Groq API + LangChain & LangGraph + TavilyでCRAGを実装する
概要
LangChain公式のexampleを参考にしてCRAGを実装します。
環境
- langchain 0.2.2
事前準備
GroqのAPIキーを取得する
こちらの記事を参照ください。
TavilyのAPIキーを取得する
TavilyはAIエージェント向けに開発された検索エンジンで、無料で1000APIコール/月までAPI呼び出しが可能です。
今回はCRAGの中で検索APIを使用し、関連ドキュメントを取得するフローがあり、その部分でTavilyを使用します。
APIキーの取得は非常に簡単ですので、説明は省略致します。ログイン後、すぐにAPIキーが生成されたはずです。
APIキーを環境変数に設定する
ターミナル上でAPIキーを環境変数に設定します。これにより、プログラム上でAPIキーを指定する必要がなくなります。
Unix/MacOSの場合
export GROQ_API_KEY="your-api-key-here"
export TAVILY_API_KEY="your-api-key-here"
WindowOSの場合
setx GROQ_API_KEY "your-api-key-here"
setx TAVILY_API_KEY "your-api-key-here"
CRAGとは?
こちらの記事で紹介しています。
CRAGのポイントは、
- 取得したドキュメントの内容がクエリに対して正しいか(関連性があるか)を評価する
- ドキュメントの内容が正しくない or 曖昧である場合は元のクエリを書き換えて、web検索をすることでより関連性の高い知識が得られるようにする
です。
処理フロー
今回実装する処理フローはこのようになっています。

- Questionを入力する
- ⚪Retrieve: Questionに関連するドキュメントをRetrieveする(通常のRAG)
- 🟣Grade: 取得したドキュメントを評価する
- 🔷Grade: どのドキュメントもirrelevant(関連性がない)か?
- Yes->🟣Queryを書き直し⚪Web検索を行う
- No->次の処理に進む
- 🟣Generation
- 今回は最低でも1つのドキュメントが関連していると判定された場合、生成処理に進む
- Answerを出力する
前項で「CRAGでは取得したドキュメントの内容がクエリに対して正しいかを評価する」と記載しましたが、これがフロー上「Any doc irrelevant」の分岐🔷Gradeで示されているものです。
補足:原論文との相違点
原論文ではドキュメントの評価に「Retrieval Evaluator」という評価用のLLMを使用しています。
しかし、LangChain公式のexampleではOpenAI APIを通して「ドキュメントの関連度を評価してください」というプロンプトを投げ、関連しているかをyes or noで回答してもらうというより簡単な方法をとっています。
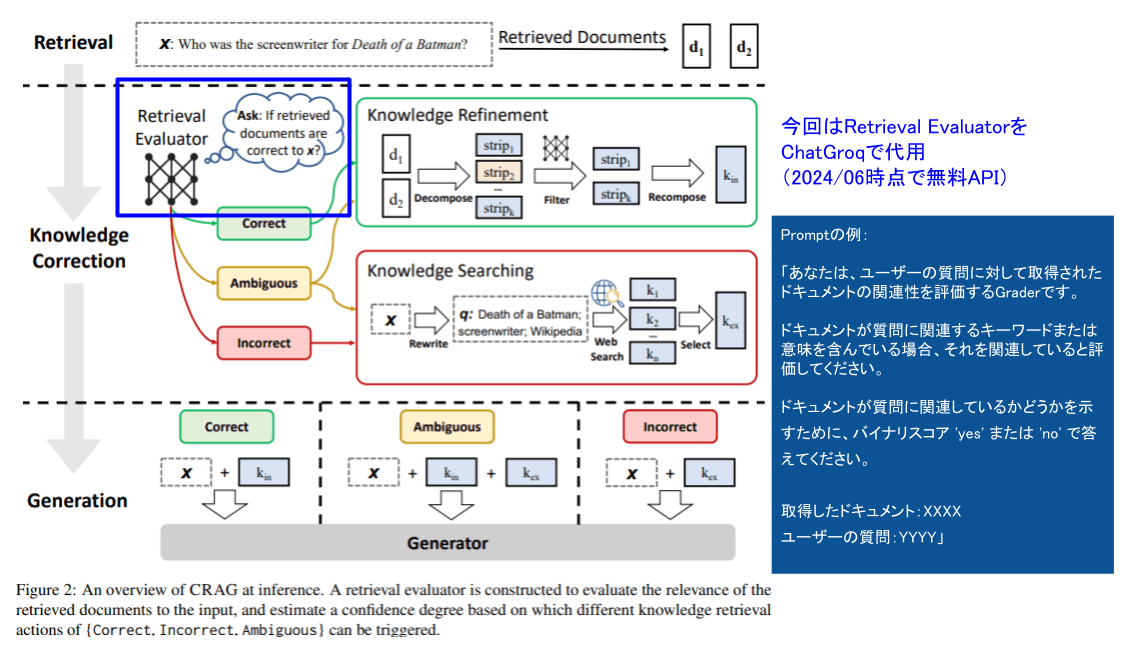
実装
今回はOpenAIのAPIを使用しないで実装したいので、元のコードを一部修正しています。
修正内容は以下です。
- Vector DB作成時のEmbeddingに
OpenAIEmbeddings()を使わず、HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")を使う - OpenAI APIを使わず、Groq APIを使うようにする
- それ以外は基本的にサンプルコードを流用していますが、自身の理解も含めてコメントは書き換えています。
- プロンプトについても動作の理解を深めるために敢えて日本語に直しています。(しかしGroqはやや日本語入力に弱い印象です。英語のままの方が精度的には安心そうです)
以降の流れとしては大きく分けて、3つあります。
- APIキーの取得
- 個々の処理を実装
- 処理フローで定義した個々の処理をパーツとして準備(3でnodeと呼ばれているもの)
- Graphの構築
- 2.で実装したパーツを繋げて組み合わせる
