はじめに
LLM(大規模言語モデル)が事前に学習していない情報を生成内容に反映させたい場合、コスト効率や時間の観点から、ファインチューニングではなくてまずRAGからやった方が良いみたいなことをよく聞きます。よく聞くのですが、じゃあRAGからやったとしてどういう状況になればファインチューニング使うの?と疑問が浮かび、そういったことをここにまとめることにしました。
以下の動画を主に参考にしてまとめました。ただ、以下の動画内でもある通り、ファインチューニングの使いどきに明確な答えはないとのことで、本記事が必ずしも正解ということではないことをご承知おきください。
AWS re:Invent 2024 - Customizing models for enhanced results: Fine-tuning in Amazon Bedrock (AIM357)
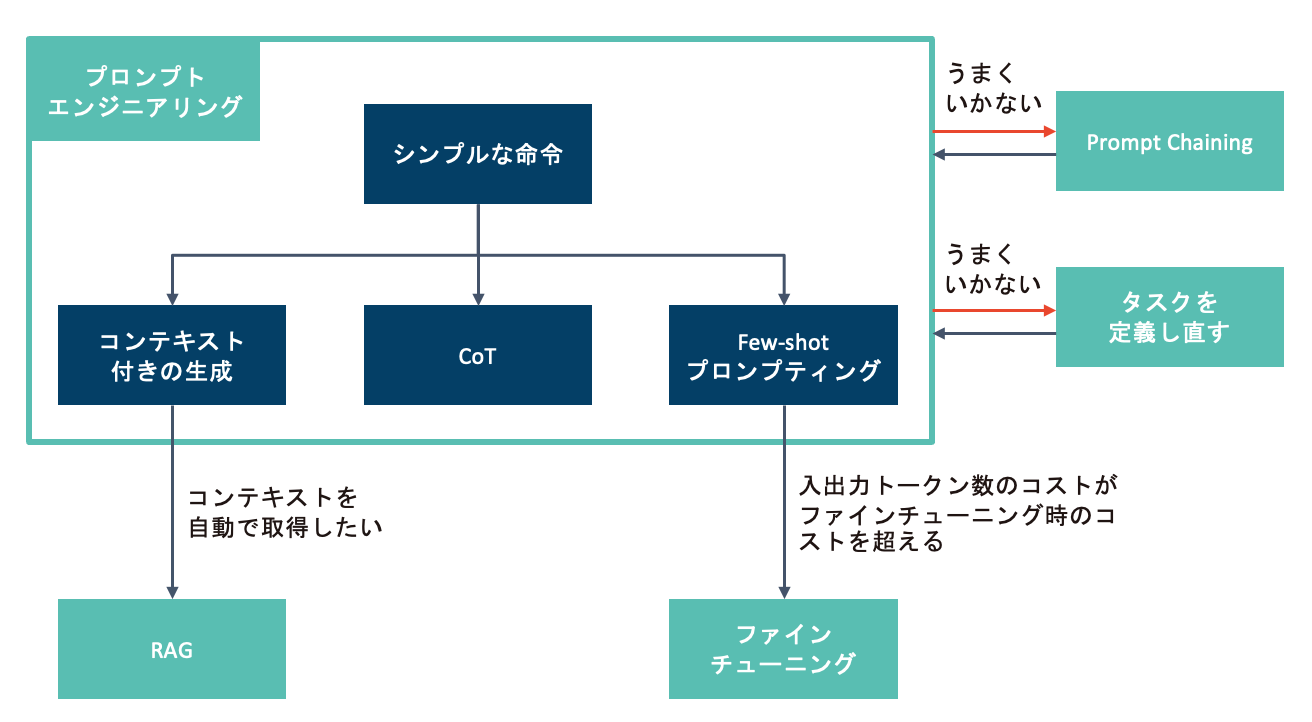
まずはプロンプトエンジニアリング
LLMに特定のタスクや処理を実行させたい場合は、まずシンプルなプロンプトから始めて、徐々にプロンプトを拡張していくのが良いようです。ここで、LLMがきちんと指示に従っているか、課題を解決できているか、プロンプトで設定した制約をきちんと守っているか確認します。
プロンプトは、できるだけ明確で直接的で詳細な指示を出すことが重要だとされています。Anthropicの公式ページには、「同僚(できればタスクについて最小限の文脈しか持っていない人)にプロンプトを見せて、指示に従ってもらいましょう。彼らが混乱するようであれば、Claudeも同様に混乱する可能性が高いです。」と記載されています。
つまり、LLMに任せたいタスクが明確でないと、求めている回答は得られないということです。[1]
また、プロンプトを拡張していく例としては、コンテキスト付きの生成やChain-of-Thought、Few-shot プロンプティングなどが挙げられます。
上記のような手法で改善しない場合、タスクをさらに分割して1つ1つのタスクをより簡単にしてあげて複数のLLMで処理を実行させたり(Prompt Chaining)、タスク自体をより簡単なタスクに置き換えてあげるなどLLMに任せたいタスクを定義し直したりすることも必要だと思います。
LLMや生成AIに任せたいタスクがきちんと定義されていない中でRAGやファインチューニング、継続的な事前学習などに取り掛かると、お金や時間を無駄にする可能性が高くなると思います。
コンテキスト付きの生成
コンテキスト付きの生成は、ユーザーからの質問に関係する文書(=文脈=コンテキスト)をプロンプトに含めることで、LLMが本来知らないことを回答してもらうことです。プロンプトとしては以下のようになります。
文脈を踏まえて質問に1文で回答してください。
文脈:"""
NCDC株式会社の事業内容は、ビジネスコンサルティング、UI/UXコンサルティング、
システム・インテグレーション、クラウドサービスの開発です。
"""
質問:NCDC株式会社の事業内容は?
