この記事は MICIN Advent Calendar 2023 の24日目の記事です。
前回はSaneさんの「データ基盤チームで社内インターンをやってみて」でした。
はじめに
abekohです。MICINでMiROHAの開発をしております。
本記事では、書籍等から得た設計・実装パターンの知識や、実際にプロダクト開発で試して得られた経験などから編み出した、開発効率向上のためのWeb API開発のプラクティスを紹介します。
筆者が関わっているMiROHAは治験の業務支援を取り扱うプロダクトです。MiROHAの開発における特性として、以下のようなものが挙げられます。
- 治験業務に関するドメインが特有で複雑
- 前例が少なく、MVPを追求中。プロダクトのアプローチが頻繁に変わる
- 外部品質は高い水準が求められる
これらの特性を意識して開発を促進させるために日々試行錯誤しております。
複雑なドメインに対する設計・実装のアプローチとして、よくDDDやオブジェクト指向を活用した事例が話題になります。これらをきちんと理解せず、見様見真似すると余計混乱していき、破綻した実装になってしまいます。筆者もとりあえずで手を出し、多くの手痛い失敗をしてきました。
過去の失敗を反省し、改めてドメイン・チームメンバー・言語・規模感のことを考えながら、より有用な実装を模索してきました。そのプラクティスの中でも特に上手くドライブした、かつ他所ではあまり見ないものをまとめてみました。万事に適用できるプラクティスではないかもしれませんが、参考になれば幸いです。
前提
- 対象は基本Web APIサーバ
- 言語はGoを想定
- Goという文法が素朴な言語の特性を活かすか、という観点が含まれます
- DDD用語を断りなく使います
- パフォーマンス・スケールに対してはやや甘めの考えです
- プロダクトの特性上、爆発的なスケールは不要という判断のもとで開発しております
- 現時点では開発者3-4人程度、モノリスなアーキテクチャです
プラクティス集
データとコードの分離を心がける
オブジェクト指向プログラミングに反して、「データ・コードを同じモデルに詰めることを考えず、データ・コードは別々に定義し責務を分離していったほうが理解しやすく柔軟だ」という考え方があります。データ指向プログラミング(DOP, Data-Oriented Programming)の原則のひとつがまさにそれです。
原則 #1
コードをデータから切り離し、コードが関数に含まれるようにする。
関数の振る舞いは、関数のコンテキストに何らかの形でカプセル化されるデータには依存しない。
(『データ指向プログラミング』p.393 付録A.1)
この考え方を「エンティティの変更操作」に適用してみます。
エンティティを定義してそれに振る舞わせて(メソッドを使って)処理を行うのではなく、エンティティはあくまでデータ、振る舞いは関数にして引数として受け取るようにコーディングしていくきます。ポイントとしては「ミュータブルな振る舞い」を使わないのはもちろん、「イミュータブルな振る舞い」も避ける方針にすべきだと考えております。
type User struct {
ID int
Name string
}
// ①こうではなく
func (*u User) UpdateNameV1(newName string) {
u.Name = newName
}
// user := User{Name: "Alice"}
// user.UpdateNameV1("Bob")
// ②こうでもなく
func (u User) UpdateNameV2(newName string) User {
return User{
ID: u.ID
Name: newName
}
}
// user := User{Name: "Alice"}
// updatedUser := u.UpdateNameV2("Bob")
// ③こう
func UpdateNameV3(u User, newName string) User {
return User {
ID: u.ID
Name: newName
}
}
// user := User{Name: "Alice"}
// updatedUser := UpdateNameV3(user, "Bob")
①はミュータブルな振る舞いの例です。同じエンティティでも状態がどうなっているのか見えにくくなり、避けたくなるのは必然かと思います。
②はイミュータブルな振る舞いの例です。イミュータブルに新しいUserを生成できますが、エンティティに紐づいたメソッドを利用しています。DOP本の文脈では原則に違反しています。エンティティに近いところにロジックがあるので見つけやすいですし、見方によっては③と同じく2引数を受け取っているだけ、とも読めて問題ないと思われるかもしれません。
しかし、関連するエンティティが増えてくると「どこに処理内容置いていたっけ…」と迷います。また、どのエンティティに振る舞いを置くのもしっくりしない例が出てくることもあります。
