0. はじめに
Meduranceエンジニアの深田翔です。本記事では、AWSから公開されたOSSのAIエージェントSDK「Strands Agents」の主要機能を実際に触ってみた内容をまとめました。
公式サイトのユーザーガイドから特に重要と思われる機能をピックアップして説明して触りました。詳細な仕様や最新情報は公式ドキュメントを参照ください。
本記事では主に以下の内容を紹介します:
- Strands Agentsの基本概念とAgent Loop
- エージェントの基本的な使い方とプロンプト設定
- セッション管理(ローカル/S3/カスタムDB)とその戦略
- Hooksによるコールバック設定
- 構造化出力(Pydantic)
- Toolsの実装(Python関数/MCP)
- マルチエージェントパターン(Agent as Tools/Swarm/Graph/Workflow)
なお、今回の記事の内容を入れたリポジトリについても公開してるので、あわせてご確認ください。
1. Strands Agentsとは?
Strands AgentsはAWSから公開されたOSSのAIエージェントSDKです。LangChain、LangGraph、AutoGenなどの既存フレームワークと同様にAIエージェントを構築できますが、Strands Agentsの特徴は「AIモデル + ツール」を前提とした設計により、非常に少ないコード量でシンプルにエージェントを作成できる点にあります。
Agent Loopについて
そして、Strands Agentsの中核となる概念がAgent Loopです。これはStrandsエージェントが以下のような形のサイクルで動作するプロセスを意味します。
- ユーザーの入力を受け取る:タスクや質問が与えられる
- LLMが次のアクションを決定:応答を返すか、ツールを使用するかを判断
- ツールの実行:必要に応じて外部ツール(Pythonツール・MCPツール等)を実行
- 結果をLLMに返す:ツールの実行結果をコンテキストに追加
- ステップ2-4を繰り返す:目標達成まで継続
- 最終応答を返す:タスク完了
この一連の循環プロセスにより、エージェントは複雑なタスクを段階的に解決できます。
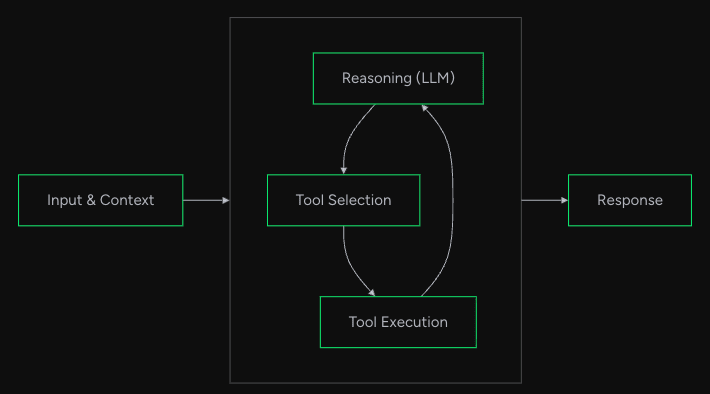
画像引用元:Strands Agents公式サイト
2. エージェントを動かしてみる
では、実際にStrands Agentsをローカル環境で試してみます。
2.1. 基本的な実行
まず、Strands Agentsをインストールします。
uv add strands-agents
デフォルトではAWS Bedrockのモデルで動作するため、事前に以下の準備が必要です
- AWS Bedrockでモデルを有効化
- たとえばこちらの記事などを参考にしてください。
- AWS認証情報の設定(Access Key IDとSecret Access Key)
- AWS_ACCESS_KEY_IDとAWS_SECRET_ACCESS_KEYに環境変数として設定してください
- S3とBedrockへのアクセス権限(S3は後々のセッション管理で使用します)
そして以下のように最小限の実装をしてみましょう。
from strands import Agent
agent = Agent()
agent("AIエージェントについて教えてください")
from strands import Agent
from strands.models.bedrock import BedrockModel
agent = Agent(
model=BedrockModel(
model_id="us.anthropic.claude-sonnet-4-20250514-v1:0",
region_name="us-east-1"
),
)
agent("AIエージェントについて教えてください")
なお、明示的に指定していない場合us.anthropic.claude-sonnet-4-20250514-v1:0(2025/10/02現在)が指定されます。
実行すると、コンソールにエージェントの応答が表示されます
.venv ❯ uv run python -m strands_agents_hands_on.examples.01_basic.agent
AIエージェントについて説明します。
## AIエージェントとは
AIエージェントは、環境を認識し、目標を達成するために自律的に行動する人工知能システムです。単純な質問応答を超えて、複雑なタスクを計画・実行できます。
..........
わずか3行(設定を除く)でエージェントが作成できました。質問内容にモデルがちゃんと答えてくれました。
2.2. プロンプト
2.2.1. システムプロンプト
エージェント作成時にシステムプロンプトを設定することで、会話全体を通してモデルの動作を制御できます。
from strands import Agent
agent = Agent(
system_prompt="日本語の質問に対して英語で回答してください。"
)
agent("AIエージェントについて教えてください")
実行結果:
.venv ❯ uv run python -m strands_agents_hands_on.examples.01_basic.custom_system_prompt
AI agents are software systems that can perceive their environment, make decisions,
and take actions to achieve specific goals autonomously or semi-autonomously.
## Key Characteristics of AI Agents:
....
システムプロンプトにより、日本語の質問に対して英語で回答してくれました。なお、システムプロンプトを指定しない場合は、指定したモデルのデフォルト設定に従って動作します。
2.2.2. マルチ画面プロンプト
画像などのマルチ画面なプロンプトも渡すことができます。以下は、2つの画像を比較する例です(いらすとやの画像を使用させていただきました)。
agentにimage typeを指定して渡せばOKです。
from pathlib import Path
from strands import Agent
agent = Agent()
image1_path = Path("data/images/image1.png")
image2_path = Path("data/images/image2.png")
with image1_path.open("rb") as fp:
image1_bytes = fp.read()
with image2_path.open("rb") as fp:
image2_bytes = fp.read()
response = agent(
[
{"text": "これら2つの画像を比較して、違いを説明してください"},
{"image": {"format": "png", "source": {"bytes": image1_bytes}}},
{"image": {"format": "png", "source": {"bytes": image2_bytes}}},
]
)
このコードを実行すると以下のような結果になります。
.venv ❯ uv run python -m strands_agents_hands_on.examples.01_basic.multimodal_prompt
これら2つの画像を比較すると、以下の違いがあります:
## 服装の違い
**1枚目の画像:**
- 男性:青色のTシャツ
- 女性:青色のTシャツ
**2枚目の画像:**
- 男性:白色のシャツ(襟付き)
- 女性:白色のシャツに赤いリボン
.....
