Swift で自動微分してみた感想



Tsoding にインスパイアされたので今回は Swift で自動微分してみました。いつも通りソースは GitHub にあります。
これまでに Rust, Zig, Scala でやっていますので、自動微分そのものについては詳しい説明は省きます。こちらの記事が旅路の出発点です。
Swift といえば、歴史的にも Rust と影響しあいながら進化してきた言語というイメージがあります。しかし、 Apple 製品以外ではほぼ使えないため、かなりコミュニティの孤立度が高いように思います。とはいえ、この辺は偏見のようなものなので、実際に試すことにします。
Swift コンパイラの依存先は少なくないようなので、 Docker でコンパイラを動かします。 Docker を使えば次のようなコマンドだけで Swift が試せます。
docker run -it -v $(pwd):/work swift /bin/bash
cd /work
swift tape.swift
出力例
-
\sin(x^2)
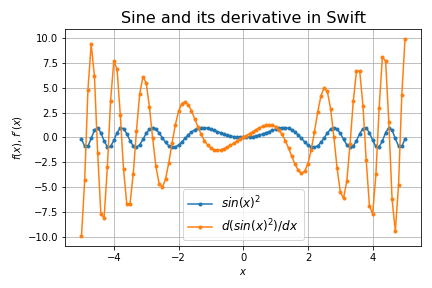
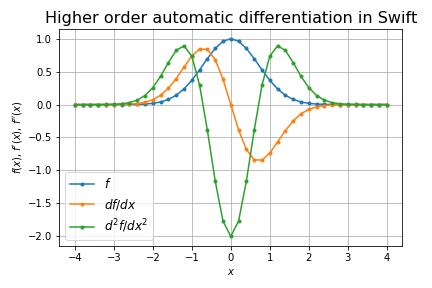
- 高階微分
- グラフの可視化

感想
いつも通り Rustacean の偏見に満ちた感想です。
名前付き引数
Swift では実引数は名前付きで呼び出すのがデフォルトです。
func add(a: Int, b: Int) -> Int {
a + b
}
print(add(a: 1, b: 2))
仮引数の宣言順と異なる順番にするとエラーになります。
print(add(b: 1, a: 2)) // error: argument 'a' must precede argument 'b'
つまり Python のように実引数の順番を好きに変えられるわけではなく、名前が正しいかのチェックに使われるだけです。
これを引数の順番だけで名前を指定しなくても良いようにするには、仮引数の名前の前にアンダースコア (_) を置きます。
func add(_ a: Int, _ b: Int) -> Int {
a + b
}
print(add(1, 2))
これに関しては複雑な気持ちを抱きます。名前付き実引数は引数リストが長くなってきたときに可読性を向上させる素晴らしい言語仕様だと思うのですが、それを省略できるようにするのにアンダースコアを前置するというのはとても奇妙に思えます。
個人的には Python のように何もつけなくても名前付きか否かを呼び出し側が選べる仕様が良いと思うのですが、 Swift はそうは思わないようです。
def add(a: int, b: int) -> int:
return a + b
print(add(a=1, b=2))
print(add(1, 2))
なぜ Python の仕様が良いと思うかというと、可読性が決まるのは呼び出し元であって、呼び出し先ではないからです。言い換えると、「引数が増えてきて読みにくくなってきたな、よし、名前付き引数で呼び出そう」と思うのはその関数を呼び出すコードを書いている人であって、その関数の定義を書いた人ではないからです。
なお、 Python にも名前付きで引数を呼び出すように強制する構文があります。名前付きにしたい引数の前に *, を置くのですが、これも個人的にはわかりにくい構文だと思います。私は一度も使ったことはありません。
def add(*, a, b):
return a + b
print(add(a=1, b=2))
直和型 Enum とパターンマッチング
代数的データ型に基づいた直和型 Enum とそれを識別して取り出すパターンマッチングの構文は、モダンな言語の例に漏れずしっかりサポートされています。
let node = terms[term]
switch node.value {
case let .Value(v): return v
case let .Add(lhs, rhs): return eval_int(lhs) + eval_int(rhs)
case let .Sub(lhs, rhs): return eval_int(lhs) - eval_int(rhs)
case let .Mul(lhs, rhs): return eval_int(lhs) * eval_int(rhs)
case let .Div(lhs, rhs): return eval_int(lhs) / eval_int(rhs)
case let .Neg(term): return -eval_int(term)
case let .UnaryFn(term, f, _, _): return f(eval_int(term))
}
特に言うことはありませんが、強いて言えば Optional 型の位置づけに一貫性がないような気がします。
Swift のオプショナル型は、内部的には次のような enum として定義されているようです。
enum Optional<T> {
case some(T)
case none
}
実際そのようにパターンマッチもできます。
let opt: Int? = 42;
switch opt {
case let .some(v): print(v)
