データサイエンティスト組織の構造的問題
こんにちは。松﨑 遥(@the_end_of_dl)です。ソフトウェアエンジニアを5年、データサイエンティストを10年ほどやっています。
本日は、CTO協会主催のDeveloper eXperience Day 2024に参加してきました。


ハイプレッシャーな日々(記事)で後回しにしていた組織課題に向き合わされたイベントでした。
今回は開発者体験を捉え直し議論するベースキャンプでしたが、データサイエンティストの議論相手は見つからず、1日目のワークショップでディスカッションしたメンバーは、
- 受託開発CEO
- Rails開発CTO
- 銀行アプリの内製部隊リーダー
2日目の議論相手は
- なんかのCXO
- なんかのVPoX
- すごい勢いの陽キャ
- 陽キャ
- CXOVPoX陽キャCXOVPoX陽キャ...
と怒涛のうちに過ぎていきました。その後、ちゃんとウチもデータサイエンティスト組織に当てはめて言語化しないとな、と感じた次第です。
(※なじみの無い方のために補足しますと、データサイエンティストとは、データサイエンスという学問を使って成果を出す、みたいな職種で、まぁ、エンジニアと言っていいんじゃないでしょうか)
本記事を通じて、いろいろなかたと、データサイエンティスト組織の設計についての議論を活発化していければと思います。
TL;DR
要約すると、マネジメント・実装集約・プロジェクト制・バリューストリーム型成長・コンテナ化・スケーリングなどについて論じています。
また、この文書で頻繁に登場する以下の耳慣れない用語を先に説明しておきます。
労働集約:投資より人件費が高く、ビジネスが流動的な労働力に強く左右される状態。
資本集約:投資が人件費より高く、ビジネスが労働力の流動には左右されにくいが、資金が非人的資産の形で流動性を失いリスクを抱えている状態。
思考集約:ビジネスが思考・計画の質に強く左右される状態。
実装集約:ビジネスが実装手段の質に強く左右される状態。
多分大体こんな感じで合ってます。ではいきましょう
経験知 as a Software
この文章の主題はあらゆるデータサイエンティストが事業貢献出来る組織形態とはですが、まず最初に議論したいのは、「データサイエンティストはソフトウェアエンジニアと比べ、エンジニアリング・マネージャー業務の経験を積む機会が少ないのではないか?」という論点です。そして、その裏には、2つの原因、ツールの問題とプロジェクトの問題があります。
これは、ソフトウェアエンジニアリングとデータサイエンティスト両方のキャリアを歩んだ自分が特に語りやすい論点ではないかと思います。
通常のマネジメントとエンジニアリング・マネージャーの業務には違いがあります。歴史的には、旧来のマネジメントをエンジニアに適用した場合に破綻したことから、新しいアプローチが試みられました。私の理解では、マネジメントは思考集約的な仕事(どの手段をとるか考える仕事)であるのに対し、エンジニアは実行集約的(決めた手段で完成させる仕事)な仕事です。そこにコミュニケーションギャップが生まれ、思考集約的な解決策はエンジニアにとって受け入れ難いものになるというのが負けパターンです。
エンジニアリング・マネージャーはあくまで実行集約的な解決策で組織課題を解決します。例えば残業時間が多いなら、コーディングによる自動化で業務を効率化する。例えばバグの究明のために必要な変更履歴が追えなければ、gitによるソース管理を行う。例えばデプロイにおける障害が多いなら、CI/CDによりデイリービルドでの障害検知を行う。これらがエンジニアにとって受け入れやすい合理的な解決策です。
