tl;dr
このリポジトリのDeep Research機構の流れは以下のようになっている。
- クエリ生成:トピックに関して最適な検索クエリを生成
- Web検索:Tavily APIを使用して複数の検索を行い情報を収集
- 要約:AIが収集した情報を分析し要約
- リフレクション:システムが知識のギャップを特定しさらなる調査を行う
- 繰り返し:リフレクションの結果、追加の調査が必要であれば調査サイクルを繰り返し実施
- レポート生成:画像を含んだ最終的かつ包括的なレポートを作成
課題点としては以下の様な点が見られた。
- リフレクションのゴール判定が固定値としてのループ回数で行われている
- 最終レポートの生成コンテキストに最初のクエリ生成からの検索結果も含める方が良い
- DeepSeek以外のモデルへの対応と構造化オプションの利用
C#で実装しなおしたコードは以下のリポジトリに公開した。
はじめに
LLMの発展は目覚ましく、直近ではChatGPTやGeminiなどさまざまなLLMサービスでDeep Researchと呼ばれる複雑な調査を自律的に実行し、数百の情報源からデータを統合したレポートを生成することができるようになりました。
多くの製品では、情報源はWeb上の情報をソースとしますが、Microsoft 365 Copilotの「リサーチャーエージェント」機能では、Microsoft Graphを通じて組織内のドキュメントやメールなどに対してDeep Researchを行うことができます。
このようにDeep ResearchはWeb上のソースだけでなく自社の情報資産を活用して調査を行うこともできます。
同様に自社でLLMを組み込んだサービスを社内外向けに開発している開発者にとっても、そのサービスにDeep Researchを実装したい場面があると考えられます。
そこで本記事ではMicrosoftがGitHubで公開しているDeep Researchのサンプルコードを紐解いていきます。
また、併せてPythonで実装されている本家コードをC#で実装しなおしてみます。
ちなみにこのリポジトリはMicrosoftの年次フラグシップカンファレンスであるMicrosoft Build 2025内でハンズオンラボのコンテンツとして使われたようです。
※これ以降特に注釈のない画像は、上記のGitHubリポジトリからの引用または著者が独自に作成したものです。
リポジトリの全体像を理解する
注目すべき部分のみを抜き出していますが、以下がサンプルコードリポジトリの全体像です。
deepresearch/
├── app/ ----------------> メインのアプリケーションコードディレクトリ
│ ├── main.py ---------> エンドポイントや全体のオーケストレーションを担っている
│ ├── prompts.py ------> プロンプト一式が入っている定数ファイル
│ ├── states.py -------> 推論実行時の状態を管理するためのクラス
│ ├── formatting.py ---> 検索結果をフォーマットしてテキスト形式にするUtilクラス
│ ├── static/ ---------> JSやCSSなど、フロントエンドの静的ファイルディレクトリ
│ └── templates/
│ └── index.html --> UI用のHTML。特にSPAフレームワークなどは使っていない
└── infra/ --------------> azdコマンドでAzureリソースを作るためのBicepテンプレート
ここまでざっとリポジトリを俯瞰してみて、特筆すべきポイントは以下の通りです。
APIはFastAPIで実装
FastAPIを使用してAPIが実装されています。FastAPIはPythonでWeb APIを作る時は最近よくみるフレームワークです。
Web検索APIにはTavilyを使用
Web検索APIとしてTavilyを使用しています。
Tavilyは、Web検索APIを提供するサービスで、Webサイトに「Connect Your LLM to the Web」とあるように、特にAIやLLMのアプリケーションでの利用が想定されています。
無料のプランも用意されており、毎月1,000 APIクレジットが使えるのも嬉しいポイントです。
LangGraphを使用した状態管理と遷移
LangGraphのStateGraphを使用した状態遷移グラフを構成し、クエリの生成やWeb検索などをノードとして定義しています。
WebSocket通信を実装
Deep Researchは深い洞察を得るために、繰り返し検索と推論が行われます。それは高精度な結果を得ることができる一方で最終的な回答まで時間を要することがあります。そのため、WebSocket通信を使用して、クライアントに進捗状を通知する仕組みが実装されています。
WebSocket通信は、FastAPIのWebSocketクラスを使用して実装されています。
azd upコマンドに対応
Azure Developer CLI(azd)を使用して、Azureリソースを簡単に作成できるようになっています。
infraディレクトリにBicepテンプレートがあり、azd upコマンドでAzureリソースの作成とアプリのデプロイまでが完結します。
Deep Research機構を理解する
全体の流れを理解する
このリポジトリのDeep Research機構の流れは以下のようになっています。
- クエリ生成:トピックに関して最適な検索クエリを生成
- Web検索:Tavily APIを使用して複数の検索を行い情報を収集
