言語モデルと知識グラフを良い感じにalignして、knowledge-awareなニュース埋め込み表現を作る推薦手法DKNの論文を読んだ
DKN: Deep Knowledge-Aware Network for News Recommendation
published date: 30 January 2018,
authors: Hongwei Wang, Fuzheng Zhang, Xing Xie, Minyi Guo
url(paper): https://dl.acm.org/doi/fullHtml/10.1145/3178876.3186175
(勉強会発表者: morinota)
n週連続推薦システム系論文読んだシリーズ36週目の記事になります。
ちなみに35週目は Twitterの2-stage推薦の2段階目(candidate ranking)で使われてるっぽいMaskNetの論文を読んだ でした!
どんなもの?
- ニュース推薦タスクにおいて、知識グラフを活用する最初の論文らしい。
- ニュース推薦タスクにおけるコンテンツベース推薦手法において、一般的な言語モデルに基づくsemanticな埋め込みだけじゃなくて、知識グラフに基づくentity埋め込みも良い感じにalignしてニュースを表現しよう、という手法 DKN(deep-knowledge-aware network) を提案してる。
- DKNの手法のキモは、ニューステキストのsemanticな単語埋め込みsequenceと、知識グラフに基づくentity埋め込みsequenceをRGB画像みたいな感じでマルチチャンネルとして扱い、knowledge-awareなニュース表現を生成するKCNN(knowledge-aware convolutional neural networks)。
- この論文を読みながらぼんやり思ったこと:
- (もしかすると最新のLLMが作るテキストの埋め込み表現は、わざわざ後天的に知識グラフの情報とalignしなくとも、割とデフォルトでknowledge-awareだったりするのかな...!:thinking:)
- 個人的には、実験の後半のケーススタディが知識グラフ情報の必要性を感じられて好きだった:)
先行研究と比べて何がすごい?
- ニュース推薦において、knowledge entitiesとcommon senseの考慮が大事という話:
- ニュース推薦タスクでは、他の推薦タスクと比較して推薦アイテムのlifetimeが短く、推薦候補が頻繁に新しいニュースに置き換えられるため、id-basedな推薦手法は効果的ではない。
- なので、ニュースのタイトルや本文などのテキスト情報から言語モデル等によってsemanticな埋め込み表現を用いたcontent-basedな推薦手法が用いられる事が多い。
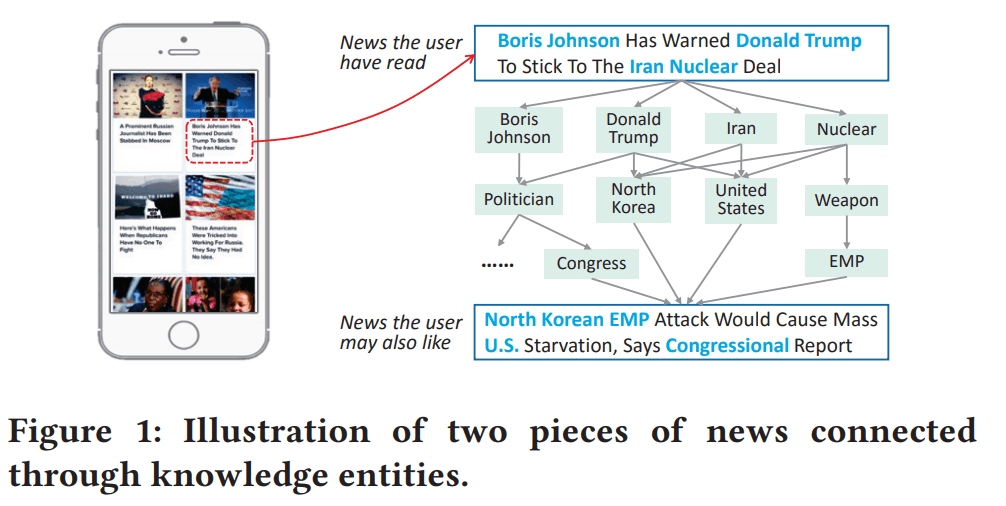
- しかしsemanticな埋め込み表現は、semantic-levelな関係性は捉えやすいが、knowledge-entities(固有名詞?)間のつながりやcommon sense(常識?)などのknowledge-levelな関係性は捉えにくい。(図1参考)
- ニューステキストは、大量のknowledge entitiesとcommon senseで構成されてる。
- knowledge graphの活用:
- (knowledge graph = ノードがentityに対応し、エッジがentity間の関係性に対応する、有向異種グラフの一種)
- ニュース間の深い論理的つながりを抽出するためには、ニュース推薦にknowledge graph情報を追加する必要がある...!
- 本論文は、ニュース推薦タスクにおいてknowledge graph を活用する最初の論文らしい。
技術や手法の肝は?
