🐸 なぜ今、Agentic Workflowなのか - Graflowの設計思想
🌟 はじめに: AIエージェント時代のワークフローと「理想と現実のギャップ」
LLMの台頭により、システム開発の現場では「AIエージェント」をどのように業務や自社製品に組み込むかが喫緊の関心事となっています。
一方で、いざプロダクション環境でエージェントを動かそうとすると、既存のツールと要件の間に 「理想と現実のギャップ」 を感じることはないでしょうか?
- 「自律的に動くエージェントは魅力的だが、本番環境では挙動を制御したい」
- 「SuperAgentの挙動が不安定なので挙動を把握したい」
- 「多数のエージェントタスクの並列処理やHuman-in-the-Loop(HITL)、長時間走るコストの高いタスクの再開処理(checkpoint/resume)がうまく扱えない」
本記事では、こうした課題意識から開発している新しいオーケストレーションエンジン 「Graflow」 の設計について解説します。
🌊 Agentフレームワークの潮流:SuperAgent型の隆盛
2025年中盤のGoogle ADKの登場あたりから、AI Agentフレームワークの潮流にも大きな変化が起きており、新世代のSuperAgent型フレームワーク が次々と登場し、開発者の注目を集めています:
- Google ADK : Googleが提供する、プログラマブルなエージェント開発フレームワーク
-
Bedrock AgentCore/Strands Agents SDK:
BedrockのAPIをサポートしたエージェント構築フレームワーク。Strandsなどでスーパーエージェントを構築。 - PydanticAI: Pydanticチームによる、型安全性を重視したシンプルなエージェントフレームワーク
- SmolAgents: HuggingFaceによる、軽量で拡張可能なエージェントフレームワーク
- OpenAI Agents SDK: OpenAIによるAI Agent構築用のフレームワーク。Swarm を本番運用向けにアップグレードしたもの
これらのフレームワークは、いわゆるスーパーエージェント[1]型の ReActスタイルのツール呼び出し(Reasoning + Acting)や推論ループ(Think-Act-Observe)を効率的に実装することに特化しています。
🎯 Graflowのアプローチ: Agentic Workflow(Type B)
AIワークフローは自律性の度合いで3つに分類されます:
- Type A: 決定的ワークフロー(従来型ETL、RPA)
- Type B: Agentic Workflow(構造化フロー + エージェント自律性)
- Type C: SuperAgent(完全自律エージェント)
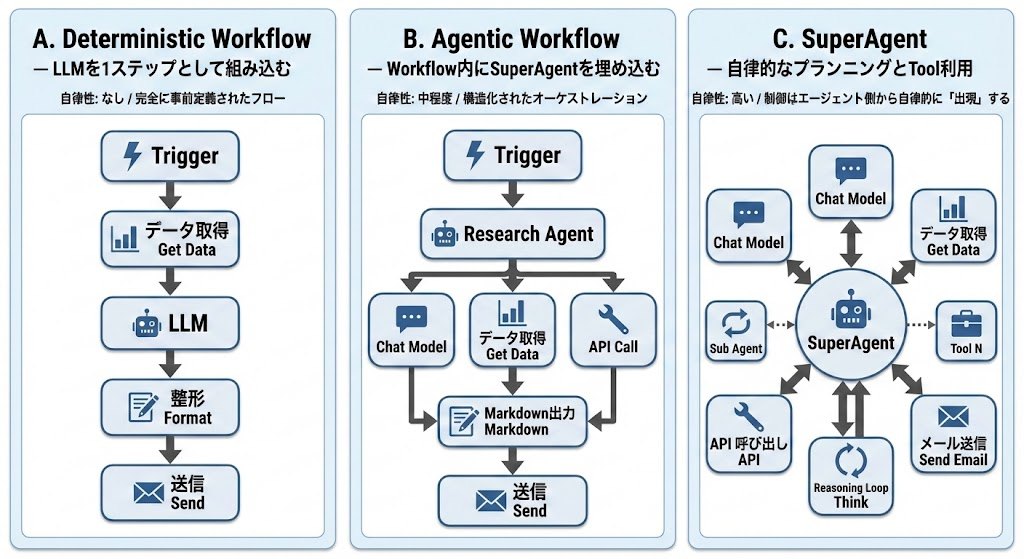
完全自律型(Type C)は魅力的ですが、プロダクション環境では制御の難しさ、コスト肥大化、品質保証の欠如という課題があります。プロンプトによるLLMの制御は、指示通りに動作するとは限りません。
Type Bは構造化オーケストレーションと局所的自律性のバランスをとった 「制御された自律性」 を実現しているアプローチと言えます。
- 構造化オーケストレーション: 全体フローは人間が設計
- 局所的自律性(Fatな自立ノード): 各タスク内部でエージェントが自律的に動作
そこでGraflowでは 柔軟性と制御性のバランスこそ、実務でAIを使いこなす最適解と考え、Type BのAgentic Workflow に特化することを選択しました[2]。
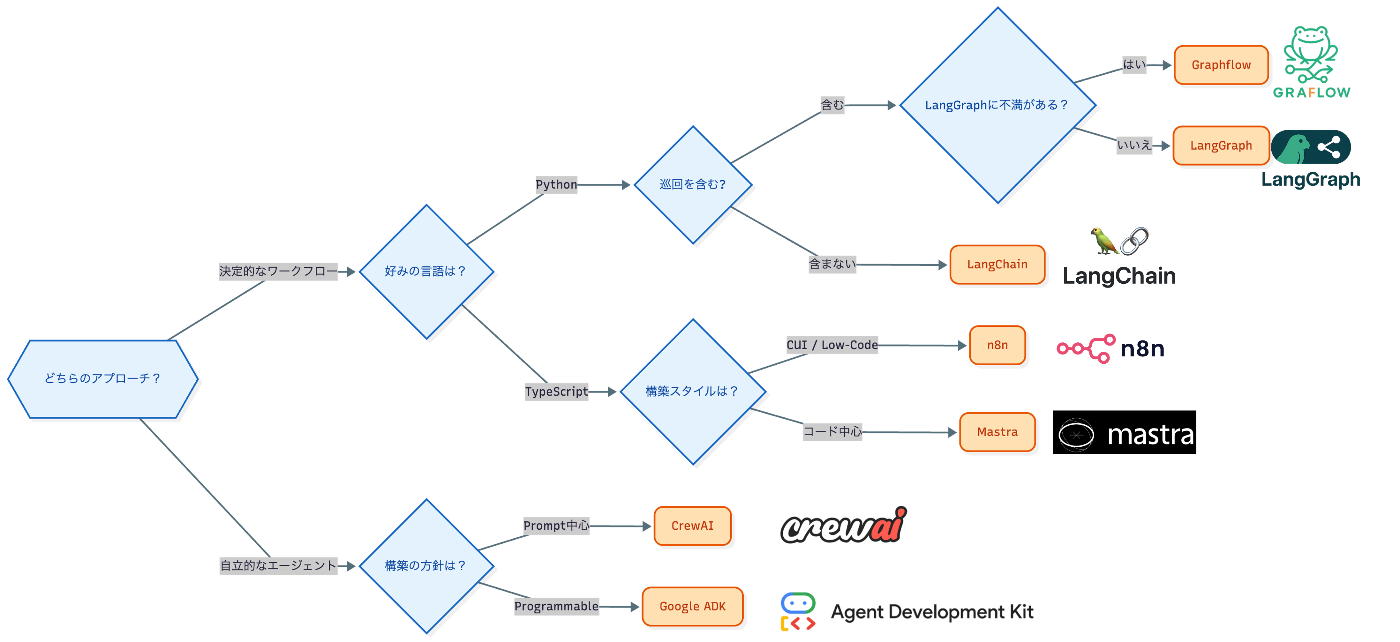
既存ツールと比較したGraflowのポジショニング
既存ツールと比較したGraflowのポジショニングを決定木で表すと次のとおりです。私自身もそうですが、Agentic Workflowを現実解として捉え、柔軟性の高い低レベルのワークフローライブラリとしてのLangGraphに元々シンパシーを感じていている方や、LangChain→LangGraphで複雑化に疑問を持ったりついていけなかった方に特に響くツールになっているかと思います。
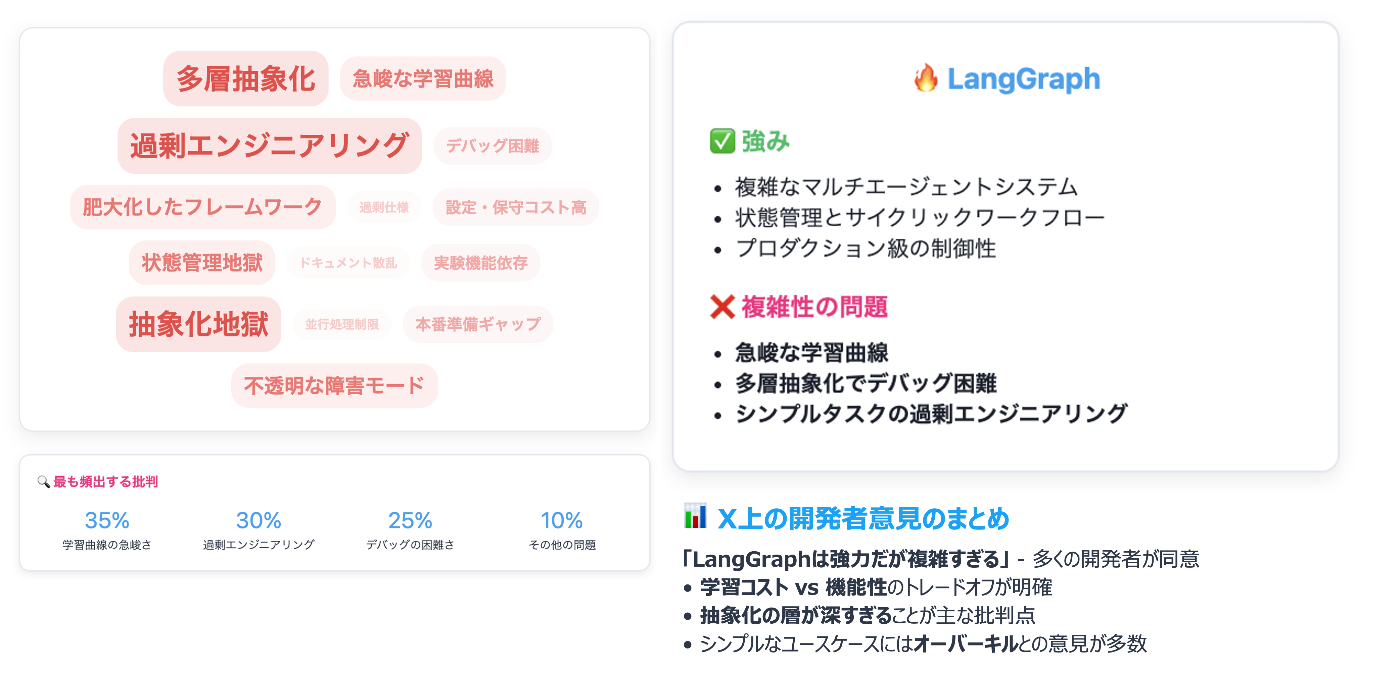
以下はGrokを用いてLangGraphについての開発者の意見をまとめたものですが、急峻な学習曲線、抽象化の層が深すぎて複雑といった意見が多かったです(Grokでさらに深掘り。身近な開発者も同じような見解)。LangGraphは、開発の早い段階から公開されたことでv1.0になるまでAPIが安定せずに、ドキュメントがoutdatedになってしまったり、API互換性が崩れたりして不評を招いた部分もあるので、Graflowでも気をつけているところです[3]。
🔧 Graflowが解決する実務課題
冒頭で挙げた課題に対して、Graflowはどう答えるのか。具体的に見ていきます。
ここでは、LangGraphのアプローチと比較して、実際のコードを交え、設計の背景を説明します。
💡 課題1: エージェント内部の推論ループまでグラフ化すると、可読性・保守性が悪くなる
✅ Graflowスタイル: SuperエージェントはFatノード