- 要約:AIが収集した情報を分析し要約
- リフレクション:システムが知識のギャップを特定しさらなる調査を行う
- 繰り返し:リフレクションの結果、追加の調査が必要であれば調査サイクルを繰り返し実施
- レポート生成:画像を含んだ最終的かつ包括的なレポートを作成

コードを理解する
リポジトリの全体像を踏まえると、基本的にapp/main.pyを見ればDeep Research機構で行なっている処理を理解できそうです。
以後、main.pyのコードを中心にDeep Researchの機構を見ていきます。
エンドポイント
エンドポイントは以下の2つが定義されています。
-
/:クライアントファイルのHTMLとJSやCSSなどを返す。Jinja2Templatesを使用してHTMLとJS/CSSをテンプレートとして返すようになっている。 -
/we/{client_id}:WebSocket通信を使ってDeep Researchを実行する。こっちがメイン。client_idはクライアント側でランダムに生成している
そのため、/we/{client_id}のエンドポイントの処理を確認すればよさそうです。このパスはwebsocket_endpoint関数にリンクされています。
この関数が実行されるとWS接続が確立されます。その後、setup_graph関数が呼び出され、Deep Researchの状態遷移グラフがセットアップされます。
setup_graph関数では、LangGraphのStateGraphを使用して、Deep Researchの各ステップ(クエリ生成、Web検索、要約、リフレクションなど)をノードとして定義しています。
def setup_graph():
# Add nodes and edges
builder = StateGraph(SummaryState, input=SummaryStateInput, output=SummaryStateOutput)
builder.add_node("generate_query", generate_query)
builder.add_node("web_research", web_research)
builder.add_node("summarize_sources", summarize_sources)
builder.add_node("reflect_on_summary", reflect_on_summary)
builder.add_node("finalize_summary", finalize_summary)
# Add edges
builder.add_edge(START, "generate_query")
builder.add_edge("generate_query", "web_research")
builder.add_edge("web_research", "summarize_sources")
builder.add_edge("summarize_sources", "reflect_on_summary")
builder.add_conditional_edges("reflect_on_summary", route_research)
builder.add_edge("finalize_summary", END)
return builder.compile()
ここで特筆すべきはbuilder.add_conditional_edges("reflect_on_summary", route_research)の部分です。これによってDeep Researchのリフレクションステップで、検索を繰り返すのか、最終的なレポートを生成するのかを条件分岐で制御しています。route_research関数がその条件分岐のロジックを実装しています。
async def route_research(state: SummaryState):
if state.research_loop_count <= 3:
# ...省略
return "web_research"
else:
# ...省略
return "finalize_summary"
この処理から、Deep Researchのリフレクションステップで、3回までの繰り返し検索を行い、それ以降は最終的なレポートを生成することがわかります。
各ノード処理を理解する
ノードとして定義されている関数は以下の通りで、全体の流れを理解するの流れをイメージすると大体名前から処理が想像できます。
- generate_query:ユーザー入力から検索クエリを作成する(LLM利用)
- web_research:Webを検索する
- summarize_sources:サマリーを生成する(LLM利用)
- reflect_on_summary:サマリーをリフレクションして不足している部分を補うためのクエリを生成(LLM利用)
- finalize_summary:ここまでの検索結果のサマリーを使って最終的なレポートを生成する。あくまで機械的に生成するだけでLLMは利用していない。
ノードの関数から呼ばれるUtil関数としてstrip_thinking_tokensがmain.pyの中で定義されています。この関数はgenerate_query、summarize_sources、reflect_on_summary関数から呼び出されています。READMEやコードからこのアプリケーションは推論のLLMとしてDeepSeekのモデルを使用することが想定されているようです。DeepSeekの推論では思考過程を<think>~</think>というトークンで囲って出力されるため、そのトークンで囲まれた思考の文字列とそれ以外のユーザーへの回答の文字列を分離するためにこの関数が使用されています。
