re:Invent 2024: Amazon BedrockによるFine-tuning手法と効果
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Customizing models for enhanced results: Fine-tuning in Amazon Bedrock (AIM357)
この動画では、Foundation ModelやSmall Language Modelのパフォーマンスを向上させるFine-tuningについて詳しく解説しています。Amazon BedrockでのFine-tuning機能の特徴や、Hyperparametersの設定方法、Custom Model Import機能などが紹介されています。特にAnthropicのClaude 3 HaikuのFine-tuningでは、TAT-QAデータセットを使用した実験で、ベースモデルと比べて25%の精度向上と35%のToken使用量削減を達成した具体例が示されています。さらに、MetaのLlama 3モデルについても、405Bモデルから8Bモデルへのdistillationとfine-tuningの実践的なデモを通じて、その効果が詳細に解説されています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
Fine-tuningの基礎と Amazon Bedrock の機能概要


これは、皆さんもすでにご存知かもしれない、非常にホットなトピックです。Foundation ModelやSmall Language Modelからパフォーマンスを引き出すための技術が数多く存在します。研究分野でもお客様からも大きな注目を集めている技術の1つが、Fine-tuningとモデルのカスタマイズです。今日は、基礎から始めて、AnthropicのモデルとMetaのモデルを使用した2つの興味深い応用例まで見ていきます。Fine-tuningが実際には何を意味するのか、これらのモデルのライフサイクルがどのようなものか、そしてFine-tuningのカスタマイズに関連してAmazon Bedrockで利用可能な機能について探っていきましょう。

Fine-tuningとは、本質的には事前学習済みのモデルを取り、自分のデータでカスタマイズするプロセスです。その事前学習済みモデルを得るまでの道のりは、ラベル付けされていない大規模なデータの集合体から始まります。豊富なリソースを持つ大規模な組織は、通常、基本的な能力を達成するためにモデルの事前学習を行い、そこから私たちがタスク固有のデータセットでFine-tuningを行うことができます。これにより、複数のタスク、言語、ドメインで一般的に使用可能なFoundation Modelが生まれます。その後、入力と期待される出力を示すPrompt-Completionのペアである、ラベル付けされたタスク固有の例を訓練データとして使用し、ベースモデルを特定のユースケース向けのモデルにFine-tuningします。

私たちは、多くのお客様が特定のドメインでこれを実装しているのを見てきました。金融サービスや医療分野にいる場合、語彙やタスクの種類は大きく異なります。関連性の高い質の良いデータでFine-tuningを行えば行うほど、その特定のタスクに対する最終的な結果は向上します。Fine-tuningの大まかなライフサイクルを見ると、通常はユースケースから始まります。例えば、文書を2行で要約するというケースを考えてみましょう。一見シンプルに見えますが、文書の詳細を2行で正確に捉えることは、今日の多くのLLMにとって難しいタスクです。もう1つの例として、テキストからSQLへの変換があります。これは、テキストクエリをSQLに変換し、そのSQLがプロットやBIの可視化のためのデータを取得するために分析バックエンドやウェアハウジングバックエンドに対してクエリを実行するというものです。
ユースケースは、実際にどのようなデータが必要かを示唆してくれます。ここでデータの準備が重要になります。データのクリーニングと強化を行い、重複がないようにして、同じデータで2回学習することがないようにする必要があります。研究と実際の運用の両方で私たちが確認してきたのは、高品質なデータが事前学習における最大の差別化要因だということです。高品質なデータは間違いなく、その特定のタスクタイプに対してより高品質なモデルを生み出します。今日でも、多くの組織がFine-tuning用のデータにラベルを付けるために、時間、リソース、そして高給の人間のラベラーに投資しています。
このデータが準備できたら、様々なフレームワークやサービスを使用できます。AWSでは、Amazon SageMakerやAmazon Bedrockなどのサービスがあり、これらを使用してモデルのFine-tuningを実行し、準備したデータに基づいてカスタマイズすることができます。このカスタマイズを実行する際は、Fine-tuningの進行状況を監視し、後のスライドで説明する異なるハイパーパラメータで再開するために、必要に応じてジョブを中断できるようにモニタリングを設定することが望ましいです。モデルのトレーニングが完了し、検証メトリクスが良好で、トレーニングがベースモデルとは異なる結果を生み出したことを確認したら、完全にブラインドなテストセットで評価を行います。文書要約やテキストからSQLへの変換などのタスクでは、評価用のテストセットとしてブラインドなタスクのセットを用意することができます。Retrieval Augmented Generationを使用している多くのお客様は独自の評価メトリクスを持っており、Amazon Bedrockはカスタマイズされたモデルを簡単に評価できる管理機能も提供しています。
Fine-tuningの実践的アプローチと Amazon Bedrock の高度な機能

