AWSで実現するカオスエンジニアリング
カオスエンジニアリングとは
カオスエンジニアリングの原則から引用させていただきますと、
カオスエンジニアリングは、分散システムにおいてシステムが不安定な状態に耐えることの出来る環境を構築するための検証の規律です
- 通常の動作を示すシステムの測定可能な出力として「定常状態」を定義することから始めます
- この定常状態は、対照群および実験群の両方で継続すると仮定します
- サーバーのクラッシュ、ハードドライブの誤作動、ネットワーク接続の切断など、現実世界のイベントを反映する変数を導入します
- 対照群と実験群との間の定常状態の違いを調べることによって仮説を反証しようとします
現場に即したもので言えば、意図的に障害を引き起こしても 正常 と定義した状態(サービスの接続性など)が担保されていますか?を確認するためのものです。
早期から活用していて有名なのは、Netflixでしょうか?
2014年10月7日 - 米動画配信のNetflix、Chaos MonkeyのおかげでAmazon EC2のメンテナンスリブートを難なく乗り切る
有名なツール類としては以下でしょうか?(他にも色々とありますが、挙げ始めたら切りがないので...
他にもどういったツールがあるかを見てみたい方は、wikipedia - Chaos engineeringなどにも記載があります。
AWS公式サービスとして
AWSのグローバルイベント「re:Invent 2020」にて 発表されていたもの が
