前置き
こんにちは、抹茶もなかです。
普段は趣味でお絵描きしたり画像処理したりしてます(専門は自然言語処理)
最近では流行りの画像系AI技術(生成やセグメント等)を創作に活用する方法がないか模索しており、その中でも特に一枚絵のレイヤー分け(PSD化)技術の実現に挑戦しています。
作ったレイヤー分けツールはこちら(最新バージョンはAI使う方法も選択できます) ありがたいことにスターも500個ほどいただいており、幾つか記事にもしていただきました。
このレイヤー分けツール、最新版ではAI(Segment Anythingなど)も活用してレイヤー分けを行っていますが、初版では一切AI(学習データを必要とする技術)は使わず、古典的な画像処理のみで制作しました。
今回はその初版レイヤー分けツールについて、AIを使わずどうやってレイヤー分けをしたか?という話をしていこうと思います。それでは本題。
レイヤー分けってなんぞ
いわゆるデジタル絵/デジタルイラストを描くうえで最も基本的な機能の一つが今回取り扱うレイヤー機能になります。
ここでいうレイヤーとは、文字通り「層」を指し、ClipStudio等のデジタルイラスト作成ソフトでは、画像を透明の「レイヤー」(または「層」)として独立させ、それらを重ね合わせて一つの画像を作り上げることができます。
各レイヤーは透明なキャンバスのようなもので、それぞれに描かれたイラストやデザインは他のレイヤーから独立しています。そのため、一つのレイヤー上での修正や変更は、他のレイヤーに影響を与えません。
このレイヤー機能何が嬉しいかというと、アナログの絵画やスケッチでは一度描かれた部分を大幅に修正することは難しく全体のバランスを考慮しながら一つひとつの要素を描いていく技術が求められますが、レイヤー機能を活用すると、各要素を個別に描き、調整し、組み合わせることができるので修正が簡単というメリットがあります。
また、最近の画像処理系ツールではレイヤー分けされていることが前提の技術(live2D等)も出てきているため、デジタルイラストを活用する上で必須の機能となっています。
実際にレイヤー分けされた絵はこんな感じ(私のレイヤー分け下手すぎ…?)

こんな感じで背景だけ透明にしたりできます。

なんで作ろうと思ったか
動機は複数ありますが、実際に手を動かし始めたきっかけは去年から流行りに流行っている画像生成AIがあります。
このツールの開発を始めた当時(2月頭)はまだまだ生成される画像を制御するすべが少なく、レタッチ(生成されたものをベースに手作業で修正する)しないと結構破綻が目立つ状況でした(プロンプト制御だけで破綻しない生成をする人もいた)
そんな折、Controlnetが発表されある程度生成画像の制御も可能となり、さすがにこれはそろそろ画像生成AIと真面目に向き合わないといけないなと思い手を付けてみたのですが、一枚絵として出力された画像は前述のレイヤー分けが当然されておらず、レタッチするにしても使い勝手が悪すぎる、という状況に陥りました。
課題が出たら技術でなんとかするのがエンジニアのサガ、という事でじゃあ一枚絵をレイヤー分けするツールを作っちまえというのが開発に着手したきっかけとなります。
またその他の動機としてはLive2Dの存在が大きく、Live2Dで使うレイヤーの分け方と実際に絵を書くときのレイヤーの分け方が違うため都度レイヤーを分けなおす、もしくはLive2D化することを前提としたレイヤー分けをして絵を描かないといけない等の課題があったため、こちらの問題にも対処しようというのも大きな動機の一つです(今はこちらがメインの動機)
着想
レイヤーの分け方は人毎にそれぞれあると思いますが、大まかに分けるのであれば線画、下塗り、効果(影や光)に分けられるかなと思います。
また、髪、肌、目、服、背景、小物など領域ごとに分割されている必要もあります。
このため、レイヤー分けを行うには
- 領域の分割
- 効果の分割
上記二つの実現が求められます。
特に難しいのが領域の分割で、ぱっと思いつくのはSemantic Segmentationによる領域分割なのですが、データセットを作る手間と学習をする手間を考えてまずは学習が必要ない方法での実現を考えました(その1か月後にSegmentAnythingが出たため、結果的には正しい判断だった)
領域の分割
さて、では学習データを使わない場合どのように領域を分けるかについてですが、今回は色情報に注目して領域判定を行いました。
先ほど、領域を分ける例として髪や肌、服などを上げましたが、作風にもよるものの基本的にはこれらの色は異なっており、似た色は同じ領域であると判定できそうです。
ただ、ここで問題となってくるのは影や光などの効果を考慮しないといけない点です。
先ほど例に挙げた画像ですが、例えば髪の領域だけに注目しても光が当たっている部分と影になっている部分では全く異なる色であることがわかります。

