【論文5分まとめ】Masked Autoencoders Are Scalable Vision Learners
概要
Vision Transformer(ViT)の画像認識のための事前学習として、入力画像のパッチをランダムにマスクし、元画像を復元できるよう学習するMasked Autoencoderが優れていることを示した研究。下図の左のように大部分がマスクされた状態から右のように元の画像を復元できるように学習する。

書誌情報
- He, Kaiming, et al. "Masked autoencoders are scalable vision learners." arXiv preprint arXiv:2111.06377 (2021).
- https://arxiv.org/abs/2111.06377
- 公式実装
ポイント
NLPとCVの比較
NLPではMasked Autoencoderを利用した事前学習モデルはBERTなどで当たり前のものになっているが、画像についてはそうなっていない。
- 近年まで画像認識ではTransformerではなくCNNが支配的だった。しかし、ViTの登場により画像もTransformerの対象とできるようになってきた。
- 自然言語の信号は情報が密で高いセマンティクスをもつが、画像は空間的な冗長性が大きく、周辺から比較的簡単に補間(インペイント)が可能である。本手法では、空間的な冗長性を回避するために、画像の大部分(実に75%)のパッチをランダムにマスクするという戦略を採用している。
- NLPでは、Decoderに相当するのはMLPだが、画像の場合は考慮の余地がある。
以上をふまえ、画像表現学習のためのmasked autoencoder(MAE)を提案している。
MAE
MAEは以下のような構造になっている。パッチに分割された画像の一部をマスクし、Encoderに入力する。Encoderの出力に、マスクされたパッチ部分に該当するものを付け加え、Decoderに入力し、元画像を復元できるようにしたい。
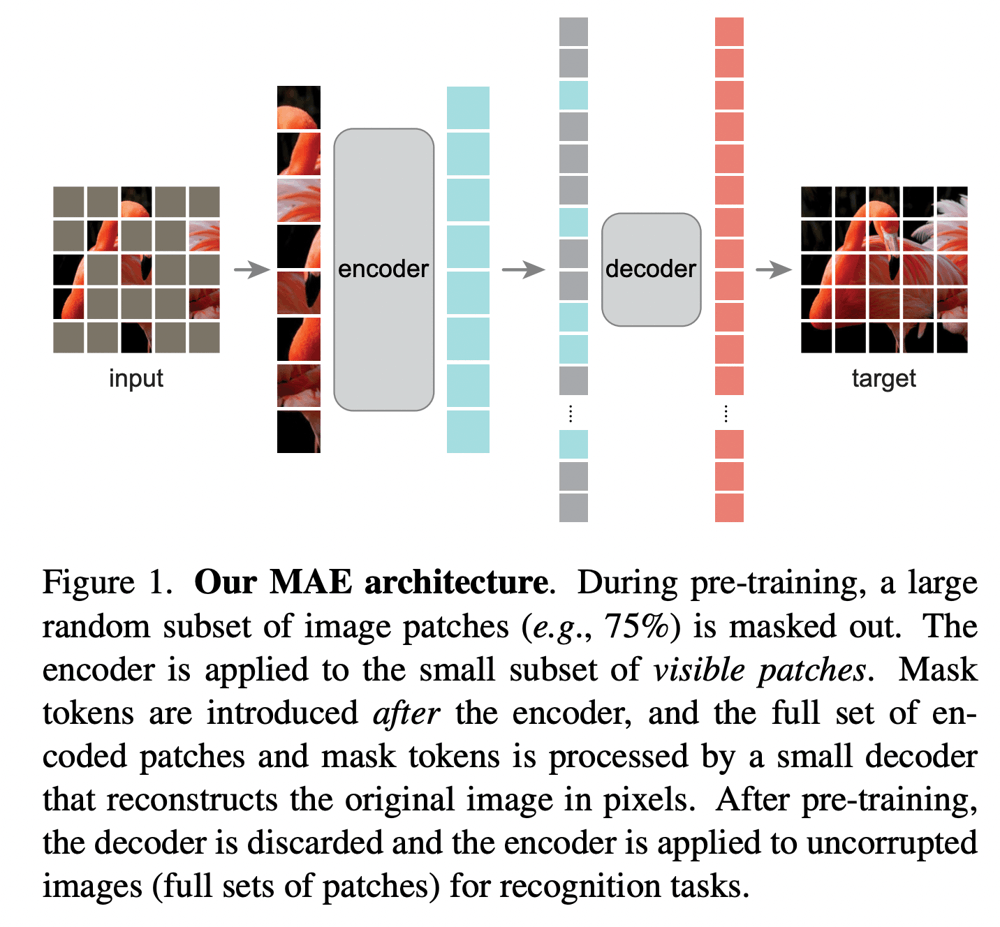
マスク処理
ViTと同様に、まずは画像を重複のないパッチ領域へと分割する。分割されたパッチからいくつかのパッチを一様サンプリングによってランダムにサンプルし、入力に使用する。それ以外のパッチはマスクされていることになる。
マスクの割合は非常に高く、75%で最も良い結果となることが実験によって示されている。これにより、周囲のパッチから容易に補間ができないようにし、適切に学習できることが期待されている。
Encoder
EncoderはViTそのものだが、違いとして、マスクされたパッチは入力しない、ということが挙げられる。つまり、Encoderの入力にはマスクトークンのようなものは使用されない。これにより、入力されるパッチ数が激減し、効率的な訓練が可能になる。入力されたパッチは線形変換によって投影されたのちPositional Embeddingを加え、一連のTransformerのブロックへと入力される。
Decoder
Encoderの出力と、Encoderでは入力されなかったマスクされたパッチに対応するマスクトークンとを結合し、Decoderへの入力とする。全てのマスクトークンは共通のもので、マスク処理でマスクされた位置に対応するようにする。マスクされたパッチについてはPositional Embeddingを加えて、一連のTransformerのブロックへと入力する。Decoderは比較的浅く、Encoderに対して10%未満の計算コストになるような非対称な形となっている。
ターゲットと損失
MAEのターゲットは、元画像のピクセルの値である。損失関数はMSEを使用しており、損失はマスクされたパッチに対してのみ計算されている。これはBERTなどと同じである。
また、別のバージョンとして、パッチ内の平均と標準偏差を用いて正規化して損失を計算する場合も検討していいる。この場合もマスクされたパッチに対してのみ損失が計算される。
BEiTのようにトークンをターゲットとするケースとも比較しているが、正規化されたピクセルの値をターゲットとする場合が、高い精度を実現している。
実装方法
実装上は、以下のような簡単な形でマスク処理を実現している。
- 全てのパッチに対して線形変換とPositional Embeddingを施す。
- パッチをランダムに並べ替え、先頭の一部をEncoderに入力し、残りは除去する。
- Encoderの出力に対してマスクトークンを追加し、ターゲットの順番に合致するように並べ替える。
こういった処理は、特殊な疎なオペレータ等は不要で、一般的なフレームワークで容易に実装でき、並べ替えのオーバーヘッドは微々たるものである。
実験
EncoderとしてViT-Largeを採用し、ImageNet-1Kで800エポック訓練を行うことで事前学習としている。
ImageNet-1Kのクラスを用いてファインチューニングする(ft)場合と、linear probingする場合(lin)に対して、Decoderの深さや幅、マスクする割合や方法などさまざまな選択肢について検証している。

