はじめに
こんにちは、松尾研究所 データサイエンティストの力岡です。
今回は、Kaggleで開催された 「MAP - Charting Student Math Misunderstandings」 コンペに参加し、金メダルを獲得することができました。本記事では、コンペの概要と上位解法、私達の取り組みについて紹介します。
コンペ概要
コンペの目的
本コンペティションでは、ある数学の問題に対する生徒の自由記述回答をもとに、潜在的な数学的誤解を予測するモデルを構築します。たとえば、以下のような問題と生徒の回答を考えます。
質問: どの数が最も大きいですか?
選択肢: (A) 6 (B) 6.2 (C) 6.079 (D) 6.0001
生徒の回答: (D) 6.0001
回答理由: 小数点以下の桁数が最も多いので、(D)だと思います。
この場合、正しい答えは (B) ですが、生徒は 「数字の桁数が多いほど値が大きい」 という誤った理解に基づいて (D) を選択しています。このような誤解は、「Longer_is_bigger(桁数が多いほど大きい)」 という予め用意されたラベルで表されます。
数学の学習において、生徒はしばしば既存の知識を誤って適用してしまい、こうした誤解が生じます。しかし、教師がすべての生徒の回答理由を手作業で分析し、誤解の種類を特定するのには時間がかかり、大規模な教育現場では現実的ではありません。
そこで本コンペでは、自然言語処理技術を用いて、生徒の自由記述回答から誤解を自動的に検出するモデルを開発することが課題とされました。
データセット
データは、教育系プラットフォーム 「Eedi」 上で収集された診断問題(Diagnostic Questions, DQs)」に基づいています。各問題は1つの正答と3つの誤答を含む4択問題で構成されており、生徒はその回答理由を自由記述で説明します。
-
QuestionId: 質問ごとの一意な識別子 -
QuestionText: 設問文 -
MC_Answer: 生徒が選択した選択肢 -
StudentExplanation: 生徒が回答を選んだ理由を自由記述した説明文 -
Category(trainのみ): 選択肢の正誤と説明内容の関係を表す分類- 以下の6種類の
Categoryが存在 -
True_Correct: 生徒の説明は論理的に正しく、正しい答えと一致 -
True_Neither: 答えは正しいが、説明は曖昧または役に立たない -
True_Misconception: 生徒は正しい答えを得たが、間違った理由で誤解している -
False_Correct: 生徒は間違った答えを出しているが、説明は正しい -
False_Neither: 答えは正しくなく、説明も曖昧または役に立たない -
False_Misconception: 答えは正しくなく、説明には特定の識別可能な誤解が示されている
- 以下の6種類の
-
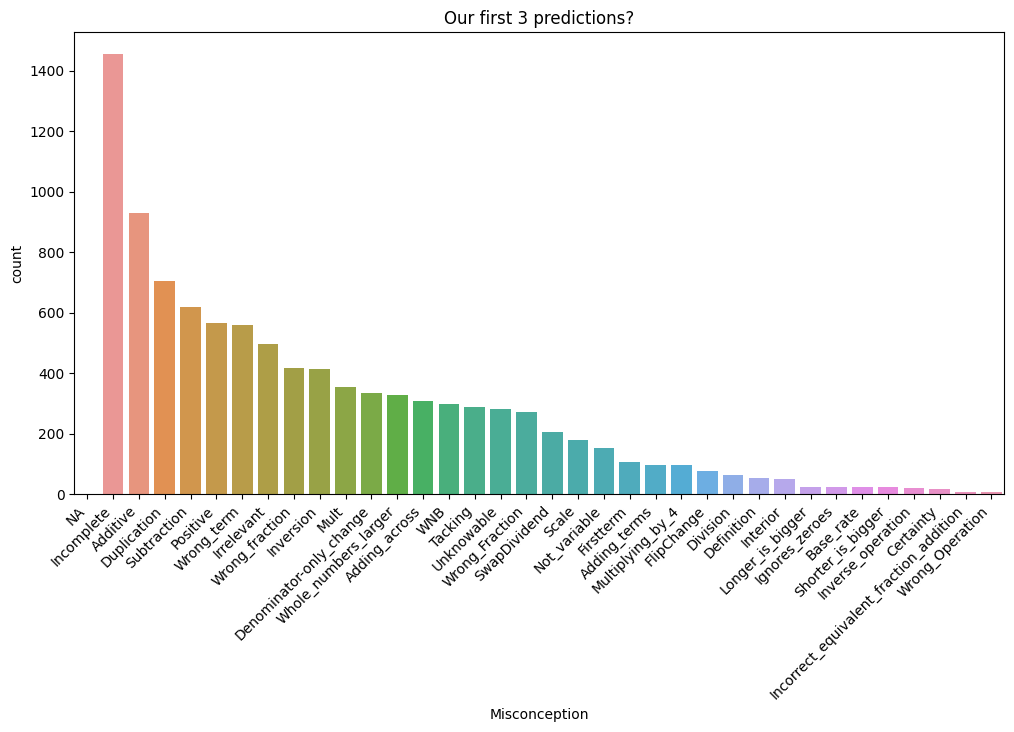
Misconception(trainのみ): 誤概念の種類を特定したラベル。誤概念がない場合はNA- 以下の35種類の
Misconceptionが存在
- 以下の35種類の
モデルは以下の3つのステップを自動化する必要があります。
- 生徒の選択が正答か誤答かを判定する。
- 記述回答に誤解が含まれているかを分類する。
- 誤解がある場合、その具体的な種類を特定する。
評価指標
評価は Mean Average Precision @3 (MAP@3) で行われます。各サンプルに対してモデルは最大3つのラベルを予測し、その中に正解ラベルが含まれるかどうかでスコアが算出されます。1つの観測(生徒回答)につき正解ラベルは1つのみで、より上位に正解を予測するほど高スコアが得られます。
| 記号 | 意味 |
|---|---|
| 観測数(テストサンプルの総数) | |
| 各観測に対して提出された予測の数 | |
