こちらは、Microsoft Azure Tech Advent Calendar 2025の4日目の記事です!(初参加!)
App Solution EngineerのMatsumotoです。
今回は、Microsoft FoundryにおけるGPT-4.1のVision Fine-tuningをテーマに記事を書きました。
よろしくお願いします!

はじめに
腕組みをした謎の人物「画像を見て、これが何の欠陥か自動で判定できるようにしてほしい」
製造業などでよくあるこういった課題に対して、Microsoft FoundryのGPT-4.1 Visionをファインチューニングしたらどれくらい精度が上がるのを今回検証してみました。
結論から言うと、53% → 96% まで精度が上がりました。正直ここまで効くとは思ってなかったです。
今回の検証についてのGitHubリポジトリはこちらです↓ Jupyter Notebookで一通り動かせるようになってます。
Vision Fine-tuningとは
2024年10月にOpenAIが発表した機能で、画像を含むデータでGPTモデルをファインチューニングできるようになりました。
Microsoft Foundry(旧Azure AI Foundry)でも2024年11月のIgnite以降利用可能になっています。テキストだけでなく画像の理解もカスタマイズできるので、製造業の外観検査とか医療画像の分類みたいな「ドメイン知識が必要な画像認識」に向いてるんじゃないかと。
ちなみにMicrosoft Foundryとは?については以下が一番わかりやすく表現されてると思いますのでご参考までに置いておきます↓
制限事項
Vision Fine-tuningには以下の制限があります(2025年12月時点)
| 項目 | 制限値 |
|---|---|
| トレーニングサンプル数 | 最大50,000件 |
| 1サンプルあたりの画像数 | 最大64枚 |
| 画像サイズ | 最大10MB/枚 |
| 対応フォーマット | JPEG、PNG、WEBP(RGB/RGBA) |
| 一度にアップロード可能なファイル | 最大8GB(Uploads API使用時) |
何をやったか
鋼材(熱間圧延鋼板)の表面に現れる欠陥を6種類に分類するタスクです。
以下は、NEU-DETデータセットのサンプル画像です。

分類する欠陥は以下の6つ:
| 欠陥名 | 英語名 | 見た目の特徴 |
|---|---|---|
| クレージング | Crazing | 細かいひび割れ模様 |
| インクルージョン | Inclusion | 異物の混入跡 |
| パッチ | Patches | まだら模様の汚れ |
| ピット表面 | Pitted Surface | 点状のくぼみ |
| 圧延スケール | Rolled-in Scale | 圧延時の酸化膜巻き込み |
| スクラッチ | Scratches | 引っかき傷 |
使ったデータセットはNEU Surface Defect Databaseです。各クラス約300枚、合計1,800枚のグレースケール画像が入っています。
Kaggleから取得↓
ちなみにこのデータセット、物体検出や画像分類のベンチマークとしてよく使われてるらしく、論文もいくつか出ています。
環境構築
コードでやるか、UIでやるか
Vision Fine-tuningは以下の2つの方法で実行できます↓
| 方法 | メリット | デメリット |
|---|---|---|
| Python SDK | 自動化しやすい、バージョン管理可能 | 環境構築が必要 |
| Microsoft Foundry UI | ノーコードで即座に試せる | 大量データのアップロードが面倒 |
今回は再現性と自動化を重視してコードでやっていますが、「とりあえず試したい」ならUIからの操作が楽です。Microsoft Foundryにログインして、「Fine-tune」メニューから操作できます。

リージョンの制限
Microsoft FoundryでVision Fine-tuningを使うには、現時点でリージョンの制限があります。
対応リージョンは公式ドキュメントで確認できます。ちょくちょく更新されてるっぽいので、始める前に要チェック。
必要なライブラリ
今回使ったライブラリはこんな感じです。Pythonは3.12.12を使いました。
[project]
requires-python = ">=3.12"
dependencies = [
"openai>=2.8.1",
"azure-identity>=1.25.1",
"azure-mgmt-cognitiveservices>=14.1.0",
"python-dotenv>=1.2.1",
"matplotlib>=3.10.7",
"scikit-learn>=1.7.2",
"pandas>=2.3.3",
"openpyxl>=3.1.5",
]
特にopenaiのPython SDKのバージョンは上記の通りです。もうあまりいないかもですが、バージョン1 以下の古いバージョンだとVision Fine-tuning周りのAPIがサポートされてないかもなので注意が必要です。
環境変数の設定
必要な環境変数はこんな感じです↓
api_key="your-azure-openai-api-key"
azure_endpoint="https://your-resource.openai.azure.com/openai/v1"
subscription_id="your-subscription-id"
resource_name="your-microsoftfoundry-resource-name"
rg_name="your-resource-group-name"
.envファイルを作って、python-dotenvで読み込みます。
import os
from dotenv import load_dotenv
from openai import OpenAI
# 環境変数の読み込み
load_dotenv(override=True)
api_key = os.environ["api_key"]
azure_endpoint = os.environ["azure_endpoint"]
subscription_id = os.environ["subscription_id"]
rg_name = os.environ["rg_name"]
resource_name = os.environ["resource_name"]
# OpenAIクライアントの初期化
client = OpenAI(
api_key=api_key,
base_url=azure_endpoint,
)
データの準備
Vision Fine-tuningでは、画像をBase64エンコードしてJSONL形式で用意します。
データセットの分割
まず、画像を訓練データと検証データに分割します。
コード
from pathlib import Path
import random
def split_dataset(image_dir: Path, train_ratio: float = 0.8):
"""データセットを訓練用と検証用に分割"""
classes = ["crazing", "inclusion", "patches",
"pitted_surface", "rolled-in_scale", "scratches"]
train_data = []
val_data = []
for class_name in classes:
class_dir = image_dir / class_name
images = list(class_dir.glob("*.jpg")) + list(class_dir.glob("*.bmp"))
random.shuffle(images)
split_idx = int(len(images) * train_ratio)
train_data.extend([(img, class_name) for img in images[:split_idx]])
val_data.extend([(img, class_name) for img in images[split_idx:]])
return train_data, val_data
train_data, val_data = split_dataset(Path("steel_surface_defects"))