このため、単純に似た色であれば同じ領域で分けるといった考え方ではうまくいきません。また、似た色の定義がそもそも困難という点や、効果レイヤーは下塗りの上に置きたい(光や影等の効果を非表示にしたときに透明ではなく下塗りの色が出てくるよういしたい)ため、色が違っていても領域が重複するような場合も考慮する必要があります。
この課題に対応するため、以下の処理手順を考えました。
- 入力画像の座標情報と色情報をもとにピクセルをクラスタリング(似た色のピクセルを同じクラスタに分ける)
- ピクセルの座標ととクラスタの組み合わせを保存
- 入力画像全体にブラーをかけてぼかす
- ぼかした後の画像に対し、[2]で保存したクラスタと座標情報をマッピングする
- クラスタ毎に色の平均値を取り、算出結果をクラスタの代表色とする
- 代表色が似ている(CIEDE2000基準)クラスタは同じクラスタとして結合
- 代表色で結合後の各クラスタに属する座標を塗りつぶし、新たな入力画像として更新
[2-7]の処理をクラスタの数が変わらなくなるまで繰り返します。
さて、肝となるのは3-6の処理です。
文字で書くと少しわかりづらいですが、やりたいこととしては、
遠目で絵をぼやっと見ると色の境目がぼけてわからなくなるので、そのぼやけた結果に基づいて画像と領域を再定義してやろうというイメージです。
ぼやかす→ぼやかした情報を元に画像を再構築→ぼやかすという作業を繰り返していく事でだんだん隣接した領域の色が似通ってくるため、隣接している似た色の領域が同じクラスタとして認識されていきます。
実際の画像処理はこんな感じ
-
入力画像

-
ぼかした画像

-
クラスタ結合後の画像

このようにぼかすことで光や影と下塗りの境があいまいになり、境界が薄れていっているのが確認できます。
これを複数回繰り返すことで、大幅に異なる色以外を同じ領域として判定できるようになります。
- 5回同じ処理を繰り返した結果

