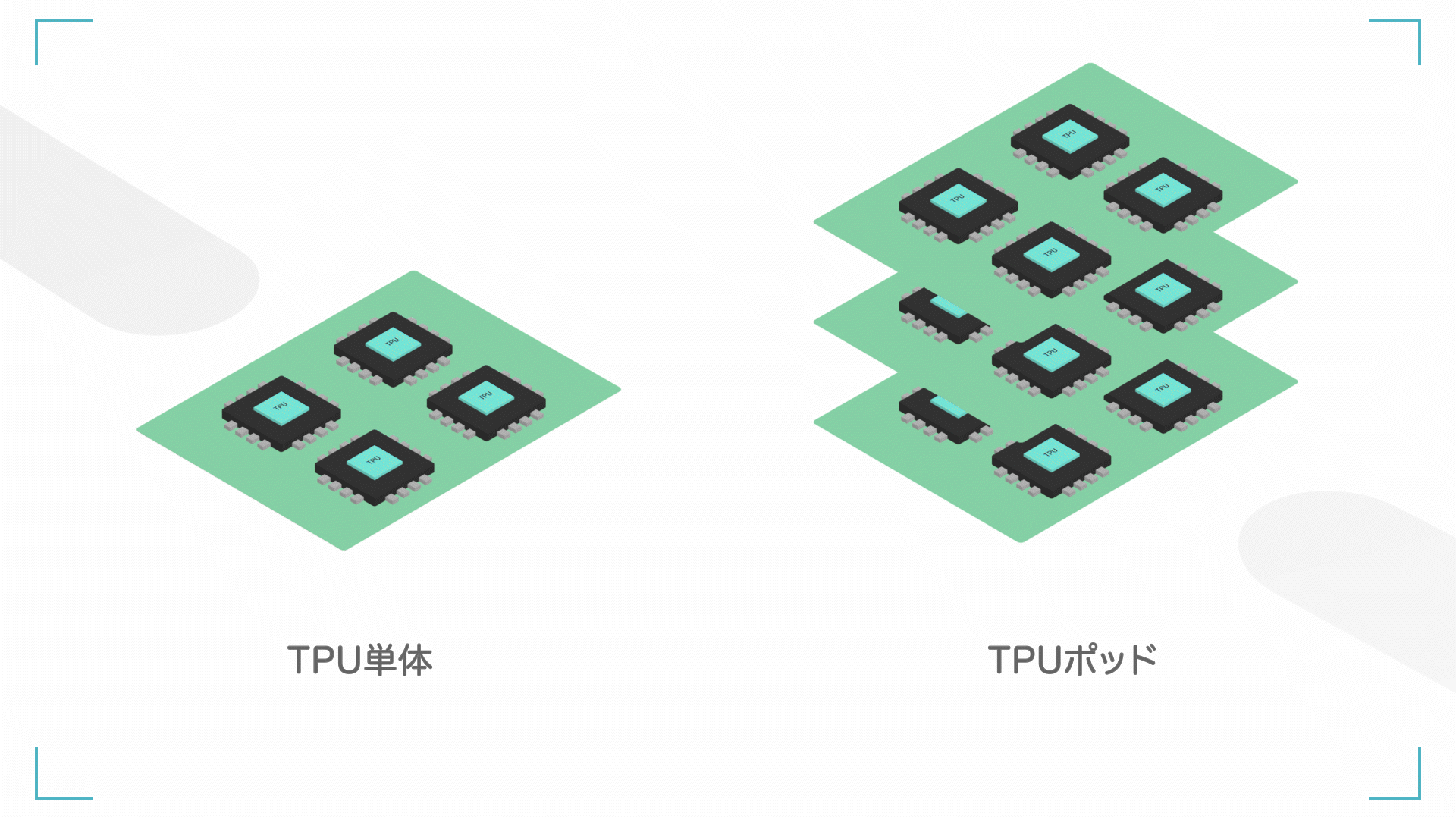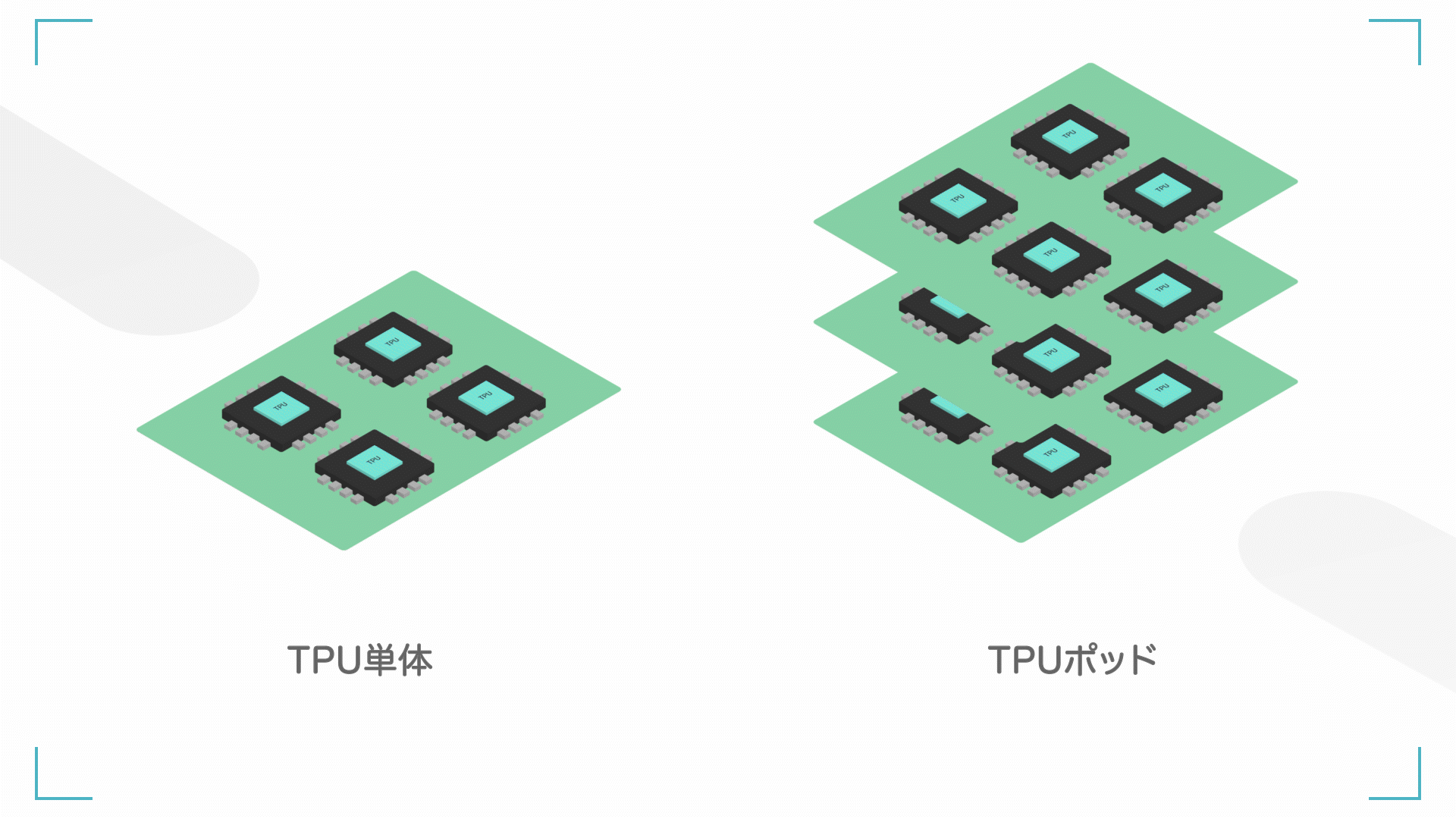
左:TPU 単体(ユニットとも呼ぶ)、右;TPU ポッド(TPU たくさん)
かなりすごいです。
最新版の TPU v4 のポッド(4096 台構成)は、1EFLOPS の演算ができます!