単にSaaSを導入するのと違うのは、こういったツールには開発現場の知が集約されているという点です。つまりエンジニアリング・マネージャーの道具の強みは、会社を超えた、いや世界的な普遍知を技術的に輸入できる点にあります。
2024年現在、日本国内のデータサイエンティストの数は、ソフトウェアエンジニアの10分の1以下であるとも言われています。さらに、それらの人が10以上の、お互いに言葉の通じない専門分野に分かれています。そうすると、100分の1になります。誰もが使っているのはライブラリ(tensorflow・torch)、エディタ(jupyter・RStudio)に留まりますし、kaggleプラットフォームを業務で使ったという話はまだ聞いたことがありません。
プロジェクト制の問題
もうひとつの原因は、データサイエンスはPoCプロジェクト形式を取りやすいという点です。この形態をとる組織は、8人のデータサイエンティストが8〜16個のプロジェクトに割り当てられていたりして、それらのプロジェクト同士が、特に何の関係も無かったりします。例えば情報共有会みたいのをやっても、シーンとしていることが多くなります。私もそうですが、大学院での専攻を活かしている場合、やはり2つ目の専門分野を作った場合1つ目に見劣りするもので、質問も気後れするものです。ですから、データサイエンティストのキャリアパスは、ひたすら1つのことに特化していく傾向があります。
PoCプロジェクト制のもうひとつの問題は予算です。チーム開発を行えるだけの規模の予算はとれないことが多く、本人の能力・資質によらず、チーム開発経験自体も乏しくなります。
よって、プロジェクト制のデータサイエンティスト組織は、専門性を高めるという意味での成長サポート、アサインによる労務サポートを行う機能が強くなります。ここに、エンジニアリング・マネージャーとしての経験を積みにくい原因があります。例えば、プロジェクト制で士気が下がった場合は、配置転換を行い、気分転換をしてもらうしかありません。それはエンジニアリング・マネージャーの行うべき実装集約的解決ではないわけです。
以上が、「データサイエンティストはソフトウェアエンジニアと比べ、エンジニアリング・マネージャー業務の経験を積む機会が少ないのではないか?」という論点です。
バリューストリーム型成長に潜む問題
次に議論したいのは、「データサイエンティストの専門性以外の成長とは何か?」という論点です。ここでの結論はバリューストリーム型成長になりがちである、ということなのですが、まずはソフトウェアエンジニア視点から見たオーナーシップという切り口で、この問題を見てみましょう。
例えば、ソフトウェアエンジニアが一向に仕事が進まないことに不満を抱えていたとしましょう。そして、その不満が、顧客からのフィードバックが遅すぎて、一向にサービス改善が進まないということだったとしましょう。そこにソフトウェアエンジニアリングの集合知がやってきます。彼は、オーナーシップを発揮することで、DevOpsに向けて一歩を踏み出すことでしょう。オーナーシップとは問題を自分ごと化するということです。運用チーム(Ops)のせいにするのではなく、自ら解決を望むことで成長が起こるわけです。