プロンプトを読み解く
プロンプトは各ノードの関数でLLMを使用している3つ分のプロンプトが定義されています。
原文はもちろん英語ですが、ここでは理解を助けるために日本語訳で記載します。
query_writer_instructions:ユーザーからのトピックに関する情報をもとに、最適な検索クエリを生成するためのプロンプト
query_writer_instructions プロンプト(日本語訳)
目標は、ターゲットを絞ったWeb検索クエリを生成することです。
<コンテキスト>
現在の日付: {current_date}
クエリには、この日付時点で入手可能な最新の情報が含まれていることを確認してください。
</コンテキスト>
<トピック>
{research_topic}
</トピック>
<フォーマット>
レスポンスは、以下の3つのキーをすべて含むJSONオブジェクトとしてフォーマットしてください。
- "query": 実際の検索クエリ文字列
- "rationale": このクエリが関連する理由の簡単な説明
</フォーマット>
<例>
出力例:
{{
"query": "machine learning transformer architecture explained",
"rationale": "Understanding the fundamentalstructure of transformer models"
}}
</例>
レスポンスはJSON形式で提供してください。タグやバッククォートは含めないでください。
例のように、JSONのみを返してください。
ポイント
- いわゆるRAGのクエリ生成のステップと同じようなプロンプトですが、クエリを生成するだけでなく「なぜそのクエリを生成しているのか」という理由も説明させている。
- 今日の日付をプロンプトに含めることで、最新の情報を取得するためのクエリを生成するように促している。
- JSON形式での出力が求められていますが、JSON Modeなど構造を保証するオプションは使用されていないようです。そのためまれに不正なJSONが生成されることがあると考えられます。
summarizer_instructions:収集した情報を要約するためのプロンプト
summarizer_instructions プロンプト(日本語訳)
<目標>
提供されたコンテキストに基づいて、質の高い要約を生成する。
</目標>
<要件>
新しい要約を作成する場合:
1. 検索結果から、ユーザーのトピックに最も関連性の高い情報を強調表示する。
2. 情報の流れが一貫していることを確認する。
既存の要約を拡張する場合:
1. 既存の要約と新しい検索結果を注意深く読む。
2. 新しい情報を既存の要約と比較する。
3. 新しい情報ごとに:
a. 既存のポイントに関連する場合は、関連する段落に統合する。
b. 全く新しい情報だが関連性がある場合は、スムーズな遷移を持つ新しい段落を追加する。
c. ユーザーのトピックに関連しない場合は、その情報をスキップする。
4. すべての追加情報がユーザーのトピックに関連していることを確認する。
5. 最終的な出力が入力要約と異なることを確認する。
< /要件 >
< フォーマット >
- 序文やタイトルを付けずに、更新された要約から直接始めます。出力にはXMLタグを使用しないでください。
< /フォーマット >
<タスク>
まず、提供されたコンテキストについて慎重に検討します。次に、ユーザー入力に対応するコンテキストの要約を生成します。
</タスク>
ポイント
- RAGの回答生成ステップと同じようなプロンプト
- 要約を生成する際に一貫性に注意する旨が記載されている。
- 既存の情報がすでに存在する場合はマージする
reflection_instructions:要約結果をもとに、さらなる調査が必要な場合のクエリを生成するためのプロンプト
reflection_instructions プロンプト(日本語訳)
あなたは、{research_topic} に関する概要を分析する、専門のリサーチアシスタントです。
<GOAL>
1. 知識ギャップや、より深く掘り下げる必要がある領域を特定する。
2. 理解を深めるのに役立つフォローアップの質問を作成する。
3. 十分にカバーされていない技術的な詳細、実装の詳細、または新たなトレンドに焦点を当てる。
</GOAL>
<REQUIREMENTS>
フォローアップの質問が自己完結的であり、Web 検索に必要なコンテキストが含まれていることを確認する。
</REQUIREMENTS>
<FORMAT>
回答は、以下のキーを含む JSON オブジェクトとしてフォーマットしてください。
- knowledge_gap: 不足している情報、または明確化が必要な情報を記述する。
- follow_up_query: このギャップに対処するための具体的な質問を記述する。
</FORMAT>
<Task>
概要をよく検討し、知識ギャップを特定してフォローアップの質問を作成する。次に、次のJSON形式に従って出力を作成してください。
{{
"knowledge_gap": "概要にはパフォーマンス指標とベンチマークに関する情報が不足しています",
"follow_up_query": "[特定のテクノロジー]を評価するために使用される一般的なパフォーマンスベンチマークと指標は何ですか?"