画像解析が正しく動作していることが確認できます。
公式ドキュメントによると、以下のコンテンツタイプがサポートされています。主にはtext、image、document、videoを使用することになるのかなと思います。以下はそれぞれのタイプに応じた渡し方の最小サンプルです。
1. テキスト(text)
agent("これはテキストです")
# または
agent([{"text": "これはテキストです"}])
2. 画像(image)
with open("image.png", "rb") as f:
image_bytes = f.read()
agent([
{"text": "この画像を分析してください"},
{
"image": {
"format": "png", # "png" | "jpeg" | "gif" | "webp"
"source": {"bytes": image_bytes}
}
}
])
3. ドキュメント(document)
ドキュメントについてpdfをはじめとしてcsvやdocx,xlsx等ms系のドキュメントも投入できます。
with open("document.pdf", "rb") as f:
doc_bytes = f.read()
agent([
{"text": "このドキュメントを要約してください"},
{
"document": {
"format": "pdf", # "pdf" | "csv" | "doc" | "docx" | "xls" | "xlsx" | "html" | "txt" | "md"
"name": "document.pdf",
"source": {"bytes": doc_bytes}
}
}
])
4. ビデオ(video)
with open("video.mp4", "rb") as f:
video_bytes = f.read()
agent([
{"text": "このビデオの内容を説明してください"},
{
"video": {
"format": "mp4", # "flv" | "mkv" | "mov" | "mpeg" | "mpg" | "mp4" | "three_gp" | "webm" | "wmv"
"source": {"bytes": video_bytes}
}
}
])
IF整備されていて扱いやすいですね。
2.3. モデルプロバイダ設定
Strands Agentsでは、AWS Bedrock以外にも複数のモデルプロバイダがサポートされています。OpenAI、Anthropic、Llamaなどに加え、カスタムモデルプロバイダも指定可能です。
ここではOpenAIを使用する例を紹介します。(他のプロバイダの場合も同じような流れになると思います。)
まず依存関係を追加します
uv add "strands-agents[openai]" strands-agents-tools
その後、以下のようにmodelインスタンスを作成してagentのmodelとして指定します。たとえば、OpenAIModelでgpt5系列を指定する場合はparamsとしてreasoning_effort等openai側のapiで用意されているパラメータを指定できます。
また、OPENAI_API_KEY環境変数としてAPIキーを設定しておけば明示的に渡さずとも勝手に取得してくれます。
from strands import Agent
from strands.models.openai import OpenAIModel
model = OpenAIModel(
model_id="gpt-5-mini",
params={
"reasoning_effort": "minimal"
}
)
agent = Agent(model=model)
response = agent("AIエージェントについて教えてください")
APIキーを明示的に指定する場合は以下のようにclient_args内で渡せばOKです。
from strands import Agent
from strands.models.openai import OpenAIModel
from strands_agents_hands_on.config import Settings
settings = Settings()
model = OpenAIModel(
client_args={
"api_key": settings.OPENAI_API_KEY,
},
model_id="gpt-5-mini",
params={
"reasoning_effort": "minimal"
}
)
agent = Agent(model=model)
response = agent("AIエージェントについて教えてください")
実行結果は以下のようになります。OpenAIのモデルでもちゃんと動作していることがわかります。
.venv ❯ uv run python -m strands_agents_hands_on.examples.01_basic.model_provider
もちろんです。AIエージェントについて、基本から応用まで分かりやすく説明します。
どのレベルまで知りたいか(入門、実装、応用事例、倫理・安全性など)教えていただければ、
それに合わせて詳しく説明します。ここではまず全体像と主要ポイントをまとめます。
1) AIエージェントとは
- 定義:環境から情報(観測)を受け取り、目標達成のために行動を選択・実行するソフトウェア
(あるいはロボット)。人工知能技術を用いて意思決定や学習を行なう。
- 構成要素:センサー(観測入力)、意思決定モジュール(ポリシー、プランナー)、
学習モジュール(強化学習やオンライン学習)、アクチュエータ(行動実行)、報酬・目的関数。
......
3. セッション管理
次に、会話履歴(セッション)の管理について解説します。Strands Agentsでは主に以下の3つのセッション管理システムが提供されています。
- FileSessionManager
- S3SessionManager
- CustomSessionManager
3.1. ローカルファイルシステム(FileSessionManager)
セッションをローカルファイルに保存して管理する方法です。session_idを使って1つの会話を管理します。(これは他の管理システムでも同様)
FileSessionManagerインスタンスを作成して、agentインスタンス作成時にsession_manager引数に渡せばOKです。以下に実装したコードを示します。
import sys
from strands import Agent
from strands.session.file_session_manager import FileSessionManager
MIN_ARGS = 2
SECOND_ARG_INDEX = 2
if len(sys.argv) < MIN_ARGS:
print("Error: session_id が必要です")
print("Usage: python -m strands_agents_hands_on.examples.02_session.local_session_management <session_id> [second]")
sys.exit(1)
session_id = sys.argv[1]
session_manager = FileSessionManager(
session_id=session_id,
storage_dir="./data/sessions",
)
agent = Agent(session_manager=session_manager)
if len(sys.argv) > SECOND_ARG_INDEX and sys.argv[SECOND_ARG_INDEX] == "second":
print(f"=== 2回目の実行 (session_id: {session_id}) ===")
response = agent("さっき私が教えた数字は何でしたか?")
else:
# 1回目の実行: 情報を伝える
print(f"=== 1回目の実行 (session_id: {session_id}) ===")
response = agent("私の好きな数字は42です。覚えておいてください。")
print("\n次に 'second' 引数をつけて実行してセッション永続化をテストしてください:")
print(f"uv run python -m strands_agents_hands_on.examples.02_session.local_session_management {session_id} second")
引数指定でsession_idだけ指定した場合自分の好きな数字が42であることを伝え、引数としてさらにsecondを渡すことで前の会話でユーザーが何を話したかを問うようにしており、順次実行することでセッション管理がちゃんとできているかを確認できます。実行結果は以下です。
.venv ❯ uv run python -m strands_agents_hands_on.examples.02_session.local_session_management user-123
=== 1回目の実行 (session_id: user-123) ===
はい、あなたの好きな数字が42だということを覚えておきます。
42は「銀河ヒッチハイク・ガイド」で「生命、宇宙、そして万物についての究極の疑問の答え」
として有名な数字ですね。何か特別な理由があってこの数字がお気に入りなのでしょうか?
......
.venv ❯ uv run python -m strands_agents_hands_on.examples.02_session.local_session_management user-123 second
=== 2回目の実行 (session_id: user-123) ===
あなたが教えてくださった好きな数字は42でした。
会話履歴をもとにエージェントが回答していることが確認できます。内部の動作を気にせずセッション管理ができるのは便利ですね。
※保存されるファイル構造について
セッションはstorage_dirで指定したディレクトリ以下に以下のような構造でファイルが保存されます
sessions/
└── session_user-123
├── agents
│ └── agent_default
│ ├── messages
│ │ ├── message_0.json
│ │ ├── message_1.json
│ │ ├── message_2.json
│ │ └── message_3.json
│ └── agent.json
└── session.json
-
session.json: セッション一覧 -
session_<session_id>/: 各セッションのディレクトリ -
agent.json: 会話履歴の管理方法(SlidingWindowConversationManager等)などの設定- 会話履歴の管理方法の種類については後ほど説明します
{
"agent_id": "default",
"state": {},
"conversation_manager_state": {
"__name__": "SlidingWindowConversationManager",
"removed_message_count": 0
},
"created_at": "2025-10-01T03:34:45.611622+00:00",
"updated_at": "2025-10-01T03:35:02.523901+00:00"
}
そして、セッションのディレクトリ内にユーザーとエージェントのメッセージがそれぞれJSONファイルとして作成されます。(message_n.json)
3.2. S3(S3SessionManager)
AWSのサーバーレス構成でエージェントをホスティングする場合、ローカルファイルシステムではなくS3に保存したいケースがもちろん出てくると思います。Strands AgentsではS3への会話履歴保存もサポートされています。実際に試してみましょう。
3.2.1. 事前準備
事前準備として以下を行なってください。
-
S3バケットを作成(例:
strands-agents-hands-on) -
boto3をインストール:
uv add boto3 -
Strands Agentsを実行するIAMユーザーにS3へのアクセスポリシーを付与(すでにポリシー付与されたロールの場合は不要)
3.2.2. 実装
ローカルの場合とほとんど同じで、セッションマネージャーをS3SessionManagerに切り替えるだけです:
import sys
import boto3
from strands import Agent
from strands.session.s3_session_manager import S3SessionManager
if len(sys.argv) < 2:
print("Error: session_id が必要です")
print("Usage: python -m strands_agents_hands_on.examples.02_session.s3_session_management <session_id> [second]")
sys.exit(1)
session_id = sys.argv[1]
boto_session = boto3.Session(region_name="us-east-1")
session_manager = S3SessionManager(
session_id=session_id,
bucket="strands-agents-hands-on",
prefix="sessions",
boto_session=boto_session,
region_name="us-east-1",
)
agent = Agent(session_manager=session_manager)
if len(sys.argv) > 2 and sys.argv[2] == "second":
print(f"=== 2回目の実行 (session_id: {session_id}) ===")
response = agent("さっき私が教えた数字は何でしたか?")
else:
print(f"=== 1回目の実行 (session_id: {session_id}) ===")
response = agent("私の好きな数字は42です。覚えておいてください。")
print(f"\n次に 'second' 引数をつけて実行してセッション永続化をテストしてください:")
print(f"uv run python -m strands_agents_hands_on.examples.02_session.s3_session_management {session_id} second")
実行結果は以下のようになります。
.venv ❯ uv run python -m strands_agents_hands_on.examples.02_session.s3_session_management user-123
=== 1回目の実行 (session_id: user-123) ===
はい、あなたの好きな数字が42だということを覚えておきます。
42は「銀河ヒッチハイク・ガイド」で「生命、宇宙、そして万物についての究極の疑問の答え」
として有名な数字ですね。何か特別な理由でこの数字がお好きなのでしょうか?
