『Goならわかるシステムプログラミング』をやっていく会 その2
2021/05/24(月) 120分
- 10.6 FUSE を使った自作のファイルシステムの作成 から
MEMO
- スクラップの投稿上限を引いてしまったww(400まで)
- ファイルシステムってつくれるんだ! という感覚が得られた(ただし、写経は失敗)
次回開催メモ
- 11章 プロセスの役割と Go 言語による操作 から
FUSE は インタフェース
Filesystem in Userspace (FUSE) はUnix系コンピュータオペレーティングシステム用のソフトウェアインタフェースである。権限を持たないユーザがカーネルコードを修正することなく独自のファイルシステムを作成できる機能を提供する
p. 202らへんから: S3のバケットをローカルのファイルシステムとしてつくるやつ(macOS)
$ go get gocloud.dev/blob
$ go get github.com/billziss-gh/cgofuse
$ go get github.com/aws/aws-sdk-go
code
package main
import (
"context"
"fmt"
"github.com/billziss-gh/cgofuse/fuse"
"gocloud.dev/blob"
_ "gocloud.dev/blob/s3blob"
"os"
)
type CloudFileSystem struct {
fuse.FileSystemBase
bucket *blob.Bucket
}
func main() {
ctx := context.Background()
if len(os.Args) < 3 {
fmt.Printf("%s [bucket-path] [mount-point] etc...", os.Args[0])
os.Exit(1)
}
b, err := blob.OpenBucket(ctx, os.Args[1])
if err != nil {
fmt.Println(err)
os.Exit(1)
}
defer b.Close()
cf := &CloudFileSystem{bucket: b}
host := fuse.NewFileSystemHost(cf)
host.Mount(os.Args[2], os.Args[3:])
}
10.6.1までの実行
# マウント用のディレクトリ
$ mkdir -p /tmp/cloudfs
$ go build oreore_filesystem.go
$ ./oreore_filesystem "s3://2021-05-24-gosys-filesystem" /tmp/cloudfs
macOSのプライバシーうんたらで許可しないといけない
ファイルシステムの自作をする、と言っているが、
何ができれば、ファイルシステムと言えるのだろうか
Google Drive Streamとか、DropBoxとかも、今回使ったようなFUSEみたいな感じっぽい。
Linuxコマンドで処理ができるっていうのがミソっぽい
2021/05/31(月) 120分
- 11章 プロセスの役割と Go 言語による操作 から
MEMO
- 11章を読む前に、 「プロセス」にまつわる興味を出したのがGood!
- プロセスってなんやねん! に対して、GoのAPIをみていく(Go言語視点からみていく)のは、単純かつ強力な作戦だと思う。
- プロセスはLinxuカーネルからみた実行単位、プロセスグループ(ジョブ)は、シェルから見た実行単位
- SUID便利〜 からの、ケーパビリティ
次回開催メモ
- 11.1.6 作業フォルダ から
プロセスは何で出来ているのか
- 何が無いと困るのか
- 何で生まれたのか
- 何で出来ているのか
ファイルシステムは、ファイルを抽象的に扱いたかったはず。
じゃあプロセスは? 何かを抽象的に扱いたかったのではないのか
スレッド、プロセス、タスク、これらの違いは?
プロセスはコンピューターシステムの中心となる概念なので、その存在をまったく無 視してシステムに関するプログラムを書くことはできません。本
きみ(プロセス)って何ができるんだい?
プロセスが自分の力でできるのは、単純な数値計算ぐらいです。
Q. 実効ユーザーID、実効グループID?
実行ファイル名と実行ファイルパス
package main
import (
"fmt"
"os"
)
func main() {
path, _ := os.Executable()
fmt.Printf("実行ファイル名: %s\n", os.Args[0])
fmt.Printf("実行ファイルパス: %s\n", path)
}
$ go build 11_1_1_execute_file_name.go
$ ./11_1_1_execute_file_name
実行ファイル名: ./11_1_1_execute_file_name
実行ファイルパス: /User/hoge/system-programming/chapter11/11_1_1_execute_file_name
$ ln -s 11_1_1_execute_file_name hoge
$ ll
total 4000
-rwxr-xr-x 1 mohira staff 1.9M May 31 21:42 11_1_1_execute_file_name
-rw-r--r-- 1 mohira staff 191B May 31 21:40 11_1_1_execute_file_name.go
lrwxr-xr-x 1 mohira staff 24B May 31 21:46 hoge -> 11_1_1_execute_file_name
$ ./hoge
実行ファイル名: ./hoge
実行ファイルパス: /Users/mohira/src/github.com/moks/system-programming/chapter11/hoge
プロセスグループ(ジョブ)は、シェルから見た実行単位
プロセスはLinuxカーネルからみた処理単位であり、ジョブはシェルごとの処理単位である
『Linuxの教科書』p.178
これこれ!
結局、プロセスIDさえあれば何でもできるんだけど、管理が激烈にだるいわけ。
複数のコマンド(≒プロセス)をつなげて、なんかの作業を実現するときとかね。
プロセスグループがない世界では、個々のプロセス二体いて、起動とか停止とかやーめた命令しないといけない(つらい)。
けど、プロセスグループがある世界では、「そのグループ停止だ!」ってのができる(楽だ)
という感じ。
プロセスグループ
パイプで繋げて実行された仲間が、1つのプロセスグループ(別名ジョブ)になるらしい。
本書には書かれてないけど、プロセスグループという概念でまとめておかないと、コマンドをkillしたい時などに、個別のPIDを全てkillするという事象が起きそう。
プロセスグループIDを見る方法
% cat | cat
% ps -eo pid,pgid,comm | grep cat
PID PGID COMMAND
4204 1848 cat
4205 1848 cat
106481 106481 cat
106482 106481 cat
プロセスグループIDをkillしてみる
kill 106481
% cat | cat
zsh: terminated cat |
zsh: done cat
プロセスグループID以外をkillする
kill 106482
特に何も起こらない
% cat | cat
何か入力して最初のコマンドの入出力が動くと、broken pipeとエラーが出る
% cat | cat
fdfd
zsh: broken pipe cat |
zsh: terminated cat
SUIDとは「Set User ID」の略で、誰がそのファイルを実行しても、セットされたユーザで実行されるという状態だ。
一般的にはUNIX系のOSでは,プロセスはroot権限(実効ユーザIDが0)で実行される特権プロセスと,一般ユーザ権限で実行される(実効ユーザIDが0以外の)非特権プロセスに分けられます。
"実効"は英語では、 Effiective だ!
// Getegid returns the numeric effective group id of the caller.
//
// On Windows, it returns -1.
func Getegid() int { return syscall.Getegid() }
2021/06/03(木) 90分
- 11.1.6 作業フォルダ から
MEMO
- Linuxにおける「タスク」という言葉の曖昧さよ!! → https://zenn.dev/mohira/scraps/ea040641f2f122#comment-20b3ea07af0894
- プロセスを理解するには、周辺の知識が必要 → 『ふつうのLinuxプログラミング』を読むといけそう!
- このへんの概念はまとめて攻略できそう!
次回開催メモ
- 11.5 exec.Cmd によるプロセスの起動
- 『ふつうのLinuxプログラミング』11.1 を読む!
1プロセスー1作業フォルダ
作業フォルダはプロセスの中で 1 つだけ持つことができます
これはなかなか特別っぽい。
スレッドとプロセスの関係 is 何?
マルチスレッドで動作するプログラムを作成しても、スレッドごとに別の作業フォルダを設定することはできません。
図を見ていると、プロセスの中に複数のスレッドがあるのでは?
スレッド、Goroutineとかもまとめて攻略できそう?
p.259
スレッドとはプログラムを実行するための「もの」であり、OSによって手配されるものです。
プログラムから見たスレッドは、「メモリにロードされたプログラムの現在の実行状態を持つ仮想CPU」です。この仮想CPUのそれぞれに、スタックメモリが割り当てられています。
一方、OSやCPUから見たスレッドは、「時間が凍結されたプログラムの実行状態」です。この実行状態には、CPUが演算に使ったり計算結果や状態を保持したりするレジスタと呼ばれるメモリと、スタックメモリが含まれます。
p.218
すべてのプロセスは、次の3つの入出力データを持っています。
- 入力:コマンドライン引数
- 入力:環境変数
- 出力:終了コード
この3つのデータは必ずどのプロセスにも含まれています。
特に例外もなく、絶対これはあるって覚えておけるので、良い抽象化
タスクマネージャのようなツールでは、プロセスIDと一緒にアプリケーション名が表示されています。
しかし、あるプロセスIDが何者なのかを知る方法は標準APIにありません。
これは意外っ!
この視点は良さげ! OSの存在意義とか目的をを考えたことなかった!
OS の仕事は、たくさんあるプロセスに効率よく仕事 をさせることです。
Linux ではプロセスごとに task_struct 型のプロセスディスクリプタと呼ばれる構造体を持っています。
初めて聞いた
Linux のカーネル開発者は「スレッド」や「プロセス」というかわりに、「タスク」という言葉をよく使う点に注意してください。
しかし、対外的なドキュメントには、プロセスという言葉を使います。
この2つの概念を理解する上では、それが「何か」を説明してもあまり意味がありません。「何のために」作られたかを知ることが大切です。
『ふつうのLinuxプログラミング 第2版』p.277
ほんと、これ!
2021/06/07(月) 120分
- 『ふつうのLinuxプログラミング』11.1 を読む!
MEMO
- 仮想CPUは「多面打ち」のたとえが暫定1位!
- 『ヒカルの碁』で院生試験を受ける前のヒカルはCPU
-
視点の切り替えが圧倒的に重要!
- CPUではなく、「プロセス視点でみるときにCPUがあればよい」という発想な!
- 『Linuxのしくみ』『ふつうのLinuxプログラミング』を併用するとめっちゃいい!
- 周辺の知識がつくとやっぱりいいよね(一般論)
- お絵かきはめっちゃ議論しやすい
次回開催メモ
- 11.5 exec.Cmd によるプロセスの起動
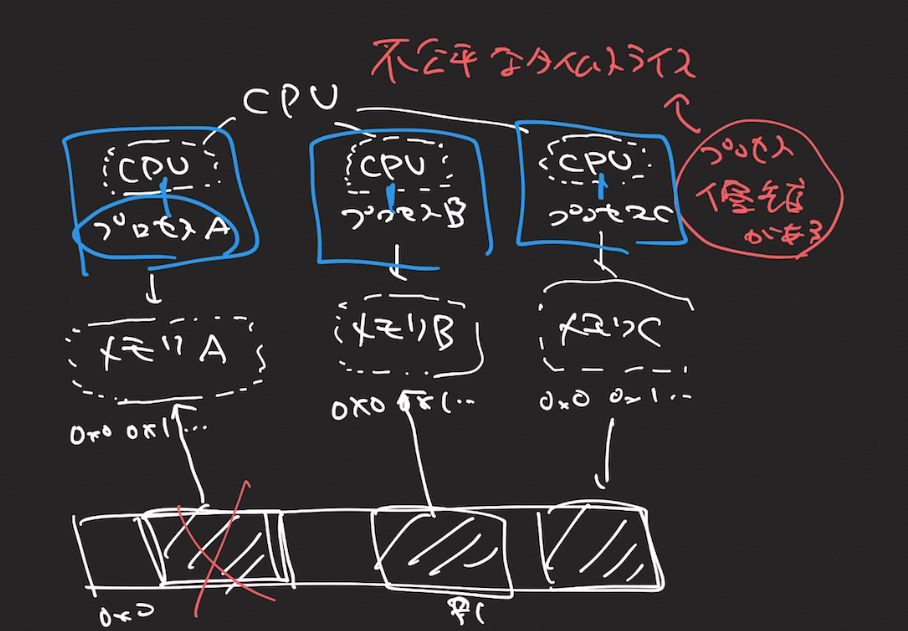
Linuxプロセスには、プロセスが複数同時に動作できる。これをマルチタスク
マルチプロセスと言わないんだ
プロセス視点から、CPUとメモリが専用であるように見せかける
「仮想CPU」と「仮想メモリ」
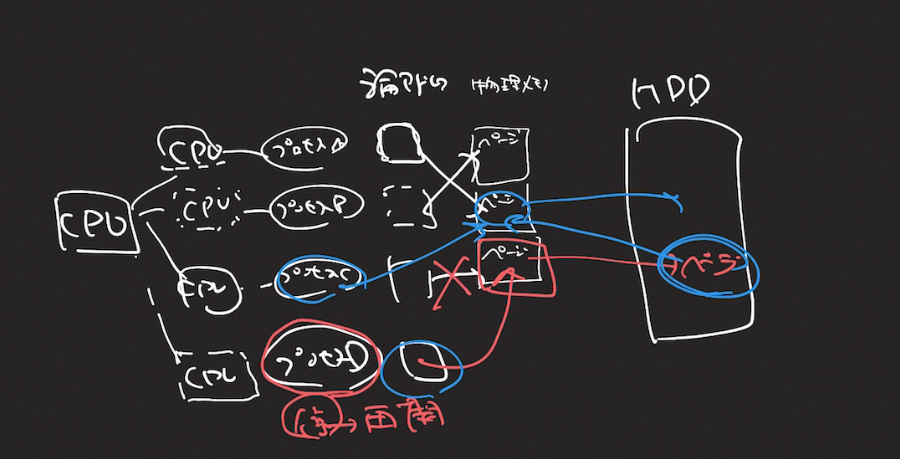
メモリマップトファイルが、物理メモリとファイルを同期することができる、ということがわかったが、
結局何に役に立つのかがわからない
スワップイン、スワップアウトを含めてスワッピングと呼びます。Linuxにおいては、スワップの単位がページ単位なのでページングとも言います。この場合は、スワップイン、スワップアウトも、ページイン、ページアウトと呼びます。
武内 覚. [試して理解]Linuxのしくみ ~実験と図解で学ぶOSとハードウェアの基礎知識 (Japanese Edition) (Kindle の位置No.2183-2185). Kindle 版.