print(f"訓練データ: {len(train_data)}枚, 検証データ: {len(val_data)}枚")
# 出力: 訓練データ: 1440枚, 検証データ: 360枚
JSONL形式への変換
各画像をBase64エンコードして、JSONL形式に変換します。
JSONLへの変換コード
import base64
import json
def create_training_example(image_path: Path, label: str) -> dict:
"""画像とラベルからトレーニング用のJSONを作成"""
with open(image_path, "rb") as f:
base64_image = base64.b64encode(f.read()).decode("utf-8")
# 画像の拡張子からMIMEタイプを判定
suffix = image_path.suffix.lower()
mime_type = "image/jpeg" if suffix in [".jpg", ".jpeg"] else "image/bmp"
return {
"messages": [
{
"role": "system",
"content": "あなたは鋼材表面の欠陥を分類する専門家です。画像を見て、欠陥の種類を判定してください。"
},
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": f"data:{mime_type};base64,{base64_image}"
}
},
{
"type": "text",
"text": "この画像の欠陥を分類してください。"
}
]
},
{
"role": "assistant",
"content": label
}
]
}
def create_jsonl_file(data: list, output_path: str):
"""データセットをJSONLファイルとして保存"""
with open(output_path, "w", encoding="utf-8") as f:
for image_path, label in data:
example = create_training_example(image_path, label)
f.write(json.dumps(example, ensure_ascii=False) + "\n")
# JSONL形式で保存
create_jsonl_file(train_data, "training_data.jsonl")
create_jsonl_file(val_data, "validation_data.jsonl")
ポイントは、systemプロンプトでタスクの文脈を与えること。これがないとモデルが何をすべきか迷う印象がありました。
JONSLファイルの中身
できあがったJSONLファイルの1行はこんな感じ:
JONSLデータ例
{
"messages": [
{
"role": "system",
"content": "あなたは鋼材表面の欠陥を分類する専門家です。..."
},
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": "data:image/jpeg;base64,/9j/4AAQ..."}},
{"type": "text", "text": "この画像の欠陥を分類してください。"}
]
},
{
"role": "assistant",
"content": "crazing"
}
]
}
参考↓
ファインチューニングの実行
Microsoft FoundryにJSONLファイルをアップロードして、ジョブを投げます。

ファイルのアップロード
まずは訓練データと検証データをアップロード。
# 訓練データのアップロード
with open("training_data.jsonl", "rb") as f:
training_file = client.files.create(
file=f,
purpose="fine-tune"
)
print(f"訓練ファイルID: {training_file.id}")
# 検証データのアップロード
with open("validation_data.jsonl", "rb") as f:
validation_file = client.files.create(
file=f,
purpose="fine-tune"
)
print(f"検証ファイルID: {validation_file.id}")
アップロードしたファイルは処理中になるので、ステータスがprocessedになるまで待ちます。
import time
def wait_for_file_processing(file_id: str, timeout: int = 600):
"""ファイルの処理完了を待つ"""
start_time = time.time()
while time.time() - start_time < timeout:
file_info = client.files.retrieve(file_id)
if file_info.status == "processed":
print(f"ファイル {file_id} の処理完了")
return file_info
elif file_info.status == "error":
raise Exception(f"ファイル処理エラー: {file_info.status_details}")
print(f"処理中... (status: {file_info.status})")
time.sleep(10)
raise TimeoutError("ファイル処理がタイムアウトしました")
wait_for_file_processing(training_file.id)
wait_for_file_processing(validation_file.id)
Microsoft Foundry上からですと以下のようになります。
ファインチューニングジョブの作成
ファイルの準備ができたら、ジョブを投げます。
# ファインチューニングジョブの作成
job = client.fine_tuning.jobs.create(
training_file=training_file.id,
validation_file=validation_file.id,
model="gpt-4.1-2025-04-14", # Vision対応モデル
hyperparameters={
"n_epochs": 3,
"batch_size": 1,
"learning_rate_multiplier": 1.0
}
)
print(f"ジョブID: {job.id}")
print(f"ステータス: {job.status}")
ハイパーパラメータについては、データ量に合わせて調整しました。Microsoftの技術ブログで紹介されている事例(Stanford Dogs)では batch_size=6, epochs=2 を使っていますが、今回はデータ量が少ないので batch_size=1, epochs=3 にしています。
| パラメータ | 今回の値 | ブログ事例の値 | 説明 |
|---|---|---|---|
| batch_size | 1 | 6 | データ量が少ない場合は小さめに |
| n_epochs | 3 | 2 | データ量が少ない分、エポック数で補填 |
| learning_rate_multiplier | 1.0 | 0.5 | デフォルト値を使用 |
ここまで参考にした公式ドキュメント↓
ジョブの完了を待つ
FIne-tuningジョブは数時間かかるので、ステータスを定期的にチェック。
def wait_for_job_completion(job_id: str, check_interval: int = 60):
"""ジョブの完了を待つ"""
while True:
job = client.fine_tuning.jobs.retrieve(job_id)
print(f"[{time.strftime('%H:%M:%S')}] ステータス: {job.status}")
if job.status == "succeeded":
print(f"ファインチューニング完了!")