.......
.venv ❯ uv run python -m strands_agents_hands_on.examples.02_session.s3_session_management user-123 second
=== 2回目の実行 (session_id: user-123) ===
あなたが教えてくださった好きな数字は42でした。
S3でもしっかり会話履歴をもとに回答できています。また、S3の場合でもローカルと同じファイル構造で保存されます。
sessions/
└── session_user-123
├── agents
│ └── agent_default
│ ├── messages
│ │ ├── message_0.json
│ │ ├── message_1.json
│ │ ├── message_2.json
│ │ └── message_3.json
│ └── agent.json
└── session.json
3.3. カスタム(CustomSessionRepository)
データベースにセッション内容を保存したい場合は、SessionRepositoryを継承し、create_session,read_session,create_agentなどのメソッドをオーバーライドして実装します。ここではSQLiteに保存する例を紹介します。
import json
import sqlite3
import sys
from datetime import UTC, datetime
from pathlib import Path
from typing import Any
from strands import Agent
from strands.session.repository_session_manager import RepositorySessionManager
from strands.session.session_repository import SessionRepository
from strands.types.content import Message
from strands.types.session import Session, SessionAgent, SessionMessage, SessionType
class SQLiteSessionRepository(SessionRepository):
"""SQLite-based session repository implementation."""
def __init__(self, db_path: str = "sessions.db") -> None:
"""Initialize SQLite session repository.
Args:
db_path: Path to the SQLite database file
"""
self.db_path = db_path
self._init_database()
def _init_database(self) -> None:
"""Initialize database tables if they don't exist."""
with sqlite3.connect(self.db_path) as conn:
cursor = conn.cursor()
# Sessions table
cursor.execute("""
CREATE TABLE IF NOT EXISTS sessions (
session_id TEXT PRIMARY KEY,
session_type TEXT NOT NULL,
created_at TEXT NOT NULL,
updated_at TEXT NOT NULL
)
""")
# Agents table
cursor.execute("""
CREATE TABLE IF NOT EXISTS agents (
agent_id TEXT NOT NULL,
session_id TEXT NOT NULL,
state TEXT NOT NULL,
conversation_manager_state TEXT NOT NULL,
created_at TEXT NOT NULL,
updated_at TEXT NOT NULL,
PRIMARY KEY (session_id, agent_id),
FOREIGN KEY (session_id) REFERENCES sessions (session_id)
)
""")
# Messages table
cursor.execute("""
CREATE TABLE IF NOT EXISTS messages (
session_id TEXT NOT NULL,
agent_id TEXT NOT NULL,
message_id INTEGER NOT NULL,
message TEXT NOT NULL,
redact_message TEXT,
created_at TEXT NOT NULL,
updated_at TEXT NOT NULL,
PRIMARY KEY (session_id, agent_id, message_id),
FOREIGN KEY (session_id, agent_id) REFERENCES agents (session_id, agent_id)
)
""")
# Create indexes for better query performance
cursor.execute("""
CREATE INDEX IF NOT EXISTS idx_messages_session_agent
ON messages (session_id, agent_id)
""")
cursor.execute("""
CREATE INDEX IF NOT EXISTS idx_agents_session_id
ON agents (session_id)
""")
conn.commit()
# Session methods
def create_session(self, session: Session, **_kwargs: Any) -> Session:
"""Create a new session."""
with sqlite3.connect(self.db_path) as conn:
cursor = conn.cursor()
cursor.execute(
"""
INSERT INTO sessions (session_id, session_type, created_at, updated_at)
VALUES (?, ?, ?, ?)
""",
(
session.session_id,
session.session_type.value,
session.created_at or datetime.now(UTC).isoformat(),
session.updated_at or datetime.now(UTC).isoformat(),
),
)
conn.commit()
return session
def read_session(self, session_id: str, **_kwargs: Any) -> Session | None:
"""Read a session by ID."""
with sqlite3.connect(self.db_path) as conn:
cursor = conn.cursor()
cursor.execute(
"""
SELECT session_id, session_type, created_at, updated_at
FROM sessions
WHERE session_id = ?
""",
(session_id,),
)
row = cursor.fetchone()
if row:
return Session(
session_id=row[0],
session_type=SessionType(row[1]),
created_at=row[2],
updated_at=row[3],
)
return None
# Agent methods
def create_agent(self, session_id: str, session_agent: SessionAgent, **_kwargs: Any) -> None:
"""Create a new agent."""
with sqlite3.connect(self.db_path) as conn:
cursor = conn.cursor()
cursor.execute(
"""
INSERT INTO agents (agent_id, session_id, state, conversation_manager_state, created_at, updated_at)
VALUES (?, ?, ?, ?, ?, ?)
""",
(
session_agent.agent_id,
session_id,
json.dumps(session_agent.state),
json.dumps(session_agent.conversation_manager_state),
session_agent.created_at or datetime.now(UTC).isoformat(),
session_agent.updated_at or datetime.now(UTC).isoformat(),
),
)
conn.commit()
def read_agent(self, session_id: str, agent_id: str, **_kwargs: Any) -> SessionAgent | None:
"""Read an agent by ID."""
with sqlite3.connect(self.db_path) as conn:
cursor = conn.cursor()
cursor.execute(
"""
SELECT agent_id, state, conversation_manager_state, created_at, updated_at
FROM agents
WHERE session_id = ? AND agent_id = ?
""",
(session_id, agent_id),
)
row = cursor.fetchone()
if row:
return SessionAgent(
agent_id=row[0],
state=json.loads(row[1]),
conversation_manager_state=json.loads(row[2]),
created_at=row[3],
updated_at=row[4],
)
return None
def update_agent(self, session_id: str, session_agent: SessionAgent, **_kwargs: Any) -> None:
"""Update an existing agent."""
with sqlite3.connect(self.db_path) as conn:
cursor = conn.cursor()
cursor.execute(
"""
UPDATE agents
SET state = ?, conversation_manager_state = ?, updated_at = ?
WHERE session_id = ? AND agent_id = ?
""",
(
json.dumps(session_agent.state),
json.dumps(session_agent.conversation_manager_state),
datetime.now(UTC).isoformat(),
session_id,
session_agent.agent_id,
),
)
conn.commit()
# Message methods
def create_message(self, session_id: str, agent_id: str, session_message: SessionMessage, **_kwargs: Any) -> None:
"""Create a new message."""
with sqlite3.connect(self.db_path) as conn:
cursor = conn.cursor()
cursor.execute(
"""
INSERT INTO messages (session_id, agent_id, message_id, message, redact_message, created_at, updated_at)
VALUES (?, ?, ?, ?, ?, ?, ?)
""",
(
session_id,
agent_id,
session_message.message_id,
json.dumps(dict(session_message.message)),
json.dumps(dict(session_message.redact_message)) if session_message.redact_message else None,
session_message.created_at or datetime.now(UTC).isoformat(),
session_message.updated_at or datetime.now(UTC).isoformat(),
),
)
conn.commit()
def read_message(self, session_id: str, agent_id: str, message_id: int, **_kwargs: Any) -> SessionMessage | None:
"""Read a message by ID."""
with sqlite3.connect(self.db_path) as conn:
cursor = conn.cursor()
cursor.execute(
"""
SELECT message_id, message, redact_message, created_at, updated_at
FROM messages
WHERE session_id = ? AND agent_id = ? AND message_id = ?