さらに、ユーザーからの質問や入力を元に文書をベクトルDBなどから検索して、検索結果をコンテキストに含めてLLMに回答させる手法がRAG(検索拡張生成)になります。
RAGの使いどきとしては、コンテキスト付きの生成をやってみてうまくいったので次は自動でコンテキストをどこかから持って来たい、または従来の経験からコンテキスト付きの生成でわざわざ確認せずともRAGでうまくいくと判断できる根拠(単純なQAボットなど)がある場合と理解しています。
なお、このコンテキスト付きの生成をIn-context-Learning(ICL)と呼ぶ記事もあれば、Few-shot プロンプティングをICLと呼ぶ記事もあり、ICLの定義が人によって違ったので本記事ではICLという言葉を使わないようにします。
Chain-of-Thought(CoT)
プロンプトに「段階的に考えてください」や「ステップバイステップで考えてください」といった一言を追加する手法です。以下のプロンプトは基本的なCoTになります。
以下の質問に段階的に考えてください。
質問:10 + 2 * 3 - 4 * 2
計算式を解くために、演算の優先順位に基づいて計算を行います。まずは掛け算を先に計算します。
1. 2 * 3 = 6
2. 4 * 2 = 8
次に、得られた値を使って足し算と引き算を行います。
3. 10 + 6 - 8
この式を左から右に計算します。
4. 10 + 6 = 16
5. 16 - 8 = 8
したがって、最終的な答えは、8 です。
思考プロセスを出力しなければ思考は行われないとのことなので、必ずLLMに思考プロセスを出力させるようにします。
メリットとしては、問題を段階的に進めることで、特に数学、論理、分析、または一般的に複雑なタスクでのエラーを減らすことができたり、LLMの思考プロセスを見ることで、プロンプトが不明確な箇所を特定するのに役立ちます。
また、LLMが従うべき具体的な思考ステップを記載する手法をガイド付きCoTと呼びます。
今年のCare for Kidsプログラムへの寄付を依頼する、
寄付者向けのパーソナライズされたメールを作成してください。
プログラム情報:
<program>{{プログラムの詳細}}
</program>
寄付者情報:
<donor>{{寄付者の詳細}}
</donor>
メールを書く前に考えてください。まず、寄付履歴と過去に支援したキャンペーンを考慮して、
この寄付者にどのようなメッセージが効果的か考えてください。
次に、その履歴を踏まえて、Care for Kidsプログラムのどの側面が彼らに訴求するか考えてください。
最後に、あなたの分析を用いてパーソナライズされた寄付者向けメールを作成してください。
Few-shot プロンプティング
複数の例をLLMに渡すことで特定のタスクの精度を高めたり、回答のトーン(言い回し)を調整したりできます。
下記の会話履歴(messages)の1つ目の文は、この会話全体でLLMが行うことの指示になっています。2つ目の文はユーザーからLLMへの入力、3つ目の文は2文目に対するLLMの回答となっていて、2,3文目で1つの例(ユーザーの入力と真値のセット)になっています。
5行目までが例示となり、6行目が例ではなく実際のユーザーの入力となります。事前に5行目までの例示がLLMに渡されている状態で、ユーザーが実際に6行目の「ChatGPTはとても便利だ」を入力した結果、LLMがtrueと答えたということになります。
messages=[
{"role": "system", "content": "入力がAIに関係するか回答してください。"},
{"role": "user", "content": "AIの進化はすごい"},
{"role": "assistant", "content": "true"},
{"role": "user", "content": "今日は良い天気だ"},
{"role": "assistant", "content": "false"},
{"role": "user", "content": "ChatGPTはとても便利だ"},
]
true
ファインチューニング時も同様の形式の例示(データセット)が必要です。
ファインチューニングの使いどき
LLMに任せたい特定のタスクに対して、プロンプトエンジニアリングをまず続けたところ、以下のことがわかったとします。
- プロンプトエンジニアリングの中でも
Few-shot プロンプティングがうまく機能するタスクであること。 - 1度のLLMの呼び出しに対して、とても多くの例が必要であること。
- とても多くの例が必要になることで、入力トークン数のコストがとてもかかること。
上記全てに合致する場合はファインチューニングを行い、より短いプロンプトでLLMにタスクを任せることで、入力トークン数のコストを抑えることができます。