これだけ聞いてもよく分からない方のために、簡単に解説します。
FLOPS って?
プロセッサの計算能力は、FLOPS(フロップス)という単位で比べられることが多いです。FLOPS とは、「1 秒間に浮動小数点の演算が何回できるか」を示す指標です。数字が大きいほどすげえってことです。
ポッドって?
また、TPU を何個か組み合わせると、ポッドと呼ばれます。TPU1 個でもやばいですが、たくさんの TPU を連動させるともっとやばいです。
基本的に、TPU の性能はポッド単位で測られることが多いです。
E(エクサ)って?
大きさの単位の前につくやつです。k(キロ)がつくと 1,000 倍、M(メガ)がつくと 1,000,000 倍されます。
| k(キロ) | 10 の 3 乗 | 1,000 |
| M(メガ) | 10 の 6 乗 | 1,000,000 |
| G(ギガ) | 10 の 9 乗 | 1,000,000,000 |
| T(テラ) | 10 の 12 乗 | 1,000,000,000,000 |
| P(ペタ) | 10 の 15 乗 | 1,000,000,000,000,000 |
| E(エクサ) | 10 の 18 乗 | 1,000,000,000,000,000,000 |
| Z(ゼタ) | 10 の 21 乗 | 1,000,000,000,000,000,000,000 |
| Y(ヨタ) | 10 の 24 乗 | 1,000,000,000,000,000,000,000,000 |
以上を踏まえて、
TPU v2 のポッド(64 台構成)は、11.5PFLOPS
TPU v3 のポッド(64 台構成)は、100PFLOPS です。
M1 Mac は、だいたい〇〇 G(ギガ)FLOPS とか〇〇 T(テラ)FLOPS とかです。
条件が違うので単純な比較はできませんが、とにかく TPU すごいです。
最新版の TPU v4 のポッド(4096 台構成)は、1exaFLOPS の演算ができます。
これは、TPU v3 のポッド(4096 台構成)と比較すると 2 倍以上らしいです。
ノート PC 用プロセッサ 1000 万台に相当するそうです。
よく分からないくらい凄いです。
CPU と TPU の違い
CPU、GPU のような汎用プロセッサと異なり、TPU はディープラーニングに特化しています。
大きく違う点は 2 つです。
ポイント ① 8 ビット/16 ビットの演算器をベースとしている点

8 ビット/16 ビットがベース
ビット数が大きくなるほど、計算精度は良くなっていきます。
CPU などの汎用プロセッサでは 32 ビットの演算が主流です。しかし、ディープラーニングの計算は、それほどの精度を求められません。推論フェーズでは、8 ビットが最適と言われています。
【補足】推論(すいろん)フェーズとは?
機械学習では、① 学習フェーズ → ② 推論フェーズという流れで AI を作っていきます。
① 学習フェーズでは、たくさんのデータを見せて学習をします。学習が完了したら AI と呼ばれるようになります。
② 推論フェーズは、実際に AI を動かして問題を解く段階です。
一般的に、学習フェーズの方が演算性能が求められます。時間もかかります。
このため、TPU v1 では 8 ビットの演算器を 6 万 5536 個搭載した構成にしました。消費電力も 1 ユニット 40W に抑えられます。
【補足】どれくらいすごいの?
