GPU1枚でもDeepSpeedを使ってLLM学習を高速化
はじめに
一般的に DeepSpeed は、複数GPU環境での学習を効率化するライブラリとして知られており
Transformers のドキュメントでは「単一GPU環境では遅くなるだけ」と記載されています
If your model fits onto a single GPU and you have enough space to fit a small batch size, you don’t need to use DeepSpeed as it’ll only slow things down.
モデルが単一の GPU に収まり、小さなバッチ サイズを収めるのに十分なスペースがある場合は、DeepSpeed を使用する必要はありません。DeepSpeed を使用すると速度が低下するだけです。
https://huggingface.co/docs/transformers/perf_train_gpu_one#deepspeed-zero より
ところが、実際に検証してみると
単一GPU環境でも DeepSpeed を導入するだけで 1.4~2.0倍 高速化することが確認できました
(※実行環境、モデル、データセットにより変化する可能性があります)
しかも、Trainer を使用している場合、実質的に6行の追加で済むため既存のコードにほぼ影響を与えずに高速化が可能です
今回は、LLMの学習時間を短縮する手法として DeepSpeed の活用方法を解説します
クイックスタート: DeepSpeed で学習時間が半分程度になる例
まずは実際どれだけの効果があるのかを検証してみます
- 検証環境
- GPU: Google Colab L4
- model: Qwen2.5-7B-Instruct
- dataset: stanfordnlp/imdb (1000件使用)
SFTTrainer の学習を以下3条件で比較します
- exp001: DeepSpeed 未使用 / ライブラリ(mpi4py, deepspeed) インストールしない
- exp002: DeepSpeed 未使用 / ライブラリ(mpi4py, deepspeed) インストールする
- exp003: DeepSpeed 使用(ZeRO-1) / ライブラリ(mpi4py, deepspeed) インストールする
ライブラリのインストール
!pip install -q huggingface_hub==0.29.1
!pip install -q transformers==4.49.0
!pip install -q bitsandbytes==0.45.3
!pip install -q peft==0.14.0
!pip install -q accelerate==1.4.0
!pip install -q datasets==3.3.2
!pip install -q trl==0.15.2
!pip install -q mpi4py==4.0.3 # exp001ではコメントアウト
!pip install -q deepspeed==0.16.4 # exp001ではコメントアウト
!pip install -q flash-attn==2.7.4.post1 --no-build-isolation
コード exp001 / exp002
import os
import wandb
import torch
from datasets import load_dataset
from huggingface_hub import snapshot_download
from peft import LoraConfig, get_peft_model, TaskType, prepare_model_for_kbit_training
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
from trl import SFTConfig, SFTTrainer
# wandb setting
wandb.login()
os.environ["WANDB_PROJECT"] = "zenn-1gpu-deepspeed"
# model download
model_name = "Qwen/Qwen2.5-7B-Instruct"
snapshot_download(repo_id=model_name, local_dir_use_symlinks=False, revision="main")
# dataset
dataset = load_dataset("stanfordnlp/imdb", split="train")
dataset = dataset.select(range(1000))
run_name = "exp001_baseline" # "exp002_only_pip_install_deepspeed"
# 学習設定
training_args = SFTConfig(
max_seq_length=512,
run_name=run_name,
output_dir="/tmp",
num_train_epochs=1,
per_device_train_batch_size=1,
gradient_accumulation_steps=8,
optim='adamw_torch',
logging_steps=1,
learning_rate=1e-4,
weight_decay=0.01,
lr_scheduler_type="cosine",
seed=1024,
bf16=True,
)
# LoRA設定
lora_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
target_modules="all-linear",
