【LCM】512×512pxの画像を0.02秒でリアルタイム画風変換する

はじめに
こんにちは。
一昨日、土日を1日潰してLatent Cosistency Model(LCM)の推論高速化に取り組んでみたところ、そこそこ上手くいき、512×512pxの画像をimage-to-image(img2img)するタスクにおいてRTX3090で26fps、A100で33fpsの推論速度が出るようになりました。
【追記】RTX4090だと45fps出たそうなので、記事のタイトルをわずかに更新しました。記事作成当時はA100で検証していたので、以下ご了承ください。
画像1枚につき0.03秒で処理できていることになるので、ほぼリアルタイムで変換できていると言ってもいいのではないでしょうか。

プログレスバーが1%進むごとに1枚の画像のimg2imgが完了しています。気持ちいいですね。
そこで、この記事では、当高速化に取り組んだとき経験的に(理論的にではない)得られた、LCM推論高速化のTipsについて書いてみようと思います。
LCMをまだご存知ではないという方は、もしかなり暇であればConsistency Modelの提案論文を解説した拙稿をご覧ください。
面倒であれば、LCMのことは単に生成スケジュールが少し変な、なんか生成が速い、LoRA付きのStable Diffusionだと思ってもらっても特に問題は起きません。
なお、今回高速化の対象とするタスクはテキスト条件付けのみによる画像生成(text-to-image)ではなく、テキスト条件付けによる画像合成・編集を行うimg2img(SDEdit)、それもかなり低strength(
また、この記事の最大の注意点ですが、今回の高速化手法探索のプロセスは決して褒められたものではなく、ただ勘でガチャガチャと色んなパラメーターを弄って生成速度を測り、生成結果があまり壊れずに速くなったものを挙げているだけなので、この記事で「良かった」ものとしてとりあげるものが、実は環境が変わったときに全然意味のない手法だったりする可能性があります。ご了承ください。
ベースとなる推論スクリプト(おそい)
以下は、高速化の工夫をする前のスクリプトです。
import time
from dataclasses import dataclass
import numpy as np
import torch
from diffusers import StableDiffusionImg2ImgPipeline
from PIL import Image
from tqdm import tqdm
@dataclass
class Config:
"""
The configuration for the FastLCM.
"""
####################################################################
# Model configuration
####################################################################
# LCM model
model_id_or_path: str = "stablediffusionapi/anything-v5"
# LCM LoRA model
lcm_lora_id_or_path: str = "latent-consistency/lcm-lora-sdv1-5"
# Device to use
device: torch.device = torch.device("cuda")
# Data type
dtype: torch.dtype = torch.float16
####################################################################
# Inference configuration
####################################################################
# Image to transfer
image_path: str = "/app/assets/sample.png"
# Generation resolution
resolution: int = 512
# Prompt
prompt: str = "1girl, (masterpiece, best quality:1.2)"
# Number of inference steps
num_inference_steps: int = 4
# Strength
strength: float = 0.2
# Guidance scale
guidance_scale: float = 1.2
# Original inference steps if not using LCM
original_inference_steps: int = 50
class FastLCM:
def __init__(self, config: Config):
"""
Constructs a FastLCM object.
Parameters
----------
config : Config
The configuration object.
"""
self.config = config
self.lcm_pipeline = self._init_lcm_pipeline()
self._image = self.lcm_pipeline.image_processor.preprocess(
Image.open(self.config.image_path)
.convert("RGB")
.resize((self.config.resolution,) * 2, Image.Resampling.LANCZOS)
)
self._warm_up()
def run(self):
"""
Runs 100 times the faster LCM pipeline, and calculates the
average time and FPS.