DKNの概要
-
本論文は、ニュース推薦においてknowledge graphを組み込んで外部知識を活用する新しいコンテンツベース推薦手法 DKN(deep knowledge-aware network) を提案。
-
DKN推論時の観察可能な振る舞い:
- 入力: 1つのニュース候補と1人のユーザのクリック履歴
- 出力: ユーザがそのニュースをクリックする確率。
- (この振る舞いはまさに一般的なcontent-basedのニュース推薦モデルって感じ:thinking:)
-
DKN推論時の内部のざっくりした動作:
- まず、入力されたニュースに対して、ニュースの内容を表すテキストの各単語をknowledge graphのentityに関連付ける。
- また、各entityのcontextual entitiesのセット(i.e. knowledge graph内での直接の隣接ノード)も関連付ける。
- 次に、DKNの主要なcomponentであるKCNN(knowledge-aware convolutional neural networks)によって、ニューステキストのsemantic-level(i.e. word-level)の埋め込み表現とknowledge-level(i.e. entity-level)の埋め込み表現を融合し、knowledge-awareなニュース表現を生成する。
- 続いて、attention moduleを使って現在の候補ニュースに関するユーザ閲読履歴の特徴を動的に集約してユーザ埋め込み表現を生成する。
- (ユーザ埋め込み表現が、候補ニュースによって変わりうる点に注意...!これは結構、他のcontent-based手法と比較したDKNの特徴な気がしている...!この場合、、ユーザ埋め込みは事前に計算せず、推論時に計算する形になるのかな:thinking:)
- 最後に、候補ニュース埋め込みとユーザ埋め込みをCTR予測のためのDNNに入力し、出力としてCTR予測値を得る。
- (この手法のscore prediction moduleは内積ではないのか...!だから推論コストがそこそこある感じなのかな:thinking:)
-
図3はDKNのアーキテクチャ図。

(おまけ) knowledge graph埋め込みの作り方について何も知らなかったのでメモ
-
knowledge graphの構成:
- 典型的なknowledge graphは、数百万のentity-relation-entityのtriplet (三つ組)
(h, r, t) - ここで、h、r、tはそれぞれtripletのhead、relation、tailを表す。
- 典型的なknowledge graphは、数百万のentity-relation-entityのtriplet (三つ組)
-
knowledge graph埋め込みの目的:
- knowledge graph内の全てのtripletが与えられた時、元のknowledge graphの構造情報を保持しつつ、各entityとrelationの低次元表現ベクトルを学習すること。
-
translation-basedな knowledge graph embedding手法:
- translation-based(翻訳ベース?) knowledge graph embedding手法は、簡潔なモデルと優れたパフォーマンスにより近年人気らしい。(2018年頃はそうだったらしい。2024年現在はどうなんだろう?)
-
論文内では、読者がself-containedできるように、以下のxつのtranslation-basedなknowledge graph embedding手法を簡単に紹介してくれてた...! (たぶん、スコア関数 i.e. 良い埋め込みの定義が少し違うだけっぽいかな...??:thinking:)
-
- TransE
-
- TransH
-
- TransR
-
- TransD
-
-
1つ目: TransEの概要:
- knowledge graph内のtriplet
(h, r, t) \mathbf{h} + \mathbf{r} \approx \mathbf{t} - よってTransEは、以下のスコア関数を仮定する:
- このスコア関数は、
(h, r, t) - (このスコア関数をグラフ内の全てのtripletに対して最小化するような損失関数を設計して、entityとrelationの埋め込みを学習する感じ...!:thinking)
- このスコア関数は、
- knowledge graph内のtriplet
- 2つ目: TransHの概要:
- entityの埋め込みをrelation 超平面に射影することで、異なるrelationに関与するときに異なる表現を持てるようにした手法。