task_type=TaskType.CAUSAL_LM,
)
# 量子化設定 4bit
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
# model load
model = AutoModelForCausalLM.from_pretrained(model_name,
quantization_config=bnb_config,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2")
model = prepare_model_for_kbit_training(model, use_gradient_checkpointing=True)
model = get_peft_model(model, lora_config)
trainer = SFTTrainer(
model,
train_dataset=dataset,
args=training_args,
)
# 学習開始
trainer.train()
wandb.finish()
コード exp003
import os
import wandb
import torch
from datasets import load_dataset
from huggingface_hub import snapshot_download
from peft import LoraConfig, get_peft_model, TaskType, prepare_model_for_kbit_training
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
from trl import SFTConfig, SFTTrainer
# DeepSpeed 分散学習用の環境変数設定 (単一GPU用)
# https://huggingface.co/docs/transformers/ja/main_classes/deepspeed#deployment-in-notebooks
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = "9994" # modify if RuntimeError: Address already in use
os.environ["RANK"] = "0"
os.environ["LOCAL_RANK"] = "0"
os.environ["WORLD_SIZE"] = "1"
# wandb setting
wandb.login()
os.environ["WANDB_PROJECT"] = "zenn-1gpu-deepspeed"
# model download
model_name = "Qwen/Qwen2.5-7B-Instruct"
snapshot_download(repo_id=model_name, local_dir_use_symlinks=False, revision="main")
# dataset
dataset = load_dataset("stanfordnlp/imdb", split="train")
dataset = dataset.select(range(1000))
run_name = "exp003_ZeRO-1"
# 学習設定
training_args = SFTConfig(
max_seq_length=512,
run_name=run_name,
output_dir="/tmp",
num_train_epochs=1,
per_device_train_batch_size=1,
gradient_accumulation_steps=8,
optim='adamw_torch',
logging_steps=1,
learning_rate=1e-4,
weight_decay=0.01,
lr_scheduler_type="cosine",
seed=1024,
bf16=True,
deepspeed="ds_config_zero1.json",
)
# LoRA設定
lora_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
target_modules="all-linear",
task_type=TaskType.CAUSAL_LM,
)
# 量子化設定 4bit
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
# model load
model = AutoModelForCausalLM.from_pretrained(model_name,
quantization_config=bnb_config,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2")
model = prepare_model_for_kbit_training(model, use_gradient_checkpointing=True)
model = get_peft_model(model, lora_config)
trainer = SFTTrainer(
model,
train_dataset=dataset,
args=training_args,
)
# 学習開始
trainer.train()
wandb.finish()
-
コード差分
- DeepSpeed 分散学習用の環境変数設定を追加
os.environ["MASTER_ADDR"] = "localhost" os.environ["MASTER_PORT"] = "9994" os.environ["RANK"] = "0" os.environ["LOCAL_RANK"] = "0" os.environ["WORLD_SIZE"] = "1" - ds_config_zero1.jsonを作成し、SFTConfigを変更ds_config_zero1.json