"""
times = []
for i in tqdm(range(100)):
start_time = time.time()
image = self.lcm_pipeline(
image=self._image,
prompt=self.config.prompt,
num_inference_steps=int(
self.config.num_inference_steps / self.config.strength
)
+ 1,
strength=self.config.strength,
guidance_scale=self.config.guidance_scale,
original_inference_steps=self.config.original_inference_steps,
output_type="pil",
).images[0]
times.append(time.time() - start_time)
print("num_inference_steps", self.lcm_pipeline._num_timesteps)
image.save(f"assets/output/output_{i}.png")
print(f"Average time: {np.mean(times)}")
print(f"FPS: {1 / np.mean(times)}")
def _init_lcm_pipeline(self) -> StableDiffusionImg2ImgPipeline:
"""
Initializes the LCM pipeline.
Returns
-------
StableDiffusionImg2ImgPipeline
The LCM pipeline.
"""
# Initialize the Img2Img pipeline
lcm_pipeline = StableDiffusionImg2ImgPipeline.from_pretrained(
self.config.model_id_or_path,
safety_checker=None,
feature_extractor=None,
)
# Load LCM LoRA and fuse
lcm_pipeline.load_lora_weights(self.config.lcm_lora_id_or_path)
lcm_pipeline.fuse_lora(lora_scale=1.5)
# Move the pipeline to the GPU
lcm_pipeline.to(device=self.config.device, dtype=self.config.dtype)
# Set the unet to channels last, which accelerates inference a little bit
lcm_pipeline.unet = lcm_pipeline.unet.to(memory_format=torch.channels_last)
# Disable the progress bar
lcm_pipeline.set_progress_bar_config(disable=True)
return lcm_pipeline
def _warm_up(self):
"""
Warms up the LCM pipeline.
"""
for _ in range(3):
self.lcm_pipeline(
image=self._image,
prompt=self.config.prompt,
num_inference_steps=21,
strength=0.1,
guidance_scale=1.2,
original_inference_steps=50,
)
if __name__ == "__main__":
config = Config()
lcm = FastLCM(config)
lcm.run()
実行時間
実行時間は、これから記載のない限りA100/cuda12.1.0/cudnn8.9.1での結果を示します。
Average time: 0.19916863203048707
FPS: 5.020870956461298
高速化に寄与した手法一覧
1. プロンプトの埋め込み表現をPre-computeする
真っ先に思いつくのはこれです。
img2imgの対象がコロコロ変わらない限り、プロンプトをその都度変更する必要はないので、ずっと同じプロンプトを使い回すことになります。
そこで、先に埋め込み表現を計算しておくことで、毎秒何十回も行われるimg2imgの際にCLIP(Text Encoder)の推論を省略できます。
最初にテキスト埋め込みを計算してVRAMに配置しておきましょう。
以下のメソッドをFastLCMクラスに追加し、
def _precompute_prompt_embedding(self) -> torch.FloatTensor:
"""
Precomputes the prompt embedding to speed up the inference.
Returns
-------
torch.FloatTensor
The prompt embedding.
"""
prompt_embedding, _ = self.lcm_pipeline.encode_prompt(
device=self.config.device,
prompt=self.config.prompt,
do_classifier_free_guidance=True,
num_images_per_prompt=1,
clip_skip=2,
)
return prompt_embedding
クラスの初期化時に呼び出して、以後runの際に使用します(最適化した全体のコードは最後に掲載します)。
実行時間
0.1fpsだけ速くなりました。
Average time: 0.19430247068405151
FPS: 5.146614947712452
2. Classifer Free Guidanceをしない
Classifer Free Guidance(CFG)とは、分類器を用いずに生成への条件付けを可能にする手法で、現在では画像生成の条件付け手法としてデファクトスタンダードとなっています。
もしご存知ない場合でも、Stable Diffusion WebUIやDiffusersのデフォルト設定でtext-to-imageをしたことがある方なら既に使ったことがあります。「ネガティブプロンプト」という概念も、CFGの考案によって生まれたものです。
ただし、このCFGには大きなデメリットがあります。というのも、次数1のサンプラーで1ステップの条件付きデノイズを行うとき、CFGを用いない場合はUNet(拡散モデル)を1回呼び出せば処理が終わりますが、CFGを用いると実質的に2回UNetを呼び出す必要があり、それを使わない場合に比べてそれなりに処理が重くなってしまいます。
とはいえ、CFGの導入によってネガティブプロンプトが使えたり、Guidance Scaleの変更によってテキスト条件付けの強度を簡単に調節できたりと、通常のユースケースではデメリットを大きく上回るメリットがあるので、使用しないことはそうそうありません。しかし、今回最優先とするメトリクスは速度なので、大胆に不使用としてしまいましょう。
run時のself.lcm_pipeline呼び出しの際の引数guidance_scaleを1に設定することでClassifer Free Guidanceを無効にできます。
@dataclass
class Config:
"""
The configuration for the FastLCM.