case .none: print("None")
}
より簡潔にパターン内で some と none を区別するには、後置 ? と nil を使うこともできます[1]。
switch opt {
case let v?: print(v)
case nil: print("None")
}
まあ、普通であれば if let 文が可読性の面からも望ましいでしょう。
if let opt {
print(opt)
} else {
print("None")
}
しかし、一般のパターンマッチの一部として使うと、次のようになります。
switch (gen_graph(lhs, wrt), gen_graph(rhs, wrt)) {
case let (lhs?, nil): return lhs
case let (nil, rhs?): return rhs
case let (lhs?, rhs?): return add_add(lhs, rhs)
case _: return nil
}
nil はともかく、後置 ? がどうにも慣れません。 Swift にはオプショナルチェイニングがあるので、その後置 ? から来ているのはわかるのですが、オプショナルチェイニングは実体としては条件分岐であり、オプショナルコンテナへの格納とは意味が異なります。これは恐らくオプショナルな型とそうでない型の構文を似せるために、オプショナルな型のコンストラクタを構文としては用意せずに、型強制によって構築するようにしたことによる結果です。
例えば、 Swift のオプショナル型の構築に前置 ? を使う構文だったとしたら、パターンマッチは次のようになり直感に沿うものになったと思います(実際には三項演算子 ?: と衝突するので、前置 ? を構文に使うことはできないと思いますが...)。
let opt: Int? = ?1;
switch opt {
case let ?v: print(v)
case nil: print("None")
}
とはいえ、これも慣れの問題で、しばらく使っていれば気にならなくなるでしょう。問題は他の言語から移ってきた人が構文を予想できない、また情報の検索性も悪いということでしょうか。
部分参照と Struct, Enum, Class
Swift は Rust よりも高レイヤな言語であり、クラスのインスタンスはヒープに確保されます。これに対し、 struct や enum はデフォルトで環境に埋め込まれます。つまり、関数のローカル変数や引数であればスタック、クラスのメンバであればオブジェクトに埋め込まれます。したがって、メモリアロケーションを減らすためにはできるだけ struct を使いたいところです。
ところが、 struct や enum はその"部分"への参照を取ることができません。つまり、 enum のマッチを行ったうえでその中身の値をかきかえるなどといったことができません。下の例では Optional<Int> にマッチした結果に書き込もうとしたときにエラーになるケースを示しています。
var opt: Int? = 1
if let val = opt {
val = 2 // error: cannot assign to value: 'val' is a 'let' constant
}
これが Rust であれば次のように書けます。
let mut opt: Option<i32> = Some(1);
if let Some(ref mut val) = opt {
*val = 2;
}
Swift にも参照を取得するような演算子 (&) はあるのですが、関数の引数に inout として渡すときにしか使えません。
struct A {
var first: Int
var second: Int
var last: Int
}
var aa = A(first: 1, second: 2, last: 3)
var second = &aa.second // error: '&' may only be used to pass an argument to inout parameter
func write_int(_ i: inout Int) {
i = 42
}
write_int(&aa.second) // Ok
個人的にはこの制約がかなりきつくて、自動微分の Tape のようにメモリ局所性を積極的に使いたいデータ構造ではヒープメモリを避けるために struct を使えるケースが限られてしまいます。
たとえばリバースモードの微分では同じノードの値を何度も参照するのですが、これを毎回インデックスを使って配列から取ってくる terms[idx] などという書き方をしないといけません。これは配列の要素も struct と同じように埋め込まれるからだと思われます。
struct TapeNode { /* ... */ }
class Tape {
var terms: [TapeNode] = []
func backward_node(_ idx: Int) {
switch terms[idx].value {
case let .Add(lhs, rhs):
let grad = terms[idx].grad
if let grad {
terms[lhs].grad = grad
terms[rhs].grad = grad
}
// ...
