voxelpose-pytorchをSageMaker Studioで動かす
学習させて推論までをやりたい。
コード:
論文:
[2004.06239] VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Environment
論文のまとめスライド:
[DL輪読会]VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wi…
デモ動画:
論文執筆者の一人、王春雨=Chunyu Wangさんのサイト
voxelpose-pytorchがPyTorch1.4.0に依存してるので、SageMakerStudioのPyTorch1.4/Python3.6/GPU Optimizedカーネルでまず試してみる。
!python --version
Python 3.6.13 :: Anaconda, Inc.
PyTorchはちょうど1.4.0がインストールされてる。
!python -m pip freeze
...
torch @ https://pytorch-aws.s3.amazonaws.com/pytorch-1.4.0/py3/gpu/torch-1.4.0-cp36-cp36m-manylinux1_x86_64.whl
torchvision @ https://torchvision-build.s3.amazonaws.com/1.4.0/py3/gpu/torchvision-0.5.0-cp36-cp36m-linux_x86_64.whl
...
notebook上でリポジトリcloneしてpip installしたら、エラーなく終了できた。クローンしたリポジトリのディレクトリのルートをカレントディレクトリにするやり方がわからない。
!git clone https://github.com/microsoft/voxelpose-pytorch.git
!python -m pip install -r voxelpose-pytorch/requirements.txt
データファイルのダウンロード1
!wget http://campar.cs.tum.edu/files/belagian/multihuman/Shelf.tar.bz2
!wget http://campar.cs.tum.edu/files/belagian/multihuman/CampusSeq1.tar.bz2
データファイルの展開1。--no-same-owner オプションをつけないと Cannot change ownership エラーが大量に発生してうざかった。
!tar -xvf CampusSeq1.tar.bz2 --no-same-owner
!tar -xvf Shelf.tar.bz2 --no-same-owner
展開したファイルを所定の場所に移動。
!mv Shelf/* voxelpose-pytorch/data/Shelf/
!mv CampusSeq1/* voxelpose-pytorch/data/CampusSeq1/
CMU Panoptic datasetのダウンロード。
You can only download those sequences you need. You can also just download a subset of camera views by specifying the number of views (HD_Video_Number) and changing the camera order in ./scripts/getData.sh. The sequences and camera views used in our project can be obtained from our paper.
Note that we only use HD videos, calibration data, and 3D Body Keypoint in the codes. You can comment out other irrelevant codes such as downloading 3D Face data in ./scripts/getData.sh.
The CMU Panoptic Dataset [15] It captures people doing daily activities
by dozens of cameras among which five HD cameras (3, 6, 12, 13, 23) are used
in our experiments. We also report results for fewer cameras. Following [37], the
training set consists of the following sequences: ‘‘160422 ultimatum1’’,‘‘16022
4 haggling1’’,‘‘160226 haggling1’’,‘‘161202 haggling1’’,‘‘160906 ian1’’,‘‘160906
ian2’’,‘‘160906 ian3’’,‘‘160906 band1’’,‘‘160906 band2’’,‘‘160906 band3’’. The
testing set consists of :‘‘160906 pizza1’’,‘‘160422 haggling1’’,‘‘160906 ian5’’,and
‘‘160906 band4’’.
使用しないhand/face関連のデータダウンロード部分をコメントアウト
# git diff
diff --git a/scripts/getData.sh b/scripts/getData.sh
index 78cbf06..13f209c 100755
--- a/scripts/getData.sh
+++ b/scripts/getData.sh
@@ -81,20 +81,20 @@ $WGET $mO hdPose3d_stage1_coco19.tar http://domedb.perception.cs.cmu.edu/webdat
fi
# 3D Face
-if [ ! -f hdFace3d.tar ]; then
-$WGET $mO hdFace3d.tar http://domedb.perception.cs.cmu.edu/webdata/dataset/$datasetName/hdFace3d.tar || rm -v hdFace3d.tar
-fi
+# if [ ! -f hdFace3d.tar ]; then
+# $WGET $mO hdFace3d.tar http://domedb.perception.cs.cmu.edu/webdata/dataset/$datasetName/hdFace3d.tar || rm -v hdFace3d.tar
+# fi
# 3D Hand
-if [ ! -f hdHand3d.tar ]; then
-$WGET $mO hdHand3d.tar http://domedb.perception.cs.cmu.edu/webdata/dataset/$datasetName/hdHand3d.tar || rm -v hdHand3d.tar
-fi
+# if [ ! -f hdHand3d.tar ]; then
+# $WGET $mO hdHand3d.tar http://domedb.perception.cs.cmu.edu/webdata/dataset/$datasetName/hdHand3d.tar || rm -v hdHand3d.tar
+# fi
# 3D Face Fitting Output
-if [ ! -f hdMeshTrack_face.tar ]; then
-$WGET $mO hdMeshTrack_face.tar http://domedb.perception.cs.cmu.edu/webdata/dataset/$datasetName/hdMeshTrack_face.tar || rm -v hdMeshTrack_face.tar
-fi
+# if [ ! -f hdMeshTrack_face.tar ]; then
+# $WGET $mO hdMeshTrack_face.tar http://domedb.perception.cs.cmu.edu/webdata/dataset/$datasetName/hdMeshTrack_face.tar || rm -v hdMeshTrack_face.tar
+# fi
# Download kinect-rgb videos
ダウンロード。めちゃめちゃ時間かかるので、寝る前に実行して朝確認するのがよさげ。
# For training
./panoptic-toolbox/scripts/getData.sh 160422_ultimatum1
./panoptic-toolbox/scripts/getData.sh 160224_haggling1
./panoptic-toolbox/scripts/getData.sh 160226_haggling1
./panoptic-toolbox/scripts/getData.sh 161202_haggling1
./panoptic-toolbox/scripts/getData.sh 160906_ian1
./panoptic-toolbox/scripts/getData.sh 160906_ian2
./panoptic-toolbox/scripts/getData.sh 160906_ian3
./panoptic-toolbox/scripts/getData.sh 160906_band1
./panoptic-toolbox/scripts/getData.sh 160906_band2
./panoptic-toolbox/scripts/getData.sh 160906_band3
# For testing
./panoptic-toolbox/scripts/getData.sh 160906_pizza1
./panoptic-toolbox/scripts/getData.sh 160422_haggling1
./panoptic-toolbox/scripts/getData.sh 160906_ian5
./panoptic-toolbox/scripts/getData.sh 160906_band4
ダウンロードしたデータはディレクトリごと${POSE_ROOT}/data/panoptic-toolbox/dataの下に配置。
Download the pretrained backbone model from pretrained backbone(https://1drv.ms/u/s!AjX41AtnTHeTjn3H9PGSLcbSC0bl?e=cw7SQg) and place it here: ${POSE_ROOT}/models/pose_resnet50_panoptic.pth.tar (ResNet-50 pretrained on COCO dataset and finetuned jointly on Panoptic dataset and MPII).