Graflowのアプローチでは、スーパーエージェント内部をタスクグラフで表現するLangGraphなどとは異なり、スーパーエージェントを Fatノードとして扱い、ワークフローの「タスク間の連携」に集中するアプローチを取っています。
その上で、SuperAgentにはGoogle ADK等の既存のSuperAgent系のライブラリをラップして利用できるようにしています[4]。
SuperAgentの実装にGoogle ADKを利用する際の利用イメージは以下のとおりです。
# ADK LlmAgent を作成
from google.adk.agents import LlmAgent
adk_agent = LlmAgent(
name="supervisor",
model="gemini-2.0-flash-exp",
tools=[search_tool, calculator_tool],
sub_agents=[analyst_agent, writer_agent]
)
# Graflow でラップ
from graflow.llm.agents.adk_agent import AdkLLMAgent
agent = AdkLLMAgent(adk_agent)
# ExecutionContext に登録
context.register_llm_agent("supervisor", agent)
# タスクで使用(inject_llm_agentで依存性注入)
@task(inject_llm_agent="supervisor")
def supervise_task(agent: LLMAgent, query: str) -> str:
result = agent.run(query)
return result["output"]
フレームワークに縛られない: Graflowはワークフローに特化しているので、Google ADK、PydanticAI、SmolAgents…どのフレームワークで作ったエージェントも、タスクとしてラップすれば同じワークフローで使えるという利点があります。
LangGraphの戦略: SuperAgentもワークフローも自前実装(フルスタック型)
一方、LangGraph v1.0は SuperAgentもワークフロー実装も自前で提供するフルスタック型の戦略を取っています。
LangChain v1.0では、LCEL(LangChain Expression Language)が公式ドキュメント上で使われなくなり、時代の潮流に乗るように create_react_agentを中核としたReActエージェント機能 が強化(開発シフト)されました[5]。
from langgraph.prebuilt import create_react_agent
agent = create_react_agent(llm, tools)
# ツール呼び出しなどの依存関係をグラフで表現
LangGraphは従来は「ワークフロー実装の低レベルライブラリ」として位置づけられていたと思いますが、現在では SuperAgent機能(ReAct、Middleware、HumanInTheLoop等)を自前で充実させる方向に向かっています。
戦略の対比: フルスタック vs 責務分離
| LangGraph v1.0 | Graflow | |
|---|---|---|
| 戦略 | フルスタック型 | 責務分離型 |
| SuperAgent | 自前実装(create_react_agent) | 外部フレームワークに委譲(ADK、PydanticAI等) |
| ワークフロー | グラフベース(SuperAgentもグラフ化) | グラフベース(Agentic Workflow特化) |
| 利点 | 統一された実装体験 | 各領域のベストツールを活用可能 |
Graflowは 「Agentic Workflowが重要、SuperAgent部分は専門フレームワークに任せる」 という戦略を取り、ワークフローオーケストレーションに集中しています。この理由として、Tool呼び出しようなノード間の依存関係(必ずしも呼び出されない)と、タスクの呼び出し関係を同一のタスクグラフで表現することに疑問を感じるからでもあります。
💡 課題2: 条件分岐とループが事前定義必須で、実行時の柔軟性が低い
LangGraphでは conditional_edge(条件分岐)やループをコンパイル時に定義する必要があります。実行時にファイル数やデータ量に応じて動的に処理を変更することが困難です。
LangGraphのアプローチ: 事前定義された条件分岐とループ
from langgraph.graph import StateGraph, END
# 条件分岐関数を事前定義
def should_retry(state):
return "retry" if state["score"] < 0.8 else "continue"
# グラフ構築時に全パスを定義
graph = StateGraph(State)
graph.add_node("process", process_fn)
graph.add_node("retry", retry_fn)
graph.add_node("finalize", finalize_fn)