このように、肌や髪、服から影や光などの効果が消え、同じ領域として判定できるようになっています。
一方で、本来は分けてほしい領域も同じ色になってしまっている事もうかがえます。
これを回避するためには、かなり細かくパラメータを設定する必要があるため、使い勝手という点ではかなり難がある結果となりました。
コードで書くと以下のようになります。
def get_blur_cls(img, cls, size):
blur_img = cv2.blur(img, (size, size))
blur_df = rgba2df(blur_img)
blur_df["label"] = cls
img_list = []
mean_list = []
cls_list = list(cls.unique())
for cls_no in tqdm(cls_list):
mask = get_mask(blur_df, cls_no)
img_df = blur_df.copy()
img_df.loc[blur_df["label"] != cls_no, ["a"]] = 0
img_df, mean = fill_mean_color(img_df, mask)
df_img = df2rgba(img_df).astype(np.uint8)
img_list.append(df_img)
mean_list.append(mean)
return img_list, mean_list, cls_list
def get_cls_update(ciede_df, df, threshold):
set_list = [frozenset({cls, tgt}) for cls, tgt in ciede_df[ciede_df['ciede2000'] < threshold][['cls_no', 'tgt_no']].to_numpy()]
merge_set = []
while set_list:
set_a = set_list.pop()
merged = False
for i, set_b in enumerate(merge_set):
if set_a & set_b:
merge_set[i] |= set_a
merged = True
break
if not merged:
merge_set.append(set_a)
merge_dict = {}
for merge in merge_set:
cls_counts = {cls: len(df[df['label'] == cls]) for cls in merge}
max_cls = max(cls_counts, key=cls_counts.get)
for cls in merge:
merge_dict[cls] = max_cls
return merge_dict
def get_color_dict(mean_list, cls_list):
color_dict = {}
for idx, mean in enumerate(mean_list):
color_dict.update({cls_list[idx]:{"r":mean[0],"g":mean[1],"b":mean[2], }})
return color_dict
def get_base(img, loops, cls_num, threshold, size, h_split, v_split, n_cluster, alpha, th_rate, bg_split=True, debug=False):
if bg_split == False:
df = rgba2df(img)
df_list = [df]
else:
df_list = get_foreground(img, h_split, v_split, n_cluster, alpha, th_rate)
output_list = []
for idx, df in enumerate(df_list):
output_df = df.copy()
cls = MiniBatchKMeans(n_clusters = cls_num)
cls.fit(df[["r","g","b"]])
df["label"] = cls.labels_
df["label"] = df["label"].astype(str) + f"_{idx}"
for i in range(loops):
if i !=0:
img = df2rgba(df).astype(np.uint8)
blur_list, mean_list, cls_list = get_blur_cls(img, df["label"], size)
ciede_df = calc_ciede(mean_list, cls_list)
merge_dict = get_cls_update(ciede_df, df, threshold)
update_df, color_dict = get_update_df(df, merge_dict, mean_list, cls_list)
df = update_df
if debug==True:
img_plot(df)
output_df["label"] = df["label"]
output_df["layer_no"] = idx
output_list.append(output_df)
output_df = pd.concat(output_list).sort_index()
mean_list = []
cls_list = list(output_df["label"].unique())
for cls_no in tqdm(cls_list):
mask = get_mask(output_df, cls_no)
img_df = output_df.copy()
img_df.loc[output_df["label"] != cls_no, ["a"]] = 0
img_df, mean = fill_mean_color(img_df, mask)
mean_list.append(mean)
color_dict = get_color_dict(mean_list, cls_list)
output_df["r"] = output_df.apply(lambda x: color_dict[x["label"]]["r"], axis=1)
output_df["g"] = output_df.apply(lambda x: color_dict[x["label"]]["g"], axis=1)
output_df["b"] = output_df.apply(lambda x: color_dict[x["label"]]["b"], axis=1)
return output_df
さて、唐突ですがここで減色処理というものを紹介します。
これは、RGB値を一定の閾値で分け、機械的に画像の中で使われている色の数を指定された数まで減らす(同じ色に寄せる)という処理になります。
先ほど紹介した手法はやっていることとしては、この減色処理と得られる結果が非常に似ています。
ただ大きな違いとしては、色をぼかして平均化するという手法上、隣接した色の影響しか受けないという点が異なり、RGB値を閾値で切って減色する方法よりもかなり柔軟性が高い点がこの方法のメリットとなります(その代わり処理に時間がかかる)
効果の分割
さて、領域の分割ができたので次は効果の分割になります。といっても、前述の処理ですでに下塗りは生成されているため、下塗りをもとに効果を割り出していきます。
具体的には、下塗りレイヤーを基準として、より明るいピクセルを光、暗いピクセルを影として判定します。
これまでRGB空間で処理を行ってきましたが、ここで入力画像と下塗り画像をRGB空間からHSL空間に変換します。
- HSL空間の説明
光か影かの判定は、この輝度を入力画像と下塗り画像で比較して、下塗り画像よりも入力画像の輝度の方が高ければ光、低ければ影という判定をピクセル毎に判断しています。
def split_img_df(df, show=False):
img_list = []
for cls_no in tqdm(list(df["label"].unique())):
img_df = df.copy()
img_df.loc[df["label"] != cls_no, ["a"]] = 0
df_img = df2rgba(img_df).astype(np.uint8)
img_list.append(df_img)
return img_list
def get_normal_layer(input_image, df):
base_layer_list = split_img_df(df, show=False)
org_df = rgba2df(input_image)
hsv_df = hsv2df(cv2.cvtColor(df2rgba(df).astype(np.uint8), cv2.COLOR_RGB2HSV))
hsv_org = hsv2df(cv2.cvtColor(input_image, cv2.COLOR_RGB2HSV))
hsv_org["bright_flg"] = hsv_df["v"] < hsv_org["v"]
bright_df = org_df.copy()
bright_df["bright_flg"] = hsv_org["bright_flg"]
bright_df["a"] = np.where(bright_df["bright_flg"] == True, 255, 0)
bright_df["label"] = df["label"]
bright_layer_list = split_img_df(bright_df, show=False)
hsv_org["shadow_flg"] = hsv_df["v"] >= hsv_org["v"]
shadow_df = rgba2df(input_image)
shadow_df["shadow_flg"] = hsv_org["shadow_flg"]
shadow_df["a"] = np.where(shadow_df["shadow_flg"] == True, 255, 0)
shadow_df["label"] = df["label"]
shadow_layer_list = split_img_df(shadow_df, show=True)
return base_layer_list, bright_layer_list, shadow_layer_list
-
光の例