panoptic datasetでtraining
!python voxelpose-pytorch/run/train_3d.py --cfg voxelpose-pytorch/configs/panoptic/resnet50/prn64_cpn80x80x20_960x512_cam5.yaml
=> creating /root/voxelpose/voxelpose-pytorch/output/panoptic/multi_person_posenet_50/prn64_cpn80x80x20_960x512_cam5
=> creating /root/voxelpose/voxelpose-pytorch/log/panoptic/multi_person_posenet_50/prn64_cpn80x80x20_960x512_cam52021-05-09-11-59
Namespace(cfg='voxelpose-pytorch/configs/panoptic/resnet50/prn64_cpn80x80x20_960x512_cam5.yaml')
{'BACKBONE_MODEL': 'pose_resnet',
'CUDNN': {'BENCHMARK': True, 'DETERMINISTIC': False, 'ENABLED': True},
'DATASET': {'BBOX': 2000,
'CAMERA_NUM': 5,
'COLOR_RGB': True,
'CROP': True,
'DATA_AUGMENTATION': False,
'DATA_FORMAT': 'jpg',
'FLIP': False,
'ROOT': 'data/panoptic-toolbox/data/',
'ROOTIDX': 2,
'ROT_FACTOR': 45,
'SCALE_FACTOR': 0.35,
'TEST_DATASET': 'panoptic',
'TEST_SUBSET': 'validation',
'TRAIN_DATASET': 'panoptic',
'TRAIN_SUBSET': 'train'},
'DATA_DIR': '',
'DEBUG': {'DEBUG': True,
'SAVE_BATCH_IMAGES_GT': True,
'SAVE_BATCH_IMAGES_PRED': True,
'SAVE_HEATMAPS_GT': True,
'SAVE_HEATMAPS_PRED': True},
'GPUS': '0',
'LOG_DIR': 'log',
'LOSS': {'USE_DIFFERENT_JOINTS_WEIGHT': False, 'USE_TARGET_WEIGHT': True},
'MODEL': 'multi_person_posenet',
'MODEL_EXTRA': {'DECONV': {'CAT_OUTPUT': True,
'KERNEL_SIZE': 4,
'NUM_BASIC_BLOCKS': 4,
'NUM_CHANNELS': 32,
'NUM_DECONVS': 1},
'FINAL_CONV_KERNEL': 1,
'PRETRAINED_LAYERS': ['*'],
'STAGE2': {'BLOCK': 'BASIC',
'FUSE_METHOD': 'SUM',
'NUM_BLOCKS': [4, 4],
'NUM_BRANCHES': 2,
'NUM_CHANNELS': [48, 96],
'NUM_MODULES': 1},
'STAGE3': {'BLOCK': 'BASIC',
'FUSE_METHOD': 'SUM',
'NUM_BLOCKS': [4, 4, 4],
'NUM_BRANCHES': 3,
'NUM_CHANNELS': [48, 96, 192],
'NUM_MODULES': 4},
'STAGE4': {'BLOCK': 'BASIC',
'FUSE_METHOD': 'SUM',
'NUM_BLOCKS': [4, 4, 4, 4],
'NUM_BRANCHES': 4,
'NUM_CHANNELS': [48, 96, 192, 384],
'NUM_MODULES': 3},
'STEM_INPLANES': 64},
'MULTI_PERSON': {'INITIAL_CUBE_SIZE': [80, 80, 20],
'MAX_PEOPLE_NUM': 10,
'SPACE_CENTER': [0.0, -500.0, 800.0],
'SPACE_SIZE': [8000.0, 8000.0, 2000.0],
'THRESHOLD': 0.3},
'NETWORK': {'AGGRE': True,
'BETA': 100.0,
'HEATMAP_SIZE': array([240, 128]),
'IMAGE_SIZE': array([960, 512]),
'INPUT_SIZE': 512,
'NUM_JOINTS': 15,
'PRETRAINED': '',
'PRETRAINED_BACKBONE': 'models/pose_resnet50_panoptic.pth.tar',
'SIGMA': 3,
'TARGET_TYPE': 'gaussian',
'USE_GT': False},
'OUTPUT_DIR': 'output',
'PICT_STRUCT': {'CUBE_SIZE': [64, 64, 64],
'DEBUG': False,
'FIRST_NBINS': 16,
'GRID_SIZE': [2000.0, 2000.0, 2000.0],
'LIMB_LENGTH_TOLERANCE': 150,
'PAIRWISE_FILE': '',
'RECUR_DEPTH': 10,
'RECUR_NBINS': 2,
'SHOW_CROPIMG': False,
'SHOW_HEATIMG': False,
'SHOW_ORIIMG': False,
'TEST_PAIRWISE': False},
'POSE_RESNET': {'DECONV_WITH_BIAS': False,
'FINAL_CONV_KERNEL': 1,
'NUM_DECONV_FILTERS': [256, 256, 256],
'NUM_DECONV_KERNELS': [4, 4, 4],
'NUM_DECONV_LAYERS': 3,
'NUM_LAYERS': 50},
'PRINT_FREQ': 100,
'TEST': {'BATCH_SIZE': 4,
'BBOX_FILE': '',
'BBOX_THRE': 1.0,
'DETECTOR': 'fpn_dcn',
'DETECTOR_DIR': '',
'FLIP_TEST': False,
'HEATMAP_LOCATION_FILE': 'predicted_heatmaps.h5',
'IMAGE_THRE': 0.1,
'IN_VIS_THRE': 0.0,
'MATCH_IOU_THRE': 0.3,
'MODEL_FILE': 'model_best.pth.tar',
'NMS_THRE': 0.6,
'OKS_THRE': 0.5,
'POST_PROCESS': False,
'SHIFT_HEATMAP': False,
'STATE': 'best',
'USE_GT_BBOX': False},
'TRAIN': {'BATCH_SIZE': 1,
'BEGIN_EPOCH': 0,
'END_EPOCH': 10,
'GAMMA1': 0.99,
'GAMMA2': 0.0,
'LR': 0.0001,
'LR_FACTOR': 0.1,
'LR_STEP': [90, 110],
'MOMENTUM': 0.9,
'NESTEROV': False,
'OPTIMIZER': 'adam',
'RESUME': True,
'SHUFFLE': True,
'WD': 0.0001},
'WORKERS': 4}
=> Loading data ..
Traceback (most recent call last):
File "voxelpose-pytorch/run/train_3d.py", line 160, in <module>
main()
File "voxelpose-pytorch/run/train_3d.py", line 85, in main
pin_memory=True)
File "/opt/conda/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 213, in __init__
sampler = RandomSampler(dataset)
File "/opt/conda/lib/python3.6/site-packages/torch/utils/data/sampler.py", line 94, in __init__
"value, but got num_samples={}".format(self.num_samples))
ValueError: num_samples should be a positive integer value, but got num_samples=0
os.chdir()でディレクトリ変更するのは、セル上で実行してもちゃんと結果が保持されてた。
[40]: os.chdir('/root/voxelpose/voxelpose-pytorch/')
[41]: os.getcwd()
[41]: '/root/voxelpose/voxelpose-pytorch'
データの展開をしてなかったせいでエラーになっていたっぽい。今朝展開スクリプト実行したが、まだまったく終わる気配なし。
cd /root/voxelpose/voxelpose-pytorch/data/panoptic-toolbox/data
# For training
/root/voxelpose/panoptic-toolbox/scripts/extractAll.sh 160422_ultimatum1
/root/voxelpose/panoptic-toolbox/scripts/extractAll.sh 160224_haggling1
/root/voxelpose/panoptic-toolbox/scripts/extractAll.sh 160226_haggling1
/root/voxelpose/panoptic-toolbox/scripts/extractAll.sh 161202_haggling1
/root/voxelpose/panoptic-toolbox/scripts/extractAll.sh 160906_ian1
/root/voxelpose/panoptic-toolbox/scripts/extractAll.sh 160906_ian2
/root/voxelpose/panoptic-toolbox/scripts/extractAll.sh 160906_ian3