print(f"モデルID: {job.fine_tuned_model}")
return job
elif job.status == "failed":
raise Exception(f"ジョブ失敗: {job.error}")
elif job.status == "cancelled":
raise Exception("ジョブがキャンセルされました")
time.sleep(check_interval)
completed_job = wait_for_job_completion(job.id)
fine_tuned_model_id = completed_job.fine_tuned_model
Microsoft Foundryのポータルからもジョブの進捗を確認できます。Training lossのグラフが見れるので、ちゃんと学習が進んでるか確認するのに便利。コードでジョブを投げた場合でも、UIで進捗を追うのがおすすめです。

Microsoft FoundryのUI上でFine-tuningジョブの進捗を確認できる
(上画像は途中経過が撮れず、ジョブ完了後の画像となります。)
また、コードベースでもFine-tuningジョブの詳細データを取得できるので、以下のようにPythonなどの描画ライブラリでメトリクスのグラフを描くことができます。(notebookセル76-81参照)
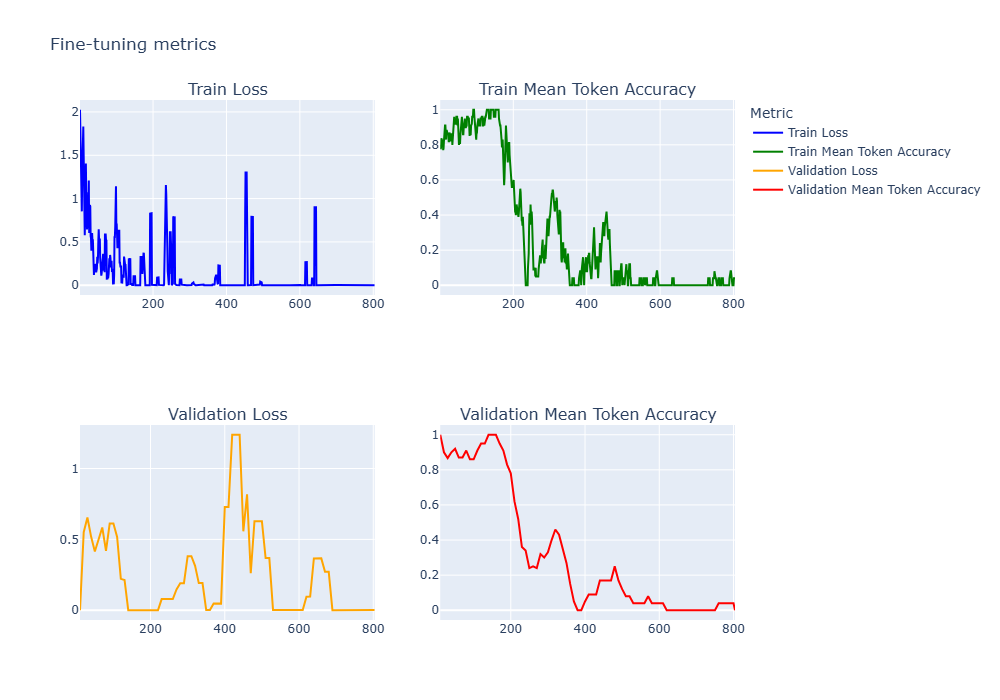
参考までに各メトリクスの説明は以下の通りです。
| メトリック | 説明 |
|---|---|
step |
トレーニングステップの数。トレーニングステップは、トレーニングデータのバッチに対する1回の前進と後退を表す |
train_loss / validation_loss
|
トレーニング/バリデーションバッチの損失 |
train_mean_token_accuracy |
トレーニングバッチ内のトークンがモデルによって正しく予測された割合 |
validation_mean_token_accuracy |
バリデーションバッチ内のトークンがモデルによって正しく予測された割合 |
モデルのデプロイ
ファインチューニングが完了したら、デプロイメントを作成します。ここからAzure Management APIを使うので、別のクライアントを用意。

デプロイメントの作成
コード例
from azure.mgmt.cognitiveservices import CognitiveServicesManagementClient
from azure.identity import DefaultAzureCredential
# Azure Management クライアントの初期化
credential = DefaultAzureCredential()
mgmt_client = CognitiveServicesManagementClient(
credential=credential,
subscription_id=config["subscription_id"]
)
# デプロイメントの作成(非同期操作)
deployment_name = "steel-defect-classifier-ft"
poller = mgmt_client.deployments.begin_create_or_update(
resource_group_name=config["rg_name"],
account_name=config["resource_name"],
deployment_name=deployment_name,
deployment={
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": fine_tuned_model_id,
"version": "1"
}
}
}
)
print("デプロイ開始...")
