こんにちは。松尾研究所シニアデータサイエンティストの太田です。
先日自己紹介にて「松尾研究所のPMは裁量を持たせてもらえる」「しかしそれがむずい」というお話をさせていただきましたが、ここでは僕が最初に携わったプロジェクトであるLLMの事後学習プロジェクトにおいて、どのように実験を管理したかについて共有したいと思います。
松尾研究所に入る前、画像解析モデルの構築はしていたものの基本はワンマンプレイであり、複数名のメンバーと共に(尚且つ未知の領域であるLLMの事後学習の)実験を走らせるというのは初の経験でした。この記事ではプロジェクトに揉まれる中でチームが培った方法論のいくつかを「ベストプラクティスに至るその途中」と一種の旅行記としてお話します。
この記事は松尾研究所 Advent Calendar 2025の記事です!
背景
まず本プロジェクトの背景ですが、現在僕のチームではLLMを特定のタスクに特化すべくSupervised Fine-Tuning(教師あり学習;以後SFT)やReinforcement Learning(強化学習;以後RL)を用いた開発を進めています。チーム構成は僕を除いて約5名であり、1名は学習データの構築ともう1名は評価指標の設計とベンチマークに専念し、残り3名がモデルの高度化に勤しんでいます。
なお技術スタックとしては下記を利用しています。
- モデル・データセットの管理はHuggingFace
- 強化学習のコードはtrlをベースにしたもの
- 実験管理にはWeights&Biasesを利用
- 横断的な取りまとめや報告にはNotionを利用
本稿では事後学習パイプラインの中でもRLに限定し、どのようにW&Bで複数名体制で実験管理を行なっているか紹介します。特にRLの中でも近年注目を浴びているGRPOの例をとって説明します。なおこの記事では強化学習の手法そのものについては(記事の理解において必須でない限り)割愛するので、興味のある方は例えば最近でたこちらの記事を参考にしてください。(体系的にかつ初心者でもわかる形でまとめられておりおすすめです!)
なぜ実験管理を真面目に考えるのか
僕らのプロジェクトでの試行錯誤に移る前に、まずはW&Bの基本の簡単なおさらいと、なぜ「基本」では足りないのか、どこが我々のケースで課題になったのかお話ししようと思います。
実験管理の必要性については今更語ることもないと思う(例えばこちらを参考にしてください)のですが、ここでは「ただLLMOpsツールを導入するだけでは片手落ち」というのを失敗談を通じて伝えることができれば幸いです。
W&Bの基本
Weights & Biases (以下W&B)の基本についてですが、、正直公式ドキュメントを見るのが良いと思います。
W&BとはMLOpsの総称で語られる機械学習・深層学習モデルの実験管理プラットフォームの一つです。直感的に利用できるPython SDKを学習コード内で利用することで、モデルの学習過程や評価結果をダッシュボードにロギング(可視化)することができます。
インストール後には基本的には学習コード内に下記の数行を入れることで初期化できます。
import wandb
wandb.login() # APIキーを設定する必要あり
wandb.init()
我々のプロジェクトの場合、基本的にHuggingFaceの学習スタックを利用しており、ロギングは至ってシンプルです。
from transformers import TrainingArguments, Trainer
training_args=TrainingArguments(..., report_to="wandb") # ロギング先をW&Bに指定
trainer = Trainer(..., args=training_args)
そうするとこのような形でW&Bのダッシュボードで実験の経過を確認することができます。
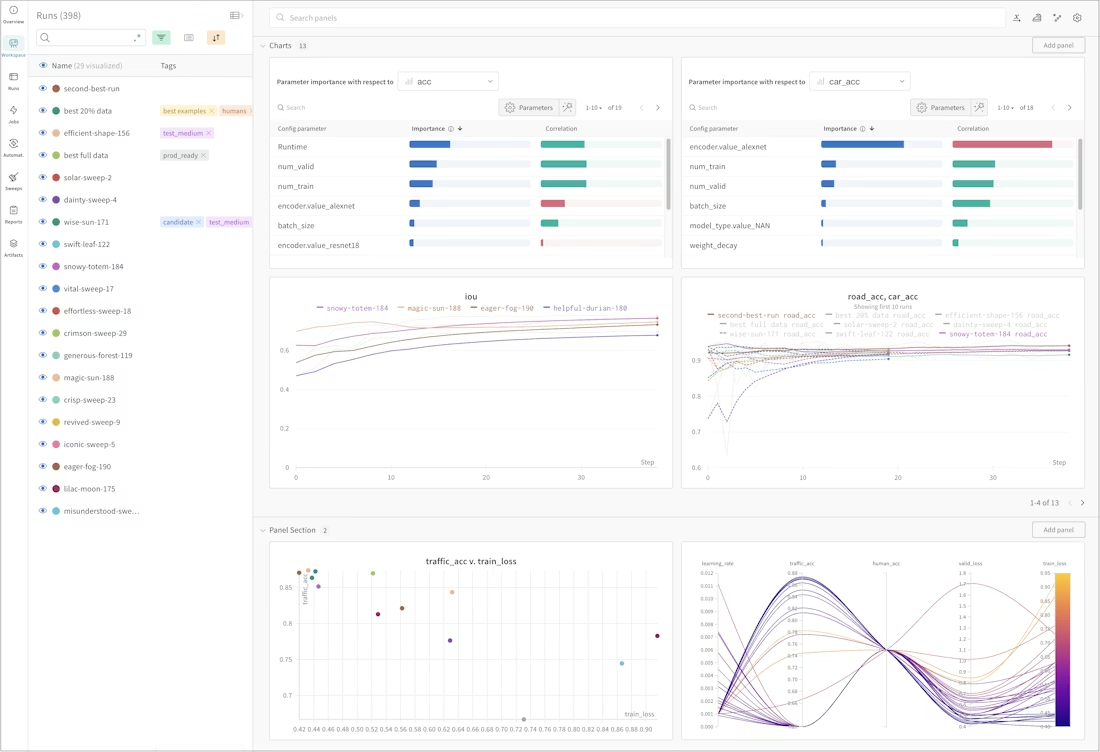
公式ドキュメントより。
なお、実験をトラックする上ではロギングの初期化時に
-
project: 複数の実験を束ねるproject名 -
name: 単一の実験に該当するrun名
を指定することも可能です(未指定だとランダムな文字列)。
wandb.init(project="my_project", name="awesome_training")
我々が直面した課題
さて、W&Bは上記の通り非常に初期設定が楽です。では上記のみで複数のメンバーを巻き込んだ、中長期にわたる、実験が管理できるかというと答えはNoです。
理由を述べる代わりに我々が直面した課題を列挙します。
管理の課題
当初実験の名称(上記 project / run と呼ばれるもの)を一定メンバー任せにしていたところ、粒度の異なるプロジェクトや本人しかわからない実験名が乱立し、後から実験を探し出すのが非常に困難となりました。
報告時の課題
実施した実験についてはNotionで結果をまとめ報告するよう管理していたものの、結果として実験結果がW&BとNotionに乱立し、双方を常に行き来する・関連性がわからなくなって確認する、というイケテない運用になっていました。
分析時の課題
前述の通り、我々が試用している学習手法の一つにGRPOがあります。詳細はトグルに隠しますが、こちらはオンライン学習(Online RL)と呼ばれる手法の一つであり、学習過程を通じてモデルが自ら与えられた質問に対して回答を生成し、これを何かしらの手段で評価する、という手法になっています。
GRPOとは