2021年3月31日に正式リリースされました。
AWS Fault Injection Simulator で出来ること
(注意)FISの設定で気をつけるポイント
AWS Fault Injection Simulator - Set up IAM permissions
In addition, the IAM role must have a trust relationship that allows the AWS FIS service to assume the role.
この「信頼するエンティティ」の修正を忘れると実行できません。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "fis.amazonaws.com"
},
"Action": "sts:AssumeRole",
"Condition": {}
}
]
}
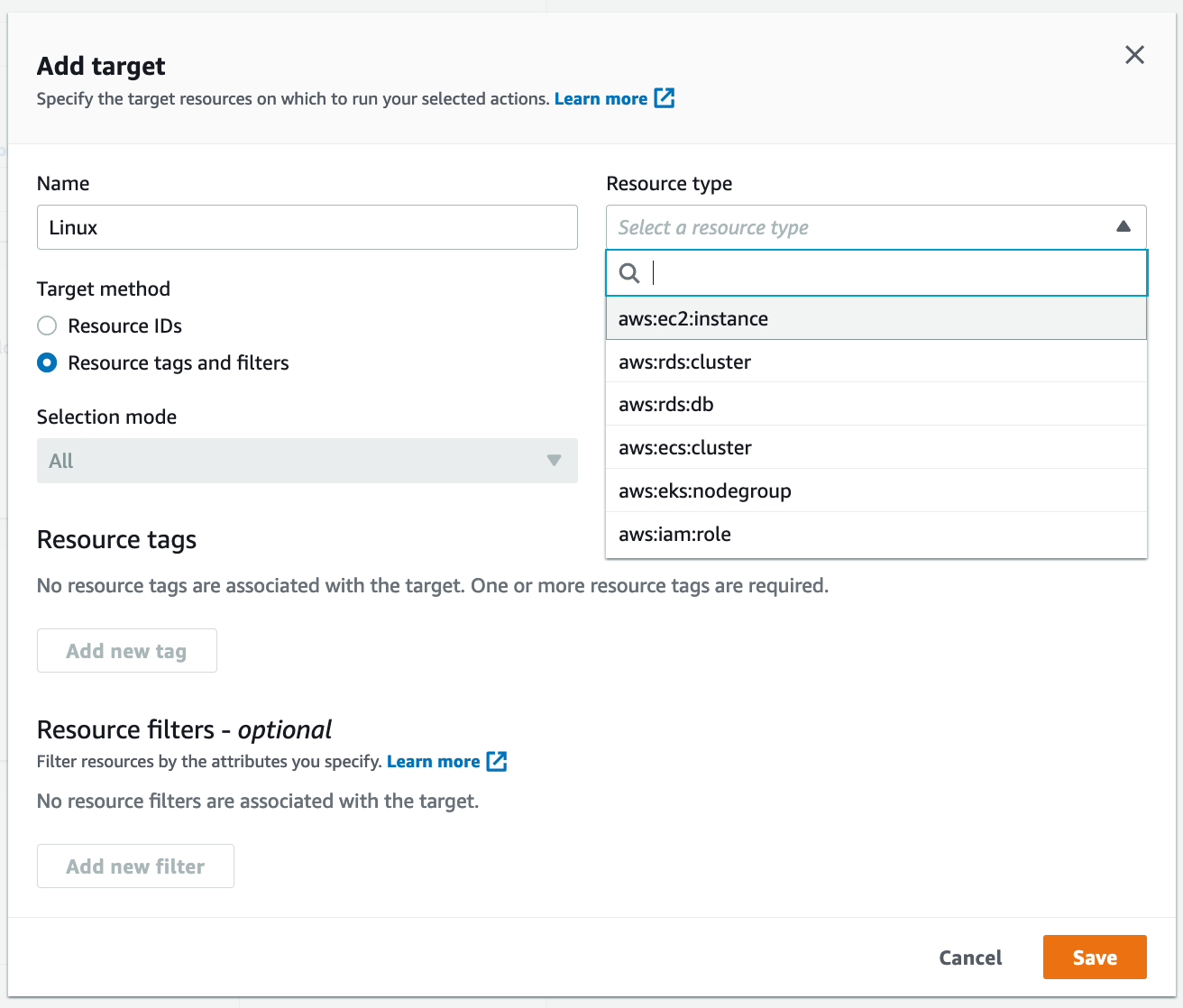
(参考)実行可能なリソース
Targets for AWS FIS - Resource types
- aws:ec2:instance – Amazon EC2 instances
- aws:ecs:cluster – Amazon ECS clusters
- aws:eks:nodegroup – Amazon EKS node groups
- aws:iam:role – IAM roles