では、重要な問題として、実際にいつFine-tuningを行うべきなのでしょうか?皆さんもきっと試したことがあると思いますが、Prompt engineeringや、ナレッジベースからコンテキストを取得してレスポンスを改善するRAG(Retrieval Augmented Generation)、そしてFine-tuningなど、様々なテクニックがあります。通常、人々はこの複雑さの順序で試していきます。
まず最初に試すべきなのがPrompt engineeringで、最適化された質の高いプロンプトを使用することで、約半分の成果が得られます。最近、Amazonでは特定のユースケースに対してプロンプトを自動的に最適化する機能をリリースしました。また、RAGを使用すると、ベクトル埋め込みインデックスやグラフ形式など、様々な形式で保存された社内の知識ベースを活用できます。ユーザーから質問があった場合、RAGは関連する文書やソースの断片を取得し、それらを質問と組み合わせてより良い回答を得ることができます。
今日のFine-tuningについて、複雑さの低いものから高いものまで見ていきましょう。例えば、カスタマーサービス業界で特定のトーンを模倣させたい場合、PromptingやPrompting plus RAGでもかなりの成功率が得られます。しかし、Fine-tuningを使用すると、複雑さの低いタスクではさらに成功率が高くなります。また、ベースとなるモデルがText to SQLが得意ではなかったけれど、今度はText to SQLを得意にさせたいというように、モデルに全く新しいスキルを教えたい場合、Fine-tuningが非常に効果的です。
このText to SQLの例を考えると、Fine-tuningしたモデルは特定のタスクセットで優れた性能を発揮しますが、少し異なる種類のSQLやGraphQLなど、他の複数のタスクには上手く一般化できません。つまり、Fine-tuningを行っても、教えた特定のタスクには非常に優れた性能を発揮しますが、類似した複数のタスクセットへの一般化は難しくなる傾向があります。最後のケースとして、モデルに新しい知識を教え、その知識を使ってタスクを解決させたい場合、Fine-tuningが機能する可能性はさらに低くなります。

Fine-tuningは特定のタスクに対して行われ、そのタスクで優れた性能を発揮し、評価して確実に機能することを確認できると考えてください。しかし、これは両刃の剣です。一般化を目指すなら、ベースモデルやPrompting、RAGを使用する方が良いでしょう。では、Fine-tuningを行う際の重要な考慮事項は何でしょうか?残念ながら、現時点での最良の答えは「場合による」です。明確な答えはまだありません。ベースモデルが既に理解している新しい概念を、小規模なFine-tuningを通じて学習させたい場合は、非常に良いユースケースとなります。
先ほど申し上げたように、これらのユースケースの中には、モデルに特定のタスクや特定の処理を実行させたい場合があり、Few-shotで有望な結果が得られた場合は、Fine-tuningが優れた成果を上げることが期待できます。Few-shotsとは、基本的に指示やPromptに添付できるインラインの例のことです。これらのFew-shotsは、モデルが特定の方法で応答するのを助け、トーンの調整や、これらのFew-shotsを提供することでタスクの精度を向上させることができます。Few-shotsがうまく機能する場合、同様の例をたくさん使ってFine-tuningを行えば、さらに良い結果が得られると考えることができます。
また、Prompt Engineeringでは、通常シンプルな形から始めて、徐々にPromptを拡張していき、最終的に非常に複雑な大きなPromptになることがあります。そこで、モデルが実際に私たちの指示に従っているか、課題を解決できているか、Promptで設定した制約をきちんと守っているかを確認する必要があります。
その過程で、うまく機能する大規模なシステム指示、Prompt、例のセットができあがるかもしれません。しかし、より多くの入力トークンを送信することになるため、トークンの予算と戦うことになります。必要な回答は得られるかもしれませんが、入力トークンに対してコストがかかります。Fine-tuningは、この複雑なPromptを回避する一つの方法です。Prompt自体に何百もの例を含めているお客様もいらっしゃいますが、それらの例でFine-tuningを行い、より短いPromptでFine-tuningされたモデルを使用することができます。同じインターフェースを使用している限り、出力Promptに対してはほぼ同じコストを支払うことになりますが、入力Promptに対するコストは少なくて済みます。
Amazon Bedrock における Fine-tuning の具体的な実装と効果

