この記事は MICIN Advent Calendar 2023 の 18日目の記事です。
前回は佐藤(帯)さんの、「DBの状態に依存したロジックを純粋関数にしたらテストしやすくなった」 でした。
1. はじめに 〜SIEM概要〜
MICINにおけるSIEMと、その役割
SIEMとは「Security Information and Event Management」の事で、セキュリティに関する情報とイベントを統合管理する仕組みを指しています。
MICINでは目的に応じて2つのSIEMを運用しています。
1つは「Sumo Logic」を使った仕組みで、これは主に社内システムや社給デバイス(PC、スマホ)等のイベントを監視、管理しています。
(「Sumo Logic」については、高橋さんの記事でも触れられています)
一方、本日の主役「SIEM on Amazon OpenSearch Service」(以下SIEMと記載したものはこちらを指します)は、お客様向けに提供する各プロダクトのプラットフォーム、AWSのイベントを蓄積、管理しています。
本記事では情報セキュリティ部黒澤が、MICINにおけるSIEMの概要や、発生した事象とその対応といった内容を、運用状況を織り交ぜながら記したいと思います。
MICINで最初にSIEMの導入が行われたのは、2021年でした。
MICINのAWS環境はプロダクト毎にアカウントが分かれており、Control Towerを利用したアカウント統制とGuardDutyを利用したセキュリティイベントの管理が行われています。
ただ様々なログを統合的に管理する仕組みはなく、イベントの管理は外部のログ管理システムや、AWSの管理コンソールからアカウント毎に確認していました。
その名が示すように、セキュリティイベントの集中管理を目的として導入されたSIEMでしたが、全てのアカウントの複数のサービスのログを横断的に確認できるという便利さもあります。
このためMICINでは、インフラの障害調査や、本番環境へのアクセスを監査するイベントチェックなど様々な場面でSIEMが利用されています。
MICINのSIEMの特徴
MICINでは、社内システムへのアクセスにSSOを用いており、SIEMはその仕組と統合されています。
これによりSIEMの利用者を社内の人(SSOにて認証され、かつSIEMへのアクセスを認可されている人)に限定でき、大切なログを安全な環境で利用しています。

MICINにおけるSIEMの概要図
また、SIEMで参照できるログですが、以下の3つを収集しています。
| 対象サービス | 概要 |
|---|---|
| CloudTrail | APIを使った操作のログ、AWSのリソースに対する操作の確認を行う |
| WAF | WAFへのアクセスログ、プロダクト環境へのリクエストログを確認 |
| Security Hub | 各リソースの設定不備を検出するためのログ |
本来であれば、VPCフローログ等ありとあらゆるログを収集したいのですが、MICINで利用しているAWSアカウントは、2023年時点で50を超えています。
そのため全てのログを収集しようとすると、必要なインスタンスのスペックやストレージは青天井となり、コストが膨大になってしまいます。
収集できないログやアプリケーションログは、他のログ収集サービスの利用等でカバーし、SIEMに蓄積するログを限定しています。
参考:MICINのSIEMのインスタンススペック
| ログ | 概要 |
|---|---|
| インスタンスタイプ | m5.large.search |
| ノード数 | 3 |
| EBSストレージタイプ | 汎用 (SSD) - gp3 |
| ストレージ容量 | 1024GB/ノード |
2. SIEMを運用する中で起きたこと
ストレージが足りなくなってきた
導入当初、SIEM上でのログ保有期間を3ヶ月と設定しました。
この時、インスタンスのEBSストレージはデフォルトで、1ノードあたり512GB(gp2)でした。
ところが、運用から1年を過ぎた頃になると、AWSアカウントが増えた事でログも増加、保持期間は1.5ヶ月程度まで短くなってしまいました。
インスタンスタイプを変更して、ストレージを増やせれば良いのですが、予算的な事もあり簡単に変更はできなさそうです。
そこでEBSのタイプをgp2からgp3に変更することで、インスタンスタイプを変更せずにストレージだけを増やす方法を選択しました。
これにより、ストレージサイズは倍の1024GB(1ノードあたり)まで増やせて、ログの保持期間を3ヶ月に戻す事ができました。
ちなみにgp2とgp3の特性の違いは以下のようなものがありますが、この時点では深く考えていませんでした。
「ストレージ容量のコストは増えるけど、全体的な利用料が下がるならラッキー」くらいに思っていました。
| 汎用SSDタイプ | 概要 |
|---|---|
| gp2 | ・ ストレージサイズに応じてパフォーマンスが可変する(バーストあり) ・ MICINのインスタンスタイプではストレージサイズの最大が512GB |
| gp3 | ・ GiB あたりの料金が汎用 SSD (gp2) ボリュームよりも20%低い ・ IOPS、スループットは固定で、必要に応じて変更が必要 ・ MICINのインスタンスタイプではストレージサイズの最大が1024GB |
参考:Amazon EBS ボリュームタイプ gp2 と gp3 を比較
Lambdaの費用が高くなってきた
今回メインで調査した事象がこちらになります。
ログの保存期間も戻り、何事もなく運用できていると思っていたのですが、ある時チームの朝会でこんな話題が出ました。
「月末になると、SIEMを管理するAWSアカウントでLambdaの費用が急激に増加するよね」
以前はそのような現象が無かったものの、2023年の6月以降、その傾向が顕著になりました。

