この記事は MICIN Advent Calendar 2023 の17日目の記事です。
前回は小泉さんの「エンジニアがfigmaに入門してデザインを加速させる」でした。
MICINのDTx事業部でアプリケーションエンジニアをやっている佐藤です。直近で、認知行動療法を行うアプリケーションの開発を担当していました[1]。本稿では、そのテストコードの実装の際に考えたことを書きます。
重要なケースを網羅するテストコードを書きたい
今回のアプリケーションでは、考慮すべき状態の数が多く、その状態に基づく画面表示の条件分岐も多いため、仕様を整理するだけで大変でした。これに対応するテストケースの数は当然多くなります。だからこそ、ロジックの単体テストで、重要なケースを網羅しておきたいと考えました。
以下、本記事での説明のために必要な要件などを簡単に示しておきます。
要件
アプリケーションの要件は、以下のようなものでした。
- ユーザーの行う課題が複数あり(課題A, B, ...とする)、それらが特定の順番で実施される必要がある
- ユーザーの課題の実施状況に応じて、画面表示を制御する
DBスキーマ
私がプロジェクトに参画した時点でDBスキーマはすでに設計済みでした[2]。
- ユーザー1つに対して、各課題(課題A, B, ...)が複数紐づく
- あるユーザーが課題(課題A, B, ...のいずれか)を完了すると、その課題の実施内容が、 そのユーザーに紐づくレコードとして、対応する課題のテーブルに追加される想定で設計されている
以降の説明のための具体例
以降では、次のように簡略化して具体例とします。
- 要件:
- ユーザーは課題A, B, Cを「課題A → 課題B → 課題C」の順番で実施する必要がある
- ユーザーの課題の実施状況(進捗状況)に応じて、「次にやるべき課題」を表示する必要がある

- ER図は図のようになります:

DBを参照する関数はテストしにくい
元々の実装
DBの状態に応じて「ユーザーが次やるべき課題」を返す関数は、下図のように関数の中でDBを参照する実装になっていました。ユーザーのIDを入力として、対象のユーザーに紐づく課題A, B, Cのテーブルのレコードの有無を確認し、「次やるべき課題」を返します。
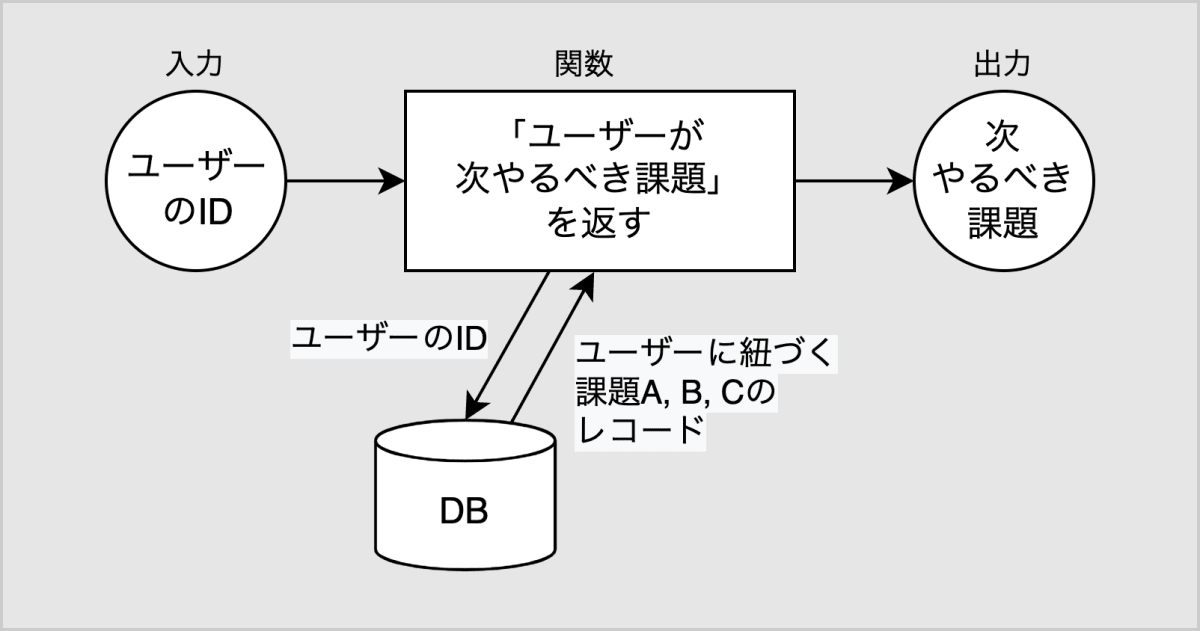
「ユーザーが次やるべき課題」を返す関数の場合、テストしたい項目は以下の通りです。各DBの状態に対して、ユーザーのIDを入力としたときに、返り値が正しいことを確かめます。
テスト項目
- ユーザーに紐づく課題のレコードがない場合、「課題A」が返ること
- ユーザーに紐づく課題Aのレコードのみがある場合、「課題B」が返ること
- ユーザーに紐づく課題A, Bのレコードのみがある場合、「課題C」が返ること
- ユーザーに紐づく課題A, B, Cのレコードがある場合、「null」が返ること
テストケースごとにDBの状態を用意しなければならないため、テストが書きにくい
関数自身の中でDBを参照している関数について、DBの状態に応じた挙動をテストするには、テストケースごとにDBの状態を用意する必要があります。使用している言語やライブラリによってはテストケースごとのDBの状態を記述しやすいものもあるかもしれませんが、今回はそうではありませんでした[3]。