GRPO (Group Relative Policy Optimization) とはLLMの強化学習における手法の一つであり、DeepSeekのDeepSeek Mathで初めて導入され、DeepSeek R1における低リソースでのReasoningモデル実現をきっかけに、LLMのRL界隈で爆発的に流行り出した手法です。
従来のLLMにおけるOnline RLがPPOに代表されるActor-Critic型の強化学習(Actorモデルが質問に対する回答を生成しそれをCriticモデルが評価・二つのモデルを同時に扱う必要がある)であったことに対して、GRPOはCriticを撤廃しています。
Criticとはモデルの回答の正誤を判定する機能とは別に、「モデルの回答が正例にどの程度近いか」を連続的に評価する役割を持ちます。GRPOではその二つの機能をデカップルすることで大幅な効率化を実現しています。具体的には
- 回答の正誤判定:ルールベースで実施。例えば数学タスクであれば、最終的な数値が正しいか否か0/1で判定。
- モデルの性能の連続的な評価:同一質問に対してモデルに複数の回答を生成させて(=回答のグループを作る)、グループ内での相対評価を実施。
ここでのポイントはいずれも大規模なモデルを別途準備する必要がないことです。特に後者のグループ評価が肝であり、十分な量の回答を生成すれば(一般的には64個)自然と回答の優劣が生まれモデルに対して連続的な評価ができます(初期では1/64しか正解できなかったモデルが徐々に64/64に近づいていく)。また回答の正誤判定についても、ルールベースにこだわる必要は全くなく、非常に高い柔軟性を持っています。後述にも記載する通り、我々のプロジェクトでは主に外部基盤モデルを活用したJudgeLLM(一般的には Generative Reward Model と呼ばれるもの)を利用しています。
GRPOは非常に強力であり、何よりその低リソース性から強化学習の民主化に大きく貢献しています。他方でデメリットはいくつかあり、わかりやすい例として下記が挙げられます。
- 報酬のシグナルがスパースであること:学習対象であるポリシーモデルは「成功したか否か」の情報は得られますが、「なぜ失敗したか」の情報は基本的に得られません。そのため学習効率は必ずしも高くありません(64個の中で1個の回答がたまたま正しくできるよう祈るしかない)。
- なお近年ではGRPOにて回答に至った過程を評価する Process Reward Modelの考えを導入する研究も増えています(参考)
- インフラが成熟していないこと:GRPOを使った強化学習が低リソースでできるとはいえ、そのトレードオフとして64個もの回答を生成する必要があります。Online RLにおいてロールアウト(ポリシーモデルの回答)生成が計算ネックになるのはつきものですが、こちらの最適化について未だ各研究機関が模索している印象です。
オンライン学習を実施する上では、学習途中のロールアウト(学習途中であるポリシーモデルが生成した出力)と報酬(ロールアウトに対する「点数」)を分析することが重要となります。ロス等の見かけ上はモデルの学習がうまく行っていても気づけば報酬ハックが生じている、と言うのは多々あることです。このオンライン学習特有の観測手法がチームで浸透しておらず分析の粒度にばらつきがあることが一つの課題でした。
報酬ハックについて
報酬ハックとはその名の通り、学習途中のモデルが想定している方法とは別の方法で報酬を獲得することを指します。報酬モデルとは前段の「GRPOとは」で説明した通りモデルの出力の正誤性を判定する機構となりますが、ここの設計が甘いとハッキングが生じてしまいます。とてもシンプルな例として、「回答を500字以内に収めるモデルを構築したい」としましょう。そこでGRPOを使って下記のようなルールベースでの報酬を設計します。
def length_reward(answers: str):
if len(answers) <= 500: # 500字以内なら報酬(1点)を与える
return 1.0
else # でないと0点
return 0.0
これでうまく行くかというと、、答えはNoです。上記の報酬のみではやがてモデルは
「」
と何も出力しなくなります。
モデルは学習を進めることで「どうやら短い回答の方が点数をもらえるらしい」と学ぶのですが、同時に「これ何も発言しなければ毎回高得点もらえるんじゃね?」と言う絡め手、すなわち報酬ハックを発見するのです。
報酬ハックはLLMに始まった話ではなく古の強化学習からあるものの、LLM特有の柔軟性がことをややこしくしているのは否めません。報酬ハックを回避する技術、報酬デザインはそれ単体で非常に興味深い内容なのでいずれどこかでまとめたいものです。
評価時の課題
それがどんなモデルであれ、機械学習を実施する上では構築したモデルの評価が最重要となります。我々のプロジェクトでも例外なく、学習途中や学習後にValidationセットや各種ベンチマークに対して評価を実施することでその性能を定量的に計っています。しかし当初のモデル構築パイプライン上では学習と最終評価が独立して走っており(学習が終わってから、各種ベンチマークを回す)後から実験に評価を紐づけるのが困難になっていました。
基本のその先へ
この通り、W&Bの「基本通り」の利用ではチーム内の実験が統一できないことや、十分な分析ができない状況に陥っていました。しかしこれらを打破する機能やベストプラクティスは最初からW&Bに備わっています。以降ではどの機能を使ってどう課題を解決したか紹介したいと思います。