-
影の例

この処理により、領域毎の分割および光と影の層分割が実現できました。
最終的なレイヤー分け結果はこちら
-
入力画像(PSD版)
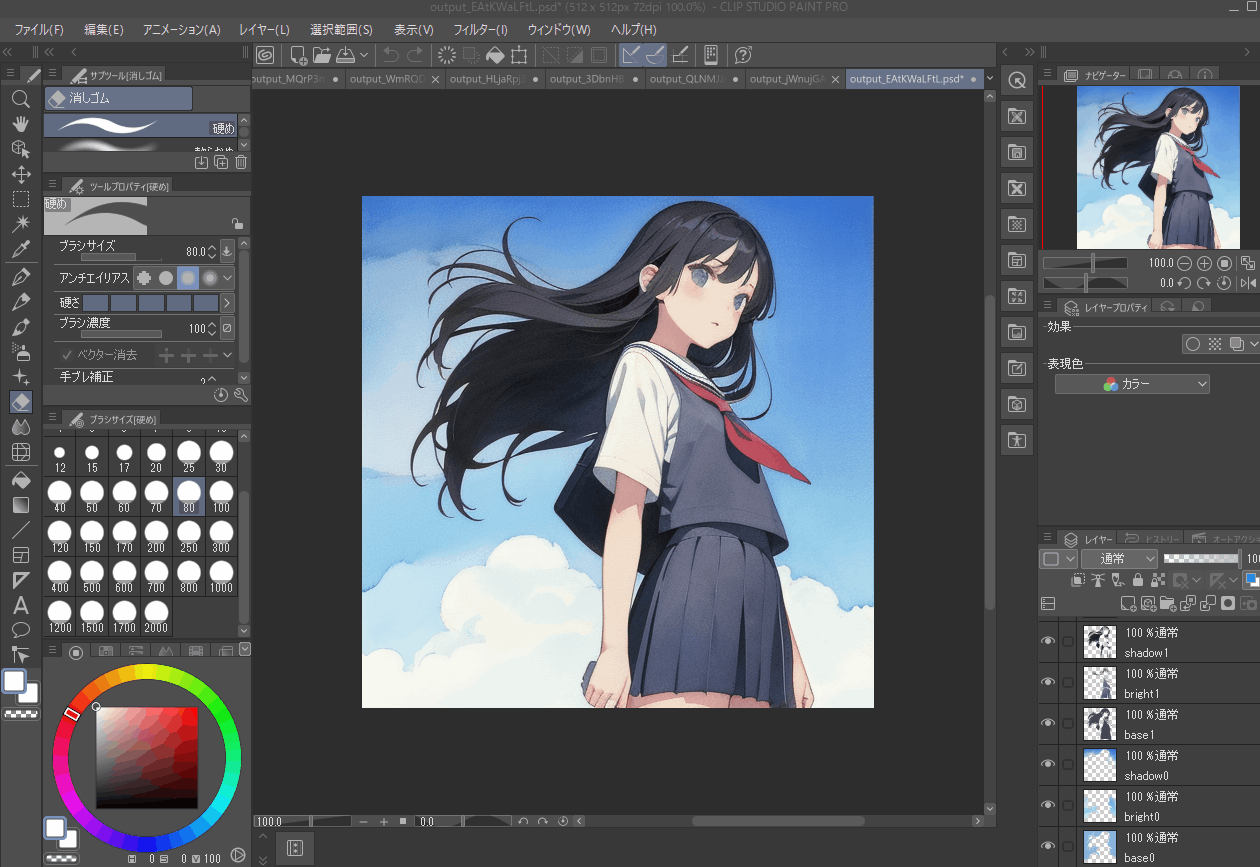
-
光効果のみ削除

-
影効果のみ削除

おわりに
レイヤー分けツール(LayerDivider)初版の構想についてここまで説明してきました。
ひとまずレイヤー分けと呼べそうなものはできたものの、使い勝手にかなり難があり、まだまだ改善の余地があるツールとなっています。
現在のLayerDividerはここで解説した内容をベースとしながら、SegmentAnythingのようなセグメンテーションAIを使ってより高精度なレイヤー分けに挑戦しています。
SegmentAnythingを使ったレイヤー分けについては、また日を改めて記事にできればと思っていますので、少しでも興味を持っていただけた方は楽しみに待っていていただければと思います。
最後に宣伝ですが、私のGithubアカウントではほかにもイラストや画像を取り扱ったツールを作って公開しています。
-
Githubアカウント
https://github.com/mattyamonaca -
高精度の背景切り抜きツール(PBRemTools)
https://github.com/mattyamonaca/PBRemTools -
線画の自動下塗り&レイヤー分割ツール(auto_undercoat)
https://github.com/mattyamonaca/auto_undercoat
この領域に興味のある方はぜひフォローいただけますと幸いです。
またスターを投げていただけるとやる気が出ます。
そのほか、Twitterでも最新の取り組み状況をつぶやいていますので、目を通してもらえたら嬉しいです。
それでは、長らくお付き合いいただきありがとうございました。

Discussion