「Tesla K80」という GPU は、32 ビット演算器が 2496 個搭載されています。そう考えると 6 万 5536 個はかなり多いですね。
TPU v1 では、機械学習の推論フェーズに特化していました。
TPU v2 では、学習フェーズでも使えるようにするため、16 ビットの演算器を 3 万 2768 個搭載したプロセッサを、1 ユニットに 4 個搭載しました。1 ユニットで 180TFLOPS の演算能力を発揮できます。
学習には 16 ビットが必要であり、16 ビットにすることで、TPU v2 では学習フェーズと推論フェーズの両方で使えるようになりました。
ポイント ② 大規模な行列演算パイプラインがある点
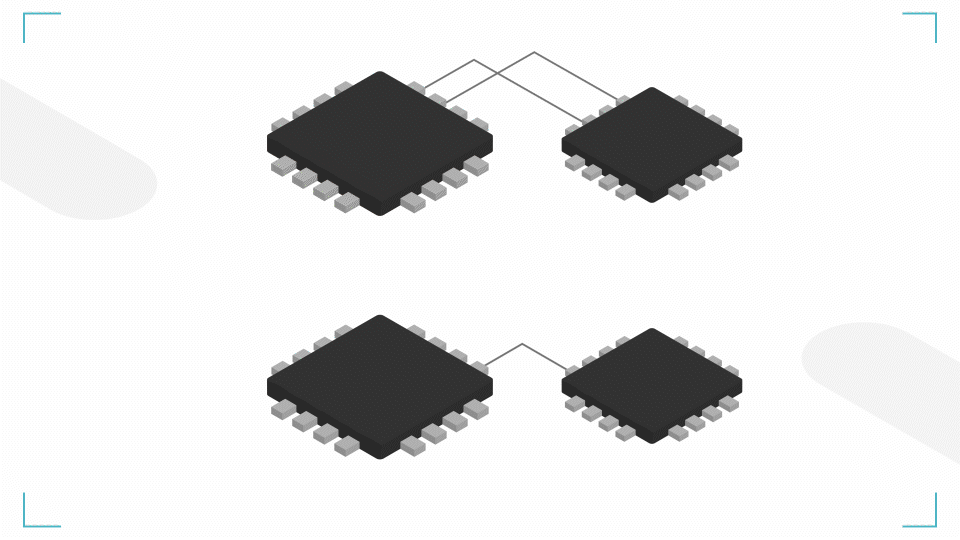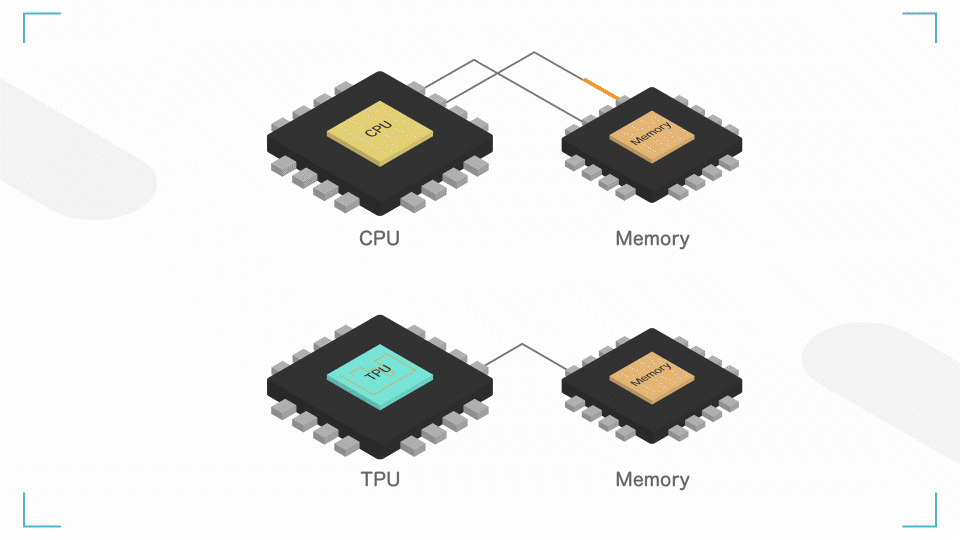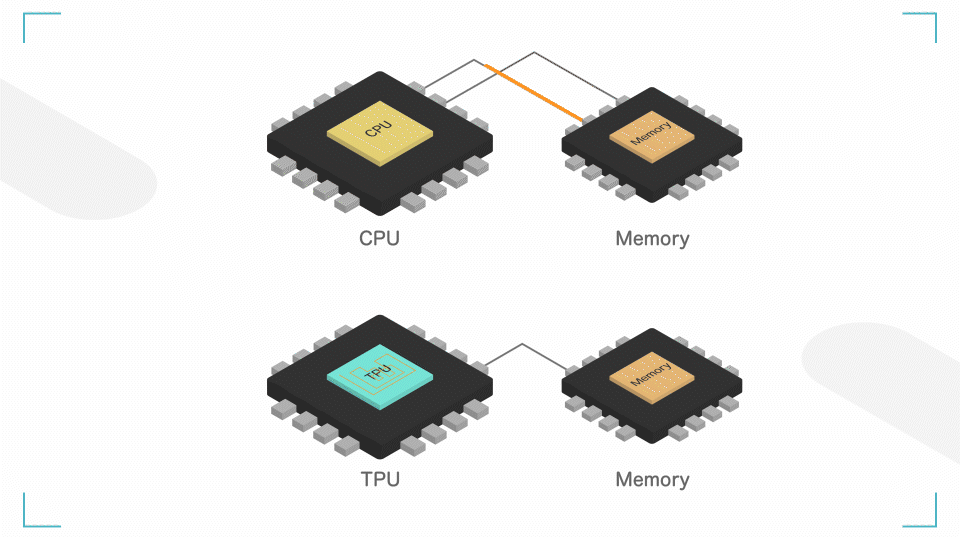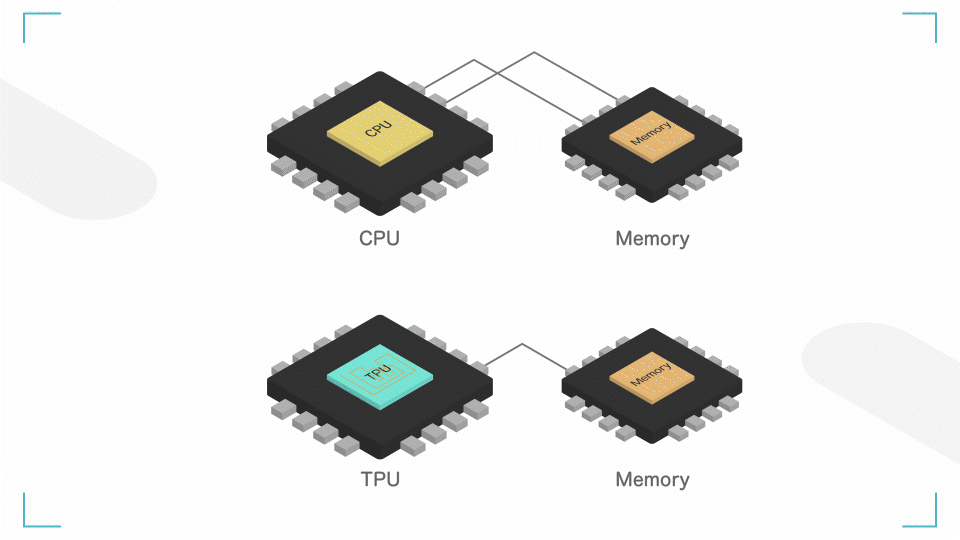
メモリへの書き込みを最小限に。
CPU では、計算する間にメモリへの読み書きを行います。これに結構時間がかかってしまいます。
TPU では、演算の結果を、演算回路内で直接渡すようにしています。シストリックアレイというそうです。これにより、メモリへの読み書きを大幅に減らす&集約度を高め、電力消費を抑えることができます。
Apple の M1 チップが高速になったのと同じような考え方ですね。
TPU すごい。僕にも使える?