デプロイの完了を待つ
デプロイも非同期なので、完了を待ちます。
def wait_for_deployment(poller, timeout: int = 1800):
"""デプロイの完了を待つ"""
start_time = time.time()
while not poller.done():
if time.time() - start_time > timeout:
raise TimeoutError("デプロイがタイムアウトしました")
elapsed = int(time.time() - start_time)
print(f"デプロイ中... ({elapsed}秒経過)")
time.sleep(30)
result = poller.result()
print(f"デプロイ完了: {result.name}")
return result
deployment = wait_for_deployment(poller)
デプロイ状態の確認
デプロイが完了したら、ステータスを確認。
# デプロイメントの状態を取得
deployment_info = mgmt_client.deployments.get(
resource_group_name=config["rg_name"],
account_name=config["resource_name"],
deployment_name=deployment_name
)
print(f"デプロイ名: {deployment_info.name}")
print(f"モデル: {deployment_info.properties.model.name}")
print(f"状態: {deployment_info.properties.provisioning_state}")
provisioning_stateがSucceededになればOK。

デプロイが完了するとエンドポイントが使えるようになる

ファインチューニング前後で精度評価してみた
テストデータ58枚を使って、ベースラインモデル(素のGPT-4.1)とファインチューニング済みモデルを比較しました。
評価コード
まず、画像を分類する関数を用意。
コード例
def classify_image(image_path: str, deployment_name: str) -> str:
"""画像を分類して予測ラベルを返す"""
with open(image_path, "rb") as f:
base64_image = base64.b64encode(f.read()).decode("utf-8")
response = client.chat.completions.create(
model=deployment_name,
messages=[
{
"role": "system",
"content": "あなたは鋼材表面の欠陥を分類する専門家です。"
},
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{base64_image}"}
},
{
"type": "text",
"text": "この画像の欠陥を分類してください。"
}
]
}
],
max_tokens=50
)
return response.choices[0].message.content.strip().lower()
そして評価を実行。
コード例
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
import pandas as pd
def evaluate_model(test_data: list, deployment_name: str):
"""モデルを評価"""
results = []
for i, (image_path, true_label) in enumerate(test_data):
pred_label = classify_image(str(image_path), deployment_name)
results.append({
"image": image_path.name,
"true_label": true_label,
"predicted_label": pred_label,
"correct": true_label.lower() == pred_label
})
if (i + 1) % 10 == 0:
print(f"進捗: {i + 1}/{len(test_data)}")
df = pd.DataFrame(results)
accuracy = accuracy_score(df["true_label"], df["predicted_label"])
return df, accuracy
# ベースラインモデルの評価
print("=== ベースラインモデル (GPT-4.1) ===")
baseline_df, baseline_acc = evaluate_model(test_data, "gpt-4.1")
print(f"精度: {baseline_acc:.2%}")
# ファインチューニング済みモデルの評価
print("=== ファインチューニング済みモデル ===")
finetuned_df, finetuned_acc = evaluate_model(test_data, deployment_name)
print(f"精度: {finetuned_acc:.2%}")
結果
| モデル | 精度 |
|---|---|
| GPT-4.1 ベースライン | 53.45% |
| GPT-4.1 ファインチューニング済み | 96.55% |
+43ポイントの精度向上です。
正直、ベースラインの53%もそこそこすごいと思ったんですが、ファインチューニング後の96%は想像以上でした。何もドメイン知識を与えてないのに半分以上当てるGPT-4.1もすごいけど、ちゃんと学習させたら96%まで行くのかと。
混同行列
混同行列も見てみます。
