はじめに
MidraLabというコミュニティを運用しています。コミュニティでは、ゲーム制作やPoC、プロト開発など様々なことを行っているのですが、その中で画像を簡単に作れると楽なのではないかと思い、数ステップで画像が生成されるSimianLuo/LCM_Dreamshaper_v7を使ってコマンドが実装しました!
概要
- ChatGPT DALL·E 3よりも1/10程度 低コストで画像が生成できる(無料枠で月に6000回程度叩ける)
- GPUサーバーレスで実装しているため、スマホ等に応用ができゲームやアプリへの組み込みが可能
デモ
以下は実際にコマンドを叩いたときのデモ動画です!動画速度はそのままなので以下のような感じで実際に使用できます
生成速度は30-40s程度になります
開発環境
bot側
- Python 3.10
- py-cord == 2.4.1
画像生成側
- modal (v0.55.4073)
- diffusers==0.22.0
準備
まずは以下のアカウントが必要になるので、登録を行います
HuggingFace
Huggin FaceのSettingからAccessTokensを生成します

Modal
- ModalのSECRETSから
Create new secretを押します
1 .
.
-
Customを選択します。

-
Keyを入力して、ValueにHuggingFaceで生成したTokenを入れます
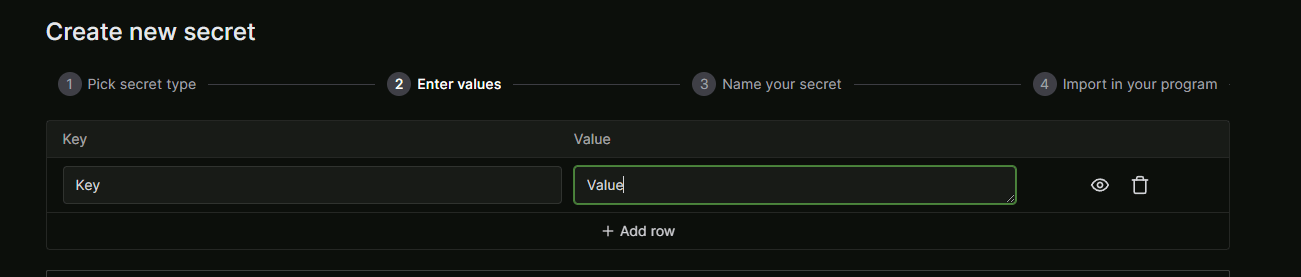
-
secrets nameを入れてNextを押せば登録完了です!

実装
Modal側で画像を生成する処理を実装します。
今回はdiscordのbotとして使用したいので、Web endpointsとして実装をします。これによってURLが分かればどこからでも叩くことができます
画像生成APIは以下の流れで実装します
- 必要なライブラリのインストール
- モデルのダウンロード
- 画像の生成
- バイナリーデータをbase64に変更する
- jsonにまとめて返す
画像生成処理
from modal import Stub, web_endpoint
import modal
stub = Stub("generate_image")
@stub.function(
image=modal.Image.debian_slim().pip_install("transformers", "torch", "diffusers==0.22.0", "requests", "accelerate"),
secret=modal.Secret.from_name("HUGGINGFACE_TOKEN"),
gpu="t4",
timeout=1000)
@web_endpoint()
def run_diffusion(prompt: str, num_images: int):
from diffusers import DiffusionPipeline
import torch
import base64
import io
import json
pipe = DiffusionPipeline.from_pretrained("SimianLuo/LCM_Dreamshaper_v7").to(torch_device="cuda",
torch_dtype=torch.float16)
# 生成された画像のBase64データを格納するための辞書
base64_images_dict = {}
for i in range(num_images):
# 画像を生成
image = pipe(prompt=prompt, width=512, height=512, num_inference_steps=6, guidance_scale=8, lcm_origin_steps=50,
output_type="pil").images[0]
# バイトIOオブジェクトを初期化
buf = io.BytesIO()
# 画像をPNG形式でバイトIOオブジェクトに保存
image.save(buf, format="PNG")
# バイトIOオブジェクトをBase64エンコードする
base64_data = base64.b64encode(buf.getvalue()).decode('utf-8')
# Base64エンコードされたデータを辞書に追加
base64_images_dict[f'image{i + 1}'] = base64_data
# バッファをクリア
buf.close()
# 辞書をJSON文字列に変換して返す
return json.dumps(base64_images_dict)
Bot側の実装
bot側では、以下の流れで実装をします
- EndpointのURLを叩いて画像生成処理を待機
- base64のデータを画像データに変換
- discord側に送信
@com.command(name="generate_image", description="画像を生成させるコマンド")
async def generate_image(
self,
ctx: discord.ApplicationContext,
prompt: Option(
str,
description="プロンプト",
)
):
await ctx.response.defer()
try:
response = requests.get(self.endpoint + "generate_image",
params={"prompt": prompt, "num_images": 4}) # 生成枚数は4枚固定
except requests.RequestException as e:
self.log_util.log_command_execution(f"Failed to send request: {e}", prompt)
await ctx.followup.send("リクエストの送信中にエラーが発生しました")
return
# 前提として、response.textにはBase64エンコードされた画像データのリストが含まれていると仮定します。
if response.status_code == 200:
try:
# 余分なエスケープシーケンスを解決する
parsed_str = response.text.encode().decode('unicode_escape')
# 最初と最後のダブルクォートを削除し、エスケープされたダブルクォートも除去する
json_str = parsed_str.strip('"').replace('\\"', '"')
# 文字列をJSONオブジェクトに変換する
images_dict = json.loads(json_str)
files = []
# 辞書の各キー(画像)に対して繰り返し処理
for key, base64_image in images_dict.items():
# Base64文字列をバイナリデータにデコード
image_data = base64.b64decode(base64_image)
# バイナリデータをファイルライクオブジェクトに変換
image_stream = io.BytesIO(image_data)
image_stream.seek(0)
# discord.Fileオブジェクトを作成し、リストに追加
files.append(discord.File(image_stream, filename=f"{key}.png"))
# メッセージとともに画像を送信(最大10個のファイルを添付可能)
await ctx.followup.send(f"画像を生成しました!\n"
f"```{prompt}```", files=files)
except json.JSONDecodeError:
await ctx.followup.send("エラー: JSONの解析に失敗しました。")
except Exception as e:
await ctx.followup.send(f"予期せぬエラーが発生しました: {e}")
else:
await ctx.followup.send(
f"サーバーからのレスポンスが200 OKではありません。ステータスコード: {response.status_code}")
```
midra-lab.notion.site/MidraLab-dd08b86fba4e4041a14e09a1d36f36ae 個人が興味を持ったこと × チームで面白いものや興味を持ったものを試していくコミュニティ
Discussion
コメント失礼します。
Bot制作をしているのですが、この記事はとても参考になりました。
ですが2点気になる場所があったのでコメントさせていただきます。
requests.getでレスポンスを待っている最中に新たなinteractionが発生し、かつ何らかの理由で3秒以上の待機時間が生じた場合、ユーザには「インタラクションに失敗しました。」というメッセージが出る可能性があります。指示しているようで恐縮ですが、検討をお願いします。
ご指摘ありがとうございます!こちら確認させていただきます
同期部分の処理および複数のリクエストが飛んだ際にエラーになることは確認済み(大変だったためスルーしていた)ため、上記のコードを含めて試してみます