"""
...(省略)...
- guidance_scale: float = 1.2
+ guidance_scale: float = 1
...(省略)...
実行時間
0.5fps早くなりました。結構デカい。
Average time: 0.17843916177749633
FPS: 5.6041509612499985
...
さて、ここまではすぐに取り組むことができる高速化の方策ですが、いかんせんこれだけでは、まだまだ速くなったとは言いがたい速度です。
現状の推論手順をまとめると、おおまかに以下の図中を上から下に順を追って処理している状態です。
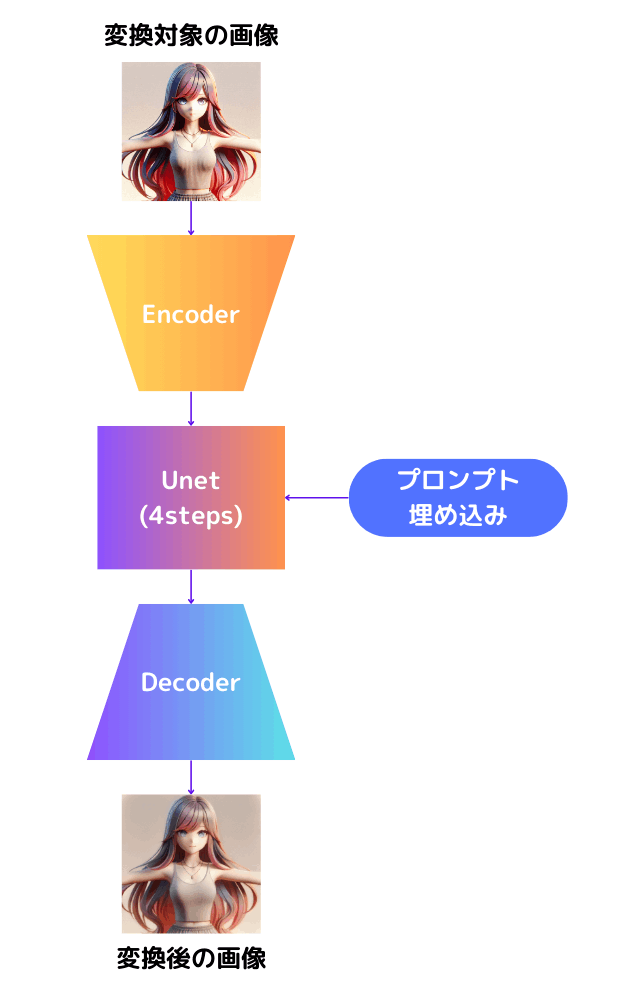
文章にすると、
- Encoderで画像を圧縮して
- 圧縮した表現に微小なノイズを付与(=低strength)し、プロンプト埋め込みで条件付けしながらUNetで4回に分けてデノイズを行い
- Decoderでデノイズ後の画像を復元する
という手順です。重い処理は太字にしています。
つまり、現状の推論手順には重い処理が6回あります。
この処理の回数を減らしたり、減らせない場合は軽くしたりすることができれば、画風変換の処理は劇的に速くなるのではないでしょうか?