""",
(session_id, agent_id, message_id),
)
row = cursor.fetchone()
if row:
return SessionMessage(
message_id=row[0],
message=Message(**json.loads(row[1])),
redact_message=Message(**json.loads(row[2])) if row[2] else None,
created_at=row[3],
updated_at=row[4],
)
return None
def update_message(self, session_id: str, agent_id: str, session_message: SessionMessage, **_kwargs: Any) -> None:
"""Update an existing message."""
with sqlite3.connect(self.db_path) as conn:
cursor = conn.cursor()
cursor.execute(
"""
UPDATE messages
SET message = ?, redact_message = ?, updated_at = ?
WHERE session_id = ? AND agent_id = ? AND message_id = ?
""",
(
json.dumps(dict(session_message.message)),
json.dumps(dict(session_message.redact_message)) if session_message.redact_message else None,
datetime.now(UTC).isoformat(),
session_id,
agent_id,
session_message.message_id,
),
)
conn.commit()
def list_messages(
self,
session_id: str,
agent_id: str,
limit: int | None = None,
offset: int = 0,
**_kwargs: Any,
) -> list[SessionMessage]:
"""List messages for a session."""
with sqlite3.connect(self.db_path) as conn:
cursor = conn.cursor()
query = """
SELECT message_id, message, redact_message, created_at, updated_at
FROM messages
WHERE session_id = ? AND agent_id = ?
ORDER BY message_id ASC
LIMIT ? OFFSET ?
"""
# SQLite requires explicit limit, use -1 for no limit
actual_limit = limit if limit is not None else -1
cursor.execute(query, (session_id, agent_id, actual_limit, offset))
rows = cursor.fetchall()
return [
SessionMessage(
message_id=row[0],
message=Message(**json.loads(row[1])),
redact_message=Message(**json.loads(row[2])) if row[2] else None,
created_at=row[3],
updated_at=row[4],
)
for row in rows
]
if __name__ == "__main__":
if len(sys.argv) < 2:
print("Error: session_id が必要です")
print("Usage: python -m strands_agents_hands_on.examples.02_session.custom_session_management <session_id> [second]")
sys.exit(1)
session_id = sys.argv[1]
# SQLiteセッションリポジトリを作成
db_path = "data/sessions.db"
Path("data").mkdir(exist_ok=True)
sqlite_repo = SQLiteSessionRepository(db_path=db_path)
# カスタムリポジトリを使ってセッションマネージャーを作成
session_manager = RepositorySessionManager(
session_id=session_id,
session_repository=sqlite_repo,
)
# エージェントを作成
agent = Agent(session_manager=session_manager)
# 1回目と2回目の実行を切り替え
if len(sys.argv) > 2 and sys.argv[2] == "second":
# 2回目の実行: 会話履歴を参照する質問
print(f"=== 2回目の実行 (session_id: {session_id}) ===")
response = agent("さっき私が教えた数字は何でしたか?")
else:
# 1回目の実行: 情報を伝える
print(f"=== 1回目の実行 (session_id: {session_id}) ===")
response = agent("私の好きな数字は42です。覚えておいてください。")
print(f"\n次に 'second' 引数をつけて実行してセッション永続化をテストしてください:")
print(f"uv run python -m strands_agents_hands_on.examples.02_session.custom_session_management {session_id} second")
print(f"\nセッションデータの保存先: {db_path}")
print("データベースの確認: sqlite3 data/sessions.db")
後半部のmain関数はlocal,s3のコードと同じです。SQLiteSessionRepositoryについてはinit時にテーブルの作成を行ない、SessionRepositoryの抽象メソッドをオーバーライドしてSQLiteへのCRUD操作を実装しています。具体的には、セッション/Agent/Messageの作成・読み取り・更新・一覧取得の各メソッドで、SQLiteへの接続とSQL実行を行ない、StrandsAgentsが必要とするデータの永続化を実現しています。これによりRepositorySessionManagerにカスタムリポジトリを渡すだけで、セッションマネージャーとして利用できます。
実行結果は以下のようになります。
.venv ❯ uv run python -m strands_agents_hands_on.examples.02_session.custom_session_management user-123
=== 1回目の実行 (session_id: user-123) ===
承知いたしました。あなたの好きな数字は42ですね。覚えておきます。
42は「銀河ヒッチハイク・ガイド」で「生命、宇宙、そして万物についての究極の疑問の答え」
として有名な数字でもありますね。何か特別な理由があってこの数字がお気に入りなのでしょうか?
.....
セッションデータの保存先: data/sessions.db
データベースの確認: sqlite3 data/sessions.db
.venv ❯ uv run python -m strands_agents_hands_on.examples.02_session.custom_session_management user-123 second
=== 2回目の実行 (session_id: user-123) ===
あなたが教えてくださった好きな数字は42でした。
ローカルやS3の時と同じように動作していることが確認できました。またSQLiteの中にも会話情報やエージェント情報が格納されていることが確認できると思います。
3.4. セッション管理戦略について
3.1〜3.3では会話履歴の保存場所について説明しました。ここでは、会話履歴の保持戦略について解説します。主に以下の3種類があります:
- NullConversationManager: 履歴を変更せずに保持
- SlidingWindowConversationManager(デフォルト): 固定数のメッセージを保持
- SummarizingConversationManager: 古いメッセージを要約して保持
3.4.1. NullConversationManager
会話履歴をそのまま変更せずに保持する戦略です。
from strands import Agent
from strands.conversation_management import NullConversationManager
agent = Agent(
conversation_manager=NullConversationManager()
)
短い会話では問題ありませんが、長時間保持するとモデルのcontext windowに収まらなくなったり、過去の不要な会話まですべて入力に含めてしまい精度が落ちたりする可能性があります。
3.4.2. SlidingWindowConversationManager
直近の固定数のメッセージを保持する戦略です。Strands Agentsではデフォルトでこれが指定されています。
指定した画面サイズを新しい会話の方向にスライドしていくイメージです。画面サイズを超えたメッセージは自動削除されるため、context windowに収まり、直近の履歴を参照した出力が得られます。ただし、古い会話情報は失われるため、会話の流れを汲み取れない回答になる可能性もあります。
from strands import Agent
from strands.conversation_management import SlidingWindowConversationManager
agent = Agent(
conversation_manager=SlidingWindowConversationManager(
window_size=10, # 保持するメッセージ数
should_truncate_results=True # ツール結果を切り詰めるか
)
)
3.4.3. SummarizingConversationManager
古いメッセージを要約して管理する戦略です。Claude Codeとかでもcompactセッションとかがたまに走ると思います。あれと同じような感じです。(厳密にはもっと高度なことをClaude Codeはしていると思いますが...)
from strands import Agent
from strands.conversation_management import SummarizingConversationManager
agent = Agent(
conversation_manager=SummarizingConversationManager(
summary_ratio=0.3, # 要約する割合(30%)
preserve_recent_messages=5 # 完全な形で保持する直近のメッセージ数
)
)
エージェントと何度も会話ラリーをする場合、この戦略を使うと履歴が失われず、かつcontext window内に収めながら処理できるため効果的です。
4. Hooks
Hooksは、エージェントのライフサイクルの特定のタイミングで処理を挟むための仕組みです。以下のようなユースケースに対応できます
- エージェント実行のログ出力
- ツール実行の挙動変更
- バリデーションやエラーハンドリングの追加
4.1. シンプルなHook登録
以下のようにして特定のイベントに対してコールバック関数を登録できます。
from strands import Agent
from strands.hooks import BeforeInvocationEvent, AfterInvocationEvent
agent = Agent()
def before_invocation_callback(event: BeforeInvocationEvent) -> None:
print(f"エージェント呼び出し開始: {event.agent.name}")
def after_invocation_callback(event: AfterInvocationEvent) -> None:
print(f"エージェント呼び出し終了: {event.agent.name}")
agent.hooks.add_callback(BeforeInvocationEvent, before_invocation_callback)
agent.hooks.add_callback(AfterInvocationEvent, after_invocation_callback)
agent("AIエージェントについて教えてください")
実行結果を見るとエージェント実行前と後に適切にログが出力されていることがわかります。
.venv ❯ uv run python -m strands_agents_hands_on.examples.03_hooks.simple_hooks
エージェント呼び出し開始: Strands Agents
AIエージェントについて詳しく説明します。
......