こうして見るとその傾向は顕著ですね
少しSIEMのログの取り込みについて補足します。
SIEMへのログの取り込みはaes-siem-es-loader(以下es-loaderと略します)というLambda関数で行われています。
この関数は、S3バケットにログが置かれたタイミングで起動し、データの抽出と加工、OpenSearchへのロードを行うETLの機能を担っています。
AWSのログは常に何かしら出力されていますので、es-loaderも頻繁に動作しています。
このため、SIEMを運用するアカウントでLambdaの利用料金が高くなってしまうのはやむを得ないといえます。
しかし、MICINの全AWSアカウントでLambdaに費やす費用の3割を1アカウントだけで占めるのは、流石に多過ぎです。
また、それが月末に急増するというのも謎です。
何とか見ないふりをしようとしましたが、Lambdaの費用が4割を超える月も出てしまい、原因調査と対策を考えてみる事になりました。
参考:AWS Lambdaで300万円以上課金されてしまった怖い話
3. 事象の調査と原因の推測
OpenSearchを調べてみる
まずはOpenSearchの管理コンソールから、インスタンスの通知を確認してみます。
すると、毎月中旬から下旬にかけて、スループットを使い果たした事によるスロットリング(処理制限)が発生している事が判明しました。

重要度[Medium]で出ているけど[Medium]どころの話しではない気がします
Lambdaの実行状況を調べてみる
次にLambda(aes-siem-es-loader)の動作状況を確認してみます。
これはLambdaの管理コンソールから関数(es-loader)を選び、モニタリングを表示することで確認できます。

