【LCM高速化】UNetを破壊して低ノイズi2iを高速化しよう!【失敗】
はじめに
最近はLCM及びLCM Loraが非常に好評ですね。
僕も過去にLCM Loraを使ってリアルタイムお絵描きをする記事(https://zenn.dev/aics/articles/3875b6e7f066d3 )を書きましたが、あれから一週間さらにとんでもない発展形が出てきました。
ついにリアルタイム達成です。
グラボは4090を使っているとのことですが、それでも40fpsは驚愕のパフォーマンスです。
僕もLCM/LCM LoRAはリアルタイムお絵描きよりも、VRoidで作った3Dモデルをリアルタイムでアニメ風に変換し、手軽に高精細なアバターを再現する、みたいな使い方こそ本流だと思っていたので、この発展は嬉しい限りです。
それはそれとして、高速化できるという実例を見せられたら、自分もチャレンジしたくなるのはエンジニアの性というもの。
幸い(?)高速化の手法はまだ公開されていないため、考察のしがいがあります。
考察の際、ヒントとなりそうな情報がこちら
どうやらスケジューラーとUNetの改造を行っているとのこと。
スケジューラーについては、低ノイズi2iを行う場合は1ステップで生成可能な事は確認できているので、肝となるのはUNetの改造部分になりそう。
(ちなみに、DiffusersでLCM-Loraを使う際は、Step数=Strength × num_inference_stepsで決まるので、用途によって使い分けると便利です)
本題
というわけでUNetを改造していきます。
LCM-LoRA使用かつ低ノイズi2iを行う場合は、UNetを一回しか通らないのでいかにここを短縮化できるかが肝です。
ここで、StableDiffusion(v1.5)のUNetの構造をおさらいしておきましょう。
v1.5では以下記事で解説されているような構造をしています。
今回使う部分だけを残して簡易化するとこんな感じの5つの層で表されます。
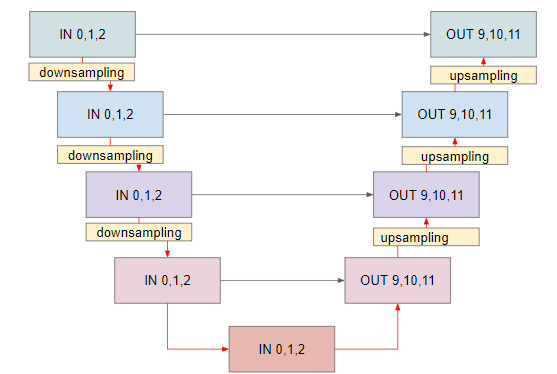
さてこのUNet、階層マージをする時などにもよく出てくるのですが、基本的には下の層ほど画像生成時に抽象的・全体への影響が大きい層となり、上の層ほど局所的・細部への影響が大きいといわれています。
これは、層の下に行くほど入力が次元圧縮される事が理由と考えられます。

さて、改めて今回のお題を考えます。
今回は、「VRoidで作った3Dモデルをリアルタイムでアニメ風に変換し、手軽に高精細なアバターを再現する、みたいな使い方」を目的として高速化に挑んでいます。
この際、3Dモデルをi2iしてアニメ風に変換するわけですが、変換後は3Dモデルにできる限り忠実に、かつテクスチャだけアニメっぽくなってくれるのが理想的です。
そこで私は思いました、入力元の画像に忠実に生成してほしいのだから、全体・抽象的な特徴への影響が大きいUNetの下の層ってこの用途だといらないんじゃないか?と
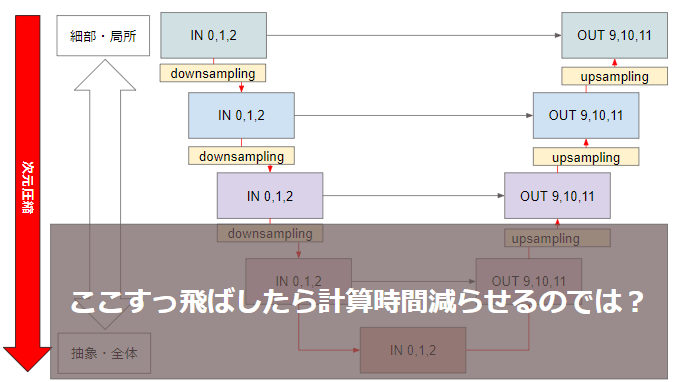
果たしてそんな無茶ができるのか、Diffusersを使って実験していきます。
実装
まずは画像生成時に中間層の処理を飛ばすようにDiffusersを改造します。
UNetの処理はmodels/unet_2d_condition.pyに書かれています。
生成時に中間層をスキップさせるのは非常に簡単で、中間層の処理部分をコメントアウトするだけで処理を飛ばせます。
#ここからUNetの処理
# 3. down
lora_scale = cross_attention_kwargs.get("scale", 1.0) if cross_attention_kwargs is not None else 1.0
if USE_PEFT_BACKEND:
# weight the lora layers by setting `lora_scale` for each PEFT layer
scale_lora_layers(self, lora_scale)
is_controlnet = mid_block_additional_residual is not None and down_block_additional_residuals is not None
# using new arg down_intrablock_additional_residuals for T2I-Adapters, to distinguish from controlnets
is_adapter = down_intrablock_additional_residuals is not None
