Open6
DynamoDBからLambdaで100万件のデータを引っこ抜いてみる
ゴール
- DynamoDBからLambda関数で大量のデータ(100万件)を全件取得する際のパフォーマンスと料金について調べる。
- DynamoDBから大量データを全件取得する場合の最適な構成を検討する。
検証概要
以下条件でDynamoDB、Lambdaを構築し、全件データ取得を行う。
DynamoDB
設定
- リージョン:ap-northeast-1
- キャパシティモード:オンデマンド
- テーブルクラス:標準
- レプリケーションなし
- その他デフォルト
データ
- 列数:23
- 行数:1,000,000
- テーブルサイズ:655.4 MB
- S3に配置したCSVを、DynamoDBのS3インポート機能を利用してAWSマネコンからDynamoDBにとり込み検証用テーブルを作成
Lambda
設定
- ランタイム:Python 3.10
- メモリ:128 MB
- エフェメラルストレージ:512MB
- タイムアウト:15分(最大値)
処理
- Boto3のDynamoDBクライアントのScanを利用して、テーブルの全件データを一括取得
- 取得したデータはLambda所のtmpメモリ上に一時保存
- 取得したデータをCSVに書き出し
- CSVをS3バケットにアップロード
コード
import csv
import boto3
def lambda_handler(event, context):
print("start function")
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('dynamodb-table-name') # テーブル名を適切に置き換えてください
print("start table scan")
response = table.scan()
print("end table scan")
items = response.get('Items', [])
print("end get items")
if not items:
print("No data found")
return {
'statusCode': 200,
'body': 'No data found'
}
csv_file = "/tmp/dynamodb_data.csv" # Lambda関数内の一時ディレクトリにCSVファイルを作成
print("start write csv")
with open(csv_file, 'w', newline='', encoding='utf-8') as csvfile:
fieldnames = items[0].keys()
writer = csv.DictWriter(csvfile, fieldnames=fieldnames, quoting=csv.QUOTE_ALL)
writer.writeheader()
writer.writerows(items)
print("end write csv")
s3 = boto3.client('s3')
s3_bucket = 's3-bucket-name' # S3バケット名を適切に置き換えてください
s3_key = 'dynamodb_data.csv'
print("start upload s3")
s3.upload_file(csv_file, s3_bucket, s3_key)
print("end upload s3")
print(f"CSV file uploaded to s3://{s3_bucket}/{s3_key}")
return {
'statusCode': 200,
'body': f'CSV file uploaded to s3://{s3_bucket}/{s3_key}'