仮想CPUは多面打ち!
2021/06/10(木) 120分
- 11.5 exec.Cmd によるプロセスの起動
MEMO
- プロセスの人間関係に迫れそうな予感! 2mmちかづいた!
- Goからプロセスいじりすると、属性とかメソッドで遊べるのでちょっとずつ理解深まる感じ
- プロセスに関係するシステムコールをみるとわかりそう
-
fork(2)とかexec(2)とか
-
- 親子生成過程が
fork(2)->exec(2)だけなのか?(そんなことはない気がするけど)
次回開催メモ
- 11.7 プロセスに関する便利な Go 言語のライブラリ
exec.CommandContextというのがコンテキストを引数でもらえるとのこと。
コンテキストってなんだろう?
、システム時間(カーネル内で行われた処 理の時間)とユーザー時間(プロセス内で消費された時間)を表示します。
消費された時間は実際の経過時間(ウォールクロック時間)
ExtraFiles は子プロセスに追加で渡すファイル。
プロセスの親子関係がわかってくると、もっとピンと来る?
親プロセスが子プロセスに引き継ぐ際に、何を引き継ぐのか? それがわかると、もっと理解できそう
問題1: fork()したらプロセスが使うメモリは倍になるのでしょうか。調べなさい。
forkするだけではメモリ使用量はほとんど増えません。 Linuxでは、forkした直後の2つのプロセスはほとんどの論理アドレスについて元の物理メモリを共有するからです。 どちらかのプロセスでメモリへの変更を行うと、そのとき始めて新しい物理メモリが割り当てられます。 この仕組みをCopy on Writeと言います。
コピーオンライトは次も見て!
知りたいこと: プロセスの人間関係とその生成過程
1. $ ls | cat とかのいわゆるパイプのコマンド使ったときの、プロセスの生成過程
こっちは、親子じゃなくて、プロセスグループ(ジョブ)のはず。
でも、システムコールがよくわかんない感じ。
2. 親プロセスと子プロセスが生まれる流れをシステムコールでみたい
あわよくば実験したい。
fork(2) -> exec(2) で解決してるのか?
3. dup(2) と fork(2) の違い
4. ってか、そもそもプロセスを複製したり、親子関係があったりするのはなんでなん? 複数のプロセスを用意したいモチベーションは? 無関係の単一プロセスがいっぱいあるのだと何かだめなの?
このへんが参考になりそう?
これ読んでくれ ここに求めている答えがあった
2021/06/14(月) 120分
- 11.7 プロセスに関する便利な Go 言語のライブラリ
MEMO
- exec属の命名規則の衝撃
- argv の v の衝撃
- fork()->exec()のコンボ
- 高速化の作戦として、スレッドベース vs プロセスベース?
- スレッドをわかりたい!!!
- グローバルインタプリタロック
次回開催メモ
- 11.8.3 デーモン化から
ANSIの発音が謎
ANSI(米国標準協会――American National Standards Institute)
擬似端末への文字列出力時のエスケープシーケンスは、 Windows と POSIX 系 OS では互換性がない部分のひとつです
WindowsとPOSIX系は別っぽい。
ANSIに則っていない??
せっかくの標準協会とは??
p.232 pipeになる例を見るとわかりやすいと思う
package main
import (
"fmt"
"os/exec"
)
func main() {
cmd := exec.Command("./check")
output, err := cmd.Output()
fmt.Println(string(output))
if err != nil {
panic(err)
}
}
$ go run pty_not.go
stdin: pipe
stdout: pipe
stderr: pipe
Linux は clone と unshare と いうシステムコールで子プロセスを作ります。
exec属(ファミリー)の命名規則
末尾の文字の命名規則は単純です。
lおよびvはパラメータがリスト(list)または配列(vector)かを表します。
pは渡したコマンド名がフルパス(fullpath)という意味です。
コマンドがユーザのPATH環境変数に含まれている場合では、pのインタフェースに単なるファイル名を渡すことも可能です。
eは新規プロセスに新たな環境(environment)も渡すことを意味します。『Linuxシステムプログラミング』 p.136
Vectorはデータを連続したメモリに保持している。
インデックスでのアクセス。
listは要素ごとにデータの前後の要素へのポインタを持っている
プロセスのfork()->exec()の流れは、生物で考えるとかなりクレイジーな状況
親から親と全く同じものが生まれて、直後に子供になるということ!!!
プロセスの新規作成には別のシステムコールを使用します。新規プロセスの初期状態は親プロセスの複製 ですが、すぐに別のプログラムを実行するのが一般的です。
え、もしかして、argv って ARGument Vector ってこと!?!??!
衝撃
わからん! p.234
フォークには、「複数のスレッドが存在しているときでも、fork() を呼び出した スレッド以外はコピーされない」という落とし穴があります。
Goでfork()するのはできないよ
各処理がどのスレッドで実行されているかを把握する必要は ありませんし、ブラックボックス化されているので実際の OS スレッドを制御する機 能はほとんど提供されていません。そのため、Go 言語のランタイムでは、fork() を カジュアルに利用するようなコードを気軽に動かすことはできません。
Q. ネイティブスレッド?
スクリプト言語では、インタプリタ内部のデータの競合が起きないようにグローバルインタプリタロック( GIL 、 Global Interpreter Lock )
知らなかった。
これは単一のスレッドしか動かないことを意味しているっぽい
2人がかりで倍遅い
Q. 並行処理 スレッドベース vs プロセスベース?
The new gc.freeze() function allows freezing all objects tracked by the garbage collector and excluding them from future collections. This can be used before a POSIX fork() call to make the GC copy-on-write friendly or to speed up collection. The new gc.unfreeze() functions reverses this operation. Additionally, gc.get_freeze_count() can be used to obtain the number of frozen objects. (Contributed by Li Zekun in bpo-31558.)
定期) スレッドって誰ですか?
『ふつうのLinuxプログラミング』のp.403より。
スレッドはプロセスに似ていて複数の作業を同時に行えるようにする仕組みですが、大きく違う点が1つあります。
それは、メモリ空間が分かれていないところです。
物理メモリを共有しているってことかな?
つまり、プロセス間通信機構を使うことなく直接データを共有できるのです。
プリフォークやマルチスレッドは『ふつうのLinuxプログラミング』のp.403みて!
2021/06/21(月) 180分
- すーぱー雑談回
MEMO
「興味」の話
- 「関心事」って言葉よりも「興味」って言葉のほうが捉えやすい話
- 「責務」って言葉意味分かんない問題は、説明側の敗北である発想
- 日本人にとっての責任は、英語におけるResponsibilityとはストレートに対応してない説
- 「責務」が正しいかどうかは、「やりたいコト」が明確でないといけない
- 責任をはたさない「審判」; 得点もファールも管理しない
- 「審判失格だな」とか「責任問題だ!」ってフレーズを使うよね
「日本語圏の興味 と 英語圏の興味」は違う。これは文字列操作の実装をみればいい
- もし、日本語がグローバルな言語だったら、
str.capitalize()は存在しなかった説- 日本語は大文字と小文字の概念がない == 興味がない
- アルファベット圏だから、実装されたメソッド == 向こうの人にとっては興味のあること
-
title()にしたいってのも、日本語圏ではありえない需要だと思う - もし、日本語がグローバルな言語だったら、
str.capitalize()は別パッケージになっていた説-
alphabet_processing.capitalize()とかね
-
やりたいコトが大事。できるコトはその次。興味からはじめよ。
- やりたいコトから考える。できるコトからは考えない。
- 「できるコト」は必ずしも「やりたいコト」ではない(みんなもそうでしょ?)
- プログラマは「できるコト」をかんたんに増やせるから、問題になるわけで。
- とりあえずスキルをセットしまくるみたいなことは良くない状態
- 「やりたいコト」が「できるコト」であるといいよね! ← この状態がいい状態!
- 「やりたいコト」 と 「できるコト」が一致する状態がベスト
- やりたくないし、できない ← どうーでもいい
- やりたくない(やる必要がない)けど、できる ← ここがマジで厄介!
- やりたいけど、できない
- やりたくて、できる ← 最強
- プログラマーは、「プログラムに能力を与える」という能力が高いので、厄介なことになるわけで!
- プログラマは「できるコト」をかんたんに増やせるから、問題になるわけで。
- もし、メソッドの追加がとてつもなく難しい作業なら、こうはならないはず。そんなポンポンなぞメソッドが生えまくることはにはならない(だから、きっと設計を頑張るのか?)
プログラミングの単位を考えよう
- 単位がわかると、表現力が高まる
- 「プログラミングの単位」
- 「業務の単位」
- 「ボールジャグリングの単位」
ストーリーとか
- ストーリーの分割
- ストーリーはユーザーにとって嬉しいことが生まれる単
- ストーリーは独立性が高いと嬉しい
- 独立性の高いストーリーに分割する方法は?
- リリース時の「影響」を考える
- ユーザーにとっての不利益
- ユーザーからの反応(ポジネガ両方)
- 後工程のメンバー負担 (一度に追加される新機能が少ないほうが、カスタマーサポートの負担も減るよね)
- 瞬間の変化量が少ない方が、後工程にとっても嬉しい説?
- 感情と論理を切り話そう
- 感情は取っ掛かりとしては優秀!
- ただし、論理も用意すること
- 自転車の置き場の議論にならないように
次回開催メモ
- 11.8.3 デーモン化から
関心事 → 興味 と言い換えるのは良い。
ユーザーの価値 → ユーザーの興味あるもの と考えると、分かりやすい
不完全な設計でも良いからストーリーを実現したものを素早く出す。
ストーリーで定義した、「ユーザーのやりたいコト」に焦点を合わせた結果である。
不完全は素朴な設計。
設計の議論ってめっちゃくちゃ深堀りしやすいし、広がりやすいので、もっと「ユーザーのやりたいコト」にフォーカスして議論して作るのは大事
ストーリーの独立性が大事。
粒度も大事(1つのイテレーションで終わることが出来るかぐらい)。
うまいストーリーの切り方
- CRUDで切る
- プロパティごとで切る
- バリデーションなどの便利機能は後で実装する
ボールを手で持つことは、任意の場所にボールを固定する。
これは良い抽象化。
リストを空リストから始めるに近い
なんで近くストーリーを小さくするのかっていう話。
小さくリリースができるのが良いよね。
なんで小さくリリースするかというと、不具合があったときに修正がしやすい。

2021/06/28(月) 120分
- 11.8.3 デーモン化から
MEMO
- fork() と exec()
- 擬似的なシェルを実装するとよくイメージがつかめた!(定義じゃなくて
- C言語でやるとめっちゃ分かる
-
strace -fでfork()の動きがわかる -
unfinishedとresumedから感じる並行処理!