{ "fp16": { "enabled": "auto", "loss_scale": 0, "loss_scale_window": 1000, "initial_scale_power": 16, "hysteresis": 2, "min_loss_scale": 1 }, "bf16": { "enabled": "auto" }, "zero_optimization": { "stage": 1, "offload_optimizer": { "device": "none", "pin_memory": true } }, "gradient_accumulation_steps": "auto", "gradient_clipping": "auto", "steps_per_print": 2000, "train_batch_size": "auto", "train_micro_batch_size_per_gpu": "auto", "wall_clock_breakdown": false }training_args = SFTConfig( ... deepspeed="ds_config_zero1.json", )
- DeepSpeed 分散学習用の環境変数設定を追加
-
結果
学習時間 (秒) 最大VRAM (GB) 結果 exp001 1384 11.4 Colab exp002 1389 11.4 Colab exp003 692 9.4 Colab

DeepSpeed を使用するだけで
同様の train/loss での学習を半分程度の時間かつVRAMも少なく実行できました
何がこの速度差を生んでいるのか
DeepSpeed の forward / backward が高速なことだと考えています
上記比較では以下のようになっていました
| forward | backward | |
|---|---|---|
| exp001 | PeftModelForCausalLM | loss.backward |
| exp003 | DeepSpeedEngine | deepspeed_engine_wrapped.backward |
forward
3759行目(exp001 / exp003 共通)
backward
2321行目(exp003) / 2329行目(exp001)
実際の forward / backward の速度を計測してみます
-
計測方法
- transformers.trainer.Trainer.training_step 1000 回実行時、以下に必要な時間を計測
- self.compute_loss における forward
- self.accelerator.backward における backward
- trainer.py に処理時間計測のためのデバックコードを入れて計測
- transformers.trainer.Trainer.training_step 1000 回実行時、以下に必要な時間を計測
-
結果
forward (秒) backward (秒) 合計 (秒) (参考) 総学習時間 (秒) exp001 533.3 773.5 1306.8 1385 exp003 204.1 432.9 637.0 678
forward 2.6倍 の高速化
backward 1.8倍 の高速化
となっていました
DeepSpeed による forward / backward の最適化については調査中ですが
通常のPytorchに比べて相当な最適化が行われていると思われます
次に DeepSpeed について概要を紹介します
DeepSpeedの概要
この記事では DeepSpeed を使うために ZeRO についてのみ記載します
詳細についてはこちらの記事を参照してください
ZeRO (Zero Redundancy Optimizer) とは
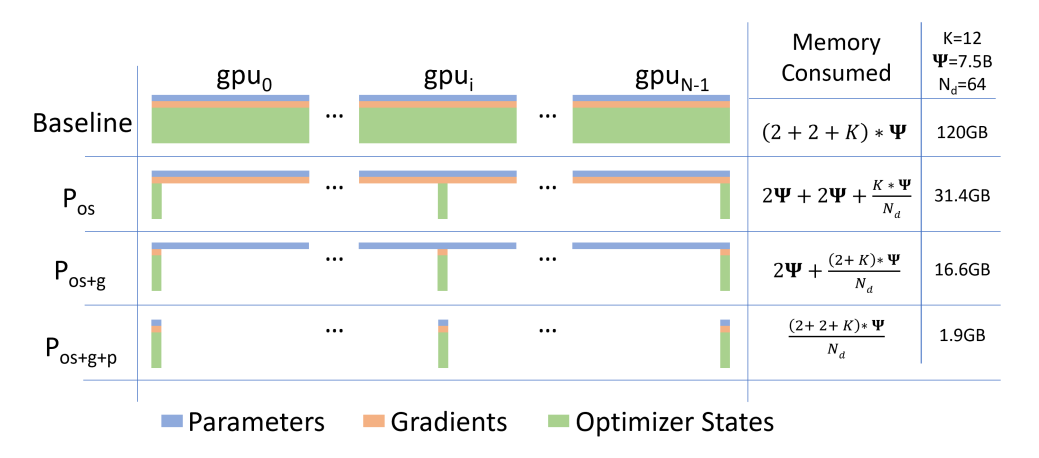
(ZeRO: Memory Optimizations Toward Training Trillion Parameter Models より)
従来の方法では Parameters, Gradients, Optimizer States を常に GPU 上に保持するのに対し
学習に必要なタイミングでのみ分割配置したデータを GPU にロードする手法です
ZeROの種類 (0,1,2,3 / Offload / Infinity)
何を分割配置するかによって呼び方が変わります
- ZeRO-0: 何も分割しない
- ZeRO-1: Optimizer States
- ZeRO-2: Gradients + Optimizer States
- ZeRO-3: Parameters + Gradients + Optimizer States
また、分割配置先を GPU からCPUメモリまたはNVMeストレージにすることができます
- ZeRO-Offload: CPUメモリに配置する手法 (ZeRO-1,2,3 で利用可能)
- ZeRO-Infinity: CPUメモリに加えてNVMeストレージに配置する手法 (ZeRO-3 のみ利用可能)
実際に色々なZeROで検証
ZeRO の設定を変えることで
- 学習時間
- 最大VRAM
がどのように変化するのかを検証してみます
Gradient Checkpointing の有無も学習時間に影響を与えるため
ZeRO-1,2 との組み合わせも確認します
- 検証環境
- GPU: Google Colab L4
- model: Qwen2.5-14B-Instruct