}}
</Task>
分析結果はJSON形式で提供してください。タグやバッククォートは含めないでください。例のように、JSONのみを返してください。
ポイント
-
現在まで収集した情報とゴールの間のギャップを確認し、より深く調べる必要がある領域を特定するためのプロンプトが用意されています。これはAzure OpenAIでいうoシリーズのような推論モデルが得意とする分野のように思えます。
-
JSON形式での出力が求められていますが、JSON Modeなど構造を保証するオプションは使用されていないようです。そのためまれに不正なJSONが生成されることがあると考えられます。
まとめと改善と発展
Deep Researchの機構に注目すると以下のような流れで構成されています。
こうしてみるとDeep Researchの機構はそこまで複雑ではなく、LLMによって計画とリフレクションが自律的に行われるシンプルな機構であることがわかります。
また、クエリの生成とその検索結果からのサマリーの作成についてのプロンプトは、Deep Researchを実現しない単純なRAGでも参考になりそうな内容でした。
今回はWebをデータソースとしていますが、これを応用することで、独自のナレッジや、アプリケーションで保持しているデータを活用したDeep Researchも作成することが可能です。
一方で、ハンズオンコンテンツゆえのあえての簡略化だと思われますが、以下の様な改善点も発見できました。
-
リフレクション機構の改善
現在は固定値で3回までの繰り返し検索を行うようになっていますが、ゴールの判定自体もLLMが行うことにより、より確実かつ柔軟な調査が可能になると考えられます。 -
最終レポートの生成に含むコンテキスト
サマリーを生成するステップでは前回のサマリーをコンテキストに含むようになっていますが、
最終的に最終レポートに含まれるコンテキストは、直近のリフレクションステップで取得された検索結果のみとなっています。これを、最初のクエリ生成からの検索結果も含めることで、より包括的なレポートが生成できると考えられます。 -
要約ロジックの改善