実験管理入門
思想
実装に入る前に、実験管理を進めるにあたって意識した思想について簡単に説明したいと思います。それは「実験を管理するという行為そのものを透明化する」ことです。言い換えれば、実験管理を個人のタスクとするのでなく、仕組みでカバーすることを指しています。
とてもシンプルかつ象徴的な例をあげると、前述の run (単一の学習からなる実験)の名称については、「こういう命名規則で実験名を決めてね」とメンバー頼りにするのではなく、「このパイプラインで実行すればユニークな名前が付与される」とコード側を整備しています。
これは当たり前と言えば当たり前のこと(恥ずかしながら自分はそれもできていなかった)ですが、run 名に限らず上記の思想を全体的に意識しました。
実験管理の高度化
まず最初に実験管理です。前述の通り煩雑な run 名や、本人しかわからない各種実験の関連性をどうするか。そのためにはW&Bが提供する構造化のフレームワークに目を向けます。
実験の定義合わせ
W&Bにおいて実験は entity/project/run の階層構造で登録されます。
-
entity: 組織。基本固定(matsuo-instituteなど)。 -
project: プロジェクト。ユーザーが任意で決める実験群の単位。 -
run: スクリプトの実行ログ。単一の学習を指す。
entity は基本的に固定であるとして、まずは project の粒度感の共通認識を作りました。私のチームでは基本的に一プロジェクト=一実験で運用しています。
ここでの「実験」とは、「特定の仮説を検証するための多数の試み」を指します。一例としては
- SFTにおけるデータ混合の検証(仮説例:「日本語データと英語データを5:5で入れることで性能維持できるのではないか」)
- DPOにおける学習率の検証(仮説例:「学習率を下げることで過学習を抑えられないか」)
- GRPOにおけるGRMプロンプトの検証(仮説例:「プロンプトをいじることでハックを抑えられないか」)
理想としては一つの実験( project )内に特定のパラメタ(ハイパラ、だけでなくプロンプトなど、広義)を変えた複数の実行( run )がまとまっており、実行間の比較から当初の仮説の良し悪しを語れることです。
命名基準
これでプロジェクトと実験の粒度に関する目線合わせができました。では、これらをどう命名すべきか?プロジェクトに横断して命名規則を決めるのが一つの手ですが、前述の思想の通り、ルールで縛るのではなく仕組みで縛る設計にしています。
我々の学習コードは基本的に設定ファイル(モデルのハイパラ等が記載された yaml ファイル)一つで実験を回せるように整備をしているのですが、project と run の名称はユーザーからの入力でなく、この設定ファイルのパスから取得するよう構築しています。
config/{project_name}/{run_name}.yaml
学習を回すときは、必ず設定ファイルを作成する必要があるので、「同じ実験群の学習は必ず同一ディレクトリで回そう」とすることで構造から名称を決めています。
なおproject_name , run_name については特に命名基準は設けておらず、実験ファイルから象徴的なパラメタを取って名称に加えるよう設定しています。
また、W&Bには実験を管理する上で、project run の構成とは他にタグ機能を導入しており、こちらも設定ファイルから自動で付与するよう整えています。タグを整備していると、W&Bダッシュボード上での検索性や視認性が高まります。
def derive_names(config):
"""Derive project, segment, run_name from config path + content"""
if not config._config_path:
raise ValueError("Config path not set; load with from_yaml()")
p = Path(config._config_path)
# Expect: config/<project>/<file>.yaml
if p.parts[-3] != "config":
raise ValueError(
f"Expected config path like 'config/<project>/<file>.yaml', got: {'/'.join(p.parts[-3:])}"
)
project = f"{config.train_method}-{slug(p.parent.name)}"
config_name = slug(p.stem)
segment = slug(config.model_name.split("/")[-1])
if config.task and config.subtask:
task = f"{slug(config.task)}-{slug(config.subtask)}"
run_name = f"{config_name}-{segment}-{task}"
else:
run_name = f"{config_name}-{segment}"
return project, segment, run_name
def auto_tags(config, project: str, segment: str) -> List[str]:
"""Automatically add tags for wandb tracking."""