- DeepSpeed 無しでは Gradient Checkpointing=False でOOMが発生
- dataset: stanfordnlp/imdb (1000件使用)
- (exp006) ZeRO-0
"zero_optimization": { "stage": 0 },model = prepare_model_for_kbit_training(model, use_gradient_checkpointing=False) - (exp007) ZeRO-1 + Gradient Checkpointing=False
"zero_optimization": { "stage": 1, "offload_optimizer": { "device": "none", "pin_memory": true } }, - (exp008) ZeRO-1 optimizer offload + Gradient Checkpointing=False
"zero_optimization": { "stage": 1, "offload_optimizer": { "device": "cpu", "pin_memory": true } }, - (exp009) ZeRO-1 + Gradient Checkpointing=True
"zero_optimization": { "stage": 1, "offload_optimizer": { "device": "none", "pin_memory": true } },model = prepare_model_for_kbit_training(model, use_gradient_checkpointing=True) - (exp010) ZeRO-1 optimizer offload + Gradient Checkpointing=True
"zero_optimization": { "stage": 1, "offload_optimizer": { "device": "cpu", "pin_memory": true } }, - (exp011) ZeRO-2 + Gradient Checkpointing=False
"zero_optimization": { "stage": 2, "offload_optimizer": { "device": "none", "pin_memory": true }, "allgather_partitions": true, "allgather_bucket_size": 2e8, "overlap_comm": true, "reduce_scatter": true, "reduce_bucket_size": 2e8, "contiguous_gradients": true },model = prepare_model_for_kbit_training(model, use_gradient_checkpointing=False) - (exp012) ZeRO-2 optimizer offload + Gradient Checkpointing=False
"zero_optimization": { "stage": 2, "offload_optimizer": { "device": "cpu", "pin_memory": true }, "allgather_partitions": true, "allgather_bucket_size": 2e8, "overlap_comm": true, "reduce_scatter": true, "reduce_bucket_size": 2e8, "contiguous_gradients": true }, - (exp013) ZeRO-2 + Gradient Checkpointing=True
"zero_optimization": { "stage": 2, "offload_optimizer": { "device": "none", "pin_memory": true }, "allgather_partitions": true, "allgather_bucket_size": 2e8, "overlap_comm": true, "reduce_scatter": true, "reduce_bucket_size": 2e8, "contiguous_gradients": true },model = prepare_model_for_kbit_training(model, use_gradient_checkpointing=True) - (exp014) ZeRO-2 optimizer offload + Gradient Checkpointing=True
"zero_optimization": { "stage": 2, "offload_optimizer": { "device": "cpu", "pin_memory": true }, "allgather_partitions": true, "allgather_bucket_size": 2e8, "overlap_comm": true, "reduce_scatter": true, "reduce_bucket_size": 2e8, "contiguous_gradients": true }, - (exp015) ZeRO-3 + Gradient Checkpointing=True
