Cloudflare Workersを中心とした、Cloudflareの開発者向け製品群(いわゆるCloudflareスタック)は、今やそれだけでちょっとしたサービスを生み出すことが不可能ではなくなってきています。
今回、システム構成をCloudflareスタックにほぼ全振りした新サービスをお仕事で作ったので、工夫した点を紹介します。
なお、本記事で紹介するサービスは7月4日に正式リリースしたばかりで、本格的なトラフィックをほとんど経験していない状態でこの記事を書き始めています。2ヶ月ほど運用した後での生の声は、8月25日に新潟で行われる、Cloudflare Meetup Niigataで講演枠をいただいてお話しする予定ですので、気が向いた方は新潟まで足をお運びいただければと思います。
他にも機会があれば登壇したいので、Cloudflare系のイベントにお誘いいただけますと幸いです!
キャラつくAI
今回リリースしたのは「キャラつくAI」というサービスです。
キャラつくAI
アンケートフォームに回答すると、その内容に応じてアバター画像を生成してメールで送信するサービスになっています。たとえば、筆者が次のように回答したとしましょう。
- 画風:ドット絵
- 生年月:1987年2月
- 性別:男性
- 興味のあること:お金・資産形成・資産運用、旅行
- お金の使い方:ついギャンブルやっちゃうな〜
- メールアドレス:****@*****
これを送信すると、だいたい30秒後くらいにメールが届きます。
ここで「生成したキャラを見る」のリンクを開くと、AIで生成したアバター画像が表示されます。
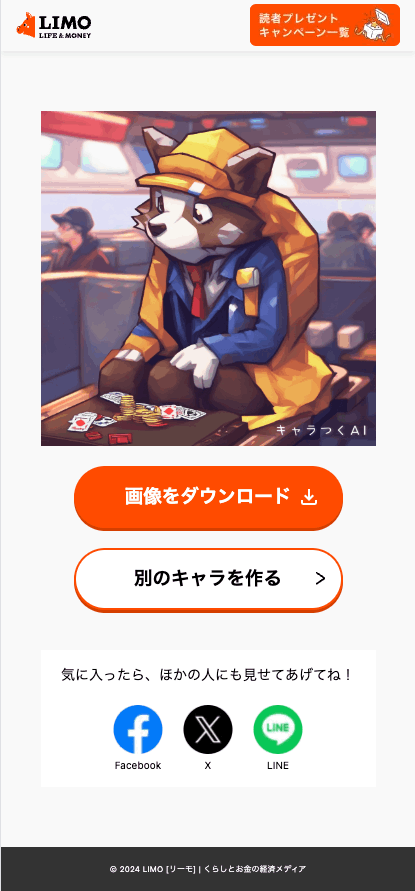
旅行中っぽい背景?のギャンブルをしていそうな感じ?のキャラが出てきました。素直に反映されていて何よりです。
この画像は好きに使っていただいて構いません。たとえばXのアイコンにしたり、ブログのプロフィール画像にしたり、使い道はいろいろです。
なぜ作ったのか
筆者が所属するモニクルグループでは、人々がお金について正しい意思決定ができる世の中を目指して、いくつかのサービスを展開しています。特に大きいものは、お金の診断・相談ができる金融サービスである「マネイロ」と、今回話題にしたい、くらしとお金に関する情報を提供する経済メディアである「LIMO(リーモ)」です。
LIMOは 月間1200万UU のトラフィックを持つ経済メディアで、くらしとお金に関する身近な情報を提供することで、読者さんがよりよいお金との付き合い方を考えるきっかけを提供しています。
キャラつくAIは、LIMOを見にきてくれた方に「AIのあるくらし」を少しでも身近に感じていただこうというコンセプトで開発しました。エモい話はプレスリリースのほうに書いてあるので、興味があれば読んでみてください。
「Webメディアが"ちょっと役立つエンタメ系ミニアプリ"を出してきた」という文脈で見ると、15年くらい前に見たことがあるような気がしなくもないですね。特に意識したつもりはなかった(本当になかった)のですが、リリースした後で「そういえばメディアとミニアプリの関係が○イリー○ータルZっぽいよね」ということに気がついて、ドンピシャ世代だらけの開発メンバー[1]がなんともいえない表情になりました。
システム構成
さて、そんなキャラつくAIですが、Cloudflareの開発者向け製品群(いわゆるCloudflareスタック)を活用して構築しました。ざっくりと次のサービスを使っています。
PagesでWebサイトを構築し、Queuesを経由して起動したWorkerの中でWorkers AIに画像生成をさせて、生成された画像をR2に保存したら、保存先のパスをD1に保存して、最後にメール送信を行う、といった流れになっています。
他にもいくつかのライブラリやサービスを利用しています。
- Remix:Webサイト構築
- Tailwind CSS:スタイリング
- Conform:フォーム制御
- Zod:バリデーション
- Kiribi:Queuesの管理
- SendGrid:メール送信
- Sentry:エラーログ収集
- Cloudflare LogPush:動作ログ収集