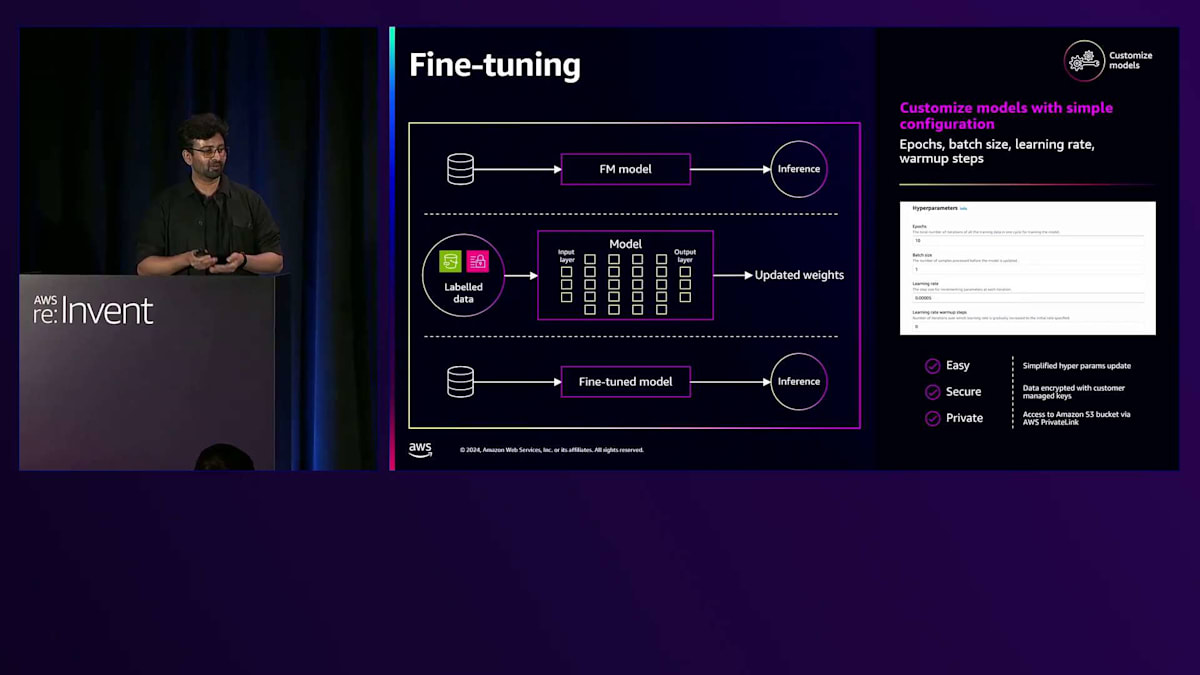
さて、Fine-tuningについて少し理解できたところで、 Amazon Bedrockの機能についていくつかお話ししたいと思います。 Bedrock Fine-tuningと呼ばれる機能があり、シンプルなデータセットを使用できます。最初の図で説明したPrompt-Completionのペアを使用して、JSONL形式のデータセットをS3にアップロードし、コンソールまたは用意されているAPIセットを通じて、ベースモデルをFine-tuningするモデルカスタマイズジョブを開始できます。その結果、特定のユースケースやタスクタイプに特化したモデルアーティファクトが生成され、それをProvisioned Throughput(基本的にはAPIとして利用できるスタンドアロンのエンドポイント)を通じて使用できます。これを最終的なアプリケーションと統合することができます。
Fine-tuningを行う際、Amazon Bedrockは、Fine-tuningの結果を制御できる最も重要なパラメータを提供します。これらはHyperparametersと呼ばれます。Fine-tuningを制御するこれらの高レベルな方法には、Learning Rate、トレーニングを実行する期間を示すEpochs数、Warmup Stepsなどがあります。これらはすべてドキュメントで詳しく説明されています。重要なポイントは、BedrockのFine-tuning機能が非常にシンプルだということです。フレームワークのセットアップ、インスタンスのセットアップ、サインイン、クラスターの管理などを心配する必要はありません。

これは非常に稀なケースですが、Continued Pre-training もAmazon Bedrockの管理機能の一つとなっています。稀である理由は、通常、大量の高品質なデータと、トレーニングのための時間やリソースが必要だからです。例えば、スケーリング則についてご存知かと思いますが、これは最適なモデルと、Fine-tuningに必要なリソース量との関係を示すものです。計算してみると、1兆パラメータのモデルを自前で訓練して起業しようとする場合、1兆トークンの高品質なデータがあれば、Pre-trainingに約2,000万ドルかかります。もし2,000万ドルの余裕資金をお持ちでしたら、ぜひご連絡ください。
より小規模なアーキテクチャを採用してPre-trainingを行うケースもあります。今週初めにリリースしたNova MicroやNova Lightなどの小規模モデルは、同様のプロセスを念頭に置いてPre-trainingされています。ラベル付けされていない大量のデータを使ってモデルをPre-trainingし、その後Fine-tuningとアライメントを行う、というのが一連のライフサイクルです。Continued Pre-trainingでは、データセットが適切なフォーマットでS3に保存されていれば、ベースとなるモデルアーキテクチャを選択できます。これはもはやベースのPre-trainedモデルではありません。モデルを完全にゼロから訓練することができ、それには十分な理由があります。とはいえ稀なケースで、ほとんどの場合はFine-tuningで十分な成果が得られるはずです。

数ヶ月前にリリースした重要な機能の一つが、Custom Model Import です。例えば、一般的なモデルアーキテクチャの一つを使用して、Bedrock以外の場所、つまりSageMakerやHugging Face Auto Train、あるいは自分のラップトップでFine-tuningを行った場合を考えてみましょう。LlamaモデルやFlan-T5モデル、その他のサポートされているモデルであれば、MistralなどのサポートされているモデルアーキテクチャとともにAmazon Bedrockにインポートでき、Bedrockのモデル呼び出しAPIを直接使用して、自分のモデルにアクセスできます。これにより非常に柔軟な運用が可能になり、Amazon BedrockのFine-tuning機能を使用しなくても、独自にFine-tuningしたモデルをBedrockで呼び出すことができます。Custom Model Importを使用してAmazon Bedrockにインポートし、そこでモデルを直接利用できるのです。Amazon Bedrockの魅力的な特徴の一つは、モデルのマーケットプレイスで、使用した入出力トークンに対してのみ料金を支払う点です。Custom Model Importでも、自分のモデルであってもトークンベースのコストで利用できます。これにより、まずモデルをテストし、アプリケーションとの統合の準備が整ったら、Provisioned Throughputを通じて特定のモデル用の専用エンドポイントを取得することができます。