こちらも顕著な傾向が
グラフを確認すると、毎月20日頃から月末にかけて、成功率が下がり、エラーカウントが増えています。
一方で月初になるとその傾向がパタっと止まっています。
ひとまず仮説を立ててみる
起きている事象と確認した内容を踏まえて、SIEMで起きている事象を整理し、原因を考えてみます。
- インスタンスのスループットが足りていない
- SIEMへのログ取り込みでLambdaのエラーが増えている
- 事象は毎月月末に発生する
1点目のOpenSearchの通知から、スループット不足に起因して、OpenSearchの処理が制限されているのは明らかです。
これは、前述したストレージをgp2からgp3に変更した事で、バースト処理に対処しなくなった事が原因のようです。
また、これが更に、2点目のLambdaの実行エラーを引き起こしているのも予測されます。(処理が止まるとLambdaがタイムアウトするため)
最後に発生時期が月末に限定されている点ですが、これはOpenSearchのインデックス管理単位に起因していると思われます。
MICINではインデックスの管理を月単位で行っています。
インデックスはログの蓄積単位となるもので、これが月単位の場合、同じ月のログは同じインデックスに蓄積され続けます。
このため、毎月月初に新規作成されたインデックスは、日を追うごとにサイズが大きくなり、月末にそのサイズが最大化します。
ログの取り込み処理は、月初より月末の方が処理負荷が高くなる事が予想できます。
インデックスサイズが大きくなる事で、処理負荷が高くなりスループットが不足、結果的にes-loaderの処理エラーを引き起こしているのだろうと考えました。
Lambdaの料金は、処理時間と割り当てたメモリ量に応じて増加します。
処理に時間がかかる、ログの取り込みエラーが増える(=有効な処理結果が得られない)という条件が揃う事で、月末にLambdaの料金がバーストするという事象に繋がっていたと思われます。
更に調べてみると・・・
仮説は立ててみたものの、裏付けが更に必要です。
情報セキュリティ部の優秀なインターン、仲野さんに相談した所、es-loaderの実行エラーをより具体的に(あっという間に)調べてくれました。
その1.タイムアウトエラー
es-loaderの処理がタイムアウトした事を示しています。
これは恐らくスループットが上限に達した事でインスタンスの処理が中断したか、インデックスサイズが大きすぎる事により、es-loaderがタイムアウトしたものと考えられます。
ちなみにタイムアウトの値は10分に設定されているので、1回タイムアウトするとLambdaの利用料金は600秒分計上されることになります。
urllib3.exceptions.ReadTimeoutError: HTTPSConnectionPool(host='vpc-aes-siem-xxxxxxxxxxx.us-east-2.es.amazonaws.com', port=443): Read timed out. (read timeout=60)
During handling of the above exception, another exception occurred:
その2.インデックスのフィールド数の上限に対するエラー
このエラーはノーマークでした。
OpenSearchではインデックスのテンプレートで、そのインデックス上で設定できるフィールド数が決まっています。
この値はデフォルト値が1000となっているため、多数のフィールドを持つログを取り込む場合はインデックス側で明示的に指定する必要があります。
以下は取り込もうとしているデータが、SecurityHubのインデックスに設定されているフィールド数の上限値(1000)を越えているために生じているエラーです。
同じエラーは、CloudTrailでも発生しており、そちらは、元々設定されていた上限値5000でも足りないとの事でした。
{
"level": "ERROR",
"message": "[[{'type': 'illegal_argument_exception', 'reason': 'Limit of total fields [1000] has been exceeded'}]]",
"location": "lambda_handler:278",
"timestamp": "2023-09-02 17:33:26,358",
"service": "es-loader",
"sampling_rate": 0,
"cold_start": false,
"function_name": "aes-siem-es-loader",
"function_memory_size": "2048",
"function_arn": "arn:aws:lambda:us-east-2:999999999999:function:aes-siem-es-loader",
"function_request_id": "54797610-47fe-48c7-92e2-1efab5144ea6",
"s3_key": "AWSLogs/999999999999/SecurityHub/ap-northeast-1/2023/09/02/17/aes-siem-firehose-securityhub-1-2023-09-02-17-29-10-58357c1a-708b-4ed5-afbf-2bced04bcad4.gz",
"xray_trace_id": "1-64f371e4-5dc8196d3a47aa1b79fae83b"
}
その3.ログのパースエラー
こちらは更にノーマークなエラーでした。
es-loaderがログをパースできなくてエラーを返していました。
以下はCloudTrailのログの取り込みで発生したログで、ここではrequestElements.sessionのフィールドでエラーを起こしています。
{"level": "ERROR", "message": "[[{'type': 'mapper_parsing_exception', 'reason': 'object mapping for [responseElements.session] tried to parse field [session] as object, but found a concrete value'}
4. 対策を取ってみる
IOPSとスループットの改善
こちらは管理コンソールに出ているエラーから原因がはっきりしているため、IOPSとスループットの値を変更することで対応します。
OpenSearchのコンソールからインスタンスに設定されているIOPSとスループットの値を更新できます。

