RAGの手法(Self-RAG, Adaptive RAG, CRAG)ざっくりまとめ🌠
概要
RAGは新たな手法が様々紹介されています。
本記事ではLangChainでサンプルコードが紹介されている下記のRAGについて紹介します。
- Self-RAG
- Adaptive RAG
- Corrective-RAG (CRAG)
RAGの有用性
RAGはLLMに対して外部の知識ベースを提供することでLLMの回答精度を良くするために効果的な手法の一つです。例えば企業で内部的にしか使用されていない質問応対マニュアルやLLMが学習していない最新の情報を回答に反映させることができます。
RAGの課題
※CRAG論文から引用
一方で、LLMが参照する知識ベースには質問に無関係なものが過剰に含まれてしまう可能性があるということがRAGの大きな課題となっています。嘘の情報をそれらしく答えてしまうというHallucinationが起きる原因にもなりえます。
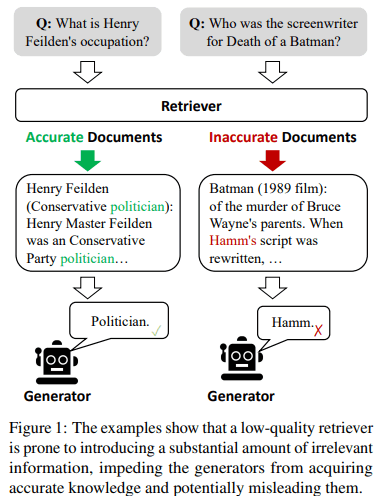
👆なお、各論文で提示されている課題には表現の違いがあると思います。あくまで参考としてお考え下さい。
Self-RAG
ざっくり言うと✨
- Self-RAGは通常のRAG+取得したドキュメントの評価(Self-reflection)を行い、最も関連性の高いドキュメントを用いて再帰的にRAGを行う手法
- Self-reflectionは自分が出力した検索結果の関連性を評価すること。Self-RAGのSelfはここから来ていると思われる
手法
以降で説明するreflection tokenを踏まえてから全体図を見るとより理解が深まると思います。
- Step1: Retrieve
- Retrieveを行うか否かを判定し、行う必要があると判断された場合は関連するドキュメントを取得する
- Retrieveを行うか否かはRetrieval tokenの
Retrieveの出力で判断する
- Step2: Generate segment in parallel
- クエリとStep1で取得したドキュメントが関連しているかどうかを判定する(Critique tokenの
ISREL) - クエリとStep1で取得したドキュメントから生成された文(Segment)に対してドキュメントの内容をどの程度含めているか評価を行う(Critique tokenの
ISSUP)
- クエリとStep1で取得したドキュメントが関連しているかどうかを判定する(Critique tokenの
- Step3: Critique outputs and select best segment
- Step2で生成したSegmentに対して評価を行う
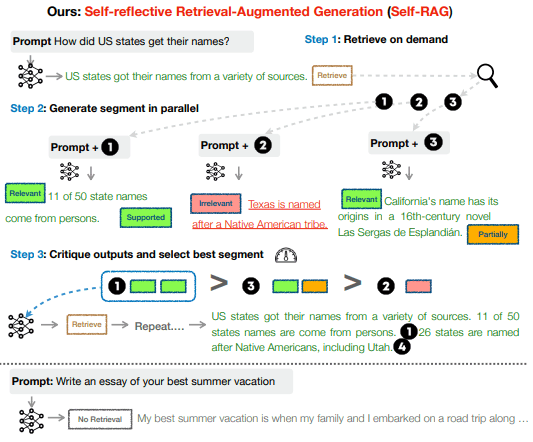
- Step2で生成したSegmentに対して評価を行う
Self-RAGの特徴的な要素としてreflection tokenという特殊なトークンがあります。reflection tokenには以下の4種類があります。

| type | 意味 |
|---|---|
Retrieve |
Retrieveを行うかどうかを判断するために使うトークン |
ISREL |
Retrieveにより取得したdocumentがinputに対し関連性のある情報かどうかを示すトークン |
ISSUP |
inputとdocumentから生成したoutputがdocumentの内容をどの程度正しく含んでいるか3段階評価で示すトークン |
ISUSE |
inputに対するoutputの内容を5段階評価で示すトークン |
reflection tokenがどのように用いられるのかはこちらのフローが分かりやすいです。

Self-RAGではreflection tokenを出力するために任意のLMを学習する必要があります。これによってSelf-RAGのハードルは若干高くなってしまうかもしれないと思いました。
SELF-RAG trains an arbitrary LM to generate text with reflection tokens by unifying them as the
next token prediction from the expanded model vocabulary.