# maintain backward compatibility for legacy usage, where
# T2I-Adapter and ControlNet both use down_block_additional_residuals arg
# but can only use one or the other
if not is_adapter and mid_block_additional_residual is None and down_block_additional_residuals is not None:
deprecate(
"T2I should not use down_block_additional_residuals",
"1.3.0",
"Passing intrablock residual connections with `down_block_additional_residuals` is deprecated \
and will be removed in diffusers 1.3.0. `down_block_additional_residuals` should only be used \
for ControlNet. Please make sure use `down_intrablock_additional_residuals` instead. ",
standard_warn=False,
)
down_intrablock_additional_residuals = down_block_additional_residuals
is_adapter = True
down_block_res_samples = (sample,)
down_blocks = self.down_blocks
for idx, downsample_block in enumerate(down_blocks):
if hasattr(downsample_block, "has_cross_attention") and downsample_block.has_cross_attention:
# For t2i-adapter CrossAttnDownBlock2D
if idx == len(down_blocks) - 1:
downsample_block.downsamplers = None
additional_residuals = {}
if is_adapter and len(down_intrablock_additional_residuals) > 0:
additional_residuals["additional_residuals"] = down_intrablock_additional_residuals.pop(0)
sample, res_samples = downsample_block(
hidden_states=sample,
temb=emb,
encoder_hidden_states=encoder_hidden_states,
attention_mask=attention_mask,
cross_attention_kwargs=cross_attention_kwargs,
encoder_attention_mask=encoder_attention_mask,
**additional_residuals,
)
else:
sample, res_samples = downsample_block(hidden_states=sample, temb=emb, scale=lora_scale)
if is_adapter and len(down_intrablock_additional_residuals) > 0:
sample += down_intrablock_additional_residuals.pop(0)
down_block_res_samples += res_samples
if is_controlnet:
new_down_block_res_samples = ()
for down_block_res_sample, down_block_additional_residual in zip(
down_block_res_samples, down_block_additional_residuals