クラスタの編集画面にて、IOPSとスループットの変更を行います
変更の反映前にドライランを行うことで、OpenSearchの稼働への影響を事前に確認することが可能です。
必要であれば、自動的にBlue/Greenデプロイを実施してくれますので設定変更中も問題なくOpenSearchを利用できます。
便利ですね。
Lambdaエラーへの対処
Lambdaで起きているエラーのうち、フィールド数の上限によるエラーは、OpenSearch側の設定変更で対応します。
このエラーに対してはこちらのリンク先を参考に、OpenSearch側で設定変更を行いました。

インデックステンプレートの更新は、OpenSearchのDev Toolsから行います
今回は以下のようにフィールド数の上限を変更しました。
| ログカテゴリ | 設定前の値 | 設定後の値 |
|---|---|---|
| SecurityHub | 1000 | 2000 |
| CloudTrail | 5000 | 8000 |
5. 対策後の効果確認
これらの対策結果を見てみます。
OpenSearchのメッセージの解消
マネージメントコンソールからドメインへの通知を確認してみます。

スループットが制限される通知は停止しました
設定変更を行った11/21以降、頻繁に出ていた「Disk Throughput Throttle」の通知が停止しました。
Lambdaのエラーの解消
es-loaderの動作ログを見てみましょう。

エラーカウントも一定抑えられているように見えます
こちらも設定変更の効果で、エラーカウント数の増加を抑える効果がハッキリと見てとれるグラフとなりました。
費用推移
費用推移は2つの視点で確認する必要があります。
1つはLambdaエラーを抑えた事によるLambda利用料の推移、もう1つはIOPSとスループットを増やしたことによるOpenSearchの増額です。
まずはLambdaの利用料推移を確認します。

11月のLambda費用は明らかに減っています
Lambdaの費用が減っている事が確認できます。
次はIOPSとスループットを増設した費用です。
画像は月末時点のコストとなっており、21日の変更から10日分の費用増加は約$40となっていました。
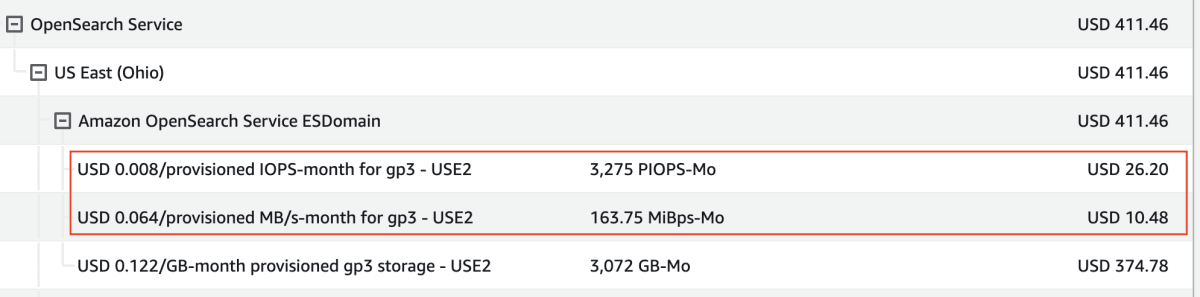
赤枠で囲まれた部分がIOPSとスループットの10日分の費用です
1ヶ月を通して利用した場合、この3倍の費用がかかりますので、月額で約$120の増額となってしまいます。
ずっとこの状態で使うのはあまりお得ではありません。
あくまで月末だけの一時的な対策とするのが良さそうです。
これで解決かと思ったら
安心したのもつかの間、月末になったらやはりLambdaエラーが上昇してしまいました。