- Cloudflare Turnstile:Bot検知
順次必要に駆られて採用していった感じです。当初はHono + Tailwind CSSで進めていたのですが、フォームを快適に制御しようとするとHono + Zodはまだフォーム制御のツール整備が追いついていない感じがあったので、Conformが使えるRemixに切り替えました。これはHonoが悪かったのではなく、時期が早すぎただけで、Honoのフォーム周りはServer Actionsへの対応によって現在進行で改善が進んでいます。このプロジェクトがあと半年遅かったら、Honoのまま突き進めた可能性もあります。
初挑戦で思いの外よかったのがTailwind CSSでした。これまではMaterial UIやChakra UIを使うことが多く、Tailwind CSSは食わず嫌いしていたのですが、たまにはチャレンジしてみようかと思って採用したところ、予想外に快適でした。筆者はstylexのスタイリングに慣れている[2]のですが、stylexにプリセットされた小さいスタイル定義がたくさんあるとこういう感覚になるんだろうな、と思いながらtailwindを使っていました。
なぜCloudflareスタックなのか
さて、前述の通り、Cloudflareスタックをモリモリ使ったサービスになったわけですが、流行っているからというだけの理由で使ったわけではありません。社内的にはGoogle Cloudを使う場面の方が多く、金融サービス分野のシステムは大半がGoogle Cloud上で動いています。筆者もひとつ前に取り組んでいたプロジェクトでは、Cloud RunやCloud SchedulerをTerraformで耕すお仕事をしていました。手に馴染んでいる、という理由であれば、Google Cloudを使うべきなのです。
では、どうしてCloudflareに挑戦してみたのかというと、それは、 キャラつくAIがLIMOの派生サービス であるという立ち位置によるところが大きいです。平たくいうと、めっちゃトラフィックが来そうで怖かった、ということです。普通の0→1開発の文脈であれば、小さく始めて、プロダクトマーケットフィットが見えてきたら徐々にスケールアップしていく、という流れがよくあるところだと思います。しかし、キャラつくAIではそんなことは言っていられません。なぜなら、母体であるLIMOは月間1200万UUのアクセス数を誇る、それなりに大規模なWebメディアであり、そこから積極的にリンクを貼られるということを甘く見ることはできないからです。
Cloudflareスタック内の各サービスの選定理由
CDNのキャッシュを手軽に効果的に活用して、それなりのトラフィックが来ても低コストで抑えたい、という目論見から、Cloudflare Pagesの採用が真っ先に決まりました。すでに会社のドメイン管理がCloudflareになっていたため、各種設定が非常に容易だったことも大きいです。
サービスのキモとなるAI画像生成についても、いくつかの候補は検討しましたが、コスト面や運用面を考えると、Cloudflareに頼ってしまった方が楽だろうということで、Workers AIのText-to-Imageのモデルに頼ることになりました。現在はベータ版ということで価格設定はまだわからないというのが正直なところではありますが、既存のモデルの料金体系を見ている感じだと、めちゃくちゃ高くなることもないだろうということで採用しました。
画像生成をWorkers AIにやらせるのはいいのですが、処理時間やメモリ使用量が気になるところです。ドキュメントを見ると、HTTPで起動したWorkerは30秒以内に処理結果を返さないといけません。AIの画像生成自体は15〜20秒程度で終わり、その他の加工処理やメール送信まで含めても25秒程度で終わることが多いので、実はHTTPリクエストの範囲で処理してもいいのですが、稀に50秒くらいかかるケースもあるので過信はできません。Cloudflare Queues経由であれば、処理時間の制限が15分以内に緩和されるので、ちょっとくらい生成や加工に時間がかかっても大丈夫そうです。
