【初心者】機械学習の〇〇データが分からない【図解】

〇〇データ
〇〇データ
機械学習や DeepLearning の記事をみると、下記のような 〇〇データ をよく目にすると思います。
- 訓練データ
- 検証データ
- テストデータ
この 3 つは機械学習ではとっても大事で基本的なワードです。しかし、ほとんどの初心者は、3 種類のデータの役割や使い方が曖昧です。間違った使い方をすると、AI の精度は上がりません。
今回はこの 3 種類のデータの使い方について図解しました。初心者にも分かりやすく解説します。基礎をしっかり押さえて、高精度な AI を作りましょう。
DeepLearning の基礎を本にまとめています。手に取って頂けるととても喜びます ↓
みなさんの理解が一歩でも進めば嬉しいです。
Created by NekoAllergy
データ命
AI のゴールは、精度の良いモデルを作ることです。
[補足] モデルってなに?

モデルとは
機械学習ではまず 「どんなモデルを作るか」 を考えます。
モデルとは、入力値をもとに、中でいろいろな計算をして、出力値を導いてくれる 箱 のことです。このモデルが、最終的に AI(人工知能) と呼ばれるものになります。
モデルにとってはデータが命です。データを効率的に有効活用するために、機械学習では 与えられたデータセットを 訓練データ、検証データ、テストデータ の 3 つに分けて使うのが一般的です。
それぞれの役割は以下の通りです。
この 3 つを正しく理解するために、まずは モデルが学習する手順 と ハイパーパラメータ について知っておきましょう。
Created by NekoAllergy
モデルが学習する手順
モデルを作るときは、1.学習 STEP ⇒ 2.評価 STEP の流れで進めていきます。

学習の手順
それぞれ解説します。
1. 学習 STEP

学習 STEP とは
モデルは最初、作っただけの状態では ただの箱 です。このモデルに、たくさんのデータを入力して 学習 をさせます。
学習とは、モデルにたくさんのデータを何度も見せることで、モデルが そのデータの特徴 をどんどん覚えていくことです。学習が終わった時点で、ただの箱だったそのモデルが AI(人工知能) と呼ばれるように変わります。モデルをむりやり学習させて、AI に進化させてあげましょう。
まずモデルを作り、データを入れて結果を見てみます。モデルは最初は何もわからないので、かなり間違った予測を出力します。ネコの画像を入力しても、「これイヌだ」とか言ってきます。この予測値を、 正しい答えにどんどん近づけていくことが、モデルの学習 STEP でやること です。
2.評価 STEP

評価 STEP とは
学習が終わったら、完成した AI モデルが どれくらい良い AI なのか を評価する必要があります。自分が作った AI が、どれくらいの性能を持っているのか気になりますよね。
精度を測るために、 これまでモデルに見せてないデータ をモデルに入れてみて、結果を確認してみます。このような、モデルに 1 回も見せていないデータ(学習していないデータ)を 未知のデータ と呼びます。AI に未知のデータを入力して、学習 STEP と同じように、出力値と正解値のズレ(差)を確認します。
ここまでの内容をまとめます。
Created by NekoAllergy
ハイパーパラメータについて