環境変数から今回必要なAPIキーの取得
import os
groq_api_key = os.environ["GROQ_API_KEY"]
tavily_api_key = os.environ["TAVILY_API_KEY"]
個々の処理を実装
webページからVector DBの作成
### Vector DB
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain.embeddings import HuggingFaceEmbeddings
urls = [
"https://lilianweng.github.io/posts/2023-06-23-agent/",
"https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/",
"https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/",
]
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]
# テキストの分割
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=250, chunk_overlap=0
)
doc_splits = text_splitter.split_documents(docs_list)
# Embeddingsの作成
# NOTE: サンプルではOpenAIEmbeddingsを使用しているが、今回はOpenAIのAPIを使用しない
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
# ベクトルデータベースの作成
vectorstore = Chroma.from_documents(
documents=doc_splits,
collection_name="rag-chroma",
embedding=embeddings,
)
retriever = vectorstore.as_retriever()
Grade chainの作成
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_groq import ChatGroq
# ドキュメントの関連度を評価するGraderの出力を定義
class GradeDocuments(BaseModel):
"""Binary score for relevance check on retrieved documents."""
binary_score: str = Field(
description="Documents are relevant to the question, 'yes' or 'no'"
)
llm = ChatGroq(groq_api_key=groq_api_key, model_name="llama3-70b-8192")
structured_llm_grader = llm.with_structured_output(GradeDocuments)
# Graderの入力プロンプト
system = """あなたは、ユーザーの質問に対して取得されたドキュメントの関連性を評価するGraderです。\n
ドキュメントが質問に関連するキーワードまたは意味を含んでいる場合、それを関連していると評価してください。\n
ドキュメントが質問に関連しているかどうかを示すために、バイナリスコア 'yes' または 'no' で答えてください。"""
grade_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
(
"human",
"取得したドキュメント: \n\n {document} \n\n ユーザーの質問: {question}",
),
]
)
retrieval_grader = grade_prompt | structured_llm_grader
# 動作確認
question = "what is adversarial attacks?"