D1やR2を採用したのはほとんど成り行きで、Workerからアクセスしやすいサービスがよいだろう、くらいの理由でした。D1に関してはデータベースのサイズ制限がありますが、キャラつくAIの場合、Queueを跨いでデータのやり取りをするための一時的なデータ置き場としての利用がメインで、古くなったデータは消してもよいので、特に問題はないと判断しました。
AI使うのめっちゃ楽だった
ここからは、実装上の感想や工夫についての話題を中心に書いていきます。
Workers AIを使うにあたって、どんな面倒ごとがあるのかとビクビクしていたのですが、結果的にはめちゃくちゃ楽でした。
- wrangler.tomlにWorkers AIへのバインディングを設定する
- バインディングの型定義(
Env)を書く-
AI: Aiみたいなやつ
-
-
env.AI.run()でAIを呼び出す
これだけです。公式ドキュメントの手順そのまんまですね。
セットアップが終われば、あとは次のようにAIを呼び出すだけです。
import { Ai } from '@cloudflare/workers-types';
export interface Env {
AI: Ai;
}
export default {
async fetch(request, env): Promise<Response> {
const response = await env.AI.run('@cf/stabilityai/stable-diffusion-xl-base-1.0', {
prompt: "がんばって研究した秘伝のプロンプト"
}
);
return new Response(response, {
headers: {
"content-type": "image/png",
},
});
},
}
簡単ですね。Envで使っている Ai 型にはちゃんと型が定義されていて、 run() の第一引数のモデル名に応じて、第二引数のオプションの型が変わるようになっています。基本的には prompt というキーでプロンプトを渡す使い方になりますね。ちまめさんの記事にもあるのですが、実は隠しパラメータとして negative_prompt が指定できそうという話もあります。弊社で検証したときには「あんまり……差がない……気がする……?」という結果になってしまったので、一旦使っていなかったのですが、意味がありそうならやっぱり使おうかなあどうしようかなあ(優柔不断)。
R2への保存には一工夫必要だった
前述の例のように、AIの生成結果をそのまま image/png なレスポンスとして返すだけならば、特に問題はありません。しかし、R2に保存する場合はひと工夫が必要になります。
素直に実装すると次のような形になります。
import { Ai, R2Bucket } from '@cloudflare/workers-types';
export interface Env {
BUCKET: R2Bucket;
AI: Ai;
}
export default {
async fetch(request, env): Promise<Response> {
const response: Uint8Array = await env.AI.run('@cf/stabilityai/stable-diffusion-xl-base-1.0', {
prompt: "がんばって研究した秘伝のプロンプト"
}
);
await env.BUCKET.put('hoge.png', response, {
httpMetadata: {
contentType: 'image/png',
},
});
return new Response();
},
}
AI.run() の結果は Uint8Array 型なので、型としてはそのまま BUCKET.put() に渡せます。しかし、実際には次のようなエラーが発生します。
Provided readable stream must have a known length (request/response body or readable half of FixedLengthStream)
なんか readable stream とか書いてあるので、念のため次のログを挟んでみました。