そのようなケースでDDDでの解決策として、ドメインサービス(サービス)を使おうというプラクティスがあります。
ドメインにおける重要なプロセスや変換処理が、エンティティや値オブジェクトの自然な責務ではない場合、その操作は、サービスとして宣言される独立したインタフェースとしてモデルに追加すること。モデルの言語を用いてインタフェースを定義し、操作名が必ずユビキタス言語の一部になるようにすること。サービスには状態を持たせないこと。
(『エリック・エヴァンスのドメイン駆動設計』p.105 第5章 ソフトウェアで表現されたモデル / サービス(SERVICES) )
ドメインサービスを使えるのは、これらの場合だ。
- 重要なビジネスロジックを実行する
- ドメインオブジェクトを、ひとつの構成から別の構成に変換する
- 複数のドメインオブジェクトからの入力にもとづいて、値を算出する
(『実践ドメイン駆動設計』 p.256 第7章 サービス)
これを読むだけでも理解しにくいですし、実際にドメインが複雑なプロダクトで試してみてもわかるのですが、ドメインサービスを使うかどうかの判断は難しいです。さらに、ビジネスロジックに関するコードが分散してしまい見通しが悪くなってしまう可能性があります。熟練度の異なるメンバー複数人が関わるプロジェクトであればなおさらです。
そのような事態を防ぐためにも、 最初から③の「ステートレスな関数」を最初から選択するが良いと筆者は考えます。ビジネスロジックに関するコードを一箇所にまとめられて整理しやすくなるのはもちろん、純粋関数なのでテストも書きやすくなります。[1]
ここまで書くと「エンティティのメソッドは絶対禁止」という思想に思われるかもですが、エンティティ変更の操作に関係ない、エンティティの状態を表すだけのものについてはメソッドが適当です。
func (u User) String() string {
return fmt.Sprinf("%d:%s", u.ID, u.Name)
}
func (u User) IsLegacy() bool {
return u.ID < 1000
}
結局判断しないといけない箇所は残ってしまいますが、「とにかくモデルに振る舞わせよう!」と頑張るのではなく、 「基本操作はステートレスに、ただモデルの状態くらいはモデルに教えてほしいな」 というスタンスでいければよいと筆者は考えます。
CQRSを採用する
CQRSを取り入れることで、書き込み系・読み込み系それぞれのユースケースに特化した実装が書きやすくなります。
CQRSとはCommand Query Responsibility Segregationのことで、日本語に訳すと「コマンドクエリ責務分離」です。
CQRSは、Bertrand Meyer氏が考案した原則であるCQS(Command Query Separation、コマンドとクエリの分離)が元となっています。
CQSの内容はざっくり、
- Query: 結果を返却するだけ、状態は変更しない (副作用を起こさない)
- Command: 状態の変更を行うが、結果の返却は行わない (返り値はvoid)
というもの。これをGreg Young氏がアーキテクチャパターンとして落とし込んだものがCQRSとなります。
CQRSを導入しない・ドメインモデルを扱う一般的なREST APIは下図のイメージです。
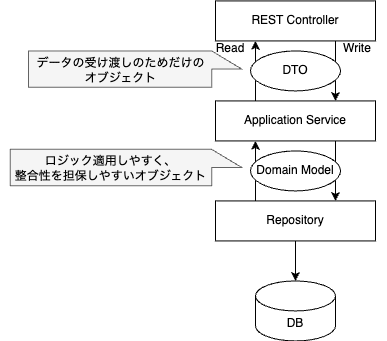
一般的なREST APIの構成
このアーキテクチャで実装を進めていくと、読み込み処理関して次のような課題が発生します。
- DTOの中身はDBの内容とほぼ一緒なのに毎回ドメインモデルを経由しなければならず、実装面でもパフォーマンス面でもコストがかかる
- ある画面で必要な値をすべて取得するのに、たくさんのドメインモデルを用意しないといけない・複数のGET APIを叩かないといけない
こうしてみると、ドメインモデルの経由が大きなネックになっているように思われます。そもそもドメインモデルは読み込み処理に必要なのでしょうか? これに関して、『単体テストの考え方/使い方』では次のように述べられています。
ここで心に留めておいてほしいことは、読み込みに関してドメイン・モデルは必要ない、ということです。ドメイン・モデルで達成しようとしていることの1つはカプセル化です。(中略)カプセル化とは、どのようなデータの変更が行われていてもデータ整合性が保たれるようにするための手法です。そのため、データの変更がないのであれば、カプセル化をする必要もなくなります。実際、データの読み込みにおいては、NHibernateやEntity Frameworkなどの本格的なO/Rマッパーは必要なく、普通のSQL文を使ったほうが不必要な抽象化層を経由せずに済むため、パフォーマンス的に優れていることになります。
(『単体テストの考え方/使い方』p.362 第10章 読み込みに対してテストをすべきか?)