- デーモン
- 制御端末を持たないセッション
- セッションとプロセスグループの存在意義
次回開催メモ
- 12章から
forkの動きを確認する
unfinishedとresumedは、各プロセスがCPUを細切れにして動かしているので、発生している
#include "sys/types.h"
#include "stdio.h"
#include "unistd.h"
int main() {
fork();
printf("プロセスid=%d\n", getpid());
}
execve("./single_fork", ["./single_fork"], 0x7ffc5a7218f8 /* 54 vars */) = 0
brk(NULL) = 0x562d80638000
arch_prctl(0x3001 /* ARCH_??? */, 0x7fff96d82040) = -1 EINVAL (無効な引数です)
access("/etc/ld.so.preload", R_OK) = -1 ENOENT (そのようなファイルやディレクトリはありません)
openat(AT_FDCWD, "/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
fstat(3, {st_mode=S_IFREG|0644, st_size=102291, ...}) = 0
mmap(NULL, 102291, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7f641e232000
close(3) = 0
openat(AT_FDCWD, "/lib/x86_64-linux-gnu/libc.so.6", O_RDONLY|O_CLOEXEC) = 3
read(3, "\177ELF\2\1\1\3\0\0\0\0\0\0\0\0\3\0>\0\1\0\0\0\360q\2\0\0\0\0\0"..., 832) = 832
pread64(3, "\6\0\0\0\4\0\0\0@\0\0\0\0\0\0\0@\0\0\0\0\0\0\0@\0\0\0\0\0\0\0"..., 784, 64) = 784
pread64(3, "\4\0\0\0\20\0\0\0\5\0\0\0GNU\0\2\0\0\300\4\0\0\0\3\0\0\0\0\0\0\0", 32, 848) = 32
pread64(3, "\4\0\0\0\24\0\0\0\3\0\0\0GNU\0\t\233\222%\274\260\320\31\331\326\10\204\276X>\263"..., 68, 880) = 68
fstat(3, {st_mode=S_IFREG|0755, st_size=2029224, ...}) = 0
mmap(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f641e230000
pread64(3, "\6\0\0\0\4\0\0\0@\0\0\0\0\0\0\0@\0\0\0\0\0\0\0@\0\0\0\0\0\0\0"..., 784, 64) = 784
pread64(3, "\4\0\0\0\20\0\0\0\5\0\0\0GNU\0\2\0\0\300\4\0\0\0\3\0\0\0\0\0\0\0", 32, 848) = 32
pread64(3, "\4\0\0\0\24\0\0\0\3\0\0\0GNU\0\t\233\222%\274\260\320\31\331\326\10\204\276X>\263"..., 68, 880) = 68
mmap(NULL, 2036952, PROT_READ, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0x7f641e03e000
mprotect(0x7f641e063000, 1847296, PROT_NONE) = 0
mmap(0x7f641e063000, 1540096, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x25000) = 0x7f641e063000
mmap(0x7f641e1db000, 303104, PROT_READ, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x19d000) = 0x7f641e1db000
mmap(0x7f641e226000, 24576, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x1e7000) = 0x7f641e226000
mmap(0x7f641e22c000, 13528, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0) = 0x7f641e22c000
close(3) = 0
arch_prctl(ARCH_SET_FS, 0x7f641e231540) = 0
mprotect(0x7f641e226000, 12288, PROT_READ) = 0
mprotect(0x562d7f9b2000, 4096, PROT_READ) = 0
mprotect(0x7f641e278000, 4096, PROT_READ) = 0
munmap(0x7f641e232000, 102291) = 0
clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLDstrace: Process 24364 attached
, child_tidptr=0x7f641e231810) = 24364
[pid 24363] getpid() = 24363
[pid 24363] fstat(1, <unfinished ...>
[pid 24364] getpid( <unfinished ...>
[pid 24363] <... fstat resumed>{st_mode=S_IFCHR|0620, st_rdev=makedev(0x88, 0x2), ...}) = 0
[pid 24364] <... getpid resumed>) = 24364
[pid 24364] fstat(1, <unfinished ...>
[pid 24363] brk(NULL <unfinished ...>
[pid 24364] <... fstat resumed>{st_mode=S_IFCHR|0620, st_rdev=makedev(0x88, 0x2), ...}) = 0
[pid 24363] <... brk resumed>) = 0x562d80638000
[pid 24363] brk(0x562d80659000) = 0x562d80659000
[pid 24363] write(1, "\343\203\227\343\203\255\343\202\273\343\202\271id=24363\n", 21プロセスid=24363
) = 21
[pid 24364] brk(NULL <unfinished ...>
[pid 24363] exit_group(0 <unfinished ...>
[pid 24364] <... brk resumed>) = 0x562d80638000
[pid 24363] <... exit_group resumed>) = ?
[pid 24364] brk(0x562d80659000) = 0x562d80659000
[pid 24363] +++ exited with 0 +++
write(1, "\343\203\227\343\203\255\343\202\273\343\202\271id=24364\n", 21プロセスid=24364
) = 21
exit_group(0) = ?
+++ exited with 0 +++
デーモンは独立心が強いのだ!
デーモンプロセスは、制御端末を持たないプロセス
ps -ef で TTY列が ? になっているやつ
『ふつうのLinuxプログラミング』を読むとめっちゃ理解進むよ! 12章らへん。
fork() と exec()の疑問
- 自分が普段イメージしているexecとexec()システムコールの動きがあまり合っていない
- exec()システムコールは、今までのプロセスから別のプロセスに変化して実行する
- サブプロセスを立ち上げる時に、fork() → exec() となるのがよくわからない
- fork()で親プロセスをコピーしてから、exec()をするより、新しいプロセスを作るようなシステムコールがあればいいのでは?
- コピーオンライトで資源を節約したいから、最初はコピーしておくということなのかもしれない
なぜ、わざわざ forkしてからexecするのか?
一見、無駄に見える。つまり、コピーなどせずに、実行したいプロセスをつくっちゃえばいいじゃん! という感じ。
でも、実際には、forkしている。
いまんところの仮説はこう。
プロセスにはいろんな属性がある(ディレクトリとかどのメモリ空間を使うとか)で、そういった情報がゼロからセットするのは、リソース的に非効率。たいていは、コピーで十分だったりしそう。
だから、まずコピーする。で、変えたいところだけ変える。
この戦略がお得というわけ。
たぶん、そう。
2021/07/05(月) 100分
- 12章から
MEMO
- zshの脅威!!!
- シグナルの理解がふかまーる
- とにかく、プロセスに何かを通知する
- そんで、割り込む!
- 突然来るし、ハンドリング中にも来るかもしれない
- SIGPWRみたいなのは利便性をイメージしやすい
次回開催メモ
- 12.4.4 シグナルを他のプロセスに送る
Q. シグナルって何?
killコマンドとかCtrl-Dとか?
ターミナルで、プロセス止めるときのアレ的なそれ?
SIGHUP :通常は、後述するコンソールアプリケーション用のシグナルだが、「ターミナルを持たないデーモンでは絶対に受け取ることはない」ので、サーバーアプリケーションでは別の意味で使われる。
あまり解せない感がある。
本当は別のシグナルを使うべきだったのでは?
Signals have always been a convenient method of inter-process communication (IPC), but in early implementations there were no user-definable signals (such as the later additions of SIGUSR1 and SIGUSR2) that programs could intercept and interpret for their own purposes. For this reason, applications that did not require a controlling terminal, such as daemons, would re-purpose SIGHUP as a signal to re-read configuration files, or reinitialize. This convention survives to this day in packages such as Apache and Sendmail.
シグナルは常にプロセス間通信(IPC)の便利な方法でしたが、初期の実装では、プログラムが独自の目的で傍受して解釈できるユーザー定義可能なシグナル(SIGUSR1とSIGUSR2のその後の追加など)はありませんでした。このため、デーモンなどの制御端末を必要としないアプリケーションは、SIGHUPを構成ファイルの再読み取りまたは再初期化のシグナルとして再利用します。この規則は、ApacheやSendmailなどのパッケージで今日まで存続しています。
killはkillだけじゃないよ〜
$ man kill
NAME
kill -- terminate or signal a process
シグナルは、伝えたい相手はプロセスくん!
とにかく、プロセスにメッセージを送りたいときに使うんだなぁ〜(プロセス間通信)
そして、特定の挙動をトリガーとして、カーネルからシグナルが送られるようになっているので、それは便利的な? (SIGPWRとか、SIGINTとかいろいろ)
他のプロセス間通信と違って、処理に割り込むってところが、シグナルの輝きポイント! だと思う。
割り込みが必要ないのなら、別に、パイプとか他のIPCでええやん?(しらんけど
Q. ってか、「割り込み」って何?
シグナルと例外処理って実は同じでは?
シグナルがプロセスに対して配送されると割り込みが発生し、今までの作業を中断する。
デフォルト動作だと無視したり、終了したりする。
場合によっては、特定のシグナルが来た場合は特定の処理を行なうように補足することも可能。
↓
これは、いつもよくある例外処理と変わらないんじゃない? っていう気持ち。
でも、例外処理っていうのは来ることを予測した上で処理内容を書くから、ぶっちゃけif文に近くないか。
割り込みとはちょっと違う気がする
シグナルはOSから来るイベント通知
- 例外とはまた別というか、意味が広い感じ。
- ウィンドウサイズの変更とか、コンティニューとかもシグナルにあるので、OSレベルから来るイベント通知っぽい
プロセスのスケジューリング と シグナル ってなんか関係あるのかな? ないのかな?
どっちかな?
AbortとHungup
Abortは明示的にプロセスを中止するに近いニュアンス。
Hungupは意図せずプロセスが停止したりする、偶発的なニュアンス。
シグナルは厄介、あと、グローバル。つまり、大変。
package main
import (
"fmt"
"os"
"os/signal"
"syscall"
)
func main() {
// サイズが1より大きいチャネルを作成
signals := make(chan os.Signal, 1)
signal.Notify(signals, syscall.SIGINT, syscall.SIGTERM)
s := <-signals
switch s {
case syscall.SIGINT:
fmt.Println("SIGINT")
case syscall.SIGTERM:
fmt.Println("SIGTERM")
}
}
$ go build main.go
$ ./main.go
# 別ターミナル
$ pkill -TERM main # SIGTERM 送信
$ pkill -INT main # SIGINT 送信
zshの便利機能!
あーん?!?!?!

killコマンドは、あくまで「シグナル送信」のコマンド
デフォルトがSIGTERM送信なだけだった!
そして、SIGTERMとかいうシグナルの、デフォルト挙動が「終了させる」だった。
だから、
$ kill -INT pid # SIGINTを送る
$ kill -HUP pid # SIGHUPを送る
$ kill -PWR pid # SIGPWRを送る
シグナルは、非同期かつ片方向の通信方向
『Linuxシステムプログラミング』p.18より。
この説明がわかりやすいな!
シグナル(signal)とは非同期片方向の通信方法です。
カーネルからプロセスへ送られる場合もありますし、プロセスから他のプロセスへ、またプロセス自身へ送られる場合もあります。
通常、シグナルは、アクセス違反(segmentationfault)やユーザが割り込みキー(Ctrl-C)を入力したなど、何らかのイベントをプロセスへ通知するために使用します。
p.289
シグナル(signal)はソフトウェア割り込みの一種で、非同期イベントを処理する仕組みです。
非同期イベントは、ユーザが割り込みキー(通常はCtrl-C)など外部から発生させることも可能ですし、また0による除算を実行するなどプログラムやカーネル内で発生することもあります。
プロセス間通信(IPC、interprocesscommunication)の基本機能の1つとして、プロセスから他のプロセスへシグナルを送信することも可能です。
2021/07/12(月) 150分
- 12.4.4 シグナルを他のプロセスに送る
MEMO
- 宿題
-
atomic.AddInt32のコードをみつける(アセンブリのやつ) - httpサーバーで数がズレるやつを実演する
-
- Graceful Shutdown(グレイスフルシャットダウン)
- Goroutineの威力がわかった! 並行処理を書くのが楽だ!
- SIGTERMとSIGKILLの違い
- Macだと、子プロセスが終了しない説!? (未検証
-
xargsテクニックありがたい! -
cmd.Start()はプロセスを実行して、処理の終了を待たない(cmd.Run()は待つ) - 「シグナル」という仕組みをしっておくと色々見えてくる感じがあるな。
- 例えば、ファイルを保存せずに終了しようとすると「保存してないけど、どうする?」って出てくるけど、あれもシグナルを活用しているわけですやん。
次回開催メモ
- 12.6 Go 言語ランタイムにおけるシグナルの内部実装
Contextとは
並行処理らへんで出てくるやつ
Atomicな処理とは
Transactionで囲いたい処理。
それ以上分解できない処理。
i++
これは、高級言語内ではAtomic処理と言えるが、
アセンブリ的には3ステップ
この処理がAtomic自体かどうかはContextによる
package main
import (
"fmt"
"os"
"os/exec"
)
func main() {
cmd := exec.Command("sleep", "300")
// cmd.Startはプロセスを実行して、処理の終了を待たない(cmd.Run()は待つ)
err := cmd.Start()
if err != nil {
panic(err)
}
fmt.Printf("%d\n", cmd.Process.Pid)
cmd.Process.Signal(os.Kill)
}
Go の標準の機能では SIGKILL がカジュアルに送信されますが、 SIGKILL は受け取り側でハンドリングできず、強制的に終了させられるシグナルです。また、そのプロセスがさらに子プロセスを持っていた場合、それらのプロセスまでは終了せず、生き残り続けます。
そうなの?
プロセスグループIDを潰すだけじゃダメなのか
プロセスを終了したい場合には、いきなり SIGKILL を送信するのではなく、まずSIGTERM を送信し、プログラム側に自分で終了処理を行わせるのが行儀の良い方法です。
SIGTERM自体を使いたい理由としては、補足ができるからかな
SIGTERM と SIGKILL の重要な違い
子プロセスがあると、SIGTERMでは親プロセスは落ちない? Macだから?
xargs -n3 便利!