console.log('response instanceof ReadableStream?', response instanceof ReadableStream);
そうしたら response instanceof ReadableStream? true が出てきたので、データの実体はReadableStreamらしいです。とはいえそれでもおかしな話で、 BUCKET.put() は引数としてReadableStream型のデータも受け入れ可能なはずです。型の違いが原因ではありません。
となると、素直にエラーメッセージを読み取って「データ長がわからん」という問題に対処したほうがよさそうです。次のような変換処理関数を挟むことにしました。
async function streamToUint8Array(stream: ReadableStream): Promise<Uint8Array> {
const reader = stream.getReader();
const chunks = [];
// eslint-disable-next-line no-constant-condition
while (true) {
const { done, value } = await reader.read();
if (done) break;
chunks.push(value);
}
const totalLength = chunks.reduce((acc, chunk) => acc + chunk.length, 0);
const result = new Uint8Array(totalLength);
let position = 0;
for (const chunk of chunks) {
result.set(chunk, position);
position += chunk.length;
}
return result;
}
ReadableStreamから一度データを取り出して、長さが判明してから、長さを明示したUint8Arrayに詰め直しています。ChatGPTに書いてもらいました。
AI生成とR2保存のコードは、最終的に次のような形になりました。
import { Ai, R2Bucket } from '@cloudflare/workers-types';
export interface Env {
BUCKET: R2Bucket;
AI: Ai;
}
export default {
async fetch(request, env): Promise<Response> {
let response: Uint8Array = await env.AI.run('@cf/stabilityai/stable-diffusion-xl-base-1.0', {
prompt: "がんばって研究した秘伝のプロンプト"
}
);
// 念のためログを残す
console.log('response instanceof ReadableStream?', response instanceof ReadableStream);
// ReadableStreamだった場合だけ一旦変換する
// 将来的にはAI.run()の結果がUint8Arrayになったら動かなくていいはず
if (response instanceof ReadableStream) {
response = await streamToUint8Array(response);
}
const r2Object = await env.BUCKET.put('hoge.png', response, {
httpMetadata: {
contentType: 'image/png',
},
});
return new Response();
},
}
これで無事、R2に保存できるようになりました。筆者の使い方が悪そうな気もしつつ、ひとまず動いてるのでこれでヨシ!としています。
Service BindingsのRPCも慣れたら楽だった