Adaptive RAG
ざっくり言うと✨
- クエリの複雑さに基づいて適切にRAGのアプローチを変える手法(Apaptive Approach)
- 率直な質問("Straightforward Query")と判断された場合、Retrieveしない
- 簡単な質問("Simple Query")にはRetrieveを一度実行するSingle-Step Approachを適用する
- 複雑な質問("Complex Query")にはRetrieveを複数回実行するMulti-Step Approachを適用する
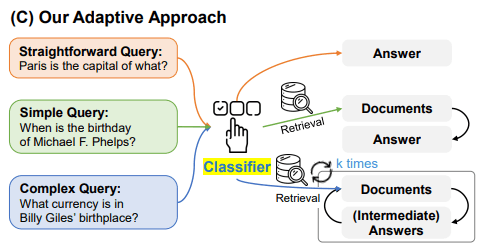
手法
Adaptive RAGのキモとも言えるクエリの複雑さを判定するClassifierは比較的小さなLMを準備するようです。
where Classifier is a smaller Language Model that is trained to classify one of three different complexity levels and o is its corresponding class label
複雑さのラベルはこのように振られています。
| クエリの種類 | ラベル |
|---|---|
| 率直な質問("Straightforward Query") | A |
| 簡単な質問("Simple Query") | B |
| 複雑な質問("Complex Query") | C |
Classifierはクエリの複雑さを上記の3段階で評価しますが、Classifierの訓練にも工夫がなされています。
- Retrieveをしないアプローチで正解が生成された場合、そのクエリには'A'を割り当てます
if the simplest non-retrieval-based approach correctly generates the answer, the label for its corresponding query is assigned ‘A’.
- それ以外のクエリについては答えが得られたアプローチのうち、簡単な方のアプローチに対応するラベルを割り当てます。例えば、Single-Step ApproachとMulti-Step Approachで同じ答えを導けた場合は複雑さが低い方の'B'ラベルを割り当てます
Also, to break the tie between different models in providing the label to the query, we provide a higher priority to a simpler model. In other words, if both single-step and multi-step approaches produce the same correct answer while
the non-retrieval-based approach fails, we assign label ‘B’ to its corresponding query. - 上記のステップでラベルが付かないクエリ(例えば3つのアプローチのいずれもで正解できなかった場合)については、ベンチマークのデータセットに対応するようにラベルを割り当てます。例えば、single-hop datasetsのクエリに 'B' を、multi-hop datasetsのクエリに 'C' を割り当てます
- single-hop datasetsにはSQuAD v1.1, Natural Questions, TriviaQA、multi-hop datasetsにはMuSiQue, HotpotQA, 2WikiMultiHopQAが含まれています
Corrective-RAG (CRAG)
ざっくり言うと✨
- CRAGではRAGで取得したドキュメントの内容がクエリに対して正しいか(関連性があるか)を評価する
- ドキュメントの内容が正しくない or 曖昧である場合は元のクエリを書き換えて、web検索をすることでより関連性の高い知識が得られるようにする手法
手法
CRAGは下記に示す図のフローになっています。
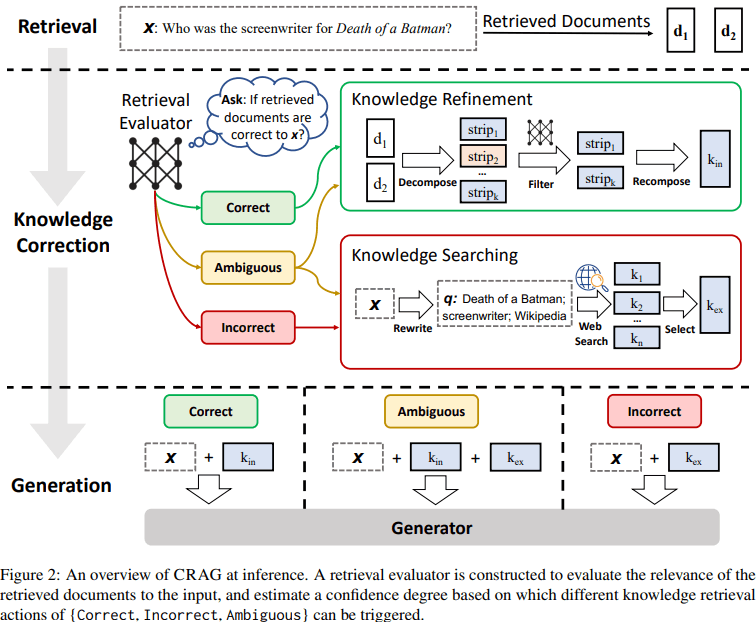
-
Retrieval
