1.はじめに
MTECの鈴木です。本記事では我々が第39回人工知能学会全国大会(JSAI2025)で発表した「独立成分分析を用いた事業リスクの分類および定量化の検討」の内容について解説します。
この研究は、タイトルの通りで、有価証券報告書の記載項目の1つである「事業リスク」の内容を独立成分分析によって分類およびクラスタリングすることによって、各企業が行っている事業に関するリスクについて整理しようという試みです。論文のアブストラクトは以下の通りです。
論文のアブストラクト
本研究では、各企業が有価証券報告書に記載している”事業リスク”の分類および定量化を試みる。基本的に事業リスクは自由形式のテキストであり、企業の事業内容によってリスクが変わるため、明確な分類について定義されておらず、また定量的な数値で開示できるものでもない。そこで、本研究では事業リスクの文章を文埋め込み表現によってベクトル化し、独立成分分析によって独立成分を抽出する。これにより、各企業がもつ事業リスクをデータドリブンに分類することができ、各企業の独立成分得点を見ることでそれぞれの事業リスクの大きさの定量化が可能となる。さらに独立成分間の高次相関を用いることにより、独立成分同士のネットワーク構築やクラスタリングを実施することで、異なる事業リスク間の関係性についての解釈性も高まり、定性的にもより納得感のある結果を得ることが出来た。
記事は本記事(前半)と次回(後半)の2回に分けて解説します。おおまかに
- 前半:独立成分分析によって事業リスクをデータドリブンに分類
- 後半:分類した事業リスク間の関係性をクラスタリングによって整理
という流れになっています。ぜひ後半も含めてご一読ください!
2.背景と課題
近年の機械学習や情報技術の発展に伴い、株価や財務情報などの数値情報以外のテキスト情報に記述されている内容を解析して、収益機会(アルファ)やリスクを認識することが重要となってきています。特に、テキスト情報をベクトルとして埋め込むことで、付加価値のある情報を定量化できる可能性があるため、埋め込み表現を活用した分析と親和性が高いと考えています。
この研究では、各企業が有価証券報告書に記載している事業リスクに着目しました。例えば、トヨタの24年3月期の有価証券報告書における事業リスクは以下のように記述されています。
3 【事業等のリスク】
以下において、トヨタの事業その他のリスクについて、投資家の判断に重要な影響を及ぼす可能性のある事項を記載しています。ただし、以下はトヨタに関するすべてのリスクを網羅したものではなく、記載されたリスク以外のリスクも存在します。かかるリスク要因のいずれによっても、投資家の判断に影響を及ぼす可能性があります。本項においては、将来に関する事項が含まれていますが、当該事項は有価証券報告書提出日(2024年6月25日)現在において判断したものです。(1)市場および事業に関するリスク
①自動車市場の競争激化
世界の自動車市場では激しい競争が繰り広げられています。トヨタは、ビジネスを展開している各々の地域で、自動車メーカーとの競争に直面しています。近年、自動車市場における競争はさらに激化しており、厳しい状況が続いています。また、世界の自動車産業におけるCASEなどの技術革新が進むことによって、競争は今後より一層激化する可能性があり、業界再編につながる可能性もあります。競争に影響を与える要因としては、製品の品質・機能、安全性、信頼性、燃費、革新性、開発に要する期間、価格、カスタマー・サービス、自動車金融の利用条件、各国の税制優遇措置等の点が挙げられます。競争力を維持することは、トヨタの既存および新規市場における今後の成功、販売シェアにおいて最も重要です。トヨタは、エンジン車から電動車へのお客様のニーズの変化など、昨今の自動車市場の急激な変化に的確に対応し、今後も競争力の維持強化に向けた様々な取り組みを進めていきますが、将来優位に競争することができないリスクがあります。競争が激化した場合、自動車の販売台数の減少や販売価格の低下などが起きる可能性があり、それによりトヨタの財政状態、経営成績およびキャッシュ・フローが悪影響を受けるリスクがあります。