D1アクセス用のWorkerを用意したり、AI用のWorkerを用意したり、なんだかんだでWorkerが増えてくると、Worker間の連携が煩雑になりそうですよね。他のWorkerをいちいちHTTP経由で(= fetch() で)呼び出していたら、確かに煩雑になりそうです。
今回は、自作のWorkerから自作のWorkerを呼び出す仕組みであるService Bindingsを活用することで、Worker間の連携をかなりスムーズに行うことができました。
Service Bindingsについての詳しい解説はchimameさんに譲ります。
上記の記事にもあるような、RPCによる呼び出しを行うことで、メインのWorkerからメソッド呼び出しを行う感覚で別のWorkerを利用することができました。
OGP画像はいい感じに作れた
キャラつくAIの生成結果のページには、SNSでシェアしたときに表示するためのOGP画像が設定されています。たとえば、Xでシェアすると次のような見た目になります。
この画像は、JSXで定義したHTMLからSVGを生成して最終的にPNG画像を作り出す、Vercel環境向けのパッケージである @vercel/og を応用することで実現しています。
そのままではCloudflare Pagesでは利用できないのですが、Cloudflare社からCloudflare Pages向けのパッケージが提供されていたので、こちらを使わせてもらいました。使い方については別の記事にまとめたので、興味があれば読んでみてください。
HTMLで画像生成ができるのが地味に便利なので、OGP画像以外の目的にも活用する道を検討しています。
Queues管理にKiribiを導入した
AIによる画像生成の処理時間を確保するために、Cloudflare Queuesを利用したのは前述の通りですが、キューを利用するにあたって、次のような管理を行いたいと思っていました。
- AIがベータ版ということもあり、失敗することを折り込んで、リトライを自動で行いたい
- Queuesもベータ版なのである程度の不安定さは想定され、キューアイテムの保持をQueuesに任せたくない
風の噂で「キューアイテムがたまに揮発する」といった話も耳にしていたので、これはRailsと一緒に使われるSidekiqみたいに、自前でキューアイテムを(D1か何かで)永続化して状態管理をする仕組みを作る必要があるかなと、設計初期に考えていました。
まあ未来の自分がなんとかするだろうと考えながら、AI周りのプロトタイピングを進めていたところ、上手いこと全く同じ課題感で作られたKiribiというライブラリを見つけました。
D1でキューアイテムを永続化してくれるし、リトライも自動でやってくれるし、Service BindingのRPCを活用していて使いやすいし、最高です。experimentalであることはやや不安でしたが、ソースコードは読めば読める感じでしたし、当初考えていた自作版をこの時点の筆者が実際に作ったところでKiribiの劣化版ができるだけなので、採用することにしました。
Kiribiについては作者の方が詳しく解説してくれています。
安心してQueuesを使えるようになったおかげで、サービスの安定性に期待が持てるようになりました。
SendGridのCloudflare Workers版がなかった
さて、キャラつくAIでは、画像生成の後の工程として、フォームで入力してもらっていたメールアドレスに完了通知を送るという処理を行なっています。メール送信に使うサービスについては、SendGridを採用しました。単純に社内の他のサービスで採用事例が多かったのが理由です。
割と楽観しながら選んだのですが、ひとつ大きな見落としがありました。それは、SendGridのCloudflare Workers向けライブラリがないということです。あった気がしたんですが覚え違いでした(てへぺろ)。最終手段としてREST APIを叩けばなんとかなるので、致命的というほどでもないのですが、まあライブラリがないのは不便です。
結論としては自作しました。といってもゼロから自作したわけではなく、Deno向けの実装を見つけたので、参考にさせてもらいました。Cloudflare WorkersもDenoもWeb標準に寄せたAPIを持っているので、概ね近い感覚で再実装することができました。
