この記事は MICIN Advent Calendar 2023 の 19日目の記事です。
前回は黒澤さんの、「AWS SIEMを運用してみて起きた事やその対処」 でした。
はじめに
SREチームの小野です。
MICINのSREチームは、各事業部で開発しているプロダクトのインフラの管理やモニタリングの整備、SLI/SLOの測定や運用サポートを事業部を横断して行っています。
SREの取り組みは2021年頃から始めていますが、2023年10月に初めて正式にMICINの組織図に「SREチーム」が登場しました。この記事では今までの取り組みやチームの変遷を改めて振り返ってみて、今後の展望もお話しします。
SREチームまでの変遷
インフラチーム
MICINでは主にAWSを利用してアプリケーションのインフラを構築、運用しています。
2019年に2名からスタートしたインフラチームは、当時以下のような取り組みを行っていました。
- ログ転送基盤の構築
- マルチアカウント管理の整備
- 本番環境とステージング環境のアカウント分離
すでにIaCやCI/CDについては仕組み化されており、インフラチームの最初の1年は運用の課題や医療事業における各種法令やガイドライン準拠への対応が主な活動内容でした。
MICINが準拠している主な法令・ガイドライン
- 個人情報の保護に関する法律(個人情報保護法)
- 医療・介護関係事業者における個人情報の適切な取扱いのためのガイダンス
- 医療情報を取り扱う情報システム・サービスの提供事業者における安全管理ガイドライン
- オンライン診療の適切な実施に関する指針
※その他サービスによって従うべきガイドライン等が存在します。
複数のアプリケーションのログをDatadogで横断して確認できるようになり、 Control Towerの統制管理の仕組みを導入しマルチアカウントでの運用が始まりました。
本番環境とステージング環境がAWSアカウントごと分離され、シンプルな権限管理のもと運用と開発が少しずつ分離していきました。
自称SREチーム
インフラチームはAWSに関する作業を全般的に引き受け、細かいトラブルシューティングなども行っていました。
セキュリティ対応も進み、プロダクト運用の統制が進んでいく一方で、「AWSに関する作業はインフラチームにお任せ」という状態になってしまっていることにいくつか課題が見えてきました。
- アプリケーションに応じて適切なAWSサービスを選択し、そのサービス特性に応じた開発ができていない
- インフラチームが運用工数に比例して大きくなる必要がありそう
- 依頼ベースの対応では中長期の目標が立てづらい
また、コロナ禍に突入したことでオンライン診療の利用率が増加し、2020年5月にはサーバ負荷による一時的なサービスダウンも発生しました。
インフラチームがSREになろうと決意したのがこの頃です。
2021年にアプリケーションエンジニアもAWSサービスを容易に構築できるようにし、その上で安心してサービスを本番リリースできる仕組みを整えました。
- kubernetes(k8s)を利用した開発環境の作成ツールの開発
- terraformを自動出力するテンプレートリポジトリの作成
- Production Readiness Checklistの作成
- ポストモーテムの文化の浸透
これらの仕組みの提供とともに、インフラチームはSREを自称するようになりました。
DevSecOps推進チーム
2022年6月に大きな組織改変があり、インフラチームがセキュリティチームと統合されます。
チーム名がDevSecOps推進チームとなり、今までできなかった中長期施策を計画して実行できる体制になりました。
この1年半での主な取り組みを紹介します。
- セキュリティチェックリストの作成
- SLI/SLOの測定開始とマネジメントマニュアルの作成
- システム障害管理マニュアルの作成
- プロダクトごとに担当するSREをアサイン
- 負荷試験プラットフォームの開発
各プロダクトにアサインされたEmbedded SREがプロダクトチームのミーティングに参加し、セキュリティのシフトレフトをはじめ、SLI/SLOの導入や障害管理マニュアルの作成など開発ライフサイクルの見直しを進めています。