- スコア関数は以下:
- ここで、
\mathbf{h}_{\perp} = \mathbf{h} - \mathbf{w}_{r}^{\top} \mathbf{h} \mathbf{w}_{r} \mathbf{t}_{\perp} = \mathbf{t} - \mathbf{w}_{r}^{\top} \mathbf{t} \mathbf{w}_{r} \mathbf{h} \mathbf{t} \mathbf{w}_{r} -
\|\mathbf{w}_{r}\|_{2} = 1
- ここで、
- 3つ目: TransRの概要:
- 各 relation r に対して、entity埋め込みを対応するrelation空間にマッピングするための射影行列
M_{r} - スコア関数は以下:
- ここで、
\mathbf{h}_{r} = \mathbf{h} M_{r} \mathbf{t}_{r} = \mathbf{t} M_{r}
- ここで、
- 各 relation r に対して、entity埋め込みを対応するrelation空間にマッピングするための射影行列
- 4つ目: TransDの概要:
- TransRの射影行列を、entity-relationペアの2つの射影ベクトルの積に置き換える。
- スコア関数は以下。
- ここで、
\mathbf{h}_{\perp} = (\mathbf{r}_{p} \mathbf{h}_{p}^{\top} + \mathbf{I}) \mathbf{h} \mathbf{t}_{\perp} = (\mathbf{r}_{p} \mathbf{t}_{p}^{\top} + \mathbf{I}) \mathbf{t} \mathbf{h}_{p} \mathbf{r}_{p} \mathbf{t}_{p} \mathbf{I}
- ここで、
- 上記の全てのembedding手法について、スコア関数をもとにした以下のランキング損失関数を使って学習する。
-
\gamma \Delta \Delta' - (正例と負例をペアにして渡す、pairwiseのランキング損失関数だ:thinking:)
-
Knowledge Distillation(ニューステキストから知識を蒸留する?)について
-
DKNの最初のステップ。
-
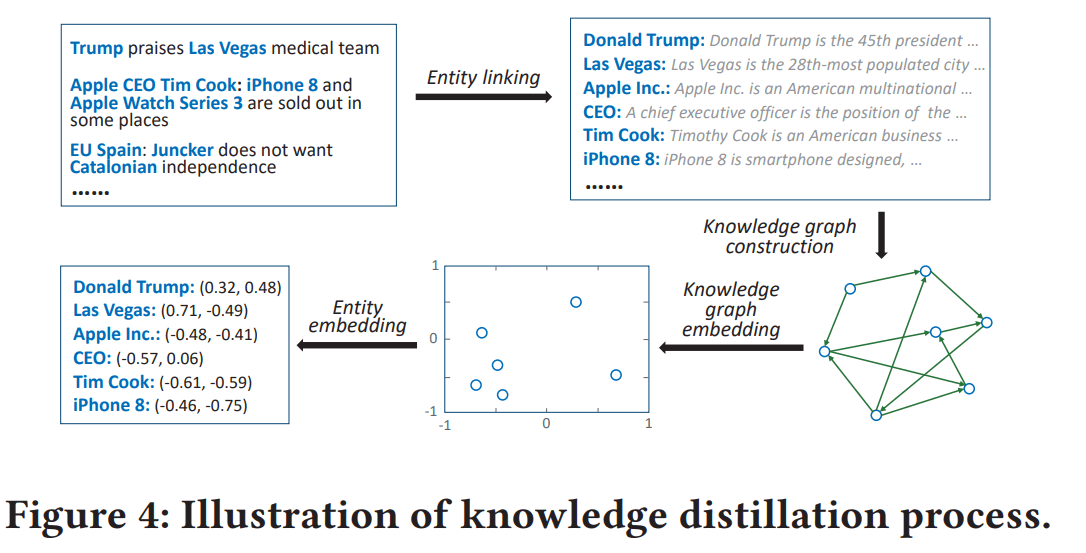
Knowledge Distillationは以下の4つのステップから構成される(図4)
-
- entity linking:
- ニューステキスト中の単語をknowledge graphのentityに関連付ける。
-
- knowledge graph construction:
- 関連付けられたentityに基づいて、knowledge graphからサブグラフを抽出する。
- (元のknowledge graph全体が必要なわけじゃなくて、今回のデータに登場するentityだけが含まれるサブグラフを作るってことかな...!:thinking:)
- このとき、関連付けられたentityだけじゃなくて、1ホップ以内のすべてのentityをサブグラフに含める。(これがcontextual entityのセットになる)
-
- knowledge graph embedding:
- 抽出したサブグラフに対して、knowledge graph embedding手法を適用して、各entityとrelationの埋め込みを学習する。(論文ではTransDを採用してた)
-
- entity embedding:
- ニューステキスト中の単語に関連付けられた各entityの埋め込みを、knowledge graph embeddingから取得する。
- この際、対象entityそのもの埋め込みに加えて、文脈情報を追加するためにcontextual entities集合のentity embeddingから算出するcontexutal embeddingも取得する。
-
-
ちなみに、DKNではcontextual entities集合を「知識グラフ内のその直接の隣接ノードの集合」と定義してる。
- 数式で表すと以下:
- ここで
r G - (orだから矢印の向きは問わないってことか)
- ここで
- 数式で表すと以下:
- contextual entitiesを使う動機:
- 通常、semanticとlogicの観点から、contextual entitiesは対象entityと密接に関連している。よって、contextual entitiesはより補完的な情報を提供し、対象entityの識別性を向上させられるはず...!