ということで、次の3.と4.では、それぞれUNetのステップ数を減らす方策、Encoder-Decoderの処理を軽くする方策を紹介します。
3. LCMSchedulerの改善
この節では、DiffusersのLCMSchedulerに対する改善方策を書いていきます。
a. Euler(っぽいサンプラー)でサンプリングする
DiffusersのLCMSchedulerの実装だと、少ないStep数で推論した場合にやたら発散しやすいので、処理の大部分をEulerに近いものに置き換えました。
単純ですが、これが全体で一番効いています。
b. Timestep Scalingの値をめちゃくちゃデカくする
LCMSchedulerのメンバー変数であるtimestep_scalingは、Consistency Modelを数式で表現したときに現れる、タイムステップ
ここで、
実際のコードでは以下のように登場します。
def get_scalings_for_boundary_condition_discrete(self, timestep):
self.sigma_data = 0.5 # Default: 0.5
scaled_timestep = timestep * self.config.timestep_scaling
c_skip = self.sigma_data**2 / (scaled_timestep**2 + self.sigma_data**2)
c_out = scaled_timestep / (scaled_timestep**2 + self.sigma_data**2) ** 0.5
return c_skip, c_out
...(省略)...
c_skip, c_out = self.get_scalings_for_boundary_condition_discrete(timestep)
...(省略)...
denoised = c_out * predicted_original_sample + c_skip * sample
ここで、
-
predicted_original_sample: 推定したデノイズ後の表現 -
sample: デノイズされる前の表現
となります。1ステップだけで完全にデノイズすることを目標としているタスクなのに、デノイズ前の表現を足す必要は(直感的に考えると)ないので、c_skipはゼロに限りなく近い値であることが望ましいはずです。
timestep_scalingのとる値ごとのc_out、c_skipの値を見てみます。

多分、1e13ぐらいの値であればc_outはほぼ1に、c_skipはほぼ0になってくれることでしょう。
以上に挙げた2つの変更によって、まともな結果を得られる生成ステップ数を4ステップから1ステップまで減らすことができました。
最終的なLCMSchedulerのConfigは以下のようになりました。
{
"_class_name": "LCMScheduler",
"_diffusers_version": "0.22.0.dev0",
"beta_end": 0.012,
- "beta_schedule": "scaled_linear",
+ "beta_schedule": "linear",
"beta_start": 0.0001,
"clip_sample": false,
"clip_sample_range": 1.0,
"dynamic_thresholding_ratio": 0.995,
"num_train_timesteps": 1000,
+ "timestep_scaling": 1e13,
"original_inference_steps": 50,
"prediction_type": "epsilon",
"rescale_betas_zero_snr": false,
"sample_max_value": 1.0,
"set_alpha_to_one": false,
"steps_offset": 0,
"thresholding": false,
- "timestep_spacing": "leading",
+ "timestep_spacing": "linspace",
"trained_betas": null
}
ちなみに、生成の品質はこんな感じです。結構いい感じに画風変換できています。
(Zennにこの画像をアップロードすると画像の品質がえげつないぐらい下がってしまったので、代わりにXにポストしたものをリンクしています)
実行時間
ほぼ2倍の速さになりました。いいですね。
Average time: 0.10019409418106079
FPS: 9.98062818146646
4. Tiny Autoencoder
前節では、UNetの推論回数を減らし、重い処理を6回から3回にすることができました(Encoder、UNet、Docoderで1回ずつ)。次は、重い処理のうちの2つである、Encoder-Decoderの速度改善に取り組みます。
ただし、Encoder-Decoderの処理の回数を減らす、もしくは無くすことは不可能なので、処理を軽くすることを試みます。そこで、Stable Diffusionで使っているEncoder-Decoderの代わりに、madebyollinさんのTAESD(Tiny AutoEncoder for Stable Diffusion)を使ってみましょう。
