データサイエンスで楽々ドイツ語学習 その3 単語を楽に覚えよう!単語リストのネットワーク解析
この記事の概要
語彙学習では、単語をバラバラに覚えるよりも「意味のつながり」を意識したほうが記憶に残りやすい──そう言われています。
そこで今回は、自然言語処理モデル FastText とネットワーク可視化ツール VOSviewer を使って、意味の近いドイツ語単語をつなげて“見える化”し、より効率的に覚える方法を模索してみました。
つまり、chatGPTなどのLLMが言葉を認識する方法を可視化することで、人間にとっても効率的に学習にならないだろうか、という、つまり 「AIの学習方法を人間の学習に応用する」 ということをしてみたいと思っています。
具体的には、ゲーテ・インスティトゥートが提供するドイツ語語彙リストをもとに、FastTextで単語間の意味的な距離を計算し、それをVOSviewerで可視化。
どのような試行錯誤を経て、どんな図ができあがったのか、その過程を記録した記事です。
時間がない方&技術的なことはすっ飛ばしたい方は「4. VOSviewerでネットワークの視覚化」だけでもどうぞ。

↑ 完成した単語リストのネットワークの視覚化です
[ゲーテの単語リスト(PDF)] はこちらを参照しています。前々回の記事で、このPDFファイルはcsvに変換済です。(https://www.goethe.de/resources/files/pdf209/dtz_wortliste.pdf)
前回のあらすじ
- ドイツ語学習の単語を覚えるという地道な作業をいかに楽して行えないか…
- データサイエンスの知識アップもしたい…
という、どうしようもない欲深い私が、遠回りしながらも、データサイエンスでドイツ語学習をする記録をつづってきました。
前回の記事その2(ゲーテCSVリストの基礎分析)
前回の記事その1(非構造データをClaudeで構造データに変換)
前回の記事その0(なぜドイツ語とデータサイエンス?)
とんでもない亀更新なので、自分専用のドイツ語学習アプリをLLMの力を借りて作ってみたい、なんて野望もありますが、まだだいぶ先の話になりそうです。
アプリまではいかなくても、今回は、単語を覚えるためのネットワーク解析に挑みます。
動機(なぜLLMの技術が単語記憶に役立つの?)
現在のLLM(ChatGPTなど)は、膨大なテキストデータから単語同士の意味的な距離を学習しています。例えば、
- 「犬」と「猫」は近い距離(どちらもペット)
- 「犬」と「自動車」は遠い距離(全く違うカテゴリー)
この距離はベクトルという数学的な表現で計算され、人間の直感的な「言葉の近さ」と驚くほど一致します。
また、人間の脳も関連する情報を「まとまり」として記憶します。
そこで、意味的に関連する単語、距離の近い単語を視覚的にクラスター化してネットワークで視覚化することで、記憶の定着を助けられないか?と考えました。
PythonでSemantic Network の図を作る
1. ドイツ語のWord2Vecをダウンロード
ドイツ語でよく使われる学習済みのWord2Vecにどんなものがあるか、わからなかったので、困ったときのChatGPTさんに聞き、日本語でもおなじみのFastTextを利用することに。これはFacebookが公開している学習済みのモデルで、157言語で利用可能だそうです。(NLP界隈は全くの初心者です。すみません。)
こちらからダウンロードできます。[1]
いざ、Pythonでモデルを読んで、CSVの単語リストをグラフに変換するぞ~と思いきや、モデルを読むだけで10分以上経過。私のロースペックPCでは、NLPはなかなかハードルが高いことが判明。
クラウド使ってやる手もありますが、プライベート用のクラウド環境を作ってないため、とりあえず、時間はかかるけど、一度読んでしまえば大丈夫そうなので、このまま行います。(フリーランスのデータサイエンティストとしてどうなん?ってお思いでしょうが、委託業務は会社から支給されたPCしか使わないため、個人端末で作業することほぼないんです。Kaggleはクラウド環境用意されてるし、というか業務以外でデータサイエンスをすることがほぼなく、普通のPCでもやれている現状です。)
2. ゲーテ単語リストだけのWord2Vecを作成
このあたりのコードはchatGPTさんにサクッと書いてもらいます。少し手直しするだけでできるし、未経験の分野において、使用するpackageなどサクサク学習できるので、本当に学習効率よいです。チート感あるけれど、どんどん賢く正しく使っていきたいです。
from tqdm import tqdm
german_words = set(df['German'].str.split().str[-1].str.lower()) # handle 'der Alkohol' → 'alkohol'
input_path = path_root + "wordvec/cc.de.300.vec"
output_path = path_root + "wordvec/german_filtered.vec"
with open(input_path, "r", encoding="utf-8") as in_file, open(output_path, "w", encoding="utf-8") as out_file:
# First line: number of words and vector size
header = in_file.readline()
total, dim = header.strip().split()
print("Filtering vectors...")