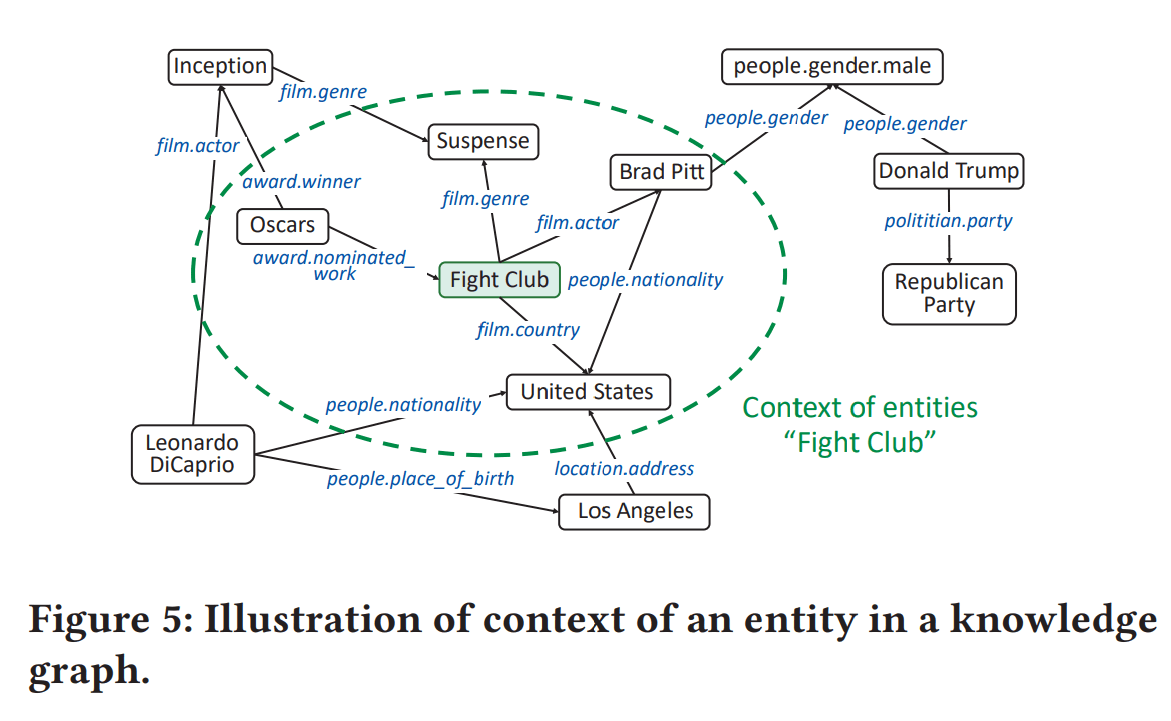
- contextの例(図5):
- 表現したい対象entity = “Fight Club”(映画の名前)
- contexutal entities = “Suspense”(ジャンル), “Brad Pitt”(俳優), “United States”(国), “Oscars”(賞)
- 対象entityの特徴を表現するために、“Fight Club”自体の埋め込みを使用するだけでなく、そのcontext、例えば“Suspense”(ジャンル)、“Brad Pitt”(俳優)、“United States”(国)および“Oscars”(賞)をその識別情報として使用したい...!
- 実験セクションにて、contextual entitiesを使うことの有効性を検証してた。
- contexual embeddingの算出方法:
- 対象entity
e context(e) \bar{\mathbf{e}} - 数式だと以下。
- ここで、
\mathbf{e}_{i} e_{i}
- ここで、
- 対象entity
DKNの重要なcomponent: KCNNについて
KCNNの入力データが作られる流れ:
-
- 長さ
n t
t = w_{1:n} = [w_{1}, w_{2}, \cdots, w_{n}]
- 長さ
-
- 言語モデル等によって、各単語
w_{i} \mathbf{w}_{i} d
- よって単語埋め込みsequenceはこんな感じ:
\mathbf{w}_{1:n} = [\mathbf{w}_{1} \mathbf{w}_{2} \cdots \mathbf{w}_{n}] \in \mathbb{R}^{d \times n}
- 言語モデル等によって、各単語
-
- さらにKnowledge Distillationによって、各単語
w_{i} e_{i} \in \mathbb{R}^{k \times 1} \bar{e}_{i} \in \mathbb{R}^{k \times 1} k
- (どのentityにも紐づかない助詞みたいな単語もあるだろうけど、それらは削除するのかな:thinking:)
- さらにKnowledge Distillationによって、各単語
- よって、1つのニュースのKCNNへの入力sequenceは、各単語に対して3種の埋め込み(単語埋め込み、entity埋め込み、contexual埋め込み)が紐付けられたsequenceになる。
KCNNの観察可能な振る舞い:
- 入力: ニュースタイトル
t - 出力: ニュースタイトル
t
KCNNの内部の動作:
-
KCNNはどうやって、1つのsemantic-levelな埋め込み表現と2つのknowledge-levelな埋め込み表現を融合して、knowledge-awareなニュース表現を出力してる?