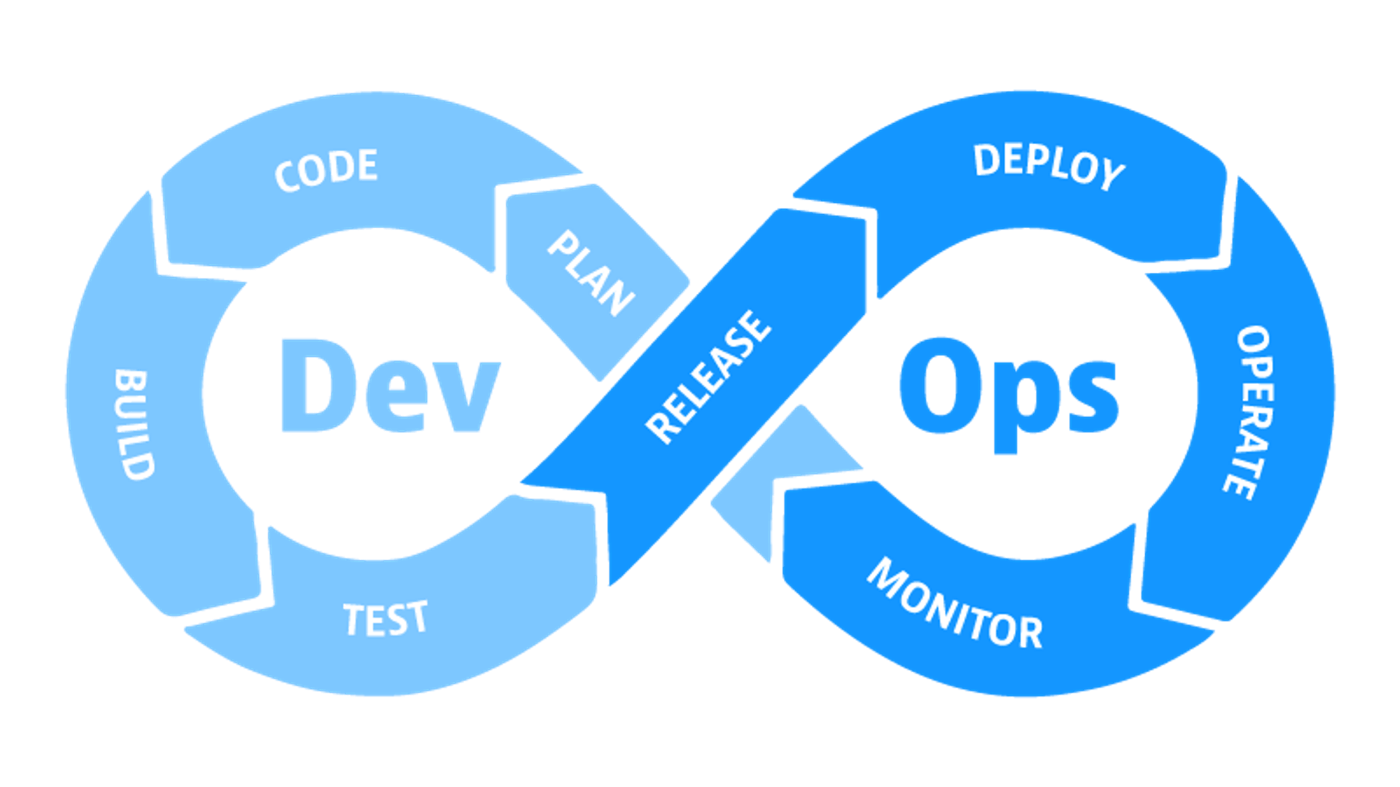
ソフトウェア開発に伴う絶え間ない問題は、解決策を必要とします。ですから、DevOps以外にも色々なオーナーシップの発揮がなされてきました。共通基盤・フレームワーク・クラウドプラットフォーム・セキュリティ・フルスタック・データマネジメントなどなどといった切り出しがなされ、ミドルレイヤーとしての成長モデルが確立されていったわけです。
これをデータサイエンティストに置き換えるとどうなるでしょうか?
ソフトウェアエンジニアリングの世界では、デベロップメント→デプロイメント→デリバリー→ラン→ユーザー価値のような流れをバリューストリームと言います。先ほどのDevOpsを推し進めていくと、バリューストリームをカバーするようにオーナーシップを発揮していくのです。データサイエンティストのバリューストリームは、次のようになっています。
- データ分析→企画→提案→PoC→効果検証→機械学習システム開発→デプロイメント→デリバリー→ラン→ユーザー価値(→再学習)
ということは、素直に考えると、このバリューストリームをカバーするべきということになるわけです。これが、10年ほど前、データサイエンティストには3つの能力が必要である、ビジネス力・データサイエンス力・エンジニア力だ、などと言われた発想の根源ではないかと思います。
そこから10年経ってどうなったかというと、バリューストリーム型成長を遂げたスーパースターは100人に1人ほどしか出ていないという印象です。ひとえに、ビジネス力もデータサイエンス力もエンジニア力もつけることが難しいスキルであり、それぞれ3年はかかってしまうというのが、その原因かと思われます。またスキルがついても、全てをカバーすることの認知負荷が高いことには変わりありません。冒頭に述べた通りデータサイエンティストが8万人程度であるとしたら、各分野に分かれると8000人、その各分野で80人ほどしかスーパースターは存在しないという計算になります。
つまり、バリューストリーム型成長は机上の空論なのです。
だから、バリューストリーム型成長を遂げたプレイングマネージャーを軸に何人か部下をつけたような思考停止的な組織設計もうまくいかないのです。
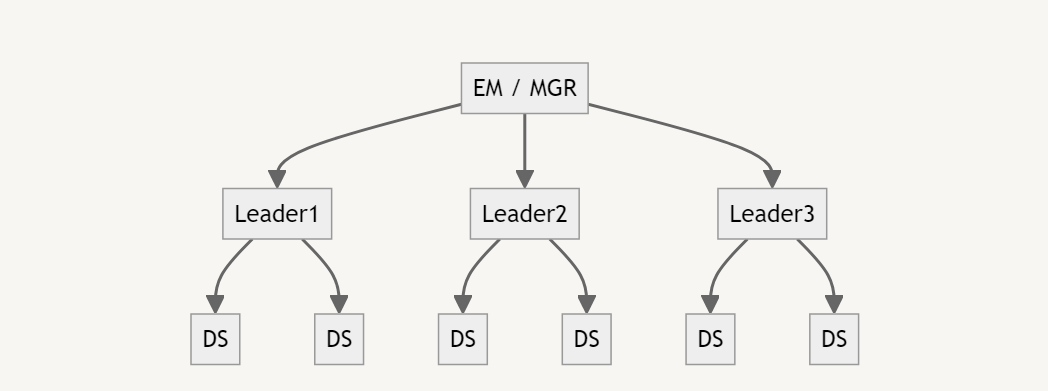
ごく普通に見える組織構造ですが、実際にはこの”Leader”の職務をこなせる人はかなりレアです。プロジェクト制の組織形態をとり、バリューストリーム型のデータサイエンティスト10人程度の組織を作れれば理想ですが、それは市場に80人しかいないような人材から10人を一社に固めるという非現実的な理想論なのです。
さらに、バリューストリーム型育成の根本的な問題は労働集約的な思考であることで、これによりハイコスト・ハイリスクになります。まず、マンツーマンな教育方法となりますが、教師を確保することが非常に難しいです。さらに、昇進した途端に退職することがよくあります。市場に80人しかいないような人材は引く手数多で、キャリアアップし放題だからです。
最後に、見落としがちなバリューストリーム型の欠点について議論します。それは、ビジネス職との蜜月による視野狭窄です。
バリューストリーム型のデータサイエンティストは過大評価されるリスクを負っています。どういうことかというと、本当は目の前の人に合わせているだけなのに、視座が高いと誤解されてしまうリスクです。すると、データサイエンティストが導き出した局所解が実行され、成果が出ないということが起こります。
