【AI動画生成】Sora 要素技術解説
もう全部OpenAIでいいんじゃないかな
はじめに
月間技術革新です。
ということで、昨日OpenAIから発表された新しい動画生成AI「Sora」が非常に話題となっていますね。
圧倒的な一貫性の保持と1分間に及ぶ長時間動画が生成可能という事で、現状の動画生成技術を圧倒的に凌駕する性能を持っているようです。
在野エンジニアの小手先テクニックなど一笑に付すような圧倒的性能を
Soraの凄さは色んなエンジニアやインフルエンサーがたくさん語っているのでそちらを見てもらうとして、この記事ではSoraを構成する各技術について簡単に解説していければと思います。
Soraの技術構成
論文が公開されているわけではないですが、OpenAIが要素技術の解説ページを公開してくれているため、そのページを参考にしていきます。
原文を見たい方はこちらからどうぞ
全体構成
Soraは以下の技術要素で構成されているとのことです。
- Turning visual data into patches
- Video compression network
- Spacetime latent patches
- Scaling transformers for video generation
- Variable durations, resolutions, aspect ratios
- Sampling flexibility
- Improved framing and composition
- Language understanding
すごく簡単にまとめると以下の4つの要素が主軸です
- 動画データを潜在空間に圧縮した後、Transformerがトークンとして利用できる「時空潜在パッチ」に変換する技術
- Transoformerベースのビデオ拡散モデル
- DALLE3を用いた高精度なビデオキャプショニングによるデータセット作成
こうしてみると、特段新しい技術を使っているわけではないみたいです。
レベルを上げて物理で殴れ。小手先のテクニックよりもレベル(お金・計算資源)の重要さがよくわかります
丁寧に各要素技術の参考論文も提示されていますので、中身を細かく見ていきましょう。
Turning visual data into patches
まずは、「時空潜在パッチ」の作り方から見ていきます。

(出展: https://openai.com/research/video-generation-models-as-world-simulators)
時空潜在パッチを作る前工程として、入力となる動画(ビデオデータ)を潜在空間に圧縮します。
画像生成でいうところのVAEに相当する部分だと思えば大体あっている気がします。
(というか、VAEの論文が引用されているので、そのまんまVAEだと思って問題ないと思います)
これにより計算量が大幅に削減され、Soraはこの圧縮された潜在空間で訓練を行っています。
画像生成ではVAEに変換後そのまま訓練に入っていますが、Soraはもう一つ変換工程を挟み、時空潜在パッチなるものを作っています。
これは、LLMでいうところのテキストトークンに相当するようです。
このパッチ作成技術として紹介されている論文は以下の4つ
-
An image is worth 16x16 words: Transformers for image recognition at scale.
- いわずとしれたVision Transformerの論文
- パッチ化の方法としては、画像を位置に基づいて分割(パッチ化)し、1次元のベクトルに変換(flatten/平滑化)している
- より詳しく知りたい人向け(https://qiita.com/wakayama_90b/items/55bba80338615c7cce73 )

(出展: https://arxiv.org/pdf/2010.11929.pdf )
-
Vivit: A video vision transformer.
- 上記のVision Transformerをベースに、動画も取り扱えるようにした論文
- ここで提案されているパッチ化手法は以下の二つ
- ViTと同様に、位置に基づいてパッチ化し、それをフレーム順に連結する方法(figure2)
- 入力動画を3次元的に捉え、t(フレーム数)×h(パッチの高さ)×w(パッチの横幅)のブロック(チューブ)を抽出し1次元に圧縮する方法(figure3)
- より詳しく知りたい人向け(https://deideeplearning.com/2021/05/26/post-476/ )


(出展: https://arxiv.org/pdf/2103.15691.pdf)
- Masked autoencoders are scalable vision learners.
- パッチ化の手法というよりは、パッチ化した画像を効率よく学習するための論文
- ViTの事前学習として有効
- パッチ化されたトークンの一部をマスク化して入力し、マスク化された部分を復元するタスクを解かせる
- より詳しく知りたい人向け(https://zenn.dev/takoroy/articles/98400e156576df )