# conditional_edge で分岐を事前定義
graph.add_conditional_edges(
"process",
should_retry, # 条件関数
{
"retry": "retry", # リトライパス
"continue": "finalize" # 正常パス
}
)
# ループもエッジで事前定義
graph.add_edge("retry", "process") # リトライ → 処理に戻る
graph.add_edge("finalize", END)
app = graph.compile() # ここで固定される
制約:
- すべての分岐パスを事前にグラフで定義する必要がある
- 実行時に判明する条件(ファイル数、データサイズ等)への柔軟な対応が困難
- ループ回数や終了条件を動的に変更できない
- 実装がややこしくなりがち
Graflowのアプローチ: 実行時の動的制御
このようなLangGraphを使っていての不満から、Graflowは動的なタスク生成と実行時のタスクグラフの動的な構成により、ユーザタスク内で条件分岐を書く方がよりシンプルだと考え、以下のような設計を取りました。
@task(inject_context=True)
def process_data(context: TaskExecutionContext):
result = run_processing()
# 実行時にスコアを見て判断
if result.score < 0.8:
# リトライが必要 → 自分自身を再度実行
context.next_iteration()
else:
# 次のタスクへ進む(通常フロー)
context.next_task(finalize_task())
@task(inject_context=True)
def process_directory(context: TaskExecutionContext):
files = list_files() # 実行時にファイル数が判明
# ファイル数に応じてタスクを動的生成
for file in files:
# 事前にグラフを定義する必要なし
context.next_task(process_file(file))
@task(inject_context=True)
def adaptive_processing(context: TaskExecutionContext):
data_quality = check_quality()
# データ品質に応じて異なるタスクを実行時に決定
if data_quality < 0.5:
context.next_task(cleanup_task())
elif data_quality > 0.9:
context.next_task(enhance_task())
else:
context.next_task(standard_task())
# Gotoパターン: 既存タスクへのジャンプ(早期脱出)
@task(inject_context=True)
def error_handler(context: TaskExecutionContext):
try:
risky_operation()
except CriticalError:
# 緊急時は既存の緊急処理タスクにジャンプ
# 後続タスクをスキップして直接ジャンプ
emergency_task = context.graph.get_node("emergency_handler")
context.next_task(emergency_task, goto=True)
柔軟性:
- ✅ 実行時に条件を評価して次のアクションを決定
- ✅ ファイル数やデータ量に応じて動的にタスクを生成
- ✅ ループ回数や終了条件を実行時に変更可能
- ✅ 既存タスクへのジャンプ(
goto=True)で後続タスクをスキップ - ✅ 早期終了(
terminate_workflow())や異常終了(cancel_workflow())も可能
Gotoパターンの特徴:
- 通常の
next_task()は新しいタスクを追加し、後続タスクも実行される -
goto=Trueを指定すると、既存タスクに直接ジャンプし、後続タスクをスキップ - エラーハンドリング、緊急処理、ワークフローの早期脱出に有効
応用例:
- LLMの回答品質で分岐(スコアが低ければ再生成ループ)
- データ品質に応じてクリーンアップタスクを追加
- エラー時にリトライタスクを自動生成
- 処理対象が1000件なら並列タスクを動的生成
- 致命的エラー発生時に緊急処理タスクへ直接ジャンプ(
goto=True)
💡 課題3: 長時間ワークフローが途中で落ちたら最初から
LangGraphのcheckpointは自動のみで、任意タイミングでの保存ができません。
長時間のMLトレーニングやデータ処理では、重要なポイントで明示的に状態を保存したいニーズがあります。
Graflowの解決策: ユーザー制御のcheckpoint/resume
チェックポイントの作成には実行時のオーバヘッドもかかるため、Graflowではユーザがタスクの中でcheckpointの作成を制御するというアプローチを取っています。保存先のパスには"s3://"のようなs3のパスかローカルファイルシステムのディレクトリを指定します。