この書籍でははっきり不必要だと明言されています。そして、読み込み時は抽象化層を経由しないほうがメリットが大きいと言及されております。この考え方がCQRSがよいとされる根拠のひとつとなります。
では、先ほどのREST APIをCQRS化してみた例を見てみましょう。

CQRSを導入したREST APIの構成
読み込みについて、Query ServiceでDTOを構築して値を返す構成となってます。Query Service内ではSQL文を直接実行するなどして、整合性を気にしない読み取りやすさを重視した実装になります。
書き込みについては従来どおりです。こちらは整合性を重視するため、集約の構築・バリデーションなどを行いやすいドメインモデルを通じた処理になります。
また、CQRSの文脈では「データベースを書き込み用・読み込み用に分けよう」「Event Sourcingとセットで考えよう」と言われますが、必ずしも合わせて使う必要はありません。パフォーマンスがプロダクトの特性として求められ、それに対するアプローチの1つとして採用するのであれば良いのですが、「同じデータベースで」「Web APIのみしかない」場合でもCQRSは十分有効です。下図でいうと、左上のパターンでも場合によっては十分です。

CQRSにおけるDB構成の様々な例
特に、「読み取り処理がなんだか冗長になるな…」という感覚がある場合は読み取り用にモデルを分けてみるのが有効に働くかもしれません。ぜひ検討してみてください。
必要にならない限り詳細を隠蔽しない
Clean Architectureなどの文脈でよく話題になる「詳細を抽象化して隠蔽、付け替え簡単にする」考え方について、その方針の採用は注意が必要です。
基本的に、次のようなケース以外では詳細を隠蔽する必要はないという考えで設計・実装しています。
- 同じインタフェースで複数のDB・外部コンポーネントに接続がある場合
- 開発途中でDB・外部コンポーネントが途中で変更になる可能性が大きくありえる場合
- 統合テスト(次の項目で解説)において、本物の再現が難しい場合はモック対象にするために抽象化
1つ目はよくあるケースだと思います。ドメインレベルでは同じ扱いのものを、複数の外部システムに連携する場合には隠蔽は有効です。
2つ目について、開発初期に「DB詳細は未決定だから一旦インタフェース定義だけで進めよう」「スケールすることが目に見えているから抽象化しておこう」ということが少なからずあるかもしれません。逆にそういった議論がなく、しばらくはDB・外部コンポーネントの置き換えがなさそうであれば隠蔽はかえってコストが高くつきます。
3つ目はやむを得ずのパターンです。対象が制御下にない外部APIや大掛かりなプロセスであれば隠蔽し、モックを差し込みやすい形にすることがあります。モック化するかどうかの判断は『単体テストの考え方/使い方』にて詳細に解説されており、筆者はこの考え方に従っております。ここでは端的に表した一文のみ引用しておきます。
システム内コミュニケーションの確認にモックを使うことはテストを壊れやすくすることに繋がる。モックを使ってもよいのはシステム間コミュニケーション(つまり、テスト対象のアプリケーションを超えるコミュニケーション)の場合で、かつ、その個ミュウ縫いケーションによる副作用が外部から観察できる場合だけである。
(『単体テストの考え方/使い方』p.166 第5章 まとめ)
上記3点に当てはまらない場合は基本的に隠蔽はせず、アプリケーション層でも詳細を扱ってよいものとすることで無駄な複雑さを防ぎ、効率の良いちょうどよい開発体験になると筆者は考えます。
単体テストでロジック網羅を試みつつ、統合テストで全体をカバーする
ここでの単体テスト・統合テストの定義について。単体テストは次の条件すべてを備えるもの、1つでも満たさないものは統合テストとします。
- 1単位の振る舞いを検証すること
- 実行時間が短いこと
- 他のテスト・ケースから隔離された状態で実行されること
(『単体テストの考え方/使い方』p.262 第8章 統合テストとは?)