そもそも混合行列って何?って人は以下の記事が参考になります。
混合行列の描画コード例
import matplotlib.pyplot as plt
from sklearn.metrics import ConfusionMatrixDisplay, confusion_matrix
def plot_confusion_matrix(df: pd.DataFrame, title: str, output_path: str):
"""混同行列をプロット"""
labels = sorted(df["true_label"].unique())
cm = confusion_matrix(df["true_label"], df["predicted_label"], labels=labels)
fig, ax = plt.subplots(figsize=(10, 8))
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=labels)
disp.plot(cmap="Blues", ax=ax, values_format="d")
plt.title(title)
plt.tight_layout()
plt.savefig(output_path, dpi=150)
plt.show()
plot_confusion_matrix(baseline_df, "Baseline Model", "confusion_matrix_baseline.png")
plot_confusion_matrix(finetuned_df, "Fine-tuned Model", "confusion_matrix_finetuned.png")
混同行列の結果

ベースライン(GPT-4.1)の混同行列 - 対角線以外にもかなり分散

ファインチューニング後の混同行列 - ほぼ対角線上に集中
ベースラインモデルは「patches」と「pitted_surface」あたりをよく間違えていました。確かに見た目似てるんですよね、どっちも表面がまだらになる感じで。
一方、ファインチューニング後はほぼ対角線上に揃っています。誤分類は58枚中2枚だけ。
詳細レポート
クラスごとの精度も確認。
# クラスごとのレポート
print(classification_report(
finetuned_df["true_label"],
finetuned_df["predicted_label"]
))
precision recall f1-score support
crazing 1.00 1.00 1.00 10
inclusion 1.00 1.00 1.00 10
patches 1.00 0.90 0.95 10
pitted_surface 0.91 1.00 0.95 10
rolled-in_scale 1.00 1.00 1.00 9
scratches 1.00 1.00 1.00 9
accuracy 0.97 58
macro avg 0.99 0.98 0.98 58
weighted avg 0.97 0.97 0.97 58
ほとんどのクラスでF1スコアが1.0。patchesとpitted_surfaceで1件ずつ間違えてるくらいでした。
Microsoft技術ブログの事例(Stanford Dogs)との比較
MicrosoftのDev Blogで公開されているVision Fine-tuningの事例(犬種分類タスク)と比較してみます↓
| 項目 | Stanford Dogs(ブログ事例) | NEU-DET(今回) |
|---|---|---|
| タスク | 犬種分類(120クラス) | 鋼材欠陥分類(6クラス) |
| ベースモデル | GPT-4o (2024-08-06) | GPT-4.1 (2025-04-14) |
| 訓練データ | 4,800枚(40枚×120クラス) | 1,440枚 |
| テストデータ | 600枚 | 58枚 |
| ベースライン精度 | 73.67% | 53.45% |
| FT後精度 | 82.67% | 96.55% |
| 精度向上 | +9ポイント | +43ポイント |
| レイテンシ改善 | 9.6%高速化 | 未計測 |
今回のNEU-DETの方が精度向上幅が大きいのは、クラス数が少なく(6クラス vs 120クラス)タスクが比較的シンプルだったこと、産業用途の画像はWebで学習されにくくファインチューニングの効果が出やすかったこと、が理由として考えられます。
この事例のコードはGitHubで公開されています:
ハマったポイント
実際にやってみて、いくつかハマったポイントがあったので共有します。
1. リージョンの罠
最初、手持ちのEast USリソースでやろうとして「Vision Fine-tuningに対応してません」と怒られました。公式ドキュメントをちゃんと読みましょう(自戒)。
Microsoft Foundry内のAzure OpenAIのモデル対応表は結構更新されるので、始める前に確認しておくといいです。
2. デプロイの待ち時間
ファインチューニング自体は2〜4時間で終わりますが、その後のデプロイにも10〜15分くらいかかります。ステータスが「Succeeded」になるまで待つコードを書いておくと便利です。
# デプロイ完了を待つ
import time
while True:
deployment_info = mgmt_client.deployments.get(
resource_group_name=config["rg_name"],
account_name=config["resource_name"],
deployment_name=deployment_name
)
state = deployment_info.properties.provisioning_state
print(f"状態: {state}")
if state == "Succeeded":
print("デプロイ完了!")