@task(inject_context=True)
def train_model(context):
for epoch in range(100):
train_one_epoch(epoch)
if epoch % 10 == 0:
# 重要なポイントで明示的に保存
context.checkpoint(path="/tmp/my_checkpoint_1211",metadata={"epoch": epoch})
# 再開
CheckpointManager.resume_from_checkpoint("/tmp/my_checkpoint_1211")
結果: 90エポック目で落ちても、90エポック目から再開。無駄な再計算なし。
💡 課題4: 承認待ちで数時間待てない
Graflowの解決策: Human-in-the-Loop (HITL) とcheckpointの組み合わせ
Graflowでは、context.request_feedback()の呼び出しによってHuman-in-the-loopを実現可能です。
@task(inject_context=True)
def request_deployment_approval(context):
response = context.request_feedback(
feedback_type="approval",
prompt="本番環境へのデプロイを承認しますか?",
timeout=300, # 5分待機
notification_config={
"type": "webhook",
"url": "https://hooks.slack.com/services/XXX",
"message": "承認が必要です"
}
)
if not response.approved:
context.cancel_workflow("承認が拒否されました")
この際、人間のフィードバックはすぐには帰ってこないことも想定されますが、その間、プロセスが待機状態になってしまうのは非効率的です。そこで、HITLにはtimeoutを設定可能とし、timeoutした際にはcheckpointが作成されるようになっています[6]。チェックポイントのBackendとしてはローカルファイルシステム(jsonで保存、PoC向け)かRedis(本格運用向け)をサポートしています。
動作:
- 5分以内に承認 → そのまま続行
- 5分経過 → 自動でcheckpoint保存
- 数時間後に承認API経由で承認 → checkpointから再開
シーケンス図で表すと次のような流れになります。
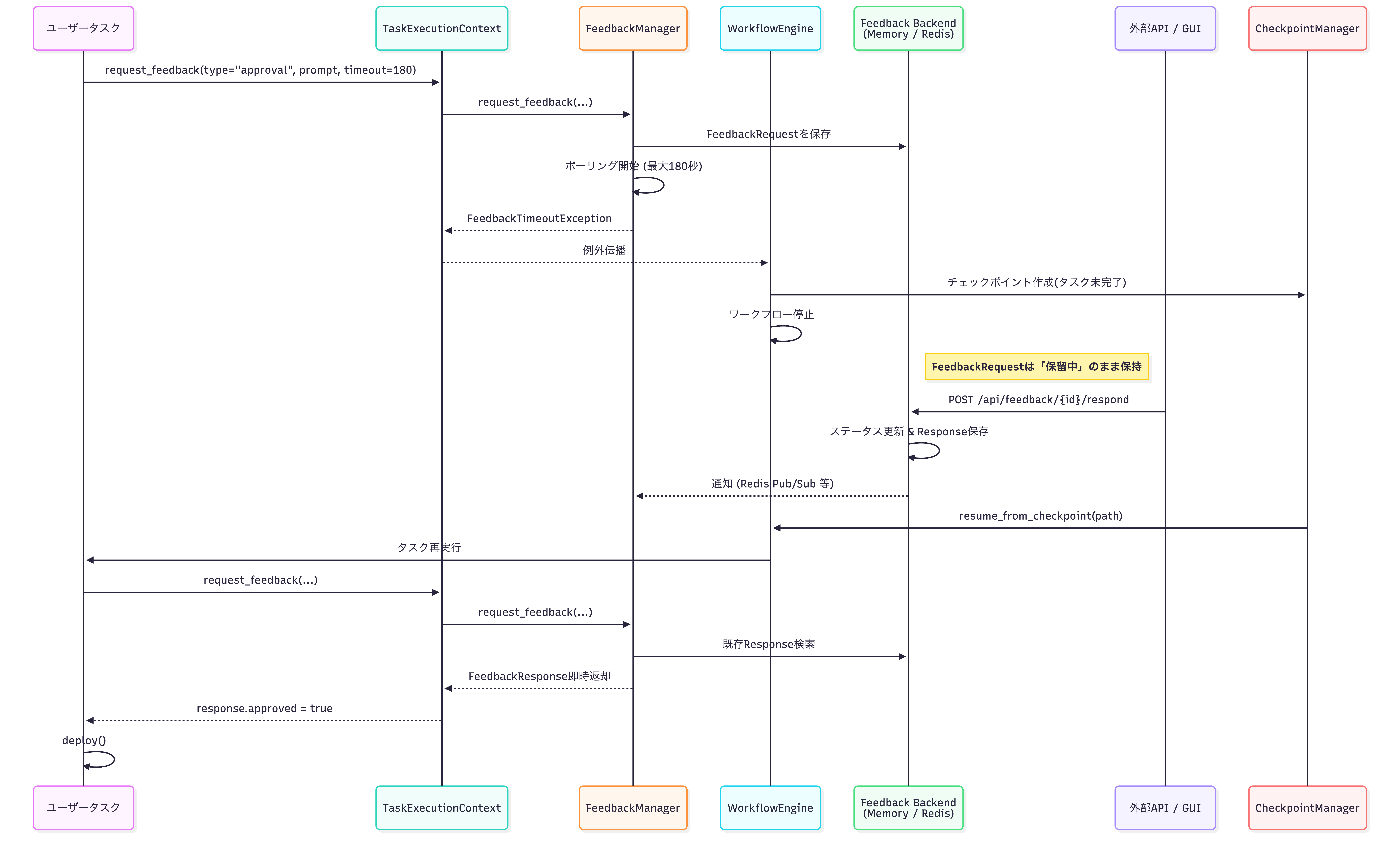
HITLのフィードバックはAPIか、それをwrapしたUIから可能です。approval/text/selection/multi selection/customのフィードバックタイプをサポート。

💡 課題5: タスクの並列処理とワーカーの水平スケールができない
実務では、数百〜数千のAgentに並列処理したいニーズがあります。例えば、「1000件の画像を並列処理」「複数リージョンのデータを同時集計」「異なるLLMモデルとコンテキストの組み合わせで並列処理」といったシナリオです。
Graflowの解決策: Redisベースの分散ワーカー実行
Graflowは分散実行アーキテクチャを採用しており[7]、タスクワーカーを水平スケール可能です(デフォルトではノード内のスレッド実行となります)。
以下のようにタスクワーカーを複数起動するだけで、並列処理が可能になります:
# Terminal 1
python -m graflow.worker.main --worker-id worker-1 --redis-host localhost
# Terminal 2
python -m graflow.worker.main --worker-id worker-2 --redis-host localhost
# Terminal 3
python -m graflow.worker.main --worker-id worker-3 --redis-host localhost
ワークフロー側は、ローカル実行から分散実行への切り替えが1行で可能:
# ローカル実行 → 分散実行を1行で切り替え
parallel = (task_a | task_b | task_c).with_execution(
backend=CoordinationBackend.REDIS,
backend_config={"redis_client": redis_client}
)
結果:
- Kubernetes環境: HPA(Horizontal Pod Autoscaler)でRedisキューの残タスク数に基づきワーカーPod数を自動調整
- ECS環境: タスク数ベースのAuto Scalingで同様の仕組みを実現
- 並列度: ワーカー数 × 同時実行タスク数で柔軟にスケール
シンプルなAPIで、分散実行と水平スケーリングを実現しています。
🎁 その他の重要機能
Graflowには、上記で紹介した課題解決機能に加えて、実務で役立つ独自機能が組み込まれています。
🤖 軽量なLLM統合: inject_llm_client