tags = list(config.wandb_tags)
tags.append(f"method:{config.train_method}")
if config.lora_r:
tags.append(f"lora:{config.lora_r}")
tags.append(f"dataset:{slug(config.dataset_name.split('/')[-1])}")
tags.append(f"model:{slug(config.model_name)}")
tags.append("status: scratch") # Track status
# deduplicate
seen, uniq = set(), []
for t in tags:
if t not in seen:
uniq.append(t)
seen.add(t)
return uniq
ロギングの高度化
ここではW&Bにログを拡充する手法をいくつか見ていきたいと思います。
ログの追加
前述の通り、W&Bは対応している学習フレームワークを活用していれば、 wandb.init() さえ実施すれば、あとは勝手にログを収集しダッシュボードで可視化してくれます。我々はtrlをベースにしているため、そこは例外ではありませんでした。しかし、利用している学習フレームワークが自分たちの欲しい出力をデフォルトでカバーしているかというと必ずしもそうではありません。
ドキュメントを漁る
カスタムなロギングに対応するためには、まず学習フレームワークが標準で対応していないか見てみます。ここではtrlのGRPOTrainerの例を見てみましょう。公式ドキュメントをよくよく漁ってみると、、

GRPO特有のロギングパラメタとして log_completions がありました。デフォルトでは無効になっていますが、こちらを有効にすることで各ステップにおけるポリシーモデルのロールアウト(オンライン生成内容)を確認することができます。
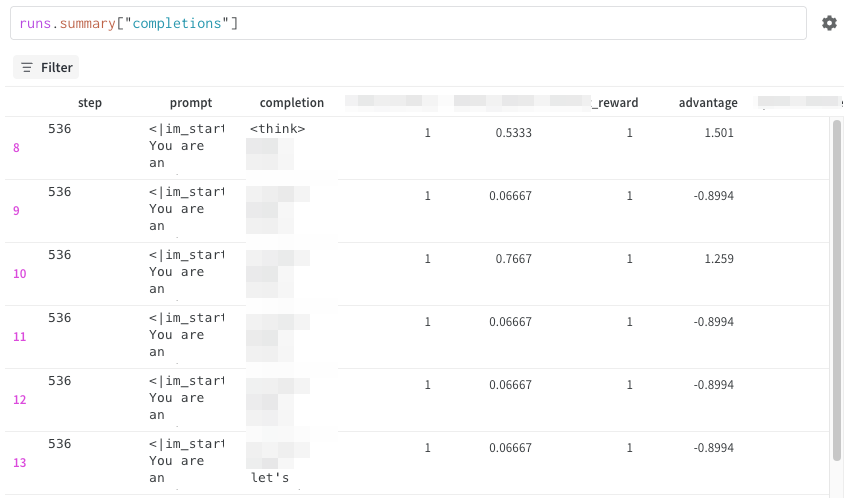
独自ログを追加する
上記のように学習フレームワークの設定で完結するのであれば良いですが、場合によっては自らログを追加する場合があります。W&Bでは簡単に好きな変数をダッシュボードにロギングすることができます。
metric = 42
wandb.log("my_metric/metric": metric)
こちらは実行されるたびに step という特別な変数が加算され、ダッシュボード上でステップ経過に伴う変化を追うことができます。
なおこちらの変数は数値である必要はなく、画像であったり、テーブルをロギングすることが可能です。特にテーブルはW&B上での簡単なJOIN処理等にも対応しており、上記のGRPOTrainerのロールアウトのログもテーブル型データでロギングされています。
Artifactの利用
W&BはArtifactと呼ばれる、実験に紐づける形での静的ファイルの保存方法があります。これは前述の(ステップと呼ばれる潜在変数を持つ)学習過程と共に進化するログとは異なり、モデルへのインプットやアウトプットを代表としたW&Bに保存する単一のファイルのイメージです。
我々のチームではArtifactを主に二箇所で活用しています。
- モデル学習後の最終評価の結果(各種ベンチマークでの結果)
- モデル学習時の実験ファイルの保存
最終評価の結果については後述の「分析の高度化」パートで詳細に説明するので、ここでは実験ファイルの保存について簡単に触れたいと思います。
前述にも記載した通り、現在私のチームでは全ての実験を一実験=一設定ファイル(yamlファイル)で運用しています。実験の再現性を担保するにあたっては、こちらのyamlファイルを学習結果が保存されるローカルのOutputディレクトリに保存するとともに、クラウド上でも残すことを意味してArtifactを使ってW&Bの実験にも紐付けます。
source_path = "path/to/config.yaml"