- 通常のRAGと同様にクエリに対して関連するドキュメントを取得する
-
Knowledge Correction
- ドキュメントがクエリに対して関連性のあるものかどうかをRetrieval Evaluatorによって3段階で評価する
- ⭕『Correct』or『Ambiguous』と判定された場合、Knowledge Refinementによって、それらのドキュメントを結合する
- ❌『InCorrect』『Ambiguous』と判定された場合、Knowledge Searchingによって、クエリの書き換え&web検索を行い、より関連性のあるドキュメントが取得できるように入力を書き換える
-
Generation
- Knowledge Correctionで取得したドキュメント(実際はdecompose->recomposeの過程を経る)とクエリを入力し、解答を得る
Retrieval Evaluatorについて
- Knowledge Correctionで使用するRetrieval EvaluatorはT5-largeの事前学習モデルを採用しfine-tuningしています。
We fine-tuned the retrieval evaluator based on the lightweight T5-large (Raffel et al., 2020) pre-trained model. Its parameter size is much smaller than the most current LLMs (Touvron et al., 2023a,b; Chowdhery et al., 2023; Anil et al., 2023; Brown et al., 2020; Ouyang et al., 2022; OpenAI, 2023).
- fine-tuningに使用するデータセットは既存のデータセットを活用しているようです。例えば、PopQAデータセットでは、各質問に対応する関連Wikipediaページのタイトルを提供しています。そのタイトルからWikipediaページを追跡して、対応文書をクエリと関連するポジティブサンプルとします。
For example, PopQA (Mallen et al., 2023) provides the golden subject wiki title from wikipedia for each question. We can use that to track a not 100% relevant but rather high-quality passage.
- クエリと関連しないネガティブサンプルはデータセットからランダムに抽出しているようです。
On the other hand, the negative samples were randomly sampled and we used the version provided by Self-RAG (Asai et al., 2023).
- ポジティブサンプルのラベルは1、ネガティブサンプルのラベルは-1と設定し、fine-tuning時にはドキュメントの関連度を-1~1までで推論します。
- Retrieval Evaluatorが出力する3つのラベル(『Correct』『Ambiguous』『InCorrect』)は関連度の閾値で決定します。閾値はデータセットに応じて可変です。
The label of positive samples was 1, while that of negative ones was -1. At inference, the evaluator scored the relevance from -1 to 1 for each document. The two confidence thresholds for triggering one of the three actions were set empirically. Specifically, they were set as (0.59, -0.99) in PopQA, (0.5, -0.91) in PubQA and ArcChallenge, as well as (0.95, -0.91) in Biography.
参考
Discussion