Encoderにマスクされたパッチに対応する部分を取り除くか、取り除かないかを比較している(上図(c))。マスクされたパッチをEncoderに入力しないことで、FLOPsも低下し、精度も向上することが判明している。
マスク処理の方法については、まとまったブロックをマスクする方法、グリッド状にマスクする方法、完全にランダムにマスクする方法を比較し、完全にランダムにすることで最も良い精度が得られることを示している(上図(f)、下図)。

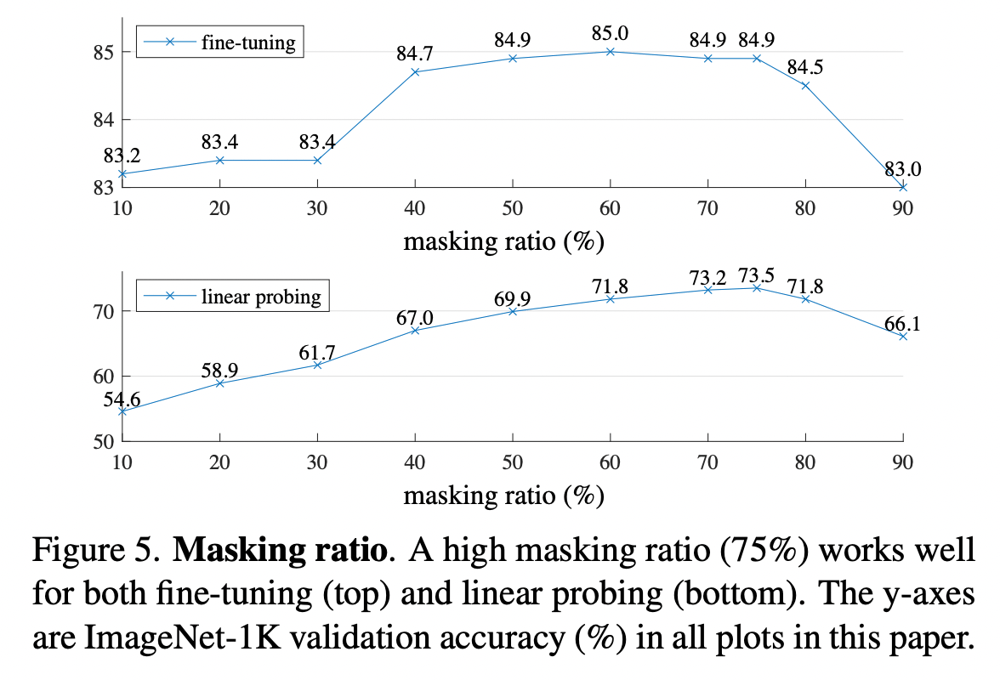
マスクの割合については、75%でft/linともによい精度が得られている。これは、BERTだと15%程度だったマスクの割合に比べると非常に大きく、画像認識の場合の大きな特徴と言える。
Discussion