target_path = "path/to/output/"
# まずはモデルの出力先にローカルコピー
shutil.copy2(source_path, target_path)
# 次にW&BのArtifactとしてクラウドに保存
artifact = wandb.Artifact(f"training-config-{wandb.run.id}",
artifact.add_file(str(source_path), name="config.yaml")
wandb.log_artifact(artifact)
こうすることでチームメンバーの誰もが同じ実験を再現できます。

W&B Weaveの活用
さてここまで紹介したW&Bの機能ですが、これらは総じてW&B Modelsと呼ばれる実験管理システムです。実はW&Bと言っても色々なソリューションが存在しており、例えば推論プラットフォームやストレージなども提供しています。

W&Bの公式サイトより(参考)
ここではそれらのソリューションの一つ、W&B Weave について簡単に紹介したいと思います。
Weaveとは
W&B Weaveとは上記の画像にも記載の通り、LLMエージェントを構築するためのソリューションです。これは近年話題のLLMOpsと呼ばれるLLM特化した実験管理です。LLMOpsについての記事は例えばこちらを参照してもらえればと思いますが、Weaveに限らず一般的には下記の観測・評価機能を持っています。
- Traces: LLMの入力や出力を構造的にロギング
- Evaluation: ルールベース・JudgeLLM・HF等を使ったLLMソリューションの評価
- Playground: LLMのプロンプト実験プラットフォーム
- Prompt Management: プロンプトのバージョン管理
RAGの例
LLMOpsの必要性をRAGを通じて見てみましょう。RAGとは一見シンプルであるものの、実際はさまざまな要所で細かなチューニング(エンジニアリング)が必要です。

以前松尾研究所で実施したLT会「LiteLLM+LangFuseでOS LLMOps」から抜粋
最もシンプルなところだと、RAG最終ステージの生成時にどのようなプロンプトを使うべきか。あるいはRetrievalステージでRerankerを使った際にどのような書類が残っているのかetc.etc. これら各要素を高度化する上では、ソリューションの全体像(E2E)と各要素の詳細をしっかりと監視し評価することが必須です。
これらを可能にするのがLLMOpsと呼ばれるツールです
さて我々はLLMモデルの開発を行っているのであり、LLMソリューションの開発を行っているわけではありません。そのため一見Weaveは場違いのように見えます。やろうと思えばweaveでLLMの評価の一元管理ができるものの、正直オーバーキルです。
我々がWeaveに着目した理由は、現在利用している学習手法、GRPOにあります。
「GRPOとは」でも簡単に説明した通り、GRPOはCriticを必要としない強化学習であり、代わりにVerifiable RewardsとGroup Rolloutsを必要としています。
このVerifiable Rewards(「検証可能な報酬」)ですが代表的なDeepSeek R1などでは、数学タスクについてモデルの出力した最終回答が実際の正例(数字)と一致しているか否かルールベースで見るものでした。そこからRLVR (Reinforcement Learning with Verifiable Rewards) は進化していき、今ではVerifiable RewardにJudgeLLMを使うことも多々あります(代表的な例)。
JudgeLLMを使うことで、数学タスクであればルールベースでは難しかった回答一致の柔軟な検証が可能になったり、そもそも数字の出力にこだわらずあらゆるタスクに置いてRLVRが可能になります。
RLVR...? JudgeLLM...?