...
(以下省略)
このように事業リスクは基本的に自由形式のテキストであり、企業の事業内容によってリスクが変わってきます。自然言語処理の技術を用いて日本の企業がどのような事業のリスクを認識しているかを整理していきたいと思います。
3.分析の流れ
基本的には、先行研究[1],[2]の方法を用いており、以下の流れで事業リスクの解釈を試みています。
前半パートでは独立成分を抽出する部分とその独立成分を解釈する試み([1]を踏襲した分析)について解説します。
3-1.利用データ
2024年3月決算の東証プライム上場銘柄の有価証券報告書を対象としました。事業リスクの文章は EDINETからXBRLで”jpcrp cor:BusinessRisksTextBlock”の項目を取得しています。EDINETやXBRLについては金融庁の資料等をご確認ください。
また、Unicode正規化や不要な括弧や番号の除外などの必要最低限の前処理を行っています。
3-2.文埋め込み表現の獲得
文埋め込み表現のモデルはpkshatech/GLuCoSE-base-jaを利用しました。GLuCoSEはMaxトークン数が512で、出力される埋め込み次元は768次元となっています。
事業リスクの記載内容は長文テキストのため、基本的にはMaxトークンを超える場合が多いです。実際に今回用いたデータのテキスト文字数のヒストグラムを見ると、数千~数万字で事業リスクを記載している企業もあります。
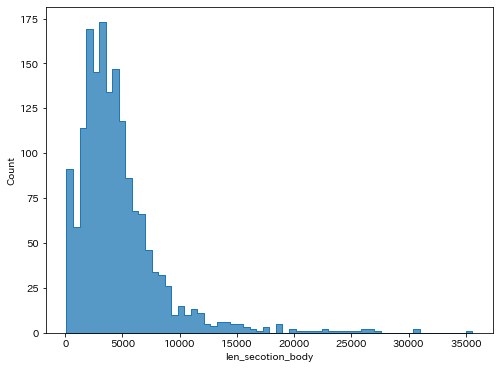
Maxトークンを超える場合はテキストをMaxトークンごとに分割し、各分割ごとに埋め込み表現を獲得してそれを平均化します。実装は以下の記事を参考にしました。
3-3.独立成分分析
独立成分分析(Independent Component Analysis, ICA)とは、主成分分析(Principal Component Analysis, PCA) と似ていますが、PCAが無相関な成分を抽出するのに対し、ICAは独立な(無相関よりも仮定が強い)成分を抽出します。数学的な話は論文をご参照していただければと思いますが、基本的には文埋め込み(d次元)から独立成分(r次元)に次元削減を行うイメージです。dは文埋め込みのモデルに依存しており768(=GLuCoSEの出力次元)で、rは自分で決める必要があり今回は25としています。また、PCAは直交するという条件のもと分散が大きい順に主成分を取っていきますが、ICAは特に順番があるわけではないため、先行研究[1]を参考に歪度が正になるように符号変換を行い、歪度が大きい順に独立成分の順番を付与しています。これは、(実際に結果を見ても分かるように)歪度が大きいほど特徴的な独立成分となっている、と考えられるためです。
ICAについては、この解説記事が分かり易いのでこちらもぜひご参照ください。
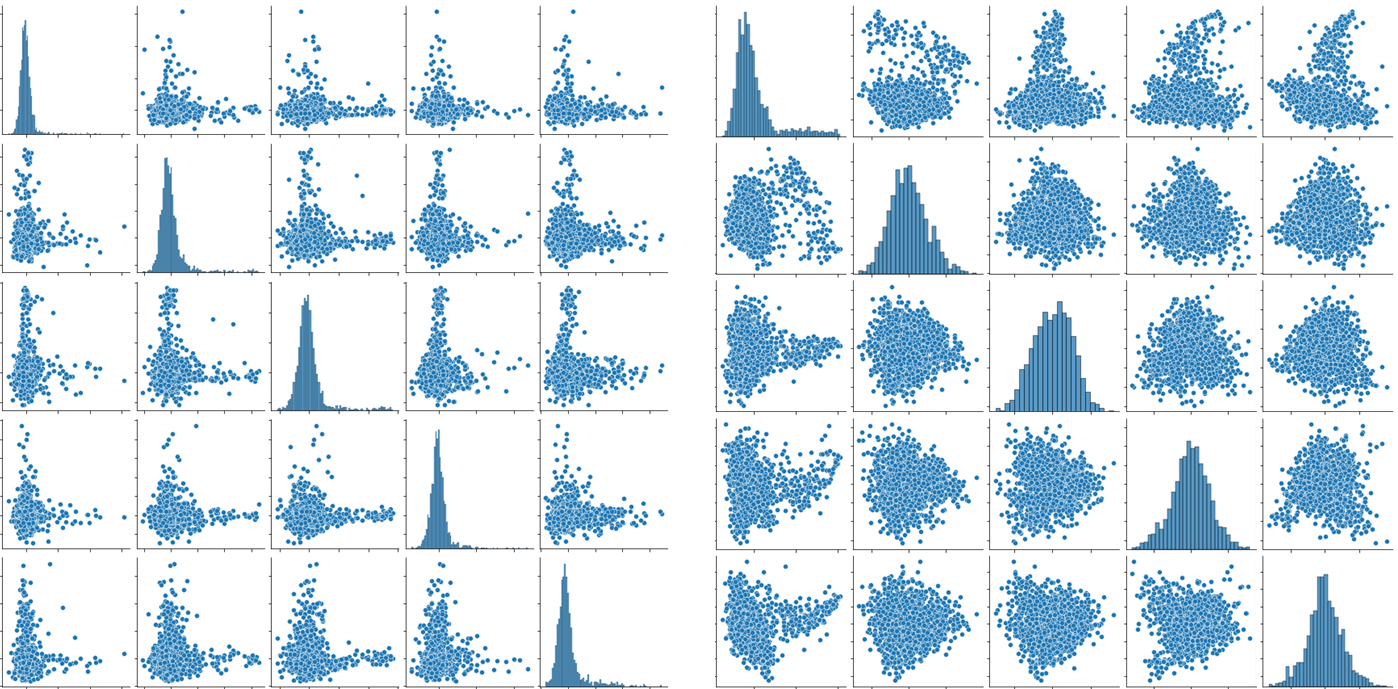
4.試算結果
まずは、ICAとPCAの結果を比較してみます。上から5つの独立成分とPCAにおける上から5つの主成分のペアプロットを見ると、ICA(左図)はPCA(右図)と比べてスパースに散布していて、軸として解釈性が高いことが期待されます。
次に、各独立成分のスコアの業種ごとの平均値を見てみます。