また、本記事での例では課題が3つですが、実際には19個ありました。後の課題になるほど、テストのために用意しなければならない状態が複雑になります。テーブル数が多いほどDBの取りうる状態は増大し、どの状態についてテストすれば十分なのかもわかりにくくなります。
このような状況で、このままテストコードを書いていくのは、とても現実的ではありませんでした。
解決策
テストしたい関数を純粋関数にする
まず、DBの状態に応じて「次やるべき課題」を返す関数を、純粋関数にすることを考えました。必要なDBの状態を、関数の中で参照するのではなく、全て外から引数で渡すようにします。これにより、この関数のテストでは入力と出力の組み合わせを確認するだけでよくなります。

関数の入力を整える
関数のテストケースを検討する際には、関数の入力値を明確にすることが重要です。関数の引数が自由な値を取ると、テストケースの数が爆発的に増加してしまいます。このため、どのような値が関数に渡される可能性があるか、入力値の型としてどのような型を指定すべきかを考えました。
最終的なデータの流れを図に示します。

4つのステップに分けて説明します。
1. 不都合な状態を作らない
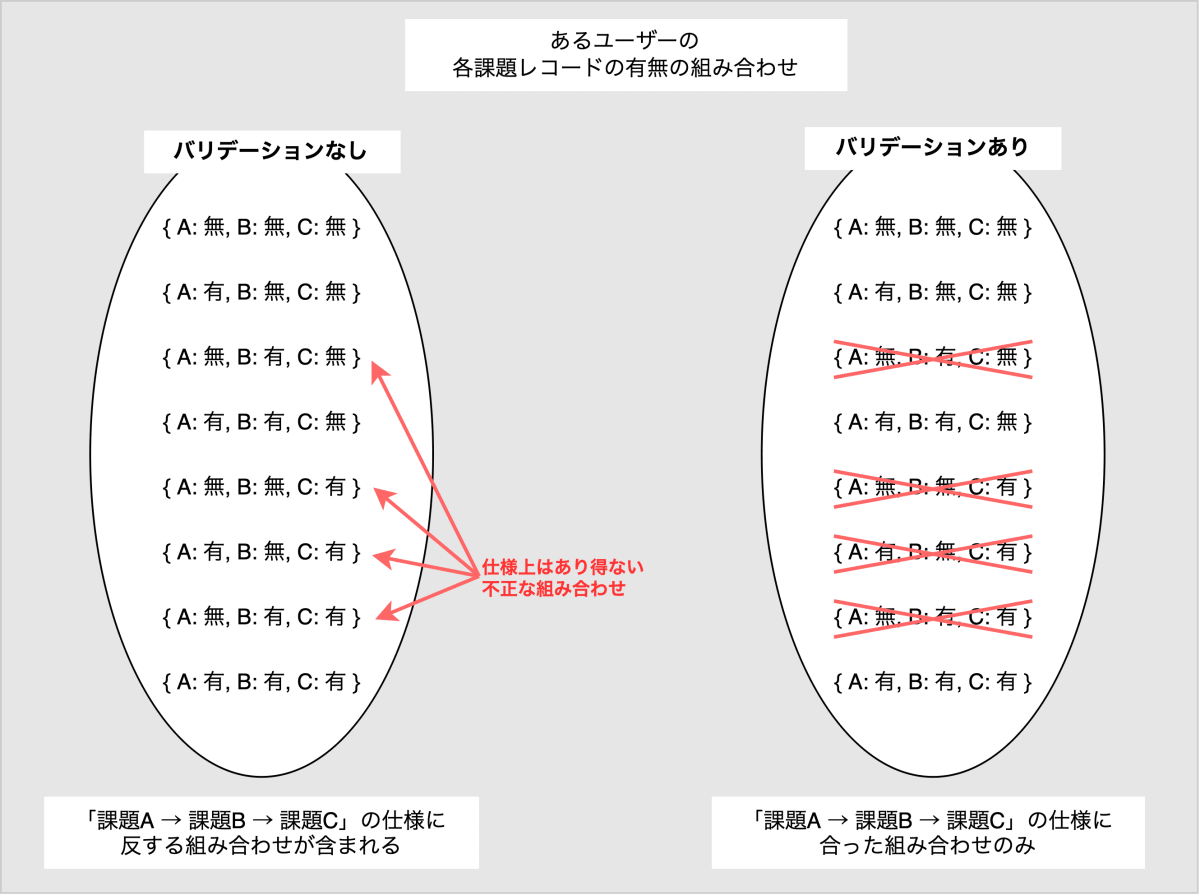
不都合な状態は、不正なデータがあることで生まれます。不正なデータとは、仕様通りの動作をしていればできることのないデータのことです。不正なデータがあると、データを参照する各処理で、不正なデータを考慮したエラー処理のために実装が複雑になり、テストケースも増えてしまいます。
不正なデータの発生は、データ作成時のバリデーションによって防ぐことができます[4]。「課題A → 課題B → 課題C」の順番に課題が実施されるという仕様に対するバリデーションは以下のようになります。このバリデーションがある場合とない場合について、あるユーザーに紐づく各課題のレコードの組み合わせを示したものが下図です。作成時のバリデーションにより、このデータの参照時には仕様に合った正常な状態のみを仮定できるようになります。
- バリデーション:
- 課題Bのレコード作成時に、課題Aのレコードがない場合はエラーを発生させる
- 課題Cのレコード作成時に、課題Bのレコードがない場合はエラーを発生させる
2. 関数の入力にふさわしい型に変換する
関数の入力には、テーブルから取得した値をそのまま渡すのではなく、関数に適した型を定義し、その型に変換した値を利用します。これにより、必要な値や正しい入力が明確になります。また、DBからの出力を関数の入力型に変換するための専用の関数を定義することで、同じ入力型の他の関数でも利用できるようになります。
今回の例では、DBの状態を「進捗状況型」として定義しました。あるユーザーの進捗状況は以下の4通りであり、ユーザーが次やるべき課題はこれらの値に応じて決まります。「進捗状況型」を、この4つの値のみ取るように定義し、「次やるべき課題」を返す関数の入力型として指定します。
- 「次やるべき課題」を返す関数の入力型(=進捗状況型)が取りうる値:
- 「何も終わっていない」
- 「課題Aまで完了している」