(出展: https://arxiv.org/pdf/2111.06377.pdf)
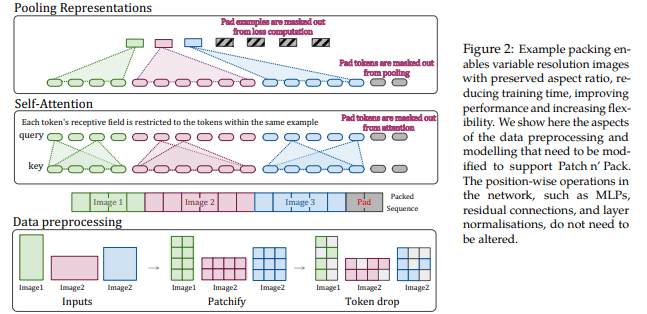
- Patch n'Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution.
- 入力するデータの解像度やアスペクト比を自由に変更できるようにする論文
- ViTが入力するシーケンスの長さを変えられる事を利用し、シーケンスにパッキングを行う事で任意の解像度やアスペクト比を入力できるようにした
- この技術を使うことで、Soraはさまざまな解像度、長さ、アスペクト比のビデオや画像でトレーニングすることができ、推論時に生成されるビデオのサイズを制御することができる
(出展: https://arxiv.org/pdf/2307.06304.pdf)
Scaling transformers for video generation
続いてSoraのモデル構造についてです。
Soraは技術レポートにも書かれている通り拡散モデルベースで作られています。
ここでも色々な論文が紹介されていますが、すべて解説するとものすごく時間がかかるので、画像生成も解説と被りそうなものは省き、一番重要そうな論文だけ紹介します。
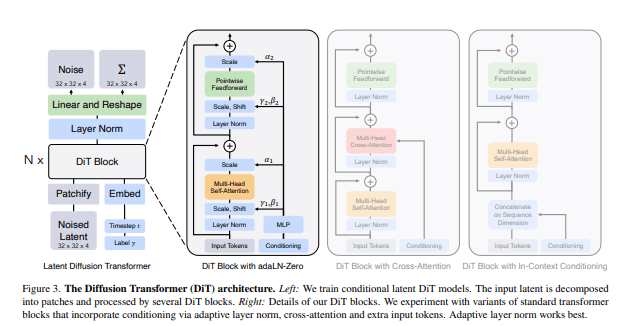
Scalable diffusion models with transformers
DiffusionモデルにTransformerを使った論文です。
StableDiffusion等、今世に出回っているlatent diffusionモデルと一番大きく違うのがこの部分だと思われます。
この論文では、StableDiffusion等が持っているUnet構造をTransformerに置き換えたモデルを紹介しています。
(出展: https://arxiv.org/pdf/2212.09748.pdf)
Soraもおそらくこの論文と同様、もしくは類似した構造を持っていると思われます。
ゆえに、LLM同様のスケーリング則が通用し、超大規模学習を行うことで圧倒的な性能を実現していると考えられます。
より詳しく知りたい人向け(https://qiita.com/sasgawy/items/8546c784bc94d94ef0b2 )
さて、この論文では画像を主に取り扱っていますが、Soraの技術レポートは画像だけじゃなく動画に拡張してもめっちゃ学習回せばうまくいくよ、という内容が示唆されています。
時空潜在パッチにノイズをかけ、Diffusion Transofomerで一気に学習することで、画像を生成するように一括で動画を生成しているようです。