すると、
- ica2:銀行業のスコアが高い
- ica5:医薬品のスコアが高い
といったように、業種特有のリスクが独立成分として抽出されていそうです。一方で、
- ica4:小売・農林水産・食料品などのスコアが高い
といったように、1つの業種に偏っていない独立成分もあります。
では、これらの独立成分が何を表しているかを解釈していきたいと思います。今回は、WordCloudを使って、各独立成分のスコアの上位5企業の事業リスクに頻出する単語を可視化してみます。可視化の際に一般的に良く出てくる単語(リスク,事業,影響など)は除外しています。また、実装は以下の記事を参考にしました。
例えば、ica2であれば

のように、資産や証券の価格変動(市場リスク)や融資先の破綻(信用リスク)など銀行特有のリスクを表していそうなことが見て取れます。
また、ica5であれば

のように、医薬品に関連する規制や医療制度に関するリスクについて表していそうです。
一方で、様々な業種にまたがっていたica4では

のように、食品に関する"衛生"という観点で括られているように見えます。ここは定性的(=ナレッジドリブン)にはさらに細分化して分けても良いように思えますが、データドリブンでやるとこのような結果が出てくるのが面白いですね。
このように、25個の独立成分をWordCloudの可視化によって目視で解釈すると、(あくまで主観ではありますが)概ね以下のような解釈ができました。歪度順に並べていることもあり、番号が大きくなるほど解釈が難しくなっています。
| ICA | 解釈結果 |
|---|---|
| 0 | サプライチェーン |
| 2 | 金融 |
| 3 | ゲームやソフトウェアなど |
| 4 | 食品関連 |
| 5 | 医療関連 |
| 6 | ガバナンス |
| 8 | エネルギー(電気ガス) |
| 9 | 設備投資や製造技術 |
| 10 | 自動車 |
| 11 | 輸送業 |
| 12 | 不動産 |
| 13 | 建設 |
| 14 | 店舗出店 |
| 15 | 新型コロナウイルス |
| 16 | Webや電気通信など |
| 17 | 資源価格の変動など |
| 18 | 為替や海外(地政学) |
| 19 | ESG関連 |
| 20 | プロダクトのライフサイクル |
| 21 | 何かに依存するリスク |
| 22 | 自然災害 |
| 23 | 取引先に関するリスク |
| 24 | M&Aや業務提携 |
5.おわりに
今回は、事業リスクとしてどのようなリスクがあるのかを独立成分で分類することを試みました。WordCloudを使うとそれなりに解釈もでき、面白い結果が得られたかなと思います。
課題点としては、入力トークン長が短すぎて埋め込みを平均化することの悪影響がありそうという点です。具体的に言うと、平均化することで特徴的な情報が失われてしまうため、全ての独立成分スコアが大きくならない(=事業リスクを定量的に識別できない)という事象が発生します。実際に、横軸に事業リスクの文字数、縦軸に独立成分スコアの最大値-最小値を取ると、文字数が長いほどその差が小さいことが見て取れます。

考えられる対策としては、
- 入力トークン数が長い埋め込みモデルの利用
- 入力テキストを分割してICAを実行
の2つの方法が考えられます。
前者は例えば、8192トークンと日本語特化モデルの中で最大の埋め込みモデルであるruri-v3-310mなどにモデルを変更することで、結果がどう変わるかが興味深い点です。
後者は[3]などでやられているように、企業単位ではなくパラグラフ単位でICAを行うことが考えられます。この場合は情報が平均化されないために、よりシャープに結果が得られることが期待できますが、企業ごとに複数(パラグラフ数)の独立成分スコアが計算されることになり、それを企業単位でどう集約するかを考える必要があります。
最後までお読みいただき、ありがとうございました。次回はさらに今回データドリブンに分類した独立成分同士の関連性について整理していきたいと思います。お楽しみに!
6.参考文献
-
Hiroaki Yamagiwa, Momose Oyama and Hidetoshi Shimodaira. Discovering Universal Geometry in Embeddings with ICA. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP , Singapore, pp. 4647-4675, 2023.
-
Momose Oyama, Hiroaki Yamagiwa and Hidetoshi Shimodaira. Understanding Higher-Order Correlations Among Semantic Components in Embeddings. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, EMNLP , Miami, Florida, USA, pp. 2883-2899, 2024.
-
土屋 和之. 事業等のリスクの分析 ―記載内容のトピックにもとづくアプローチ―. 千葉商大論叢 第 57 巻 第 3 号(2020 年 3 月), pp. 185-197, 2020.

Discussion