-
そのための2つの工夫:
- 工夫1. word-entity-aligned: 3種の埋め込みをalignさせ、単語埋め込み空間とentity埋め込み空間のheterogeneity(異質性, i.e. 違い)を除去するために、transformation function(変換関数?)を用いる。
- 工夫2. ニュースの単語埋め込み、entity埋め込み、contextual entity埋め込みを、stackされた3つのチャンネルとして扱う。(つまり、カラー画像のようなデータとして扱う...!:thinking:)
-
(工夫1!)まずsemantic埋め込みとentity埋め込みは埋め込み空間が違うし次元数も全然違うので、整合するために、2種のentity埋め込みに対して transformed function
g - 以下の数式は、変換されたentity埋め込みとcontextual埋め込み:
- transformed function
g - 式(14)が線形関数ver.、式(15)が非線形関数ver.。
- ここで、
M \in \mathbb{R}^{d \times k} \mathbf{b} \in \mathbb{R}^{d \times 1} - (
d k - transformed functionは連続的なので、entity埋め込み & context埋め込みを元の空間的関係性を保ったまま、entity埋め込み空間からsemantic埋め込み空間にmappingできる。
- (工夫2!) 工夫1によって3種の埋め込みが同じサイズになったので、それらをstackして、3つのチャンネルとして扱う(RGB画像みたいに!)。
- 以下の式のようにstackし、multi-channel入力
W
- 以下の式のようにstackし、multi-channel入力
- このmulti-channel入力
W - 異なるウィンドウサイズ
l h \in \mathbb{R}^{d \times l \times 3} - 部分行列
W_{i:i+l-1} h
- 異なるウィンドウサイズ
- その後、畳み込み層の出力を以下の式のようにmax-poolingして、最大の特徴量を得る:
- 全ての特徴量
\tilde{c}_{h_i} t e(t) -
m
-
その他の重要なcomponent: ユーザの興味を抽出するattention module
- attention moduleの入力は2つ:
-
- ユーザのクリック履歴に関連付けられたニュース埋め込みsequence
- ユーザ
i \{t_{i1}, t_{i2}, \cdots, t_{iN_{i}}\} e(t_{i1}), e(t_{i2}), \cdots, e(t_{iN_{i}})
-
- 候補ニュースのknowledge-awareニュース埋め込み表現
- 候補ニュースを
t_{j} e(t_{j})
- (ユーザ埋め込みを作るのに、候補ニュースの埋め込みを使う点に注意...! dynamicなユーザ埋め込みなのか...!:thinking:)
-
- (DKNのユーザの作り方の前に...)クリック履歴のニュース埋め込みsequenceからユーザ表現を作るシンプルな方法は...
- 最もnaiveな方法は履歴内の全てのニュース埋め込みを平均すること。
- 数式にすると以下:
- 最もnaiveな方法は履歴内の全てのニュース埋め込みを平均すること。
- ↑のnaiveな方法の課題:
- ユーザのニューストピックへの興味は様々。ユーザ
i t_{j} - (これは例えば、「自動車産業」と「政治」という2つのトピックの記事をよく読むユーザに対して、「自動車産業」に関する推薦候補ニュースとユーザの相性を評価する上で、クリック履歴内の「自動車産業」に関するニュース達の方が「政治」に関するニュース達よりも重要な情報を持ってる、みたいな?:thinking:)
- -> よってDKNでは、クリック履歴に加えて候補ニュースの情報をattention moduleに入力することで、クリック履歴内の各ニュースが候補ニュースに与える影響のモデル化を試みてる...!
- ユーザのニューストピックへの興味は様々。ユーザ
- DKNのユーザ埋め込みの作成手順1:
- ユーザ
i t_{ik} t_{j} H s_{t_{ik}, t_{j}} - (
H - 数式にすると以下:
- (
- ユーザ
- DKNのユーザ埋め込みの作成手順2:
- 候補ニュース
t_{j} i e(i, t_{j})
- 候補ニュース
DKNのprediction module:
- 最後に、prediction moduleはfeed-forward network
G - prediction moduleの振る舞い:
- 入力: ユーザ
i e(i, t_{j}) t_{j} e(t_{j}) - 出力: ユーザ
i t_{j}
- 入力: ユーザ
DKNの学習方法:
- 論文内では、対数損失関数(=binary cross-entropy loss)を採用したとのこと。
- (ニュースのクリック履歴を学習データとして使う設定なので、たぶん「ユーザがニュースをクリックした」履歴(=positive example)以外に、「ユーザにニュースが表示されたけどクリックされなかった」履歴(=negative example)も存在してる前提っぽい...!:thinking:)
- (もしくはnegative sampling技術みたいな工夫を使って、擬似的にnegative exampleを生成してる可能性もある。)
- (でも論文内に記述がなかったから、たぶん前者だと思う...!:thinking:)
どうやって有効だと検証した?