}
いきなり実行は料金爆発が怖いので、料金について調べる。
- 書き込みキャパシティーユニット (WCU): 0.000742USD/WCU
- 読み込みキャパシティーユニット (RCU): 0.0001484USD/RCU
このツールで料金を計算する。
- 料金見積もり:0.29 USD/month
- 補足
- 今回の検証で実行するLambdaは書き込みはせず、読み取りのみ
- WCU:1
- RCU:1,000,000
- ストレージ:1GB (実際の使用量は600~700MB)
- 無料枠を適用
- その他はデフォルト設定
- クロスチェック
- 同条件で計算した場合、約40円/月 で大きなずれはなさそう。
特に料金の心配は無さそうなので検証を進める。
事前検証
Lambda関数の実行はせずに、まずはAWS CLIでDynamoDBの件数を取得してみる。
aws dynamodb scan --table-name <dynamodb-table-name> --select "COUNT"
response
{
"Count": 1000000,
"ScannedCount": 1000000,
"ConsumedCapacity": null
}
ちゃんと取得できた。所要時間は40~50秒。
検証実施
AWS CLIのコマンドでLambda関数を実行。
aws lambda invoke --function-name <dynamodb-table-name> output.json
response
{
"StatusCode": 200,
"FunctionError": "Unhandled",
"ExecutedVersion": "$LATEST"
}
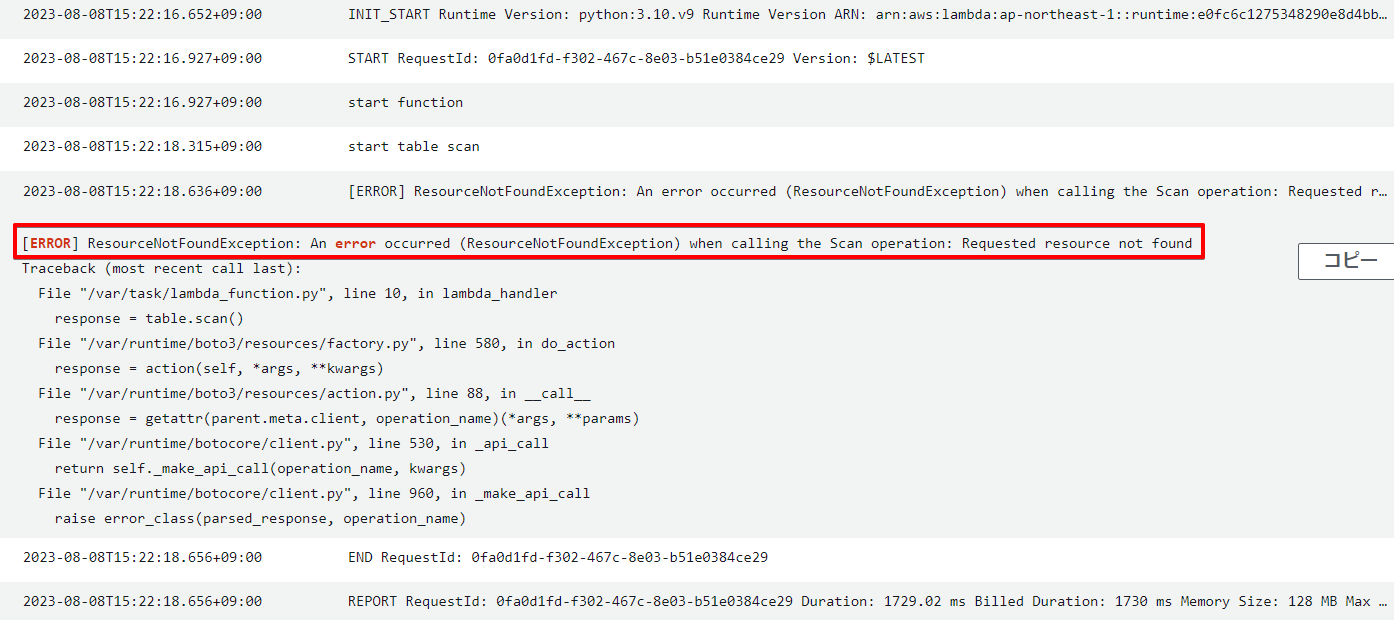
エラーになった。
例: リクエストされたテーブルが存在しないか、ごく初期の CREATING 状態にあります。
テーブル名を間違えていたので修正して再実行。
response
{
"StatusCode": 200,
"ExecutedVersion": "$LATEST"
}
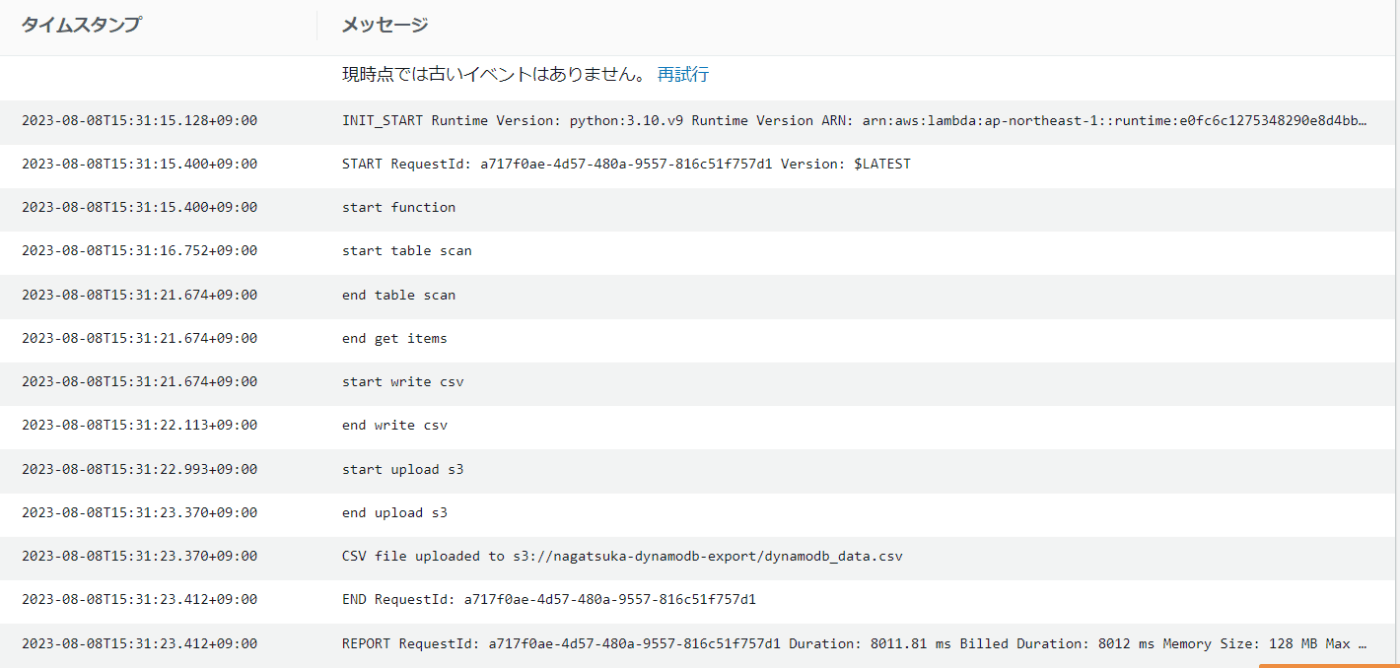
今度は成功。ログも問題なし。
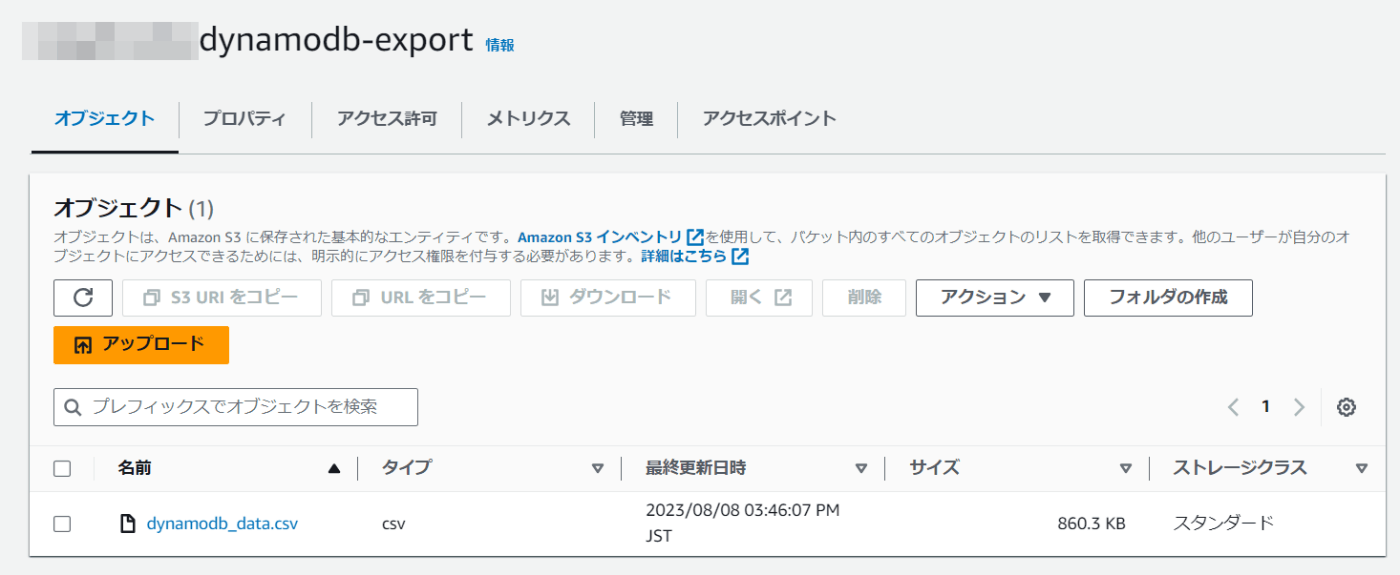
S3にCSV出力完了。
実行時間:約8秒
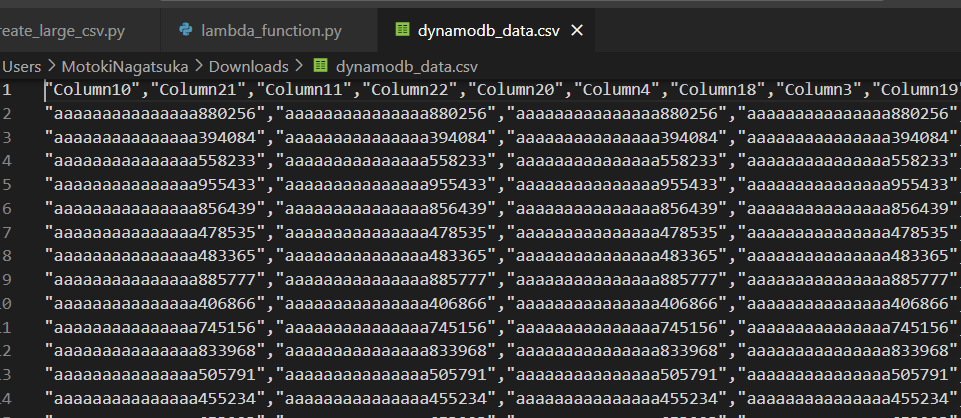
列も行もソートされていない。
列はプライマリーキーのみ先頭に固定、行はプライマリーキーの昇順でソートしたい。
以下パターンで追加検証を行う。
- 行のみソート
- 列のみソート
- 行・列 両方ソート
1. 行のみソート
コード
lambda_function.py
import csv
import boto3
def lambda_handler(event, context):
print("start function")
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('dynamodb-table-name') # テーブル名を適切に置き換えてください
print("start table scan")
response = table.scan()
print("end table scan")
items = response.get('Items', [])
print("end get items")
if not items:
print("No data found")
return {
'statusCode': 200,
'body': 'No data found'
}