}
}
}
もし参照型があれば、次のように var term = &terms[idx] を使いまわせたはずです。
class Tape {
var terms: [TapeNode] = []
func backward_node(_ idx: Int) {
var term = &terms[idx]
switch term.value {
case let .Add(lhs, rhs):
let grad = term.grad
if let grad {
terms[lhs].grad = grad
terms[rhs].grad = grad
}
// ...
}
}
}
「じゃあ TapeNode を class にしろ」ということなんでしょうが、それだと Tape のメリットの一つであるメモリ局所性を手放すことになります。
同時アクセスとメモリ安全性
もう一つの問題は、上記の部分参照を inout 引数によって実現しようとすると起こります。
class Tape {
func backward_node(_ term: inout TapeNode) {
switch term.value {
case let .Add(lhs, rhs):
let grad = term.grad
if let grad {
terms[lhs].grad = grad
terms[rhs].grad = grad
}
// ...
}
}
}
関数の引数を使えば参照渡しができるのでこの方法はうまくいくように思いますが、実際には実行時エラーになります。
Simultaneous accesses to 0x55811c0231d0, but modification requires exclusive access.
Previous access (a modification) started at 0 <unknown> 0x00007fedbbad7061
(0x7fedbbad7061).
Current access (a read) started at:
0 libswiftCore.so 0x00007fedbfd49a3d <unavailable> + 4442685
1 libswiftCore.so 0x00007fedbfd49b40 swift_beginAccess + 66
2 <unknown> 0x00007fedbbad63c2
3 <unknown> 0x00007fedbbad2da5
4 <unknown> 0x00007fedbbad7083
5 <unknown> 0x00007fedbbad3695
6 <unknown> 0x00007fedbbad22f5
7 <unknown> 0x00007fedbbad49ee
8 swift-frontend 0x0000558111a7bea0 <unavailable> + 12422816
9 swift-frontend 0x0000558111920954 <unavailable> + 11000148
10 swift-frontend 0x000055811191ee9e <unavailable> + 10993310
11 swift-frontend 0x00005581118bfd55 <unavailable> + 10603861
12 swift-frontend 0x00005581118bc102 <unavailable> + 10588418
13 swift-frontend 0x00005581118bb13a <unavailable> + 10584378
14 swift-frontend 0x00005581118c87ab <unavailable> + 10639275
15 swift-frontend 0x00005581118be663 <unavailable> + 10597987
16 swift-frontend 0x00005581118bccd8 <unavailable> + 10591448
17 swift-frontend 0x00005581116cf4dd <unavailable> + 8570077
18 libc.so.6 0x00007fedbe22e1ca <unavailable> + 172490
19 libc.so.6 0x00007fedbe22e200 __libc_start_main + 139
20 swift-frontend 0x00005581116ce635 <unavailable> + 8566325
Fatal access conflict detected.