break
elif state == "Failed":
raise Exception("デプロイ失敗")
time.sleep(30)
3. Azure CLIの認証
DefaultAzureCredentialを使うときに、Azure CLIでログインしてないとエラーになります。
# 先にログインしておく
az login
# サブスクリプションを確認・設定
az account show
az account set --subscription "your-subscription-id"
4. 15日ルール
ファインチューニングしたモデルのデプロイは、15日以上非アクティブ(APIが呼ばれない)状態が続くと自動削除されます。検証用に作ったデプロイが消えてて焦りました。
ただし、モデル自体は削除されません。デプロイが消えても、モデルは残っているので再デプロイすれば使えます。
これ、公式ドキュメントにもちゃんと書いてあるんですが見落としてました。
コストについて
Vision Fine-tuningのコストは主に3つ:
- トレーニング費用 - 学習にかかる計算コスト
- ホスティング費用 - デプロイしているモデルの維持費(時間課金)
- 推論費用 - 実際にAPIを叩いた分
今回かかったコスト
今回の検証では、Developerティアを使ったのでトレーニング費用は抑えられました。
| 項目 | 費用 |
|---|---|
| トレーニング(~1,400枚、3エポック) | 約$20〜30 |
| ホスティング(数時間) | 約$5〜10 |
| 推論(評価58枚×2回) | 約$2〜3 |
正確な金額はAzureポータルのコスト分析で確認できます。
API課金は本当に高いのか?具体的に計算してみた
公式料金表(2025年12月時点)から、GPT-4.1の推論コストを計算してみます:
| デプロイタイプ | 入力(/1Mトークン) | 出力(/1Mトークン) |
|---|---|---|
| Global | $2.00 | $8.00 |
| Regional | $2.20 | $8.80 |
| Data Zone | $2.20 | $8.80 |
画像1枚あたりのトークン数は、解像度によって変わりますが、今回のNEU-DET画像(200×200ピクセル程度)だと約85〜170トークン程度。テキストも含めて1リクエストあたり約300トークン(入力)、出力は「scratches」みたいに短いので約10トークン程度。
月間コストのシミュレーション
| 月間推論回数 | 入力トークン | 出力トークン | 月額コスト |
|---|---|---|---|
| 100回 | 30,000 | 1,000 | 約$0.07 |
| 1,000回 | 300,000 | 10,000 | 約$0.68 |
| 10,000回 | 3,000,000 | 100,000 | 約$6.80 |
| 100,000回 | 30,000,000 | 1,000,000 | 約$68 |
| 1,000,000回 | 300,000,000 | 10,000,000 | 約$680 |
月1万回程度なら$7弱。これを「高い」と見るか「安い」と見るかはユースケース次第です。
「エグい」ケースとは
本当に課金がエグくなるのは:
- リアルタイム大量処理: 工場のラインで毎秒10枚 × 24時間 = 月2,600万回 → 約$17,000/月
- 高解像度画像: 4K画像(~1500トークン)を大量に処理
- ホスティング費用の放置: $1.7/時間 × 24時間 × 30日 = $1,224/月
PoCや低頻度の本番運用なら問題ないが、製造ラインでリアルタイム検査をやるなら確かにエグい。そういう用途にはCNN系モデルを自前デプロイした方がいいです。
ホスティング費用の落とし穴
推論費用よりも注意すべきはホスティング費用です。
- GPT-4.1ファインチューニングモデル: $1.70/時間
- 1日つけっぱなし: $40.80
- 1ヶ月つけっぱなし: $1,224
検証後にデプロイを消し忘れると、月末に請求書を見て青ざめることになります(経験談)。
ホスティング費用に注意
ファインチューニングしたモデルはデプロイしている間、時間課金が発生します。検証が終わったらデプロイを削除しておかないと、地味にお金がかかります。
# デプロイの削除
poller = mgmt_client.deployments.begin_delete(
resource_group_name=config["rg_name"],
account_name=config["resource_name"],
deployment_name=deployment_name
)
poller.result() # 完了を待つ
print("デプロイを削除しました")
料金表
公式の料金表はこちら。リージョンやティアによって変わるので要確認。
従来のディープラーニングとの違い
「画像分類ならResNetとかEfficientNet使えばいいじゃん」という声が聞こえてきそうなので、違いを整理しておきます。
ResNetは古い?2025年の画像分類モデル事情
2015年に発表されたResNetは確かに古いモデルですが、いまだに現役で使われています。理由はシンプルで「軽量で高速で十分な精度が出る」から。
ただ、2025年現在の最新モデルと比較すると:
| モデル | 発表年 | 特徴 | ImageNet精度 |
|---|---|---|---|
| ResNet-50 | 2015 | 残差接続の元祖、今も産業界で現役 | ~76% |
| EfficientNetV2 | 2021 | 複合スケーリングの進化版、高速 | ~85% |
| Vision Transformer (ViT) | 2020 | 画像をパッチ分割してTransformer適用 | ~88% |
| Swin Transformer | 2021 | ViTの計算効率を改善、物体検出にも強い | ~87% |
| ConvNeXt V2 | 2023 | CNNをViT的に再設計、ViTに匹敵 | ~88% |
| EVA-02 | 2023 | 大規模事前学習ViT | ~90% |
「ResNetは古い」というより「ResNetで十分なタスクも多い」が正確です。NEU-DETのような産業用途では、ResNet-50やEfficientNet-B0〜B3くらいで十分な精度が出ることが多いです。
Vision Transformer系は精度は高いですが、学習にGPUメモリを食うので、手元のPCでサクッと試すにはCNN系の方が楽だったりします。
今回のタスクをこれらのモデルでやるなら
ResNet、EfficientNet、Vision Transformerなどを使う場合、こんな流れになります:
- PyTorch / TensorFlowの環境構築
- 事前学習済みモデルのダウンロード
- 画像の前処理パイプライン作成(リサイズ、正規化、データ拡張)
- 最終層の差し替えとファインチューニング
- GPUマシンで数時間〜数日学習
- 推論サーバーのデプロイ(FastAPI + Docker + Kubernetesとか)
- モデルのバージョン管理
NEU-DETデータセットは1,800枚しかないので、データ拡張をガッツリやらないと過学習しそうです。回転、反転、色調変換、Cutoutとか。
Vision Fine-tuningでやるなら
- JSONLファイルを作る(画像をBase64エンコード)
- Azure OpenAI APIにアップロード
- ジョブを投げて待つ
- デプロイボタンをポチ
- APIを叩く
以上。GPU環境もDockerも不要。
比較表
| CNN系モデル | Vision Fine-tuning | |
|---|---|---|
| 必要なデータ量 | 数千〜数万枚(少ないとデータ拡張必須) | 数百〜数千枚で動く |
| 環境構築 | GPU環境、PyTorch/TensorFlow、CUDAなど | Python + openaiライブラリのみ |
| 学習時間 | 数時間〜数日(GPUスペック次第) | 数時間(待ってるだけ) |
| 推論コスト | 安い(自前サーバーなら電気代のみ) | API課金(1リクエストごと) |
| 推論速度 | 速い(数十ms) | 遅め(数秒) |
| 説明可能性 | GradCAMとかで可視化はできる | 「なぜ?」と聞けば答えてくれる |
| デプロイ | Kubernetes、Docker、MLflowなど | ポータルでポチ |
| オフライン動作 | ○ | × |
| エッジデバイス | ○(ONNX、TensorRT等で最適化) | × |
どっちを使うべき?
