llama2 7Bの事後学習として以下を行いました
- LoRaによる3種類のexpertの作成
- 3つのexpertをマージしMoEとし、router部分を学習
- SFTで全体を学習
事前学習についてはこちら
事前学習編:Llama2 7B マルチノード/マルチGPU環境での事前学習
LoRaによる3種類のexpertの作成
Branch-Train-MiX(BTX)を参考に、事前学習を行ったllama2 7Bをベースとして、Finetunigを行い、3つのFT済みモデルを作成します。
Branch-Train-MiX(BTX)とは
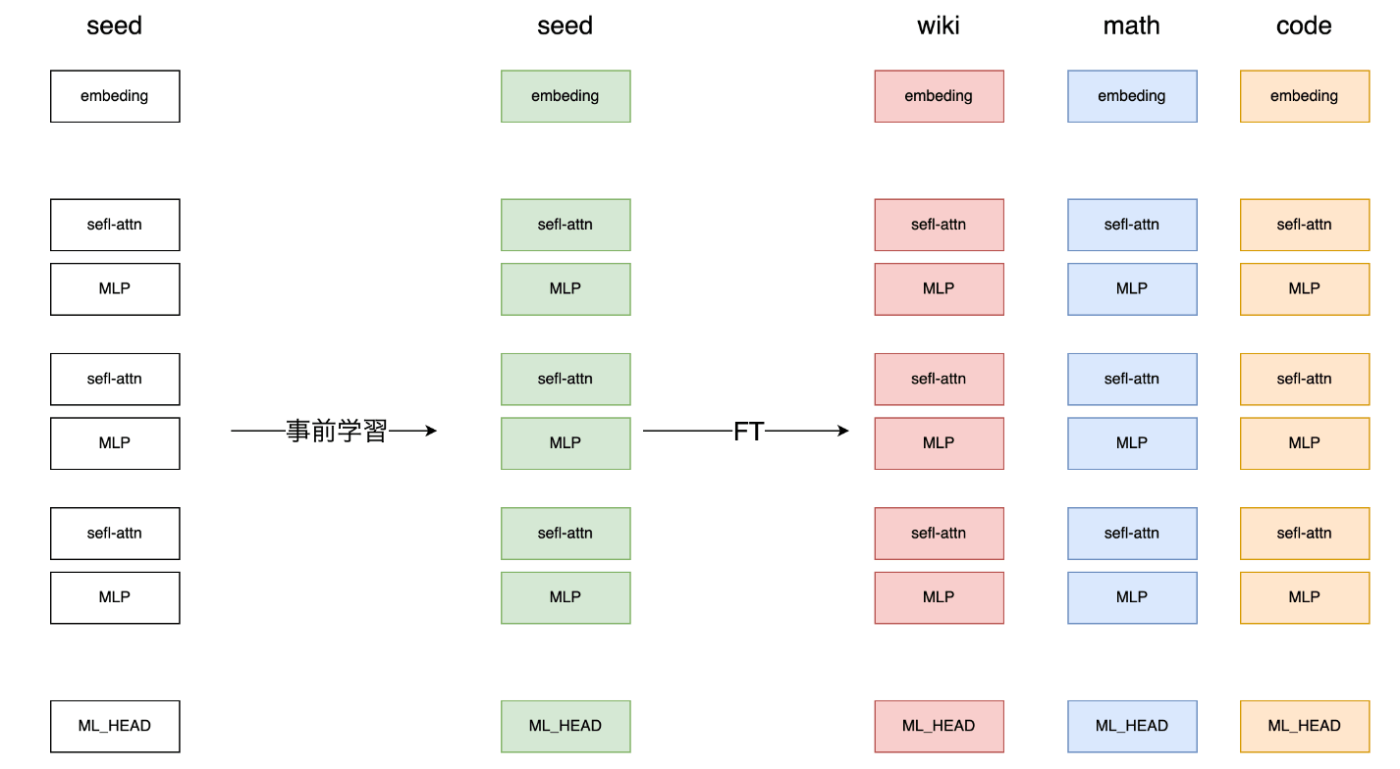
事前学習したseedモデルを、Math、Code、Wikipediaの3種類でFinetuningし、FT後のモデルのMLP層をベースモデルに配置、MoE構造とし全体をトレーニングする手法です。
以下の図のイメージです
-
事前学習後のseedモデルに対し、異なるデータでFTを行い3種類のexpertを作成する
-
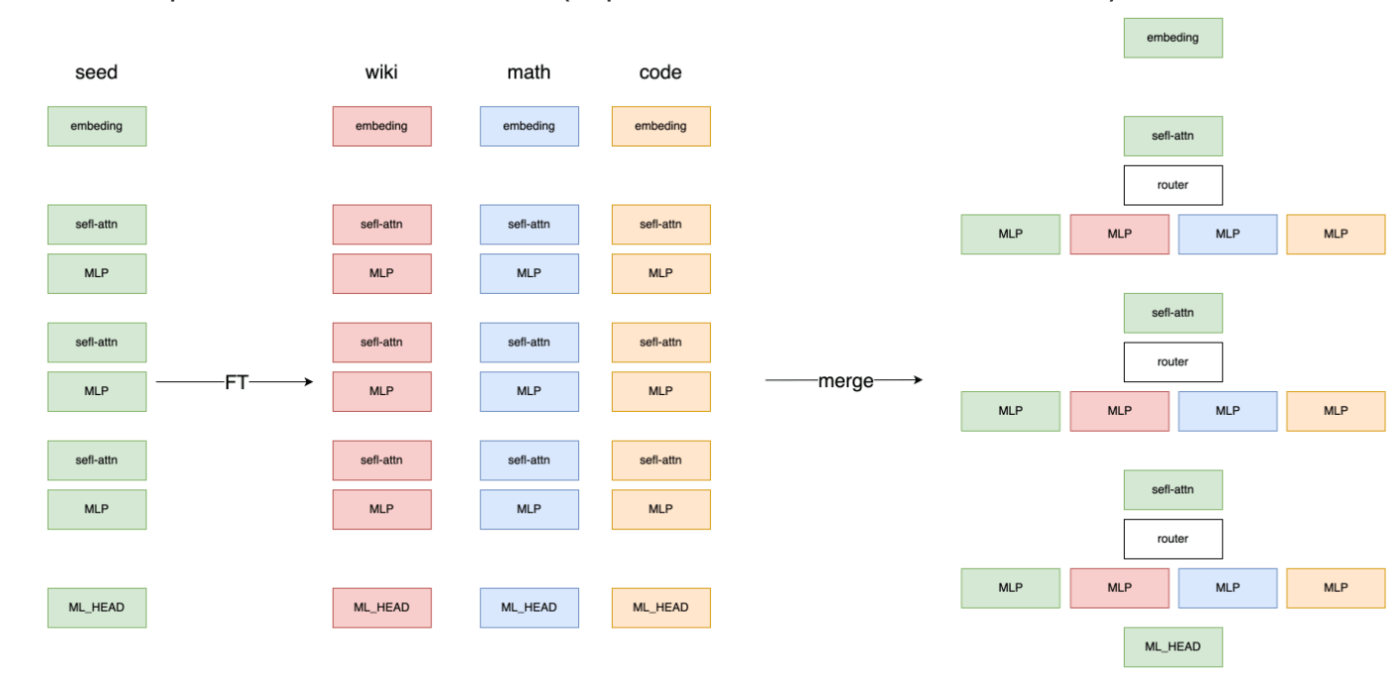
3つのexpertをseedモデルにマージ(expertのうち1つはseedモデルのもの)
-
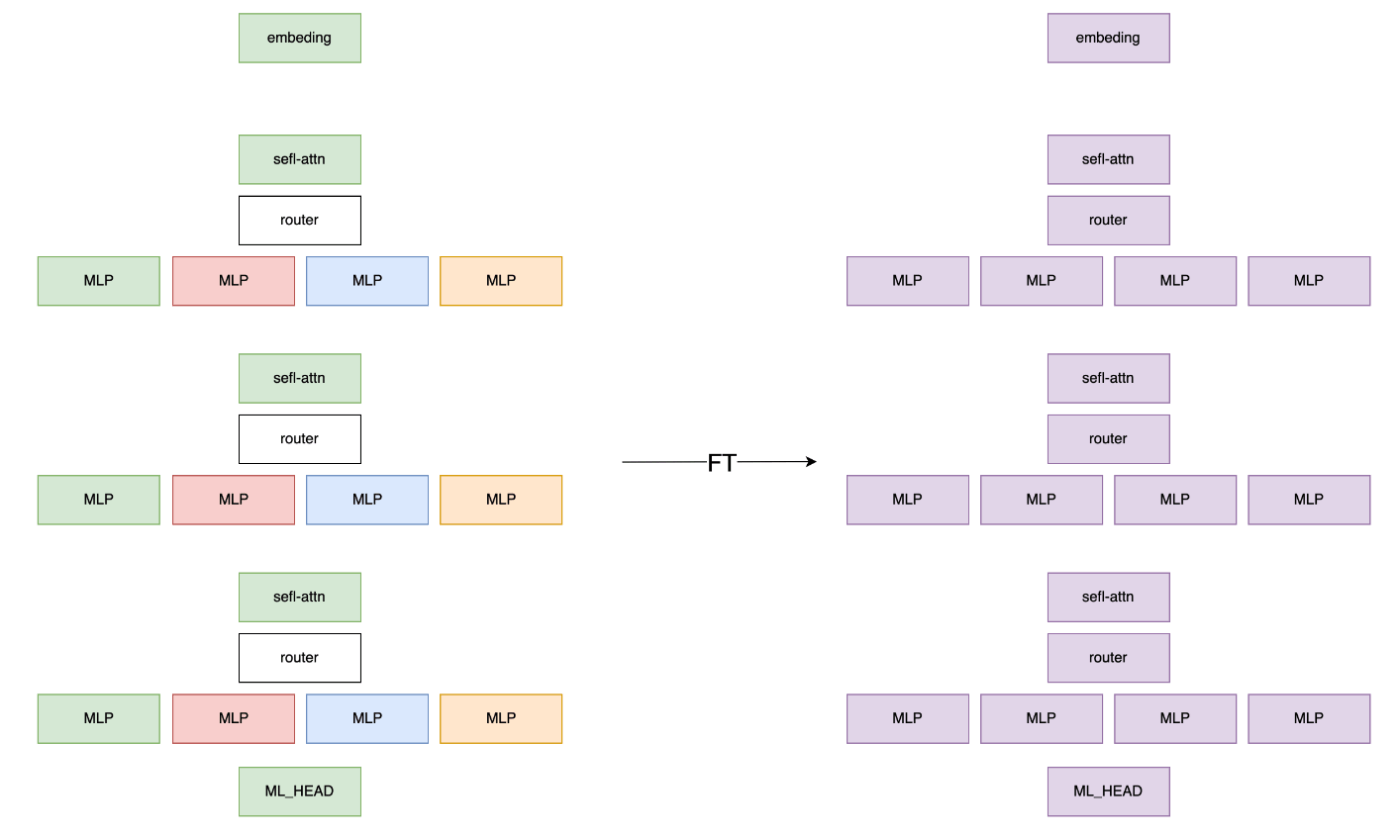
router部分を含め全体をtraining
LoRAを使ったFT
expertの学習にはLow-Rank Adaptation (LoRa)を使いました。