TPU は GCP(Google Cloud Platform)で使うことができます。サービスの名前は Cloud TPU です。Cloud TPU を使用すると、私たちも爆速で機械学習ができて便利です。
現在(2021/11)は、TPU v2 と TPUv3 が使えます。2021 年後半には、TPU v4 も利用可能になる予定らしいです。
Cloud TPU では、①TPU 単体 もしくは ② TPU ポッド のどちらかを選ぶことができます。TPU 単体はお手頃価格で、TPU ポッドはより高性能な演算ができます。
料金は以下の通りです。(2021/11 時点)
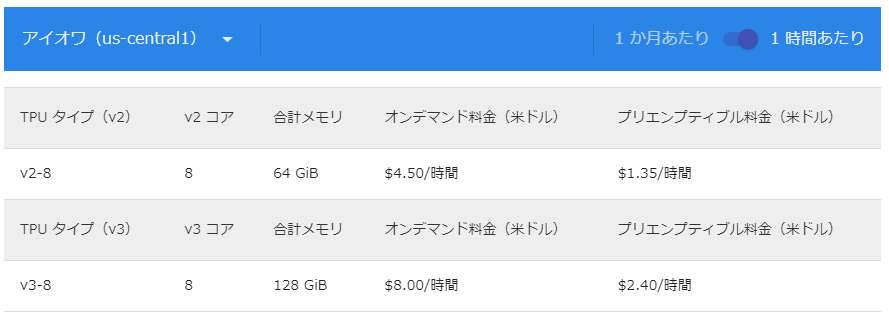
TPU 単体の料金
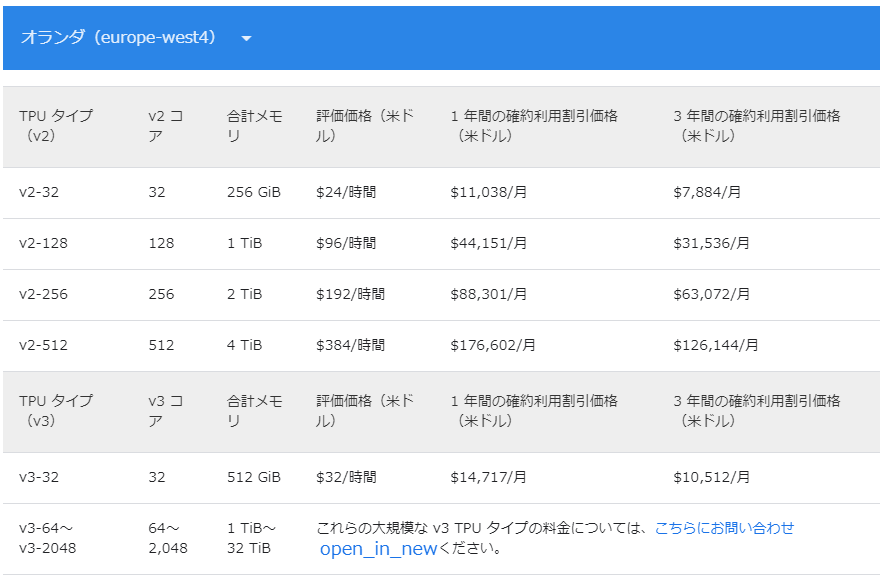
TPU ポッド(TPU たくさん)の料金
オンデマンド料金って欄が、かかる料金です。
TPU v2 は 1 時間 4.5 ドル~、TPUv3 は 1 時間 8.0 ドル~ 使えるみたいです。
ポッドを使おうとするともっと高いです。
また、プリエンプティブル料金っていうのも選べます。
Google が勝手に接続を切る可能性がありますが、そのぶん安く使用できます。
お試しなどならこっちで良さそうです。
- TPU 単体か TPU ポッドか選ぶ
- TPU タイプ(v2 か v3 か)を選ぶ
- オンデマンド料金かプリエンプティブ料金かを選ぶ
て流れだと思います。
まとめ
TPU について簡単にまとめました。
TPU すごいらしいです。
Cloud TPU 使ってみようと思います。
使用したらまた記事にしますのでフォロー&いいねお願いします。
機械学習をもっと詳しく
Python の基礎を本にまとめています。併せてご覧いただけるととても嬉しいです ↓ DeepLearning の基礎を本にまとめています。手に取って頂けるととても喜びます ↓

ねこアレルギーの AI
YouTube で機械学習について発信しています。お時間ある方は覗いていただけると喜びます。
参考文献
Created by NekoAllergy
Discussion