最終的にはコスト増加が発生しました
ログを確認すると、今回対応していないログのパースエラーが激増しています。
今回の対応では安易に対応を済ませようとサボったのですが、根本的な解決に辿り着くにはこの問題にも向き合わないとダメなようです。
6. 今後の対応について
今回は完全解決までたどり着けていませんが、引き続き対応は必要なので、幾つか今後の対応策を挙げておきます。
インデックス管理単位の見直し
まずインデックス管理単位の変更により、インデックスのサイズを小さくする事から始めます。
具体的にはインデックスの管理単位を月単位から週単位に切り替える事で、個々のインデックスサイズを小さくします。
これにより月末に肥大化したインデックスを更新する処理負荷が高くなる事を避けます。
また、インデックスサイズを小さくする事は、ストレージを効率的に使う事に繋がると考えています。
現在はインデックスサイズが大きいため、月末になるほどストレージ空き容量が逼迫し、月初になると古いインデックスが削除されストレージが空くという事を繰り返しています。
インデックスサイズが小さくなり、毎週ローテーションできるようになると、ストレージ空き容量が増減する波を抑え、より効率的にストレージを使えるはずです。
この変更は、es-loaderのパラメータを定義するuser.iniファイルによりインデックスのローテーション間隔を設定してあげることで設定します。
インデックスへの反映はインデックスが更新されるタイミングとなりますので、今月実施して来月からの反映を目指します。
参考:SIEM on Amazon OpenSearch Service の設定変更
Lambdaのparseエラーへの対処
今回、月末にLambdaの実行回数が増加したのは、このエラーが原因でした。
費用に直結する事象の大きな要因ですので、解決する必要があります。
ただ、es-loaderのコード内の見直しも必要なため、対応には若干腰が重くなってしまいます。
願わくばインデックス管理単位を見直す事で月末にこのエラーが急増するのだけでも防げたら良いなと思います。
シャードの配置見直し
インデックス管理単位の変更により解決するかもしれませんので優先度は低ですが、1シャードあたりのインデックスサイズは10〜50GiB程度が推奨値とされています。
現状では、CloudTrailのログが月末には300GBを越えてしまうのに、シャードの数が2つと少ないままとなっています。
ただ、これはインデックス管理単位の変更により、インデックスサイズが小さくなる事で、推奨値に収める事ができるかもしれません。
その他パフォーマンス・チューニング
色々探してみると、実施したほうが良さそうなものがあったので、以下のページを参考にして幾つか対応していきます。
Amazon OpenSearch Service クラスターでインデックス作成のパフォーマンスを向上させるにはどうすればよいですか?
新アーキテクチャの検討
12月の頭まで行われていたAWSのイベント(re:invent2023)で発表された幾つかのアーキテクチャの導入を検討するのも面白そうです。
OpenSearch関連ではZERO-ETL、Serverlessといったキーワードが挙げられており、そもそもes-loaderによるETL処理を無くす事ができるかもしれません。
また、OpenSearchで利用できるインスタンスの種類が追加されており、よりOpenSearchでの利用に特化したインスタンスがリリースされるそうです。
(OR1インスタンスの利用はOpenSearch2.11以降での利用なので、メジャーバージョンアップが必要そうです)
7. さいごに
本記事を最後までお読みいただきありがとうございます。
今回の記事で解決できなかった部分と、追加で対応した結果については、来年にでも記事として書ければと考えています。
(その時は「解決編」になっているはずです、多分)
SIEMの導入以降の出来事を色々思い出して記事にしてみましたが、改めて日々の運用は色々あるものだなと感じています。
SIEMに限ったことでは無いですが、ソフトウェアに設定するパラメータやサイジング、運用形態や環境の変化により、必要な対応は刻々と変わっていきます。
その結果起きた事象の調査にあたり、様々な記事を参考にさせていただきました。
それらの記事を参考に、MICINの環境に適した対応を適切に選んでいく事で、MICINの環境をより良くできました。
MICINの環境は日々変化しています。引き続きより良い環境を維持していければと思います。
今回記載した内容も、また他のどこかのSIEM環境の運用のお役に立てたら幸いです。
でも将来的にはOpenSearchがServerlessになって、この辺の面倒な運用が一切なくなったら嬉しいな!
MICIN ではメンバーを大募集しています。
「とりあえず話を聞いてみたい」でも大歓迎ですので、お気軽にご応募ください!

Discussion