):
down_block_res_sample = down_block_res_sample + down_block_additional_residual
new_down_block_res_samples = new_down_block_res_samples + (down_block_res_sample,)
down_block_res_samples = new_down_block_res_samples
"""
# 4. mid
if self.mid_block is not None:
if hasattr(self.mid_block, "has_cross_attention") and self.mid_block.has_cross_attention:
sample = self.mid_block(
sample,
emb,
encoder_hidden_states=encoder_hidden_states,
attention_mask=attention_mask,
cross_attention_kwargs=cross_attention_kwargs,
encoder_attention_mask=encoder_attention_mask,
)
else:
sample = self.mid_block(sample, emb)
# To support T2I-Adapter-XL
if (
is_adapter
and len(down_intrablock_additional_residuals) > 0
and sample.shape == down_intrablock_additional_residuals[0].shape
):
sample += down_intrablock_additional_residuals.pop(0)
if is_controlnet:
sample = sample + mid_block_additional_residual
"""
# 5. up
up_blocks = self.up_blocks
for i, upsample_block in enumerate(up_blocks):
is_final_block = i == len(up_blocks) - 1
res_samples = down_block_res_samples[-len(upsample_block.resnets):]
down_block_res_samples = down_block_res_samples[: -len(upsample_block.resnets)]
# if we have not reached the final block and need to forward the
# upsample size, we do it here
if not is_final_block and forward_upsample_size:
upsample_size = down_block_res_samples[-1].shape[2:]
if hasattr(upsample_block, "has_cross_attention") and upsample_block.has_cross_attention:
if idx == 0:
upsample_block.upsamplers = None
sample = upsample_block(
hidden_states=sample,
temb=emb,
res_hidden_states_tuple=res_samples,
encoder_hidden_states=encoder_hidden_states,
cross_attention_kwargs=cross_attention_kwargs,
upsample_size=upsample_size,
attention_mask=attention_mask,
encoder_attention_mask=encoder_attention_mask,
)
else:
sample = upsample_block(
hidden_states=sample,
temb=emb,
res_hidden_states_tuple=res_samples,
upsample_size=upsample_size,
scale=lora_scale,
)
#ここまで
これで中間層が処理されなくなったので、生成結果を見てみましょう。