ビジネス側も人間ですから、ジュニア〜ミドル〜ハイレイヤーまで色々な人間がいるのですが、誰しも初めのうちは、自分にできないことが出来る人と話すと相手を過大評価してしまうものなのです。
データサイエンティスト組織の悪循環
つまり、データサイエンティスト組織では、エンジニアリング・マネージャーとしての経験も積めないですし、バリューストリーム型の無理なキャリアしかないですし、チームのことなど気にせずみんな個人主義者となってひたすら専門化していこう、ということになりがちなわけです。
そこで育っていった若手は、やはり同じ結論になっていくのではないかと思うわけです。
スケーリングプラットフォーム
バリューストリーム型スーパースターの育成は机上の空論であるものの、それに似た考えは巷に溢れています。データサイエンスさえ出来ればいいデータサイエンティストであるとか、いいデータサイエンティストを集めればチームとして機能であるとか。はては、東大京大の研究室の研究者(でチームワークが良さそうなやつ)を採用すれば自然とよいチームになる、だとか。そんなナイーヴな考えでうまくいくことは残念ながらあり得ません。

ではデータ分析から企画、ユーザー価値までをオーナーシップでカバーするという非現実的な働き方を、全員をスーパースターで構成せずに可能にするには、どうしたらいいでしょうか?言い換えれば、全員が気持ちよく働ける労働プラットフォームとしての職場の構成要素とは、何でしょうか?
ひとつは資本集約的な考え方として、データ集約・ベンチマーキングがあります。次に実装集約的な考え方として、コンテナチームがあります。最後にハイブリッドでどちらかといえば資本集約的な考え方として、サブシステムコンテナチームがあります。(用語は私が勝手に言っているだけです)
同じ人数を使うなら、私は先ほどの図のようではなく、下の図のように組織を構成すべきだと思うのです。これは3人のリーダーを次のような横軸ミッションにアサインします。
- ピープル担当のメンター
- プラットフォーム担当
- プラットフォームをデザインするエンジニアリング・マネージャー
- 企画・提案を仕上げるコンセプター
抽象的でよくわからないと思うので具体的に彼らの仕事①~⑥を説明します。
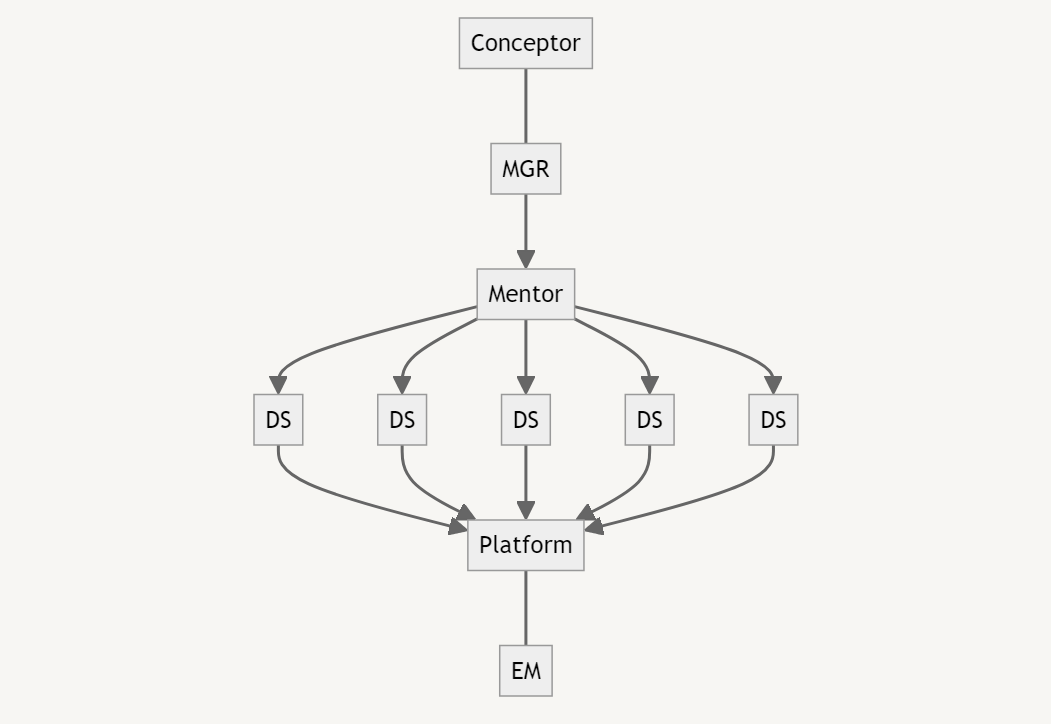
①データ集約
これは、お金をデータの形に変換しておくことです。
基本的にはアノテーターを雇ったり、アノテーターをマネジメントしたり、相互チェックの仕組みを考えたり、アノテーション企業に発注することでデータを集めます。
去年ブログで取り上げたPRM800のようなデータセットをまず作り、その上で効率的な開発を行うという作戦です。データフォーマットが通用しなくなるという陳腐化のリスクがあるとは言われますが、新しい学習パラダイムの到来にいち早く乗ることが出来るという考えもあります。
また、合成データを管理するアプローチがあります。合成データを生成するコードや、3Dアセットなど、実は学習データに加工する業務は意外に多いもので、ここをジャンプスタート化することで誰もがスムーズにプロジェクトに入ることが出来ます。