「JudgeLLMを使ったRLVRはそもそもRLVRと呼べるのか」という疑問が沸きます。ルールベースだったからRLVR(検証可能)であって、JudgeLLMを使っていると決定性が担保されないんじゃないかと。実際に外部AIを使って強化学習を使う手法は(人手で報酬を与えるReinforcement Learning with Human Feedback/RLHFと対比して)RLAIF (Reinforcement Learning with AI Feedback)と呼ばれることもあります。
ここは正直名前がまとまっていない印象はあるのですが、あくまでも僕の理解だとRLHF/RLAIFは基本的にBradley-Terryライクなアラインメントタスク(回答Aと回答Bのどちらが好ましいかという問題設定)に利用される一方で、単体の回答そのものにスコアを付与するものに関してはCritique Rewardであったり、Verifiable Rewardが使われている印象です。下記の図がわかりやすいかなと。
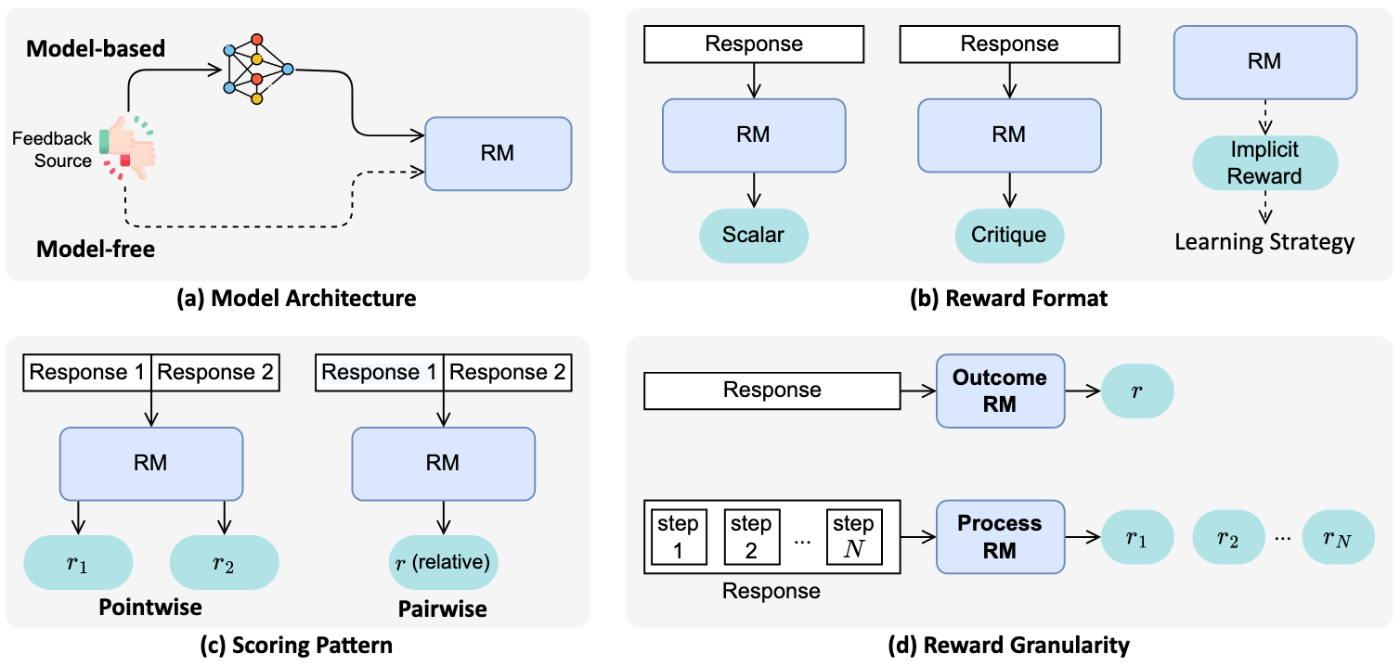
例えば上記の図の整理だと、RLHFはModel-based/Scalar/Pairwise/Outcome に基本的になり、ルールベースのRLVRは Model-free/Rule/Pointwise/Outcomeに、JudgeLLMを使ったものは Model-free/Critique/Pointwise/Outcome になります。
またより厳密にいうと、強化学習の文脈で報酬を与えるのに生成AIを活用する際には、報酬モデルのことを(JudgeLLMではなく)Generative Rewad Model と呼ぶこともあります。この辺の名称も定まりきっていない印象ではあるのですが、下記が図としてはわかりやすかったです。

我々のプロジェクトにおいても報酬モデルにJudgeLLM(あるいは別途学習したGRM)を使うことが多々あり、JudgeLLMの挙動、特に
- JudgeLLMの入力(ロールアウトの受け取り方・プロンプト)出力(スコア)は何か
- Reasoningモデルを使っている場合、最終スコアに至ったJudgeLLMの判断基準は何か
をWeaveのTrace機能を使って検証しています(詳細は後続にて)。
モデル開発におけるWeave活用術
さて、W&B Modelsをすでに使っているプロジェクトでWeaveは利用するのは非常に簡単です。学習コード冒頭にて
import weave
と入れるだけで完了です!あとは wandb.init() を実行した時に勝手にweaveも動いてくれます。特にOpenai APIやメジャーな推論SDK(vLLMなど)使っている場合は、指定せずともLLMの推論が走るたびに勝手にトレースをロギングしてくれます。

OpenAI Python SDKを使った際の例(公式Docから抜粋)。Input/Outputはもちろん、コストなども取ってくれている。
なお、自作の関数の入力・出力をロギングする上では
import weave
@weave.op() # ここが重要
def my_function(input):
output = 2*input
return output
とデコレーター一つで関数の入力値・出力値のロギングが可能となります。
Weaveの特徴としていくつか挙げると
-
weave.opはW&Bのロギングのように内部でstep変数を持っているので、学習ループの中に入れれば学習ステップに対する進化も追うことも可能 - Nested Callがある場合(
wave.opした関数がweave.opした別の関数を呼び出す)勝手に構造化をしてくれる
今回はモデル学習の一環のため基本的な機能しか使用していませんが、WeaveはLLMOpsに必要ないろいろな機能を提供しているのでぜひドキュメントを見てみてください。
既存実験の更新
最後に既存の実験の更新についてです。例えば学習の途中でエラーが起きて、中途半端なチェックポイントで終わった場合や、あるいは学習実施後に別途評価用のパイプラインを実行し結果を同じrunに対してロギングしたい場合などは下記のようなコードで対応できます。
wandb.init(project=project, id=run_id, entity=entity, resume="allow")
分析の高度化
前の章で紹介したロギングの手法ですが、こちらを活用することでどのような分析が可能になるのか簡単に紹介したいと思います。
テーブルを使った評価の管理
まずArtifactのテーブルの利用についてです。
こちらは最も簡単な例として、学習後のベンチマークのロギングと実験ごとの相対比較が可能となります。例えば学習を回した後でモデルをベンチマークに対して評価するとしましょう。下記のようなコードを使うと
benchmark_name = "mybench_1" # 実際に存在するベンチマーク名