ベースラインとなるUNetのスキップを行わない方法では、同条件で1枚生成するのに約FPS2.5くらいでした(撮ったベースラインの動画を紛失した)
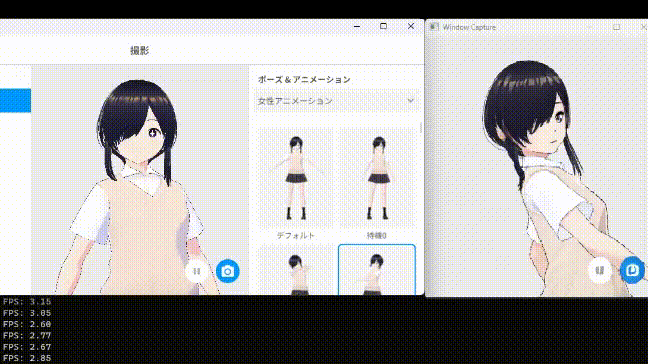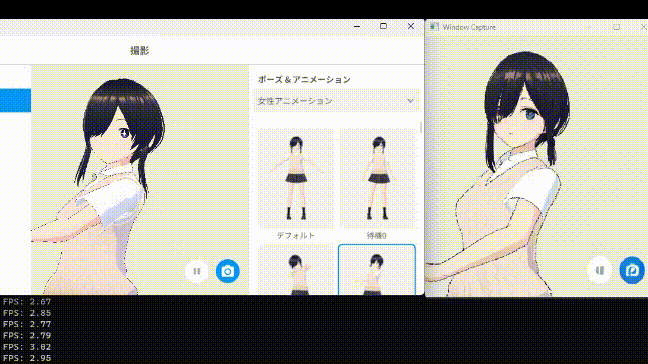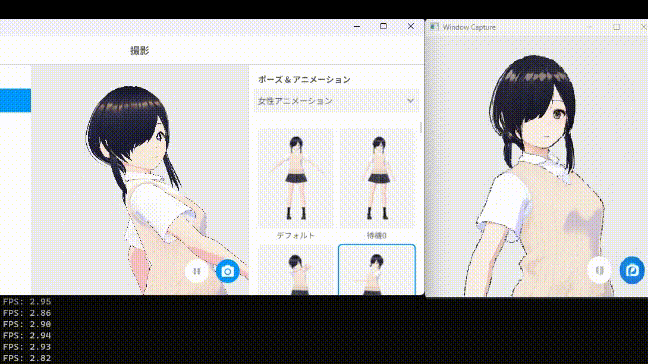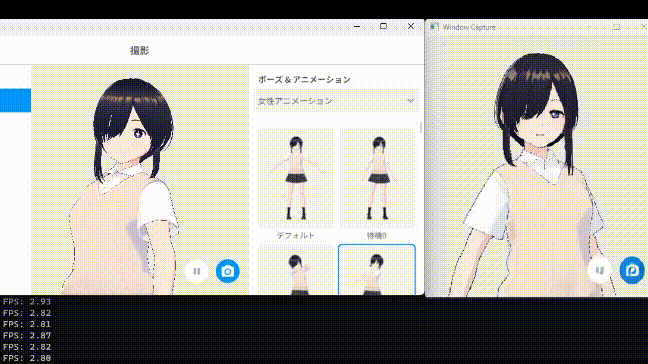
中間層をスキップしてもほぼ生成結果に影響がない事がわかりました。
…が、一方で生成速度はあまり変わっていません。
もう一層削ってみましょう。
次はUNetの第4層を削ります。
第4層は中間層と違い、スキップするのにいくつか手順が必要となります。
まずは、第4層のサンプリング層が邪魔なので、ダウン/アップともに入力テンソルがこの層を通らないようにしましょう。
有難い事に、第4層を構成しているCrossAttn層は、サンプリング層がオフにできるように作られています。
class CrossAttnUpBlock2D(nn.Module):
#省略
def forward(#省略) -> torch.FloatTensor:
#省略
if self.upsamplers is not None: #samplersがNoneの時は、サンプリング層の処理が行われない
for upsampler in self.upsamplers:
hidden_states = upsampler(hidden_states, upsample_size, scale=lora_scale)
return hidden_states
サンプリング層を削ることで、左(ダウン)側第3層の出力を右(アップ)側第3層にそのまま入力できるようになります。
サンプリング層を削ったのち、第4層の処理をスキップするようにunet_2d_condition.pyを書き換えます。
# 3. down
lora_scale = cross_attention_kwargs.get("scale", 1.0) if cross_attention_kwargs is not None else 1.0
if USE_PEFT_BACKEND:
# weight the lora layers by setting `lora_scale` for each PEFT layer
scale_lora_layers(self, lora_scale)
is_controlnet = mid_block_additional_residual is not None and down_block_additional_residuals is not None
# using new arg down_intrablock_additional_residuals for T2I-Adapters, to distinguish from controlnets
is_adapter = down_intrablock_additional_residuals is not None
# maintain backward compatibility for legacy usage, where
# T2I-Adapter and ControlNet both use down_block_additional_residuals arg
# but can only use one or the other
if not is_adapter and mid_block_additional_residual is None and down_block_additional_residuals is not None:
deprecate(
"T2I should not use down_block_additional_residuals",
"1.3.0",
"Passing intrablock residual connections with `down_block_additional_residuals` is deprecated \
and will be removed in diffusers 1.3.0. `down_block_additional_residuals` should only be used \
for ControlNet. Please make sure use `down_intrablock_additional_residuals` instead. ",