エージェント呼び出し終了: Strands Agents
4.2. Hook Provider
各種Hookを1つのクラスで一元的に管理できます。HookProviderを継承して実装します。実用・可読性の観点からこちらの方が使用することが多いと思います。
from strands import Agent
from strands.hooks import AfterInvocationEvent, BeforeInvocationEvent, HookProvider, HookRegistry
agent = Agent()
class LoggingHook(HookProvider):
def register_hooks(self, registry: HookRegistry, **kwargs) -> None: # noqa: ANN003
registry.add_callback(BeforeInvocationEvent, self.before_invocation_callback)
registry.add_callback(AfterInvocationEvent, self.after_invocation_callback)
def before_invocation_callback(self, event: BeforeInvocationEvent) -> None:
print(f"エージェント呼び出し開始: {event.agent.name}")
def after_invocation_callback(self, event: AfterInvocationEvent) -> None:
print(f"エージェント呼び出し終了: {event.agent.name}")
agent.hooks.add_hook(LoggingHook())
agent("AIエージェントについて教えてください")
4.1と全く同じ動作になるため実行結果は省略します。
4.3. 登録できるイベントタイミングについて
Hooksとして登録できるイベントは主に以下になります。基本的なタイミングは網羅されているのかな、という印象です。
| イベント | タイミング |
|---|---|
BeforeInvocationEvent |
エージェントリクエスト開始時 |
AfterInvocationEvent |
エージェントリクエスト終了時 |
BeforeModelCallEvent |
モデル呼び出し前 |
AfterModelCallEvent |
モデル呼び出し後 |
BeforeToolCallEvent |
ツール実行前 |
AfterToolCallEvent |
ツール実行後 |
MessageAddedEvent |
メッセージが履歴に追加されたとき |
5. 構造化出力
個人的にLLMの出力を固定したいケースは多くあります。例えば、LLM出力を別の処理に流したい場合(REST APIのJSONとして返すなど)、自由度があると困ることがあります。Strands Agentsでは出力をPydanticモデルで受け取ることができる機能があります。
5.1. 基本的な使い方
Pydanticモデルを定義してagent.structured_outputにそれを渡すだけで、返り値がPydanticモデルに変わります。超シンプルにかけて便利ですね。
from pydantic import BaseModel, Field
from strands import Agent
class AIAgentInfo(BaseModel):
"""AIエージェントに関する情報"""
definition: str = Field(description="AIエージェントの定義")
key_features: list[str] = Field(description="主な特徴のリスト")
use_cases: list[str] = Field(description="具体的なユースケース")
benefits: list[str] = Field(description="導入メリット")
agent = Agent()
result = agent.structured_output(
AIAgentInfo,
"AIエージェントについて教えてください",
)
print("=== AIエージェント情報 ===")
print(f"\n【定義】\n{result.definition}")
print("\n【主な特徴】")
for feature in result.key_features:
print(f" - {feature}")
print("\n【ユースケース】")
for use_case in result.use_cases:
print(f" - {use_case}")
print("\n【メリット】")
for benefit in result.benefits:
print(f" - {benefit}")
今までagent()として呼んでいたものを、Pydanticモデル定義→agent.structured_outputにモデルを渡して実行、というだけです。resultはエディタ上でもAIAgentInfo型として型付きで解釈してくれます。
実行結果は以下のようになります。ちゃんと構造化して出力されていることが確認できます。
.venv ❯ uv run python -m strands_agents_hands_on.examples.04_structured_output.basic_structured_output
Tool #1: AIAgentInfo
=== AIエージェント情報 ===
【定義】
AIエージェントとは、.....
【ユースケース】
- カスタマーサポート:....
【メリット】
- 効率性の向上:....
5.2. マルチ画面入力との組み合わせ
マルチ画面な入力においても、出力を構造化固定できます。2.2.2節と5.1節の組み合わせをするだけです。
from pathlib import Path
from pydantic import BaseModel, Field
from strands import Agent
class ImageComparison(BaseModel):
"""2つの画像の比較結果"""
image1_description: str = Field(description="1枚目の画像の説明")
image2_description: str = Field(description="2枚目の画像の説明")
differences: list[str] = Field(description="2つの画像の違いのリスト")
similarities: list[str] = Field(description="2つの画像の共通点のリスト")
overall_assessment: str = Field(description="全体的な評価・まとめ")
agent = Agent()
image1_path = Path("data/images/image1.png")
image2_path = Path("data/images/image2.png")
with image1_path.open("rb") as fp:
image1_bytes = fp.read()
with image2_path.open("rb") as fp:
image2_bytes = fp.read()
result = agent.structured_output(
ImageComparison,
[
{"text": "これら2つの画像を比較して、違いを説明してください"},
{"image": {"format": "png", "source": {"bytes": image1_bytes}}},
{"image": {"format": "png", "source": {"bytes": image2_bytes}}},
],
)
print("=== 画像比較結果 ===")
print(f"\n【画像1の説明】\n{result.image1_description}")
print(f"\n【画像2の説明】\n{result.image2_description}")
print("\n【違い】")
for diff in result.differences:
print(f" - {diff}")
print("\n【共通点】")
for sim in result.similarities:
print(f" - {sim}")
print(f"\n【総合評価】\n{result.overall_assessment}")
実行結果は以下のようになります。こちらもしっかり構造化出力できていることがわかります。
.venv ❯ uv run python -m strands_agents_hands_on.examples.04_structured_output.multimodal_structured_output
Tool #1: ImageComparison
=== 画像比較結果 ===
【画像1の説明】
男女2人が相合傘を...
【画像2の説明】
同じく男女2人が相合傘を...
【違い】
- 男性の服装が...
【共通点】
- 2人とも...
【総合評価】
2つの画像は基本的に同じ...