count = 0
vectors = []
for line in tqdm(in_file, total=int(total)):
parts = line.rstrip().split(" ")
word = parts[0].lower()
if word in german_words:
vectors.append(line)
count += 1
# Write new header
out_file.write(f"{count} {dim}\n")
for vec in vectors:
out_file.write(vec)
print(f"Filtered {count} word vectors saved to {output_path}")
3. networkxを使って可視化
いよいよSemantic Networkに可視化していきます。
まず、最初の200の単語について、プロット
import pandas as pd
import numpy as np
import networkx as nx
import matplotlib.pyplot as plt
from gensim.models import KeyedVectors
from itertools import combinations
from sklearn.manifold import TSNE
# Load the filtered FastText model (assumed already trimmed as discussed)
model_path = path_root + "/wordvec/german_filtered.vec"
model = KeyedVectors.load_word2vec_format(model_path, binary=False)
# Clean German words (e.g., remove articles like "der", "die", "das")
german_words = df['German'].str.split().str[-1].str.lower().unique()
# Filter words that exist in the model
valid_words = [word for word in german_words if word in model]
# Limit to top N for visualization clarity
N = 200 # You can increase this for a denser graph
selected_words = valid_words[:N]
# Calculate similarity matrix
edges = []
threshold = 0.4 # Similarity threshold
for w1, w2 in combinations(selected_words, 2):
sim = model.similarity(w1, w2)
if sim > threshold:
edges.append((w1, w2, sim))
# Create graph
G = nx.Graph()
for w in selected_words:
G.add_node(w)
for w1, w2, sim in edges:
G.add_edge(w1, w2, weight=sim)
# Use t-SNE for better node layout
vectors = np.array([model[word] for word in selected_words])
tsne = TSNE(n_components=2, random_state=42, perplexity=30)
tsne_coords = tsne.fit_transform(vectors)
# Map t-SNE positions to nodes
pos = {word: tsne_coords[i] for i, word in enumerate(selected_words)}
# Plotting
plt.figure(figsize=(16, 12))
nx.draw_networkx_nodes(G, pos, node_size=300, node_color='coral', alpha=0.7)
nx.draw_networkx_edges(G, pos, alpha=0.3)
nx.draw_networkx_labels(G, pos, font_size=10)
plt.title("Semantic Network of German Words", fontsize=20)
plt.axis('off')
plt.tight_layout()
plt.show()
うーん、微妙、微妙すぎる。というか、名詞と動詞が混合していて、あまり意味がない気がする。

ということで、名詞に限定してみます。

うーん、名詞に限定して最初の200語をプロットしてみたけど、うーん、どうだろう、見にくい、美しくない、単語学習が効果的になるかというと、全然そんなことない。というか醜い。
色とか大きさとか変えたいけど、networkxをつかった描写はかなり設定がめんどくさそう。
ということで、Python使うのやめた。
4. VOSViewerでネットワークの視覚化
少し調べたところ、VOSviewerという意味ネットワークの図を作成する無料ツールがあるらしい。[2]

ダウンロードして、動かしてみる。
FastTextでconnectivityを計算したファイルをVOSviewerに投入。このあたりも、ChatGPT様様に計算スクリプトを救ってもらい、少し手直しするだけです。なんていい時代でしょう。
そして、、、
やったー!!!これです!いい感じのができた!!!

