

はじめに
ご覧いただきありがとうございます。阿河です。
今回は小ネタです。
AWS Glueの新しいエンジンオプションとして、AWS Glue for Rayがプレビューリリースされました。
本記事では以下の内容を扱います。
- Rayを使わない場合の処理
- Rayを使った場合の処理
- プレビュー版であるGlue for Rayの場合の処理
それぞれの処理を比較していきます。
概要
- AWS Glueジョブを作成する
- Rayを使ったコードに書き換える
- AWS Glue for Rayを使用したジョブ実行
Rayのドキュメントは上記を御覧ください。
なお今回AWS Glue for Rayの情報に触れておりますが、本記事の執筆は2022年12月12日時点のものであり、現時点ではプレビュー版となっております。リリース後に全く同じ機能が使用できるとは限らないことはご了承お願いします。
1. AWS Glueジョブを作成する
事前準備
- S3バケットの作成
Glue用のIAMロールを作成
- 信頼されたエンティティタイプ: AWSのサービス
- 一般的なユースケース: Glue
- ポリシー: AmazonS3FullAccess/CloudwatchLogsFullAccess
- ロール名: ※任意の名前をつけてください
簡易検証のためFullAccessを与えていますが、必要に応じて権限を絞ってください。
Glueジョブの作成
-
AWS GlueのJobs画面に移行
-
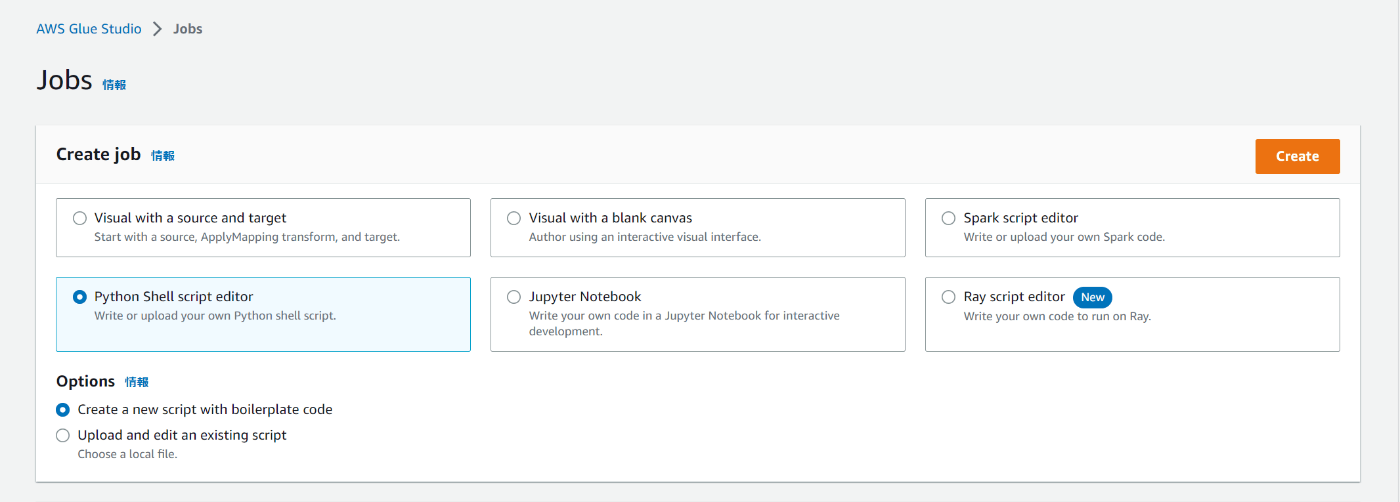
Create jobで「Python Shell script editor」を選択
-
Optionsで「Create a new script with boilerplate code」を選択
-
Script
import time
def test_func(i, start):
time.sleep(3)
return f"process {i}:{time.time()- start} "
start = time.time()
result_list = [test_func(i,start) for i in range(4)]
print(result_list)
print("time:", time.time() - start)
Python Shellで経過時間を図るスクリプトを作成します。
- Job details
⇒Name: 任意の名前
⇒IAM Role: 先ほど作成したIAMロール
⇒Python version: Python3.9
⇒Data processing units: 1DPU
⇒Job: parameters: 下記の値を入れる。
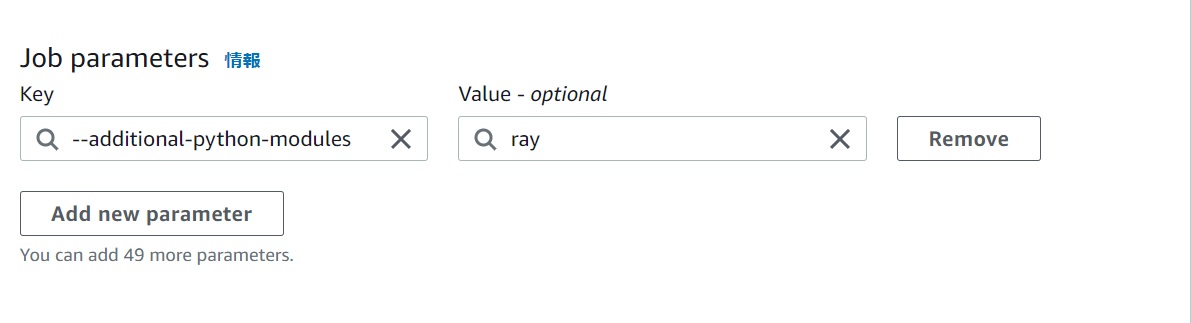
「--additional-python-modules」を指定して、Rayを追加します。