TAESDは、Stable DiffusionのAutoEncoderからパラメーター数と重い計算処理を劇的に減らしたアーキテクチャーをもつ軽量のEncoder-Decoderです。Decoderを例に挙げると、Stable DiffusionのDecoderのパラメーター数は4950万もある一方、TAESDのDecoderは122万パラメーターしかありませんし、InstanceNormやMatMulのような重い処理も使用されていません。
ただし、TAESDの使用による生成品質の低下はそこそこあり、特に人の顔のような複雑な構造は溶けてしまいがちなので、状況に応じて使い分ける必要があります。今回の目標はなんと言っても速度なので、もちろん採用します。
実行時間
強すぎる…。
Average time: 0.04446950912475586
FPS: 22.487318157584678
5. torch.compile()
ここまでで、1日や2日で素人の人間が見直せるような改善部分は大体見直せたと思うので、最後に計算処理全体の最適化を行います。
torch.compile()の他にAITemplateとStable Fastも試してみましたが、自分の環境ではtorch.compile()がお手軽さも含めて最強でした。
こんな感じでUNetとEncoder-Decoderをコンパイルしてもらいます。
if self.config.compile:
lcm_pipeline.unet = torch.compile(
lcm_pipeline.unet, mode="reduce-overhead", fullgraph=True
)
lcm_pipeline.vae = torch.compile(
lcm_pipeline.vae, mode="reduce-overhead", fullgraph=True
)
あとはただ実行するだけです。お手軽すぎる。
実行時間
ほぼタダでえらい高速化になりました。これが最終的な結果です。
Average time: 0.029962685108184815
FPS: 33.3748459588768
試していない、高速化に寄与しそうな手法
量子化(Q-Diffusion・TensorRTなど)
Q-Diffusionは拡散モデルの生成品質を極力落とさずにW4A8(4-bit weights, 8-bit activations)で推論できるようにした手法です。絶対にめちゃくちゃ強いと思うんですが、量子化のためにキャリブレーションをやる必要があり、ちょっと手間がかかりすぎると思ったので断念しました。
TensorRTも大体同じ理由です。この記事でFuture Worksっぽく書いておくことで誰かやってくれないかなぁと思っています。
UNetの層スキップ
どこかしらは飛ばせる気がしますが、軽く試すには面倒だったのでやりませんでした。これも誰かやってほしいな〜。
試して微妙だった手法
FreeU
Skip Connectionの係数を小さくしてbackboneを通過するほうの係数を大きくしたら、デノイジングが早く進むかな、とか思いましたが、そんなことはありませんでした。
v-prediction
v-predictionはProgressive Distillation for Fast Sampling of Diffusion Modelsで提案され、Google Researchから発表されたImagen Videoで使用されたことで有名になった、少ないステップ数で安定した生成を行うための手法です。
Consistency Modelでも拡散モデルの高速化手法を使っていいのか? そもそもv-predictionってそういうやつだったっけ? など様々な疑問が浮かびますが、LoRAをStable DiffusionにくっつけただけでLCMが出来上がってしまうような現状、なんでもありだろと思い、とりあえず試してみたところ、結構上手くいくことがありました。
ただ、なぜちゃんと動くのかについて後から考えても全然分からなかったので、試して微妙だった手法にカテゴライズしておきます。

v-predictionのイメージ図。Progressive Distillation for Fast Sampling of Diffusion Modelsから引用しています。
Ancestral Sampling
Ancestral Samplingとは、タイムステップごとに予定されていたよりも少し大きくステップ幅をとって進み(予定よりも少し余分にデノイズを行い)、その後少しだけ戻る(ノイズを付与する)ことで帳尻を合わせる、というサンプリング手法です。
AUTOMATIC1111ではEuler a、DPM2 aなどの"a"がついているサンプラーがこの手法を用いていて、少ないステップ数でも比較的良い結果が得られることから好まれています。
ただし、今回の画風変換タスクでは、最終的に1ステップで画風変換を行うようになったためあまり関係がありませんでした。
Dynamic Thresholding
Dynamic ThresholdingはGoogle Researchから発表されたImagenの論文で提案された手法です。
Latent Diffusionで必要なんか? と思いつつ使ってみると発散を防ぐので当初結構良い感じだなと思っていましたが、サンプラーをEuler風に書き換えたら結局必要なくなりました。
おわりに
最終的なコードはこちらです。Dockerfileも用意したので、良かったら遊んでみてください。
Xでは40fps前後出ている人もいらっしゃるようなので、そのうち知見が集まってきて60fpsが達成できたら嬉しいですね。
Discussion