standard_warn=False,
)
down_intrablock_additional_residuals = down_block_additional_residuals
is_adapter = True
down_block_res_samples = (sample,)
down_blocks = self.down_blocks[:-1] #右(ダウン)側第4層をスキップする
for idx, downsample_block in enumerate(down_blocks):
if hasattr(downsample_block, "has_cross_attention") and downsample_block.has_cross_attention:
# For t2i-adapter CrossAttnDownBlock2D
if idx == len(down_blocks) - 1:
downsample_block.downsamplers = None
additional_residuals = {}
if is_adapter and len(down_intrablock_additional_residuals) > 0:
additional_residuals["additional_residuals"] = down_intrablock_additional_residuals.pop(0)
sample, res_samples = downsample_block(
hidden_states=sample,
temb=emb,
encoder_hidden_states=encoder_hidden_states,
attention_mask=attention_mask,
cross_attention_kwargs=cross_attention_kwargs,
encoder_attention_mask=encoder_attention_mask,
**additional_residuals,
)
else:
sample, res_samples = downsample_block(hidden_states=sample, temb=emb, scale=lora_scale)
if is_adapter and len(down_intrablock_additional_residuals) > 0:
sample += down_intrablock_additional_residuals.pop(0)
down_block_res_samples += res_samples
if is_controlnet:
new_down_block_res_samples = ()
for down_block_res_sample, down_block_additional_residual in zip(
down_block_res_samples, down_block_additional_residuals
):
down_block_res_sample = down_block_res_sample + down_block_additional_residual
new_down_block_res_samples = new_down_block_res_samples + (down_block_res_sample,)
down_block_res_samples = new_down_block_res_samples
"""
# 4. mid
if self.mid_block is not None:
if hasattr(self.mid_block, "has_cross_attention") and self.mid_block.has_cross_attention:
sample = self.mid_block(
sample,
emb,
encoder_hidden_states=encoder_hidden_states,
attention_mask=attention_mask,
cross_attention_kwargs=cross_attention_kwargs,
encoder_attention_mask=encoder_attention_mask,
)
else:
sample = self.mid_block(sample, emb)
# To support T2I-Adapter-XL
if (