- aws:rds:cluster – Amazon Aurora DB cluster
- aws:rds:db – Amazon RDS DB instances
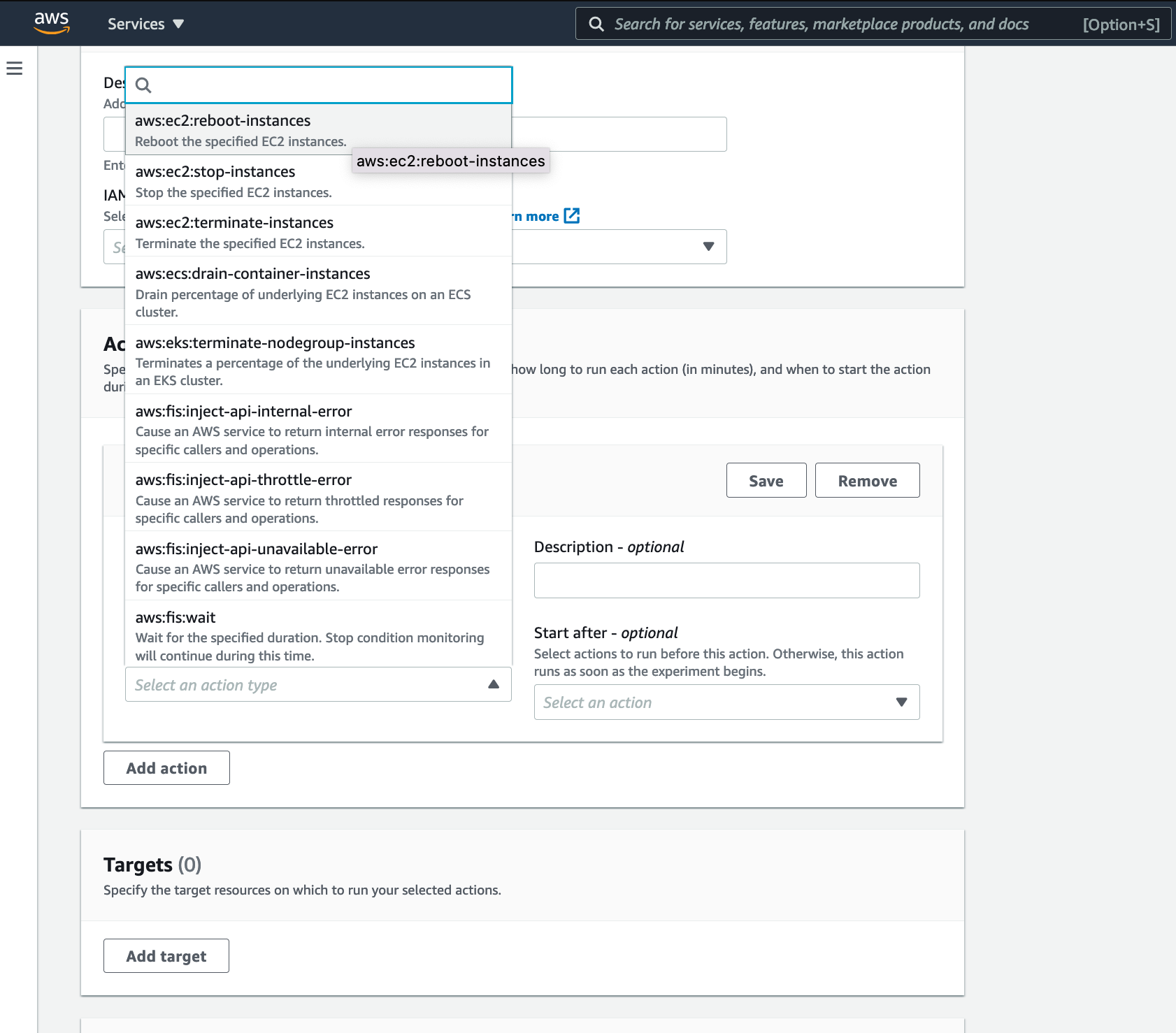
(参考)実行可能なアクション
(基本的にドキュメントの主観に基づく意訳です)
-
Fault injection actions
- aws:fis:inject-api-internal-error - 内部エラー(何かよく分からんエラー)
- aws:fis:inject-api-throttle-error - スロットルエラー(一度に呼び出しすぎ)
- aws:fis:inject-api-unavailable-error - 利用不可エラー(権限不足など)
-
Wait action - 複数のFIS実験を動かす際の休憩するときに利用
- aws:fis:wait - 待つ
-
Amazon EC2 actions - EC2に対してなにかするときに利用
- aws:ec2:reboot-instances - 再起動
- aws:ec2:stop-instances - 止める
- aws:ec2:terminate-instances - 終了する(=インスタンス削除)
-
Amazon ECS action - ECSに対してなにかするときに利用
- aws:ecs:drain-container-instances - ECSクラスタのEC2インスタンスを排出(?)
