コンテンツ産業に画像生成AIを社会実装する上で越えるべき課題と提案
こんにちは、抹茶もなかです。
もう夏も終わりという事でちょうど区切りの良いタイミングのため、久しぶりにポエム記事でも書こうかと思います。
今回は画像生成AIの社会実装について。
進む高精度化と進まない社会実装
今年も画像生成AIはその速度を緩めることなく成長をし続けています。
アーキテクチャがUnetベースからTransformerベースへ移行し、生成精度も格段に良くなってきました。
FluxやImageFXなど、AIによる生成画像とAIを使用せずに制作された写真・イラストとの区別はどんどんつかなくなってきています。
また、画像生成に留まらず、動画生成も徐々に実用的なレベルに達しつつあり、今年はKling, Vidu, Gen3など去年とは比較にならないほど高精度な動画生成サービスもでてきています。
また、画像生成AIを支える周辺技術も整備され始めており、必要スペックの要求水準引き下げや、より簡易的な環境構築手順の構築など、使い勝手の面でも少なくない変化があります。
しかし、留まる事を知らない成長速度とは裏腹に、実業務での活用、すなわち社会実装は画像生成AIが出現して2年以上たった今でも、あまり進んでいるとは言えません。
確かに、ネット上の広告であったり、短時間のCMなどで画像生成AIで作成された作品は徐々に目にするようになりましたが、出現当時から活用が渇望されているコンテンツ産業、とりわけキャラクタービジネス領域での生成AIの使用は、かなり限定的な用途に留まっているのが現状です。
この理由として、データセットにまつわる権利問題や生成AIを使用することによる炎上リスク
を考慮し、使用を控えているのではないか?等を挙げる方もいると思います。
事実として、上記の懸念点を考慮し使用を控えている企業も多く存在します。
ただもう一方で、現状の法運用であれば上記懸念は許容できるリスクと判断し、活用に向けて動いている企業も少なくない数存在します。
ありがたい事に、私にも画像生成AIの活用に関する相談が多くの企業様から来ており、微力ながら生成AIの活用に向けて助力をさせていただいている状況にあるため、活用に積極的な企業の存在は実体験を通して把握しています。
にもかかわらず、生成AIを積極的に取り入れようとしている企業であっても、実業務への導入はほとんど進んでいないといってよいでしょう。
このことから、画像生成AIに権利・炎上リスクがなかったとしても画像生成AIを実業務に取り入れることは現状困難であり、その理由として画像生成AIが技術的に社会実装に耐えうるレベルに到達できていないのではないか、と私は考えています。
そしておそらく、社会実装に向けて解くべき技術的な課題と、今の画像生成AIが進んでいる進化の方向(高精度化)にもズレがあるため、どれだけ成長速度が速くとも今の方向性のままではいつまでたっても社会実装には至らないのではないか?とも考えています。
「一貫性の維持」というあまりにも大きな課題
では具体的にはどのような課題があるのでしょうか?
この2年間で複数の企業様と活用に向けた協議を重ねた結果、凡そどの企業も同じような課題にぶつかりました。その中でも最たるものが「一貫性の維持」です。
この一貫性にも種類がいくつかあるのですが、概ねキャラクタービジネスで画像生成AIを使用するうえで問題になるのは、配色の一貫性、形状の一貫性、構造の一貫性の3種類だと感じています。
ではなぜこの3つの一貫性が重要になるのでしょうか?
