🖼
複数のカテゴリーやクラスタリング結果を組み合わせて散布図で表示してみた

クラスタリングやカテゴリーの分布を確認するのに散布図を使うことが多いですが、複数組み合わせて表示できるかどうかを試してみたのでまとめます。
具体的にはこんな感じです。

GitHub はこちら、Google Colab はこちら。
![]()
シンプルな散布図
plt.figure(figsize=(10, 6))
plt.scatter(
df["G1"],
df["G2"]
)

カテゴリデータ(性別)で散布図を表示
sex_list = df["sex"].unique()
plt.figure(figsize=(10, 6))
for i in range(len(sex_list)):
temp_df = df[df["sex"]==sex_list[i]]
plt.scatter(
temp_df["G1"],
temp_df["G2"],
c = [cmap(i)],
label=sex_list[i]
)
plt.legend()

年代でbin分けして散布図を表示
まずは age カテゴリの分布を確認します。
df["age"].hist()
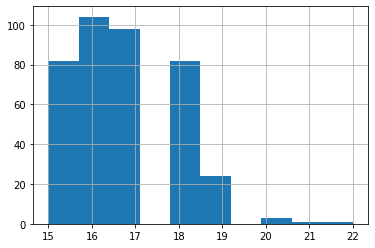
# 年代をbin分
df["era"] = pd.cut(df["age"], [14, 16, 18, 20, 22], labels=["14-16", "16-18", "18-20", "20-22"])
https://note.nkmk.me/python-pandas-cut-qcut-binning/
era_list = df["era"].unique()
plt.figure(figsize=(10, 6))
for i in range(len(era_list)):
temp_df = df[df["era"]==era_list[i]]
plt.scatter(
temp_df["G1"],
temp_df["G2"],
c = [cmap(i)],
label=era_list[i]
)
plt.legend()

クラスタリング
k-means法をつかいます。
k = 4
# one-hot-encoding
df_dummy = pd.get_dummies(df)
# k-means法によるクラスタリング
kmeans_model = KMeans(n_clusters=k, random_state=42).fit(df_dummy)
labels = kmeans_model.labels_
df["category"] = labels
label_list = np.unique(labels)
plt.figure(figsize=(10, 6))
for i in range(len(label_list)):
temp_df = df[df["category"]==label_list[i]]
plt.scatter(
temp_df["G1"],
temp_df["G2"],
c = [cmap(i)],
label=label_list[i]
)
plt.legend()

3つを統合する
性別が2区分、年代が4区分、クラスタリングが4区分で32の組み合わせができます。
それぞれの組み合わせごとにカラーマップを使って別の色になるように下記のようにします。
num = len(label_list) * len(era_list) * i + len(era_list)*j + k
また、カラーマップ matplotlib.colors.CSS4_COLORS は辞書型なのでそのまま使うと数字で切り替えられません。
そこでDataFrameにします。
cmap = pd.DataFrame(matplotlib.colors.CSS4_COLORS.items())[1]
# 148色のカラーマップをDataFrame化
cmap = pd.DataFrame(matplotlib.colors.CSS4_COLORS.items())[1]
plt.figure(figsize=(10, 6))
for i in range(len(sex_list)):
temp_df_1 = df[df["sex"]==sex_list[i]]
for j in range(len(era_list)):
temp_df_2 = temp_df_1[temp_df_1["era"]==era_list[j]]
for k in range(len(label_list)):
temp_df_3 = temp_df_2[temp_df_2["category"]==label_list[k]]
num = len(label_list) * len(era_list) * i + len(era_list)*j + k
plt.scatter(
temp_df_3["G1"],
temp_df_3["G2"],
c = cmap[num],
label=[sex_list[i], era_list[j], label_list[k]]
)
plt.legend(bbox_to_anchor=(1.05, 1), ncol = 2)
以上になります、最後までお読みいただきありがとうございました。
参考サイト
Discussion