"zero_optimization": { "stage": 3, "offload_optimizer": { "device": "none", "pin_memory": true }, "offload_param": { "device": "none", "pin_memory": true }, "overlap_comm": true, "contiguous_gradients": true, "sub_group_size": 1e9, "reduce_bucket_size": "auto", "stage3_prefetch_bucket_size": "auto", "stage3_param_persistence_threshold": "auto", "stage3_max_live_parameters": 1e9, "stage3_max_reuse_distance": 1e9, "stage3_gather_16bit_weights_on_model_save": true }, - (exp016) ZeRO-3 parameters offload + Gradient Checkpointing=True
"zero_optimization": { "stage": 3, "offload_optimizer": { "device": "none", "pin_memory": true }, "offload_param": { "device": "cpu", "pin_memory": true }, "overlap_comm": true, "contiguous_gradients": true, "sub_group_size": 1e9, "reduce_bucket_size": "auto", "stage3_prefetch_bucket_size": "auto", "stage3_param_persistence_threshold": "auto", "stage3_max_live_parameters": 1e9, "stage3_max_reuse_distance": 1e9, "stage3_gather_16bit_weights_on_model_save": true }, - (exp017) ZeRO-3 optimizer & parameters offload + Gradient Checkpointing=True
"zero_optimization": { "stage": 3, "offload_optimizer": { "device": "cpu", "pin_memory": true }, "offload_param": { "device": "cpu", "pin_memory": true }, "overlap_comm": true, "contiguous_gradients": true, "sub_group_size": 1e9, "reduce_bucket_size": "auto", "stage3_prefetch_bucket_size": "auto", "stage3_param_persistence_threshold": "auto", "stage3_max_live_parameters": 1e9, "stage3_max_reuse_distance": 1e9, "stage3_gather_16bit_weights_on_model_save": true },
実行時間、最大VRAM使用率の比較は以下です
- 結果
| ZeRO | Gradient Checkpointing | offload optimizer | offload param | 学習時間 (秒) | 最大VRAM (GB) | 結果 | |
|---|---|---|---|---|---|---|---|
| exp004 (参考) | --- | False | --- | --- | OOM発生 | --- | Colab |
| exp005 (参考) | --- | True | --- | --- | 2643 | 17.6 | Colab |
| exp006 | 0 | False | --- | --- | 915 | 20.1 | Colab |
| exp007 | 1 | False | --- | --- | 932 | 20.8 | Colab |
| exp008 | 1 | False | cpu | --- | 932 | 20.0 | Colab |
| exp009 | 1 | True | --- | --- | 1368 | 14.0 | Colab |
| exp010 | 1 | True | cpu | --- | 1374 | 13.4 | Colab |
| exp011 | 2 | False | --- | --- | 953 | 20.8 | Colab |
| exp012 | 2 | False | cpu | --- | 957 | 19.7 | Colab |
| exp013 | 2 | True | --- | --- | 1361 | 14.4 | Colab |
| exp014 | 2 | True | cpu | --- | 1371 | 12.7 | Colab |
| exp015 | 3 | True | --- | --- | 2798 | 16.4 | Colab |
| exp016 | 3 | True | --- | cpu | 3610 | 13.6 | Colab |
| exp017 | 3 | True | cpu | cpu | 3637 | 13.6 | Colab |
- 考察
- (exp012 / exp014) ZeRO-2 optimizer offload の train/loss が大きく異なっています
- Wandb train/grad_norm が他と異なることが確認できます
- 既知の不具合 による勾配計算の不具合が影響していそうです
- 現状は ZeRO-2 optimizer offload は回避したほうが無難かもしれません
- (exp015) ZeRO-3 w/o offload のGPU使用率は学習終了時のみ 16.4GB / 学習中は 13.5GB