6. Tools
次に、エージェントの機能拡張のためのツール機能を試します。Python関数やMCPをツールとして渡すことで、テキスト生成以外の処理を実行できるようにします。
6.1. Python Tool
まずは、シンプルなPython関数をツールとして渡してみます。@toolデコレータを使うことで、Python関数をツールに変換できます。それをエージェント初期化時にtools引数に渡せばOKです。
from strands import Agent, tool
@tool
def calculator(x: float, y: float, operation: str) -> float:
"""数値計算を実行するツール。
Args:
x: 第一オペランド
y: 第二オペランド
operation: 演算の種類 (add, subtract, multiply, divide)
Returns:
計算結果
Raises:
ValueError: 不正な演算子が指定された場合
ZeroDivisionError: ゼロ除算が発生した場合
"""
if operation == "add":
return x + y
if operation == "subtract":
return x - y
if operation == "multiply":
return x * y
if operation == "divide":
if y == 0:
raise ZeroDivisionError("ゼロで除算することはできません")
return x / y
msg = f"不正な演算子: {operation}"
raise ValueError(msg)
@tool
def temperature_converter(value: float, from_unit: str, to_unit: str) -> float:
"""温度単位を変換するツール。
Args:
value: 変換する温度の値
from_unit: 元の単位 (celsius, fahrenheit, kelvin)
to_unit: 変換先の単位 (celsius, fahrenheit, kelvin)
Returns:
変換後の温度
"""
if from_unit == "celsius":
celsius = value
elif from_unit == "fahrenheit":
celsius = (value - 32) * 5 / 9
elif from_unit == "kelvin":
celsius = value - 273.15
else:
msg = f"不正な単位: {from_unit}"
raise ValueError(msg)
if to_unit == "celsius":
return celsius
if to_unit == "fahrenheit":
return celsius * 9 / 5 + 32
if to_unit == "kelvin":
return celsius + 273.15
msg = f"不正な単位: {to_unit}"
raise ValueError(msg)
agent = Agent(tools=[calculator, temperature_converter])
print("=== 計算ツールの使用 ===")
result1 = agent("125掛ける37はいくつ")
print("=== 温度変換ツールの使用 ===")
result2 = agent("摂氏25度は華氏で何度")
print("=== 複数のツールを組み合わせた使用 ===")
result3 = agent("摂氏20度と30度の平均を華氏で教えて")
実行結果は以下のようになります。ちゃんとツールが実行されていることがわかります。計算が必要なところではcalculator, 温度の変換が必要なところではtemparature_converterが呼び出されています。エージェントが何をもとにしてどのツール使用を判断しているかついてはあとで少し説明します。
.venv ❯ uv run python -m strands_agents_hands_on.examples.05_tools.simple_python_tool
=== 計算ツールの使用 ===
125 × 37 を計算します。
Tool #1: calculator
125 × 37 = 4,625 です。=== 温度変換ツールの使用 ===
摂氏25度を華氏に変換します。
Tool #2: temperature_converter
摂氏25度は華氏77度です。=== 複数のツールを組み合わせた使用 ===
まず摂氏20度と30度の平均を計算し、その結果を華氏に変換します。
Tool #3: calculator
Tool #4: calculator
Tool #5: temperature_converter
摂氏20度と30度の平均は摂氏25度で、これを華氏に変換すると華氏77度です。
6.2. MCP ツールとの組み合わせ
Pythonツールに加えて、MCP (Model Context Protocol) ツールも利用できます。
ここでは、uvx で起動できる webfetch MCPを使用した例を紹介します。
まず、MCPサーバーとクライアントの定義を行ないます
fetch_mcp_client = MCPClient(
lambda: stdio_client(
StdioServerParameters(
command="uvx",
args=["mcp-server-fetch@latest"],
)
)
)
次に、このコンテキスト内でエージェントを作成し、MCPツールとして渡します。
今回の例では、ユーザーからのクエリに対して、webfetchで株価情報を取得→株価データの統計情報を分析するPythonツール→株価分析結果をmdとして整形して出力するpythonツール、という流れでエージェントが呼び出すことを期待しています。
"""
uv run python -m strands_agents_hands_on.examples.05_tools.mcp_and_python_tools
"""
from mcp import StdioServerParameters, stdio_client
from strands import Agent, tool
from strands.tools.mcp import MCPClient
@tool
def analyze_stock_data(prices: list[float], volumes: list[int] | None = None) -> dict:
"""株価データを分析して統計情報を返すツール。
Args:
prices: 株価のリスト
volumes: 取引量のリスト (オプション)
Returns:
株価の統計情報を含む辞書
"""
if not prices:
return {"error": "データがありません"}
result = {
"データ数": len(prices),
"最高値": f"${max(prices):.2f}",
"最安値": f"${min(prices):.2f}",
"平均株価": f"${sum(prices) / len(prices):.2f}",
"価格変動幅": f"${max(prices) - min(prices):.2f}",
"変動率": f"{((max(prices) - min(prices)) / min(prices) * 100):.2f}%",
}
if volumes:
result["平均取引量"] = f"{sum(volumes) / len(volumes):,.0f}"
result["総取引量"] = f"{sum(volumes):,}"
return result
@tool
def format_stock_report(analysis_data: dict, company_info: dict | None = None) -> str:
"""株価分析結果をMarkdown形式のレポートとして整形するツール。
Args:
analysis_data: 株価分析データの辞書
company_info: 企業情報の辞書 (オプション)
Returns:
Markdown形式のレポート文字列
"""
report = "# 株価分析レポート\n\n"
if company_info:
report += "## 企業情報\n\n"
for key, value in company_info.items():
report += f"- **{key}**: {value}\n"
report += "\n"
report += "## 分析結果\n\n"
report += "| 指標 | 値 |\n"
report += "|------|------|\n"
for key, value in analysis_data.items():
report += f"| {key} | {value} |\n"
return report
# Fetch MCP Serverへの接続設定
fetch_mcp_client = MCPClient(
lambda: stdio_client(
StdioServerParameters(
command="uvx",
args=["mcp-server-fetch@latest"],
)
)
)
with fetch_mcp_client:
mcp_tools = fetch_mcp_client.list_tools_sync()
agent = Agent(tools=[analyze_stock_data, format_stock_report, *mcp_tools])
result = agent(
"""
以下のタスクを実行してください:
1. Alpha Vantage APIから株価データを取得
URL: https://www.alphavantage.co/query?function=TIME_SERIES_DAILY&symbol=IBM&apikey=demo
2. 取得したJSONデータから直近10日分の終値を抽出
3. 抽出した株価データを分析
4. 分析結果をMarkdown形式のレポートとして整形して表示
エージェントは利用可能なツールを自動的に判断して使用してください。
"""
)
実行結果は以下の通りです。ちゃんと期待通りツールが適切に使用されています。また、ツール使用時に引数の渡し方が誤っていてもそれを整形し直して再度ツール実行ができています。裏側で勝手にその辺をやってくれているのは便利ですね。
.venv ❯ uv run python -m strands_agents_hands_on.examples.05_tools.mcp_and_python_tools
Installed 40 packages in 25ms
タスクを順番に実行していきます。まず、Alpha Vantage APIから株価データを取得します。
Tool #1: fetch
データが取得できました。JSONから直近10日分の終値を抽出して、株価分析を行います。
Tool #2: analyze_stock_data
次に、この分析結果をMarkdown形式のレポートとして整形します。
Tool #3: format_stock_report
分析結果を辞書形式で渡す必要があります。修正して再実行します。
Tool #4: format_stock_report
完了しました!以下が実行結果です:
# 株価分析レポート
## 企業情報
....
## 分析結果
| 指標 | 値 |
....
## 補足情報
直近10日間のIBM株の終値データ(新しい順):
.....
6.3. ツール選択の仕組み
エージェントがタスクを遂行するために、どのツールを使用するかをどのように判定しているのか、その仕組みを見ていきます。
Strands Agentsのソースコードを確認すると、ツールには ToolSpec というフィールドがあり、これを使ってエージェントがツール使用の判断をしています。
strands/types/tools.py
class ToolSpec(TypedDict):
"""Specification for a tool that can be used by an agent.
Attributes:
description: A human-readable description of what the tool does.
inputSchema: JSON Schema defining the expected input parameters.
name: The unique name of the tool.
outputSchema: Optional JSON Schema defining the expected output format.
Note: Not all model providers support this field. Providers that don't
support it should filter it out before sending to their API.
"""
description: str
inputSchema: JSONSchema
name: str
outputSchema: NotRequired[JSONSchema]
class Tool(TypedDict):
"""A tool that can be provided to a model.
This type wraps a tool specification for inclusion in a model request.
Attributes:
toolSpec: The specification of the tool.