最後に、最近リリースした機能としてAmazon Bedrock Model Distillationがあります。共著者のYanが素晴らしいガイドをすでに公開しており、ご覧いただけます。この機能のアイデアは、より大規模で高度な性能を持つモデルを使用してプロンプトと完了のペアを生成し、それを小規模モデルのラベル付きデータセットとして活用するというものです。例えば、大規模な汎用モデルであるLlama 405Bを使用してデータセットを生成し、それを使って1Bや8Bといった小規模なLlamaモデルを訓練することができます。Amazon Bedrock Model Distillationでは、TeacherモデルとStudentモデルを選択し、データセットをS3ファイルとして提供するだけです。特に興味深いのは、Amazon BedrockのInvocation APIを使用している本番アプリケーションがある場合、CloudWatchログ内に入出力ペアの呼び出しログが記録されており、それらのログを直接解析してトレーニングに使用できる点です。Bedrockのシンプルなウィザードを使用して、関連するAPIを利用することができます。
プロセスの最後には、特定のタスク向けに精密に調整された蒸留モデルが得られます。唯一の違いは、最初はほとんどデータがないか、まったくない状態からスタートし、Teacher Modelがそれらを例として使用して、より小さなモデルのダウンストリームFine-tuningのために、さらに質の高い例を生成するという点です。ぜひこれらの機能を試してみてください。ドキュメント、API、そして関連するブログも公開されています。以上がAmazon Bedrockの機能についての説明でした。次は、特にAnthropic Claude 3 Haikuのカスタマイズについて説明し、その後ESAとMetaについて説明します。
Anthropic Claude 3 Haiku の Fine-tuning:ベストプラクティスと実験結果

皆様、ありがとうございます。先ほど彼女がBedrock Modelのカスタマイズ機能についてかなり詳しく説明してくれましたが、ここではAnthropic Claude 3 Haikuのカスタマイズについてより詳しく見ていきたいと思います。この時間を使って、ベストプラクティスと実験結果を共有し、この機能を成功させる方法をお伝えしたいと思います。Fine-tuningのライフサイクルで説明したように、まず明確なユースケースを持つ必要があります。ユースケースが定義できたら、次はデータの準備段階に入ります。Claude 3 Haiku Fine-tuningでは、JSONL形式のデータを準備する必要があり、このデータはMessage APIを使用して、各行が1つのトレーニングレコードを表す必要があります。各行を詳しく見ると、まず任意でSystem Promptを設定できますが、これは強く推奨されています。なぜなら、モデルに役割を割り当てると、より良いパフォーマンスが得られる可能性が高いことがよくあるからです。次に、必須フィールドとしてMessageフィールドが必要で、このフィールド内には2つの役割が必要です:Fine-tuningされたモデルと対話する際のプロンプト入力を含むUserロールと、望ましい出力を担うAssistantロールです。
これら2つのロールは交互に配置する必要があり、マルチターンの会話もサポートしています。つまり、各JSONLファイルには複数のUserとAssistantの会話を含めることができますが、それらは交互に配置され、Message API形式に従う必要があります。データの準備が整ったら、Fine-tuningのパラメータ設定に進むことができます。

これらは、Amazon BedrockでのClaude 3 Haiku Fine-tuningでサポートされている5つのパラメータのリストです。最初の3つは必須パラメータで、下の2つはオプションですが強く推奨されています。最初のパラメータはEpochCountで、トレーニングデータセット全体を繰り返す最大回数です。これは最大10まで設定できますが、Haiku Fine-tuningでは検証データセットを提供すると早期停止が可能です。検証データセットを使用する場合、指定したカウント内で Fine-tuning ジョブを完了する必要はないかもしれません。これは単に設定する最大数となります。
2番目のパラメータはBatch Sizeで、モデルパラメータを更新する前に処理されるサンプル数です。このBatch Sizeはトレーニングレコード数と密接に関連しています。3番目のパラメータはLearning Rate Multiplierで、学習率に影響を与えます。デフォルトでは1に設定されており、私たちのサイエンスチームの広範な実験でこの値が最も効果的であることが判明しているため、お客様にもこの値から始めることをお勧めしています。Early Stopping ThresholdとEarly Stopping Patienceは、検証データセットを提供する場合に有効にできるオプションパラメータです。Early Stoppingは、指定されたしきい値と忍耐パラメータ内で検証損失が十分に減少しない場合にトレーニングジョブを停止することで、過学習を防ぐテクニックです。