$ kill -l | xargs -n3
HUP INT QUIT
ILL TRAP ABRT
EMT FPE KILL
BUS SEGV SYS
PIPE ALRM TERM
URG STOP TSTP
CONT CHLD TTIN
TTOU IO XCPU
XFSZ VTALRM PROF
WINCH INFO USR1
USR2
xargsであそぶ
$ echo "a,b,c" | xargs -d, -n1
a
b
c
sync/atomicを体感するコード
package main
import (
"fmt"
"net/http"
"sync/atomic"
"time"
)
func main() {
var (
count1 int
count2 int32
)
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
x := count1 + 1
time.Sleep(30 * time.Millisecond)
count1 = x
count2 = atomic.AddInt32(&count2, 1)
fmt.Fprintln(w, count1, count2)
})
http.ListenAndServe(":8080", nil)
}
アトミックな処理って始めて覚えた
2021/07/19(月) 120分
- 12.6 Go 言語ランタイムにおけるシグナルの内部実装
MEMO
- 12章おわり!
- 久々に説明暴走機関車したw
- 並行処理と並列処理
- 並列処理の話をするときは、コアの話が必要
- スレッドをコアに割り当てる感覚がよい感じ
- クロージャ
- CPUバウンド、I/Oバウンド、お風呂バウンド、電子レンジバウンド
- 電子レンジの性能(ワット数) と CPUコア性能 の対比がわかりやすい説
次回開催メモ
- 13.3 スレッドと goroutine の違い
マルチスレッドのプログラムでは、リソースアクセス時にロックを取得する スレッドがどれかわからないと容易にブロックしてプログラムがおかしくなってしま うため、シグナル処理用のスレッドとそれ以外のスレッドを分けるのが定石です。
へ〜
この12.6,全然わかんなかった!
でもとにかく、マルチスレッドプログラミングでは、シグナル受け取り専門スレッドくんを作るのが良いらしいよ!
本章では、強制力が高いプロセス間通信の手法であるシグナルを紹介しました。
強制力の高さ!
12章おわり!
並行と並列
並行: CPU 数、コア数の限界を超えて複数の仕事を同時に行う
マルチプロセスやマルチスレッドで、スレッドを増やして複数の仕事を行なう。
各スレッドが仕事をその一時的な処理内容を覚えている
13.3 スレッドとgoruoutineの違いで言っていた、OSから見たスレッドは「時間が凍結されたプログラムの実行状態」
並列:複数の CPU 、コアを効率よく扱って計算速度を上げる
複数のCPUに、スレッドでやっている仕事内容を分散させて、効率よく仕事を行なう
宿題
1コアのものと2コアのコンテナを立てて、並行性を確認してみる
嬉しいタイミング
CPUにおける処理時間が大きい場合(ユーザー時間が支配的な場合)は並列、
I/O 待ちなどで CPU が暇をしているときは並行で処理するというのが基本です。

お風呂バウンドな処理
お風呂にお湯を入れている間は、「ヒマ」なので、別の仕事をしたほうがお得。
並行処理の嬉しいときはそういうときだよね。
他にも、電子レンジバウンドな処理もある。
time.Sleepで待たないと、goroutineの値が実行されない
package main
import (
"fmt"
"time"
)
func sub1(c int) {
fmt.Println("share by arguments:", c*c)
}
func main() {
go sub1(10)
c := 20
go func() {
fmt.Println("share by capture", c*c)
}()
// time.Sleep(time.Second)
}
func() int はint型の値を返す関数を返す
func fibonacci() func() int {
…
}
2021/07/22(月) 160分
- 13.3 スレッドと goroutine の違い
MEMO
- スレッドとプロセスの違いを見極めるコーナー
- C言語の
pthreadで遊んだ - PyCharmのProfileが強力!
- 実は、600文字進んだ!(1ページ未満っw)
- 同期と非同期、ブロックとノンブロッキング、並行と並列、プロセスとスレッド がごちゃまぜになりがち
次回開催メモ
- 13.3 スレッドと goroutine の違い
Linuxカーネルはスレッドを興味深くまたユニークな観点から実装しています。本質的にスレッドという概念を持たず、スレッドを独立したプロセスとして扱います。広義では、1プロセス内の2スレッドは、特に関係を持たない2つのプロセスと変わりありません。カーネルはスレッドを単にリソースを共有した複数のプロセスとみなします。すなわち、1プロセス内の2スレッドを、カーネルリソース(アドレス空間、オープンしたファイルなど)を共有した個別のプロセスとしています。
マルチタスクを実現する方法として、マルチプロセス、マルチスレッドと種類がある?
これを使って可視化、いいぞ!
PyCharmのProfile機能でもいい感じ
プロセスを作るのは重い
import os
import time
from multiprocessing import Process
def info(title):
print(title)
print('module name:', __name__)
print('parent process:', os.getppid())
print('process id:', os.getpid())
def f(name):
print('hello', name)
if __name__ == '__main__':
for _ in range(10):
time.sleep(2)
p = Process(target=f, args=('bob',))
p.start()
p.join()
print('done')

スレッドはプロセスより軽いことがわかる感じ
ここまでスレッドとプロセスを勉強して、以下のC10K問題を読むと理解度が高まってきた感じ
並行処理と並行処理、マルチスレッドとマルチプロセスの比較 → C10K問題対策としての、非同期I/Oやイベントループの話がとてもよくまとまっている
参考文献の参考文献
これもいい感じっぽい。
2021/07/26(月) 90分
- 13.3 スレッドと goroutine の違い
MEMO
- Goのランタイムは、Goroutineをスレッドとみなせば、OSと同じ構造になる(p.261)
-
GMPそれぞれの構造体が持つ属性を見ると相似関係が見やすい - CPUとレジスタの関係
- ゴルーチン最強! と見せかけて、スレッドにしかできないこともちゃんとあるよ
次回開催メモ
- 13.5 runtime パッケージの goroutine 関連の機能から
は?
OS のネイティブなスレッド
スレッドとCPUの関係性 is 何?
CPUのスペックで表記される"スレッド" と プロセス内にある"スレッド" って同じ? 違う?
これ、よさそう
タスクを切り替えるときに「レジスタを退避する」のが結構たいへんみたいですな
起動時間の遅さ
プロセス>スレッド>groutine
p.261 と https://zenn.dev/hsaki/books/golang-concurrency/viewer/gointernal は一緒に読んで!
構造体の属性をみるといい感じ!
相似形ってことがよくわかる。
コメントで日本語になっているのでそれを読むといい感じ
図 13.2 Go 言語のランタイムと goroutine の関係は、 OS とスレッドの関係と相似
相似形になっているからこそ、理解がしやすい
読んでいると、Goroutine最強じゃん、スレッドいらなくね? とか一瞬思うけど、いやいや、スレッドにしかできないこともあるんやで? って話
- 優先度の設定
- あるCPUコアを優先的に使ったり
- あるスレッドの処理を優先に行ったり
- よくわからんけど、ProcessorAffinityであーだこーだ → CPUコア間のタスク移動でキャッシュが失われない → CPUキャッシュの効率が最大化される
2021/07/29(木) 150 分
- 13.5 runtime パッケージの goroutine 関連の機能から
MEMO
- スレッドってなんだよ!!!(N回目
- コンテキストスイッチの軽さとスピンロックの重要性の話!
- ハイパースレッディング
- CPU動作原理 → CPU高速化技術 → パイプライン方式とかスーパースカラ方式 → ハイパースレッディング
- 流れが大事や!
- Archtecutual State(Arch State)
-
runtime.GoSchedの使い所は不明だが、動きはおもしろい- というか、普通は使わないほうが良さそう
- あくまで、まじ低レイヤーやるとき用
- CPUの物理的な部分っていうか、レジスタ意識するとみえてきそう
- コンテキストスイッチってなんだよ!?!?!?!(N回目
次回開催メモ
- 13.7.1 sync.Mutex / sync.RWMutex
メインスレッドでの実行が強制されているライブラリ(GUIのフレームワークや、OpenGLと依存ライブラリなど)をGo言語で利用する場合が挙げられます
そもそも、メインスレッドのみしか使えないものがあるのか、という驚き
main パッケージの init() 関数は確実にメインスレッドで実行されるため、それを利用してメインスレッドを固定することができます † 4 。
package main
import "fmt"
func init() {
fmt.Println("init")
}
func main() {
}
他の使いみちとして、Goのランタイムで、シグナルを受け取るスレッドを固定するために使う
ん?
現在実行中のgoroutineを一時中断して、他のgoroutineに処理を回します。
goroutineには、OSスレッドとは異なり、タスクをスリープ状態にしたり復元したりする機能がありません。ランキューの順番が回ってきたら、何ごともなく処理が再開します。
このコード動かすと、動きはわかる(使い所はわからない)
package main
import (
"fmt"
"runtime"
)
func main() {
go func() {
fmt.Println("hi")
}()
for {
runtime.Gosched() // コメントアウトしてみなよ?
}
}
sched_yield(2)が元ネタっぽい
- こっちは、あるスレッドに対して、CPUを明け渡すようにするシステムコール
-
GoShcedは、これの、スレッド→ゴルーチンになった版みたいな感じっぽい
typo: p.263

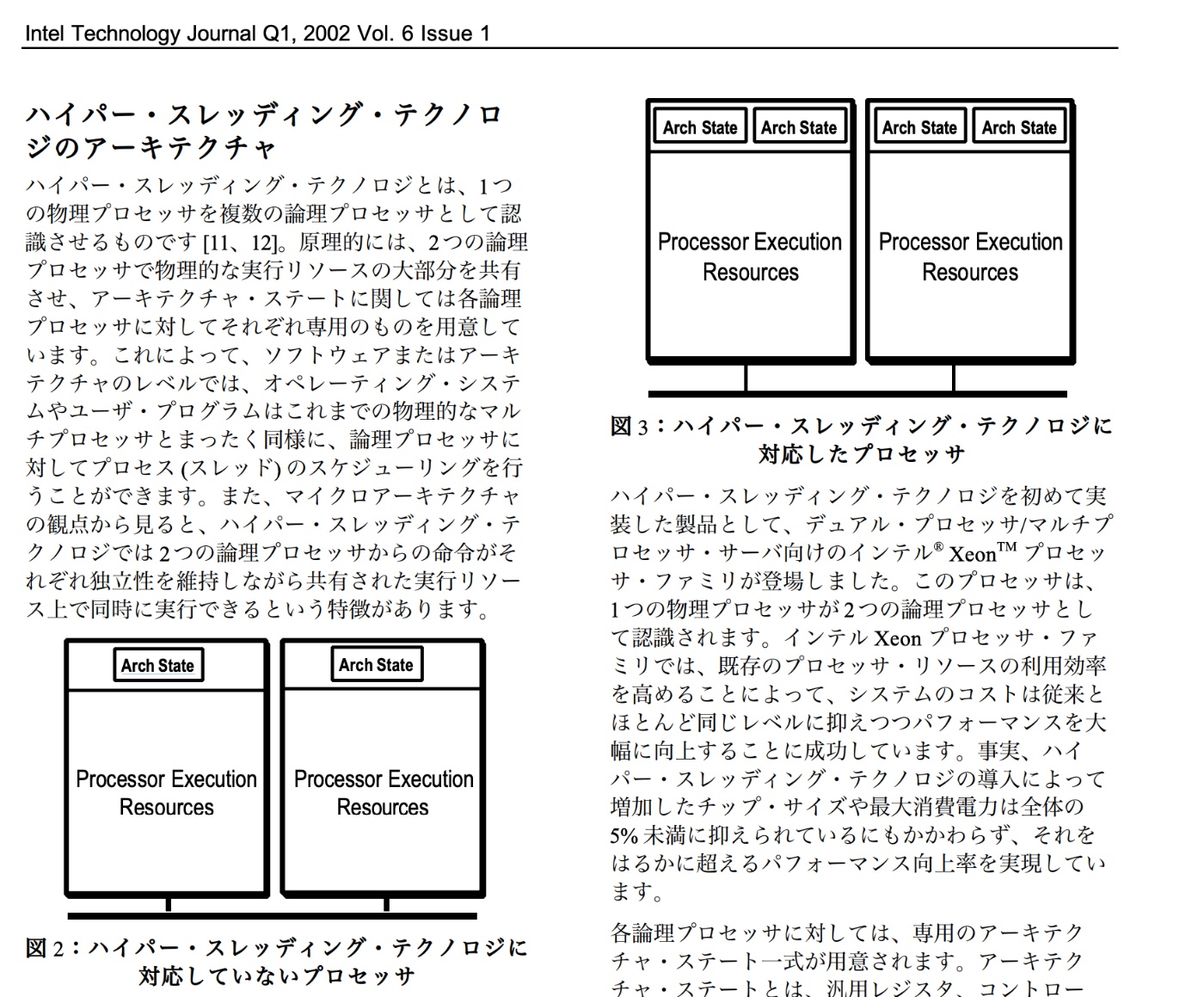
ハイパースレッディングを実現するために、CPUコアに「Arch State」が2つある
Arch Stateはプロセスの状態を保持するもの(汎用レジスタ、制御レジスタを含む)
ハイパースレッディング (SMT) のモチベーションは、スーパースカラのときからの課題であった CPU コア内部の『実行ユニット (パイプライン)』の利用率を上げることです。1 つの物理コアが 2 つの論理コアに見えるのはこれを実装した結果であって、目的ではありません。(以前騒動になった Spectre/Meltdownの原因となった予測分岐やアウトオブオーダー実行も同じです。)
CPUの動作原理とか命令処理の手順(フェッチして、デコードして...)とか、CPU高速化技術の話があると進むな!