/root/voxelpose/panoptic-toolbox/scripts/extractAll.sh 160906_band1
/root/voxelpose/panoptic-toolbox/scripts/extractAll.sh 160906_band2
/root/voxelpose/panoptic-toolbox/scripts/extractAll.sh 160906_band3
# For testing
/root/voxelpose/panoptic-toolbox/scripts/extractAll.sh 160906_pizza1
/root/voxelpose/panoptic-toolbox/scripts/extractAll.sh 160422_haggling1
/root/voxelpose/panoptic-toolbox/scripts/extractAll.sh 160906_ian5
/root/voxelpose/panoptic-toolbox/scripts/extractAll.sh 160906_band4
まねこんのセッション期限切れてログインし直したりしつつ、まだextract終わってないっぽい。プロセスにそれっぽいのが動き続けてるようだから、処理自体はちゃんと進行してるっぽいが。。
# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 4504 1624 ? Ss May07 0:00 /bin/sh /opt/.s
root 19 0.2 0.6 662396 104120 ? Rl May07 18:17 /opt/.sagemaker
root 37 0.6 1.6 2577340 273520 ? Ssl May07 45:39 /opt/conda/bin/
root 197 0.0 0.0 4504 796 pts/0 Ss+ May07 0:00 /bin/sh -l
root 199 0.0 0.0 4504 796 pts/1 Ss+ May07 0:00 /bin/sh -l
root 303 0.0 0.0 4504 1604 pts/2 Ss+ May07 0:00 /bin/sh -l
root 336 0.0 0.3 567824 51480 ? Ssl May07 0:09 /opt/conda/bin/
root 365 0.0 0.0 4504 700 pts/3 Ss+ May07 0:00 /bin/sh -l
root 4453 0.0 0.0 4504 1620 pts/4 Ss+ May08 0:00 /bin/sh -l
root 5739 0.0 0.0 4504 840 pts/6 Ss+ May08 0:00 /bin/sh -l
root 8818 0.0 0.5 595732 81208 ? Ssl May09 0:07 /opt/conda/bin/
root 10899 0.0 0.0 4504 700 pts/5 Ss+ May09 0:00 /bin/sh -l
root 11769 0.0 0.0 4504 748 pts/7 Ss+ May10 0:00 /bin/sh -l
root 14368 0.0 0.0 4504 708 pts/8 Ss+ May11 0:00 /bin/sh -c sh /
root 14369 0.0 0.0 4504 756 pts/8 S+ May11 0:00 sh /root/voxelp
root 15956 0.0 0.0 4504 744 pts/9 Ss+ May11 0:00 /bin/sh -l
root 16070 0.0 0.0 4504 700 pts/10 Ss+ May11 0:00 /bin/sh -l
root 19709 0.0 0.0 19768 3248 pts/8 S+ 00:21 0:00 /bin/bash /root
root 19713 0.0 0.0 4504 748 pts/11 Ss+ 00:22 0:00 /bin/sh -l
root 20721 0.0 0.0 19784 2528 pts/8 S+ 00:31 0:00 /bin/bash /root
root 20925 110 0.8 873044 131732 pts/8 Dl+ 02:09 0:25 ffmpeg -i hdVid
root 20939 1.0 0.0 4504 696 pts/12 Ss 02:09 0:00 /bin/sh -l
root 20941 0.0 0.0 34108 3240 pts/12 R+ 02:09 0:00 ps aux
いったんstudio消して、最初からやりなおしてみようかな。
studioにつないだEFSをすべてクリアして、appもjupyter serverのみの状態からしきり直し。regionはtokyo。
Pytorch 1.4 Python3.6 CPU Optimizedのkernelでノートブックを作成。
!git clone https://github.com/microsoft/voxelpose-pytorch.git
!cat voxelpose-pytorch/requirements.txt
tqdm==4.29.1
json_tricks==3.13.2
torch==1.4.0
opencv_python==4.0.0.21
prettytable==0.7.2
scipy==1.4.1
torchvision==0.5.0
numpy==1.16.2
matplotlib==2.0.2
easydict==1.9
PyYAML==5.4
tensorboardX==2.1
!python -m pip install -r voxelpose-pytorch/requirements.txt
.....
Attempting uninstall: numpy
Found existing installation: numpy 1.16.4
Uninstalling numpy-1.16.4:
Successfully uninstalled numpy-1.16.4
Attempting uninstall: tqdm
Found existing installation: tqdm 4.56.0
Uninstalling tqdm-4.56.0:
Successfully uninstalled tqdm-4.56.0
Attempting uninstall: scipy
Found existing installation: scipy 1.2.2
Uninstalling scipy-1.2.2:
Successfully uninstalled scipy-1.2.2
Attempting uninstall: PyYAML
Found existing installation: PyYAML 5.4.1
Uninstalling PyYAML-5.4.1:
Successfully uninstalled PyYAML-5.4.1
Attempting uninstall: matplotlib
Found existing installation: matplotlib 3.3.4
Uninstalling matplotlib-3.3.4:
Successfully uninstalled matplotlib-3.3.4
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
spacy 3.0.5 requires tqdm<5.0.0,>=4.38.0, but you have tqdm 4.29.1 which is incompatible.
Successfully installed PyYAML-5.4 easydict-1.9 json-tricks-3.13.2 matplotlib-2.0.2 numpy-1.16.2 opencv-python-4.0.0.21 prettytable-0.7.2 scipy-1.4.1 tensorboardX-2.1 tqdm-4.29.1
以下を再度実行。
Self/Campusのデータセットではトレーニングしない、とREADMEに書いたるが、トレーニング実行のコマンドが書いてあるので、一番小さいCampusデータセットのトレーニング実行してみる。
!python run/train_3d.py --cfg configs/campus/prn64_cpn80x80x20.yaml
GPUなしのkernelだと実行できないっぽい。
AssertionError: Torch not compiled with CUDA enabled
Pytorch 1.4 Python3.6 GPU Optimizedのkernelに変更。
kernelが起動したのち、requirements.txtを入れ直して再度以下実行。
!python run/train_3d.py --cfg configs/campus/prn64_cpn80x80x20.yaml
=> creating /root/voxelpose-pytorch/output/campus_synthetic/multi_person_posenet_50/prn64_cpn80x80x20
=> creating /root/voxelpose-pytorch/log/campus_synthetic/multi_person_posenet_50/prn64_cpn80x80x202021-06-01-05-59
Namespace(cfg='configs/campus/prn64_cpn80x80x20.yaml')
{'BACKBONE_MODEL': '',
'CUDNN': {'BENCHMARK': True, 'DETERMINISTIC': False, 'ENABLED': True},
'DATASET': {'BBOX': 2000,
'CAMERA_NUM': 3,
'COLOR_RGB': True,
'CROP': True,
'DATA_AUGMENTATION': False,
'DATA_FORMAT': 'png',
'FLIP': False,
'ROOT': 'data/CampusSeq1',
'ROOTIDX': [2, 3],
'ROT_FACTOR': 45,
'SCALE_FACTOR': 0.35,
'TEST_DATASET': 'campus',
'TEST_SUBSET': 'validation',
'TRAIN_DATASET': 'campus_synthetic',
'TRAIN_SUBSET': 'train'},
'DATA_DIR': '',
'DEBUG': {'DEBUG': True,
'SAVE_BATCH_IMAGES_GT': True,
'SAVE_BATCH_IMAGES_PRED': True,
'SAVE_HEATMAPS_GT': True,
'SAVE_HEATMAPS_PRED': True},
'GPUS': '0',