下図のように、ドメインに関することは単体テスト、コントローラを通してAPIからDBまで通してのテストを統合テストで書くという方針で運用するとよいでしょう。

『単体テストの考え方/使い方』p.263 図8.1
「データとコードの分離を心がける」の項目で述べたとおり、ビジネスロジックはステートレスな関数のみで表しています。これらは正常系・異常系ともに網羅性を意識してユニットテストを書きましょう。
ドメインモデリングを緻密に行い、ロジックもすべてドメイン層に置いてるからそこさえクリアすれば完璧だ…。そう思いたいところですが、現実問題そこまでの理想状態にはできません。
コントローラレベルでバリデーションが発生したり、重複・外部キー制約などをDBレベルで担保するほうが都合がよく、それらに任せることもあります。イメージとしてはこのような感じ。[2]

ドメインに関する情報は完全に閉じ込めることは難しいため、他のレイヤーに入りこむことを許容する
これらのテストもユニットテストでカバーするという考えもありますが、テストの前提構築が難しく手間がかかることがあります。こういった場合も踏まえて、統合テストは 「正常系パターンに加えて、ドメインのユニットテストでカバーできない箇所」 を書くのがちょうどよい塩梅かと考えます。
API・DBスキーマに関するものを二重管理しない
API・DBのスキーマは異なるシステムとの結合に用いるために、コードに加えて別の表現が必要になります。それらを二重で修正する必要がある状態にならないようにしましょう。単純に書く手間がかかる・時間が無駄になるのはもちろん、修正忘れによるミスも頻発してしまいます。
『達人プログラマー』でも次のように言及されています。
あなたがデータベースアプリケーション開発をしているのであれば、既に2つの環境――すなわち、データベース環境とプログラミング言語環境に直面しているはずです。ここでスキーマに基づいて、特定のデータベーステーブルのレイアウトと同じ低レベル構造の定義を行う必要が出てきたと考えてください。こういったものを直接手作業でコーディングすることも可能ですが、それではDRY原則に反します。スキーマの知識が2ヶ所で表現されてしまうわけです。つまり、スキーマが変更された時に、対応しているコードを変更するということを記憶しておかなければなりません。また、テーブルからカラムが削除されたのに大元のコードの変更を忘れていると、コンパイルエラーにさえならない場合もあるのです。そして、それが発覚するのはテストでおかしな結果が出てから(あるいはユーザーからの呼び出しがあってから)なのです。
(『新装版 達人プログラマー 職人から名匠への道』[3] 20. コードジェネレータ)
解決策のひとつとして、コード生成ツールを利用することが挙げられます。スキーマ→コード(Schema First)、コード→スキーマ(Code First)とアプローチは言語・ツールによって様々ですが、いずれにしても一元管理を徹底することに役立ちます。
Goにおいては、REST APIならoapi-codegen、GraphQLならgqlgenが有名です。またDBのモデル生成にはsqlc、SQLBoilerなど様々な選択肢が存在します。自身の環境にあったものを選定しましょう。
言語によってはコード生成ではなく、フレームワークに頼ることで上記の課題が解決する場合もあります。その場合はフレームワークに存分に頼りましょう。
AIに理解してもらいやすいコーディングを心がける
2023年、今年は新興AIツールの話題に尽きない1年でした。筆者もGitHub Copilot、ChatGPTなしの開発はもう考えられない日々を過ごしております。
特にGitHub Copilotを使いこなすためにですが、実装のやり方も 「AIにいい感じに補完してもらえるように」 と意識した開発がより効率的だと考えるようになりました。具体的には以下に挙げるような点になります。
ファイルを分割しすぎない