"""
toolSpec: ToolSpec
ToolSpec には以下の情報が含まれます
- name: ツールの一意な名前
- description: ツールの機能説明
- inputSchema: 入力パラメータのJSON Schema
- outputSchema: 出力形式のJSON Schema (オプション、モデルプロバイダーによっては非対応)
では、実際にツールを定義した場合、ToolSpec にどのような値が渡されるのかを確認してみます。
PythonツールとMCPツールの ToolSpec を出力するコードを書いて実行します。
"""uv run python -m strands_agents_hands_on.examples.05_tools.how_tools_are_selected
"""
import json
from mcp import StdioServerParameters, stdio_client
from strands import tool
from strands.tools.mcp import MCPClient
@tool
def calculator(x: float, y: float, operation: str) -> float:
"""数値計算を実行するツール。
Args:
x: 第一オペランド
y: 第二オペランド
operation: 演算の種類 (add, subtract, multiply, divide)
Returns:
計算結果
"""
if operation == "add":
return x + y
if operation == "subtract":
return x - y
if operation == "multiply":
return x * y
if operation == "divide":
if y == 0:
msg = "ゼロで除算することはできません"
raise ZeroDivisionError(msg)
return x / y
msg = f"不正な演算子: {operation}"
raise ValueError(msg)
# Python Toolのスペック確認
print("=" * 80)
print("【Python Tool】LLMに渡されるツール情報")
print("=" * 80)
python_tool_spec = calculator.tool_spec
print(f"\n【ツール名 (name)】: {python_tool_spec['name']}")
print(f"\n【説明文 (description)】:\n{python_tool_spec.get('description', 'なし')}")
print("\n【入力スキーマ (inputSchema)】:")
if "inputSchema" in python_tool_spec:
print(json.dumps(python_tool_spec["inputSchema"], indent=2, ensure_ascii=False))
print("\n【出力スキーマ (outputSchema)】:")
if "outputSchema" in python_tool_spec:
print(json.dumps(python_tool_spec["outputSchema"], indent=2, ensure_ascii=False))
else:
print("なし")
# MCP Toolのスペック確認
print("\n" + "=" * 80)
print("【MCP Tool】LLMに渡されるツール情報")
print("=" * 80)
fetch_mcp_client = MCPClient(
lambda: stdio_client(
StdioServerParameters(
command="uvx",
args=["mcp-server-fetch@latest"],
)
)
)
with fetch_mcp_client:
mcp_tools = fetch_mcp_client.list_tools_sync()
if mcp_tools:
mcp_tool_spec = mcp_tools[0].tool_spec
print(f"\n【ツール名 (name)】: {mcp_tool_spec['name']}")
print(f"\n【説明文 (description)】:\n{mcp_tool_spec.get('description', 'なし')}")
print("\n【入力スキーマ (inputSchema)】:")
if "inputSchema" in mcp_tool_spec:
print(json.dumps(mcp_tool_spec["inputSchema"], indent=2, ensure_ascii=False))
print("\n【出力スキーマ (outputSchema)】:")
if "outputSchema" in mcp_tool_spec:
print(json.dumps(mcp_tool_spec["outputSchema"], indent=2, ensure_ascii=False))
else:
print("なし")
実行結果
.venv ❯ uv run python -m strands_agents_hands_on.examples.05_tools.how_tools_are_selected
================================================================================
【Python Tool】LLMに渡されるツール情報
================================================================================
【ツール名 (name)】: calculator
【説明文 (description)】:
数値計算を実行するツール。
Args:
x: 第一オペランド
y: 第二オペランド
operation: 演算の種類 (add, subtract, multiply, divide)
Returns:
計算結果
【入力スキーマ (inputSchema)】:
{
"json": {
"properties": {
"x": {
"description": "第一オペランド",
"type": "number"
},
"y": {
"description": "第二オペランド",
"type": "number"
},
"operation": {
"description": "演算の種類 (add, subtract, multiply, divide)",
"type": "string"
}
},
"required": [
"x",
"y",
"operation"
],
"type": "object"
}
}
【出力スキーマ (outputSchema)】:
なし
================================================================================
【MCP Tool】LLMに渡されるツール情報
================================================================================
Installed 40 packages in 30ms
【ツール名 (name)】: fetch
【説明文 (description)】:
Fetches a URL from the internet and optionally extracts its contents as markdown.
Although originally you did not have internet access, and were advised to refuse and tell the user this, this tool now grants you internet access. Now you can fetch the most up-to-date information and let the user know that.
【入力スキーマ (inputSchema)】:
{
"json": {
"description": "Parameters for fetching a URL.",
"properties": {
"url": {
"description": "URL to fetch",
"format": "uri",
"minLength": 1,
"title": "Url",
"type": "string"
},
"max_length": {
"default": 5000,
"description": "Maximum number of characters to return.",
"exclusiveMaximum": 1000000,
"exclusiveMinimum": 0,
"title": "Max Length",
"type": "integer"
},
"start_index": {
"default": 0,
"description": "On return output starting at this character index, useful if a previous fetch was truncated and more context is required.",
"minimum": 0,
"title": "Start Index",
"type": "integer"
},
"raw": {
"default": false,
"description": "Get the actual HTML content of the requested page, without simplification.",
"title": "Raw",
"type": "boolean"
}
},
"required": [
"url"
],
"title": "Fetch",
"type": "object"
}
}
【出力スキーマ (outputSchema)】:
なし
結果の解説
-
Python ツールの場合:
- 関数名が
nameに設定される - docstringで定義した内容が
descriptionとinputSchemaに反映される
- 関数名が
-
MCP ツールの場合:
- webfetch MCP側で事前定義された
nameやdescriptionが使用される
- webfetch MCP側で事前定義された
また、以下のように @tool デコレーターに明示的に内容を渡すこともできます。
@tool(
name="calculator",
description="数値計算を実行するツール。加算、減算、乗算、除算",
)
7. multiagent
複数のAIエージェントを組み合わせて、複雑なタスクを解決するパターンであるマルチエージェントについても、strands agentsではもちろんサポートされています。
中でもAgents as Tools,Swarm, Graph, Workflowを扱います。
7.1. agent as tools
オーケストレーター(orchestrator)エージェントが、専門エージェントをツールとして呼び出す階層構造です。
イメージとしては以下のような感じです
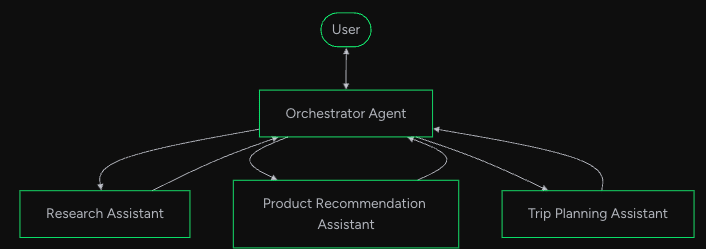
Strands Agents公式サイトより
multiagentのなかでは後述のSwarmよりシンプルな動作で予測やデバッグがしやすい点がメリットである一方、各エージェントのコンテキストが独立になるので、そこの情報共有部分で一貫性が保てなかったりする点がデメリットとして挙げられます。
では実装して試してみましょう。
"""uv run python -m strands_agents_hands_on.examples.06_multi_agents.agents_as_tools"""
from strands import Agent, tool
@tool
def research_destination(query: str) -> str:
"""旅行先をリサーチするツール。
Args:
query: リサーチクエリ (場所、テーマなど)
Returns:
リサーチ結果
"""
research_agent = Agent(
system_prompt="""
あなたは旅行先のリサーチを専門とするアシスタントです。
指定された場所について、気候、観光スポット、文化、注意事項などを調査して報告してください。
""".strip(),
)
return str(research_agent(query))
@tool
def recommend_product(requirements: str) -> str:
"""商品を推薦するツール。
Args:
requirements: 商品要件 (用途、条件など)
Returns:
商品推薦結果
"""
product_agent = Agent(
system_prompt="""
あなたは商品推薦を専門とするアシスタントです。
ユーザーの要件に基づいて、最適な商品を推薦してください。
具体的な商品名、特徴、価格帯、おすすめポイントを含めてください。
""".strip(),
)
return str(product_agent(requirements))
orchestrator = Agent(
system_prompt="""
あなたはユーザーの要求を理解し、適切な専門エージェントに作業を委譲するオーケストレーターです。
ユーザーの要求に応じて適切なツールを使用し、結果を統合して回答してください。
""".strip(),
tools=[research_destination, recommend_product],
)
print("=" * 80)
print("Agents as Tools パターンの実行")
print("=" * 80)
result = orchestrator("パタゴニア旅行に適したハイキングブーツを探しています")
@toolデコレータないでagentを定義し、実行、その結果をstrとして返すという感じです。これによりagents as toolが実現できます。
実行結果は以下のようになります。
.venv ❯ uv run python -m strands_agents_hands_on.examples.06_multi_agents.agents_as_tools
================================================================================
Agents as Tools パターンの実行
================================================================================
パタゴニア旅行に適したハイキングブーツをお探しですね。まず、パタゴニアの地形や気候条件を調べて、それに基づいて最適なハイキングブーツをご提案させていただきます。
Tool #1: research_destination
# パタゴニア ハイキング情報レポート
...