現在のロジックでは前段階のWeb 検索の結果が0件だった場合、その前と同じソースを要約するようなロジックになっています。
これはリフレクションによるクエリで検索した結果が0件である場合、その前のソースから同じ要約を生成する可能性があり、LLMの無駄遣いになる。
たとえば、検索結果が0件だった場合にはリフレクションステップにサイドクエリを生成させるなどの改善が考えられます。 -
DeepSeek以外のモデルへの対応
おそらくAzureを利用するユーザーの多くは企業やエンタープライズ系の組織が多く、今回のDeepSeekのようなサードパーティやOSSのモデルではなくAzure OpenAIの様な商用モデルを利用することが多いと考えられます。そのため、Azure OpenAIのモデルへの対応ニーズがありそうです。また次の「構造化オプションの利用」にもそれが関係してきます。 -
構造化オプションの利用
現在は、Deep Researchの結果をテキスト形式で出力していますが、JSON Modeなど構造化されたデータ形式(例えばJSONやXML)で出力することで確実なアプリケーションへの組み込みが期待できます。ただし、JSON Modeは、AzureではAzure OpenAI Serviceの機能として提供されているため、Azure OpenAI Serviceを利用する必要があります。 -
各ステップにおけるモデルの使い分け
クエリの生成やリフレクションはモデルによって結果が大きく変わりそうですが、要約ステップはいわゆる従来からのRAGの回答生成に相当するため、経験上比較的軽量かつ安価なモデルを使用しても良いかもしれません。例えば、前者にはo4-mini、後者はGPT-4oなど。
C#で実装する
ここからが著者個人の本題なわけですが、著者はC#を使用することが多いため今後の持ち駒としてC#でDeep Researchの機構を実装しなおしてみます。
基本的には本記事で紹介したサンプルリポジトリの機構を再現しつつも、前述した改善点を踏まえた以下のような実装を目指します。
実装方針