これらのパラメータについて理解できたところで、適切な設定方法について説明していきましょう。Learning rate multiplierについては、私たちの研究者による実験結果から、まずは1.0から始めることをお勧めします。その後の評価結果に基づいて調整していくことができます。Batch sizeの最適値は、データセットの大きさによって異なります。1,000レコードを超える学習データの場合は、32-64という大きめのBatch sizeを推奨します。500から1,000レコード程度の中規模データセットでは、16から32のBatch sizeを検討してください。500レコード未満の小規模データセットでは、4から16の小さめのBatch sizeを試してみてください。私たちの実験では、1,000から10,000の大量データのシナリオではLearning rateの影響が大きく、100未満の小規模データセットではBatch sizeがFine-tuningのパフォーマンスを左右する主要な要因となることがわかっています。

ここで、TAT-QAデータセットをターゲットユースケースとして使用したパフォーマンス評価を見ていきましょう。このデータセットは一般に公開されており、財務テキストと表形式のコンテンツに関する質問応答タスクに焦点を当てています。私たちはこのTAT-QAデータセットから10,000レコードを使用してモデルを学習し、約3,500レコードを使用して評価を行いました。ここでは単語マッチングのF1スコアを使用して評価しています。
実験を行い、さまざまな設定を試した結果、Fine-tuningを施したClaude 3 Haikuから得られる最高のパフォーマンスは約91.2%の精度でした。これは実際、ベースのHaiku、Claude 3 Sonnet、さらには最新のClaude 3.5 Sonnetモデルよりも優れた結果です。モデルのパフォーマンス向上を見ると、ベースのHaikuと比べて約25%の改善が見られ、Claude 3 Sonnetと比べて約20%上回り、Claude 3.5 Sonnetと比べても約10%上回る結果となりました。
ここでもう一つ強調したいのは、In-context learningについてです。お客様から「すでにモデルをFine-tuningしたのですが、まだIn-context learningを使用すべきでしょうか?」という質問をよく受けます。答えは「はい」です。In-context learningは、ベースモデルとFine-tuningされたモデルの両方でパフォーマンスの向上に役立つため、引き続き使用を検討すべきです。モデルを最高のパフォーマンスに引き上げたい場合は、Fine-tuningとIn-context learningを組み合わせて使用することを検討してください。

最後のスライドで説明したいのは、Fine-tuningされたモデルを使用することのもう一つの利点、つまりToken使用量の削減についてです。通常、出力Tokenが多いとレイテンシーとコストが高くなることはよく知られています。Fine-tuningを使用することで、モデルの出力Token使用の効率性を高めることができます。TAT-QAデータセットを例に取ると、ベースのHaikuでは平均出力Tokenが約34であるのに対し、Fine-tuningされたモデルでは平均出力Tokenが約22となり、35%の改善が見られます。このヒストグラムを見ると、Fine-tuningされたHaikuは非常に密な分布を示しており、これは出力が非常に簡潔であることを意味します。一方、ベースのHaikuは不必要な情報を生成する傾向にあります。
ここで私のパートを締めくくるために、具体例をお見せしたいと思います。ライブコーナーでは、TAT-QAデータセットからの質問があります:「企業はTopic 606をどのように採用したのか?」正解は非常に簡潔で、おそらく4単語程度です。Base Haikuは、ここで不必要な説明を加える傾向にあります。ベースモデルの回答は事実としては正確でしたが、それほど効率的ではありませんでした。一方、Fine-tuningされたHaikuは、実際に正解と100%一致しました。事実に基づいた結果を生成しながら、非常に簡潔な出力を提供しています。
Meta の Llama モデルのカスタマイズとデモンストレーション
ここで、Amazon Bedrock上のMetaのモデルのカスタマイズについて、Isaにお話しいただきたいと思います。MetaのAIパートナーエンジニアリングチームのIsaです。これからMetaのLlamaモデルのカスタマイズについてご説明させていただきます。Fine-tuningが本当に効果を発揮するユースケースをいくつか紹介し、例を1つか2つお見せした後、8Bモデルのディスティレーションとファインチューニングの例を実際にデモでご紹介します。

Llama 3のFine-tuningユースケースについてです。ここに示しているのは、Fine-tuningが本当に効果を発揮するユースケースの一部です。これをここでご紹介する理由は、よくある質問に答えるためです:「なぜFine-tuningが必要なのか?」「なぜプロンプトエンジニアリングとRAGだけを使用してFine-tuningを行っていない場合、Llamaモデルが期待通りのパフォーマンスを発揮しないのか?」ここでは5つの例を挙げていますが、これはほんの一部で、他にも多くのユースケースが存在します。カスタマーサービスチャットボットは、企業の顧客からの問い合わせを理解し、その企業の内部知識や製品のコンテキストを持つことでFine-tuningの恩恵を受けます。コンテンツ生成は、ブランドのトーンやスタイルに合わせることができます。さらに、コンプライアンスや規制分析、財務チャート分析なども考えられます - これらはすべて組織や企業の要件に非常に特化したものとなり得ます。金融の場合、その企業の指標や、実行しようとしている特定の分析に非常に特化したものになる可能性があります。これらは一例に過ぎません。