'LOG_DIR': 'log',
'LOSS': {'USE_DIFFERENT_JOINTS_WEIGHT': False, 'USE_TARGET_WEIGHT': True},
'MODEL': 'multi_person_posenet',
'MODEL_EXTRA': {'DECONV': {'CAT_OUTPUT': True,
'KERNEL_SIZE': 4,
'NUM_BASIC_BLOCKS': 4,
'NUM_CHANNELS': 32,
'NUM_DECONVS': 1},
'FINAL_CONV_KERNEL': 1,
'PRETRAINED_LAYERS': ['*'],
'STAGE2': {'BLOCK': 'BASIC',
'FUSE_METHOD': 'SUM',
'NUM_BLOCKS': [4, 4],
'NUM_BRANCHES': 2,
'NUM_CHANNELS': [48, 96],
'NUM_MODULES': 1},
'STAGE3': {'BLOCK': 'BASIC',
'FUSE_METHOD': 'SUM',
'NUM_BLOCKS': [4, 4, 4],
'NUM_BRANCHES': 3,
'NUM_CHANNELS': [48, 96, 192],
'NUM_MODULES': 4},
'STAGE4': {'BLOCK': 'BASIC',
'FUSE_METHOD': 'SUM',
'NUM_BLOCKS': [4, 4, 4, 4],
'NUM_BRANCHES': 4,
'NUM_CHANNELS': [48, 96, 192, 384],
'NUM_MODULES': 3},
'STEM_INPLANES': 64},
'MULTI_PERSON': {'INITIAL_CUBE_SIZE': [80, 80, 20],
'MAX_PEOPLE_NUM': 10,
'SPACE_CENTER': [3000.0, 4500.0, 1000.0],
'SPACE_SIZE': [12000.0, 12000.0, 2000.0],
'THRESHOLD': 0.1},
'NETWORK': {'AGGRE': True,
'BETA': 100.0,
'HEATMAP_SIZE': array([200, 160]),
'IMAGE_SIZE': array([800, 640]),
'INPUT_SIZE': 512,
'NUM_JOINTS': 17,
'PRETRAINED': '',
'PRETRAINED_BACKBONE': '',
'SIGMA': 3,
'TARGET_TYPE': 'gaussian',
'USE_GT': False},
'OUTPUT_DIR': 'output',
'PICT_STRUCT': {'CUBE_SIZE': [64, 64, 64],
'DEBUG': False,
'FIRST_NBINS': 16,
'GRID_SIZE': [2000.0, 2000.0, 2000.0],
'LIMB_LENGTH_TOLERANCE': 150,
'PAIRWISE_FILE': '',
'RECUR_DEPTH': 10,
'RECUR_NBINS': 2,
'SHOW_CROPIMG': False,
'SHOW_HEATIMG': False,
'SHOW_ORIIMG': False,
'TEST_PAIRWISE': False},
'POSE_RESNET': {'DECONV_WITH_BIAS': False,
'FINAL_CONV_KERNEL': 1,
'NUM_DECONV_FILTERS': [256, 256, 256],
'NUM_DECONV_KERNELS': [4, 4, 4],
'NUM_DECONV_LAYERS': 3,
'NUM_LAYERS': 50},
'PRINT_FREQ': 100,
'TEST': {'BATCH_SIZE': 4,
'BBOX_FILE': '',
'BBOX_THRE': 1.0,
'DETECTOR': 'fpn_dcn',
'DETECTOR_DIR': '',
'FLIP_TEST': False,
'HEATMAP_LOCATION_FILE': 'predicted_heatmaps.h5',
'IMAGE_THRE': 0.1,
'IN_VIS_THRE': 0.0,
'MATCH_IOU_THRE': 0.3,
'MODEL_FILE': 'model_best.pth.tar',
'NMS_THRE': 0.6,
'OKS_THRE': 0.5,
'POST_PROCESS': False,
'SHIFT_HEATMAP': False,
'STATE': 'best',
'USE_GT_BBOX': False},
'TRAIN': {'BATCH_SIZE': 1,
'BEGIN_EPOCH': 0,
'END_EPOCH': 30,
'GAMMA1': 0.99,
'GAMMA2': 0.0,
'LR': 0.0001,
'LR_FACTOR': 0.1,
'LR_STEP': [90, 110],
'MOMENTUM': 0.9,
'NESTEROV': False,
'OPTIMIZER': 'adam',
'RESUME': True,
'SHUFFLE': True,
'WD': 0.0001},
'WORKERS': 4}
=> Loading data ..
=> load /root/voxelpose-pytorch/data/CampusSeq1/pred_campus_maskrcnn_hrnet_coco.pkl
=> Constructing models ..
=> no checkpoint found at /root/voxelpose-pytorch/output/campus_synthetic/multi_person_posenet_50/prn64_cpn80x80x20/checkpoint.pth.tar
=> Training...
Epoch: 0
ERROR: Unexpected bus error encountered in worker. This might be caused by insufficient shared memory (shm).
ERROR: Unexpected bus error encountered in worker. This might be caused by insufficient shared memory (shm).
ERROR: Unexpected bus error encountered in worker. This might be caused by insufficient shared memory (shm).
Traceback (most recent call last):
File "/opt/conda/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 761, in _try_get_data
data = self._data_queue.get(timeout=timeout)
File "/opt/conda/lib/python3.6/queue.py", line 173, in get
self.not_empty.wait(remaining)
File "/opt/conda/lib/python3.6/threading.py", line 299, in wait
gotit = waiter.acquire(True, timeout)
File "/opt/conda/lib/python3.6/site-packages/torch/utils/data/_utils/signal_handling.py", line 66, in handler
_error_if_any_worker_fails()
RuntimeError: DataLoader worker (pid 119) is killed by signal: Bus error. It is possible that dataloader's workers are out of shared memory. Please try to raise your shared memory limit.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "run/train_3d.py", line 160, in <module>
main()
File "run/train_3d.py", line 133, in main
train_3d(config, model, optimizer, train_loader, epoch, final_output_dir, writer_dict)
File "/root/voxelpose-pytorch/run/../lib/core/function.py", line 37, in train_3d
for i, (inputs, targets_2d, weights_2d, targets_3d, meta, input_heatmap) in enumerate(loader):
File "/opt/conda/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 345, in __next__
data = self._next_data()
File "/opt/conda/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 841, in _next_data
idx, data = self._get_data()
File "/opt/conda/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 798, in _get_data
success, data = self._try_get_data()
File "/opt/conda/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 774, in _try_get_data
raise RuntimeError('DataLoader worker (pid(s) {}) exited unexpectedly'.format(pids_str))
RuntimeError: DataLoader worker (pid(s) 119) exited unexpectedly
RuntimeError: DataLoader worker (pid 119) is killed by signal: Bus error. It is possible that dataloader's workers are out of shared memory. Please try to raise your shared memory limit.