SuperAgentを使わない、よりシンプルなLLM呼び出しには inject_llm_client を使います。タスク内で直接LLM APIを呼び出し、複数のモデルを使い分けることも可能です。
# LLMClient を ExecutionContext に登録
from graflow.llm.client import LLMClient
context.register_llm_client(LLMClient())
# タスク内で複数モデルを使い分け
@task(inject_llm_client=True, inject_context=True)
def multi_model_task(llm: LLMClient, context: TaskExecutionContext) -> dict:
"""タスク内で複数のモデルを使い分け"""
# チャンネルからデータを取得
channel = context.get_channel()
text = channel.get("input_text")
# 簡単なタスクは低コストモデル
summary = llm.completion_text(
[{"role": "user", "content": f"Summarize: {text}"}],
model="gpt-4o-mini"
)
# 複雑な推論は高性能モデル
analysis = llm.completion_text(
[{"role": "user", "content": f"Analyze deeply: {text}"}],
model="claude-3-5-sonnet-20241022"
)
# 結果をチャンネルに保存
result = {"summary": summary, "analysis": analysis}
channel.set("analysis_result", result)
return result
inject_llm_client の利点:
- ✅ シンプル: ReActループ不要、直接API呼び出し
- ✅ 柔軟なモデル選択: タスク内で用途に応じてモデルを切り替え可能
- ✅ コスト最適化: 簡単なタスクは低コストモデル、複雑なタスクは高性能モデル
- ✅ マルチプロバイダー: LiteLLM統合により、OpenAI、Anthropic Claude、Bedrock、Gemini、Azureなどを統一APIで利用。Ollama経由でgpt-ossも利用可能。
使い分けの指針:
- SuperAgent(inject_llm_agent): ツール呼び出しを伴う複雑な推論タスク、マルチターン対話
- LLMClient(inject_llm_client): 単発のLLM呼び出し、プロンプトベースのシンプルな処理
📝 Pythonic演算子DSL: DAG × State Machineのハイブリッド設計
Graflowは演算子オーバーロード(>>、|)を使って、DAGとループを数学的・直感的に記述できます。
ハイブリッド設計の核心
Graflowは 「DAG × State Machine のハイブリッド」 という独自のアプローチを採用しています:
-
DAG部分(静的構造): 演算子(
>>、|)でタスクグラフの骨格を定義 -
State Machine部分(動的遷移):
next_task()、next_iteration()で実行時に状態遷移
この2つの組み合わせにより、静的な可読性と動的な柔軟性を両立しています。
with workflow("etl_pipeline") as wf:
# DAG部分: 演算子で静的な構造を定義
# 直列実行: >>
fetch >> transform >> load
# 並列実行: |
(transform_a | transform_b | transform_c) >> merge
# 複雑なフロー
fetch >> (validate | enrich) >> process >> (save_db | save_cache)
# State Machine部分: タスク内で動的に遷移
@task(inject_context=True)
def adaptive_task(context: TaskExecutionContext):
result = process_data()
# 実行時に次の状態を決定(State Machineのように)
if result.needs_retry:
context.next_iteration() # 自己ループ
elif result.quality > 0.9:
context.next_task(premium_task()) # 動的分岐
else:
context.next_task(standard_task()) # 別の動的分岐
LangChain/LangGraphとの違い:
- LangChain: 巡回を含まないDAGのみ(State Machine不可)
-
LangGraph: StateGraphで巡回をサポートするが、
add_node、add_edge、add_conditional_edgesで全パスを事前定義 - Graflow: 演算子でDAG骨格 + 実行時動的遷移のハイブリッド
# LangGraph
graph = StateGraph(...)
graph.add_node("fetch", fetch_fn)
graph.add_node("transform", transform_fn)
graph.add_edge("fetch", "transform") # エッジを貼っていく表現が面倒
# Graflow
fetch >> transform
関数スタイルの代替記法: chain() と parallel()
演算子が読みにくい場合や、動的にタスクリストを構築する場合に便利な関数も提供しています。
from graflow.core.task import chain, parallel
# 演算子スタイル
fetch >> transform >> load
# 関数スタイル(同じ意味)
chain(fetch, transform, load)
# 並列実行も同様
# 演算子スタイル
task_a | task_b | task_c
# 関数スタイル(同じ意味)
parallel(task_a, task_b, task_c)
# 動的なタスクリスト構築に便利
tasks = [create_task(i) for i in range(10)]
parallel(*tasks) # 10個のタスクを並列実行
使い分けの指針:
-
演算子スタイル(
>>、|): 静的な構造を視覚的に表現したい場合 -
関数スタイル(
chain()、parallel()): 動的にタスクリストを構築する場合、可読性を重視する場合
なお、State Machine内部の実行ループを簡略化すると以下のようになります。
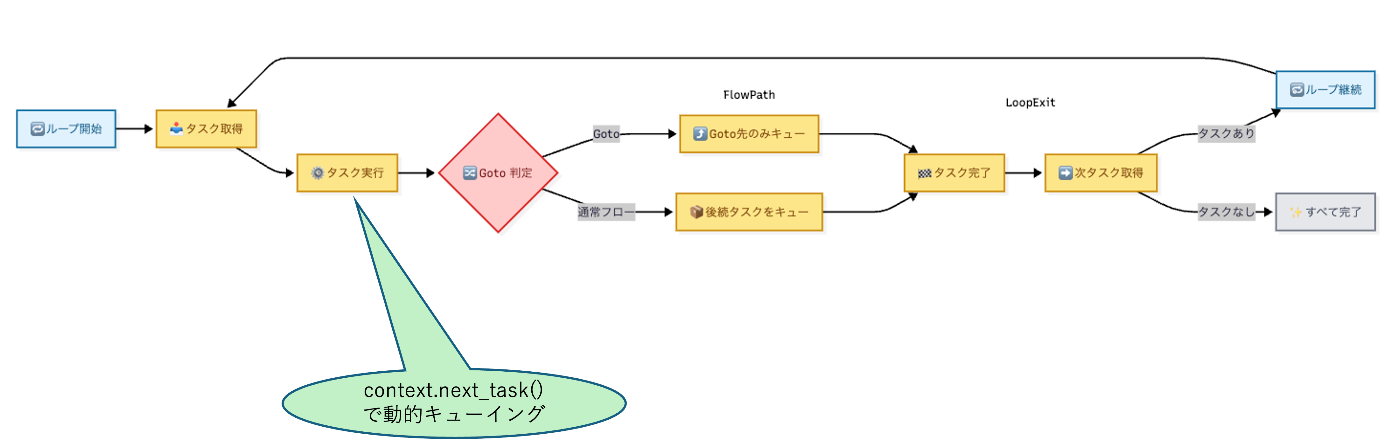
🐳 プラグ可能タスクハンドラー: Docker実行を標準装備
タスクごとに実行戦略(ハンドラー)を切り替えられます。Docker実行は標準装備で、依存関係の隔離やサンドボックス実行(LLMによって生成されたコードを後続タスクで安全に実行)が可能です。
@task(handler="docker", handler_kwargs={
"image": "pytorch/pytorch:2.0-gpu",
"gpu": True,
"volumes": {"/data": "/workspace/data"},
})
def train_on_gpu():
# Dockerコンテナ内でGPU実行
return train_model()
ハンドラーの種類:
-
direct: プロセス内実行(デフォルト) -
docker: コンテナ実行(GPU、依存関係隔離) - カスタム: クラウド実行(cloud-run)、リモート実行など自由に実装可能
📡 チャンネル通信: タスク間のステート共有
ワークフロー全体で共有される名前空間付きKey-Valueストア(Channel)により、タスク間で柔軟にデータをやり取りできます。
@task(inject_context=True)
def task_a(context):
channel = context.get_channel()
channel.set("user_id", "user_12345")
channel.set("session_data", {"score": 0.95})
@task(inject_context=True)
def task_b(context):
channel = context.get_channel()
user_id = channel.get("user_id") # "user_12345"
score = channel.get("session_data")["score"] # 0.95
# チャンネルを更新
channel.set("processed", True)
バックエンドの選択: メモリとRedis
Channelは2つのバックエンドをサポートし、ローカル実行と分散実行をシームレスに切り替えられます。Apache AirflowのXComのようなコンセプトになります。
MemoryChannel(デフォルト): ローカル実行向け
- ✅ 高速: メモリ内で完結、レイテンシ最小
- ✅ シンプル: 追加インフラ不要
- ✅ チェックポイント対応: checkpoint時に自動保存
- ⚠️ 制約: 単一プロセス内のみ有効
RedisChannel: 分散実行向け
- ✅ 分散対応: 複数ワーカー・複数マシン間でステート共有
- ✅ 永続性: Redisの永続化機能で障害耐性向上
- ✅ スケーラブル: 大量のワーカーでもデータ一貫性を保持
- ⚠️ 要インフラ: Redis サーバーが必要
型安全なデータ交換: TypedChannel
大規模開発やチーム開発では、タスク間のデータ構造を明確にすることが重要です。GraflowはTypedChannelにより、コンパイル時の型チェックとIDEの自動補完を実現します。
from typing import TypedDict
# メッセージスキーマを定義
class UserProfile(TypedDict):
"""ユーザープロファイル情報"""
user_id: str
name: str
email: str
age: int
@task(inject_context=True)
def collect_user_data(context):
# 型安全なチャンネルを取得
profile_channel = context.get_typed_channel(UserProfile)
# IDEが自動補完してくれる
user_profile: UserProfile = {
"user_id": "user_123",
"name": "Alice",
"email": "alice@example.com",
"age": 30
}
profile_channel.set("current_user", user_profile)
TypedChannelの利点:
- ✅ コンパイル時型チェック: mypyやpyrightで型エラーを事前検出
- ✅ IDEの自動補完: フィールド名や型をIDEが補完
- ✅ 自己文書化: TypedDictがAPI契約として機能
- ✅ リファクタリング安全性: フィールド名変更時にIDEが全箇所を検出
- ✅ チーム開発: 共有スキーマで認識齟齬を防止
オンメモリのTypedDictをタスク間で共有するLangGraphとは異なり、Redisを利用できるので、メモリに載せるには大きなデータも保管可能です。
⚙️ 並列グループの細粒度エラーポリシー: 柔軟な障害制御
並列タスク実行時、すべてのエラーが同じ重要度とは限りません。Graflowは並列グループ単位で柔軟にエラーハンドリングポリシーを設定でき、ビジネス要件に応じた細かい制御が可能です。
4つの組み込みポリシー
1. Strict Mode(デフォルト): すべてのタスクが成功必須
parallel = (task_a | task_b | task_c).with_execution(
backend=CoordinationBackend.THREADING # デフォルトでstrict mode(明示的にpolicy指定不要)
)
- 適用例: 金融取引、セキュリティ操作、データ検証パイプライン
2. Best-effort: 一部失敗しても続行
from graflow.core.handlers.group_policy import BestEffortGroupPolicy
# マルチチャンネル通知(一部失敗しても続行)
notifications = (send_email | send_sms | send_slack).with_execution(
backend=CoordinationBackend.THREADING,
policy=BestEffortGroupPolicy() # または policy="best_effort"
)
- 適用例: マルチチャンネル通知、任意のデータ enrichment、オプション分析処理
3. At-least-N: 最小成功数を指定(クォーラムベース)
from graflow.core.handlers.group_policy import AtLeastNGroupPolicy
# 4つのタスク中、最低2つが成功すればOK
parallel = (task_a | task_b | task_c | task_d).with_execution(
backend=CoordinationBackend.THREADING,
policy=AtLeastNGroupPolicy(min_success=2)
)
- 適用例: マルチリージョンデプロイ、冗長データソース、分散コンセンサス
4. Critical Tasks: 重要タスクのみ失敗判定
from graflow.core.handlers.group_policy import CriticalGroupPolicy
# extract_data と validate_schema だけが必須
parallel = (extract_data | validate_schema | enrich_metadata).with_execution(
backend=CoordinationBackend.THREADING,
policy=CriticalGroupPolicy(
critical_task_ids=["extract_data", "validate_schema"]
)
)
# enrich_metadata が失敗してもワークフローは続行
- 適用例: 必須ステップ + オプションステップの混在パイプライン
カスタムポリシーの実装
ドメイン固有のロジックを実装できます:
from graflow.core.handlers.group_policy import GroupExecutionPolicy
from graflow.exceptions import ParallelGroupError
class CustomFailuresPolicy(GroupExecutionPolicy):
def __init__(self, critical_task_ids: list[str], max_failures: int):
self.critical_task_ids = critical_task_ids
self.max_failures = max_failures
def on_group_finished(self, group_id, tasks, results, context):
# 結果の整合性チェック
self._validate_group_results(group_id, tasks, results)
...
# 使用例
parallel = (task_a | task_b | task_c).with_execution(
policy=CustomFailuresPolicy(
critical_task_ids=["task_a"],
max_failures=1
)
)
ポリシーの選択指針
| ポリシー | 適用場面 | 例 |
|---|---|---|
| Strict Mode | すべて成功必須 | 金融取引、重要な業務処理 |
| Best-effort | 部分成功で可 | 通知、分析、任意のエンリッチメント |
| At-least-N | クォーラム/冗長性 | マルチリージョンデプロイ、データソース冗長化 |
| Critical Tasks | 優先度混在 | 必須 + オプションステップの混在パイプライン |
| Custom Policy | ドメイン固有ロジック | 段階的ロールアウト、コンプライアンス要件 |
利点まとめ:
- ✅ ビジネスロジックに合致: ポリシーで業務要件を直接表現
- ✅ 詳細なエラー情報: ParallelGroupError で失敗タスクと成功タスクを把握
- ✅ 拡張可能: カスタムポリシーで複雑なロジックも実装可能
🔍 LangFuse/OpenTelemetryトレーシング: 実行時の可観測性を強化
LLMワークフローでは、「どのタスクがどのLLM呼び出しを行ったか」「エラーがどこで発生したか」を追跡することが重要です。GraflowはLangFuseのOpenTelemetryクライアント を統合し、ワークフロー全体の実行トレースを自動収集します。
トレーシング機能の特徴
- 自動トレース収集: タスク開始/終了、LLM呼び出しを自動記録
- OpenTelemetryコンテキスト伝播: LiteLLMやGoogle ADKのLLM呼び出しを自動的にワークフロートレースに関連付け
- 分散トレーシング: Redis経由の分散実行でも、複数ワーカー間でトレースIDを共有
- ランタイムグラフエクスポート: 実行時のタスク依存関係をグラフとして可視化
基本的な使い方
from graflow.core.workflow import workflow
from graflow.trace.langfuse import LangFuseTracer
# LangFuseトレーサーを初期化
tracer = LangFuseTracer(enable_runtime_graph=True)
with workflow("my_workflow", tracer=tracer) as wf:
search >> analyze >> report
wf.execute("search")
# トレースはLangFuseプラットフォームに自動送信される
OpenTelemetryコンテキスト伝播によるLLM呼び出しの自動リンク
Graflowの強力な機能の一つが、OpenTelemetryコンテキスト伝播による自動トレースリンクです。LiteLLMやGoogle ADKなどのLLMクライアントは、OpenTelemetryコンテキストを検出すると、自動的にGraflowのワークフロートレースに紐づけられます。
動作の仕組み:
- Graflowがタスク開始時にLangFuse spanを作成
- LangFuseTracer が OpenTelemetry コンテキストを設定(trace_id、span_id)
- LiteLLM/ADKがOpenTelemetryコンテキストを検出し、同じtrace_id/span_idでLLM呼び出しを記録
- LangFuseプラットフォームで「ワークフロー → タスク → LLM呼び出し」の階層構造が自動的に表示される

分散実行でのトレーシング
分散ワーカー環境でも、トレースIDが自動的に伝播され、複数ワーカー間で統一されたトレースが構築されます。
ランタイムグラフのエクスポート
実行時のタスク依存関係をグラフとして取得できます。
tracer = LangFuseTracer(enable_runtime_graph=True)
# ワークフロー実行後
runtime_graph = tracer.get_runtime_graph()
# エクスポート(dict/json/graphml形式)
graph_data = tracer.export_runtime_graph(format="json")
利点まとめ:
- ✅ 完全なトレーサビリティ: ワークフロー → タスク → LLM呼び出しの全階層を追跡
- ✅ 自動統合: LiteLLM/ADKの呼び出しを手動でログ記録する必要なし
- ✅ デバッグ効率化: エラーがどのタスクのどのLLM呼び出しで発生したか即座に特定
- ✅ パフォーマンス分析: タスク実行時間、LLMレイテンシ、並列度を可視化
- ✅ OSS: LangFuseをself-hostすれば完全無料で運用可能
📊 課題と解決策まとめ
| 課題 | 既存ツールの課題 | Graflowの解決策 |
|---|---|---|
| グラフ爆発 | エージェント内部までグラフ化 | Fatノード設計(内部ブラックボックス化) |
| 柔軟性不足 | compile()で固定 | 動的タスク生成(runtime fan-out) |
| 長時間処理 | checkpoint自動のみ | ユーザー制御checkpoint/resume |
| 承認フロー | 承認待ち時に実行継続できない | HITL + checkpoint(長時間待機も対応) |
| 並列処理 | 分散実行が困難または複雑 | Redisベース分散ワーカー(Airflow風の水平スケール) |
📰 Agentic Workflowのアプリケーション例: GPT newspaper
Graflowを利用したAgentic Workflow例として、LangGraphで実装されたGPT newspaperをGraflow用に移植して、SuperAgentノードを使うように改変してみました。以下のようなワークフロー構成です。

🚀 OSS公開について
先行ユーザー募集
正式公開前に試してみたい方は、@myui にDMなりでお問い合わせください。
📝 まとめ
Graflowは、プロダクション環境でAIエージェントワークフローを安心して動かすための、新しいオーケストレーションエンジンです。
Graflowの5つのコア価値
- 戦略的シンプルさ: SuperAgent(ReAct等)はADK/PydanticAI等の専門フレームワークに委譲し、ワークフローオーケストレーションに集中
-
実行時の柔軟性:
next_task()による動的タスク生成、next_iteration()によるループ制御、terminate/cancel_workflow()による早期終了 -
開発体験: Pythonic演算子DSL(
>>、|)で直感的にワークフローを記述 - プロダクション対応: checkpoint/resume、分散実行(Airflow風の水平スケール)、HITL、Dockerハンドラー
- 並列分散処理によるスケーリング: ローカル実行→分散実行の切り替えが1行で可能
LangGraph v1.0との戦略的違い
| LangGraph v1.0 | Graflow | |
|---|---|---|
| 方針 | フルスタック(SuperAgent + Workflow) | 責務分離(Workflow特化) |
| SuperAgent | 自前実装(create_react_agent) | 外部委譲(ADK、PydanticAI等) |
| 得意領域 | エージェント内部の推論制御 | タスク間連携・分散実行・HITL |
| 開発哲学 | LangChain エコシステム統合、SuperAgent方面にシフト中 | ベストツール組み合わせ、Agentic Workflow中心 |
2025年1月のOSS公開をどうぞご期待ください。
-
SuperAgentの定義として、ReActのようにツール呼び出しを利用して自立的に動作すること。Subエージェントを定義できるものをSuperAgentと呼んでいます。 ↩︎
-
既存ワークフローツールとの違い: Apache Airflow、Dagster、Temporal、PrefectなどとGraflow/LangGraphは設計思想が異なります。(1) DAG制約: Airflow/Dagsterは非巡回グラフ(DAG)専用で、AIエージェントの推論ループ(リトライ、収束判定等)を表現できません。Temporal/Prefectは巡回をサポートしますが、長時間実行される分散ワークフロー(マイクロサービス間の調整、バッチ処理等)に特化しており、ワークフロー定義を事前に宣言的に記述する必要があります。(2) ワークフローマネジメントシステム vs アプリケーション組み込みライブラリ: Airflow/Dagster/Temporal/Prefectは「ワークフローをスケジュール実行・監視する基盤」であり、Webダッシュボード、スケジューラ、モニタリング機能を持つ重厚なシステムです。一方、LangGraph/Graflowは「アプリケーションに組み込むライブラリ」として設計され、Pythonコードから直接呼び出して実行します。(3) LLMネイティブ設計: Airflow/Dagster/Temporal/Prefectは汎用ワークフローエンジンとして設計されており、LLM統合は後付けです。一方、Graflow/LangGraphはLLMネイティブに設計され、HITL、LLM統合(inject_llm_client/inject_llm_agent)、プロンプトトレーシング、実行時動的タスク生成など、AIワークフロー特有の機能を標準装備しています。 ↩︎
-
アプリで参考にしたgpt-newspaperとかもAPI互換性の問題でかなり古いバージョンのlanggraphでしか動きません。これは早期のリリースで着目を集めるのとトレードオフで仕方ない。開発リソースを最新ブランチに注がざるを得ない。 ↩︎
-
ADKのcontext compressionやcontext caching等もそのまま利用できるという利点があります。Google ADK以外にもBedrock AgentCoreやPydanicAIなどをLLM Agent(SuperAgent)としてサポートする予定です。 ↩︎
-
これだけで分かり!LangChain v1.0 アップデートまとめ(Generative Agents 大嶋さん)に詳しい解説があります。 ↩︎
-
Airflowも同様の分散実行アーキテクチャ(Celery/Kubernetes Executor)を採用しています。詳細はZOZOのテックブログを参照してください。 ↩︎
Discussion