Fine-tuningについてもう少し掘り下げて、ShreyasとYNNが提供した内容を基に説明します。Fine-tuningの最も重要な部分の1つは、データセットの分析と処理です。意図した目的に適した、十分に多様で一般化されながらも特化したデータセットを確保することが重要です。このスライドでお分かりの通り、適切にキュレーションされたデータセットが、Fine-tuningの利点を得るために極めて重要であることを強調しています。データセットが十分に多様でなかったり一般化されていなかったりすると、投入した労力やリソースに見合うだけのパフォーマンスと精度の向上が得られない可能性があります。2番目のポイントは、多様なデータセットがデータの一般化に本当に役立つということです。ドメイン固有のデータセットとカスタムデータセットについて、ドメインは当然、データセットを調整したい業界ドメインを指します。特定のタスクやプロジェクトについては、そのモデルとのFine-tuningパスで高い関連性と精度のある結果を提供するように設計されたカスタムデータセットを検討することになります。

大まかな説明をしていきますと、私たちはLlamaと、Fine-tuningに関する一般的なデフォルト設定を全ての例で公開しています。GitHubのリソースをご覧いただくと、Llamaはオープンソースで、Llama RecipesとLlama Stackという私たちのオープンソースリポジトリがあります。これらには推論やFine-tuning、Llama Guardによる安全性確保に関する多くの例が含まれています。そこには、Full ParameterやLoRA、Q-LoRAなどのFine-tuningの例が全て用意されています。通常、私たちが推奨するパラメータを公開していますが、具体的なケースによって変更が必要かもしれません。これはデータセットの性質や規模、ニーズ、十分な検証データがあるかどうかによって変わってきます。また、デプロイして修正可能なチャットボットを使用したエンドツーエンドのRAGの例や、数ヶ月前にリリースしたマルチモーダルモデルのレシピへのリンクも含めています。Llama 3.2は、テキストと画像の入力からテキスト出力が可能なマルチモーダル機能を備えています。

ここで、Fine-tuningがどのように役立つかを強調したいと思います。この例では、抽象化して説明していますが、Llama Base 8BモデルとそのFine-tuned版で数学の問題を解く簡単な分析を実行した例をお見せしています。Llama 3 8Bモデルの出力を見ると、あまり意味が通らず、計算も少しおかしいことがわかります。一方、Fine-tuned版を見ると、問題の指示を理解して簡潔な言葉で説明し、正しく計算を行うことができています。これはFine-tuningが妥当で正確な出力を生成する上で大きな違いを生む例を示しています。
では、デモに移りましょう。このデモでは、GitHubで利用可能なノートブックをお見せします。これはAWSと共同で作成し、AWS上のLlamaリポジトリで公開されているもので、Llama Recipesからもリンクされています。このノートブックでは、SageMakerやBedrock上で405Bモデルを実行する場合の手順を示しています。

ここでデモンストレーションしているように、そのデータセットを取得し、Distillationを使用して8Bモデルに教え込みます。そのパフォーマンスを向上させるために8Bモデルをファインチューニングすることになります。ここでは多くのテキストをスキップして、コードの部分に進みたいと思います。

前提条件として、AWSアカウント、SageMakerへのアクセス、Bedrockへのアクセス、そしてIAM設定が必要です。これらについては詳しく触れませんが、実際の内容に進みましょう。 ここで実際に行うのは、Llama 3 8B Instructモデルをデプロイし、deepmind/aqua_ratデータセットを使用することです。これは約10万の代数的な文章題を集めた大規模なデータセットです。このデータセットは、モデルのトレーニングと評価に非常に適しており、代数的な問題を自然言語で推論する能力を本当に測ることができます。
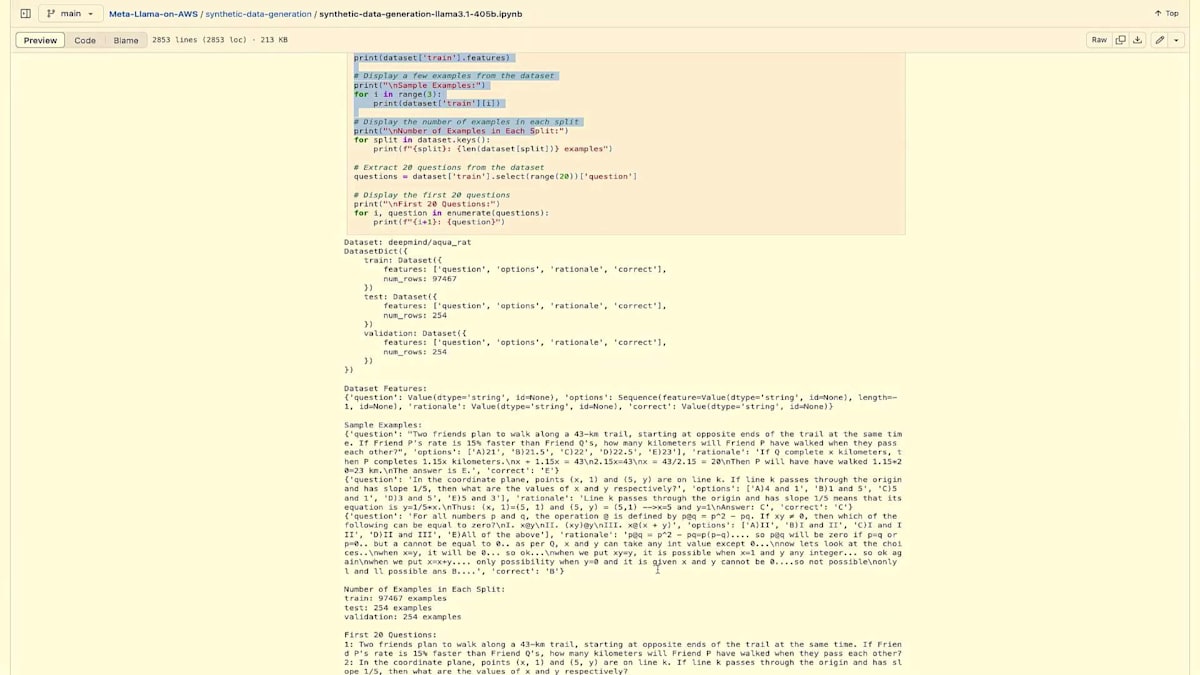