こちらの記事を参考にして、共有メモリの容量を確認。
!df -H
Filesystem Size Used Avail Use% Mounted on
overlay 19G 296M 18G 2% /
tmpfs 68M 0 68M 0% /dev
tmpfs 8.3G 0 8.3G 0% /sys/fs/cgroup
shm 68M 0 68M 0% /dev/shm
127.0.0.1:/200005 9.3E 62G 9.3E 1% /root
/dev/nvme0n1p1 90G 16G 74G 18% /usr/bin/nvidia-smi
devtmpfs 8.3G 0 8.3G 0% /dev/tty
tmpfs 8.3G 13k 8.3G 1% /proc/driver/nvidia
tmpfs 8.3G 0 8.3G 0% /proc/acpi
tmpfs 8.3G 0 8.3G 0% /sys/firmware
Pytorch 1.4, Python3.6, GPU Optimized kernelのapp nameは pytorch-1-4-gpu-py3-ml-g4dn-xlarge-XXXXX みたいになってるので、ml.g4dn.xlargeインスタンスで動いているっぽい。
現在と同じg4dnのxlargeから2xlargeに変更して試してみる。
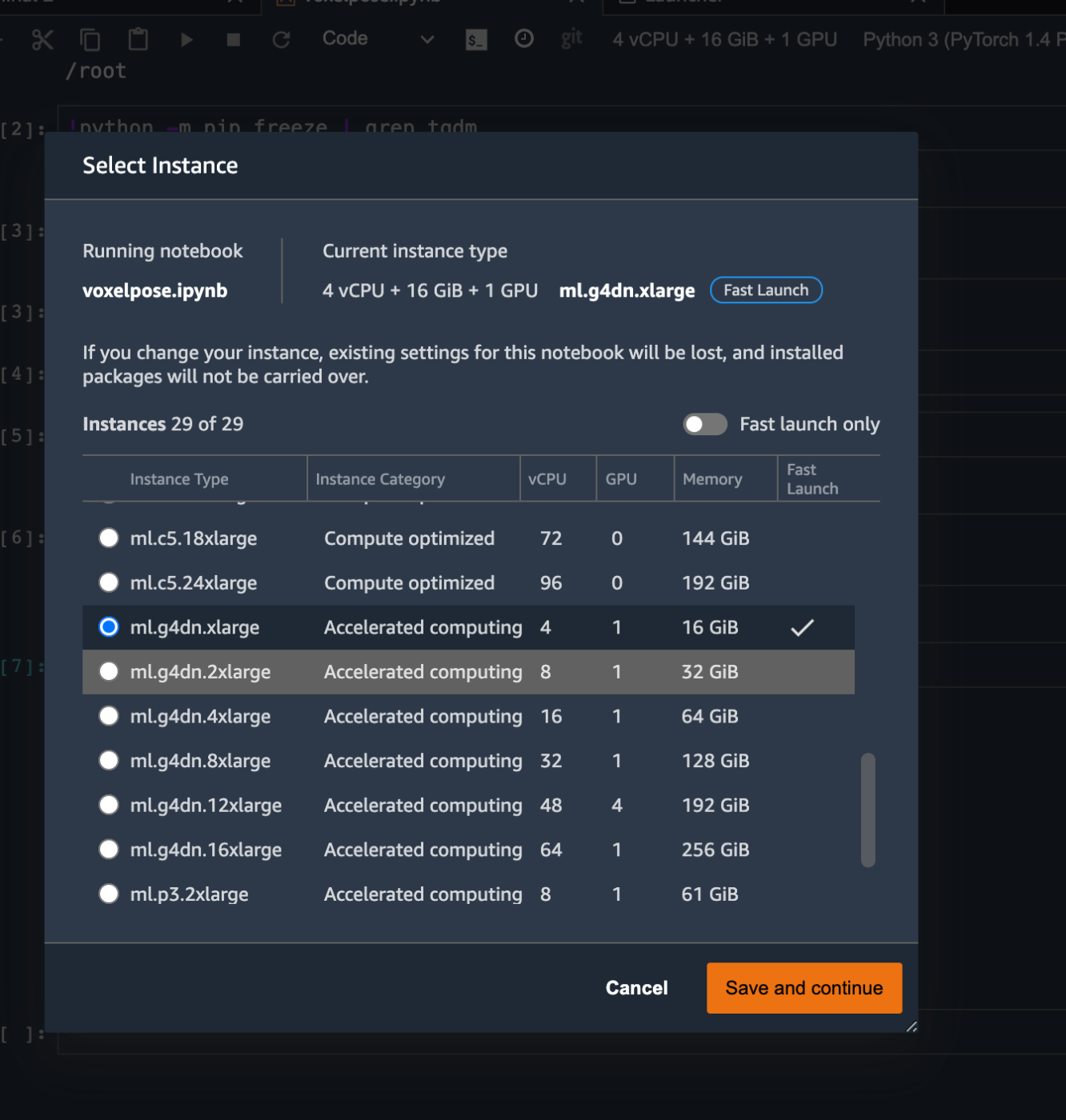
ml.g4dn.xlarge -> ml.d4dn.2xlargeに変更しても、shmのサイズは68Mのままだった。
!df -H
Filesystem Size Used Avail Use% Mounted on
overlay 19G 11M 19G 1% /
tmpfs 68M 0 68M 0% /dev
tmpfs 17G 0 17G 0% /sys/fs/cgroup
shm 68M 0 68M 0% /dev/shm
127.0.0.1:/200005 9.3E 62G 9.3E 1% /root
/dev/nvme0n1p1 90G 18G 72G 20% /usr/bin/nvidia-smi
devtmpfs 17G 0 17G 0% /dev/tty
tmpfs 17G 13k 17G 1% /proc/driver/nvidia
tmpfs 17G 0 17G 0% /proc/acpi
tmpfs 17G 0 17G 0% /sys/firmware
以下の実行結果も同じ。
!python run/train_3d.py --cfg configs/campus/prn64_cpn80x80x20.yaml
ERROR: Unexpected bus error encountered in worker. This might be caused by insufficient shared memory (shm).
Traceback (most recent call last):
File "/opt/conda/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 761, in _try_get_data
data = self._data_queue.get(timeout=timeout)
File "/opt/conda/lib/python3.6/queue.py", line 173, in get
self.not_empty.wait(remaining)
File "/opt/conda/lib/python3.6/threading.py", line 299, in wait
gotit = waiter.acquire(True, timeout)
File "/opt/conda/lib/python3.6/site-packages/torch/utils/data/_utils/signal_handling.py", line 66, in handler
_error_if_any_worker_fails()
RuntimeError: DataLoader worker (pid 103) is killed by signal: Bus error. It is possible that dataloader's workers are out of shared memory. Please try to raise your shared memory limit.
とりあえずインスタンスタイプはいちばん安いml.t3.mediumに変更して、カスタムイメージでshmのサイズを増やせないか調べる。てかノートブックインスタンスでカスタムイメージって使えるのかな?(推論用のエンドポイント上でしか使えないんじゃないか、という懸念)
大丈夫そう。
使わなくなったインスタンスは、ちゃんとdeleteすること。。
Add a Studio-compatible container image to Amazon ECR - Amazon SageMaker
!aws ecr create-repository --repository-name smstudio-custom --image-scanning-configuration scanOnPush=true
{
"repository": {
"repositoryArn": "arn:aws:ecr:ap-northeast-1:xxxxxxxx:repository/smstudio-custom",
"registryId": "xxxxxxxx",
"repositoryName": "smstudio-custom",
"repositoryUri": "xxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/smstudio-custom",
"createdAt": 1622604099.0,
"imageTagMutability": "MUTABLE",
"imageScanningConfiguration": {
"scanOnPush": true
},
"encryptionConfiguration": {
"encryptionType": "AES256"
}
}
}
install the cli
!pip install sagemaker-studio-image-build
コンテナイメージのビルドはローカルでやることにした。pyenvで3.6.9に切り替えて、venvで環境作った。
❯❯❯ wget https://raw.githubusercontent.com/docker-library/python/ec37e63c36278c8916d1e758bd551b5d3f0f6db6/3.6/buster/slim/Dockerfile
❯❯❯ aws --region ap-northeast-1 ecr get-login-password | docker login --username AWS --password-stdin xxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/smstudio-custom
Login Succeeded
❯❯❯ docker build . -t my_base_python36 -t xxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/smstudio-custom:my_base_python36
[+] Building 450.3s (9/9) FINISHED
.....
Use 'docker scan' to run Snyk tests against images to find vulnerabilities and learn how to fix them
❯❯❯ docker push xxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/smstudio-custom:my_base_python36
The push refers to repository [xxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/smstudio-custom]
.....
