データサイエンスで楽々ドイツ語学習 その1 非構造化データを構造化データに変換する
その1 単語を楽に覚えよう!非構造化データ⇒構造化データ変換
(忙しい人へ記事の要約)
LLM(Claude)つかって、PDFの非構造データをCSV構造化データに変換したよ!
このCSVつかえば、単語学習が超効率的になるんでは!?期待!という内容です。
モチベーション
1.単語を覚えるの嫌だ
単語を地道に覚えるのが一番の近道!何事も基礎錬が大事!私に足りていないのは語彙力!とにかく単語を覚えるのだ!!!!・・・が、いやすぎる!!!!!!!
このゲーテの単語リスト、これを覚えればいいんですよ。でもね、これ見てください、いやじゃないです?もうこれ見るだけで超やる気そがれません?
ゲーテの単語リスト(PDF)
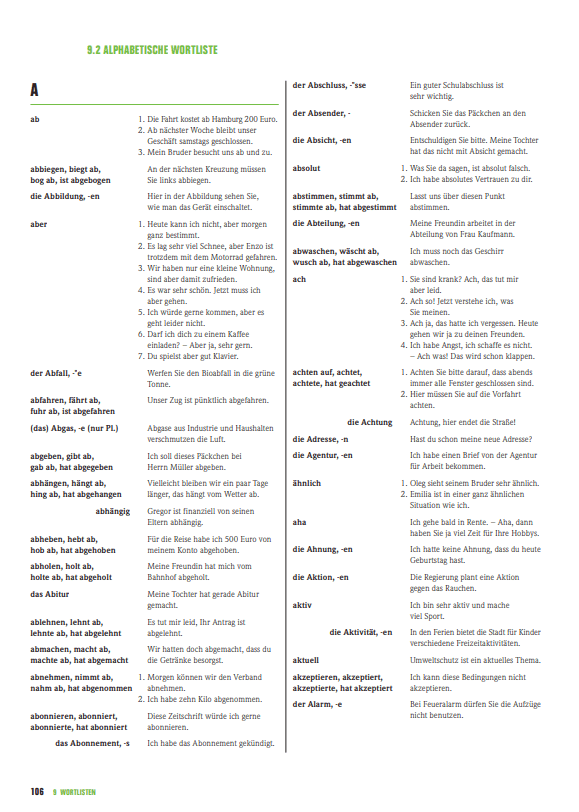
80ページもあるし、このリスト全然楽しくないし、見ているだけで一瞬で眠くなるし、モチベーションあがらないにもほどがある!!!!!
しかも一回やって終わりじゃなくて、何度も繰り返し覚えなきゃ…
いやすぎるーーーーーーーー!!!!!
2. 構造化データ変換技術が熱い
あ!!!ひらめいた!!!!
このPDFをCSV形式に変換すれば、後々Ankiアプリに入力したり、なんならお手製のアプリなんか開発できるんじゃね?その方が効率いいんじゃない?
AI界隈でも、最近は、非構造化データを構造化データに変換するのが激熱技術って聞いた。
会社員時代は、研修という名のもと、お金にならない業務でも、興味のあることや最新の動向チェックのために、一定の時間を割くことができていたし、同僚と情報交換ができていたけれど、フリーランスになった今、そんなことはあたりまえだにできないので、自分の領域以外のテーマについて知る機会も、学ぶ機会も、なくなってしまった。
フリーランスのデータサイエンティストなんて将来不安定すぎる私。技術をキャッチアップしなければ!
ということで、今回は、ゲーテの単語リスト(PDF)非構造データ を
構造化データ(CSV)に変換して、単語を覚える効率を上げたいと思っています。
非構造化データから構造化データへの長い試行錯誤
- PDFファイルを読み込む
- 整形する
- 英語の意味を持ってくる
- csvに保存する
やりたいことはこの4点だけなのに、何せ初めてのことなので、かなり回り道しました。
回り道の過程が長いので、「失敗の方法なんていらん!時間ない!結果だけ知りたい!」という方は、この章は飛ばして、次の章を見てくださいね。(この章の5以降がClaudeつかってます)
1. pythonで普通にやってみる
tabula-py というPDFファイルをtableデータに変換してくれるツールがあるらしいので、これでやってみる。も、全然できない。
- PDFをpythonで読むという初めの第一歩でつまずく
- ゲーテのリストみたいに、真ん中半分で分割されてるPDFはかなりややこしい
- PDFに鍵かかってるっぽくてそれもなんかめんどい
なんか無理。あきらめる。ここまで1時間経過。うん。はじめてのことって時間かかるよね。
2. LLM(Claude)に投げる
PDFの文章をコピペして、「この文章をいい感じに区切ってcsvにしてね」ってざっくりお願いすると、いい感じに吐き出してくれる!!