最後に、昔から言われているのがデータマート・クエリ管理・BIです。最近は生成AIによるクエリ生成もありますね。ただ、毎日更新を考えると、バッチの管理や障害対応でデータマネジメントの仕事を増やしてしまい、逆効果になる可能性も否めない難しいところです。また、我々も人間なのでBIを解読できず再利用性が絵に描いた餅になるということも多いように感じます。結局、探索的データ分析のスキルは属人的なもので、プラットフォーム化するのは難しいという肌感です。
②テスト駆動・ベンチマーキング
機械学習においてテスト駆動開発を行うことは、特徴量管理に近いです。新しいモデルやSaaSが出現した時にApple 2 Apple比較を行うためには、特徴量の差とモデルの差を切り分けなければなりません。そこで、学習期間や学習可能な特徴量を制限したデータマートとtrain test split・またはスプリットアルゴリズムを管理することで、この切り分けが可能になります。
データマートを固定することは、ベンチマークとしても機能します。
これは可視化だけが目的なのではなく、生産性の問題です。テストを簡単にすることは、比較の型化であり、アルゴリズムの評価に関する無数の議論業務を節約してくれます。クエリが無限のバリエーションに増えていくのは、探索的データ分析であったり、精度を向上しようとするからです。テストの標準化が目的であれば、簡潔で少ない個数の特徴量を厳選するため、無秩序になることはありません。
③コンテナ化
これは、アプリケーションが動くコンテナの最新化を行い続けることです。
github管理のコードにタグをつけ、git tagとdocker image tagを組み合わせで管理することで、一度書いたコードが誰の手元でも動くという状態を担保し続ける担当者を任命します。
docker imageはbaseとdeploy tagを分けて管理します。baseではドライバーやフレームワークのバージョンを管理し、deploy tagでは開発したコードと依存ライブラリのバージョンの管理を行います。すなわち、githubにはpythonであればsetup.pyを入れてpip管理可能にし、dockerfile的なものにはpipを実行させ、それにより依存ライブラリの特定バージョンが入るようにしておきます。
データサイエンスでは学習データ・アルゴリズム内容・ライブラリ依存関係・GPUドライバー・適用先を同期させる作業が重く認知負荷も高いため、ジュニアレイヤーの助けとなります。私も助かります。
④サブシステムコンテナ
これは、機械学習の全分野についてコンテナ化を行い、管理することです。
ABEMAのようなサービスであれば画像・ローカルLLM・レコメンド・時系列・異常検知・線形計画ソルバー・効果検証・強化学習といったありとあらゆる分野が使われますが、ABEMAはモノリシックではないのでそれらは別々のサブシステムから呼ばれることになってしまいます。
さらに、コードベース外で機械学習が行われることはもはや当たり前です。一部のサブシステムについてはSaaSを呼ぶことがありその場合はSaaS上で推論が行われますし、実はサイバーエージェントの最も強力な学習基盤はオンプレにあるのです。他社の報告では70Bのスクラッチ学習にクラウドを使うと10億円を超えてしまったという声もありますから、こうしたプライベート基盤は大変安価です。
このような機械学習の全分野に対する認知負荷はもはや耐え難く、これもジュニアレイヤーや私の助けとなるところです。
⑤企画提案DoJo
データサイエンティストがバリューストリーム型になるときにつまづく最も高い壁が、経営陣への企画・提案能力です。これを助けるために、業務時間内で勉強会やレビューをしています。