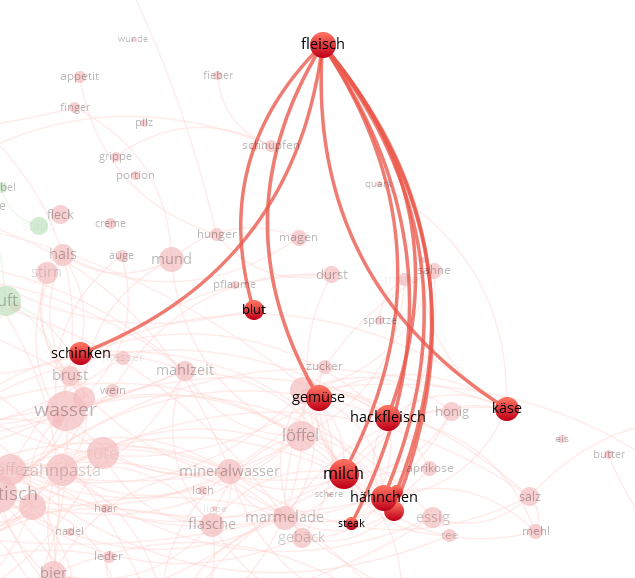


拡大して観察すると、似た意味の言葉が確かにつながっていて、カテゴリーとして認識できる。
これ、これ、これです。これを作りたかった。
glück(運)にunglück, pech(不運) という言葉伸びているのは、その通りだし、
glückからgeld(金)につながってるのも、なんかなるほどーって感じだし、
glückから、erfolg(成功)、geduld(忍耐)につながっているのも、なんかエモいですね。
地道に勉強することでつくりあげていった頭の中にフワフワっと存在するドイツ語の言葉空間の地図を、こうやって視覚化することで、もっとはっきりと自分の中に位置づけたり、まだ作り上げてないものをここに埋め込むことの手伝いにできないかと、思っています。
この図を見たからといって、実際の効果は何もなくて、単語帳とかは初めからカテゴリ分けされているし、ドイツ語の文章に触れることで、個人のこういう地図を少しずつ作っていくしかないのだけれど、私にとって大嫌いなドイツ語単語学習を、私なりの方法で、少しでも助けたくてつくってみました。
今、名詞だけに限定しているので、つながりがあるけれど、動詞だけや、あえて動詞と名詞を全部のせることもできます。
動詞のみバージョン
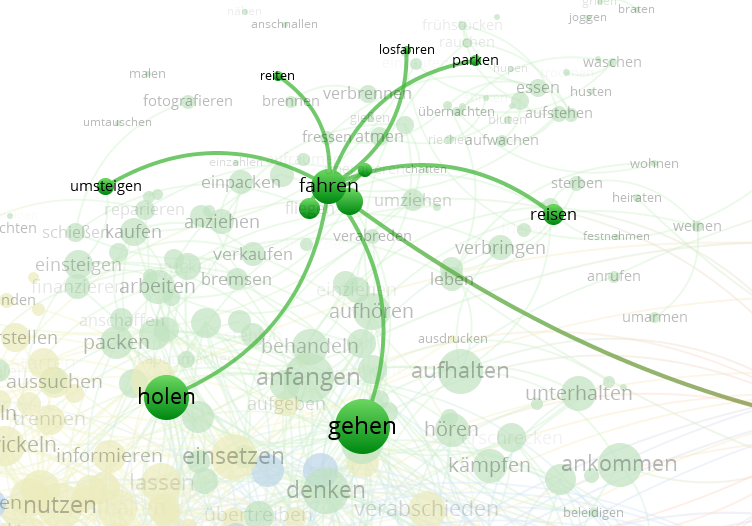