- 「課題Bまで完了している」
- 「課題Cまで完了している」
3. どこかでDBを参照する必要があり、そのテストも不可避
DBを参照しユーザーに紐づく各課題のレコードを取得する処理は、前節で述べた、DBの状態を「進捗状況型」に変換する関数の中で行うことにしました。型の変換のみの単純な処理なので、ロジックをこれ以上分離する必要はないと判断しました。
この関数のテストでは、DBの取りうる各状態(各課題レコードの有無の組み合わせ)に対して、進捗状況が取得されることを確認する必要があります。しかし、前述のとおり、DBの参照を含む関数のテストコードは書きにくいです。テストケースごとにDBの状態を1から用意するのは現実的ではありません。そのため、全ての状態を通るように課題のレコードを追加していき、各時点での進捗状況が正しく取得されることを確認するようなテストコードを記述することにしました。
テストの流れとしては、以下のようなイメージです。
- ユーザーを登録する
- → 進捗状況を取得し、「何も終わっていない」であることを確認する
- 課題Aのレコードを追加する
- → 進捗状況を取得し、「課題Aまで完了している」であることを確認する
- 課題Bのレコードを追加する
- → 進捗状況を取得し、「課題Bまで完了している」であることを確認する
- 課題Cのレコードを追加する
- → 進捗状況を取得し、「課題Cまで完了している」であることを確認する
4. 入力値のリストを定義する
ここまで進んで、ついに本来の関数において考慮すべき入力値が特定できました。この入力値をリストアップしたものを、関数が責任を持たなければならない入力値のリストとしてテスト用に定義しておきます。これは、同じ入力型の他の関数が必要になった際にも、過不足のないテストコードを書くの役立ちます。関数の引数として同じ入力の型を使用する場合、このリスト内の各値に対して正しく動作するように実装する必要がある、と明示できるためです。
今回の例では、以下のようになります。
- 「次やるべき課題」を返す関数の入力値のリスト:
- 「何も終わっていない」
- 「課題Aまで完了している」
- 「課題Bまで完了している」
- 「課題Cまで完了している」
関数の入力に対する出力の期待値を定義する
前述の入力値のリストが、定義すべきテストケースのリストです。リストの各値に対して、期待される出力を仕様に基づいて定義します。これに従って入力と出力の組み合わせを確認するテストコードを書きます。
今回の例の「次やるべき課題」を返す関数のテストケースを、それぞれ入力値と出力の期待値の組で表すと以下のようになります。
- 「次やるべき課題」を返す関数のテストケース:
- 入力値:「何も終わっていない」, 出力の期待値:「課題A」
- 入力値:「課題Aまで完了している」, 出力の期待値:「課題B」
- 入力値:「課題Bまで完了している」, 出力の期待値:「課題C」
- 入力値:「課題Cまで完了している」, 出力の期待値:「null」
以上で、重要なケースを網羅するテストコードを無事書けるようになりました。
結果
実際の仕様はもう少し複雑でしたが、基本的には同じアプローチでロジックを分離し、テストコードを設計・実装しました。
実際のアプリケーションの課題や状態の数