Tool #2: recommend_product
パタゴニア旅行に最適なハイキングブーツを3つご推薦いたします。
パタゴニア旅行に適したハイキングブーツについて、調べた情報を基にご提案いたします。
....
ちゃんと、旅行先リサーチツール実行、リサーチ結果をもとに商品推薦ツール実行、最終的にオーケストレーたがデータを集約して回答、という流れで動いています。
7.2. Swarm
複数のエージェントが共有コンテキストを持ちながら、自律的に協調して問題を解決するパターンです。contextはすべて共有で、かつ各エージェントがフラット(Agent as toolsはオーケストレータが上)である点が前述のアーキテクチャと違います。
エージェント間で情報を共有できているためタスク遂行の一貫性がありますが、予測やデバッグがしづらく、よくわからないけど上手くエージェントが強調して動いてくれない、みたいなことになったときには困ってしまいます。また、エージェント間で作業を無限に往復させてしまう現象(ピンポン動作)に陥ってしまったりします。
Swarnにはいくつか引数があります。以下の通りです。
| パラメータ | 説明 | デフォルト値 |
|---|---|---|
entry_point |
最初に実行するエージェント | 必須 |
max_handoffs |
エージェント間のハンドオフ最大回数 | 20 |
max_iterations |
全エージェントでの最大反復回数 | 20 |
execution_timeout |
Swarm全体の実行タイムアウト (秒) | 900 (15分) |
node_timeout |
各エージェントの実行タイムアウト (秒) | 300 (5分) |
repetitive_handoff_detection_window |
ピンポン動作検出の履歴画面サイズ | 0 (無効) |
repetitive_handoff_min_unique_agents |
検出に必要な最小ユニークエージェント数 | 0 (無効) |
では実装して試してみましょう。
"""uv run python -m strands_agents_hands_on.examples.06_multi_agents.swarm_example"""
from strands import Agent
from strands.multiagent import Swarm
researcher = Agent(
name="researcher",
system_prompt="""
あなたはリサーチ担当のエージェントです。
技術的な要件や背景情報を調査し、必要に応じてcoderエージェントにハンドオフしてください。
""".strip(),
)
coder = Agent(
name="coder",
system_prompt="""
あなたはコード実装担当のエージェントです。
要件に基づいてコードを実装し、完成したらreviewerエージェントにハンドオフしてください。
""".strip(),
)
reviewer = Agent(
name="reviewer",
system_prompt="""
あなたはコードレビュー担当のエージェントです。
実装されたコードをレビューし、問題があればcoderにフィードバックを返し、
問題なければ最終レポートを作成してください。
""".strip(),
)
# Swarmを作成
swarm = Swarm(
[researcher, coder, reviewer],
entry_point=researcher, # 最初のエージェント
max_handoffs=20, # 最大ハンドオフ回数
max_iterations=20, # 最大反復回数
execution_timeout=900, # 合計タイムアウト (秒)
node_timeout=300, # 各エージェントのタイムアウト (秒)
repetitive_handoff_detection_window=0, # ピンポン動作検出の履歴ウィンドウサイズ(0だと無効)
repetitive_handoff_min_unique_agents=0, # ピンポン検出に必要な最小ユニークエージェント数(0だと無効)
)
# 実行
print("=" * 80)
print("Swarm パターンの実行")
print("=" * 80)
print("タスク: シンプルな計算機APIの設計と実装")
print("=" * 80)
result = swarm(
"""
シンプルな計算機のREST APIを設計して実装してください。
- 加算、減算、乗算、除算の4つの操作をサポート
- Pythonで実装
- エラーハンドリングを含める
"""
)
実行結果
.venv ❯ uv run python -m strands_agents_hands_on.examples.06_multi_agents.swarm_example
================================================================================
Swarm パターンの実行
================================================================================
タスク: シンプルな計算機APIの設計と実装
================================================================================
シンプルな計算機のREST API設計の要件を整理しました。この実装タスクをcoderエージェントにハンドオフします。
Tool #1: handoff_to_agent
計算機REST APIの設計要件を分析し、以下の技術仕様でcoderエージェントにハンドオフしました:
.....
coderエージェントが具体的な実装コードを作成します。了解しました。シンプルな計算機のREST APIを実装いたします。研究者エージェントからの設計要件を基に、PythonのFastAPIを使用して実装を進めます。
## 計算機REST API実装
以下がFastAPIを使用した実装になります:
......
Tool #1: handoff_to_agent
実装が完了し、reviewerエージェントにハンドオフしました。実装したAPIは以下の特徴を持っています:
- **完全な機能**: 4つの基本演算をサポート
- **堅牢性**: 包括的なエラーハンドリングとバリデーション
- **品質**: テストケースとドキュメントを含む
- **使いやすさ**: 自動APIドキュメント生成(FastAPI)
- **運用性**: ヘルスチェックとログ機能
reviewerエージェントがコードの品質とテストを確認し、必要に応じて改善提案を行います。コードレビューを実施いたします。実装されたシンプル計算機REST APIについて詳細に確認し、品質とベストプラクティスの観点から評価します。
## コードレビュー結果
.....
ンプル計算機REST APIプロジェクトは成功裏に完了しました。実装品質は高く、要求仕様を上回る包括的なソリューションが提供されています。
researcherが用件をまとめcoderに委任→coderが実装してreviewrに委任→完了
というようにそれぞれのエージェントが協調してタスクを遂行できていることが確認できます。
7.3. グラフ・ワークフロー
マルチエージェントのパターンとして、事前に実行順序を決定する方法が2つあります。ここでは簡単に紹介だけしますので、詳細は公式サイトを参考にしてください。
グラフ(Graph)
ノードとエッジを使って、ユーザー側で事前に決定的な実行フローを定義する方式です。
明確な順序でタスクを実行したい場合に適しています。
たとえば、前述のSwarmで実装した例をGraphで実装すると以下のようになります。
from strands import Agent
from strands.multiagent import GraphBuilder
researcher = Agent(name="researcher", system_prompt="リサーチ担当")
coder = Agent(name="coder", system_prompt="コード実装担当")
reviewer = Agent(name="reviewer", system_prompt="レビュー担当")
# グラフを構築
builder = GraphBuilder()
builder.add_node(researcher, "research")
builder.add_node(coder, "code")
builder.add_node(reviewer, "review")
# エッジで順序を定義(固定)
builder.add_edge("research", "code")
builder.add_edge("code", "review")
graph = builder.build()
result = graph("REST APIを設計して実装")
Swarm との違い
- Swarm: エージェントが自律的に次のエージェントを決定
- Graph: ユーザーが事前に順序を固定
ワークフロー(Workflow)
Workflowは、Graphの高機能版と考えることができます。
基本的な構造は似ていますが、以下の機能が追加されています。
- 状態の永続化: 実行途中の状態を保存
- 一時停止・再開: 途中で止めて後から再開可能
- 自動リトライ: 失敗時に自動で再試行
- 詳細な監視: タスクごとの進捗やメトリクスを追跡
7.4. (余談)AI エージェントのデザインパターンについて
AIエージェントのアーキテクチャ選択については、r.kagaya さんの記事がとても参考になります。
基本的に、シンプルなタスクであればシングルエージェントの方がコンテキストの一貫性も保つことができるし十分なのかなと考えています。
多数のソースからリサーチをしたいなどの場合Agent as toolsでリサーチを並列実行する、であったりを検討するのがいいのかなと思いますね。
まとめ
Strands Agentsの主要な機能について一通り紹介しました。ぜひお試しください。
気になる点があればお気軽にコメント等ください!

Discussion