使用ライブラリ: hugginface/peft
事前学習を行ったllama2 7BをHuggingface形式に変換します。seed modelのMLP層のみをtrainingします。今回は、wiki, math, novelの3つのexpertを作ります。各expertが約1Bとなるようにします。
コード
MLP層に当たる["gate_proj","up_proj","down_proj"]の層のみtargetとします。各expertが約1Bとなるように、rank=640 としました。
peft_config = LoraConfig(
r=640, lora_alpha=32, lora_dropout=0.1,
target_modules=target_modules
)
HugginfaceのTrainerでは Data Parallel(DP)が実装されていなかったので、以下のようにTrainer classを継承してDPが行えるようにします。
class DDPTrainer(Trainer):
def get_train_dataloader(self) -> DataLoader:
sampler = self._get_train_sampler()
data_loader = DataLoader(self.train_dataset,
batch_size=BATCH_SIZE,
shuffle=sampler is None,
sampler=sampler,
collate_fn=self.data_collator,
drop_last=self.args.dataloader_drop_last,
)
return data_loader
def _get_train_sampler(self) -> Optional[torch.utils.data.Sampler]:
train_sampler = DistributedSampler(self.train_dataset, num_replicas=NUM_GPUS, rank=dist.get_rank(), shuffle=True) if NUM_GPUS > 1 else None
return train_sampler
pytorchの提供する並列処理であるFully Sharded Data Parallel(FSDP)を使用します。FSDPでは、オプティマイザーの状態、勾配、パラメーターをシャーディングすることで、より多くのデータとより大きなモデルのtrainingを可能にします。
hugginfaceのtrainerでfsdpを使用するには、TrainingArgumentsを指定します。以下の引数が利用できます。
fsdp (bool, str or list of FSDPOption, optional, defaults to '') — Use PyTorch Distributed Parallel Training (in distributed training only).