まず最初に基本的なインポートがあり、データセットの設定を始めていきます。ここでは、データセットを読み込んで実際に表示していきます。このノートブックを実行すると、このデータセットが実際にどのように見えるのかを確認できます。コードを見ていただくとわかるように、10万件以上の例を全て表示しないように、これらの行で制限をかけています。また、適切に分割も行っていますが、それがここでの出力となります。実際に何を扱っているのかを確認することができます。

このノートブックの次のステップでは、8B Instructモデルをデプロイし、問題を実行して、Fine-tuningや学習を行う前の出力が100%正確ではなく、私たちが望む結果と完全には一致していないことを確認します。同じプロンプトを405Bで実行すると、はるかに良い出力が得られることがわかります。つまり、405Bを使用して良好な応答が得られた場合、その405Bの出力を使用して、より小さなモデルを学習させるための合成データやデータを作成できる可能性があるということです。

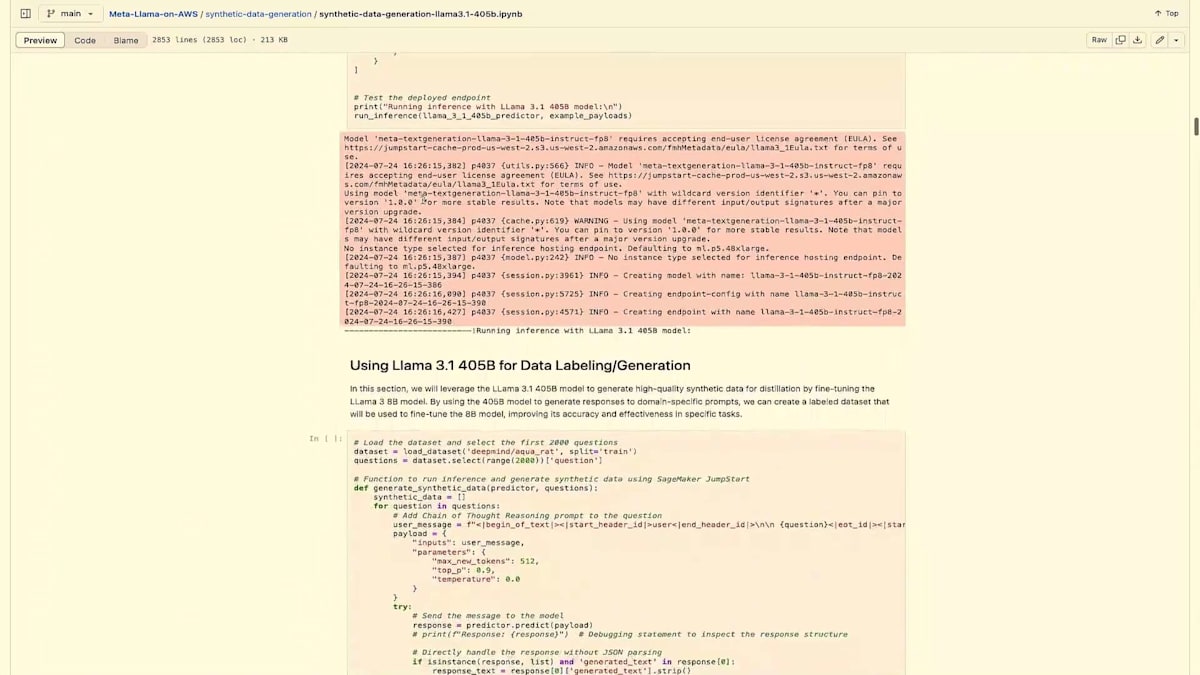
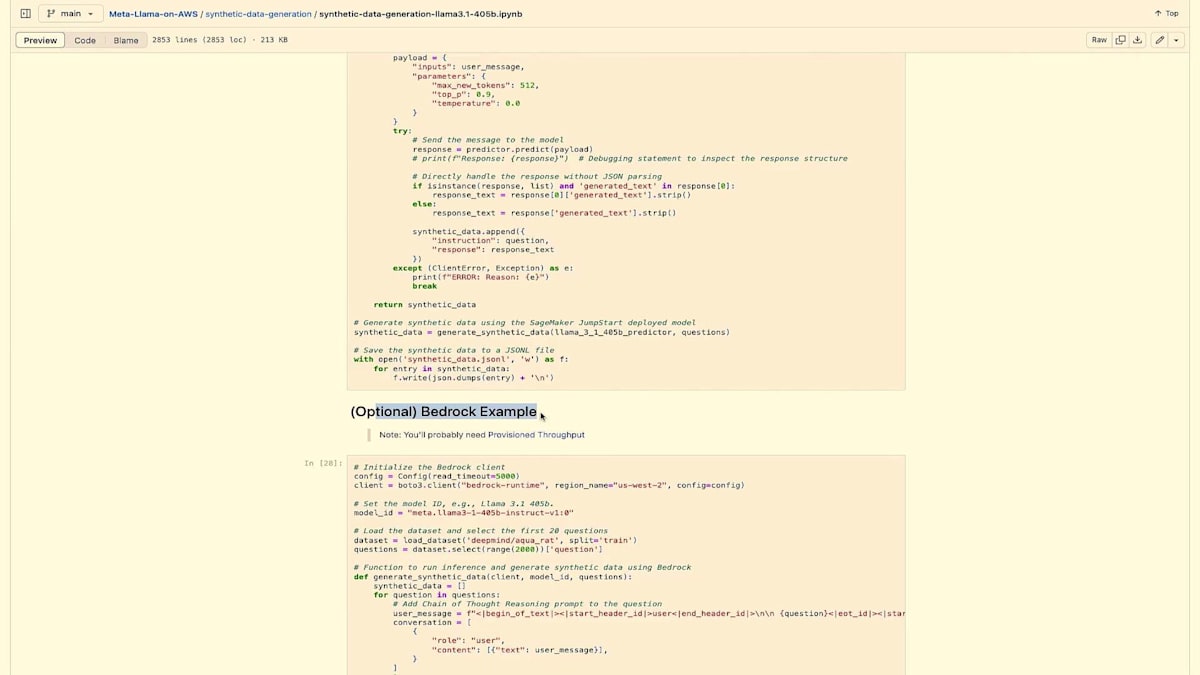
次のセクションでは、405Bモデルをデプロイします。このコードには2つの形式があります。SageMakerでデプロイしていますが、Bedrockでも実行可能で、実際にBedrockで実行するための例も下の方にあります。このように、Bedrockを使用して合成データを作成するためのコードがオプションとして用意されています。これは非常に有利で、SageMakerが多くを抽象化してくれているとはいえ、DevOpsの理解やリソースのスピンアップ方法を知る必要性がなくなり、物事をシンプルにしてくれます。