docs = retriever.get_relevant_documents(question)
doc_txt = docs[1].page_content
print(f"page contents: {doc_txt}")
print(retrieval_grader.invoke({"question": question, "document": doc_txt}))
Generate chainの作成
from langchain import hub
from langchain_core.output_parsers import StrOutputParser
# Promptの取得
prompt = hub.pull("rlm/rag-prompt")
# Chain
rag_chain = prompt | llm | StrOutputParser()
# Run
generation = rag_chain.invoke({"context": docs, "question": question})
print(generation)
Question Re-writerの作成
最初のRetrieve結果が入力と関係するものでなかった場合は、web検索を行うために適したプロンプトを作成し直します。
# Prompt
system = """あなたは、入力された質問をウェブ検索に最適化されたより良いバージョンに変換するQuestion Rewriterです。\n
入力を見て、根底にある意味/意図を推論しようとしてください"""
re_write_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
(
"human",
"これが最初の質問です: \n\n {question} \n 改善された質問を作成したら、改善された質問だけを最初の質問と同じ言語で簡潔に返してください。",
),
]
)
question_rewriter = re_write_prompt | llm | StrOutputParser()
# 動作確認
question_rewriter.invoke({"question": "美味しいコーヒーを淹れる方法"})
動作確認の結果はこのように出力されました。元の入力が書き換えられていることが分かります。
'コーヒーの淹れ方を最適化するための基本的なテクニック'
web検索モジュールの作成
### Search
from langchain_community.tools.tavily_search import TavilySearchResults
web_search_tool = TavilySearchResults(k=3)
# 動作確認
docs = web_search_tool.invoke({"query": "LLMに対する攻撃にはどんなものがありますか?"})
web_results = "\n".join([d["content"] for d in docs])
web_results
Graphの構築
Graphで引き回す状態を定義
from typing import List
from typing_extensions import TypedDict
class GraphState(TypedDict):
"""
グラフに渡す情報を格納するクラス
Attributes:
question: question
generation: LLM generation
web_search: Web検索を行うかどうか。Yes or No
documents: list of documents
"""
question: str
generation: str
web_search: str
documents: List[str]
nodeとして定義する処理を関数で実装
from langchain.schema import Document
def retrieve(state):
"""
Retrieve documents
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, documents, that contains retrieved documents
"""
print("---RETRIEVE---")
question = state["question"]
# Retrieval
documents = retriever.get_relevant_documents(question)
return {"documents": documents, "question": question}
def generate(state):
"""
Generate answer
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, generation, that contains LLM generation
"""
print("---GENERATE---")
question = state["question"]
documents = state["documents"]
# RAG generation
generation = rag_chain.invoke({"context": documents, "question": question})
return {"documents": documents, "question": question, "generation": generation}
def grade_documents(state):
"""
Determines whether the retrieved documents are relevant to the question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with only filtered relevant documents
"""
print("---CHECK DOCUMENT RELEVANCE TO QUESTION---")
question = state["question"]
documents = state["documents"]
# Score each doc
filtered_docs = []
web_search = "No"
for d in documents:
# Retrieveで取得したドキュメントがinputに関連するかをYes or Noで判定
score = retrieval_grader.invoke(
{"question": question, "document": d.page_content}
)
# 結果を取得
grade = score.binary_score
if grade == "yes":
print("---GRADE: DOCUMENT RELEVANT---")
filtered_docs.append(d)
else:
print("---GRADE: DOCUMENT NOT RELEVANT---")
web_search = "Yes"
continue
return {"documents": filtered_docs, "question": question, "web_search": web_search}
def transform_query(state):
"""
Transform the query to produce a better question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates question key with a re-phrased question
"""
print("---TRANSFORM QUERY---")
question = state["question"]
documents = state["documents"]
# Re-write question
better_question = question_rewriter.invoke({"question": question})
print(f"[DBG] better_question: {better_question}")
return {"documents": documents, "question": better_question}
def web_search(state):
"""
Web search based on the re-phrased question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with appended web results
"""
print("---WEB SEARCH---")
question = state["question"]
documents = state["documents"]
# Web search
docs = web_search_tool.invoke({"query": question})
web_results = "\n".join([d["content"] for d in docs])
web_results = Document(page_content=web_results)
documents.append(web_results)
return {"documents": documents, "question": question}
### Edges
def decide_to_generate(state):
"""
Determines whether to generate an answer, or re-generate a question.