Sentryはちょっと頑張りが必要だった
エラー監視の環境も整えたいなということで、Sentryを導入しました。いつも使ってるから以上の理由はないです。
ここでも問題が起きました。RemixにSentryを組み込む方法は、公式ドキュメントで解説されています。
このまま進めればいいと考えていたのですが、大甘でした。ブラウザ上での動作に関しては、公式ドキュメントそのまま進めて大丈夫でしたが、問題はサーバー、つまりPages Functions上での動作です。 @sentry/remix のサーバーサイドの挙動はNode.jsを前提に作られているため、Cloudflare Workersの動作環境には対応していません.Cloudflare Workersに適した方法を別途用意する必要がありました。
キャラつくAIでは、Cloudflare Workers/PagesとSentryの連携方法を3つ採用しました。
- Workersのエラーをキャッチする
- Pages Functionsのエラーをキャッチする
- Pages Functionsで個別にエラーやメッセージを送信する
それぞれ解説します。
1. Workersのエラーをキャッチする
Workersでthrowされたエラーをキャッチする場合は、公式のインテグレーションを利用できます。Workersの「Integrations」タブの中にSentry連携があるので、こちらを有効にすればOKです。
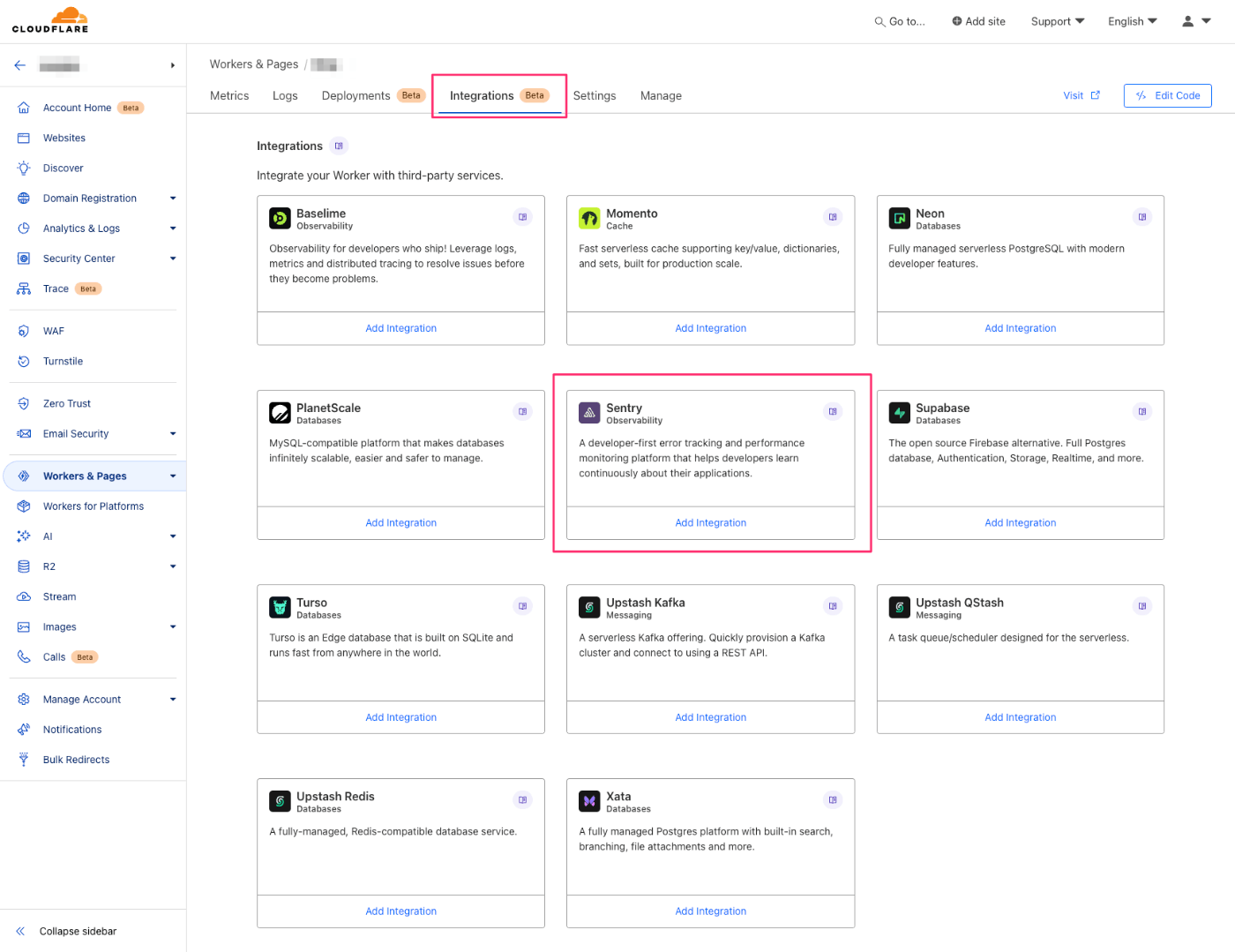
仕組みは次のドキュメントで解説されています。
このインテグレーションにより、監視用に新しいWorkerがひとつ自動で作られます。これはTail Workersというログ用のWorkerで、エラーの発生時にSentryへエラー情報を送信してくれます。
2. Pages Functionsのエラーをキャッチする
Pages Functionsにも公式の仕組みがあります。Sentry Pages Pluginです。
Pagesのプロジェクトに @cloudflare/pages-plugin-sentry をインストールして、Pages Functionsのミドルウェア機能の実装として functions/_middleware.ts を次のように実装すればOKです。
import sentryPlugin from "@cloudflare/pages-plugin-sentry";
export const onRequest: PagesFunction = sentryPlugin({
dsn: "https://sentry.io/welcome/xyz",
});
これを実装することで、Pagesへの全てのリクエストについてエラーをキャッチしてSentryに送信することができます。
3. Pages Functionsで個別にエラーやメッセージを送信する
さて、ここまでの実装で、意図せず発生したエラーはSentryに送信されるようになりそうです。これだけでもある程度は監視できそうですが、ユーザーが入力したフォームデータに入っていた異常値や、異常というほどではないが気になる挙動について、if文の中で captureMessage() でログを送っておきたい場面もありますよね。
ここでは公式ツールではないのですが、toucan-jsを利用します。
toucan-jsはCloudflare Workers環境向けのSentryライブラリです。Pages FunctionsとRemixで使う場合は、次のように実装します。
export function loader({ params, request, context }: LoaderFunctionArgs) {
const sentry = new Toucan({
dsn: "https://sentry.io/welcome/xyz",
context: context.cloudflare.ctx, // (1)
request,
});
sentry.captureMessage("Loader function called");
// ...