package main
import (
"fmt"
)
func main() {
var count int
go func() {
count = 3
}()
go func() {
count = 4
}()
fmt.Println(count)
}
$ go run -race main.go |pbcopy
==================
WARNING: DATA RACE
Read at 0x00c00001c0c0 by main goroutine:
main.main()
/Users/mohira/src/github.com/mohira-books/system-programming/main.go:16 +0xaa
Previous write at 0x00c00001c0c0 by goroutine 7:
main.main.func1()
/Users/mohira/src/github.com/mohira-books/system-programming/main.go:10 +0x38
Goroutine 7 (finished) created at:
main.main()
/Users/mohira/src/github.com/mohira-books/system-programming/main.go:9 +0x7a
==================
Found 1 data race(s)
exit status 66
マルチスレッドなどの環境の排他制御において、ロックを獲得するまでスピン(ビジーループ)で待つ方法。
共有メモリー型のマルチプロセッサー環境に適した手法である。
ロックが獲得できるまで単純にループで待ち続け、定期的にロックの獲得試行と確認を実施する。
その間、スレッド(またはタスク)は待機状態となり有益な処理が実行できない。ロックが獲得できないとCPUを無益に占有し続けることになり、ビジーウェイト状態となる。
競合が多数発生するような場合はミューテックスと比較するとCPUパワーを無駄に消費することになり非効率となるが、処理は簡潔で済み、ロックが短期間で済む場合はミューテックスより高速である。
え? 「コンテキストスイッチが軽い => スピンロックが重要でない」という流れがわからん!
スピンロックは、ビジーループでロックを獲得する仕組みです。goroutineの軽量スレッドは、ブロックしてしまってもコンテキストスイッチが軽いため、スピンロックの重要性があまりなく、この機能が提供されていません。
A: ロック権利
B: ロックほしいよ〜
C: 他の仕事する人
D: 他の仕事する人
E: 他の仕事する人
Case1: Aのロックしている時間が長い場合
(Aのしごとがなかなか終わらないあ場合)
Bはスピンロック戦略をとる
Aのしごとはなかなか終わらないので、
CPU不可が高まるし、
スレッドC,D,Eも仕事できなくてもったいない
→ なので、スピンロックするよりも、スレッドCやDへとコンテキストをスイッチしたほうがお得
Case1: Aのロックしている時間が、めっっちゃ短い場合(ex: 1命令で終わる)
i) Bはスピンロック戦略をとる。
Aの仕事はすぐおわるので、Bはすぐにロックを勝ち取れる。
ii) Bはスピンロックをあきらめて、スレッドCやDへとコンテキストスイッチをしてみる
コンテキストスイッチのコストが安いと、スピンロックせずとも、ガンガンコンテキストを入れ替えたほうが
全体で多くの仕事ができるし、いろいろ仕事しているうちに、Aのしごとが終わって、Bはロックをかちとれる。
謎のメモ
B ->「変数X」 <- A
コア2個
プロセス
- スレッドA -> 変数X [Lock] -> 。。。。 -> Unlcok!
- スレッドB -> ロック取れない...(ブロック) →
↓ ↓ - スレッドC -> しごと しごと
↓ ↓ - スレッドD しごと
強豪がおきないとき
プロセス
- スレッドA -> 変数X
- スレッドB -> 変数Y
- スレッドC ->
- スレッドC ->
コンテキストスイッチとロックの関係?
スレッドのコンテキストスイッチって何?
プロセス > スレッド > Goroutine
ところで、コンテキストスイッチってなんだっけ?
コンテキストスイッチというものがよくわかっていない
- プロセスの場合
- スレッドの場合
- プロセスのスレッド
- OSのスレッド…?
- goroutineの場合
結局どれがどのくらいコスト掛かるのだろうか
スレッドの意味がよくわからん。
スレッドが使われるところが多すぎる
2021/08/02(月) 150 分
- 13.7.1 sync.Mutex / sync.RWMutex
MEMO
- 並行性は相対的な話!
-
sync.Condは難しい! 必要にならないと理解できない系なのか?-
close()でよくね? ってわけでもないらしい
-
- セマフォ(Semaphore)や
pthreadをちょっと知っていると、理解がスムーズ -
sync.Mapの実装例がほしいな〜
次回開催メモ
- 13.8.1 メモリマップド I/O と sync/atomic
実際に保護するのは実行パスであり、メモリを直接保護するわけではありません。
いわれてみれば!
あ、そうなんだ?
マップや配列に対 する操作はアトミックではないため、
sync.Mutex のコピー問題は、コードの静的チェックツールである go vet を実行することで発見できます。a
Lockしてないとかぶりがでる! クリティカルセクション!
package main
import (
"fmt"
"sync"
)
var id int
func generateId(mutex *sync.Mutex) int {
//mutex.Lock()
id++
result := id
//mutex.Unlock()
return result
}
func main() {
var mutex sync.Mutex
var wg sync.WaitGroup
n := 1000
wg.Add(n)
for i := 0; i < n; i++ {
go func() {
defer wg.Done()
fmt.Printf("id: %d\n", generateId(&mutex))
}()
}
wg.Wait()
}
$ go run chapter13/13.7.1/1/main.go | sort | uniq -d
id: 472
id: 559
id: 798
id: 90
id: 909
id: 946
go vet を実行することで発見できます。
便利ー。
package main
import (
"fmt"
"sync"
)
var id int
func generateId(mutex *sync.Mutex) int {
mutex.Lock()
id++
result := id
mutex.Unlock()
return result
}
func main() {
var mutex sync.Mutex
var mutex2 sync.Mutex
var wg sync.WaitGroup
n := 1000
wg.Add(n)
for i := 0; i < n; i++ {
go func() {
defer wg.Done()
fmt.Printf("id: %d\n", generateId(&mutex))
}()
}
mutex = mutex2 // こぴーしたらあかんぜよ!
mutex2 = mutex
wg.Wait()
}
$ go vet chapter13/13.7.1/1/main.go
# command-line-arguments
chapter13/13.7.1/1/main.go:36:10: assignment copies lock value to mutex: sync.Mutex
chapter13/13.7.1/1/main.go:37:11: assignment copies lock value to mutex2: sync.Mutex
semaphore
type Mutex struct {
state int32
sema uint32
}
セマフォ(Semaphore)の存在を発見!
// A Mutex is a mutual exclusion lock.
// The zero value for a Mutex is an unlocked mutex.
//
// A Mutex must not be copied after first use.
type Mutex struct {
state int32
sema uint32 // <-- セマフォ(Semarphore)やん!
}
runtime_Semrelease(s *uint32, handoff bool, skipframes int)の handoffは多分旗揚げ的な意味で、上げ下げをboolで指定する感じがする
// Semrelease atomically increments *s and notifies a waiting goroutine
// if one is blocked in Semacquire.
// It is intended as a simple wakeup primitive for use by the synchronization
// library and should not be used directly.
// If handoff is true, pass count directly to the first waiter.
// skipframes is the number of frames to omit during tracing, counting from
// runtime_Semrelease's caller.
func runtime_Semrelease(s *uint32, handoff bool, skipframes int)
Cの<sys/sem.h>のsemopとなんか似ている感じ
//
// Created by jun on 2021/08/01.
//
#include <stdio.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <stdlib.h>
#include <string.h>
#include <sys/sem.h>
static struct sembuf down_1 = {0, -1, 0};
static struct sembuf up_1 = {0, 1, 0};
void down (int semaphore){
semop(semaphore, &down_1, 1);
}
void up (int semaphore) {
semop(semaphore, &up_1, 1);
}
// ...
sync.Onceは並行処理のエッセンス詰まっているとおもう
↓を読んでね
sync.Condの理解に有用な記事!
クリティカルセクション
同時に実行されると問題が起きる実行のコードの行のこと(1行とは限らない。プログラミングの言語より小さいこともある)
マルチスレッドプログラミング入門 P.12から
また、たまに誤解しているプログラマがいらっしゃいますが、コンテキストスイッチが起こるタイミングはプログラムの行とは関係がありません
sync.Mapを使うと、ただのMapと違って、壊れないことが保証されるコード例がほしい
たのむぅ
Mapとゴルーチンの関係性がわからん!
わかrな!
いつコンテキストスイッチが発生するかは神のみぞ知るセカイ!
途中でコンテキストスイッチが入って操作が失敗しないことが保証されるのです。
しかも、マルチコアCPUだと、本当に同時に怒るかもしれない
runtime/internal/atomic
アセンブリ頑張れ〜
LOCKしているかんじ
// uint32 Xadd(uint32 volatile *val, int32 delta)
// Atomically:
// *val += delta;
// return *val;
TEXT runtime∕internal∕atomic·Xadd(SB), NOSPLIT, $0-20
MOVQ ptr+0(FP), BX
MOVL delta+8(FP), AX
MOVL AX, CX
LOCK
XADDL AX, 0(BX)
ADDL CX, AX
MOVL AX, ret+16(FP)
RET
sync.Mutex や sync.Cond 、チャネルなどを使っても、複数の goroutine がアクセスしてロックされると、コンテキストスイッチが発生します。こちらのロックフリーな関数を使えばコンテキストスイッチが発生しないため、うまく用途が合えば本章で紹介した機能の中では最速です。
atomic.AddInt64などは、アセンブリレベルではロックをしているかもしれないけど、
アプリケーションコード上ではロックをしていない?
並行性の議論をするときは、コンテキストが大事! すべて相対的です!
ヤムチャ目線か? 悟飯目線か? で全然違う!
そして最後の3つめは、並列性は時間やコンテキストの機能であるということです。1.2.2 アトミッ ク性を思い出してください。コンテキストの概念について話しましたね。そこでコンテキストはある操 作がアトミックであると考えられる境界だと定義しました。ここではコンテキストは2つ以上の操作が 並行に動作していると考えられる境界と定義します。
たとえば、もしコンテキストが5秒間に1秒かかる2つの操作を実行するのであれば、これらの操作 が並列して実行されたものと考えることになるはずでしょう。もしコンテキストが1秒間だったら、操 作を逐次的に実行するでしょう。
2021/08/12(木) ○○分
- 13.8.1 メモリマップド I/O と sync/atomic
MEMO
- Kotlinのpmap、そして、Elixrのプロセス
- GPUの物量作戦がえげつない
- CPUからみえると、コンテキストスイッチはめっっっっっっっっっちゃ遅い
- ちなみに、pingは15日かかるよ
- Linuxのカーネルにおいては、プロセスもスレッドも同じ構造体(
task_struct) - FiberとかGVMとかGILとか
- ネイティブなスレッド、ユーザースレッド
- プリエンプティブ(OS任せ)とノンプリエンプティブ(アプリで頑張る)
次回開催メモ
- 14.2 Go における並行・並列処理のパターン集
現代の CPU では、実行ファイルに書かれた命令どおりに実行するのではなく、メモリアクセスのオーバーヘッドをうまく隠すために命令の実行順序を実行時に柔軟に入れ替えることがあります。
へー。
CPUパイプライン化
命令フェッチ・命令デコード・命令実行という順番で考えたときに、命令を詰めて実行するやり方
p.247 typoやん!
- o: LoadUnit32
- x: LoadUint32
並行・並列処理の手法と設計のパターン
マルチプロセス、イベント駆動、マルチスレッド、ストリーミング・プロセッシングという4種類のやり方がある
Linux ではプロセ スもスレッドもカーネル上は同じ構造体で表現されています。
わかってない
スレッドセーフとは
カーネル・スレッドはスケジュール可能なエンティティーで、 これは、システム・スケジューラーがカーネル・スレッドを扱うということを意味します。
これらのスレッドはシステム・スケジューラーが知っており、 インプリメンテーションに強く依存しています。
Linuxのカーネルスレッドを、Windowsにそのまま移植するのは難しい的な話だと思う。
移植性のあるプログラムの作成を容易にするために、 ライブラリーではユーザー・スレッドが提供されています。
だから、ユーザースレッド(==プログラムでどうこうできるやつ)で頑張れってことだと思う。
ユーザー・スレッド は、 プログラマーが 1 つのプログラム内で複数の制御の流れを処理するために使用するエンティティーです。
こっちは、プログラマのもちもの(Entity)
ユーザースレッドは、アプリケーションスレッドって言ったほうがつかめるな
Linuxにおけるプロセスとスレッド
プロセスは概念的なプロセスをそのまま実装されたもの
プロセス内で並列・並行化するためのスレッドは2つの意味がある軽量プロセス(LWP)
プロセス内でスレッドを実現するが、スレッドの実行スケジュールはOSのスケジューラが行う なので、OSスケジューラから見たら、プロセスとスレッド(LWP)は同じ単位になる
OSのスケジューラを使うので、マルチコアにおけるCPU資源の割り当てが可能ユーザースレッド(アプリケーションスレッド)
ユーザ空間で 実装 されたスレッド機構
実際は プロセス - LWP - ユーザースレッド という紐付けになる
ユーザ空間で実装されたランタイムでスケジューリングされるので、プロセス内でのタスク切り替えになるのでシングルコアでしか動かないなので、 Linux上でスレッドを使って並行・並列化するという文脈の時は
LWPを多重化すれば、並列化(CPUコアでスケールする)
ユーザースレッドを多重化すれば並行化(シングルコアでタイムスライス)
ユーザー空間上の実装で並列・並行化可能という意味で、この2つの方法を区分けせずに ユーザー(空間上の)スレッド と表記するケースがある
sedの g
$ echo hello | sed 's/l/X/g'
heXXo
$ echo hello | sed 's/l/X/'
heXlo
2021/08/26(木) ○○分
- 14.2 Go における並行・並列処理のパターン集
MEMO
- いろんなパターンやったじゃ〜ん
- 『並行プログラミング入門』買うしかない!