SREチーム
2023年10月に私がチームリーダーに就任したことをきっかけに、DevSecOps推進チームは正式にSREチームへと名称変更しました。
DevSecOpsを推進することに変わりはないですが、未経験で拙いながらもマネジメント業務も行い、MICINのSREチームがより信頼性のビジネス価値を最大化していくための計画を考えています。
チーム名称の変更とは関係ないですが、SREチームがコミュニケーション活動として取り組んでいるものも紹介します。
| 内容 | 頻度 | |
|---|---|---|
| 朝会 | 昨日やったこと、今日やることを共有する | 日次 |
| 週次定例 | その週のホットトピックやクラウドの利用料金などを確認する | 週次 |
| 勉強会 | 技術書の輪読や触ってみたツールの紹介 | 週次 |
| モブプロ | アプリケーションのログの実装やslack botの開発 | 週次 |
| リファクタ会 | 技術負債をリストアップし、タスク化していく | 四半期ごと |
振り返って
MICINはここ数年で様々なバックグラウンドを持つモンスターな人たち[1]が参画し、組織改変を何度も経験しました。チームの形が変化する中でいろいろな取り組みを行なってきましたが、うまくいかなかったものもたくさんあります。
うまくいかなかったもの
k8sの環境作成ツール
k8sを利用した環境作成ツールは、skaffoldのテンプレートをGo言語で整形して出力する内製のプロダクトでしたが、メンテナンスコストやk8s自体の認知負荷などを理由としてあまり浸透しませんでした。
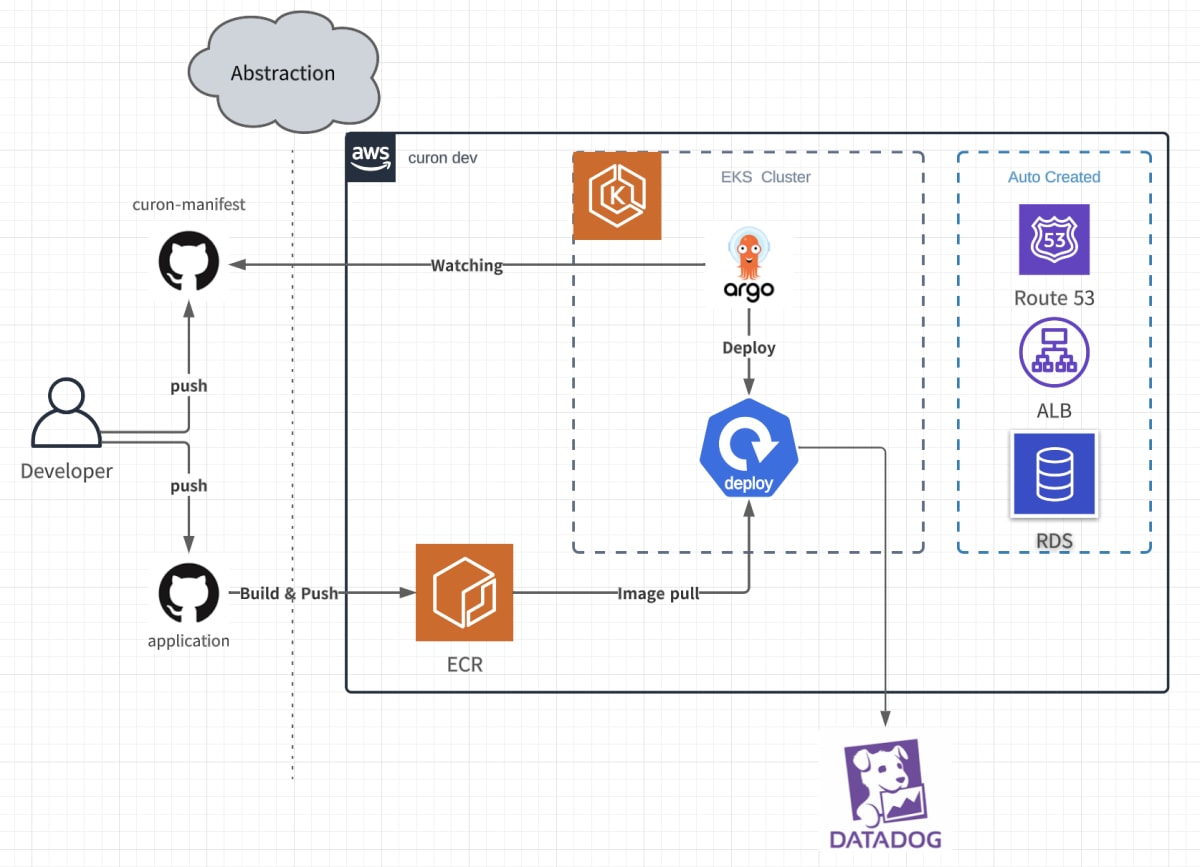
argocdを利用した再チャレンジ
AWS上に開発したプロダクトを気軽にデプロイしたいことは変わらないので、EKSとArgocdを使った環境作成の仕組みもトライしています。
OSSを利用することで仕組み自体のメンテナンスコストが抑えられ、Gitにpushするだけで環境が作成されるので、開発者にとっての認知負荷も抑えられると期待しています。
terraformのテンプレートリポジトリ
terraformのテンプレートリポジトリは開発者が容易にインフラを構築するために作成しましたが、こちらもterraform自体の認知負荷、AWSの各サービスの設定値についての理解が求められることから開発者にとってはあまり嬉しくないものでした。
このテンプレートリポジトリはMICINの標準的なAWSアーキテクチャとして、SREチームがメンテナンスをして利用しています。
SLI/SLOの定期的な見直し
SLI/SLOは導入後に定期的に見直しを行うことを想定していました。
しかし、測定自体がterraform管理されていること、権限管理が適切に設定できてないことからSREチームしかメンテナンスできず手が回ってないものもあります。
導入して終わりになってしまわないように、しっかりとメンテナンスしていきたいですね。
今後の展望
Google社のSite Reliability EngineeringやThe Site Reliability Workbookなど読みながら、今回紹介したもの以外にも多くの仮説検証を行なってきました。
SREのプラクティスをどう自社の文化に取り入れていくのかは試行錯誤が必要になります。
Google社のブログにあるように、J カーブを意識してより深くSREを実践していくつもりです。
DORA は、組織変革には「J カーブ」があると説明しています。これは、挫折と教訓の後にのみ永続的な成功がもたらされるという現象です。
最後まで読んでいただきありがとうございました。
MICIN ではメンバーを大募集しています。
「とりあえず話を聞いてみたい」でも大歓迎ですので、お気軽にご応募ください!
MICIN 採用ページ:https://recruit.micin.jp/
-
MICINでは入社時にその人のイメージに合ったMICIN MONSTERというイラストがもらえます ↩︎

Discussion