結論から言うと、ケースバイケースです。ただ、いくつか判断軸があります。
Vision Fine-tuningが向いてるのは:PoCで素早く精度を確認したいとき、データが数百〜数千枚しかないとき、GPU環境を用意するのが面倒なとき、推論頻度が低い(月に数百〜数千回程度)とき、予測理由をテキストで説明してほしいとき、あたり。
CNN系モデルが向いてるのは:大量推論が必要(毎秒数百リクエストとか)なとき、推論コストを最小化したいとき、エッジデバイス(Jetson、ラズパイ等)で動かしたいとき、オフライン環境で使いたいとき、レイテンシが重要(リアルタイム検査など)なとき。
今回みたいな「とりあえず精度出るか試したい」というPoCには、Vision Fine-tuningがかなり楽でした。環境構築で消耗せずに、本質的な検証に集中できる。
逆に本番環境で毎秒何百枚も処理するなら、CNN系モデルをちゃんと作り込んだ方がいいと思います。API課金がエグいことになるので。
精度はどっちが上?
これは正直、データとタスクによります。
今回のタスクだと、CNN系モデル(ResNet50とか)でもちゃんとデータ拡張してチューニングすれば90%以上は出せると思います。NEU-DETは結構研究されてるデータセットなので、先行研究でも高い精度が報告されてます。
Vision Fine-tuningの強みは「少ないデータでも高精度が出やすい」ことと「すぐに試せる」こと。今回96%出たのは、GPT-4.1の事前学習で大量の画像を見てるおかげかなと。
RAG・AIエージェントへの応用可能性
ここからは少し妄想も入りますが、今回の画像ファインチューニングがRAGやAIエージェントにも使えそうだなと思ったので書いておきます。
図表を含むドキュメントのRAG
RAGで「PDFから情報を取ってきて回答させる」みたいなことをやるとき、図表が含まれてると結構困ります。素のVLM(GPT-4o、GPT-4.1など)でも図表は読めますが、ドメイン固有の図表だと精度が微妙なことがあります。
たとえば、製造業の設備図面とか、医療画像のレポートとか、特殊な記法で書かれたグラフとか。こういう「見方を知らないと読めない」系の画像は、ファインチューニングで精度を上げられる可能性があります。
RAGの文脈で言うと:
- PDFから画像を抽出
- ファインチューニング済みVLMで画像を解釈
- 解釈結果をテキストとしてベクトルDBに格納
- 質問に対してテキスト検索 + 回答生成
みたいな流れ。画像をそのままベクトル化するよりも、一度テキストに変換した方が検索精度が上がるケースもありそう。
AIエージェントのツールとして
最近流行りのAIエージェントの文脈でも使えそうです。
エージェントが「画像を見て判断する」ステップが必要なワークフロー、たとえば:
- 製造ラインの画像を見て、不良品かどうか判定
- 監視カメラの画像を見て、異常検知
- 書類の画像を見て、必要な情報を抽出
こういうタスクで「素のVLMでは精度が出ない」場合に、ファインチューニング済みモデルをツールとして呼び出せると便利。
Microsoft Foundry Agentsとかと組み合わせると面白そう。
構造化出力との組み合わせ
GPT-4.1は構造化出力(Structured Outputs)をサポートしてるので、画像分類の結果をJSONで返すこともできます。
from pydantic import BaseModel
class DefectClassification(BaseModel):
defect_type: str
confidence: str
reasoning: str
response = client.chat.completions.create(
model=deployment_name,
messages=[...],
response_format={"type": "json_schema", "json_schema": {...}}
)
エージェントのワークフローに組み込むとき、構造化されたJSONで返ってくると後段の処理が楽になります。
まとめ
今回やったことを振り返ります。
- GPT-4.1 VisionのFine-tuningで53% → 96%まで精度向上
- 約1,400枚の訓練データ、3エポックで学習
- リージョン制限(Sweden Central / North Central US)に注意
- ドメイン特化の画像分類には効果大
- 環境構築の手間がほぼゼロなのが最高
プロンプトエンジニアリングだけでは限界がある画像分類タスクに対して、Fine-tuningは有効な選択肢だと感じました。「ちょっと試してみるか」が本当にすぐできる。
製造業の外観検査とか医療画像の分類みたいな、「ドメイン知識が必要で、でもデータ量は多くない」タスクには特に向いてると思います。RAGで図表を含むドキュメントを扱うときとか、AIエージェントに画像判断をさせるときにも使えそうな予感。
2025年12月時点の最新情報
この記事を書いている2025年12月4日時点での情報です。Microsoft Foundryは頻繁にアップデートされるので、最新情報は公式ドキュメントを確認してください。
名称変更について