参考:
作成したイメージを Amazon SageMaker に登録
dockerイメージとしては_を名前に使ってOKだったけど、sagemaker imageとしては_は使ってはいけなかった。失敗した。
❯❯❯ set ACCOUNT_ID xxxxxxxx
❯❯❯ set IMAGE_NAME my_base_python36
❯❯❯ set REGION ap-northeast-1
❯❯❯ set ROLE_ARN arn:aws:iam::XXXXXXXXX
❯❯❯ aws --region ${REGION} sagemaker create-image --image-name ${IMAGE_NAME} --role-arn ${ROLE_ARN}
fish: Variables cannot be bracketed. In fish, please use {$REGION}.
aws --region ${REGION} sagemaker create-image --image-name ${IMAGE_NAME} --role-arn ${ROLE_ARN}
^
❯❯❯ aws --region {$REGION} sagemaker create-image --image-name {$IMAGE_NAME} --role-arn {$ROLE_ARN}
An error occurred (ValidationException) when calling the CreateImage operation: 1 validation error detected: Value 'my_base_python36' at 'imageName' failed to satisfy constraint: Member must satisfy regular expression pattern: ^[a-zA-Z0-9]([-.]?[a-zA-Z0-9]){0,62}$
❯❯❯ set SM_IMAGE_NAME my-base-py36
❯❯❯ (main ☡=) aws --region {$REGION} sagemaker create-image --image-name {$SM_IMAGE_NAME} --role-arn {$ROLE_ARN}
{
"ImageArn": "arn:aws:sagemaker:ap-northeast-1:xxxxxxxx:image/my-base-py36"
}
❯❯❯ aws --region {$REGION} sagemaker create-image-version --image-name {$SM_IMAGE_NAME} --base-image "{$ACCOUNT_ID}.dkr.ecr.{$REGION}.amazonaws.com/smstudio-custom:{$IMAGE_NAME}"
{
"ImageVersionArn": "arn:aws:sagemaker:ap-northeast-1:xxxxxxxx:image-version/my-base-py36/1"
}
❯❯❯ aws --region {$REGION} sagemaker describe-image-version --image-name {$IMAGE_NAME}
An error occurred (ValidationException) when calling the DescribeImageVersion operation: 1 validation error detected: Value 'my_base_python36' at 'imageName' failed to satisfy constraint: Member must satisfy regular expression pattern: ^[a-zA-Z0-9]([-.]?[a-zA-Z0-9]){0,62}$
❯❯❯ aws --region {$REGION} sagemaker describe-image-version --image-name {$SM_IMAGE_NAME}
{
"BaseImage": "{xxxxxxxx}.dkr.ecr.{ap-northeast-1}.amazonaws.com/smstudio-custom:{my_base_python36}",
"CreationTime": "2021-06-02T17:04:40.335000+09:00",
"FailureReason": "Invalid ECR image uri: {xxxxxxxx}.dkr.ecr.{ap-northeast-1}.amazonaws.com/smstudio-custom:{my_base_python36}",
"ImageArn": "arn:aws:sagemaker:ap-northeast-1:xxxxxxxx:image/my-base-py36",
"ImageVersionArn": "arn:aws:sagemaker:ap-northeast-1:xxxxxxxx:image-version/my-base-py36/1",
"ImageVersionStatus": "CREATE_FAILED",
"LastModifiedTime": "2021-06-02T17:04:40.612000+09:00",
"Version": 1
}
❯❯❯
ダブルクオーテーションが邪魔をしていたので、除去して再実行。
❯❯❯ aws --region {$REGION} sagemaker create-image-version --image-name {$SM_IMAGE_NAME} --base-image {$ACCOUNT_ID}.dkr.ecr.{$REGION}.amazonaws.com/smstudio-custom:{$IMAGE_NAME}
{
"ImageVersionArn": "arn:aws:sagemaker:ap-northeast-1:xxxxxxxx:image-version/my-base-py36/2"
}
❯❯❯ aws --region {$REGION} sagemaker describe-image-version --image-name {$SM_IMAGE_NAME}
{
"BaseImage": "xxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/smstudio-custom:my_base_python36",
"CreationTime": "2021-06-02T17:11:48.109000+09:00",
"FailureReason": "Repository smstudio-custom_base_python36 doesn't exist in the region ap-northeast-1",
"ImageArn": "arn:aws:sagemaker:ap-northeast-1:xxxxxxxx:image/my-base-py36",
"ImageVersionArn": "arn:aws:sagemaker:ap-northeast-1:xxxxxxxx:image-version/my-base-py36/2",
"ImageVersionStatus": "CREATE_FAILED",
"LastModifiedTime": "2021-06-02T17:11:48.314000+09:00",
"Version": 2
}
❯❯❯ (main ☡=) aws --region {$REGION} sagemaker describe-image --image-name {$SM_IMAGE_NAME}
{
"CreationTime": "2021-06-02T17:03:37.482000+09:00",
"ImageArn": "arn:aws:sagemaker:ap-northeast-1:xxxxxxxx:image/my-base-py36",
"ImageName": "my-base-py36",
"ImageStatus": "CREATED",
"LastModifiedTime": "2021-06-02T17:11:48.109000+09:00",
"RoleArn": "xxxxxxxx"
}
DockerイメージURIは正しく指定できたはずだが、またバージョンの作成に失敗した。sagemakerイメージとしては作成できてるようだが、バージョンがなぜか作成できない。マネコン上でバージョン作成試しても同じ結果だった(失敗した)。
"Repository smstudio-custom_base_python36 doesn't exist in the region...."と出てたけど、dockerのイメージ名とsagemakerイメージ名が一致してないとダメなのかな?
コンテナイメージ名(タグ名?)自体を_を使用せず-を使用した名前でつけなおしたら、いけた。
❯❯❯ docker build . -t {$SM_IMAGE_NAME} -t {$ACCOUNT_ID}.dkr.ecr.{$REGION}.amazonaws.com/smstudio-custom:{$SM_IMAGE_NAME}
.....
❯❯❯ docker push {$ACCOUNT_ID}.dkr.ecr.{$REGION}.amazonaws.com/smstudio-custom:{$SM_IMAGE_NAME}
The push refers to repository [xxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/smstudio-custom]
.....
❯❯❯ aws --region {$REGION} sagemaker create-image-version --image-name {$SM_IMAGE_NAME} --base-image {$ACCOUNT_ID}.dkr.ecr.{$REGION}.amazonaws.com/smstudio-custom:{$SM_IMAGE_NAME}
{
"ImageVersionArn": "arn:aws:sagemaker:ap-northeast-1:xxxxxxxx:image-version/my-base-py36/4"
}
❯❯❯ aws --region {$REGION} sagemaker describe-image-version --image-name {$SM_IMAGE_NAME}
{
"BaseImage": "xxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/smstudio-custom:my-base-py36",
"ContainerImage": "xxxxxxxx",
"CreationTime": "2021-06-02T18:00:01.965000+09:00",
"ImageArn": "arn:aws:sagemaker:ap-northeast-1:xxxxxxxx:image/my-base-py36",
"ImageVersionArn": "arn:aws:sagemaker:ap-northeast-1:xxxxxxxx:image-version/my-base-py36/4",
"ImageVersionStatus": "CREATED",
"LastModifiedTime": "2021-06-02T18:00:02.749000+09:00",
"Version": 4
}
appconfigの作成。
app-image-config-input.jsonを作るために、一度ローカルでDockerコンテナを起動する必要がある。ベースにしたDockerファイル上で`jupyter-kernelspec'コマンドをインストールする定義は無かったらから、当然command not foundになる。
❯❯❯ docker run -it {$SM_IMAGE_NAME} bash
root@3c7c002553e5:/# jupyter-kernelspec list
bash: jupyter-kernelspec: command not found
root@3c7c002553e5:/# exit
のecho-kernel-imageをベースにやりなおす。
❯❯❯ git clone https://github.com/aws-samples/sagemaker-studio-custom-image-samples.git
❯❯❯ cd sagemaker-studio-custom-image-samples/examples/echo-kernel-image/
❯❯❯ set SM_IMAGE_NAME echo-kernel
❯❯❯ docker build . -t {$SM_IMAGE_NAME} -t {$ACCOUNT_ID}.dkr.ecr.{$REGION}.amazonaws.com/smstudio-custom:{$SM_IMAGE_NAME}
❯❯❯ docker push {$ACCOUNT_ID}.dkr.ecr.{$REGION}.amazonaws.com/smstudio-custom:{$SM_IMAGE_NAME}
❯❯❯ aws --region {$REGION} sagemaker create-image --image-name {$SM_IMAGE_NAME} --role-arn {$ROLE_ARN}
❯❯❯ aws --region {$REGION} sagemaker create-image-version --image-name {$SM_IMAGE_NAME} --base-image {$ACCOUNT_ID}.dkr.ecr.{$REGION}.amazonaws.com/smstudio-custom:{$SM_IMAGE_NAME}
❯❯❯ aws --region {$REGION} sagemaker describe-image-version --image-name {$SM_IMAGE_NAME}
❯❯❯ aws --region {$REGION} sagemaker create-app-image-config --cli-input-json file://app-image-config-input.json
❯❯❯ vim update-domain-input.json # modify "studio id"
❯❯❯ aws --region {$REGION} sagemaker update-domain --cli-input-json file://update-domain-input.json
StatusがUpdate_Failedになってた。
Failure reason
Image with ARN arn:aws:sagemaker:ap-northeast-1:xxxxxxxx:image/custom-echo-kernel does not exist
実際のimage arnはarn:aws:sagemaker:ap-northeast-1:xxxxxxxx:image/echo-kernelとなってる。
custom-ってどこから来た?