まず、キャラクターをキャラクターたらしめる要因として、「配色」と「形状」は非常に重要です。
登場のたびに毎回髪の色や目の色が変わっていたら(そういうキャラクターがいない事もないですが)、人々はそのキャラクターが同じ人物であると認識することは困難です。
同様に形状に関しても、服装やアクセサリー、体型などに連続性がなければ、やはり同一のキャラクターとして認識することは難しいでしょう。
ここで、ある程度画像生成AIに知見がある方は、キャラクターLoRA等を使えばよいのでは?と思われるかもしれません。
実際に、LoRAやプロンプト、ControlNetなどの制御手法を駆使して、生成される画像にある程度の一貫性を付与し、連続するキャラクターとして運用している方はSNS等にも何人かいらっしゃいます。
ただし、ビジネスとして求められる一貫性のレベルは現状の制御方法で得られる程度の一貫性では全く足りていないというのがこの2年間の結論です。
服装であれば服の形状はもちろんのこと、細かい装飾や丈の長さ、体型による形状の変化まで完璧な一貫性が求められます。
また配色に関しても、ぱっと見同じような色遣いに見える程度ではダメで、同じ服装であるならばいつどんな時でも同じ個所は同じ色が塗られていなければなりません。
(たまに人間がやってもミスってるじゃないかという話はややこしくなるので置いておきます)
また、構造的な一貫性も重要になります。
例えば、髪飾り一つとっても、前から見るときと横から見るとき、後ろから見る時では見える形状が異なります。
複雑な衣装や装飾品にまで、このような別角度から見たときの構造的な矛盾のなさを維持することは、現在の画像生成AIの制御技術では不可能といっても過言ではないでしょう。
ぱっと見同じキャラクターに見える、程度の一貫性では実際のビジネスでは使い物にならないのです。
また漫画やアニメを制作する場合は、この構造的な一貫性というのはより重くのしかかってきます。
というのも、漫画やアニメの様な媒体だと背景に関しても空間的な一貫性が必要になってくるためです。
コマの移動等で視点が切り替わった際、背景も空間的な整合性を保ったまま視点を変えるというのが非常に難しく、現状では背景だけAIを導入するといったこともままなりません
このような課題は現在の生成AI技術の方針である高精度化では解決が難しい課題であり、前項の課題提起につながっていきます。
人とAIの協業は難しい
さて、この問題に対して一番最初に思い浮かぶ対策案が人とAIの協業です。
LoRAやControlNet等を駆使することである程度一貫性を持った画像を生成できるので、一貫性を満たせていない部分だけを人が手描きで修正することで実用化まで持っていこうという方針です。
確かに、この方針であれば最終的には人の手が入るため、品質上はビジネスで使用できるレベルまで持っていくことはできます。
しかし、ここで問題になってくるのがコスト感です。
というのも、生成AIによる画像素材の作成と、人が手で描く画像生成とでは完成までのワークフローが全く異なります。
そのため、AIのワークフローに人間が途中から割り込むことが難しく、また逆に人間のワークフローの一部分にだけAIを使うというのも難しい状況にあります。
例えば、昨今主流のデジタル作画では、線画、下塗り、影、光、仕上げなどをその要素ごとに描き、層のように重ねることで最終的な完成形を成す形式で作品が構成されています。
このようなデータ形式であれば、もし後々修正が必要となった場合でも、線画(形状)だけの修正、下塗り(配色)だけの修正、影や光(光源)だけの修正などを個別に行うことができます。
一方、生成AIによって作られる画像は基本的に完成品を出力するため、このようなレイヤー構造をもっていません。