次回開催メモ
- 14.2.9 イベントの流れを定義する:ReactiveX
非同期→同期化
各スレッドを.join()させる必要がある
Go言語だとチャネルで待つ
chanのchanのchan
package main
import (
"fmt"
)
func main() {
chanchanchan := make(chan chan chan int)
chanchan := make(chan chan int)
ch := make(chan int)
go func() {
chanchanchan <- chanchan
chanchan <- ch
ch <- 111
}()
fmt.Println(<-<-<-chanchanchan)
}
だめな書き方(理由はまだわからん)
package main
import (
"fmt"
)
func main() {
chanchan := make(chan chan int)
ch := make(chan int)
go func() {
// 先に ch に送信するとだめ!
ch <- 111
chanchan <- ch
}()
fmt.Println(<-<-chanchan)
}
バックプレッシャー
バックプレッシャーとは、半二重接続のネットワーク機器などで用いられるフロー制御方式の一つで、受信側が記憶装置の容量の飽和を防ぐためにわざと送信側の送信動作を妨害・抑止する手法。
イーサネット(Ethernet)のハブやスイッチなどの集線装置でよく採用される方式で、受信したデータの一時保管を行うバッファ領域があふれそうになると、あえてコリジョン(信号の衝突)の発生を通知するメッセージを相手方に送り、送信側の新たなデータの送り出しを一時的に中断させる。
イメージ
□ <-------送信
□ ----------->x<-------送信
2021/09/06(月)
- 14.2.9 イベントの流れを定義する:ReactiveX
MEMO
- 14章おわり!
次回開催メモ
- 15章 Go 言語のメモリ管理 から!
Rx感を出すコード
エラーハンドリングどうするの?
package main
import (
"fmt"
"github.com/reactivex/rxgo/observable"
"github.com/reactivex/rxgo/observer"
"os"
"strings"
)
func main() {
emitter := make(chan interface{})
source := observable.Observable(emitter)
// イベントを受け取る observer を作成
watcher := observer.Observer{
NextHandler: func(item interface{}) {
fmt.Println("NextHandlerやで!!")
line := item.(string)
if strings.HasPrefix(line, "func ") {
fmt.Println(line)
}
},
ErrHandler: func(err error) {
fmt.Printf("Encouterd error: %v\n", err)
},
DoneHandler: func() {
fmt.Println("Done!")
},
}
// ここで、Filterをかましている!
sub := source.Filter(func(item interface{}) bool {
line := item.(string)
return strings.HasPrefix(line, "func ")
}).Subscribe(watcher)
go func() {
content, err := os.ReadFile("reactive.go")
if err != nil {
emitter <- err
} else {
for _, line := range strings.Split(string(content), "\n") {
emitter <- line
}
close(emitter)
}
}()
<-sub
}
アクターモデルは、Future/Promise よりも古い、1973 年に発表された並列演算モデルです。
古くね!?
Erlang では、このメッセージキューのことを mailbox と呼んでいる。
Protocol Buffers
実は全然知らない系
アクターモデルの話
アクターモデルは堅牢性の話をよく聞いていたので、
並行処理の文脈でも出てくるんだっていう気づき
アクターモデルっていうか、メッセージキューを用いたマルチプロセスって感じじゃねーのか?
ReactiveX
RXも、非同期にイベントを受け取って、よしなにやる文脈でしか知らなかった
並行処理の文脈で出てくるとは思わなかった
Erlang入門
~ (130) 0s 23:35:28$ erl
Erlang/OTP 22 [erts-10.6.4] [source] [64-bit] [smp:8:8] [ds:8:8:10] [async-threads:1]
Eshell V10.6.4 (abort with ^G)
1> 1 + 1.
2
2>
OSのプロセスは、重い!

2021/10/11(月)
- 15章 Go 言語のメモリ管理 から!
MEMO
- 1ヶ月ぶりの開催ワロタw
- 10ヶ月後に役立つGo
次回開催メモ
- 15.1.5 ユーザーコードでメモリを使う
ヒープメモリとスタックメモリってどう違うんだっけ
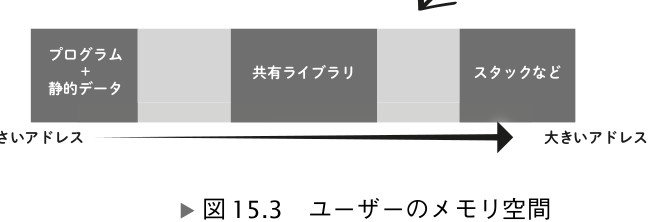
ユーザーのメモリ空間の 3 つの領域のうち、若い番地(小さいアドレス)には、プ
ログラムとプログラムの静的変数などが置かれます。その先の番地の空いている領域
には、カーネルから動的にもらうヒープと呼ばれるメモリが置かれていきます。中段
には共有ライブラリがマッピングされて置かれます。最上段は、スタックと呼ばれる
メモリ領域などです。
スタックメモリは、ユーザーメモリ空間であらかじめ(静的)用意されているもの
ヒープメモリは、カーネルから動的にもらうもの、らしい
Q. そもそも、プロセスからみたときに、メモリが連続領域ではいけない理由って何?
プロセスから見えるメモリは4GBでフラットに繋がっていて欲しい、らしい。
だから仮想メモリとMMUがあるんだろうなぁという動機
ページテーブルによる変換が挟まるので遅くなるように思えますが、実際には変 換テーブルをキャッシュして高速化する仕組みが CPU には備わっています。この キャッシュをTLB(Translation Lookaside Buffer)と呼びます。
仮想メモリは、物理メモリと 1:1 にリンクしているわけではなく、メモリ節約のた めに 1 つの物理アドレスをたくさんの仮想メモリから参照することがあります
仮想メモリは、物理メモリと 1:1 にリンクしているわけではなく、メモリ節約のた
めに 1 つの物理アドレスをたくさんの仮想メモリから参照することがあります。たと
えば、システムで提供されている DLL や共有ライブラリは数多くのプロセスが利用し
ます。それぞれのプロセスごとにロードするとメモリをたくさん無駄に消費してしま
います。そこで、最初にロードしたものを多くのプロセスで共有することでメモリの
無駄を減らします。
めっちゃ合理的!
ページ税的なw
Linux の場合、4KB のページごとに 64 バイトの管理領域を必要とします。つまり、ペー ジごとに 1.5% ほどの容量が管理のために必要です。
ユーザーのメモリ空間は仮想メモリとどう違う?
ヒント情報 is 何?
mmapのアノニマスフラグはどういうときに使う?
typo? 開放 → 解放
p.299
OS 内部でのメモリ確保はコストのかかる可能性のある処理です。物理メモリが足 りなければ、優先度の低いメモリ領域を開放して領域を確保したり、
。そこで、前項のコラム「メモリの確保に使うシステム コール」で紹介した mmap システムコールなどを使って大きめの塊でメモリを OS か ら分けてもらい、そのメモリの細かな管理はユーザーランドの中で行うことで、パ フォーマンスを維持します。
つどつど、OSに依頼すると、おっっそい。っていうか、システムコールって遅い。
おれ(ユーザー)にやらせろ! って感じ。
OS 内部でのメモリ確保はコストのかかる可能性のある処理です。物理メモリが足 りなければ、優先度の低いメモリ領域を開放して領域を確保したり、HDD などのス トレージにスワップアウトしたり、それでも必要なメモリを確保できなければ他のプ ロセスを強制終了(Linux の OOM キラー)させたりするといったことが裏で行われ る可能性があります。そのため、こまめに OS にメモリ確保を依頼すると、OS がボトルネックになってしまいます。
マルチプロセスが重たい理由の理解が深まったっぽい。
ユーザーのメモリ空間の 3 つの領域のうち、若い番地(小さいアドレス)には、プ
ログラムとプログラムの静的変数などが置かれます。その先の番地の空いている領域
には、カーネルから動的にもらうヒープと呼ばれるメモリが置かれていきます。中段
には共有ライブラリがマッピングされて置かれます。最上段は、スタックと呼ばれる
メモリ領域などです。
スレッドって、プロセスのメモリ空間を共用するからコストが安いっていうイメージだったから、これはちょっと意外
実行時の動的なメモリ確保という意味では、スタックもヒープも同じ
メモリリークってのがすごくピンと来ない
デマンドページングによって初期化コストが削れ、使用メモリのピーク が異なるプロセス同士でうまくメモリを融通しやすくなります。
仮想メモリには、複数のプロセスでシステムの同じ共有ライブラリをロードしている 場合にメモリ消費を抑える仕組みもあります。それぞれのプロセスの仮想メモリには 同じライブラリが個別にロードされているように見えますが、ページテーブルを使って 同じアドレスを参照することで、1 つ分のメモリしか消費しないようにするのです。こ のようなメモリの使われ方は、メモリの使用方法を観察するツールで確認できます † 14 。
なんでこんなレイアウトなんだろう。
プログラム+静的データと共有ライブラリの間にヒープが挟まっているのか。
共有ライブラリの後にヒープがあっても良さそう
2021/10/18(月)
- 15.1.5 ユーザーコードでメモリを使う
MEMO
- スライスと配列!
- 多対多は違くね?
次回開催メモ
- 15.3.3 マップとパフォーマンス改善のヒントから
スライスの背後には、配列がある
スライスは、配列のポインタと、lenとcapを持っている
C/C++ の場合は、ポインタを使わずにローカル変数として宣言するとスタックにメ モリが確保され、new や malloc() を使うとヒープメモリにメモリが確保される、と いうシンプルな仕組みになっています。
Go 言語の場合、ヒープに置くかスタックに 置くかは、コンパイラが自動的に判断します。new で作っても、その関数内でしか利 用されなければスタックに確保されます。ローカル変数として宣言しても、そのポイ ンタを他の関数に渡したり、関数の返り値として返すような場合にはヒープに置かれ ます。
「スタックフレーム」とは?
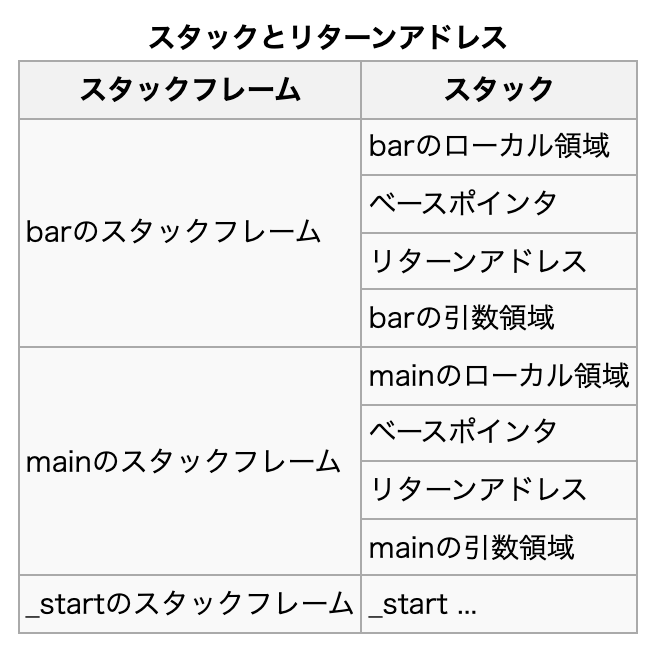
スタックフレームの巻き戻しの説明
スタックフレームの巻き戻し(Unwinding)
サブルーチンのエントリをコールスタックに追加することを「ワインディング」と呼ぶこともあります。 逆に、エントリを削除することは "巻き戻す"ことです。
アンワインド
「どちらか適切なほうに自動で割り当てられる」という Go 言 語の方針を実現するには、ヒープであってもスタックと同じように不要になったら自 動で解放するガベージコレクタが不可欠になります。
15.2でようやく配列が出てくるのは面白い
[4]intと[3]intはデータ型が違う
スライスと配列は 1 対 1 の関係ではなく、多対多の関係だといえます。実体であ
る配列を隠したままスライスだけを使って操作することも、 1 つの配列から複数のス
ライスを作り出すこともできます。
スライスに対して、配列が複数つながる??