これはロジックの内部で同じ配列の別の要素にアクセスしているからです。
terms[lhs].grad = grad
terms[rhs].grad = grad
つまり、配列への可変アクセスを同時に一つだけにするように実行時チェックが行われています。これは Rust の RefCell に相当しますが、ランタイムが暗黙のうちの行っているのが違いです。このため、エラー時のハンドリングもできず、クラッシュします。
個人的にはこれは結構残念な仕様です。同時可変アクセスを防ごうという意図は、安全なソフトウェアを目指すという目的からすれば悪くないと思いますが、型システムに統合されておらず実行時の動的チェックになっているので、コンパイル時に検出できず、実行時オーバーヘッドもあります(多分リリースビルドでは無効になるとは思いますが)。しかもエラーメッセージがかなり不親切です。これだけではどの変数が複数の可変参照を持っているか突き止めるのは困難です。
Rust であれば、まず借用チェッカがこのような参照をコンパイル時に防ぎます(同じオブジェクトへの二つ以上の可変参照を作ることはできない)。この上で Cell を使って Copy な型のみ変更を許すか、 RefCell を使って実行時チェックのオーバーヘッドを受け入れるかをプログラマが選ぶことができます。
結局、私の実装では毎回インデクシングすることにしました。
このような仕様になった理由については想像は付きます。 Swift のようなある程度高レイヤの言語は、オブジェクトの寿命を参照カウンタや GC で制御し、プログラマに意識させないようにすることをゴールにしています。これは個別のヒープに確保される class のインスタンスについては問題ないのですが、配列や struct, enum のような一続きのオブジェクトの一部への参照を得る際には問題になります。このため、 Swift はまずそのような参照の作成を防いでいます。しかし、そのような参照が全く作れないのも不便なので、 inout 引数への参照渡しとしてだけ許しています。これはエイリアシングの問題を起こしうるので、実行時チェックをしているのだと思います。
ランタイムの依存先
これは自動微分の実装とは直接の関係はないのですが、 Linux 上で Swift を動かそうとすると直面する課題です。
Swift はネイティブコンパイル言語ですが、実行時に独自のランタイムライブラリを必要とします。それだけではなく、共有ライブラリとして Swift の名前のついたいくつかのライブラリに依存します。
root@363d7037d889:/work# ldd main
linux-vdso.so.1 (0x00007ffedd506000)
libswiftSwiftOnoneSupport.so => /usr/lib/swift/linux/libswiftSwiftOnoneSupport.so (0x00007f92d54ac000)
libswiftCore.so => /usr/lib/swift/linux/libswiftCore.so (0x00007f92d4de4000)
libswift_Concurrency.so => /usr/lib/swift/linux/libswift_Concurrency.so (0x00007f92d4d4d000)
libswift_StringProcessing.so => /usr/lib/swift/linux/libswift_StringProcessing.so (0x00007f92d4c72000)
libswift_RegexParser.so => /usr/lib/swift/linux/libswift_RegexParser.so (0x00007f92d4b5f000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f92d4948000)
libstdc++.so.6 => /lib/x86_64-linux-gnu/libstdc++.so.6 (0x00007f92d46cb000)
libm.so.6 => /lib/x86_64-linux-gnu/libm.so.6 (0x00007f92d45e2000)
libgcc_s.so.1 => /lib/x86_64-linux-gnu/libgcc_s.so.1 (0x00007f92d45b5000)
/lib64/ld-linux-x86-64.so.2 (0x00007f92d54f8000)
libdispatch.so => /usr/lib/swift/linux/libdispatch.so (0x00007f92d4555000)
libswiftGlibc.so => /usr/lib/swift/linux/libswiftGlibc.so (0x00007f92d4540000)
libBlocksRuntime.so => /usr/lib/swift/linux/libBlocksRuntime.so (0x00007f92d453b000)
このため、 Docker でコンパイルするとその外からは実行できません。
./main: error while loading shared libraries: libswiftSwiftOnoneSupport.so: cannot open shared object file: No such file or directory
これはコンパイルした環境から持ち出すには依存先ライブラリもパッケージ化する必要があることを意味します。依存先ライブラリをスタティックリンクする方法もあるのですが、その情報がめちゃくちゃ見つけにくく、さらに追加の SDK を使ってビルドする必要があります。コンパイラに組み込みの機能にはできなかったんでしょうか。 Apple 製品のようにランタイムがシステムにインストールされていることを前提としたツール群であるという印象を受けます。
総括
Rust の文脈でもたびたび言及されるので、触ってみるまでは Rust に近い低レイヤのプログラミング言語としても使えると思っていたのですが、実際には Rust や C++ よりも Go や Java や C# に近い、比較的高レイヤの言語であることが分かりました。特にランタイムへの依存性はマーケティング的な意図を感じます。以下のようなイメージでしょうか。
- Go - Google
- Java - Oracle
- C# - Microsoft
- Swift - Apple
オープンソースかつクロスプラットフォームであることは確かですが、囲い込み効果が強いです。言語仕様などに参考になるところはあるものの、 Apple 製品に使うなどの理由がない限り積極的に使うことはないと思います。
-
実は最初大文字始まりの
SomeとNoneかと思って動かなかったので探しているうちに?とnilに行きつきました。
Swift の命名規則では列挙子は小文字始まりのようで、ここは少しだけ Rust と異なります。 ↩︎
Discussion