- UIとDeep Research機構を分離し、DeepResearchをクラスライブラリとして実装する。
- LangGraphはC#ではサポートされていないため、状態遷移を独自に実装する。
- TavilyのSDKもPythonまたはJavaScriptでしか提供されていないため、Web APIを直接呼び出す。
- LLMは各ステップにおいて、Azure OpenAI Serviceのモデルを使い分ける。
- クエリ生成とリフレクション:o4-mini
- 要約:GPT-4o
- Azure OpenAI ServiceのJSON Modeを使用して、構造化されたデータ形式で出力する。
- UIをBlazorで実装する。
- 画像の表示用HTMLをDeepSearchロジック部分から分離し、画像のURLのみを保持する様にする。
できたもの
MITライセンスで公開しているので、ぜひご活用ください。
ディレクトリ構成は以下のようになっています。
DeepResearch-dotnet/
└── app/
├── DeepResearch.Core -----------> DeepResearchのコアライブラリ
├── DeepResearch.SearchClient ---> DeepResearchを行うために情報を取得するための検索クライアント
├── DeepResearch.Console---------> サンプルのコンソールアプリケーション
└── DeepResearch.Web-------------> サンプルのWebアプリケーションのUI
DeepResearch.CoreおよびDeepResearch.SearchClientは、Deep Researchのコア機能と検索クライアントを実装したクラスライブラリです。
この2つのプロジェクトは、Deep Researchの機能を提供するためのもので、コンソールアプリケーションやWebアプリケーションから利用されます。
DeepResearch.Consoleは、コンソールアプリケーションのサンプルで、Deep Researchの機能をコマンドラインから実行できます。