ここでも、SageMakerでデプロイする場合は、そのインスタンスをデプロイします。その後、合成データを生成しますが、それがこのコードの役割です。そして、そのデータを保存し、基本的にJSONフォーマットで出力します。Bedrock側でも同様の処理が行われます。これらはすべてBedrock Converse APIを使用しており、このようなケースで非常に役立ちます。


次に、当然ながら、405Bから生成したデータをトレーニングジョブのためにS3にアップロードする必要があります。このノートブックでは、SageMakerを使用してトレーニングを行いましたが、もはやその必要はありません。BedrockでLlama 8Bや7Bのトレーニングを行うことができ、これも非常に有利です。繰り返しになりますが、リソースを確保したり、自前でスピンアップしたりする必要がなく、ジョブが完了した後のリソースのコスト消費を心配する必要もありません。それでは、8Bモデルの実際のFine-tuningを開始します。この場合、直接実行しているため、Bedrockの出力ではなく、非常に詳細な出力が表示されます。ここではすべてのEpochが実行され、その出力が表示されています。先に進むために少しスクロールしていきましょう。これで完了です。



さて、これで完了です。8Bモデルのトレーニングを終え、Fine-tuningも完了したので、このセクションでモデルのデプロイに進みたいと思います。 この時点で、405Bモデルの出力によって学習させた8B Fine-tunedモデルをデプロイしました。 そして今、Fine-tuningの効果を明確に示す、見やすい表が用意できています。ご覧いただけるように、左の列に質問が定義されており、 3番目の列にFine-tuning済みモデルの出力、最後の列にFine-tuningしていないモデルの出力が表示されています。
ここで結論を簡単にまとめさせていただきます。その多くはReusも触れていましたが、Fine-tuningによってモデルのパフォーマンスと精度を明らかに向上させることができ、どのようなユースケースにも適応させることが可能です。さらに、計算リソースの面でも多くの利点があります。トークン使用量の削減、つまりコスト面でのメリットもその一つです。私のパートはここまでとさせていただきます。これで発表を終わります。私たちは全員しばらくこの部屋に残っていますので、どなたかご質問がありましたら、お気軽に声をかけてお話しください。ありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion