1.はじめに
MTECの鈴木です。本記事では我々が第39回人工知能学会全国大会(JSAI2025)で発表した「独立成分分析を用いた事業リスクの分類および定量化の検討」の内容について解説します。
本記事は前回(前半パート)の続きとなっております。ぜひ前半からご一読ください!
2.分析の流れ
前半パートでも説明していますが、先行研究[1],[2]の方法を用いており、以下の流れで事業リスクの解釈を試みています。後半パートでは抽出した独立成分同士の関連性を解釈する試み([2]を踏襲した分析)について解説します。
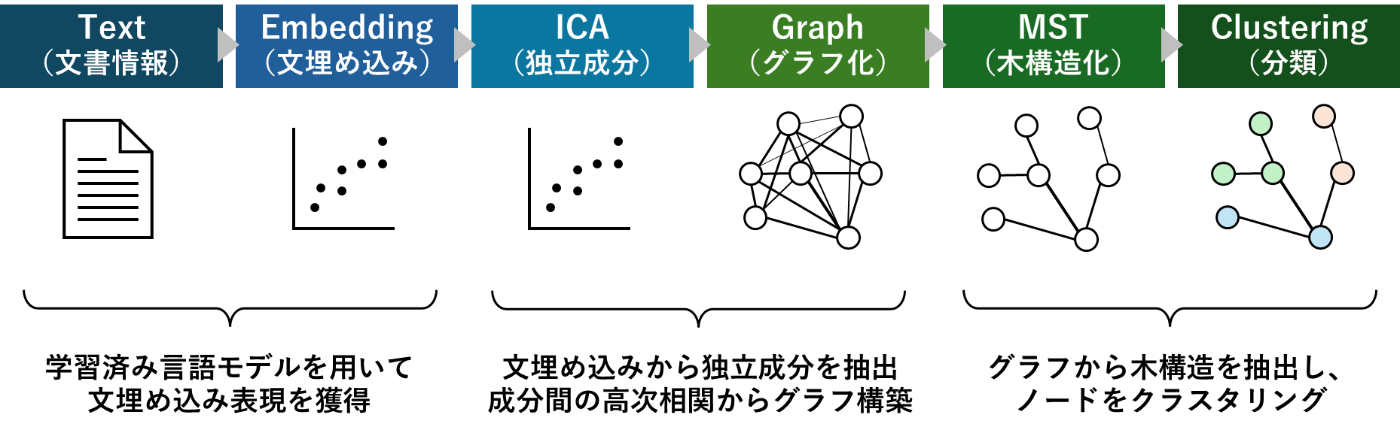
2-1.利用データ&埋め込みモデル
利用データ
前半パートの復習ですが、利用データは2024年3月決算の東証プライム上場銘柄の有価証券報告書を対象としました。事業リスクの文章は EDINETからXBRLで”jpcrp cor:BusinessRisksTextBlock”の項目を取得しています。
利用埋め込みモデル
文埋め込み表現のモデルはpkshatech/GLuCoSE-base-jaを利用しました。GLuCoSEはMaxトークン数が512で、出力される埋め込み次元は768次元となっています。Maxトークンを超える場合はテキストをMaxトークンごとに分割し、各分割ごとに埋め込み表現を獲得してそれを平均化しています。
2-2.独立成分間のネットワーク構築
[2]によると、埋め込み表現から抽出した独立成分同士には高次相関が存在することが知られています。その高次相関を独立成分間の繋がり(エッジ)と考えてグラフを構築し、最大全域木 (Maximum Spanning Tree, MST)を抽出します。全域木とは、グラフを木構造に(=ループが無いようにエッジを削減)しているもので、特に繋がりが強いものを残すようにしています。
実装は、NetworkXのmaximum_spanning_tree関数を利用しました。
2-3.独立成分同士のクラスタリング
構築した最大全域木をベースに独立成分のクラスタリングを考えます。グラフに対するクラスタリングなので、Spectral Clusteringという手法を利用しています。理論的な話などは下記の資料がまとまっていますのでご参照ください。
実装は、Scikit-learnのSpectralClustering関数を利用しました。
3.試算結果
ここからは前半パートで計算していた独立成分のスコアを使って計算を行っています。まず2次相関を見てみると、[2]と同様にいくつかの独立成分間で相関が高いことが見て取れます。
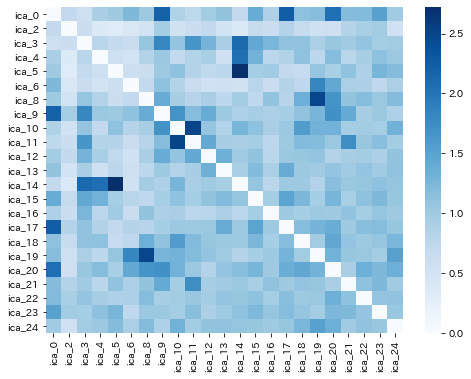
この2次相関を独立成分(ノード)間の繋がり(エッジ)としてネットワークを構築し、そこから最大全域木を抽出します。さらにSpectral Clusteringによってクラスタリング(※今回はクラスタ数を5と設定)を行います。クラスタリングの結果、前回の各独立成分の解釈と併せて、各クラスタについて以下のように解釈が出来ました。
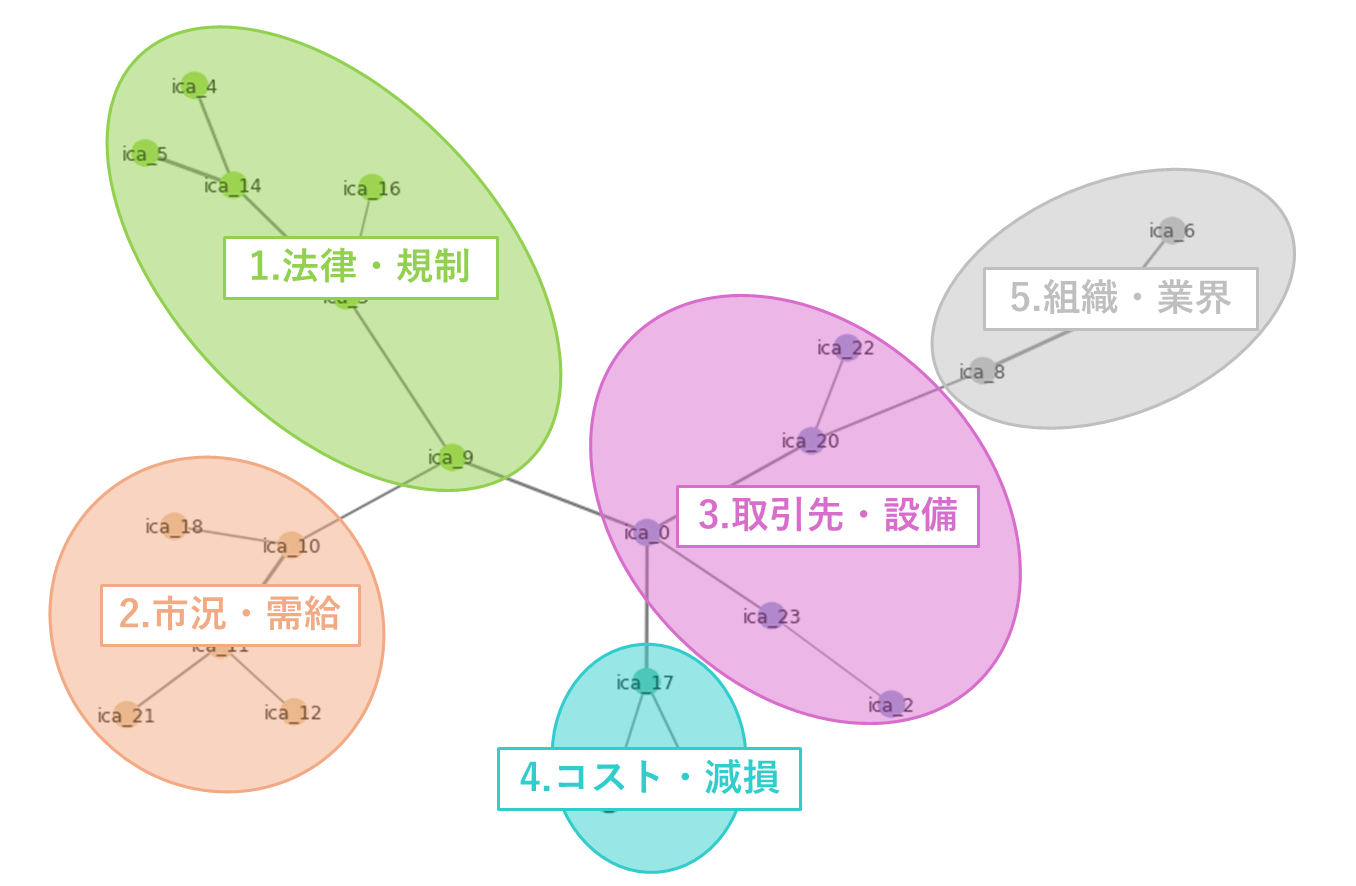
この解釈を前提として、[2]と同じようにそのクラスタ間の定性的な関係性について考えてみます。例えば「1. 法律・規制」と「2. 市況・需給」のクラスタ間には規制変更による市況変化といった関係や、「3. 取引先・設備」と「4. コスト・減損」のクラスタ間には取引先の値上げ圧力や破綻による財務の悪化といった関係が想像できます。つまり、MSTとSpectral Clusteringによって事業リスク間の関係性について納得感のある結果がデータドリブンに抽出できていることが見て取れています。
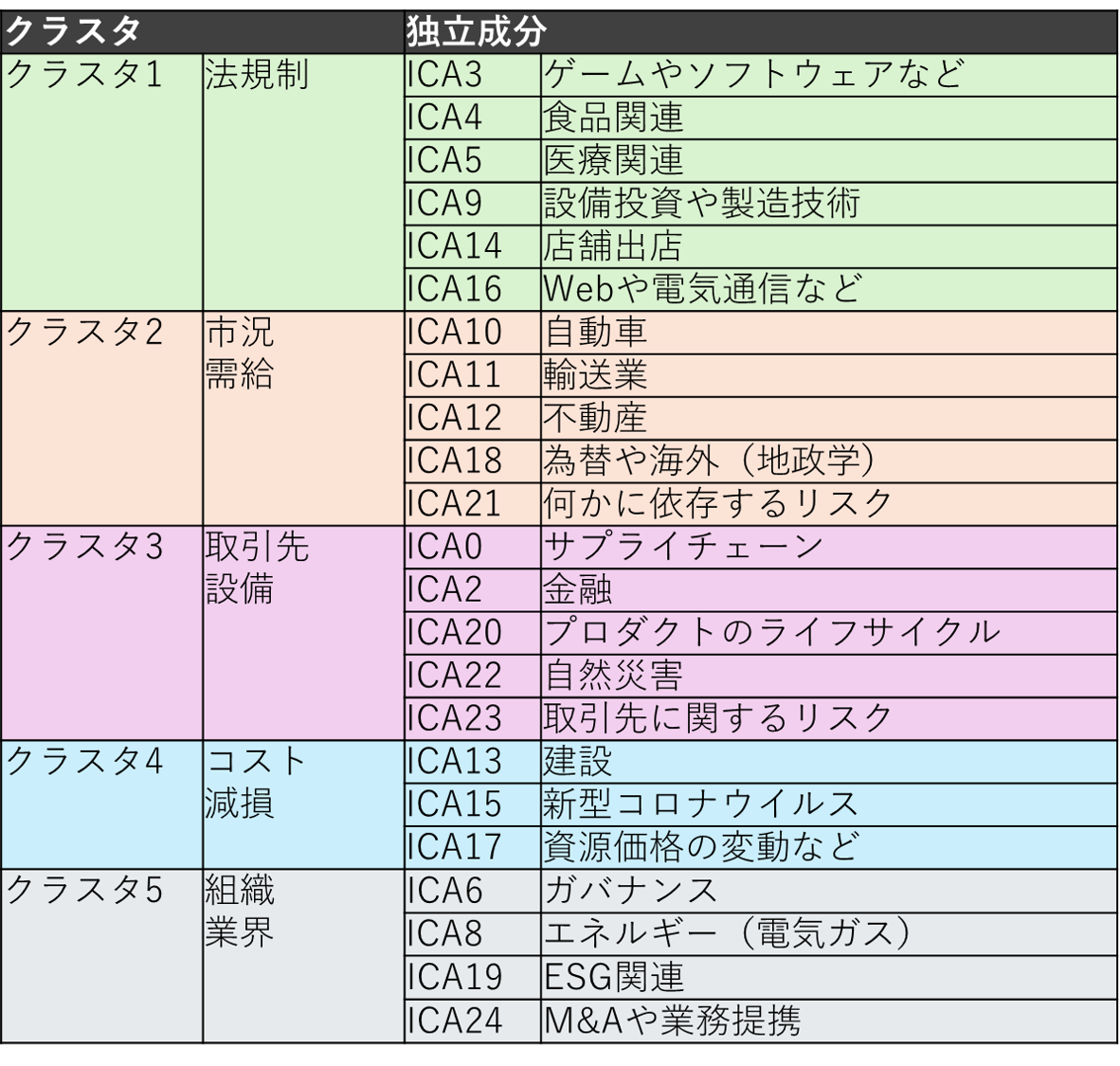
今一度、分析結果における独立成分およびそのクラスタの一覧について記載しておきます。
4.今後の展望
今回の分析では、独立成分の数やクラスタ数は決めの問題で行っており、さらにその解釈も人(主観)で行っています。独立成分の妥当な数は主成分分析でいう累積寄与率みたなものを定義して定量的な観点で決定できると良いな、と考えております。何か名案があれば是非教えていただけるとありがたいです!
また、独立成分やそのクラスタの解釈自体は、大規模言語モデルを使ってうまくやれないか?と考えています。例えば類似した独立成分分析に関する先行研究[3]ではGPT-4を使って独立成分のカテゴリを命名しています。
また、この分析は2024年3月時点でのクロスセクションで行っています。すなわち、異なる時点間で独立成分の平仄が取れなくなることが課題として考えられます。例えば、2025年3月時点で新しく計算しなおした場合、2024年3月におけるICA2に対応する独立成分はどれに該当するかが分からなかったり、新型コロナウイルスなど未知の新しいリスクが顕在化した場合は、新たな軸が生成されて既存の軸との整合性が取れなくなる、といったことになり得るかと思います。もし、継続的にモニタリングをしていく場合はこのあたりのケアが必要になります。
5.おわりに
前半と後半の2回にわたって、事業リスクを独立成分分析で解釈する試みについて説明させていただきました。埋め込みモデルを使うことでテキスト情報を定量化し、そこから情報を抽出することで事業リスクについて比較的うまく整理することができ、個人的には非常に興味深い結果となりました。また、企業ごとに独立成分スコアがついている、すなわちどういったカテゴリやクラスタの事業リスクが大きいかが定量化できているため、定量的なリスク管理などへの応用にも使えると面白いな、とひそかに考えております(このあたりも是非色々とご意見をいただければと思います)。
MTECではこの他にも色々と金融におけるテキスト情報を用いた分析や研究を行っています。
これまでの活動一覧については、以下のサイトをご覧ください。
また、MTECにご興味のある方は、ぜひ以下の採用サイトをご覧ください。
最後までお読みいただき、ありがとうございました!
6.参考文献
-
Hiroaki Yamagiwa, Momose Oyama and Hidetoshi Shimodaira. Discovering Universal Geometry in Embeddings with ICA. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP , Singapore, pp. 4647-4675, 2023.
-
Momose Oyama, Hiroaki Yamagiwa and Hidetoshi Shimodaira. Understanding Higher-Order Correlations Among Semantic Components in Embeddings. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, EMNLP , Miami, Florida, USA, pp. 2883-2899, 2024.
-
新妻 巧朗, 田口 雄哉, 田森 秀明. 計量テキスト分析のための文埋め込みによる探索的カテゴリ化. 言語処理学会 第 30 回年次大会 発表論文集(2024 年 3 月), 2024.

Discussion