# `run_benchmark` 関数はモデルのパスとベンチマーク名を受け取って、ベンチマークを実施するとする。
# ベンチマークの結果は、メタデータとスコアが記載されたdictと、ベンチマークの各項目(質問)に対してモデルの詳細な出力が記載された List[dict] が返ってくるとする
result, detailed_result = run_benchmark(my_model, benchmark_name)
# resultに関しては普通にロギング
wandb.log({f"benchmark/{banchmark_name}": result["score"]})
# 詳細な結果についてはテーブルとしてロギング
data_rows = [] # 1行=ベンチの1質問
columns=["question", "thought", "answer", "score"]
for item in detailed_results:
question = item["question"]
response = item["response"]
# ここでは一例として出力からReasoningトレースの抽出
match = re.search(r"<think>.*?</think>", response, re.DOTALL)
if match:
thought = match.group(0)
answer = response.replace(thought, "")
else:
answer = response
# 別途質問に対する単体スコアがあれば
score = item["score"]
row = [
question,
thought,
answer,
score,
]
data_rows.append(row)
table = wandb.Table(columns=columns, data=data_rows)
wandb.log({"bench/full_results": table})
モデルのベンチマークに対する最終スコアはもちろん、各質問への回答もロギングできます。

テーブルログはLLMと特に相性が良く、W&B上で精緻な応答を確認することが可能です。
またテーブルは簡単な結合処理が可能です。これは複数のRunのベンチマーク結果を横比較する際に便利です。ステップとしては下記の通りです。
- ⚙️ を選択
- Combined Table > Joining Rows > Inner Join
- JOIN Keyを選択(同じベンチマークでのモデルの横比較の場合→
Input)
すると下記のように複数の実験(モデル)間での応答の差分を見ることができます。

文章の横比較は現状ホーバーしないと出てこない(後述のReportを使えば回避可能)ので、もう少し見やすい形になって欲しいのが正直なとこです。
Weaveを使った強化学習の分析
次にWeaveを使った強化学習の分析です。
繰り返しになりますが、現在我々が利用している手法の一つであるGRPO + JudgeLLMにおいては、モデルが学習途中に生成した回答(ロールアウト)に対して、JudgeLLMがどのように評価をつけたのか、報酬ハックが生じていないか、学習経過中に観測することが重要です。
trlを使ったGRPOTrainerにおいては報酬関数は特定の引数と返り値を持ったPythonの関数で定義することが可能です(詳細はこちら)。各ステップにおけるGRPOの挙動を確認する上では、こちらの報酬関数にWeaveのトレースを仕込みました。
@weave.op() # スコア算出関数をラッピング
def get_openai_score(input, model="my_model"):
model = get_model("my_model") # OpenAI, vLLM..
output = model(input) # 推論
return output
@weave.op() # 報酬関数そのものをラッピング
def reward_fn(completions, **kwargs):
with weave.ThreadPoolExecutor() as exc: # 並列計算を想定
outputs = exc.map(get_openai_score, inputs)
scores = [output["score"] for output in outputs]
return scores
上記では並列処理を実施する上で、Weaveの公式ドキュメントに沿って weave.ThreadPoolExecutor を利用しています。また、複数の weave.op を入れたNested Calls を実施しているのも特徴です。
上記のコードの結果が下記のようなものになります。
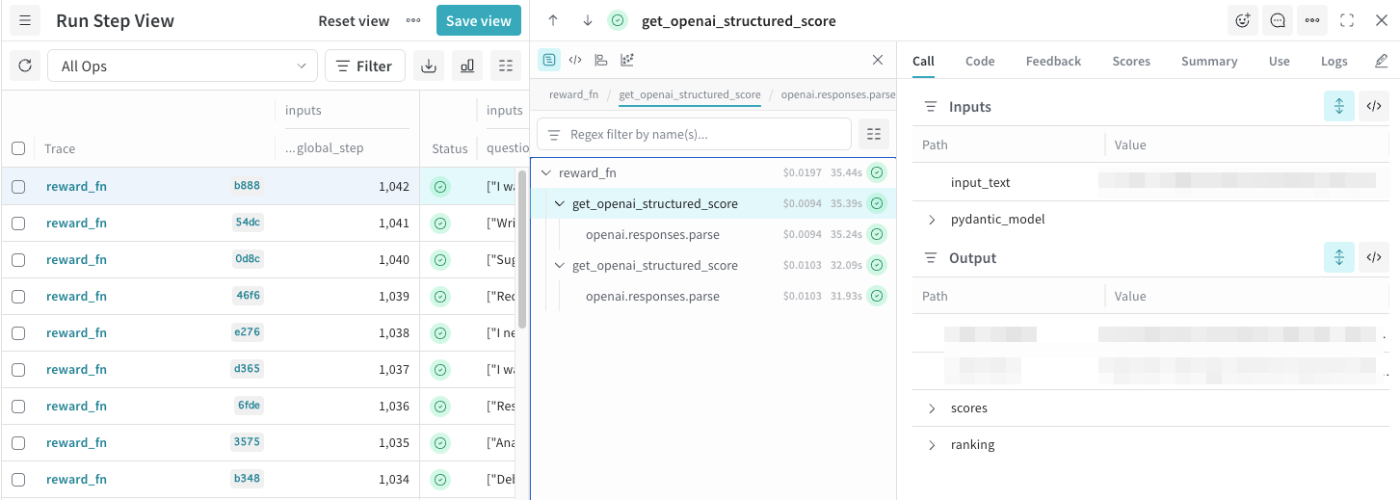