A list of options along the following:
"full_shard": シャードのパラメータ、勾配、オプティマイザの状態。
"shard_grad_op": オプティマイザーの状態と勾配をシャードする。
"hybrid_shard": ノード内でFULL_SHARDを適用し、ノード間でパラメータを複製する。
"hybrid_shard_zero2": ノード内でSHARD_GRAD_OPを適用し、ノード間でパラメータを複製する。
"offload": パラメータと勾配をCPUにオフロードする("full_shard "および "shard_grad_op "とのみ互換)。
"auto_wrap": default_auto_wrap_policyを使用してFSDPでレイヤーを自動的に再帰的にラップする。
学習させるデータはhuggingface/trlの実装を参考に、packingできるようにします。packingとは、通常学習データはbatch sizeごとにsentenceの長さを揃えるためにpaddingされますが、padding埋めせずに次の文章を繋げていく方法です。
以下のような例です
## no packing
[
[a, b, <pad>, <pad>],
[c, d, <pad>, <pad>],
[f, <pad>, <pad>, <pad>]
]
## packing
[
[a, b, <eof>, c],
[d, <eof>, f, <eof>],
]
データセット
3つのexpertのデータセットはそれぞれ以下を用いました。括弧内は比率です。
wiki
- wikipedia_ja (36%)
- wikipedia_en (20%)
- news_ja (43%)
合計: 5B tokens
math
- AtlasMathSets (43%)
- OpenMathInstruct (37%)
- basicMath (17%)
- gsm8k (1%)
合計: 1.6B tokens
novel
- 青空文庫 (10%)
- 公開されている小説データ (90%)
合計: 9B tokens
学習
lossの結果になります。
青: novel
紫: wiki
ピンク: math
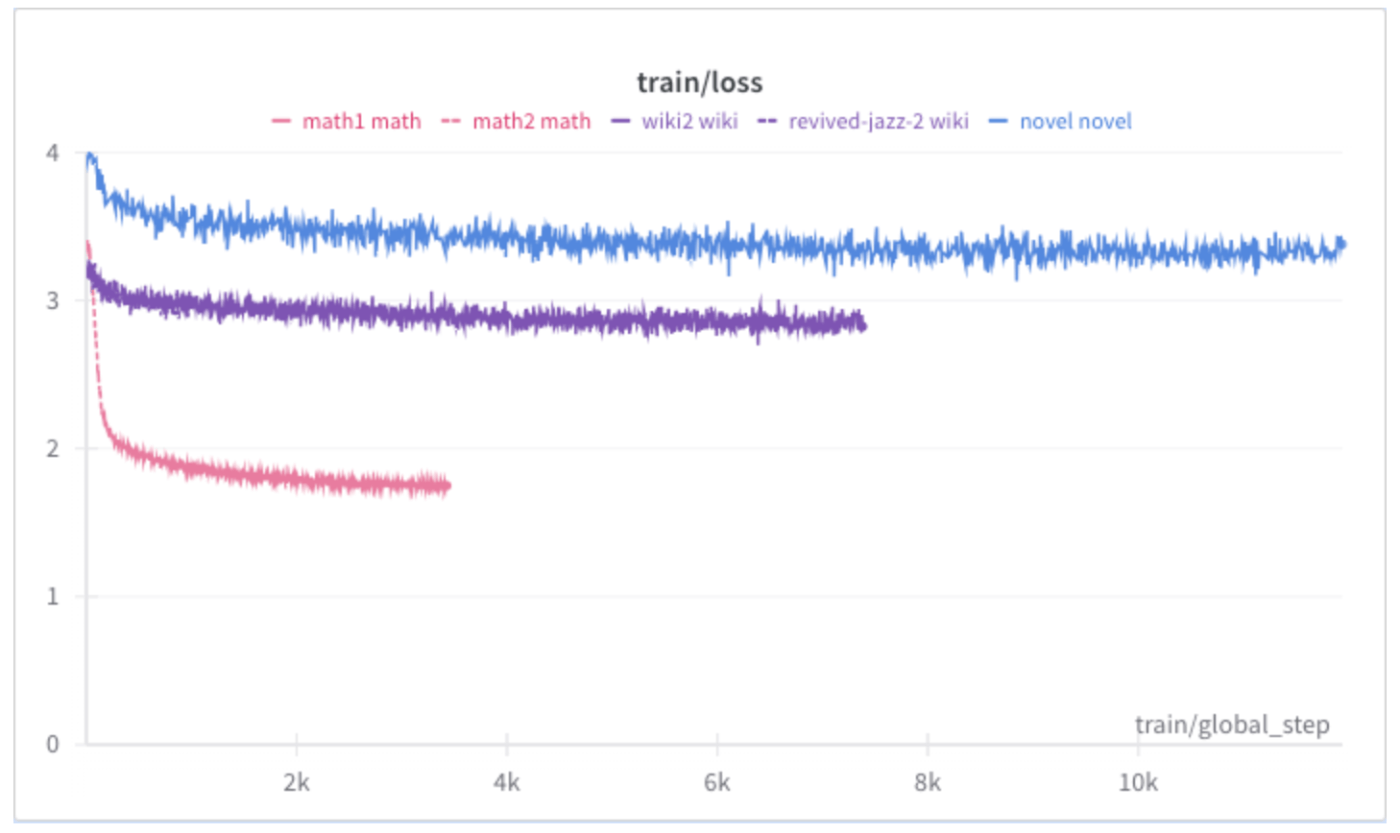
mathのlossが一番小さくなっています。これはデータセットの日英の比率と考えられます。novelについては全て日本語、wikiについては半分が日本語、mathについては1/3が日本語でした。
mathやwikiがnovelに対して、step数が少ないのは日本語のデータが少なかったためです。今回はどのexpertについても1epochしか行なってないですが、2,3epochほど行ってもよかったかもしれません。mathのlossについてはもう少し下がりそうですが、novelやwikiについてはこの先も大きい変動はなさそうです。expertとしてマージして利用するという点ではある程度過学習させておいた方が良さそうにも思えます。