2025年11月の Microsoft Ignite で、Azure AI Foundry は Microsoft Foundry に名称変更されました。ポータルのUIやドキュメントは順次更新されており、旧名称と新名称が混在している期間があります。
ポータルは以下の2種類があります:
- Microsoft Foundry(新): シンプルなUIでエージェントアプリケーションの構築に特化。Foundryプロジェクトのみ表示
- Microsoft Foundry(クラシック): Azure OpenAIリソース、ハブベースのプロジェクト、Foundryプロジェクトなど複数のリソースタイプに対応
Microsoft Foundryのファインチューニング機能を使う場合は、上記どちらのUIでも使うことができます。
最新のモデル・リージョン対応状況
- Vision Fine-tuning対応モデル:
gpt-4o (2024-08-06)とgpt-4.1 (2025-04-14) - 対応リージョン:
2025年12月4日時点の Vision ファインチューニング対応モデル:
| モデル | リージョン | Vision対応 | 備考 |
|---|---|---|---|
| gpt-4o (2024-08-06) | East US2, North Central US, Sweden Central | ✅ | テキスト+画像 → テキスト |
| gpt-4o-mini (2024-07-18) | North Central US, Sweden Central | ❌ | テキストのみ |
| gpt-4.1 (2025-04-14) | North Central US, Sweden Central | ✅ | テキスト+画像 → テキスト |
| gpt-4.1-mini (2025-04-14) | North Central US, Sweden Central | ❌ | テキストのみ |
| gpt-4.1-nano (2025-04-14) | North Central US, Sweden Central | ❌ | テキストのみ |
| o4-mini (2025-04-16) | East US2, Sweden Central | ❌ | 推論モデル(RFT対応) |
- GPT-4.1のコンテキスト長: 最大1,047,576トークン(約100万トークン)
- トレーニング層: Standard、Global Standard、Developer の3種類
| ティア | 説明 | 特徴 |
|---|---|---|
| Standard | 専用キャパシティ | 予測可能なパフォーマンスとSLA、本番ワークロード向け |
| Global Standard | グローバル分散 | より手頃な価格、データレジデンシーなし |
| Developer | アイドルキャパシティ使用 | コスト効率重視、実験・探索向け(ジョブが中断される可能性あり) |
今後試したいこと
- マルチラベル分類(1枚の画像に複数の欠陥がある場合)
- 物体検出との組み合わせ(欠陥の位置も特定したい)
- Few-shot学習との比較(Fine-tuningなしでどこまで行けるか)
- GPT-4o (2024-08-06) との精度比較
- RAGパイプラインでの画像解釈への適用
- Microsoft Foundry Agentsとの統合
コードの全体
コードはGitHubで公開しています。Jupyter Notebookで一通り動かせるようになってます。
質問やフィードバックがあればIssueやコメントでお気軽にどうぞ。
ここまでお読みいただきありがとうございました!
参考資料
Fine-tuning関連
モデル・リージョン情報
データセット
Vision Fine-tuning発表
- Introducing vision to the fine-tuning API (OpenAI)
- Announcing new fine-tuning capabilities with images on Azure OpenAI Service
ブログ記事・チュートリアル
- A Developer's Guide to Fine-Tuning GPT-4o for Image Classification
- Image Breed Classification FT Demo (GitHub)
- gpt-4o-image-classification-finetuning (GitHub)
RAG・エージェント関連
料金
免責事項
本記事は情報提供を目的としており、2025年12月4日時点の情報に基づいています。本記事について、内容の正確性・完全性は保証されず、誤りを含む可能性があります。公式ドキュメントで最新情報をご確認ください。記事内のコードサンプルは自己責任でご利用ください。APIキー等の機密情報は適切に管理し、公開環境での使用時はセキュリティに十分ご注意ください。本記事内容の利用によって生じたいかなる損害(サービスの中断、データ損失、営業損失等を含む)についても、著者は一切の責任を負いません。本記事に掲載されている各社製品・サービスは各社の利用規約に従ってご利用ください。

Discussion