一つの報酬関数内にて各ロールアウトに対応する複数のトレースがネストされました。詳細をクリックすると、各ロールアウトの生成内容やJudgeLLMの付与したスコア、スコアの理由等をさらに深ぼることができます。
上記を分析することで、各ステップにおけるポリシーモデル・報酬モデルの挙動を確認し、双方の高度化に繋げることができます。
タグを使った実験の昇格
これはとてもシンプルなTipsなのであまり語ることもないのですが、メンバーから実験結果についてW&Bを見せながら報告してもらう際には、いい結果が出た場合(今後のベースラインになる、特定の指標が高い、など)は その場で status:staged というタグをつけてもらいます。
こうすることでプロジェクトの終盤等で実験を横断する評価やまとめを実施する際に、これら特定の実験だけ絞り込むことが可能になります。
報告の高度化
いよいよ最後の章です。ここまで来ると冒頭に挙げた課題ってなんだったけとなっているかもしれないのですが(お付き合いいただき中途半端なこの場で感謝申し上げます!)、当初僕のチームでは下記の課題がありました。
実施した実験についてはNotionで結果をまとめ報告するよう管理していたものの、結果として実験結果がW&BとNotionに乱立し、双方を常に行き来する・関連性がわからなくなって確認する、というイケテない運用になっていました。
こちらに応える上で、今回は報告を全てW&Bで完結する というアプローチを取っています。
W&BにはModels, Weave以外にもいくつかソリューションが存在するのですが、そのうちの一つがW&B Reportsです。こちらは端的にいうと「W&Bダッシュボードのインテラクティブなパネルを埋め込むことができるWYSIWYM型Markdownエディタ」です。
公式ドキュメントから引用。
使い方の詳細についてはこちらのドキュメントを確認してもらえばと思います(要はMarkdownエディタなのでNotionとかと使い方は同じです)。
レポートは特定のプロジェクトあるいはホーム画面から作成することができ、特筆すべき要素としては
- プロジェクト横断のログの表示
- パネル作成から、特定Projectのパネルを表示
- またパネル下のメニューから複数の
Run Set(= Project)を追加可能
- Publish後、共有リンクの発行が可能
- 特定のユーザーに閲覧・編集権限を与えることができます
プロジェクト横断でログを横比較するのはダッシュボード上からは無理なので、最終ベンチ等を比較する上では便利です。
また共有リンクの発行についても、例えばクライアントへの連携が必要となる(かつ、クライアントが自ら学習過程を精査したい)場合に活用できます。
一般公開されているわかりやすい例としてはW&Bが管理している日本語モデルリーダーボードであるNejumi Leaderboardが有名だと思います。
我々が直面した課題 again
課題を見つめ直す
今回LLMの学習を進める上で初歩的な実験管理では十分な分析ができないことをきっかけに、W&Bを使った高度化を模索しました。具体的には
- 管理の課題
-
project/runやタグの仕組みで対応
-
- 報告時の課題
- Reportsで対応
- 分析時の課題
- 独自のロギングを追加することで対応
- 評価時の課題
- Artifactを利用することで対応
といった形で各課題をカバーしています。
そして生まれる新たな課題
さて、ここまでW&B縛りで課題解決について語ってきましたが、これで理想の実験管理ができているのでしょうか?答えはもちろん否です。
これだけW&Bについて書くと、自分がW&Bの回し者なんじゃないかと思われそうですが、もちろん違います。そしてW&Bに対する不満は色々とあります。ここではその代表的なものをいくつかだけあげます。
- ReportのUXがイケてない
- 正直Notionからくると、機能が少ないのはもちろん、バグが多く、利用していて苦痛な時があります
- PDFやLatexへのエクスポートも崩れることが多くそのままでは使えません
- Table Artifactについて帯域が狭いとエラー発生
- 特にGRPOですが、一度に複数のロールアウトをロギングすることが多く環境とクラウドのネットワークが不安定な場合エラーを吐き出し学習が中断されることがあります(キャッチすればOkですが)
なお後者については最近W&BがターミナルでのダッシュボードUIを提供し始めたので、そちらも試しているところです。
無論W&Bそのものに課題がある、というよりかは使いこなせてない自分にも課題があることは言うまでもありません。
まとめ
今回、LLM学習プロジェクトを初めて担当するにあたって、いかに実験管理をするべきか試行錯誤の軌跡を共有しました。
W&Bは恐ろしいくらいの機能を提供しており、自分もまだ旅路の途中ですが、誰かの参考になれば幸いです。

Discussion