そのためもし修正するとなった場合は、周囲との整合性を捕りながら違和感が出ないよう線画、下塗り、影や光を全て同時に修正しなければいけなくなります。
このような状況になると、今度はAIを使うよりも一から人が描いたほうが早い場合が出てきてしまい、コストを減らすために導入したはずのAIによって逆にコストが増してしまうという問題に直面してしまうわけです。
これでは当然、画像生成AIを業務に導入はできません。
ではどの程度であればコストが増えることなく使用できるのかというと、案出しや下書き用の参考として使用するのが現状では限界だと思われます。
実際、そのような活用方法はすでに導入されている場所もありますが、これでは画像生成AIの使用は非常に限定的であり、当初期待されていたようなインパクトには全く及びません。
生成AIを扱う技術が特殊技能化しつつある
前項に記載した通り、人とAIの協業では一貫性の課題は解決しない、もしくは非常に限定的な
解決しかできません。
一方で、実は生成AIだけでワークフローを完結させる場合は、もう少し希望があります。
画像生成AIにはinpaintという修正機能があるのですが、これを使うと周囲との整合性を保ったまま修正箇所だけを生成しなおすことができます。
これは、人が手描きで修正するよりも現実的なコストで対応ができ、ただ画像生成をしただけ(いわゆるポン出し)よりかなり高品質かつ一貫性を持った画像を作成できます。
また、最近はNovel AIやMidjourney等を筆頭に、AIで生成した画像を、他のAI機能と組み合わせて生成後に編集できるサービスもでてきました。
まだまだビジネス的に使えるレベルの一貫性を維持できるとは言えませんが、AI技術だけで完結するワークフローを完全に1から作り上げる、といったアプローチは。下手に人間とAIが協業するよりは使えるものになる可能性が高いです。
ただし、この方針にも大きな問題があります。
プロンプトを練って一枚絵を出す程度であればともかく、このような生成後の編集機能を駆使したり、そもそも一枚絵生成時点でControlNetやLoRAのような追加モデルを適切に選択したり、場合によっては自分で追加モデルの学習も行う必要があるなど、画像生成AIの緻密に制御しようとすればするほど、生成AIに特化した知識が必要になってきます。
こうなってくると、とても片手間で触れるような技術ではなくなってしまい、企業では画像生成AIを使用することに特化した人材を用意するか、既存の社員をスキルトランスファーする必要がある等、人的なコスト面で課題が出てきます。
画像生成AIがビジネス上で使い物になるか、将来的にも不透明な状況で上記の策を取るのは前者にしろ後者にしろ博打的な側面が多く、ハードルが高くなってしまい導入に踏み出しきれないという場合が多いです。
ではどうすればよいのか
ここからは、いままであげてきた課題をどう解決すべきかについて、私見を述べていきたいと思います。
まず一つ目は前項でも挙げた通り、AIだけで完結する編集ワークフローを確立する方針です。
ただし、生成AIの特性上厳密な制御をしようとすればするほど難易度が指数的に跳ね上がるため、実用化までには数年単位で時間が必要でしょう。
二つ目は、完成した一枚絵をレイヤー分けできるようにするという方針です。
色々と課題を述べてきましたが、結局のところAIによって生成された画像がレイヤー分けさえできればすぐにでもビジネスに導入できるという状況はかなり多いです。
が、この方針は技術的な難易度が非常に高いのが難点で、以前から僕の活動を知ってくれている方もいるかとおもいますが、僕自身一枚絵のレイヤー分けができないのかかなりの時間をかけて開発に挑んだことがあり、見事に挫折しました。
一応完成はしたものの、このツールは現状作者目線でもおもちゃ程度にしか使えず、ビジネス活用はまず無理です。