+ # プライマリーキーでソート
+ items_sorted = sorted(items, key=lambda x: x['PrimaryKey']) # 'PrimaryKey'をプライマリーキーのフィールドに置き換えてください
csv_file = "/tmp/dynamodb_data.csv" # Lambda関数内の一時ディレクトリにCSVファイルを作成
print("start write csv")
with open(csv_file, 'w', newline='', encoding='utf-8') as csvfile:
fieldnames = items[0].keys()
writer = csv.DictWriter(csvfile, fieldnames=fieldnames, quoting=csv.QUOTE_ALL)
writer.writeheader()
writer.writerows(items)
print("end write csv")
s3 = boto3.client('s3')
s3_bucket = 's3-bucket-name' # S3バケット名を適切に置き換えてください
s3_key = 'dynamodb_data.csv'
print("start upload s3")
s3.upload_file(csv_file, s3_bucket, s3_key)
print("end upload s3")
print(f"CSV file uploaded to s3://{s3_bucket}/{s3_key}")
return {
'statusCode': 200,
'body': f'CSV file uploaded to s3://{s3_bucket}/{s3_key}'
}
- 実行時間:8.4秒
2. 列のみソート
コード
lambda_handler.py
import csv
import boto3
def lambda_handler(event, context):
print("start function")
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('dynamodb-table-name') # テーブル名を適切に置き換えてください
print("start table scan")
response = table.scan()
print("end table scan")
items = response.get('Items', [])
print("end get items")
if not items:
print("No data found")
return {
'statusCode': 200,
'body': 'No data found'
}
csv_file = "/tmp/dynamodb_data.csv" # Lambda関数内の一時ディレクトリにCSVファイルを作成
print("start write csv")
with open(csv_file, 'w', newline='', encoding='utf-8') as csvfile:
fieldnames = items[0].keys()
writer = csv.DictWriter(csvfile, fieldnames=fieldnames, quoting=csv.QUOTE_ALL)
writer.writeheader()
writer.writerows(items)
print("end write csv")
s3 = boto3.client('s3')
s3_bucket = 's3-bucket-name' # S3バケット名を適切に置き換えてください