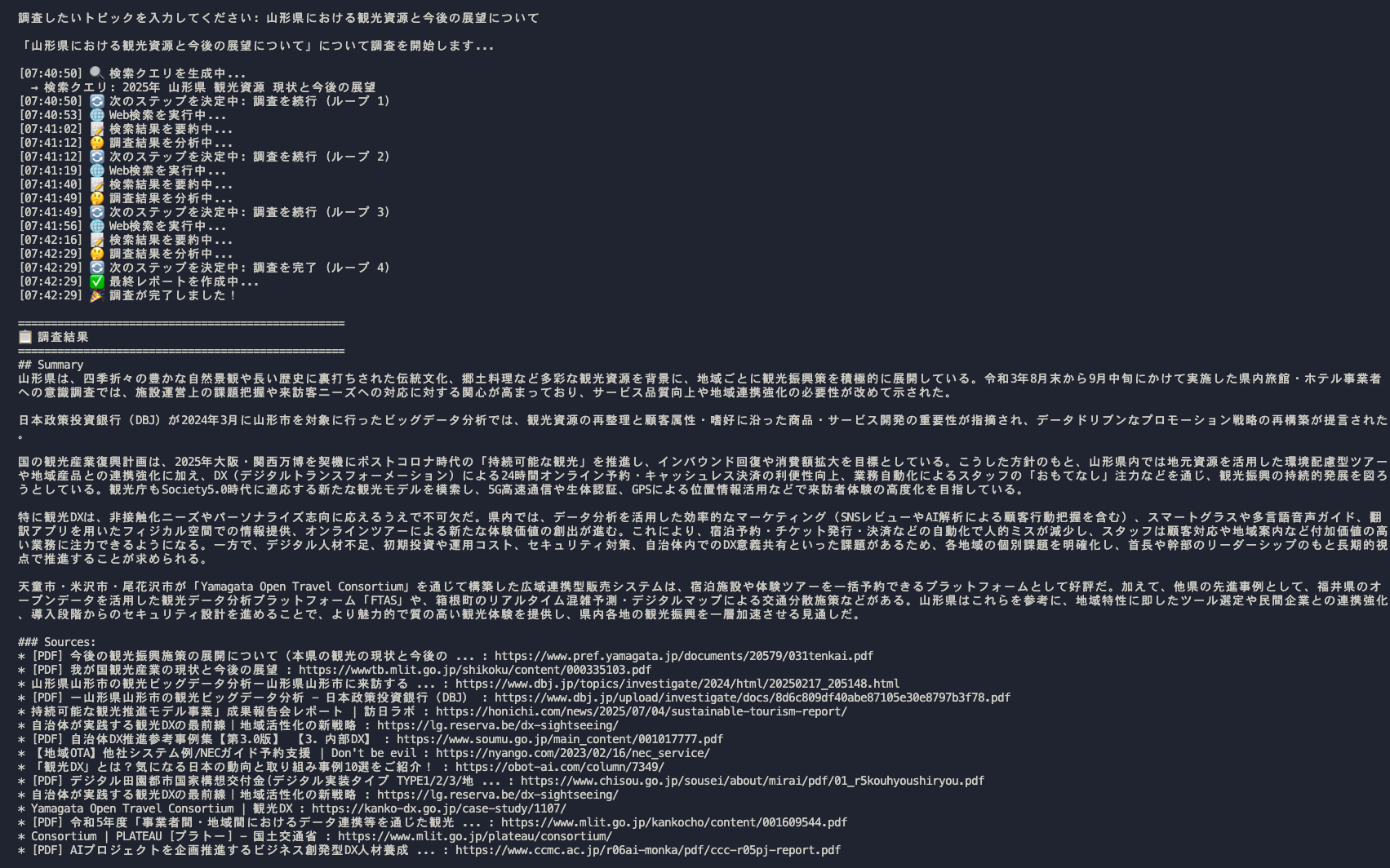
DeepResearch.Webは、Blazorを使用したWebアプリケーションのサンプルで、Deep Researchの機能をWebブラウザから利用できます。
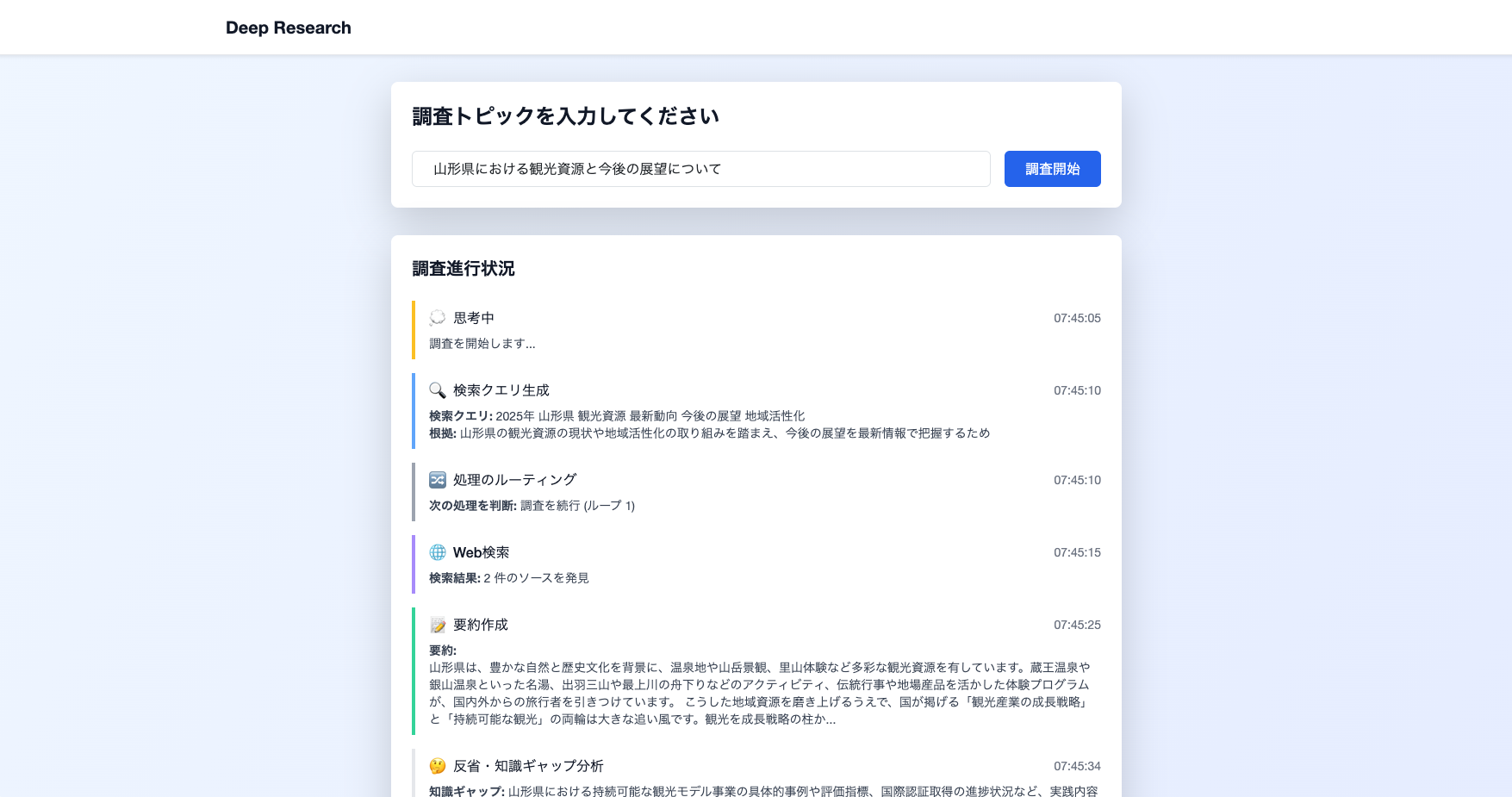
DeepResearch.Webは以下の動画のように動作します。 (最終レポートに画像が表示されていませんが、HTMLで画像(imgタグ)として表示できないInstagramの投稿をTavilyが返したためです。)
拡張性
C#化にあたり、特に工夫した点としては検索エンジンの差し替え容易性です。
DeepResearchをフルスクラッチで開発したいシナリオを考えると、単純にWebを検索するだけでなく、例えば社内のナレッジやデータベースなどを検索するケースが考えられます。そのため、作成したDeepResearchのコアライブラリは、検索クライアントを抽象化したインターフェースISearchClientを定義し邸増す。
そのインターフェースを実装した検索クライアントを独自に追加することで、例えば特定のSharePiintライブラリ内のドキュメントを検索する検索クライアントを追加し、DeepResearch.Coreの変更なしでどのようなデータソースもDeep Researchを実行できるようにしています。
以下は、ISearchClient周りのイメージ図です。
残課題
以下は残課題として今後実装予定です。
- リフレクションステップのゴール判定をLLMに行わせる。
-
最終レポートの生成のコンテキストに、最初のクエリ生成からの検索結果も含める。→ 実装完了 - Web検索結果が0件だった場合にはリフレクションステップにサイドクエリを生成させるなどの改善を実装。
- azd upコマンドでAzureリソースの作成とアプリデプロイできるようにする。
- 各ステップにおけるモデルの使い分け
- クエリ生成とリフレクション:o4-mini
- 要約:GPT-4o

Discussion