にもかかわらず一枚絵のレイヤー分け技術は僕が作ったツールが一番使われているあたり難易度の高さを感じてもらえるかと思います。
最後に3つ目、これが今回提案したい内容になります。
現在、画像生成AIはいきなり完成品を作り出してしまうため既存のワークフローに当てはめることが難しく、人とAIの協業を困難にしています。
つまり、人のワークフローに沿った形で各フロー毎に画像生成が使えるのであれば協業も可能になると考えています。
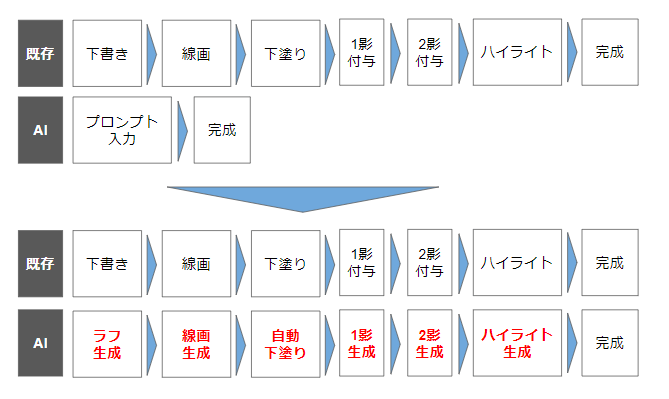
そして、この方針であれば現在のAI技術と画像処理技術を組み合わせるだけでも実現が可能だと考えています。
現在私はこの方針に沿って技術開発を進めていますが、現状ではここまでAIでできるようになりました。
(自動下塗りについては精度に難があるのでもう少し頑張る必要がありますが…)
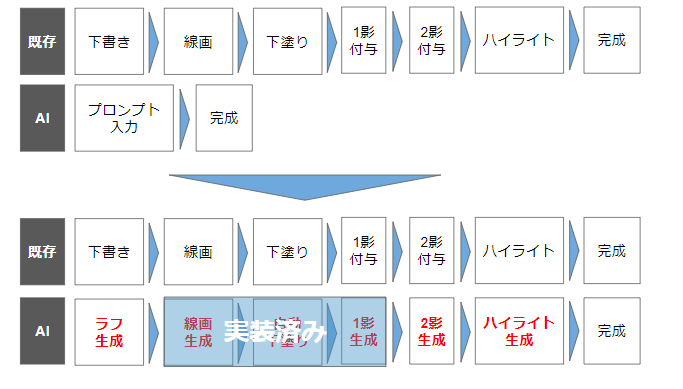
この方針を採用するうえで悩みの種だったのは、ひとつ前のフローで作成した結果は次のフローで完全に引き継げる必要があるという点です。
何も工夫せずに生成AIを使用すると、前のフローとよく似た結果を再生成した上で次のフローの効果を載せる、といった動きになってしまうため、フロー毎に微妙に結果が異なってしまうという課題があったのです。
ただし、この課題も画像処理技術を駆使することで現状ではほぼ解決可能となっています。
また、ワークフローごとに分けて画像生成ができ、かつフロー毎の結果を完全に別のフローへ引き継げるようになると、結果的にレイヤー構造を持ったAI画像を作ることができるようになります。
現時点では、線画、下塗り、1影付与までが生成AIだけで可能ですので、以下のようにレイヤー分けした画像ができるようになります。
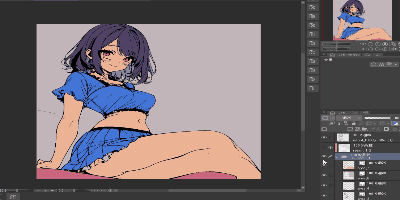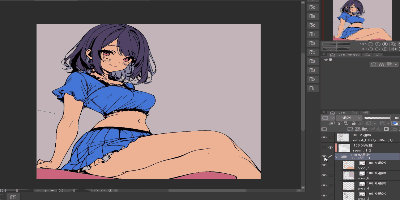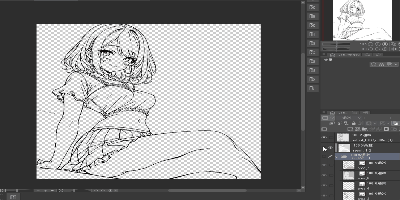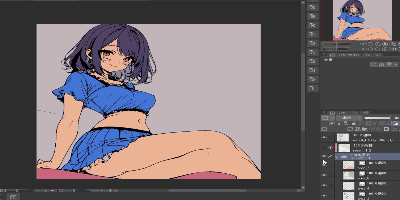
残るは2影(細かい影)とハイライト及びラフ生成ですが、ラフ生成は割と画像生成AI単体でもどうにかなる場合が多く、実質的には2影とハイライトが残る課題となります。
最も、一枚絵をレイヤー分けするのに比べれば技術的な難易度はかなり低いです。
体感として図で示したような粒度であれば、今年中か遅くとも来年には各フロー毎に生成AIの利用が可能になるでしょう。
また、私だけでなく似たような方針で生成AIツールの開発を進めている企業様もあります。
(一部私が作ったものも参考にしてくださっているとのことで、大変感謝です)
いずれにせよ、3つ目の方針に関しては明確な進捗もでてきており、この方針で人とAIが協業する新しいワークフローが確立されるのが最も早いのではないかな、と考えています。
終わりに
今回は技術的な内容はほとんどないポエム回でしたが、実際に私がビジネスに生成AIを導入しようとするうえで課題に感じた点と、その解決方針について提案してみました。
もし画像生成AIの導入を考ている企業様がいらっしゃいましたら、ぜひ今回提案した内容も検討してもらえたら嬉しいです。
画像に限らず、生成AIの発展スピードは恐ろしく速いため将来を予測することは困難です。
なので、今回書いた内容が来年も通用するかは微妙なところではありますが、ひとまずこのような形で社会実装に向けて一歩ずつ着実に進んで行っているんだ、ということを少しでも感じとってもらえたら良いかなと思います。
今日で8月も終わりですが、まだまだ暑い日々が続くと思います。
人間は体が資本ですので、暑さに気をつけて健やかにお過ごしください。
良き生成AIライフを!
Discussion