| 上位 |
|
| ランク |
具体的な計算例
| 観測 | 正解 | 予測 (上位3件) | AP@3 | 説明 |
|---|---|---|---|---|
| 1 | B | A, B, C | 0.5 | 2位で正解を当てたため 0.5 |
| 2 | A | A, B, C | 1.0 | 1位で正解を当てたため 1.0 |
| 3 | D | C, B, A | 0.0 | 正解が1~3位以内にないため 0.0 |
参考: Kaggle 評価指標ページ
コンペの特徴
-
問題文は学習・評価で共通
- 学習データに含まれる問題と同一のテキストがテストデータにも含まれていることが、 LB Probing によって確認されていました。そのため、未知の問題に対する汎化性能よりも、既知の問題をどれだけ高精度に再現できるかが焦点となっていました。
- また、この構造上、各選択肢の正誤は学習データから復元可能であるため、モデルは主に誤解ラベルの推定に専念することができます。
-
一部ラベルの不整合・ノイズ
- 誤解ラベルは人手によるアノテーションで付与されており、一部にはラベルの揺れや不整合が見られました。(例: 同一の生徒説明に対して、
CorrectとMisconceptionが併存) - そのため、これらのアノテーションノイズを考慮した前処理や学習戦略が重要でした。
- 誤解ラベルは人手によるアノテーションで付与されており、一部にはラベルの揺れや不整合が見られました。(例: 同一の生徒説明に対して、
このような背景から、本コンペは小数点第3桁以下の僅差を競う精密な勝負となり、「いかに一問一問を取りこぼさず、丁寧に予測できるか」が肝となっていました。
【PB LeaderBoard】
金メダル圏ボーダー: 0.94792
銀メダル圏ボーダー: 0.94625
銅メダル圏ボーダー: 0.94579
上位解法
上位チームの多くは Qwen 系モデルを中心としたアンサンブル構成を採用していました。
特にラベル空間の圧縮や候補ラベルの制限などの探索空間の最適化や、ラベルノイズ対策として soft/hard 損失の併用や R-Drop・EMA・AWP の導入などの工夫が目立っていました。また、推論面では量子化やvllmを駆使して、パラメータ数の大きなモデルを速く動かす工夫が施されていました。
| 順位 | 利用モデル | 前処理・後処理 | 工夫・トリック |
|---|---|---|---|
| 1st | ・Qwen3-32B ・GLM-Z1-32B |
・QuestionIdごとに候補suffixを定義 | ・suffix分類 ・SmoothQuant → LMDeploy ・レイヤー逐次推論 ・補助SFTロス |
| 2nd | ・Qwen2.5-14B/32B ・Qwen3-32B |
・65→37クラス統合 ・QuestionIdごとの候補制約 |
・合成データ作成 ・soft/hard併用のマルチロス |
| 3rd | ・Qwen2.5-14/32/72B | ・QuestionId別の候補ラベルに縮約 |
・プロンプト強化 ・R-Drop+AWP+EMAで汎化改善 ・多段階推論 |
| 4th | ・Qwen3-Reranker-8B ・Qwen3-32B |
・65→37クラス統合 ・既知の誤ラベルを修正 ・QuestionIdごとに候補4〜6へ縮約 |
・Pointwise Reranker ・蒸留でReranker強化 |
| 5th | ・Gemma2-9B ・Qwen2.5-14B ・Qwen3-8B ・DeepSeekMath-7B |
・65→37クラス統合 ・質問ごとに出現ラベルのみに制限 |
・多様性重視のアンサンブル ・データ拡張 |
ラベル空間の圧縮・拡張
-
[1st] ラベル候補そのものを入力テキストとして与え、どの候補が正しいかを選ばせる(suffix分類)
- 通常の分類:
[入力] → クラス数分のlogitを直接出力する - suffix分類: 入力の末尾に「候補ラベル文」を並べて入れ、どの候補が正しい続きかをモデルに選ばせる
- 通常の分類:
- [2nd, 4th, 5th] 学習データより問題の正誤を規則で後付けし、65→37クラス分類に縮約する
-
[5th]
QuestionIdごとに出現しうるラベル集合に絞る(未出ラベルを候補から除外する) - [3rd] 問題ごとの全ての選択肢や対象となる誤解をプロンプトに埋め込む
ラベルノイズ対策&汎化
- [1st] 重複除去(35,960件まで縮約)
-
[4th] 既知の誤ラベル(特定 QuestionId の誤アノテーション)修正
- 詳細はこちらのDiscussionで話されている
- [2nd] 合成データを作成し、LLMでラベル付け(Pseudo Labeling)
- [2nd] OOF平均や外部生成データを使い、SFTのhard損失+soft損失をマルチロスで学習
-
[3rd] R-Drop / AWP / EMA の重ね掛けでseed依存のブレを低減・汎化を改善
- Regularized Dropout: 同一入力の2回forwardを整合化
- Adversarial Weight Perturbation: 重み摂動でロバスト化
- Exponential Moving Average: 滑らかな重み更新で安定化
検証設計&アンサンブル
- [1st] ラベルノイズ由来のばらつき対策として、fold固定+3seedで検証を安定化
- [1st] foldアンサンブルではなく、seedアンサンブルを運用
- [2nd, 5th] 37/65クラス両系統のモデルを併用し、公開ノート由来モデルも取り込んで多様性を確保
- [4th] Pointwise Rerankerの導入
推論の工夫
- [1st] SmoothQuant → W8A8(LMDeploy)、場面により AWQ/GPTQ も活用
- [1st] レイヤー逐次推論(layer-wise offload)でT4×1/2でも32Bを動かす
- [3rd] bf16→fp16、padding=False、短プロンプト最適化で4倍速化
- [3rd] 14B/32Bで全件 → 低信頼だけ72B という段階的推論
私達の取り組み
最後に、チームとしてのアプローチを紹介します。
特別なトリックや工夫があったわけではなく(様々な方法を試したもののうまく機能しませんでした)、最終的には堅実にモデル検証を行い精度を積み上げる形になりました。前述の通り、非常に僅差の競争だったため、可能な限り大きなモデルを用い、多数のモデルをアンサンブルすることで差別化を図る戦略で進めました。
ここでは、主に実装面に焦点を当て、使用モデル・前処理・学習設定・推論フローをまとめます。
概要
使用モデルは以下の2種類です。
Qwen/Qwen2.5-32B-Instructdeepseek-ai/DeepSeek-R1-Distill-Qwen-32B
両モデルをそれぞれ異なるシードで 5-fold × 2モデル = 計10モデル の CausalLM として構築し、推論には vLLM を使用しました。
学習環境: Google Colab Pro (A100 80GB)
学習時間: 1 fold あたり 約220分
推論時間: kaggle T4環境にて 約460分
前処理
まず、既知のアノテーションエラーを修正し、重複していた Misconception ラベルを統一しました。統一後は、対応する QuestionID に基づいてラベルを再分配しています。
# 既知のアノテーションエラーを修正
def wrong_corrections(df: pd.DataFrame) -> pd.DataFrame:
false_to_true_ids = [12878, 12901, 13876, 14089, 14159, 14185]