is_adapter
and len(down_intrablock_additional_residuals) > 0
and sample.shape == down_intrablock_additional_residuals[0].shape
):
sample += down_intrablock_additional_residuals.pop(0)
if is_controlnet:
sample = sample + mid_block_additional_residual
"""
# 5. up
up_blocks = self.up_blocks[1:] #左(アップ)側第4層をスキップする。右(ダウン)側とはリストの入り方が逆になっている点に注意
for i, upsample_block in enumerate(up_blocks):
is_final_block = i == len(up_blocks) - 1
res_samples = down_block_res_samples[-len(upsample_block.resnets):]
down_block_res_samples = down_block_res_samples[: -len(upsample_block.resnets)]
# if we have not reached the final block and need to forward the
# upsample size, we do it here
if not is_final_block and forward_upsample_size:
upsample_size = down_block_res_samples[-1].shape[2:]
if hasattr(upsample_block, "has_cross_attention") and upsample_block.has_cross_attention:
if idx == 0:
upsample_block.upsamplers = None
sample = upsample_block(
hidden_states=sample,
temb=emb,
res_hidden_states_tuple=res_samples,
encoder_hidden_states=encoder_hidden_states,
cross_attention_kwargs=cross_attention_kwargs,
upsample_size=upsample_size,
attention_mask=attention_mask,
encoder_attention_mask=encoder_attention_mask,
)
else:
sample = upsample_block(
hidden_states=sample,
temb=emb,
res_hidden_states_tuple=res_samples,
upsample_size=upsample_size,
scale=lora_scale,
)
それでは第4層を削った場合の生成結果を見てみましょう。
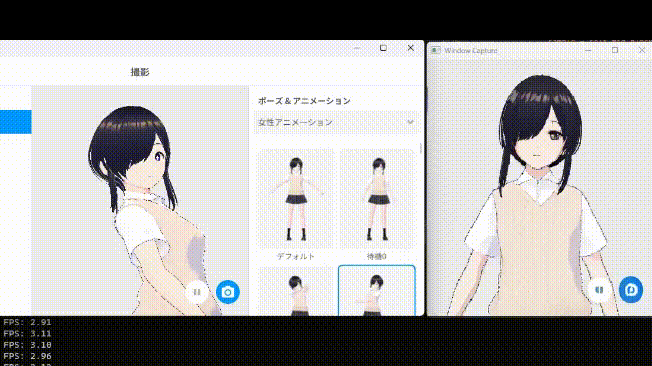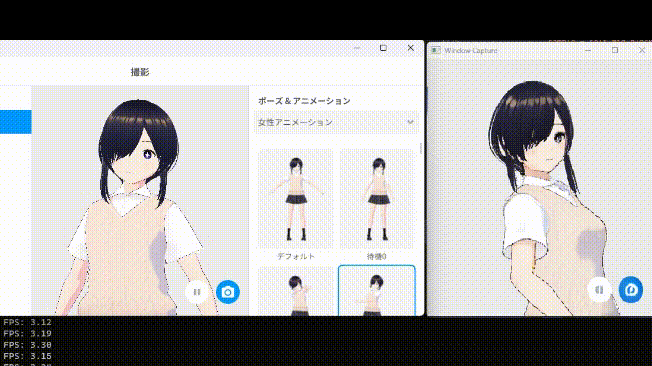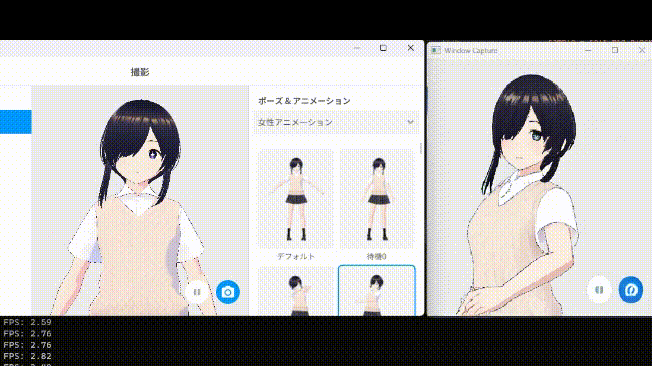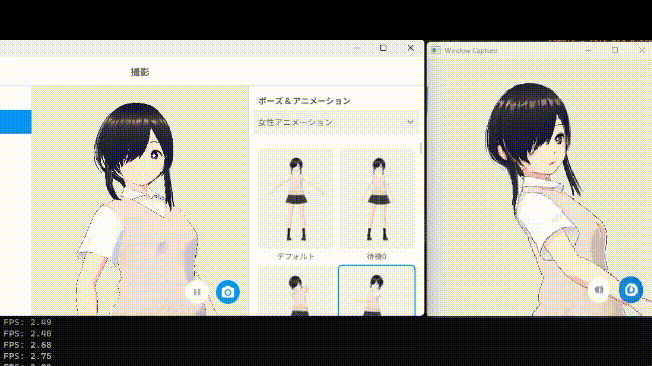
...気持ち早くなりましたね
また、第4層を削ったあたりから生成結果に少し歪みが乗るようになってきています。
まとめ
今回はLCMの高速化を目指して、低ノイズi2iを行う際にUNetの下層を削ったら高速化ができるか?また品質は劣化しないか?の検証を行いました。
結果としては、著しい品質の劣化は見られなかったものの、生成速度への影響も下層を削っただけではそこまで大きくないという知見が得られました。
さて、この記事を書いている間に動詞さんが素晴らしい高速化記事を投稿してくださっていました。
高速化を目指す皆さんは、まずこの記事を参照してみることを強くお勧めします!
幸いなことに、この記事のまだ試していない事の部分に似たような内容の検討(UNetのスキップ)があったので、僕の検証も無駄ではなかったという事にしておきたいと思います。
第3層より上を削った時の検証も後ほど行おうと思いますので、情報更新でき次第、記事にも追記していく予定です。
Discussion