- ベンチマークデータセットによるオフライン実験。
使用データセット:
-
Bing News Dataset
- ユーザのニュースに対するクリック履歴(クリック=1、クリックなし=0)
- 学習データは2016年10月16日から2017年6月11日まで。
- テストデータは2017年6月12日から2017年8月11日まで。
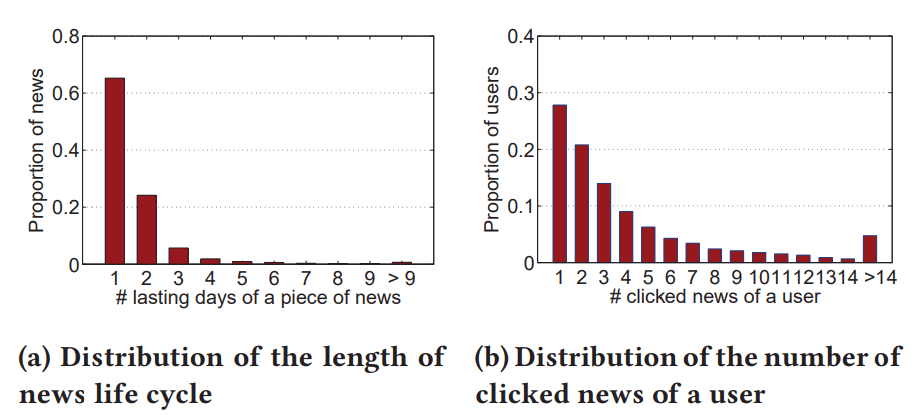
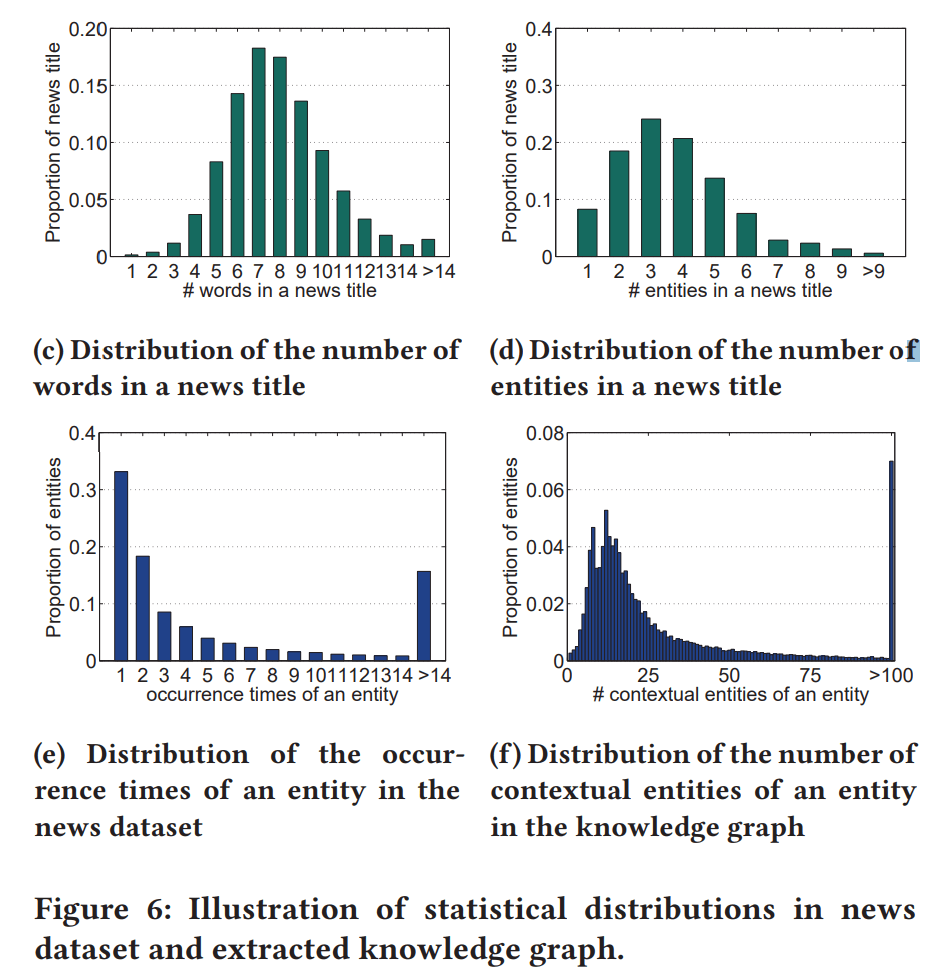
- 図6aは、ニュースのlifecycleの長さの分布:
- lifecycle = 掲載日から最後にクリックされた日までの期間と定義してる(この定義いいね...!自社データの分析に使えそう:thinking:)
- 全ニュースのうちの約90%が、lifecycleが2日以内。
- -> オンラインニュースが非常に時間に対して敏感で、lifecycleが短いことがわかる。
- 図6bは、1人のユーザがクリックしたニュース数の分布:
- 77.9%のユーザは5つ以上のニュースをクリックしておらず、ニュース推薦シナリオにおけるデータのsparce性を示している。
- ユーザのニュースに対するクリック履歴(クリック=1、クリックなし=0)
- また、Bing News Dataset内に含まれる全てのentityと、Microsoft Satori知識グラフ内におけるそれらの1ホップ以内のentityを検索し、信頼度が0.8以上のすべてのedge(Triplet)を抽出して、知識グラフを構築。
- 図6cは、ニュースタイトルに含まれる単語数(stop wordsは含まない)。図6dは、ニュースタイトルに含まれるentity数。
- (ここでstop wordsとは、たぶんa, the, is, ofとか、文の意味にはあまり影響しない単語のことを指しているのかな...!:thinking:)
- ニュースタイトル1つ辺り、単語数が平均7.9個、entity数が平均3.7個。
- -> ニュースタイトル内の単語の2つに1つにentityがあるイメージ。
- entity出現密度が高いことも、経験的に本手法のKCNNの採用を正当化してる。(なるほど、タイトルは他のテキストと比較するとentity出現密度が高い方なのか...!:thinking:)
- 図6eは、データセット内の各entityの出現頻度の分布。図6fは、抽出された知識グラフにおける各entityのcontextual entity数の分布。
- entityの出現頻度の分布はlong tailな分布である(80.4%のエンティティは10回以上出現しない)
- 各entityは知識グラフ内において、豊富なcontextual entityを持ってる。entityあたりの平均contextual entitiesの数は42.5で、最大値は140,737だった。
- ->contexual entityの活用は、ニュース推薦において単一のentityの表現を大幅にenrichできる...!