- Wandb exp015 GPU Memory Allocated (Bytes)
- 学習終了時にGPUメモリ使用率が上がっている原因は調査中です
- (追記) 学習完了時にstate_dictをまとめる処理で受け取り用のTensor分増えている
- _allgather_params
- parameterをoffloadしているときはVRAMを再利用しているが、していないときは新規に領域確保しているため
- (追記) 学習完了時にstate_dictをまとめる処理で受け取り用のTensor分増えている
- ZeRO-2 / ZeRO-3 による省メモリ化ができませんでした
- 今回の設定/環境ではメモリ削減に失敗している可能性がありそうです
- (exp012 / exp014) ZeRO-2 optimizer offload の train/loss が大きく異なっています
今回の検証では DeepSpeed を使わない場合と比較して
- 学習時間は最大65%削減 (exp005: 2643秒 -> exp006: 915秒)
- 最大VRAMは最大24%削減 (exp005: 17.6GB -> exp010: 13.4GB)
- ZeRO-2 optimizer offload は除外
という結果になりました
実際に調整する場合には
- ZeROを0->3へと調整 (逆でも良いと思います)
- OOMが発生しなくなった段階で以下を調整し最適化
- Gradient Checkpointing
- offload対象
- バッチサイズ
という順番で進めてみてください
まとめ
本来遅くなると言われていたGPU1枚で DeepSpeed を使って学習が早くなる例をご紹介しました
もちろん DeepSpeed の本来の強みは、複数GPU・複数ノードでの学習の最適化にあります
単一GPU環境での導入をきっかけに、必要に応じてマルチGPU・マルチノードへスケールアップしていくことも試してみていただければと思います
参考資料
ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
ZeRO-Offload: Democratizing Billion-Scale Model Training
補足
RunpodでのGPUアーキテクチャ / 検証環境 ごとの比較
-
検証したGPU
- A100 SXM 80GB (Ampere)
- L4 24GB (Ada)
- L40S 48GB (Ada)
- H100 NVL 94GB (Hopper)
-
検証内容
- クイックスタートにおける exp001, exp003
- GPUと環境を変えて検証
- クイックスタートにおける exp001, exp003
-
検証環境
- runpod/pytorch:2.4.0-py3.11-cuda12.4.1-devel-ubuntu22.04 (以下 runpod-2.4)
- us-docker.pkg.dev/colab-images/public/runtime (以下 colab)
-
結果
| GPU | DeepSpeed | イメージ | 学習時間(秒) | baseline速度比 | |
|---|---|---|---|---|---|
| baseline | A100 | --- | runpod-2.4 | 428 | 1.00 |
| A100 | --- | colab | 422 | 1.01 | |
| A100 | ZeRO-1 | runpod-2.4 | 330 | 1.30 | |
| A100 | ZeRO-1 | colab | 246 | 1.74 | |
| baseline | L4 | --- | runpod-2.4 | 1353 | 1.00 |
| L4 | --- | colab | 1364 | 0.99 | |
| L4 | ZeRO-1 | runpod-2.4 | 914 | 1.48 | |
| L4 | ZeRO-1 | colab | 649 | 2.08 | |
| baseline | L40S | --- | runpod-2.4 | 492 | 1.00 |
| L40S | --- | colab | 492 | 1.00 | |
| L40S | ZeRO-1 | runpod-2.4 | 336 | 1.46 | |
| L40S | ZeRO-1 | colab | 232 | 2.12 | |
| baseline | H100 | --- | runpod-2.4 | 291 | 1.00 |
| H100 | --- | colab | 290 | 1.00 | |
| H100 | ZeRO-1 | runpod-2.4 | 210 | 1.39 | |
| H100 | ZeRO-1 | colab | 201 | 1.45 |
- 考察
- Ada 世代の高速化が顕著 (2倍程度)
- 特にL40Sが同一条件では通常のH100より高速化できることに驚いた
- 実際はVRAMの差によりH100では Gradient Checkpointing を無効 / バッチサイズを大きくすることで高速化できる可能性があるのでこの差にはならない
- ただ、時間当たりのコストが約3倍($0.86 vs $2.79)の差があるため、費用対効果的には優秀
- 特にL40Sが同一条件では通常のH100より高速化できることに驚いた
- runpod-2.4 では高速化の恩恵を受け切れていない
- ライブラリのバージョンが違うことが原因と思われるが何かまでは不明
- A100 / H100 でも高速化の恩恵を受けられるがそこまで大きくない
- 今回高速化したところ以外がボトルネックになっているのかも
- Ada 世代の高速化が顕著 (2倍程度)
Discussion