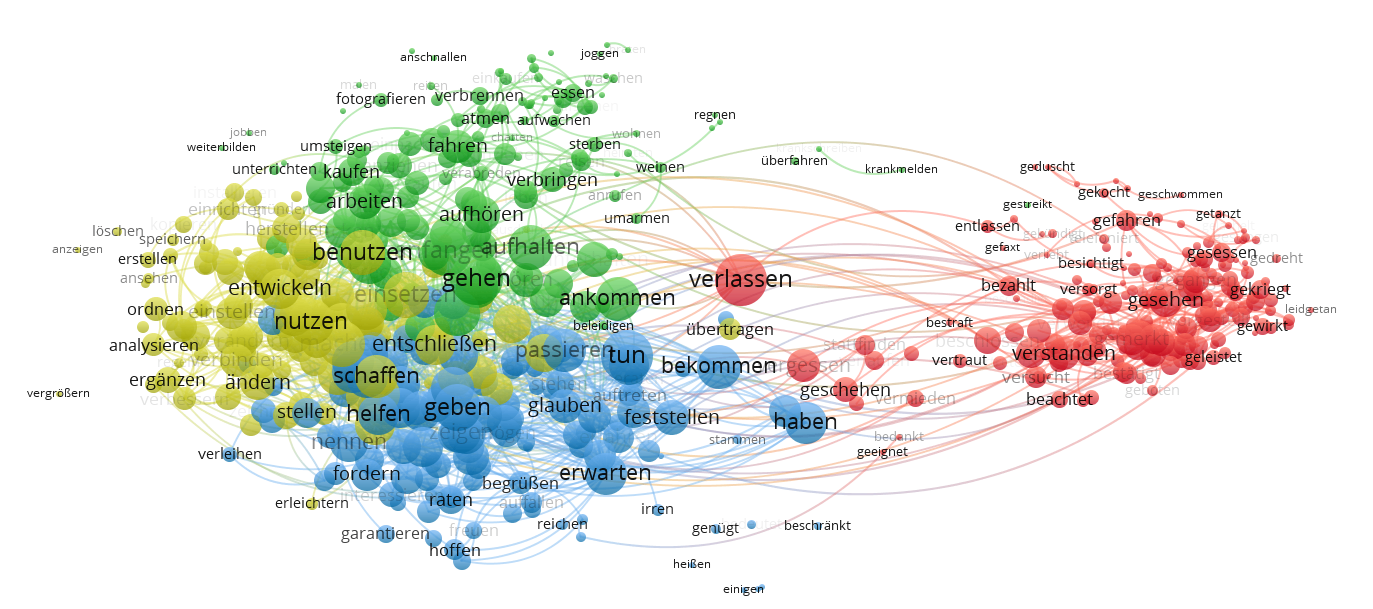
まとめ
少し変わった視点で単語を見ることで、
- 記憶の定着を少しでも助けたり、
- 意味的にまとまった単語をまとめて覚えることで、学習の質をあげたり、
- 知らない単語があれば、すでに知っている単語とセットで覚えることが可能になる。
のではないかと思っています。
新聞を読んだりすれば、自然とそういうことが脳の中で構築されていくわけではあるのですが、今回はNLPやグラフ理論のお勉強もかねて、こういう形でやってみました。
私にとっては、ドイツ語の新聞読むのは面白くないけど、データサイエンスの勉強は楽しいので、それも一つの理由です。能動的にやる勉強って定着するんですよね。ドイツ語もいつか能動的に楽しく学べたらいいな、と思いつつ、今日はここまで。
今回の単語リスト少しレベルが低く初心者向け単語が多いので、C1-C2向けの難易度の高い語彙で、グラフを作成してみたいし、次は、ある新聞の記事をグラフ空間に描写してみるのも、面白そう、と思っています。
やってみたいことは、いろいろとあるけれど、なんせ時間との戦いです。
亀更新ですが、また次回お会いできると嬉しいです。
少しでも面白いと思ったら、Likeお願いします!
-
VOSviewer https://www.vosviewer.com/ ↩︎
Discussion