s3_key = 'dynamodb_data.csv'
print("start upload s3")
s3.upload_file(csv_file, s3_bucket, s3_key)
print("end upload s3")
print(f"CSV file uploaded to s3://{s3_bucket}/{s3_key}")
return {
'statusCode': 200,
'body': f'CSV file uploaded to s3://{s3_bucket}/{s3_key}'
}
8.2
3. 行・列 両方ソート
コード
lambda_function.py
import pandas as pd
import boto3
import io
import csv
def lambda_handler(event, context):
print("start function")
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('<dynamodb-table-name>') # テーブル名を適切に置き換えてください
# データをすべて取得
response = table.scan()
items = response.get('Items', [])
if not items:
print("No data found")
return {
'statusCode': 200,
'body': 'No data found'
}
# 列項目リストを定義
column_order = ['Column1', 'Column2', 'Column3', 'Column4', 'Column5', 'Column6', 'Column7', 'Column8',
'Column9', 'Column10', 'Column11', 'Column12', 'Column13', 'Column14', 'Column15',
'Column16', 'Column17', 'Column18', 'Column19', 'Column20', 'Column21', 'Column22', 'Column23'] # 列項目の並び順に置き換えてください
# DataFrameにデータを読み込み、指定した列項目のみを選択して処理
df = pd.DataFrame(items)[column_order]
# PrimaryKeyで行を昇順にソート
df_sorted = df.sort_values(by=['Column1'])
csv_buffer = io.StringIO()
df_sorted.to_csv(csv_buffer, index=False, quoting=csv.QUOTE_ALL)
s3 = boto3.client('s3')
s3_bucket = '<s3-bucket-name>' # S3バケット名を適切に置き換えてください
s3_key = 'dynamodb_data.csv'
print("start upload s3")
s3.put_object(Body=csv_buffer.getvalue(), Bucket=s3_bucket, Key=s3_key)
print("end upload s3")
print(f"CSV file uploaded to s3://{s3_bucket}/{s3_key}")
return {
'statusCode': 200,
'body': f'CSV file uploaded to s3://{s3_bucket}/{s3_key}'
}
- 実行時間:9.8秒
- 文字列と数値が混ざっていると想定通りのソートにはならない(もう少し工夫がいる)