ローカルで動かせる日本語TTSをいろいろ試す
スクラップで試してましたが溜まってきたのでTTSに関する部分を整理。
モチベーション
私の主観評価でしかないのですが、OpenAIのTTSは「日本語を喋れる外国人」という感が強いし声が若くない、大手パブクラのTTSはロボット感が強い。
にじボイスとかのサービスは素晴らしいけどお金がかかる(OpenAIやパブクラもだけど)。
VOICEVOXのような素晴らしいものもあるが、もうちょっと品質良いものが欲しい。
前提
- 自分が試している目的がAIアバター、ゲーム、アニメの制作を目的としているので、その目的に対して私の主観で評価してます。
- リアルタイム性は評価してません。
試したもの
| TTS | 確認時期 | 評価 |
|---|---|---|
| Style-Bert-VITS2 | 2024/07/05 | 良い |
| Fish Speech | 2025/02/19 | 良い |
| hexgrad/Kokoro-82M | 2025/04/05 | ダメ |
| OuteAI/Llama-OuteTTS-1.0-1B | 2025/04/15 | ダメ |
| 2121-8/canary-tts-0.5b | 2025/04/29 | 悪くはない |
| 2121-8/japanese-parler-tts-mini | 2025/04/29 | ダメ |
| Respair/Tsukasa_Speech | 2025/04/29 | とても良い |
Kimi-Audioも試したけどメモリが足りなくて動かせなかった。
環境構築方法
冒頭にあげたスクラップに書いています。
「Bert」とか「Fish」とかで検索してください。
生成結果
Zennには音声をあげれないのでTwitterにあげたものを参照。
GPT-4oで画像生成→FramePackで動画化して適当に映像つけてます。
Style-Bert-VITS2
そこそこの自然さで結構早く動くし、トレーニングもGUIで出来てとても簡単。
GitHubも日本語で親切。
Fish Speech
そこそこの自然さで動きます。
サンプル通りだと毎回ランダムで話者が選ばれるので、リファレンスをつけて動かします。
末っ子の声をリファレンスにしたら可愛すぎて悶絶しました。
ただ、Fish Audioを見ると明らかに無許可の音声がアップされているので嫌な気持ちになる。
Kokoro-82M
日本語はイマイチっぽいです。
Llama-OuteTTS-1.0-1B
日本語はイマイチっぽいです。
canary-tts-0.5b
サンプルプログラム通りに動かしたつもりだけど昔のアニメの音声みたいな音質。
嫌いじゃないんだけど。
sample_rateのパラメータをあげれば良いのかと思ったけど、あげたら早送りになった。
japanese-parler-tts-mini
Hugging Faceのサンプルを見る限りは話者を変えれそうなんだけど、
プロンプトを変えてもあまり変わらない。
Tsukasa_Speech
主にゲームやノベルからのデータらしいのでアニメ感が強い。
サンプルがそのままだと動かなかったり、いろいろ未整備感はあるけど遊べる。
発展を期待してます。
おわり
こんなのもあるよというのがあれば教えてくださいー。
続き
Discussion
Avis Speech とかどうでしょうか? VOICEVOX 互換のAPIで操作できますよ。
コメントありがとうございます!
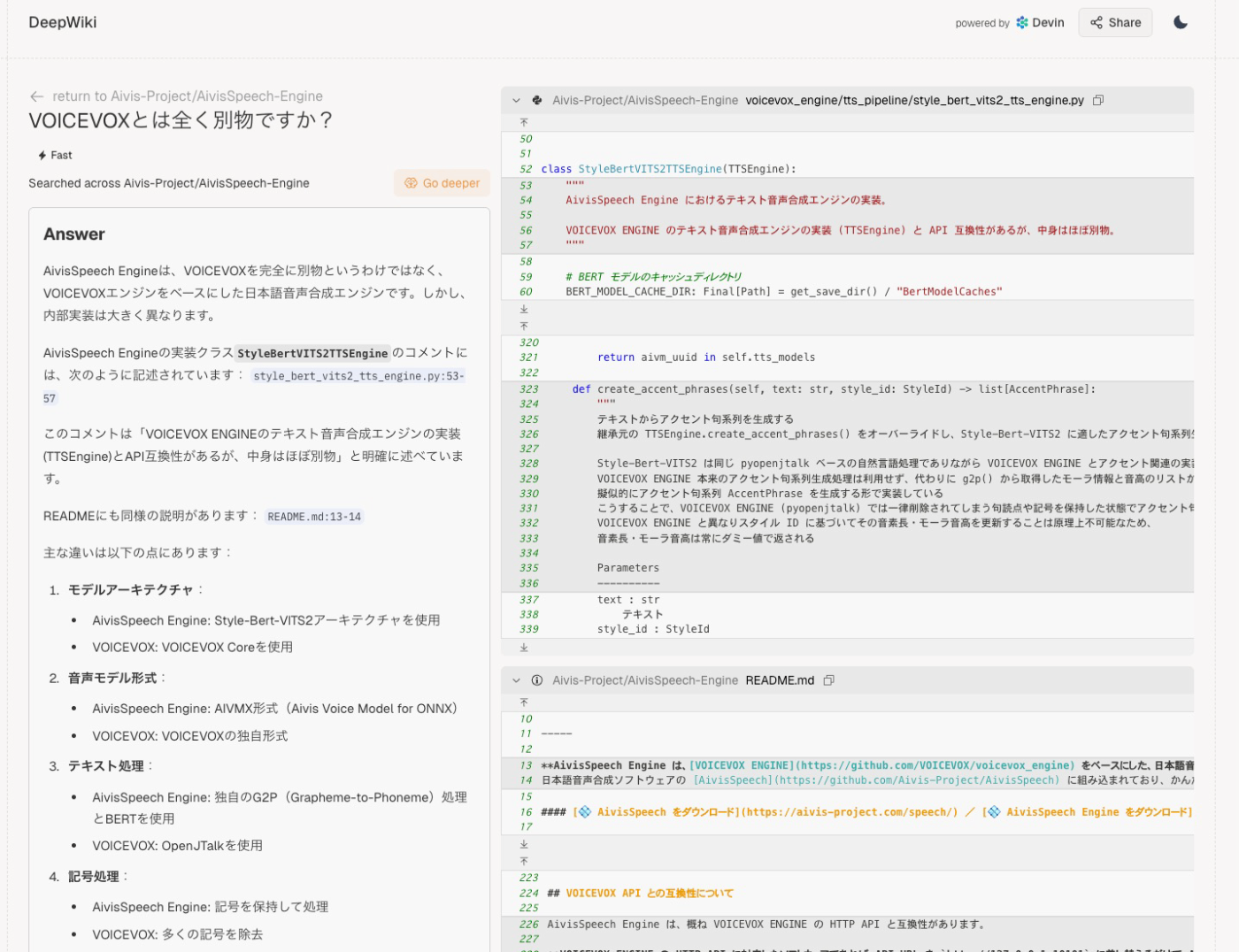
自分のPCを見返したらAivisSpeechを試した痕跡がありました。記憶がぼんやりしてますがモデルが少なかったから、あまり使わなかったのかな・・・
あと、勝手にVOICEVOXとエンジンのベースは同じかと思い込んでたのですが全然違うんですね(Style-Vert-VITS2)
また改めて触ってみようと思います。