さすがやん~!最新のLLMはやっぱりすごい!
でもさ、コピペめんどいわ。
80ページあるし、何回もコピペするの嫌なのよね。
そしてこのPDFが、コピーするの大変。1ページのコピぺに何回も分けてコピペせんとダメっぽい。なんでこんな変なPDFつくったんです?ゲーテさん?
3. ClaudeにPythonスクリプト書いてもらう
「ドイツ語単語と例文が書いてあるPDFファイルを読み込んで、構造化にするためのpythonスクリプト書いてね」ってざっくりお願いすると、良い感じのスクリプト書いてくれるんだけど、やっぱり無理。
- まず、PDFが全然読み込めない。
このゲーテのPDFになんかしらの制限がかかっているみたいで(全然詳しくないのでわかりません。初心者ですみません)、いろんなPDFリーダー使って読み取り試みるも、難しいことが判明。 - 読めた頁もルールベースではデータ整形うまくいかない。
単語によって、例文の数が違ったり、パターンが多すぎて、このPDFの構造だとルールベースで書くの大変すぎる。すべてのパターンに対してルール書けばいいけど、そんなのしたくない。めんどい。無理。
→ 非構造データを構造化する技術がなぜ今熱いか、身をもって体感
4. pythonでPDFを画像に変換して、画像からOCRでテキスト読んでみる
PDFをpythonで読むことにつまずいているので、いっそ、画像から光学文字認識するって方法はどうだい???
- (1) PDFを画像ファイルに変換する
pdf2image に使用するpopplerのダウンロード
https://laboratory.kazuuu.net/convert-a-pdf-file-to-an-image-using-pdf2image-in-python/
def pdf_to_images(pdf_path):
return convert_from_path(pdf_path, poppler_path="path_to_poppler/poppler/Release-23.11.0-0/poppler-23.11.0/Library/bin/")
images = pdf_to_images(pdf_path)
for i in range(len(images)):
images[i].save(path+"wortlist_png/"+"wl_%d.png"%i)
- (2) Tesseract OCR 使う
https://zenn.dev/nifumafu/books/f6f7ba7b0d5333/viewer/6a8f60
→ やっとちゃんとデータ読めた!!!! やったー!!!
でもその先の構造化がむずい・・・
Claudeにデータ渡して、構造化するpythonスクリプト書いてもらっても、いろんなパターンがありすぎて、ルール化するのは難しいみたい。