❯❯❯ aws --region {$REGION} sagemaker describe-image-version --image-name {$SM_IMAGE_NAME}
{
.....
"ImageArn": "arn:aws:sagemaker:ap-northeast-1:xxxxxxxx:image/echo-kernel",
.....
"ImageVersionStatus": "CREATED",
.....
"Version": 1
}
これか。
❯❯❯ (main ⚡=) cat update-domain-input.json
{
"DomainId": "xxxxxxxx",
"DefaultUserSettings": {
"KernelGatewayAppSettings": {
"CustomImages": [
{
"ImageName": "custom-echo-kernel", <----これ!!!
"AppImageConfigName": "custom-echo-kernel-image-config"
}
]
}
}
}
AppImageConfigNameは変えてなかったからたぶんcreate-app-image-configした時に使ったapp-image-config-input.jsonに書いてあるcustom-echo-kernel-image-configのままにしてあるから、何もいじらなくてよいはず。
update-domain-input.json'のImageNameをecho-kernelに変更して再度update-domain`実行。無事イメージがstudioにアタッチされた。

studioでjupyter serverをシャットダウンして、まだserver appがdeleteになってない状態でopen studioクリックしたら502 bad gatewayが返ってきた。
来たー!
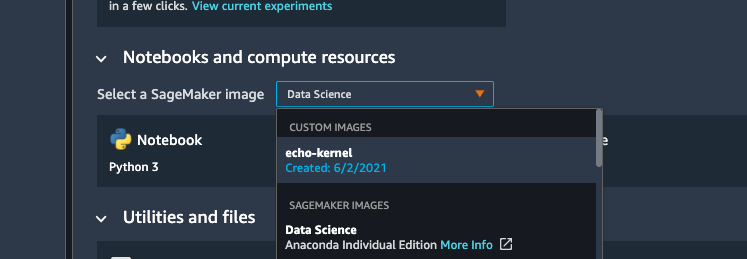
カスタムイメージでノートブック起動してみたが、なんか挙動が変。

あ、"echo"って、そういうこと??w
のFROMをpython:3.6に変更して、イメージを改めて作成。
❯❯❯ set SM_IMAGE_NAME base-py36
❯❯❯ docker build . -t {$SM_IMAGE_NAME} -t {$ACCOUNT_ID}.dkr.ecr.{$REGION}.amazonaws.com/smstudio-custom:{$SM_IMAGE_NAME}
❯❯❯ docker push {$ACCOUNT_ID}.dkr.ecr.{$REGION}.amazonaws.com/smstudio-custom:{$SM_IMAGE_NAME}
❯❯❯ aws --region {$REGION} sagemaker create-image --image-name {$SM_IMAGE_NAME} --role-arn {$ROLE_ARN}
❯❯❯ aws --region {$REGION} sagemaker create-image-version --image-name {$SM_IMAGE_NAME} --base-image {$ACCOUNT_ID}.dkr.ecr.{$REGION}.amazonaws.com/smstudio-custom:{$SM_IMAGE_NAME}
❯❯❯ aws --region {$REGION} sagemaker describe-image-version --image-name {$SM_IMAGE_NAME}
❯❯❯ docker run -it {$SM_IMAGE_NAME} bash
root@xxxxxxxx:/# jupyter-kernelspec list
Available kernels:
python3 /usr/local/share/jupyter/kernels/python3
❯❯❯ docker run -it -p 8888:8888 {$IMAGE_NAME} bash -c 'pip install jupyter_kernel_gateway && jupyter-kernelgateway --ip 0.0.0.0 --debug --port 8888'
KernelGatewayが起動。別ターミナルで以下を実行。
❯❯❯ curl http://0.0.0.0:8888/api/kernelspecs
{"default": "python3", "kernelspecs": {"python3": {"name": "python3", "spec": {"argv": ["python", "-m", "ipykernel_launcher", "-f", "{connection_file}"], "env": {}, "display_name": "Python 3", "language": "python", "interrupt_mode": "signal", "metadata": {}}, "resources": {"logo-32x32": "/kernelspecs/python3/logo-32x32.png", "logo-64x64": "/kernelspecs/python3/logo-64x64.png"}}}}
❯❯❯ docker run -it {$SM_IMAGE_NAME} bash
root@xxxx:/# id -u
0
root@xxxx:/# id -g
0
以上を踏まえて、app-image-config-input.jsonはconfig nameのみ変更して以下の通りとした。
❯❯❯ cat app-image-config-input.json
{
"AppImageConfigName": "base-py36",
"KernelGatewayImageConfig": {
"KernelSpecs": [
{
"Name": "python3",
"DisplayName": "Python 3"
}
],
"FileSystemConfig": {
"MountPath": "/root/data",
"DefaultUid": 0,
"DefaultGid": 0
}
}
}
❯❯❯ cat update-domain-input.json
{
"DomainId": "<domain-id>",
"DefaultUserSettings": {
"KernelGatewayAppSettings": {
"CustomImages": [
{
"ImageName": "base-py36",
"AppImageConfigName": "base-py36"
}
]
}
}
}
❯❯❯ aws --region {$REGION} sagemaker update-domain --cli-input-json file://update-domain-input.json
いけたー!!
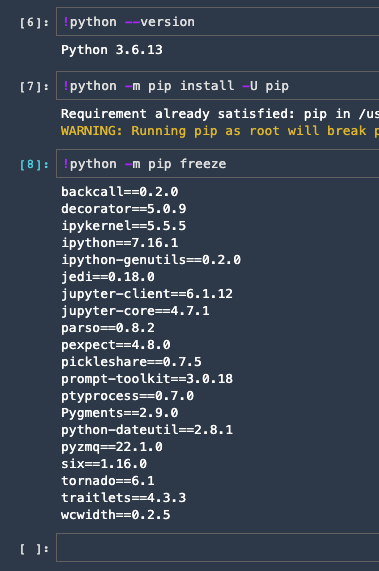
shmは、いじってなかったので、68Mのまま。
!df -H
Filesystem Size Used Avail Use% Mounted on
overlay 19G 87k 19G 1% /
tmpfs 68M 0 68M 0% /dev
tmpfs 2.1G 0 2.1G 0% /sys/fs/cgroup
shm 68M 0 68M 0% /dev/shm
127.0.0.1:/200005 9.3E 68G 9.3E 1% /root/data
/dev/nvme0n1p1 90G 8.0G 82G 9% /opt/.sagemakerinternal
devtmpfs 2.1G 0 2.1G 0% /dev/tty
tmpfs 2.1G 0 2.1G 0% /proc/acpi
tmpfs 2.1G 0 2.1G 0% /sys/firmware
docker buildに--shm=2gみたいなオプション指定してイメージ作り直したが、これではダメっぽい。
As explained here, the default shared memory for docker is quite low.