- 図6cは、ニュースタイトルに含まれる単語数(stop wordsは含まない)。図6dは、ニュースタイトルに含まれるentity数。
ベースライン手法:
- ニュースの内容を使用しない手法:
- DMF: 協調フィルタリング系の深層行列分解モデル。
- ニュースの内容を使用する手法(いずれの手法も、特徴量にentity埋め込みを含むver.と含まないver.をそれぞれ比較する):
- 非deepなハイブリッド手法:
- LibFM: SOTAの特徴量ベースのfactorization machine系列の手法。
- deepなハイブリッド手法:
- DSSM
- DeepWide
- DeepFM
- YouTubeNet
- KPCNN
- 提案手法 DKN:
- 非deepなハイブリッド手法:
評価方法
- テストデータに対して、F1 scoreとAUCを用いる(オフライン評価)
- (implicit feedbackと言えども、「clickした/しなかった」のpositiveとnegativeのラベルがついているので、一般的なbinary classificationの評価指標を使ってる感じか...!:thinking:)
議論はある?
ベースラインモデルとのオフライン精度の比較結果:

- 結果の見方:
- DMF以外の各ベースラインモデルについて、entity埋め込みを入力するver.と入力しないver.の2つの結果がある。入力しないver.の結果は
(-)で表されてる。
- DMF以外の各ベースラインモデルについて、entity埋め込みを入力するver.と入力しないver.の2つの結果がある。入力しないver.の結果は
- 結果からわかること:
-
- entity埋め込みを使用することで、ほとんどのベースラインモデルの性能を向上できる。
-
- DMF(唯一の協調フィルタリング系のベースラインモデル)は、全ての手法の中で最も低い性能と評価された。-> 一般的にlifecycleが短いニュース推薦シナリオにおいて、純粋なCFベースの手法は上手く機能しづらい。
-
- ニュースの内容を使用する手法の中では、deepな手法の方が非deep手法よりも高い性能を示した。
-
- 全てのベースライン手法の中で、KPCNNが最も高い性能を示した。-> CNNを使って入力テキスト内のlocal patternをいい感じにモデル化できるから??
-
- 提案手法 DKN は、KPCNNを上回る性能を示した。
- 単語のsemantic表現と知識グラフのentity埋め込みをalginするKCNNによって、単語とentity間の関連性をより良い感じに抽出できている??
- ユーザのクリック履歴をattention層に通すので、多様なユーザの興味をより良い感じに捉えられている??