つまり上記全てに合致する時がファインチューニングの使いどきという理解をしました。
ファインチューニングにかかる料金のイメージ
上記の理解をした後、ファインチューニングにかかる料金を求めてみました。この料金をFew-shot プロンプティングで超えた場合にファインチューニングに切り替えれば良いという具体的な金額感が掴めると思ったためです。AWS公式の料金ページでファインチューニングにかかる料金を参考にしました。
以下のケースで料金を求めてみました。
- 使用するLLM:Amazon Titan Text Express(Claude 3 Haikuの料金がなかったので…)
- 1件のレコードあたりの平均トークン数:1000トークン(日本語およそ2000字)
- レコード数:100件(50~100件のレコードから始めるのが妥当とのこと。)
1度のファインチューニングの料金
= 1000トークン × 100件 × 0.000008ドル/トークン × 10エポック
= 8ドル
ファインチューニングしたモデルの保存料金
= 1.95ドル/月
プロビジョニングされたスループット (No commitments, 1モデルユニット)
を使用してファインチューニングしたモデルをホストした場合の推論にかかる料金
= 20.5ドル/時間
プロビジョニングされたスループット (1 month commitment, 1モデルユニット)
を使用してファインチューニングしたモデルをホストした場合の推論にかかる料金
= 18.4ドル/時間 × 24時間 × 31日間
= 13689.6ドル/月
求めてみましたが、プロビジョニングされたスループットだけで1ヶ月あたり13689.6ドル=約204万円です(ここまでの計算間違ってないですよね…?)。正直、この料金だけLLMを呼び出される状況に合ったことがないんですよね…。
個人的には、相当なことがない限り、ファインチューニングは選択肢から外れるのではと思いました。
継続的な事前学習の料金のイメージ
ついでに、真値なしのデータの継続的な事前学習のことも書いておきます。これは、LLMに特定分野の知識(例:金融業界の用語など)を与える目的で利用されます。学習に利用するデータのイメージは以下です。
{"input": "AWSはAmazonが提供するクラウドです。"}
{"input": "BedrockはAWSの生成AIサービスです。"}
...
通常、上記のようなデータを少なくとも10億トークンを供給すると有効性が確認できるようです。(参考)
1度の学習の料金
= 100000000トークン × 0.000008ドル/トークン × 10エポック
= 8000ドル
モデルの保存料金とプロビジョニングされたスループットの料金は、ファインチューニング時と同じ。
1度学習してうまくいかなかったときのことを考えるとRAGとかに取り組んだ方が良い気がする…😅
動画内でもこの機能を使うのは非常に稀だと言っています…費用もそうですが大量の高品質なデータも必要ですしね…。
おわりに
ここまでをまとめるとこんな感じでしょうか。
ここまでご覧いただきありがとうございました。
認識間違っているところありましたらぜひご教示いただけると幸いです。
参考
- Anthropic 公式ページ
- AWS公式ブログ:Amazon Bedrock における Anthropic の Claude 3 Haiku モデルのファインチューニングの一般提供を開始
- AWS公式ブログ:Amazon Bedrock で Anthropic の Claude 3 Haiku を微調整し、モデルの精度と品質を向上
- AWS公式ブログ:微調整と事前トレーニングの継続を使用して、独自のデータで Amazon Bedrock のモデルをカスタマイズする
- re:Invent 2024: Amazon BedrockによるFine-tuning手法と効果
- Amazon Bedrock 生成AIアプリ開発入門 [AWS深掘りガイド]
- LangChainとLangGraphによるRAG・AIエージェント[実践]入門 エンジニア選書
-
とはいってもあるタスクの専門家の方が必ず命令を言語化できるとは限らないし、言語化できたとしてプロンプトにそのまま書いたとしてもうまくいくとは限らない。あるタスクに限定して専門家の方がひたすらプロンプトを試してその結果が溜まっていくような(ファイルが必要ならそれも添付して試せるような)デモアプリをご提供するところから始めることもあるんですかね…。 ↩︎

NCDC株式会社( ncdc.co.jp/ )のテックブログです。 主にエンジニアチームのメンバーが投稿します。 募集中のエンジニアのポジションや、採用している技術スタックの紹介などはこちら( github.com/ncdcdev/recruitment )をご覧ください!
Discussion