謎
スライスと配列は 1 対 1 の関係ではなく、多対多の関係
capacityを先に確保したほうがお得だよ実験
package main
import (
"fmt"
"time"
)
func main() {
start := time.Now()
x := 1 << 25 // 2^25
s := make([]int, 0, x)
//s := []int{} // ← ここのコメントをはずと無駄が増えるよ
fmt.Println(s, len(s), cap(s))
for i := 0; i < x; i++ {
s = append(s, 1)
}
elapsed := time.Since(start)
fmt.Println(elapsed.Milliseconds())
}
2021/11/01(月)
- 15.3.3 マップとパフォーマンス改善のヒントから
MEMO
- GCアルゴリズムいろいろ
- Stop the World
- 昔のJavaは遅かったんだなぁ〜
- ありがとうGC
- 弱参照(Weak Reference)
次回開催メモ
- 15.5 アプリケーションのメモリ配置
map では、 8 個の要素を 1 つにまとめた「バケット」という単位でデータを保持し
ます。
各言語のデータ構造がどうなっているのかは、そういえばよく知らないな
スライスのときと同じく、マップも要素数が増えてくると新しいバケットのリスト が作られて移動が行われるので
スラブアロケータ
スラブアロケータとは、Linux カーネルに用意されてい るメモリ管理機構で、Linux 内部で大量に使われる inode やファイルディスクリプタといった同一種類の構造体のメモリの在庫を一括で管理し、不要になったオブジェク トを回収して必要になったら渡す仕事をします。カーネルはメモリを自分で管理しな ければならないので、スラブアロケータのような仕組みが必要となります。
今回の範囲全然わからんちんwwww
sync.Poolというものでデータを取り出す
func main() {
// poolを作成する
var count int
pool := sync.Pool {
New: func() interface{} {
count++
return fmt.Sprintf("created: %d", count)
},
}
// 追加した要素から受け取れる
// プールが空だと新規作成
pool.Put("manualy added: 1")
pool.Put("manualy added: 2")
fmt.Println(pool.Get())
fmt.Println(pool.Get())
fmt.Println(pool.Get()) // 新規作成
}
WeakRefernce(弱参照)
https://developer.mozilla.org/ja/docs/Web/JavaScript/Reference/Global_Objects/WeakRef#avoid_where_possible
可能な限り避ける
WeakRef の正しい使用には慎重な検討が必要であり、可能であれば避けた方が良いでしょう。また、仕様で保証されていない特定の動作に依存しないことも重要です。ガベージコレクションがいつ、どのように、そしてどのように発生するかは、使用している JavaScript エンジンの実装に依存します。あるエンジンで観察した動作が、別のエンジン、同じエンジンの別のバージョン、あるいは同じエンジンの同じバージョンでも少し違う状況では異なる可能性があります。ガベージコレクションは、 JavaScript エンジンの実装者が常に解決策を改良している難しい問題です。
weakref --- 弱参照 — Python 3.10.0b2 ドキュメント
弱参照の主な用途は、巨大なオブジェクトを保持するキャッシュやマッピングを実装することです。ここで、キャッシュやマッピングに保持されているからという理由だけで、巨大なオブジェクトが生き続けることは望ましくありません。
https://www.weblio.jp/content/弱い参照
弱い参照(英: weak reference、ウィークリファレンス)あるいは弱参照とは、参照先のオブジェクトをガベージコレクタから守ることのできない参照のことである。弱い参照からのみによって参照されるオブジェクトは到達不可能とみなされ、従っていつでも解放することができる。弱い参照は、通常の参照(強い参照、強参照)による諸問題を解決するために用いられる。PythonやJavaをはじめとするガベージコレクタを実装したオブジェクト指向プログラミング言語の多くは、弱い参照を実装している。
https://ufcpp.net/study/csharp/RmWeakReference.html
普通に C# を使っていて、WeakReference を見かけることはほとんどないと思います。 だいたいのプログラムでは、メモリ管理について気にすることはめったにありません(GC 任せ)。 弱参照を使うというのは、メモリ管理を自分で気にかけるということなので、当然、あまり出番はありません。
それに、弱参照を使うと、GC が掛かるタイミング(普通は制御しない。不定なタイミング)に依存することになるので、挙動が読めないという問題もあります。
なお、内部では要素はキャッシュでしかなく、(他の言語で言うところの)WeakRef のコンテナとなっています。そのため、ガベージコレクタが稼働すると、保持してい るデータが削除されます。sync.Pool は、消えては困る重要なデータのコンテナに は適しません。
ストップ・ザ・ワールド
「Goがはやい」と言われるのはGCの優秀さもあるのかな?
Go 1.8 ではさらに高速化して 10 マイクロ秒から 100 マイクロ秒の停止時間となっ ており、その後もさらに改善されています。この値がどれくらいすごいかというと、 現在の Linux カーネルの 8 コアの CPU におけるタスク切り替え時間が 3∼24 ミリ秒く らい † 21 なので、複数のプロセスを起動して処理が回ってくるよりも停止時間が短い ことになります。つまり、GC がなく停止時間のないプログラムを実行するのと比べ ても、Go を使うことによってリアルタイム性が損なわれることがまったくないとい うことです。
GCアルゴリズムの可視化のめっちゃいい記事
日本語訳。ただし、画像がリンク切れている(?)なので、画像については、本家の記事を見ましょう。
“Stop the World”を防ぐコンカレントGCとは?:現場から学ぶWebアプリ開発のトラブルハック(2)(1/2 ページ) - @IT
Javaで構築したシステムにかかわる者ならば誰しもが体験するであろう事象、そうFull GC(ガベージ・コレクション)だ。Full GCが行われている間、すべてのアプリケーションスレッドは停止する。この事象は“Stop the World”とも呼ばれている。
2021/11/08(月)
- 15.5 アプリケーションのメモリ配置
MEMO
- メモリ管理って大変ですね
- バッファオーバーフロー(バッファオーバーラン)とセキュリティの関係
- シェルコードの実行
-
gets()はやめなさい! ← API消してくれよ!
- 実行ファイルのフォーマット
- セクション
- ELF / PE / Mach-o
次回開催メモ
- 16章 時間と時刻
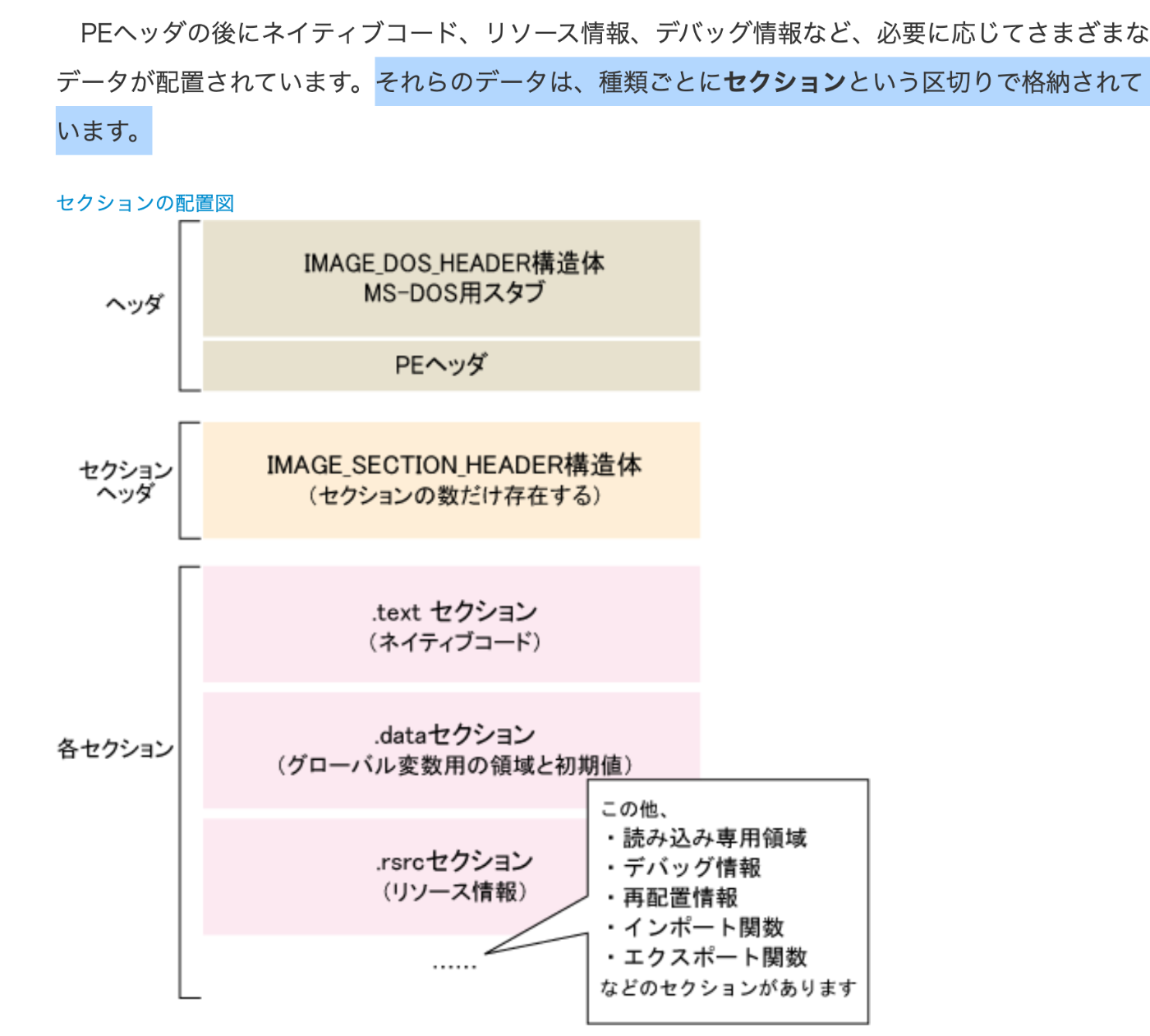
実行ファイル「セクション」でググればいいい
デバッガの「シンボル」
シンボルとは、プログラムのアドレスと可読なソースコード上の名前 (シンボル) を対応させるためのものです。
https://www.keicode.com/debug/dbg115.php
デバッグシンボルは、よりよいデバッグセッションができるようにします。
https://www.electronjs.org/ja/docs/latest/development/setting-up-symbol-server
シンボル情報には、関数名、変数名、ソースコード上の位置情報などが含まれる。ソースコードがあれば、ソースコード上で通過待機位置を指定した実行も可能であり、プログラムの不具合調査、動作確認の際に非常に便利である。
https://www.sophia-it.com/content/シンボリックデバッガ
セクションごとに、CPU がどのようにアクセスできるかを、フラグにより設定でき ます。これをメモリパーミッションといいます。メモリパーミッションには、実行命 令を置いて実行できる、読み込みができる、書き込みができる、などがあります。
Clang ([ˈklæŋ]:クランのように発音) は、プログラミング言語 C、C++、Objective-C、Objective-C++ 向けのコンパイラフロントエンドである。
「実行ファイルがメモリにロードされて、命令実行サイクルに従って、実行される」
みたいな話をより細かく見た感じの話でした。
バッファーオーバーフローで、ずぶずぶいってしまう!