機械学習では、パラメータとハイパーパラメータという言葉を使います。これらの意味は以下の通りです。
今回は、ニューラルネットワークを作る場合を考えながら、パラメータとハイパーパラメータの解説をします。そんなに難しくありません。
[補足] ニューラルネットワークって何?
ニューラルネットワークは人工知能を作るための方法(アルゴリズム)の 1 つです。
入力層に学習データを入力すると、入力層 → 中間層 → 出力層を通りながら勝手にいろいろ計算をします。
何回も計算(学習)を繰り返すことで、正解ラベルとの誤差を小さくしていき、最終的に良い感じの予測結果が出力層に出てくるというアルゴリズムです。
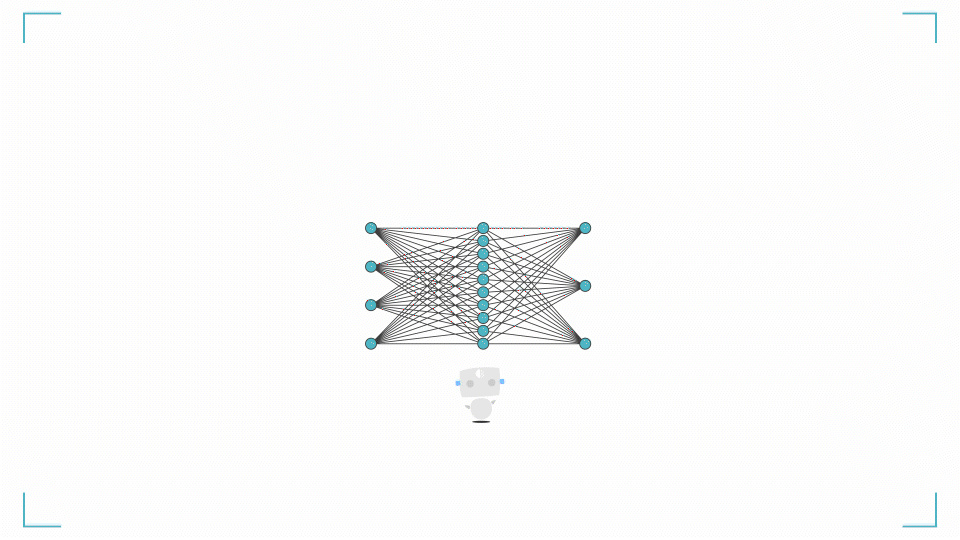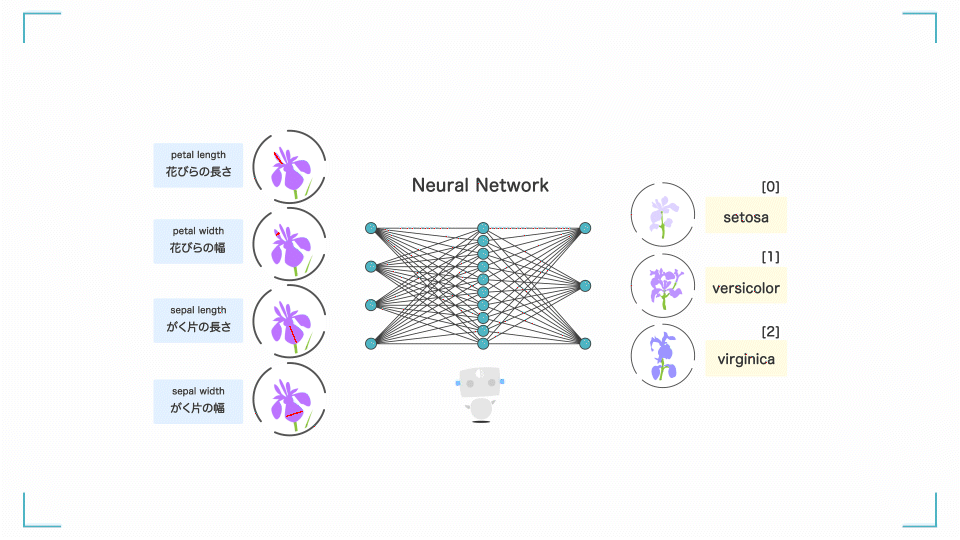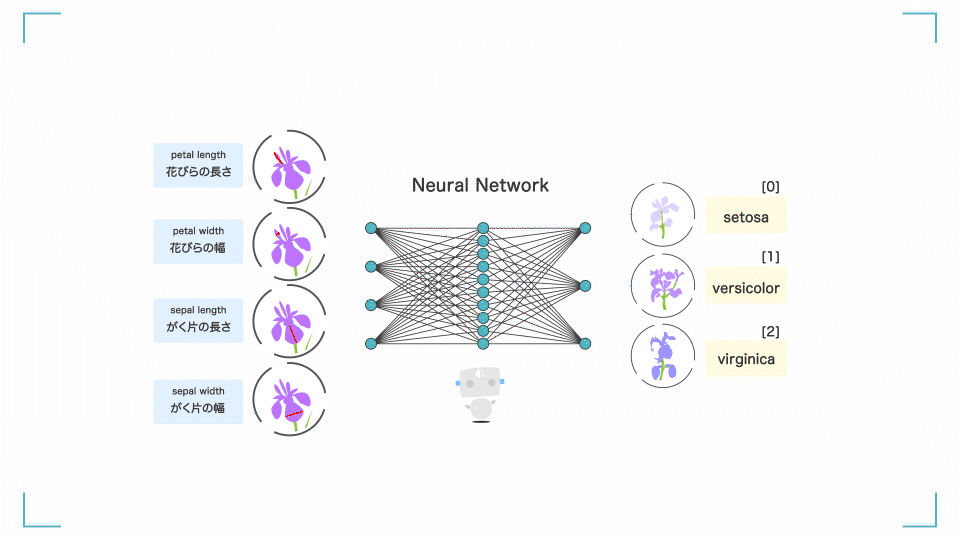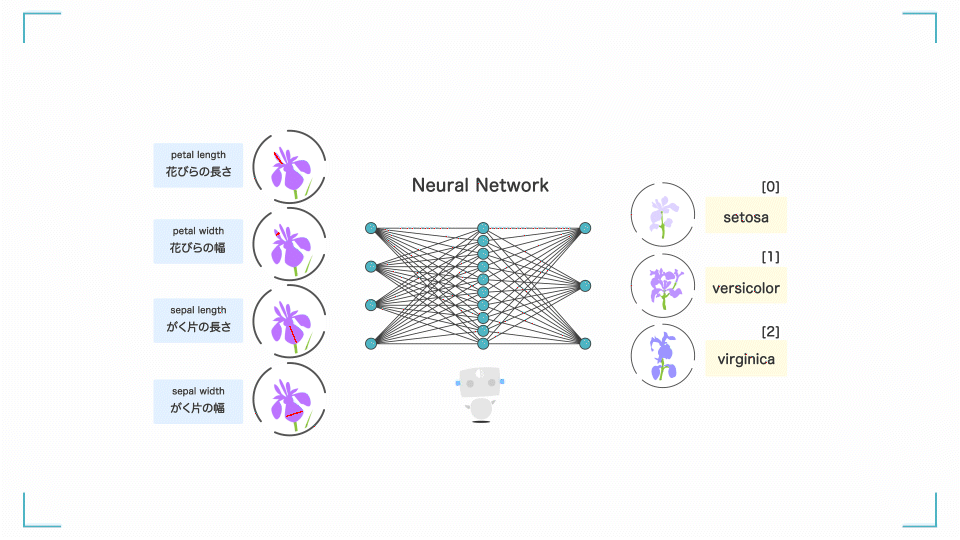
ニューラルネットワークとは?
(花びらの長さなどから花の種類を分類する AI の例)
ニューラルネットワークをもっと詳しく知りたい方は、初心者向けの記事と動画を上げていますので、よければご覧ください。
📄文字で見たい方はこちら
🎥動画で見たい方はこちら
パラメータって?
ニューラルネットワークを使ったモデルでは、学習を繰り返していくうちに、良い感じの答えに自動で近づけてくれます。このときモデルが自動で調整しているのが、パラメータ です。
ニューラルネットワークでは、重み と バイアス などの値がパラメータに当たります。モデルは与えられたデータを見ながら、パラメータを勝手に調整してくれます。これがいわゆる学習です。
ハイパーパラメータって?
一方、モデルが勝手に調整してくれないパラメータもあります。これをハイパーパラメータ と呼びます。ニューラルネットワークだと、ニューロンの数や層の数、学習回数や学習係数などがハイパーパラメータに当たります。
ハイパーパラメータの値は、学習の前にプログラマが決定する必要があります。モデルの精度を確認しながら、プログラマがコードの修正を繰り返します。
訓練?検証?テスト?