設定を保存したら、Runを実行します。
Runsの画面で結果を確認できます。
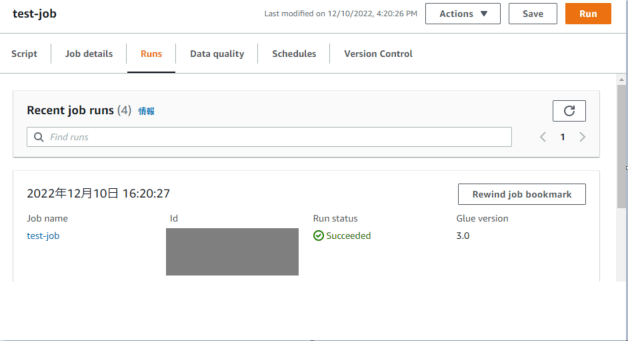
またCloudWatchに出力されたログも合わせて確認します。
['process 0:3.0030407905578613 ', 'process 1:6.006091117858887 ', 'process 2:9.009138584136963 ', 'process 3:12.012187957763672 ']
time: 12.012217283248901
3秒間Sleep処理をする関数を4回実行しているため、約12秒の時間がかかっています。
2. Rayを使ったコードに書き換える
GlueジョブのPythonスクリプトを書き換えます。
クイックスタートに下記のようなコードが載っています。
import ray
ray.init()
@ray.remote
def f(x):
return x * x
futures = [f.remote(i) for i in range(4)]
print(ray.get(futures)) # [0, 1, 4, 9]
例を参考にしながら今回のコードを置き換えてみます。
import ray
import time
@ray.remote
def test_func(i,start):
time.sleep(3)
return f"process {i}:{time.time()- start} "
ray.init()
start = time.time()
result_list = [test_func.remote(i,start) for i in range(4)]
print(ray.get(result_list))
print("time:", time.time() - start)
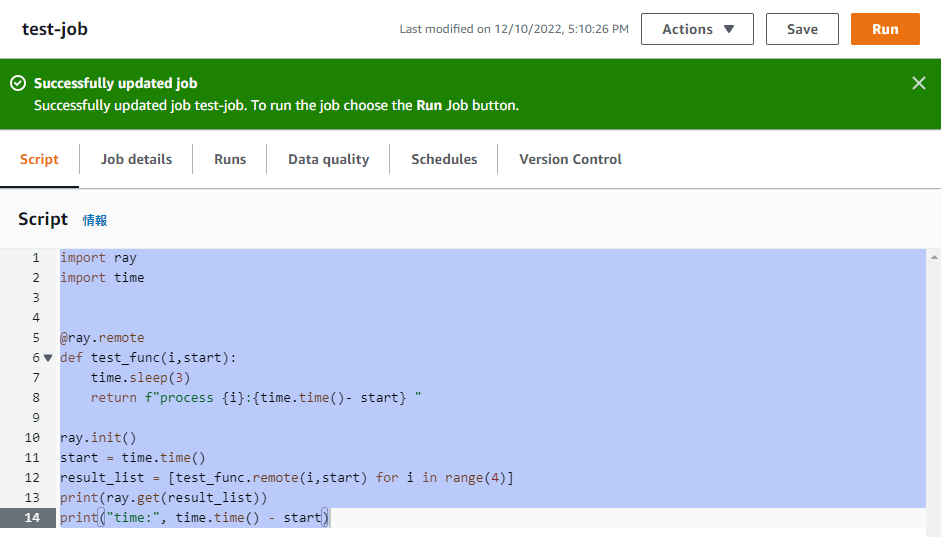
Runを実行後、CloudWatchログを確認します。
Successfully installed click-8.0.4 distlib-0.3.6 filelock-3.8.2 grpcio-1.51.1 jsonschema-4.17.3 msgpack-1.0.4 platformdirs-2.6.0 protobuf-4.21.11 pyrsistent-0.19.2 ray-2.1.0 virtualenv-20.17.1
まずrayがインストールされています。
['process 0:3.0150182247161865 ', 'process 1:3.0229310989379883 ', 'process 2:3.0116465091705322 ', 'process 3:3.022773504257202 ']
time: 3.023655891418457
4つの処理がほぼ同時並行で、実行完了していることが分かります。