ファイル分割は張り切って行わず、1ファイルに継ぎ足しで書いたほうがAIにとって理解しやすく、より補完が正確になる印象です。
例えばVSCode拡張の場合は開いたタブから学習されるとされていますが、分割したファイルが多いと多くのファイルを開く必要があり、人間にとって操作が煩雑になってしまいます。特にGoの場合は同じディレクトリであればファイル分割しようとしまいと扱いは変わらないので、「行数が長い」という理由だけで分割しないのが賢明です。
命名規則の統一性を意識
読みやすいコードを書くための基本的な原則でもありますが、命名規則はよりいっそう大切になるようにしています。
例えばドメインのビジネスロジックの関数を置くファイルでは、入力の型・出力の型・関数名・引数名の命名規則が統一的になるように徹底しております。
以下のコードはその一例です。入出力の型を必ず作成・Input,Outputを後置となる名前にし、関数名・引数名も一律した形式となっています。
type (
CreateUserInput struct {
}
CreateUserOutput struct {
}
)
func CreateUser(ctx context.Context, inp CreateInput) (CreateUserOutput, error) {
// TODO: implement
return CreateUserOutput{}, nil
}
type (
UpdateUserInput struct {
}
UpdateUserOutput struct {
}
)
func UpdateUser(ctx context.Context, inp UpdateInput) (UpdateUserOutput, error) {
// TODO: implement
return UpdateUserOutput{}, nil
}
最新情報をキャッチアップ
これも当たり前な観点ですが、AIツールの最新情報は追いかける・可能ならすぐに試すことを心がけてます。
すでにGitHubがCopilot Workspaceを発表しているように、2024年はさらに便利なツールが登場することが予想されます。常にキャッチアップを意識し、さらなる効率向上のために導入を早急に検討していきたいところです。
おわりに
以上、オムニバス形式で開発効率向上のためのプラクティスを紹介してみました。どこでも使えるプラクティスとは言えないかもしれませんが、参考にしていただければ幸いです。
この他にも追求しているプラクティスもありますが、まとめきることが難しく今回は見送りました。またの機会に紹介していけたらと思います。
また、文中で引用した書籍はいずれも得られることが多い内容となっております。特に何度も引用した『単体テストの考え方/使い方』は、表題のテストに関してはもちろん、筆者の設計・実装に対する考えが大きく変わる一冊でした。気になった方はぜひ読んでみてください。
MICINではメンバーを大募集しています。
「とりあえず話を聞いてみたい」でも大歓迎ですので、お気軽にご応募ください!
-
純粋関数にしてテストを書きやすくしたという事例について、弊社のメンバーの記事も参考になりますのでぜひご覧ください。
DBの状態に依存したロジックを純粋関数にしたらテストしやすくなった ↩︎ -
より詳しく知りたい方は、ぜひ「DDDトリレンマ」問題の記事を読んでみてください。
Domain model purity vs. domain model completeness (DDD Trilemma) · Enterprise Craftsmanship
https://twitter.com/kawasima/status/1617405025567014917) ↩︎ -
2023年現在発行されている『第2版』では「コードジェネレータ」の項目が削除されておりました。削除された理由は不明ですが、このプラクティスは(特にGoにおいて)現在も有用だと筆者は考えます。 ↩︎

Discussion