バッファオーバーフロー: gets()は使うな! の理由
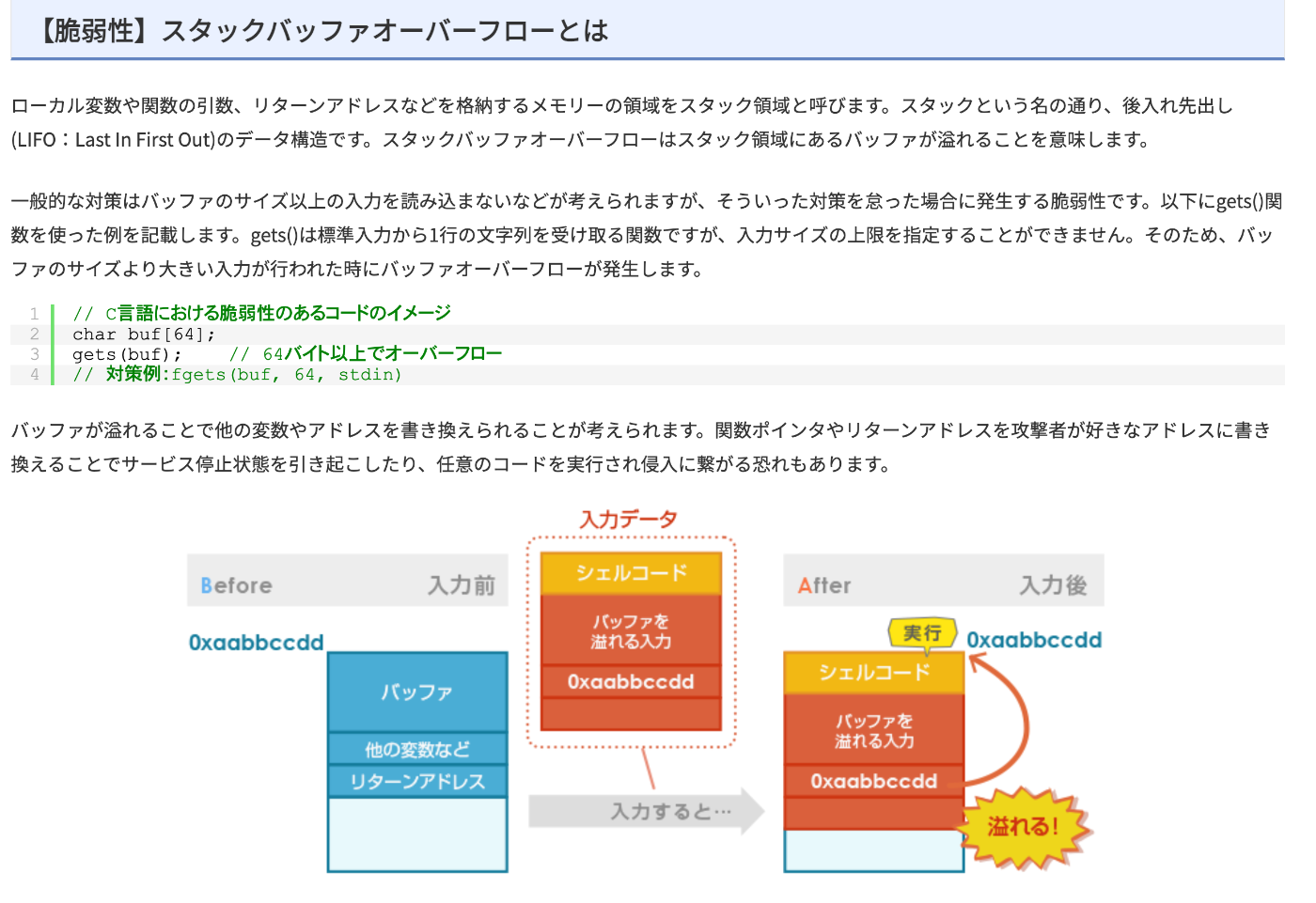
プログラムの実行に必要なデータをファイルと一緒にバンドルし、1 ファイルで配 布したいことがあります。Go では、あらかじめバイト列として変数宣言した Go の ソースコードに変換し、
え?
一方、実行 ファイルの末尾に情報が載っている状態なら、実行時にはメモリにロードされませ ん。必要に応じてメモリに読み込めますし、不要になったらメモリを解放できます。
「実行ファイルの末尾に情報が乗っている」なら「実行時にはメモリにロードされない」が理解できてないぜ!
「メモリ確保は裏でこれだけがんばっている高価なオペレーションだ」というのが 伝わったなら、本章の役目は果たせたと思います。
たしかに、メモリ管理とかって大変ですね...
2021/11/15(月)
- 16章 時間と時刻
MEMO
- お絵かきがうまくなった
- セマフォあたりは意味不明だった
- 時間と時刻は難しい
- いろんな種類の時間(時刻)があるね!
次回開催メモ
- 17章 Go言語とコンテナ
分解能ってなに?
解像度と言っても差し支えない。
どれだけ細かく測れるかどうか
精度とも言えそう
また、OS はハードウェアのタイマーを設定し、一定間隔で割り込みがかかるよう にします。この割り込みを受けて、システムクロックを更新したり、現在実行中のプ ロセスが持つ残りのタイムスライスを減らしたり、必要に応じてタスクの切り替えを 行ったりします。

Linuxカーネルが起動してから、一定時間ごとにカウントアップされる変数。jiffyの複数形。
Linuxカーネルが起動してから、一定時間ごとにカウントアップされる変数。jiffyの複数形。
jiffy /dʒífi(米国英語), ˈdʒɪfi:(英国英語)/
現在の Linux カーネルのデフォルト設定だと、このタイマー割り込みの間隔は 1 秒 あたり 250 回となっています。この割り込みのたびに、jiffies というカウンター 変数が増えます。このカウンター変数が 1 増加することを「1 Tick」と呼びます。し たがって、Tick というのは、特定の決まった時間ではなく、コンピューター上で観測 可能な最小の時間間隔を表すことになります。たとえば、ゲームのようなアプリケー ションでは、画面 1 回更新(1/60 秒など)を Tick と呼ぶこともあります。
1sで250回ってことは、0.004sで1回。
クロック周波数からすると、めっちゃ遅いな。Tick。
完全なタイマーはない
よくある失敗は、何かしらのID を作成するのにタイマーの数値をそのまま利用するというものです。分解能よりも 小さい間隔で時刻を取得すると、まったく同じ ID が複数個発生することになります。
APIC(Advanced Programmable Interrupt Controller)
APICはAdvanced Programmable Interrupt Controllerの略で、インテルにより開発された、x86アーキテクチャにおける割り込みコントローラのことである。
OS の中で扱う時間にはいくつもの種類があります。
え、そうなの?
1. リアルタイム時刻が最強に正確
そのコンピューターシステム内でもっとも正しい時間を表 すものをリアルタイム時刻と呼びます。
2. モノトニック時刻
タイマー待ちで正確に「100 ミリ秒測定したい」という場合や、ベンチマー クで経過時間を計測したい場合には、時刻が調整されては困ります。た
???「調整しといたよ!」はめっちゃ困るwww
たとえば「途中 でうるう秒調整で 1 秒挿入されてしまって 100 ミリ秒が 1100 ミリ秒になってしまっ ては困る」といったケースです
そうなると、リアルタイム時刻は使えないじゃん!
モノトニック時刻にもいくつかあります。OS は、OS 起動からの時 間や、各プロセス起動からの時間をカウントしています。
Pythonにもあった
Return the value (in fractional seconds) of a monotonic clock, i.e. a clock that cannot go backwards. The clock is not affected by system clock updates. The reference point of the returned value is undefined, so that only the difference between the results of two calls is valid.
単調な時計、つまり逆方向に移動できない時計の値(秒単位)を返します。クロックは、システムクロックの更新の影響を受けません。戻り値の参照ポイントは未定義であるため、2つの呼び出しの結果の差のみが有効です。
Goのtimeパッケージにもmonotonic timeの記述ある
Operating systems provide both a “wall clock,” which is subject to changes for clock synchronization, and a “monotonic clock,” which is not. The general rule is that the wall clock is for telling time and the monotonic clock is for measuring time. Rather than split the API, in this package the Time returned by time.Now contains both a wall clock reading and a monotonic clock reading; later time-telling operations use the wall clock reading, but later time-measuring operations, specifically comparisons and subtractions, use the monotonic clock reading.
3. ウォールクロック
壁掛け時計。時刻を知りたいときに使うのが、ウォールクロック。
ある基準時点からどれくらいの時間が経過したかを知りたいときに使うのが、モノトニック時刻
4. CPU時間
CPU が消費した時間です。10% の CPU 使用率であれば、5 分起動して も 30 秒ですし、8 コアをフルに使えば 40 分です。CPU 時間の計算では、ユーザーの プロセス内で消費された時間と、カーネル内部で消費された時間とが、別々にカウン トされます。
~ .4s 21:45:22$ time seq 1 1000000 | while read x; do echo $(($x*$x)) > result ; done
7seq 1 1000000 0.04s user 3.82s system 9% cpu 41.473 total
~ 41.8s 21:46:34$
CPU時間
41.473 * 0.09 = 3.73257
Go のタイマーでは逆にタイムアウトの機構を使って処理待ちを行っ ています。
???
アプリケーションの中でたくさんの時間を待つ処理があったとしても、 Go のラン
タイムの中で使う OS のタイマーは 1 つだけです
タイマーはなぜ1つだけにしているのだろう
Goでは、時間と時刻を明示的に別の構造体にしているのは、非常によい設計だと思いました。
2021/11/22(月)
- 17章 Go言語とコンテナ
MEMO
- コンテナ
- 仮想化
- ネイティブ仮想化
- エミュレーション
- CPU側から歩み寄ることによるパフォーマンス改善
- 準仮想化
次回開催メモ
- 17章読破の振り返りと、次回どうする会議!
エミュレーションとネイティブ仮想化
「ネイティブ仮想化方式」と「エミュレーション方式」の違いがわかってません!
1974 年に論文化された「Popek と Goldberg の仮想化要件」として知られていま す† 1 。
VT-x
仮想化のためにCPU(ハードウェア)をいじってるのがミソっぽい
CPU内部に仮想化に対応する機能を組み込み、ハードウェア側から資源の分割や管理を支援することにより、ソフトウェアのみによる仮想化よりも大きく性能を向上させ、同時に高いセキュリティを実現することができる。
AMD-Vとは、AMD社のマイクロプロセッサ(MPU/CPU)製品に搭載された、コンピュータの仮想化をハードウェアレベルで支援するための拡張機能。
https://e-words.jp/w/AMD-V.html
-1 の下に、 -2 、 -3 もあり、 -3 では Minix という OS が動作しているとのことです。 https://pc.
watch.impress.co.jp/docs/news/1090/501/index.html
センシティブ(CPU)命令
ハードウェアの状態を変更するようなCPU命令のこと。
例えば、2つのOSが1つのCPU上で動作している場合に、一方のOSがCPUのレジスタに値をセットして、他方のOSがそのレジスタ値を書き換えた場合、先にセットしたOSとしては「覚えの無い」値に勝手に変わったように見えてしまいます。このCPUのレジスタを設定するような、複数のOSが同時に実行すると悪影響をおよぼす命令をセンシティブ命令と呼びます。
コンテナのことを「 OS レベル仮想化」と呼ぶこともあります。
OSが主体で仮想化を行なうから、OSレベル
OSレベルの仮想化とは、文字どおりOS(ホストOS)の機能によって仮想化を実現するアーキテクチャである。ハイパーバイザ・レイヤは存在せず、ホストOSが自らハードウェア・リソースを分割したり各サーバを独立して走らせたりする。すべての仮想サーバが同一のOS上で稼働するという点が、ほかの仮想化技術との大きな違いだ(ただし、各インスタンスは固有のアプリケーションとユーザー・アカウントを保有する)。
コンテナ技術は、今までの仮想化技術と比べて早いよっていうのが、ようやくわかった!
仮想化では OS を起動する必要があるため、起動には長い時間がかかります。一方、コンテナはプロセスを起動するように仮想環境を構築できます。コンテナのほうが効率がよいからといって、コンテナが仮想化を置き換えるとか、仮想化は古いというわけではありません。
コンテナ=プロセスなので、ようやく合点がいった!
2021/11/29(月) グランドフィナーレ - 振り返り回
雑に感想
- Scrapの投稿上限を超えた話w
- ようやったね!w えらい!
- 2021/01/14スタートで、50回!
- 100~120hくらいかな?
- わりと気楽にやっていた感じがある
- 辛いときもあったと思う
- 気づけば終わってた?w
- 当初の想定より、システムプログラミングがわかっている状態ではなかった!w 奥が深いね
- Linuxの世界に踏み込めるようになった気がする
- Cも意外と触れる経験と勇気
- 文献や語彙のindexが増えた!
- 目に見えにくいところが鍛えられた感じ
- 2000年前半の記事の安心感
- 本の図解にめっちゃ文句言ってた記憶があるw
- 誤字脱字に関するPR結構出した!
- 目標が低いのがよかった! 音読するか写経すればOK。「効率の良さとか、ちゃんと理解する」は努力目標。
- システムプログラミングは飛空艇
- なにはともあれ完読した経験はデカいと思う! 下手に飛ばさなかった!
- XPまつり会はおもろかった!
感想のコーナー
-
Goシスから派生して読んだ本は多い
- ふつうのLinuxプログラミング
- Linuxによる並行プログラミング
- Real World HTTP
- etc...
-
10ヶ月後あたりにGoをプロダクションコードで触る
- Gin
- なんとなく触れた
-
最後の方はGoに対するモチベーションは低かった
-
なんでこんなに続けられたかな?
-
月曜日、木曜日なんかしらやるようになった
-
仕事終わりの後にやると、めっちゃ眠い時があった
-
気になることを数ページ分しか読まないときもあった
-
途中、Linux並行マラソンをやった
- あれはなかなかしんどかったな…
-
気になる単語はちゃんとしらべた
-
同期ブロッキング、同期ノンブロッキングの違いがわからない
- ついでに非同期ブロッキングもよくわからない
-
完読というものをちゃんと経験する
- 今、欲しいかどうかはわからない。けど、読む
-
ペアでの読書の威力
-
こういう読書スタイルもアリだなっていう
完!