3. AWS Glue for Rayを使用したジョブ実行
ではプレビュー版のAWS Glue for Rayで、同様の処理を実行します。

コードは前回と同じ内容で記述します。
import ray
import time
@ray.remote
def test_func(i,start):
time.sleep(3)
return f"process {i}:{time.time()- start} "
ray.init()
start = time.time()
result_list = [test_func.remote(i,start) for i in range(4)]
print(ray.get(result_list))
print("time:", time.time() - start)
ジョブの「Create job」で「Ray script editor」を選択します。
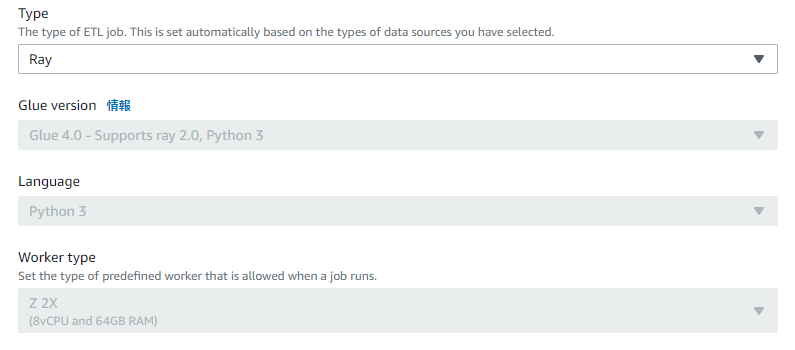
Job detailsは、基本的にPython Shell Scriptと変わりませんが、設定値が固定されている部分があります。

ジョブパラメータの設定は行わず、次に進みます。
設定を保存して、Runを実行します。
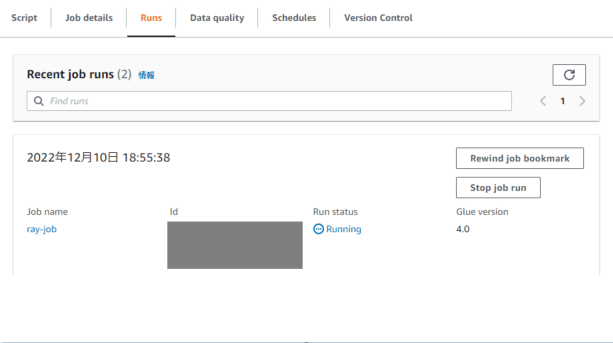
処理が成功したら、CloudWatch Logsでログを確認します。
2022-12-10 09:55:57,061 - __main__ - INFO - ['process 0:3.6782989501953125 ', 'process 1:3.6758944988250732 ', 'process 2:3.7317874431610107 ', 'process 3:3.801825761795044 ']
time: 3.802616596221924
処理時間はほぼ変わりませんが、特にジョブパラメータの設定等無しで、簡単にジョブを作成/実行できました。
参考
短い動作検証ですが、重い処理を行う場面で役に立ちそうです。
実際にS3バケットに約 400 MB (約 800 万行) 分のcsvファイルを置いて、読み込みを行いました。
multiprocessing等の並列的なライブラリを使用しないPythonコード: 19.58秒
Ray: 6.45秒
勿論コードの書き方によって変わる部分は出てくると思いますが、Rayを使うことでシンプルに処理時間の軽減を実現することができました。
また機会があればテスト用データを用いた検証の手順をアップできればと思います。
以上です。
MEGAZONEはAWS プレミアティア サービスパートナーとして多数のCompetencyを取得しており、大企業、ゲーム会社、スタートアップ、公共機関などさまざまな分野の5,000以上のお客様にAWSソリューションとサービスを提供しています。
Discussion