はじめに
以下のポストの通りStability AIが「Japanese Stable CLIP」を公開されたので、画像の内容を感情分析ようにしたい & ほかからでも使えるようにAPIを実装しました
バックエンドのGPUサーバーレスには、最近ハマっているModalを使っていきます
Modalを使ってLCMを使ったdiscordコマンドを実装した内容は以下で書いています!
環境
- Modal
- Python3.10
ライブラリ
- modal
実装
Modal側で動くAPIを実装します
from modal import Stub, web_endpoint
import modal
stub = Stub("clip_api")
emotions = [
"喜び", "悲しみ", "怒り", "驚き", "恐怖", "愛情", "幸福", "落胆", "焦燥", "安心",
"羨望", "憎悪", "恥ずかしさ", "後悔", "感謝", "切望", "無関心", "興奮", "ストレス", "満足",
"嫌悪", "不安", "穏やか", "孤独", "誇り", "羞恥心", "同情", "嫉妬", "安堵", "希望"
]
@stub.function(
image=modal.Image.debian_slim().pip_install("ftfy", "pillow", "requests", "transformers", "sentencepiece",
"protobuf", "torch"),
secret=modal.Secret.from_name("HUGGINGFACE_TOKEN"),
gpu="t4",
timeout=1000)
@web_endpoint()
def run_clip(image: str):
from transformers import AutoModel, AutoTokenizer, AutoImageProcessor
token = os.environ["HUGGINGFACE_TOKEN"]
model_name = "stabilityai/japanese-stable-clip-vit-l-16"
# モデルとトークナイザーとプロセッサーの準備
model = AutoModel.from_pretrained(
model_name,
trust_remote_code=True,
token=token
).to("cuda")
tokenizer = AutoTokenizer.from_pretrained(
model_name,
token=token
)
processor = AutoImageProcessor.from_pretrained(
model_name,
token=token
)
import ftfy, html, re, torch
from typing import Union, List
from transformers import BatchFeature
def basic_clean(text):
text = ftfy.fix_text(text)
text = html.unescape(html.unescape(text))
return text.strip()
def whitespace_clean(text):
text = re.sub(r"\s+", " ", text)
text = text.strip()
return text
def tokenize(
tokenizer,
texts: Union[str, List[str]],
max_seq_len: int = 77,
):
if isinstance(texts, str):
texts = [texts]
texts = [whitespace_clean(basic_clean(text)) for text in texts]
inputs = tokenizer(
texts,
max_length=max_seq_len - 1,
padding="max_length",
truncation=True,
add_special_tokens=False,
)
input_ids = [[tokenizer.bos_token_id] + ids for ids in inputs["input_ids"]]
attention_mask = [[1] + am for am in inputs["attention_mask"]]
position_ids = [list(range(0, len(input_ids[0])))] * len(texts)
return BatchFeature(
{
"input_ids": torch.tensor(input_ids, dtype=torch.long),
"attention_mask": torch.tensor(attention_mask, dtype=torch.long),
"position_ids": torch.tensor(position_ids, dtype=torch.long),
}
)
import io
import requests
from PIL import Image
# 画像とラベルの準備
url = str(image)
image = Image.open(io.BytesIO(requests.get(url).content))
image = processor(images=image, return_tensors="pt").to("cuda")
text = tokenize(
tokenizer=tokenizer,
texts=emotions
).to("cuda")
# 推論の実行
with torch.no_grad():
image_features = model.get_image_features(**image)
text_features = model.get_text_features(**text)
text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
# 出力テンソル
output_tensor = text_probs[0]
print(output_tensor)
# 確率値が0より大きいラベルのみを辞書型で出力
label_probs = {label: prob.item() for label, prob in zip(emotions, output_tensor.squeeze()) if prob.item() > 0}
return label_probs
デプロイ
上記の内容をmodal側にDeployします!
modal deploy ファイル名
結果
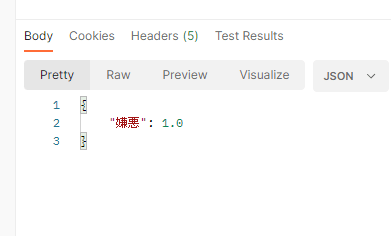
以下の画像を判定してみます

嫌悪な画像という判定になりました?

midra-lab.notion.site/MidraLab-dd08b86fba4e4041a14e09a1d36f36ae 個人が興味を持ったこと × チームで面白いものや興味を持ったものを試していくコミュニティ
Discussion