個人的には、ここが一番既存の動画生成モデルと異なる部分だと思います。
AnimateDiffやStable Video Diffusion(こっちはちゃんと論文読み切ってないのでもしかしたら違うかも)はあくまでベースは画像生成であり、そこに時間経過(フレーム推移)を認識できるレイヤーを追加し、直前のフレームと整合性が取れるような画像を生成するモデルでした。
(だからPrompt travelのように、フレーム単位でテキストプロンプトを反映させるみたいな芸当ができる)
一方、Soraはいきなり動画を生成しに行くので、まさしくtext2Videoモデルというのに相応しいアーキテクチャとなっています。
(他に誰がそんなバカげた学習できる計算資源持ってるっていうんだ)
Variable durations, resolutions, aspect ratios
普通の画像/動画生成は入力されたデータを標準化(256×256×4秒とか)しないと取り扱えないけど、Soraはそんなことせずに入力データをそのまま学習できるよ、という技術。
といっても、この仕組み自体は先ほど紹介した 「Patch n'Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution.」 の仕組みをそのまま使用しているように見えるので、特段新しく解説するものはない気がします。
この技術によって、いろんな解像度で生成できるためあらゆるデバイス(画面サイズ)向けのコンテンツに対応した動画を生成できるし、低解像度でプロトタイプを高速生成する、みたいな動きもできるよとの事。
ちなみに、正方形にトリミングするよりも、ネイティブ(入力データそのまま)の画面サイズで学習したほうが出力結果もよくなるとの事。
これは入力シーケンスに自由がきくTransformerの明確な強みですね。
Language understanding
最後です。
高精度なText2Videモデルを作るには、高い精度でキャプショニングされた動画のデータセットが必要不可欠です。
機械学習はデータセットの品質が非常に大事なので、ここも他の動画生成モデルと大きく品質の差がでる要因となっています。
ただ、この項について技術的に解説する部分はあまりありません。
DALLE3を作ってそいつに動画を読み込ませてキャプショニングをさせる、以上です。
無理
終わりに
今回はSoraの要素技術解説を行ってきました。
こうして要素要素を見ていくと特段新しい技術を使っているわけではなく、今まで有効とされた技術を愚直に積み重ね、莫大な資本力と計算力でモデルを訓練すれば強いモデルが作れるという、当たり前の結果が見えてきます。
夢も希望もない
もし技術理解などに間違いがある場合はコメント等で訂正いただけますと幸いです!
ここまで読んでいただきありがとうございました!
Discussion
"Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets"の論文で、
In ourwork, we follow the former approach and show that the resulting model is a strong general motion prior, which can easily be finetuned into an image-to-video or multi-view synthesis model. Additionally, we introduce micro-conditioning [60] on frame rate. We also employ the EDM-framework[48] and significantly shift the noise schedule towards highe rnoise values, which we find to be essential for high-resolution finetuning. See Section 4 for a detailed discussion of the latter.
私たちの研究では、前者のアプローチに従い、結果として得られるモデルが、画像からビデオ、またはマルチビュー合成モデルに簡単に微調整できる、強力な一般的動き事前分布を持つことを示します。さらに、フレームレートに関するマイクロコンディショニング[60]を導入します。また、EDM-framework[48]を採用し、ノイズスケジュールを高ノイズ値へ大幅にシフトします。後者の詳細な議論についてはセクション4を参照。
4.4. Frame Interpolation: To obtain smooth videos at high framerates, we finetune our high-resolution text-to-video model into a frame interpolation model. We follow Blattmann et al.[8] and concatenate the left and right frames to the input of the UNet via masking. The model learns to predict three frames with in the two conditioning frames, effectively increasing the framerate by four. Surprisingly, we found that a very small number of iterations(≈10k) suffices to get a good model. Details and samples can be found in App. D and App.E,respectively.
4.4. フレーム補間: 高フレームレートで滑らかな動画を得るために、高解像度テキスト-動画モデルをフレーム補間モデルに微調整します。Blattmannら[8]に従い、左右のフレームをマスキングによってUNetの入力に連結します。このモデルは2つの条件フレームで3つのフレームを予測することを学習し、フレームレートを効果的に4つ増加させます。驚くべきことに、非常に少ない反復回数(≒10k)で良いモデルが得られることがわかりました。詳細とサンプルはApp. DとApp.Eにそれぞれあります。
D5にその詳細がありますが、「クロスアテンション・コンディショニングのCLIPテキスト表現を、対応する開始フレームと終了フレームのCLIP画像表現に置き換えることで、長さ2のコンディショニング系列を形成しました。AdamW[56]を使用し、学習率10-4、減衰率0.9999のエクスポネンシャル移動平均を組み合わせ、Pmean=1、Pstd=1.2のシフトノイズスケジュールを使用して、空間分解能576×1024の高画質データをモデル化します。 驚くべきことに、私たちは、256という比較にならないほど小さなバッチサイズで訓練したこのモデルが、わずか10回の繰り返しで、極めて高速に収束し、一貫性のある滑らかな出力を得ることを発見しました」とあるので、この論文の段階で、UNetとCLIPを使って時間方向の学習ができていることは発見できていたけど、先行研究の論文(PYoCo:Preserve Your Own Correlation: A Noise Prior for Video Diffusion Models)で、「Video Diffusionにおいて素朴に画像ノイズ事前分布を映像ノイズ事前分布に拡張すると、最適な性能が得られない」ことが発見されていたので、その部分を検証しているため、という理解をしています。
以下は個人的な理解ですが、ゼロショットのビデオ生成と、時間方向の拡散モデルによるフレーム補間は同じアプローチではなく、むしろ逆の要素があります。今回の もなかさん の主旨である「UNetとdiffusionではなくvideo transformer」で実現した、というところは趣旨として間違いではないですが、この分野の各社の研究公開に加えて、OpenAIの組織的な研究統合、西海岸的なリソース集中が功を奏したというところは同意したいところです。今後もどんどん進化しそうですね。
長くなりそうなのでこちらのブログにまとめておきますね