なぜつまづくのか。データサイエンティスト間の会話では、ファクトやモデルと言った言語を利用しているからです。これらは説明の必要もなければ、否定することなどもできません。バリューストリームで言えば、
- データ分析
- 効果検証→機械学習システム開発
のステップにおいては企画提案能力は全く必要ないのです。しかし、
- データ分析→企画→提案→PoC
- 機械学習システム開発→デプロイメント→デリバリー→ラン→ユーザー価値
のステップにおいては、決裁者・運用現場・運用技術・障害担当・VoC担当を動かさなければいけないのです。
定番の教材は以下のようなもので、1Qで1冊を、ハンズオンを含めてじっくりとやっています。
- MBAクリティカルシンキング
- ピラミッド原則
- プロフェッショナルアイディア
- ストーリーとしての競争戦略
- パワポ禁止。〜カレー風味の提案書の作り方〜(※自作のオリジナル教科書。メンバーのみに配布)
気になりますよね。気にしていただければ幸いです。
⑥テキーラパーティー
最後にオチのようになってしまいますが、サイバーエージェントといえば飲み会、そしてその飲み会を開催するのは私のような者のミッションと言っても過言ではありません。単なる飲み会ではなく、これから切り込むドメインの現場や、そのドメインの担当役員含めた経営陣との信頼関係づくりです。このような飲み会を開催することや、参加することは激しい精神的ストレスを伴います。
私はこれこそ、スケーラビリティのために自分のような陽キャが粉骨砕身すべきところだと考えております。(飲み会でなく頭出しのミーティングや根回しでもいいのですが)
飲み会のために私は普段から信頼貯金を貯めております。また、居室にはテキーラの瓶を置き、芹沢サンに怒られながら、普段から肝臓の耐性を高めております。この信頼貯金を使って飲み会を作り、飲み会をきっかけに成果を作り、信頼を利息をつけて回収します。いわば信頼通貨の銀行のような仕事をすることで、プラットフォームとして機能するというのが大事なことです。貸借の帳簿もしっかりと管理しています。

現場や担当役員、そして法務と信頼関係を築くということは、それほどまでに仕事の出来を左右することなのです。
まとめ
本記事では、プラットフォーム機能のみが、データサイエンティスト組織において注目しまた強化していくべき点だということを語りました。その背景には、
- データサイエンティストにはエンジニアリング・マネージャー出身者が少ないこと
- データサイエンティストの業務がソフトウェアエンジニアと大きく異なること
- PoCの先が考えられていないこと
があるということを解説しました。
スケーリングプラットフォームを設計するには、以下の点に留意する必要があるでしょう。
- 資本集約でデータサイエンティストを助ける方法
- 実装集約でデータサイエンティストを助ける方法
- 思考集約でデータサイエンティストを助ける方法
- 信頼貯金の貸し出しでデータサイエンティストを助ける方法
具体的には、
- データ管理と進化
- 比較の型化
- 開発リードタイムの短縮
- 肝臓の酷使
といった指標を置いて、プラットフォームを強化していくことが有効であると考えています。
その後
人と議論するたびに本体を更新していこうと思っています。Xのidも併記していったら面白いんじゃないかと思っています。
Discussion