df["MC_Answer"] = np.where(
df["row_id"].isin(false_to_true_ids),
df["MC_Answer"].str.replace(r"\( 6 \)", r"\( 9 \)"),
df["MC_Answer"]
)
true_to_false_ids = [14280, 14305, 14321, 14335, 14338, 14352, 14355, 14403, 14407, 14412, 14413, 14418]
df["MC_Answer"] = np.where(
df["row_id"].isin(true_to_false_ids),
df["MC_Answer"].str.replace(r"\( 9 \)", r"\( 6 \)"),
df["MC_Answer"]
)
return df
# 重複する Misconception ラベルを統一
def replace_duplicate_misc(df: pd.DataFrame) -> pd.DataFrame:
df["Misconception"] = df["Misconception"].replace({"Wrong_Fraction": "Wrong_fraction"})
return df
# 推論後は QuestionID に基づいて再分配
submission.loc[
submission.index[test_df["QuestionId"] == 31777],
"Category:Misconception"
] = submission.loc[
submission.index[test_df["QuestionId"] == 31777],
"Category:Misconception"
].str.replace("Wrong_fraction", "Wrong_Fraction")
プロンプト最適化
プロンプトは、余計な情報を排除したシンプルな形式が最も安定しました。上位解法でみられた選択肢や誤解の詳細を追加した複雑なプロンプトも試しましたが、精度が低下する傾向が見られたため採用していません。
prompt_format = """Question: {QuestionText}
Answer: {MC_Answer}
Correct: {Correct}
Student Explanation: {StudentExplanation}
Label: """
この形式により、CVスコアが改善し、学習・推論時間も短縮されました。
学習
全65クラスのラベルを special token として登録し、SFTTrainer + AutoModelForCausalLM を使用して QLoRA によるファインチューニングを実施しました。
推論時には、追加した special token の生成確率(logit)を取得して分類を行います。
# 分類ラベルをspecial_tokenに登録する
def add_completion_token(
model: AutoModelForCausalLM,
tokenizer: PreTrainedTokenizer,
completions: list[str]
) -> PreTrainedTokenizer:
special_tokens_dict = {"additional_special_tokens": completions}
tokenizer.add_special_tokens(special_tokens_dict)
print(f"Added {len(completions)} special tokens.")
model.resize_token_embeddings(len(tokenizer))
print(f"Resized model embeddings to {len(tokenizer)} tokens.")