Args:
state (dict): The current graph state
Returns:
str: Binary decision for next node to call
"""
print("---ASSESS GRADED DOCUMENTS---")
state["question"]
# grade_documentsで判定したweb_searchの値を取得
web_search = state["web_search"]
state["documents"]
if web_search == "Yes":
# All documents have been filtered check_relevance
# We will re-generate a new query
print(
"---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY---"
)
return "transform_query"
else:
# We have relevant documents, so generate answer
print("---DECISION: GENERATE---")
return "generate"
Node, Graphを定義
from langgraph.graph import END, StateGraph
workflow = StateGraph(GraphState)
# Define the nodes
workflow.add_node("retrieve", retrieve) # retrieve
workflow.add_node("grade_documents", grade_documents) # grade documents
workflow.add_node("generate", generate) # generatae
workflow.add_node("transform_query", transform_query) # transform_query
workflow.add_node("web_search_node", web_search) # web search
# Build graph
workflow.set_entry_point("retrieve")
# retrieve -> grade
workflow.add_edge("retrieve", "grade_documents")
# generationに進むか、Question re-writeするか分岐するためのエッジ
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
# node遷移のマッピング
# e.g. decide_to_generateの返り値が"generate"の場合はgenerateに遷移
{
"transform_query": "transform_query",
"generate": "generate",
},
)
# Re-write query -> web search
workflow.add_edge("transform_query", "web_search_node")
workflow.add_edge("web_search_node", "generate")
workflow.add_edge("generate", END)
# Compile
app = workflow.compile()
実行結果
from pprint import pprint
# Run
inputs = {
"question": "LLMに対する攻撃にはどんなものがありますか。日本語で教えてください。"
}
for output in app.stream(inputs):
for key, value in output.items():
pprint(f"Node '{key}':")
pprint("\n---\n")
# Final generation
pprint(value["generation"])
あらかじめDBに登録したドキュメントに関連する質問をしたところ、正しく「relevant」と判定され、回答が得られていることが分かります。
---RETRIEVE---
"Node 'retrieve':"
'\n---\n'
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: GENERATE---
"Node 'grade_documents':"
'\n---\n'
---GENERATE---
"Node 'generate':"
'\n---\n'
('LLMに対する攻撃には、Universal Adversarial Trigger with Language Model Loss (UAT-LM) '
'や Unigram Trigger with Selection Criteria (UTSC) '
'などのバリエーションがあります。これらの攻撃方法は、言語モデルの出力結果を操作することを目的としています。具体的には、UTSC '
'では、トоксィクスィティスコアに基づいて攻撃メッセージをフィルタリングするなどの手法を用いています。')
今後は質問をドキュメントと全く関係のないものにしてみましょう。
from pprint import pprint
# Run
inputs = {
"question": "美味しいコーヒーの淹れ方を日本語で答えてください。"
}
for output in app.stream(inputs):
for key, value in output.items():
pprint(f"Node '{key}':")
pprint("\n---\n")
# Final generation
pprint(value["generation"])
grade_documentsで「not relevant」と判定され、Tavilyでウェブ検索が行われていることが分かります。
ただ、re-writeされた質問は「日本式コーヒーの淹れ方の基本テクニックやtipsを教えてください。」となっており、元の質問と意味が異なってしまっています。
そのため、得られた出力も当初の「日本語で答えてください」という指示が忘れられ、英語での回答となってしまいました。
---RETRIEVE---
"Node 'retrieve':"
'\n---\n'
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY---
"Node 'grade_documents':"
'\n---\n'
---TRANSFORM QUERY---
[DBG] better_question: 改善された質問:
「日本式コーヒーの淹れ方の基本テクニックやtipsを教えてください。」
"Node 'transform_query':"
'\n---\n'
---WEB SEARCH---
[DBG] [{'url': 'https://www.roomie.jp/2023/02/953809/', 'content': 'コーヒーのハンドドリップの方法をプロが解説。初心者から上級者までおすすめのおいしい淹れ方を動画付きで詳しく紹介します。コーヒーの粉や抽出時間が一目で分かる便利な早見表もあり。アイスコーヒーやカフェオレの淹れ方、おすすめの器具なども紹介しています。'}, {'url': 'https://coffeely.jp/article/1109', 'content': '自宅でコーヒーを飲む際、どのようにしてコーヒーを淹れていますか?. コーヒーの淹れ方は種類が豊富で、淹れ方を変えるだけで同じ豆で
# 一部出力を省略
"Node 'web_search_node':"
'\n---\n'
---GENERATE---
"Node 'generate':"
'\n---\n'
('Here are some basic techniques and tips for Japanese-style coffee brewing: '
'understand the optimal water temperature, coffee-to-water ratio, and pouring '
'technique. The way you brew coffee can greatly affect the taste, even with '
'the same beans.')
まとめ
今回はCRAGの概念を理解するためにLangChainで提供されているソースコードを一部改変しながら動作確認を行いました。
LangGraphに触れたのが初めての経験だったので、その勉強にもなり良い機会でした🐻❄️
ここまでお読みいただきありがとうございました。
Discussion