3 種類のデータ
話を戻します。機械学習では、与えられたデータセットを 訓練データ、検証データ、テストデータ の 3 つに分けて使うのが一般的です。
それぞれの役割は以下の通りです。
訓練データの使い方

訓練データの使い方
先ほど言った通り、訓練データは学習 STEP で使います。モデルは訓練データを 何度も見て 賢くなって いきます。
検証データの使い方

検証データの使い方
検証データは、ハイパーパラメータの調整 をするために使います。
これは、テストデータでの性能評価をする前に使います。
我々プログラマが決めなくてはいけないハイパーパラメータの値は、訓練データでもテストデータでもなく、検証データを見ながら調整していきます。ハイパーパラメータを調整する専用のデータ = 検証データということです。
検証データをモデルに渡してモデルの結果を確認します。その結果から、ハイパーパラメータが良いか悪いかを決めていきます。ハイパーパラメータは私たちが適切な値に設定しなければ、性能の悪いモデルになってしまいます。
検証データはあくまでハイパーパラメータを決めるためだけに使われるデータのため、記事の内容によっては省略される場合もあります。
テストデータでよくない?
テストデータを見てハイパーパラメータを調整するのは NG です。それをすると、テストデータに過度に対応しすぎてしまい、逆に汎化性能が落ちてしまいます。
※汎化性能 : どんなデータにも汎用的に対応できる能力。過学習を起こすと汎化性能は悪くなってしまう。
実際の動き
実際にハイパーパラメータを設定する際には少し時間がかかります。
ランダムに選んだハイパーパラメータをモデルに渡して、少ない学習回数(50 回など)で学習させます。学習が終わった段階で、用意しておいた検証データをモデルに渡し、検証データを使って精度を出します。精度〇〇%などの数値が出てきます。
この処理を何回か(100 回など)繰り返します。毎回ランダムなハイパーパラメータが選ばれるので、最終的な精度も毎回異なってきます。
最終的には、100 個の数値が得られます。これはそれぞれのモデルの精度です。これを数値の高い順に並べると、どのハイパーパラメータを使ったモデルが精度が高いかが分かります。
得られたハイパーパラメータの数値を使って、今度は学習回数を増やした条件で、本格的な学習を行います。検証データはあくまでハイパーパラメータを決めるためだけに使われるデータです。
テストデータの使い方

テストデータの使い方
テストデータは評価 STEP において、学習済みモデルの精度を予測 するためにテストデータを使います。
3 種類のデータの中では、最後に使われるデータです。
訓練データとテストデータが分かれている理由は?
訓練データとテストデータが分かれている理由は、汎化性能を評価するためです。訓練データだけで学習を行い、データの特徴を理解します。その後、テストデータを使って、未知のデータに対しても正しく判断できるかをチェックします。こうすることで、訓練データだけに過度に対応しすぎていないか(過学習していないか)を評価することができます。
Created by NekoAllergy
まとめ
今回は、訓練データ、検証データ、テストデータについて解説しました。
(1)訓練データ : モデルが学習
(2)検証データ : ハイパーパラメータを調整
(3)テストデータ : 精度を出す
皆さんの理解が一歩でも進んだのなら嬉しいです。
フォロー ♻️、いいね 👍、サポート 🐱 お願いします。とっても嬉しいです。
機械学習をもっと詳しく
DeepLearning の基礎を本にまとめています。手に取って頂けるととても喜びます ↓

ねこアレルギーの AI
YouTube で機械学習について発信しています。お時間ある方は覗いていただけると喜びます。
Created by NekoAllergy
参考文献
Discussion