}
(1)の部分で一工夫が必要です。loader(またはaction)の引数で出てくる context は、Remixのコンテキスト情報です。toucan-jsはWorkersのコンテキスト情報を受け取るように作られているため、そのままでは渡すことができません。Workersのコンテキスト情報は context.cloudflare.ctx に格納されているので、これを渡すようにします。
手続き的にsentryを呼び出したい時は、toucan-jsを使うとよいでしょう。ちなみに @cloudflare/pages-plugin-sentry も内部的にはtoucan-jsを使っているようです。
Bot対策
最後に、皆さんに画像をたくさん生成してほしいながらも、Botによる不正利用は喜ばしくないので、Bot対策を導入しました。CloudflareのTurnstileを使って、Botを検知しています。これは当初、Cloudflareスタックの文脈で構成を考えている段階では導入する予定はありませんでした(というか存在を忘れていました)。完成間近になって、Bot対策をどうしようかと考えていたところ、Turnstileを見つけたので、導入した形になります。
いわゆるCAPTCHAのようなものです。次のようなチェックをどこかのサイトで見かけたことがあるのではないでしょうか。
これをフォーム内に設置して、フォームの送信データにTurnstileのパラメータを含めます。さらにサーバーサイドでパラメータの検証を行うことで、人間らしきユーザーからのリクエストであることを保証できるのです。
フォームへの埋め込みは次のライブラリを使うことで簡単に実装できました。
たまに人間判定に失敗して、チェックボックスのクリックを求められることもありますが、多くの場合は自動でチェックが終了するので、ユーザー体験も悪くないんじゃないかなと期待しています。
まとめ
Remixについては幾らか経験がありましたが、Cloudflareスタックを使った開発については初めての試みです。最終的に、Pages 1つとWorkers 5つを扱うことになり、それなりの規模の構成になったと思いますが、KiribiやService BindingsのRPCを活用したことで、快適に各サービスを連携させることができました。
高負荷に耐えられるかどうかはこれからに期待ですが、現時点でもコストの低さとデプロイの早さについては非常に満足しています。今後もチャンスを見つけて、Cloudflareスタックを活用していきたいと思います。これからも面白いサービスをたくさん作っていきたいので、CloudflareスタックによるWebサービス開発や、モバイルアプリ開発に興味がある方は、ぜひ一緒にやりましょう! カジュアル面談も受け付けていますので、お気軽にご連絡ください。XでリプなりDMなりをいただければOKです!
というわけで、どこまで行ったら動かなくなるのか見てみたいので、みなさんたくさんアクセスしてくださいね!(自殺行為)

Discussion
#R2への保存には一工夫必要だったの節で次のコードを提示していただいていますが、このコードは下のように書き換えることができます
改善前
改善後
ReadableStreamは非同期反復処理に対応しているので
for await ... ofを使うことができます。また、改善前のコードではUint8Arrayを生成するにあたって、全てのバイトチャンクの長さの合計を計算してその長さ分のUint8Arrayを確保してから改めてバイト列を詰め込む処理をしています。しかしこの処理を行うにあたって配列の走査が計2回(ストリームからの読み込み処理も合わせれば計3回)発生します。
Uint8Arrayは
.from()という静的メソッドを利用すれば既存のバイト配列から生成できるので冗長な処理を減らすことができますおーありがとうございます