- 「課題」の数:19個
- 各課題の内容や開放条件や完了条件は課題によって異なる
- 「課題の進捗状況の状態」の数:約100個
- 遷移経路が単純に前から順番に進むだけではなく、途中で戻ったり、飛ばしたりすることがあるため状態の数が多くなる
- 「次やるべき課題を返す」などの「状態に応じた値を返す関数」:6種類
- 次に開始できる課題、警告メッセージ、特定の課題の更新権限など
結果は以下の通りです。
- 各種の主要ロジックに対する単体テストでそれぞれ重要なケースを網羅でき、細かいバグを見逃すことなく修正できました
- テストケースが明確になっていたことで、仕様の確認も漏れなくできました
- 大量のテーブルの状態を「進捗状況」として扱えるようにしたことで、テストだけでなく実装もやりやすくなったと感じます(各所で必要なテーブルをひとつひとつ参照しに行く必要がなくなるためです。)
まとめ
今回のテストコードの設計と実装を通じて得られた学びをまとめます。
- テスト対象を明確にすることで、効果的なロジックの分離が可能になる
- 重要な関数を純粋関数にすることで、重要なケースを網羅するテストコードを書きやすくなる
- 純粋関数のテストは、テストケースが入力値で定まる
- バリデーションにより不正なデータを防ぐことで、全体の実装とテストで考慮すべきケースを減らせる
- DBからのデータは適切な型に変換することで、関数の実装とテストが容易になる
チームのみなさんへ
今回のロジックの分離とテストコードの設計・実装をやり切ることができたのは、チームのみなさんのおかげです。
- テストしにくくて困っていると相談した際、一緒に考えて、貴重な意見やアドバイスをいただいたこと
- 解決策として提案したアプローチを柔軟に受け入れていただいたこと
- 本対応のためやや大きくなってしまったプルリクエストにもかかわらず、こころよくレビューしてくださったこと
- この挑戦に対してポジティブなフィードバックをいただいたこと
これらのサポートに、心から感謝しています。
おわりに
読んでいただきありがとうございました。
本文中で触れることができませんでしたが、今回のアプローチには、特にロジックの分離に関する検討において、社内の読書会[5]で得た知見が少なからず影響しています。今後もこのような機会を通じて、より良い設計ができるよう努めていきます。
MICINではメンバーを大募集しています。
「とりあえず話を聞いてみたい」でも大歓迎ですので、お気軽にご応募ください!
-
参画した際、DBスキーマがtblsで整理されており非常に助かりました。これがなければ大量のテーブルに心が押しつぶされてしまっていたことでしょう。tblsでのドキュメンテーションについては、まじまっちょさんの DBスキーマはtblsのViewpointsで整理しよう をご覧ください。 ↩︎
-
テストケースごとのDBの状態を用意するのに、RedwoodJSのscenarios(※2025/11/10時点でアクセス不可になっています)を使用していました。 ↩︎
-
イミュータブルな設計を仮定しています。 ↩︎
-
Domain Modeling Made Functional の輪読会を、社内有志のエンジニアで開催しました。 ↩︎

Discussion