Pythonを使わず、Claudeにデータを入力すれば、構造化はうまくやってくれる。やはりLLMが必要。
5. 構造化の最適化のため、複数のLLM試す
- chatGPTは上手に整形できず
- Groqは指示を無視する傾向あり
- Claudeが一番賢そう
ということで、Claudeでプロンプトエンジニア。
課金すると直接画像を入力できることが判明。賢い。
従量課金オプションがあったので、とりあえず5ドル課金。チャリーン。
OCR使わなくても、直接画像入力できるの賢すぎる。好き。
微調整を繰り返すこと1時間。
こんな感じです。単語の英訳つけたり、例文を省略せずに全部載せたり。
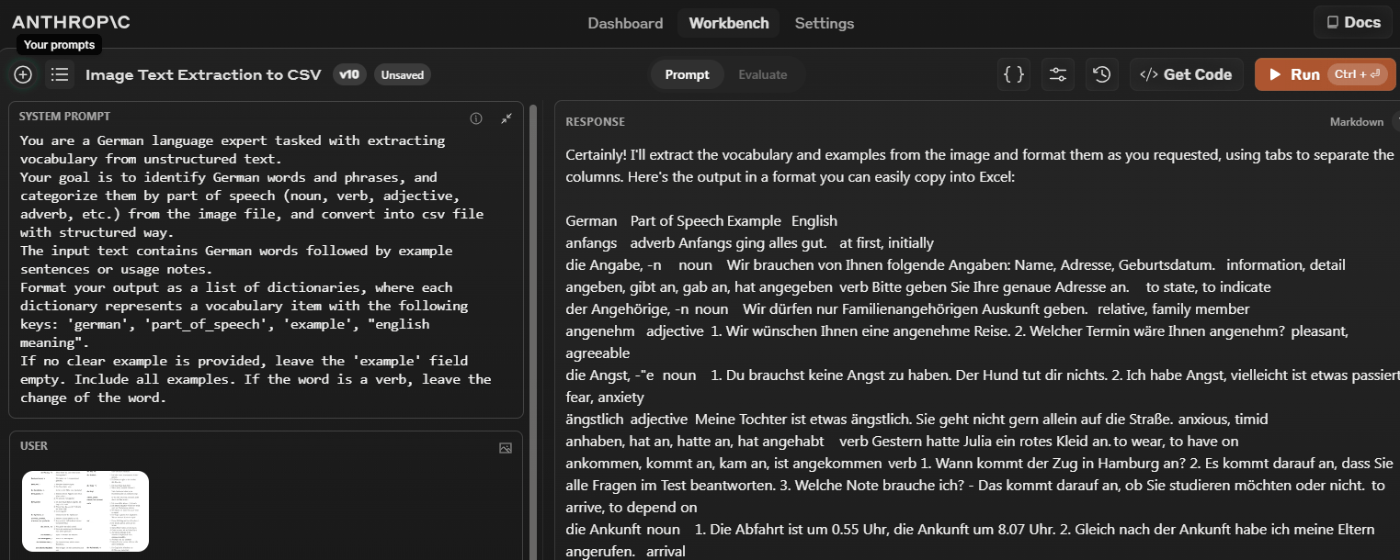
6. ClaudeをAPIでたたく
Claudeの出力文字が4000が最大なので、1ページずつが限界。
単語リストが80ページあるし、画面上で何度もやるのは嫌だなぁ。
PythonからCaludeをAPIで叩くかぁ、コード書くのめんどいかなぁ、って思ってたら!!!
なんと画面右上に[Get Code]ボタンを発見!!!
マジか!賢い!すぐに変換してくれる!しかもプログラム言語も選べる!!!

もうマジで賢すぎる・・・愚かな人間の私ごときでは太刀打ちできない・・・
ありがとう・・・
ということで、txtファイルに変換保存を一括で。
7. .txtファイルを.csvに変換

これですこれ!これを作りたいがための今までの努力!!!
やったー!やったー!やったー!
結果
試行錯誤の結果、
- PDFファイルを画像ファイルに変換
- LLM(Claude)に画像渡して、構造化データに変換(API利用でtxtファイルに保存)
- txtファイルをcsvファイルに変換
という3ステップでPDFファイル(非構造データ)をCSVファイル(構造データ)に変換するということに成功しました!!!!
ここまで費やした時間、10時間くらい。使用したAPI利用料2.1ドル。
10時間あれば、手入力でもCSVリスト作れたんじゃね?という突っ込みはいらないです。なぜなら、私は、CSVが欲しいけど、LLMでやりたかったから!LLMのすごさをハンズオンで体験する10時間は私にとってプライスレス!そしてこの熱意というかやる気が学習に必要なわけだと再認識しました。この感覚をドイツ語学習にも持てたら、私のドイツ語はどんなに素晴らしいものになるのだろうか。。。。
とにかくにも、ドイツ語の勉強には役立つかはわからんけど、このCSVリストがあれば、もっともっと効率的な勉強ができるに違いない!!!!
ということで、次回はこのCSVリストを分析してみます。
このCSVリスト結構需要あるんじゃないかな。
ほしい人いたらメッセージください。
著作権で問題になりそうなので、販売するつもりはないですが、方法考えます~。
Discussion