-
Amazon EKS action - EKSに対してなにかするときに利用
- aws:eks:terminate-nodegroup-instance - EKSクラスタのEC2インスタンスを終了
-
Amazon RDS actions - RDSに対してなにかするときに利用
- aws:rds:failover-db-cluster - Multi-AZのインスタンスでF/O
- aws:rds:reboot-db-instances - 再起動
-
Systems Manager action - SSMに対してなにかするときに利用
- aws:ssm:send-command - EC2に対してSSMアクションを実行
(注意)実験テンプレート
(注意)実験結果
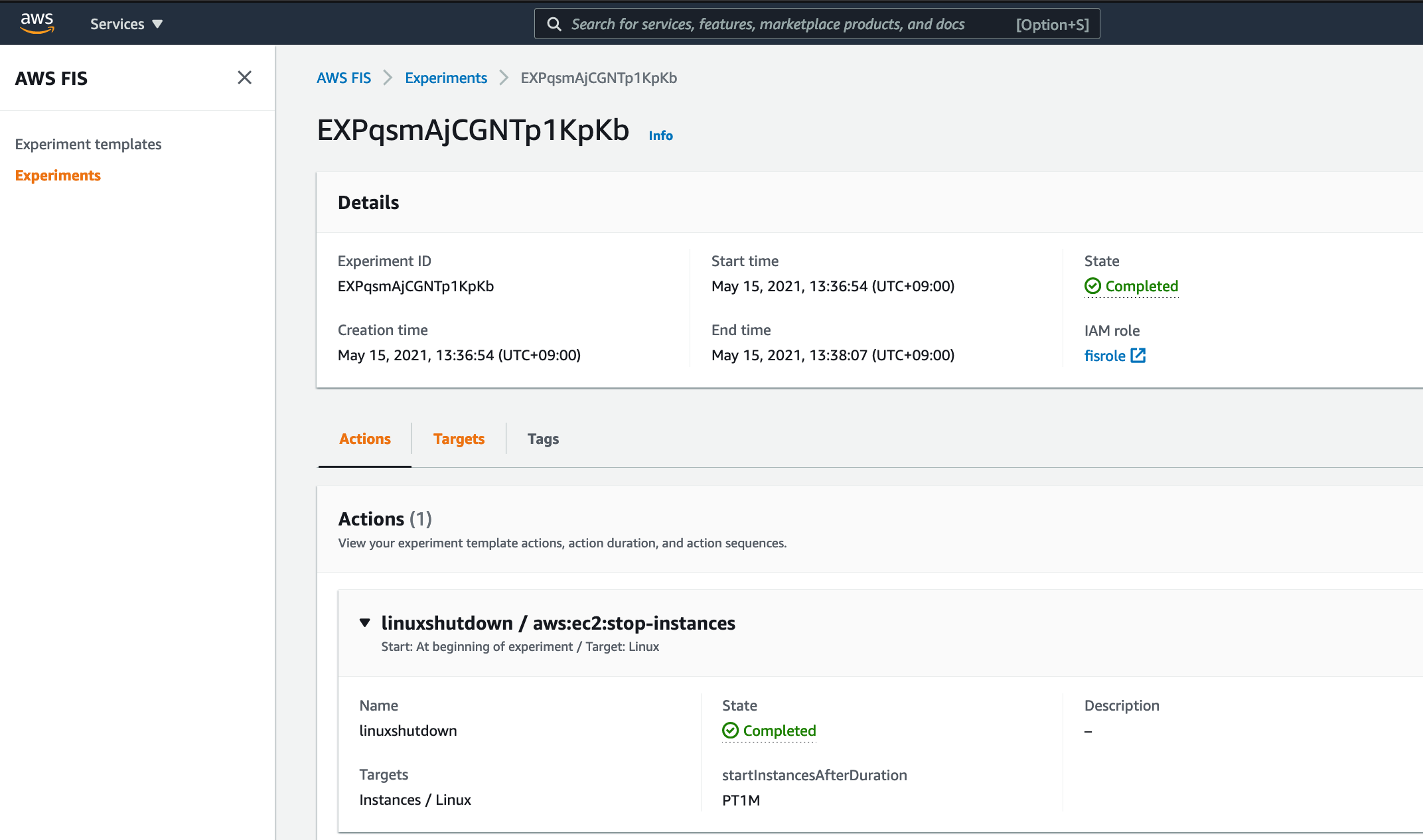
EC2の場合