return model, tokenizer
参考実装: LB 0.942 Train FullFT Qwen3-8B by SFTTrainer
なお、special_token を LoRA で学習する際は、以下のように lm_head および embed_tokens を学習対象に含めないと学習が進まない点に注意が必要です。
# LoRAの設定
lora_config = LoraConfig(
r=CFG.lora_r,
lora_alpha=CFG.lora_alpha,
lora_dropout=CFG.lora_dropout,
bias=CFG.lora_bias,
target_modules=CFG.target_modules,
task_type=CFG.task_type,
modules_to_save=["lm_head"],
trainable_token_indices={"embed_tokens": new_token_ids}
)
参考: Efficiently train tokens alongside LoRA
DeepSpeed の活用
学習には DeepSpeed を使用しました。これにより、学習時間の短縮やVRAM使用量の削減が可能になります。チームメンバーが過去に書いた解説記事がとても参考になるので、ぜひご覧ください。
推論
推論は vLLM + AWQ で実施しました。量子化方式を bitsandbytes から awq に変更することで、精度を維持したまま推論時間を約1/6に短縮できました。最終的には各モデルで算出した special token の logit を単純平均して最終スコアを決定しています。
推論結果(MAP@3)
| モデル / 設定 | Valid | Public LB | Private LB |
|---|---|---|---|
| Qwen2.5-32B-Instruct (fold0) | 0.950182 | 0.946 | 0.944 |
| Qwen2.5-32B-Instruct (5-fold) | — | 0.950 | 0.946 |
| DeepSeek-R1-Distill-Qwen-32B (fold0) | 0.947956 | 0.948 | 0.945 |
| DeepSeek-R1-Distill-Qwen-32B (5-fold) | — | 0.950 | 0.946 |
| 5-fold × 2 ensemble | — | 0.950 | 0.948 |
うまくいかなかったこと
- Reranker(pairwise / pointwise)による再順位付け → 効果なし
- 70B / 72B モデル:CVスコアは良好だが推論時間(約150分)が長くうまく機能しなかった
- 32B×5 + 72B×2 のサブも提出したが、32B×10 よりも PB Score は低かった
- Llama 3.3-70B、gpt-oss-20b、Mistral、Hermes、Gemma 3、Qwen 3 などを試したが
、どのモデルも Qwen 2.5 モデルを上回らなかった - Qwen-32B の logit を用いて Soft Label で再学習したが、Public LB では変化なし(Private LB +0.001)
- 5-fold の LoRA アダプタをマージすると、単一モデル使用時より性能低下
-
Misconceptionのみで学習(True/False 除外)は、標準のカテゴリ分類を上回らず
Soft Label での学習方法について
SFTTrainer を用いた Soft Label 学習ではいくつかの落とし穴があるので、メモとして残します。結論として、デフォルト設定のままでは CustomTrainer に Soft Label が渡されないため、以下の対応が必要です。
- SFTConfig の
remove_unused_columnsを False に設定 - Soft Label を渡すための CustomCollator を定義(以下例)
class SoftLabelCollator:
"soft_labelsをcustom_trainerに渡す"
def __init__(self, base_collator):
self.base_collator = base_collator
def __call__(self, examples):
has_soft_labels = "soft_labels" in examples[0]
if has_soft_labels:
soft_labels = [ex["soft_labels"] for ex in examples]
else:
soft_labels = None
# 既存のcollatorを通す
batch = self.base_collator(examples)
# soft_labels をそのまま追加
if has_soft_labels:
batch["soft_labels"] = soft_labels
return batch
SFTTrainer のデフォルト設定では不要なカラムが自動削除されるようになっているため、Soft Label などの通常学習以外のカラムを扱う場合は明示的にデータを渡し、独自の損失計算を実装する必要があります。詳細はライブラリの実装を確認するのが最も確実です。
参考: GitHub TRLのリポジトリ
以下に私が Soft Label の検証で利用したコードもあるので、参考にしてください。
おわりに
Kaggleの MAP - Charting Student Math Misunderstandings というコンペについて紹介しました。上位チームが行っていた推論の工夫や合成データの作成などはあまり試せていなかったので、次回のコンペに活かしていきたいと思います。
あと銀メダル以上を1枚獲得すれば、晴れてKaggle Masterに昇格できますので、引き続き頑張っていきます。

Discussion