PyTorch uses shared memory to share data between processes, so if torch multiprocessing is used (e.g. for multithreaded data loaders) the default shared memory segment size that container runs with is not enough, and you should increase shared memory size either with --ipc=host or --shm-size command line options to nvidia-docker run.
Our default build command does not have --shm-size arg. But if you want to configure this variable, you can use our pre-built PyTorch image and extend from it to customize your container.
Here's an example of Extending our PyTorch containers
ここに書いてあるコンテナを使えば、shmが増量されているようだけど、プリインストールのPyTorchのバージョンが古いw
FROM python:3.6
RUN pip install ipykernel && \
python -m ipykernel install --sys-prefix
でつくったコンテナを起動した直後のpip freeze結果
backcall==0.2.0
decorator==5.0.9
ipykernel==5.5.5
ipython==7.16.1
ipython-genutils==0.2.0
jedi==0.18.0
jupyter-client==6.1.12
jupyter-core==4.7.1
parso==0.8.2
pexpect==4.8.0
pickleshare==0.7.5
prompt-toolkit==3.0.18
ptyprocess==0.7.0
Pygments==2.9.0
python-dateutil==2.8.1
pyzmq==22.1.0
six==1.16.0
tornado==6.1
traitlets==4.3.3
wcwidth==0.2.5
この状態から、voxelpose-pytorhのrequirements.txtをpip installしたあとのpip freeze結果
backcall==0.2.0
cycler==0.10.0
decorator==5.0.9
easydict==1.9
ipykernel==5.5.5
ipython==7.16.1
ipython-genutils==0.2.0
jedi==0.18.0
json-tricks==3.13.2
jupyter-client==6.1.12
jupyter-core==4.7.1
matplotlib==2.0.2
numpy==1.16.2
opencv-python==4.0.0.21
parso==0.8.2
pexpect==4.8.0
pickleshare==0.7.5
Pillow==8.2.0
prettytable==0.7.2
prompt-toolkit==3.0.18
protobuf==3.17.2
ptyprocess==0.7.0
Pygments==2.9.0
pyparsing==2.4.7
python-dateutil==2.8.1
pytz==2021.1
PyYAML==5.4
pyzmq==22.1.0
scipy==1.4.1
six==1.16.0
tensorboardX==2.1
torch==1.4.0
torchvision==0.5.0
tornado==6.1
tqdm==4.29.1
traitlets==4.3.3
wcwidth==0.2.5
ワーカーの数を減らしてみたら、shm不足エラーは出なくなった!
!git diff
diff --git a/configs/campus/prn64_cpn80x80x20.yaml b/configs/campus/prn64_cpn80x80x20.yaml
index 98de5e5..b3b5780 100644
--- a/configs/campus/prn64_cpn80x80x20.yaml
+++ b/configs/campus/prn64_cpn80x80x20.yaml
@@ -8,7 +8,7 @@ DATA_DIR: ''
GPUS: '0'
OUTPUT_DIR: 'output'
LOG_DIR: 'log'
-WORKERS: 4
+WORKERS: 1
PRINT_FREQ: 100
DATASET:
workerは2でもダメだった。
ml.p3.2xlargeで1 epockだけ回して時間を図ろうとしてみた。最後の最後にまたshm不足とエラーになってしまった。。
......
Epoch: [0][2900/3000] Time: 1.100s (0.822s) Speed: 2.7 samples/s Data: 0.000s (0.016s) Loss: 32.198444 (45.030597) Loss_2d: 0.0000000 (0.0000000) Loss_3d: 0.0002321 (0.0002387) Loss_cord: 32.198212 (45.030358) Memory 435533312.0
ERROR: Unexpected bus error encountered in worker. This might be caused by insufficient shared memory (shm).
Traceback (most recent call last):
File "/usr/local/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 761, in _try_get_data
data = self._data_queue.get(timeout=timeout)
File "/usr/local/lib/python3.6/queue.py", line 173, in get
self.not_empty.wait(remaining)
File "/usr/local/lib/python3.6/threading.py", line 299, in wait
gotit = waiter.acquire(True, timeout)
File "/usr/local/lib/python3.6/site-packages/torch/utils/data/_utils/signal_handling.py", line 66, in handler
_error_if_any_worker_fails()
RuntimeError: DataLoader worker (pid 245) is killed by signal: Bus error. It is possible that dataloader's workers are out of shared memory. Please try to raise your shared memory limit.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "run/train_3d.py", line 160, in <module>
main()
File "run/train_3d.py", line 134, in main
precision = validate_3d(config, model, test_loader, final_output_dir)
File "/root/data/voxelpose-pytorch/run/../lib/core/function.py", line 119, in validate_3d
for i, (inputs, targets_2d, weights_2d, targets_3d, meta, input_heatmap) in enumerate(loader):
File "/usr/local/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 345, in __next__
data = self._next_data()
File "/usr/local/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 841, in _next_data
idx, data = self._get_data()
File "/usr/local/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 798, in _get_data
success, data = self._try_get_data()
File "/usr/local/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 774, in _try_get_data
raise RuntimeError('DataLoader worker (pid(s) {}) exited unexpectedly'.format(pids_str))
RuntimeError: DataLoader worker (pid(s) 245) exited unexpectedly
CPU times: user 35.3 s, sys: 13.9 s, total: 49.1 s
Wall time: 41min 41s
num_workersは0にもできるっぽいから、0にして、再度1 epoch学習にチャレンジ。インスタンスはml.g4dn.xlargeに戻した。
epoch 0の学習終了。ml.g4dn.xlargeだと1.5時間くらいかかってしまった。。
いちおう、evaluateスクリプトの実行結果。
%%time
!python test/evaluate.py --cfg configs/campus/prn64_cpn80x80x20.yaml
=> creating /root/data/voxelpose-pytorch/output/campus_synthetic/multi_person_posenet_50/prn64_cpn80x80x20
=> creating /root/data/voxelpose-pytorch/log/campus_synthetic/multi_person_posenet_50/prn64_cpn80x80x202021-06-03-06-28
=> Loading data ..
=> load /root/data/voxelpose-pytorch/data/CampusSeq1/pred_campus_maskrcnn_hrnet_coco.pkl
=> Constructing models ..
=> load models state /root/data/voxelpose-pytorch/output/campus_synthetic/multi_person_posenet_50/prn64_cpn80x80x20/model_best.pth.tar
100%|███████████████████████████████████████████| 56/56 [01:26<00:00, 1.91s/it]
+------------+---------+---------+---------+---------+
| Bone Group | Actor 1 | Actor 2 | Actor 3 | Average |
+------------+---------+---------+---------+---------+
| Head | 98.0 | 99.5 | 94.9 | 97.5 |
| Torso | 100.0 | 100.0 | 100.0 | 100.0 |
| Upper arms | 88.8 | 99.5 | 98.9 | 95.7 |
| Lower arms | 79.6 | 64.0 | 89.9 | 77.8 |
| Upper legs | 100.0 | 100.0 | 100.0 | 100.0 |
| Lower legs | 100.0 | 100.0 | 99.3 | 99.8 |
| Total | 93.5 | 92.6 | 97.1 | 94.4 |
+------------+---------+---------+---------+---------+
CPU times: user 1.09 s, sys: 442 ms, total: 1.53 s
Wall time: 1min 32s
p3.2xlargeでepoch 1を回してみる。
45分くらいでおわった。2倍くらい速いな。
CPU times: user 37.3 s, sys: 14.7 s, total: 52 s
Wall time: 46min 52s
p3.8xlargeでepoch2を回してみたが、2xlargeとほとんど同じ。パラメータをチューニングしないのであれば、8xまで使わなくて良さそう。
CPU times: user 35.1 s, sys: 16 s, total: 51.1 s
Wall time: 46min 29s
p3 vs g4dn