一度停止させたあとに、何分後に起動するかを設定可能です
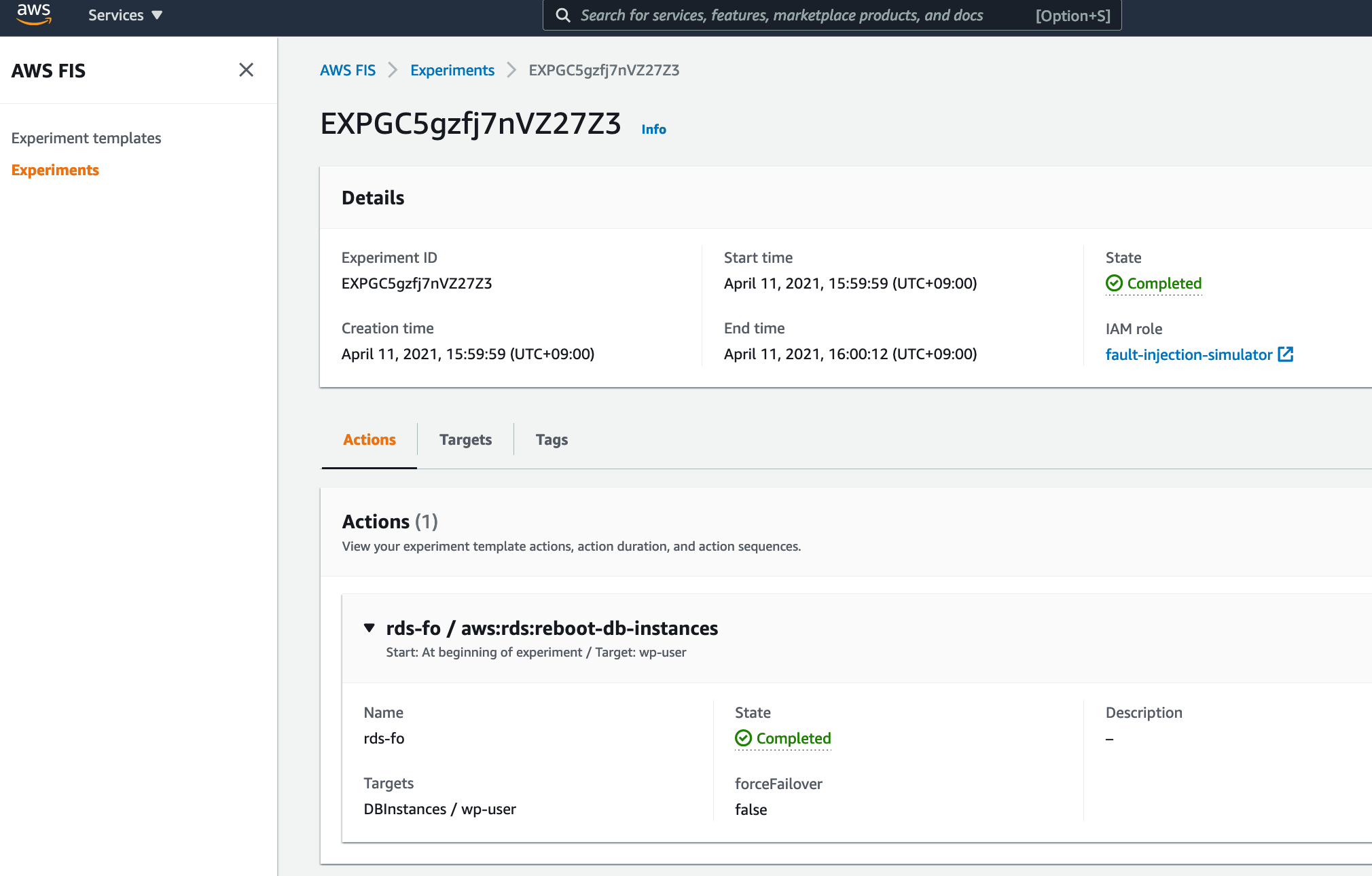
RDSの場合
Multi-AZ構成のときはF/O(Fail Over)オプションも選べます
まとめ
私自身、10年前に新卒からオンプレミスで本番環境での障害対応の経験をすることが多く、
WebサーバからDBサーバまで一連の経験値を積むことが出来ました。
一方で、2・3年も保守運用もすれば、軽微なインシデントを除くとなかなか後から入るメンバに対して、
そういった経験を積ませることができないことが悩みのポイントでもありました。
今回のFISを通じて、本来は本番環境で正常性を確認するためのサービスですが、
そういった障害訓練を積ませるための使い方もAWSの中だけで完結するというのは選択肢に入ってきたので広めてみようと思います。
Discussion