-
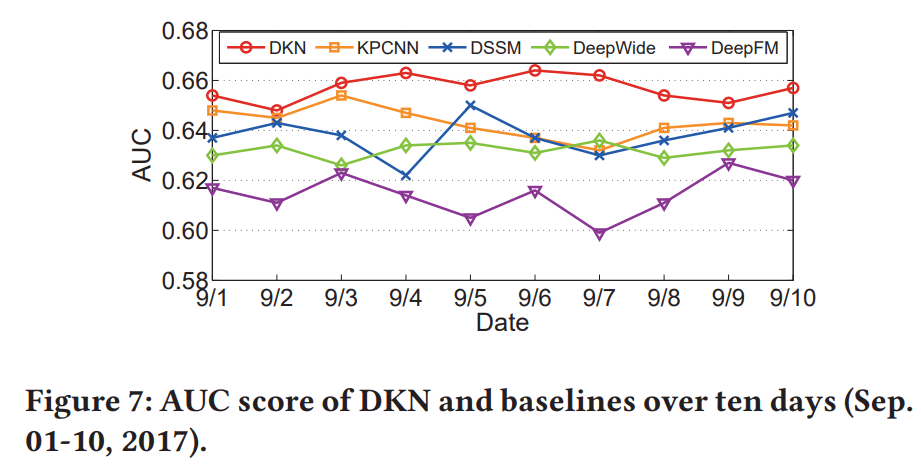
- また、図7は、テストデータよりも後の10日間のデータに対する予測結果を示したもの。
- DKNのAUCの推移は、10日間一貫してベースラインを上回っている。
- DKNの指標の変動性(分散)は、ベースラインと比較して小さい。
DKNの各componentの有効性の検証結果:
- DKNアーキテクチャの設計の有効性を示すために、以下の4つの側面に関してDKNのvariant間を性能比較してた:
-
- 知識グラフの使用(entity embeddingとcontextual embeddingをそれぞれ使うか否か)
- 結果: entity embeddingとcontextual embeddingを利用することで、AUCがそれぞれ1.3%と0.7%向上した。組み合わせることで更にAUCが改善された。
-
- 知識グラフの埋め込み方法の選択:
- 結果: DKN+TransDは他の翻訳ベースの手法よりも高いAUCを示した。
-
- 変換関数の選択 (線形関数 or 非線形関数):
- 結果: 非線形関数のほうが高いAUCを示した。(3種の埋め込みをマルチチャンネルにする際に、単語埋め込み空間とentity埋め込み空間の異質性をalignするための変換関数の話...!:thinking:)
-
- attention networkの使用:
- 結果: attention networkを使うことで、AUCが0.9%向上した。(ユーザ埋め込みを作り方の話。比較対象は、naiveにニュース埋め込みの平均値かな??:thinking:)
-
知識グラフに基づくentity埋め込みの効果の検証:
- 知識グラフによるentity埋め込みを使うことの効果を、直感的に理解するためのケーススタディ:
- 実験方法:
- 表4は、ランダムサンプリングしたユーザの、学習データ期間内とテストデータ期間内でクリックしたニュース一覧(positiveサンプルの一覧)。
- 一覧には、ユーザの関心がはっきり現れている: No.1-3は自動車に関するもの、No.4-6は政治に関するもの。
- 知識グラフの埋め込みを使用するver.のDKNと使用しないver.のDKNを学習させた。
- 学習後、サンプルユーザの学習ログとテストログ内の各ニュースペアの組み合わせをユーザ埋め込みmodule内のattention層に入力し、その出力値を監視した。
- 表4は、ランダムサンプリングしたユーザの、学習データ期間内とテストデータ期間内でクリックしたニュース一覧(positiveサンプルの一覧)。

- 結果(図8):
- 青が濃いほどattention value(=attention weight?)が高いことを意味する。(i.e. DKNがニュースペア間の関連性が高いと推論してることを意味するっぽい:thinking:)
- 知識グラフの埋め込みを使用しない結果(図8a):
- テストログ内の最初のニュース(1列目)はタイトル内に「Tesla」を含んでいるため、学習ログ内の自動車関連のニュースのうち、同じく「Tesla」を含むニュース(2, 3行目)に高い類似性を捉えられている。
- 一方で、テストログ内のもう一つの自動車関連ニュース(2列目)は、学習ログ内のどの自動車関連ニュースとも明確な出現単語の重複がないため、attentionが類似性を捉えることができていない。
- テストログ内の3列目のニュースも同様。
- 知識グラフの埋め込みを使用する結果(図8b):
- 図8aとは対象的に、attention networkが「車」と「政治」という2つのカテゴリ内の関連性を正確に捉えられていることがわかる。
- (semantic埋め込みだけじゃなくて、知識グラフに基づくentity埋め込みたちのおかげか...!:thinking:)
- 知識グラフ内では、自動車関連ニュースにおける「General Motors」や「Ford Inc.」は「Tesla Inc.」や「Elon Musk」と多くのcontextual entitiesを共有している。また、政治関連ニュースにおける「Jeh Johnson」「Russian」は「Donald Trump」とも結びついている。
- 図8aとは対象的に、attention networkが「車」と「政治」という2つのカテゴリ内の関連性を正確に捉えられていることがわかる。
- 図8の表の下側の値がクリック確率の予測結果を示している。
- 知識グラフありver.のDKN(図8b)はすべてのテストログを正確に予測したが、知識グラフなしver.のDKN(図8a)は3つ目のテストログで失敗した。(semantic埋め込みで捉えられる関連性のテストは成功しているが...!:thinking:)

(他にも、DKNのハイパーパラメータの選択に対するsensitivity analysis的な結果も報告されてた。)
次に読むべき論文は?
- 知識グラフとはあんまり関係ないけど、最近ABテストでより良い意思決定ができるように頑張りたくて、それ関連の論文を読んだりしてみてる...!
Discussion