3つのexpertをマージしMoEを構成し、router部分を学習
mergoについて
mergooというマージ用のscriptが公開されているので利用します。
mergooでは通常の(BTXのような)マージに加え、loraを用いたマージ、attention層をexpertとするマージの機能が提供されています。今回はloraでのマージを行います。
mergooでは現在、llama2, mistral, phi3がサポートされています。
llama2では、以下のコードでMLP層をloraのweightを使いexpertを持つように拡張します。
llama2では、MLP層はgate_proj、up_proj, down_projの3つの全結合層から構成されます。
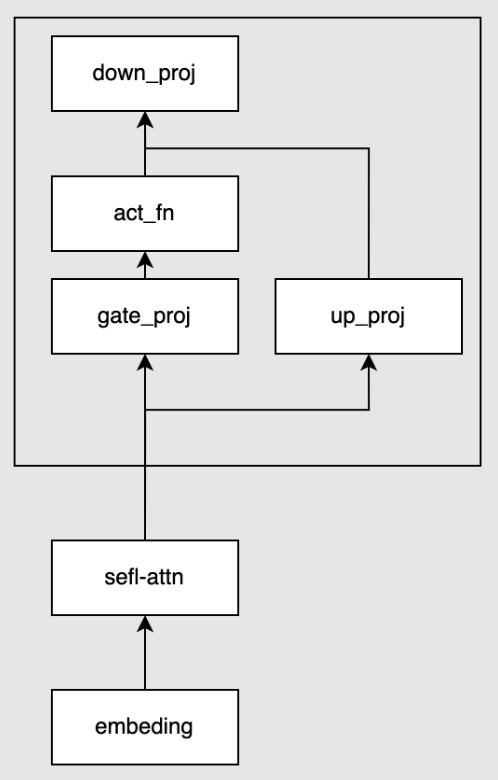
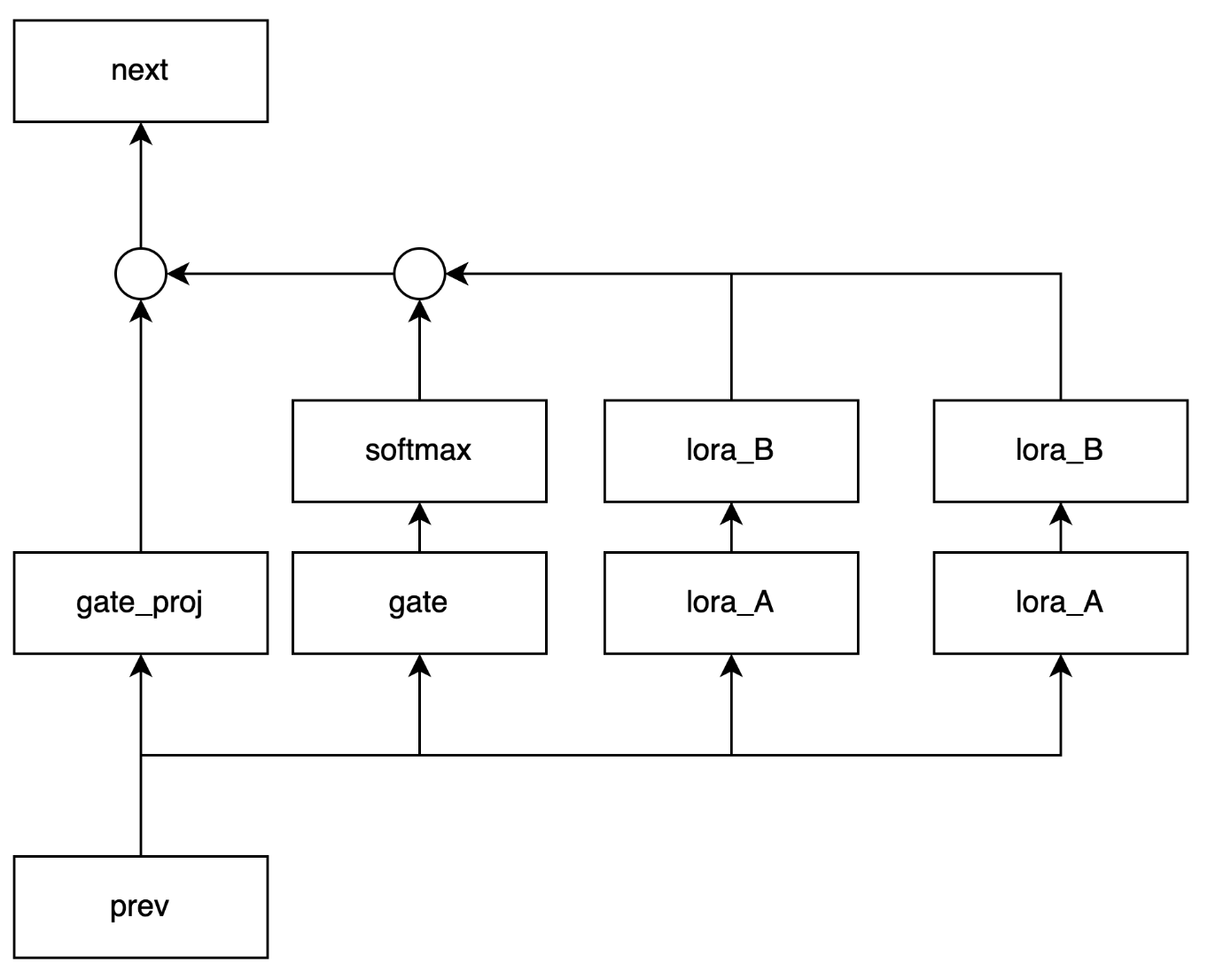
mergooのlora拡張では、1つの全結合層にgateとexpert追加で配置します。ここでexpertはloraのweightとなります。例えば、2つのexpertでgate_projを拡張する場合は以下のようになります。gateの出力のsoftmaxを取り、expertの出力に対して積を取ります。
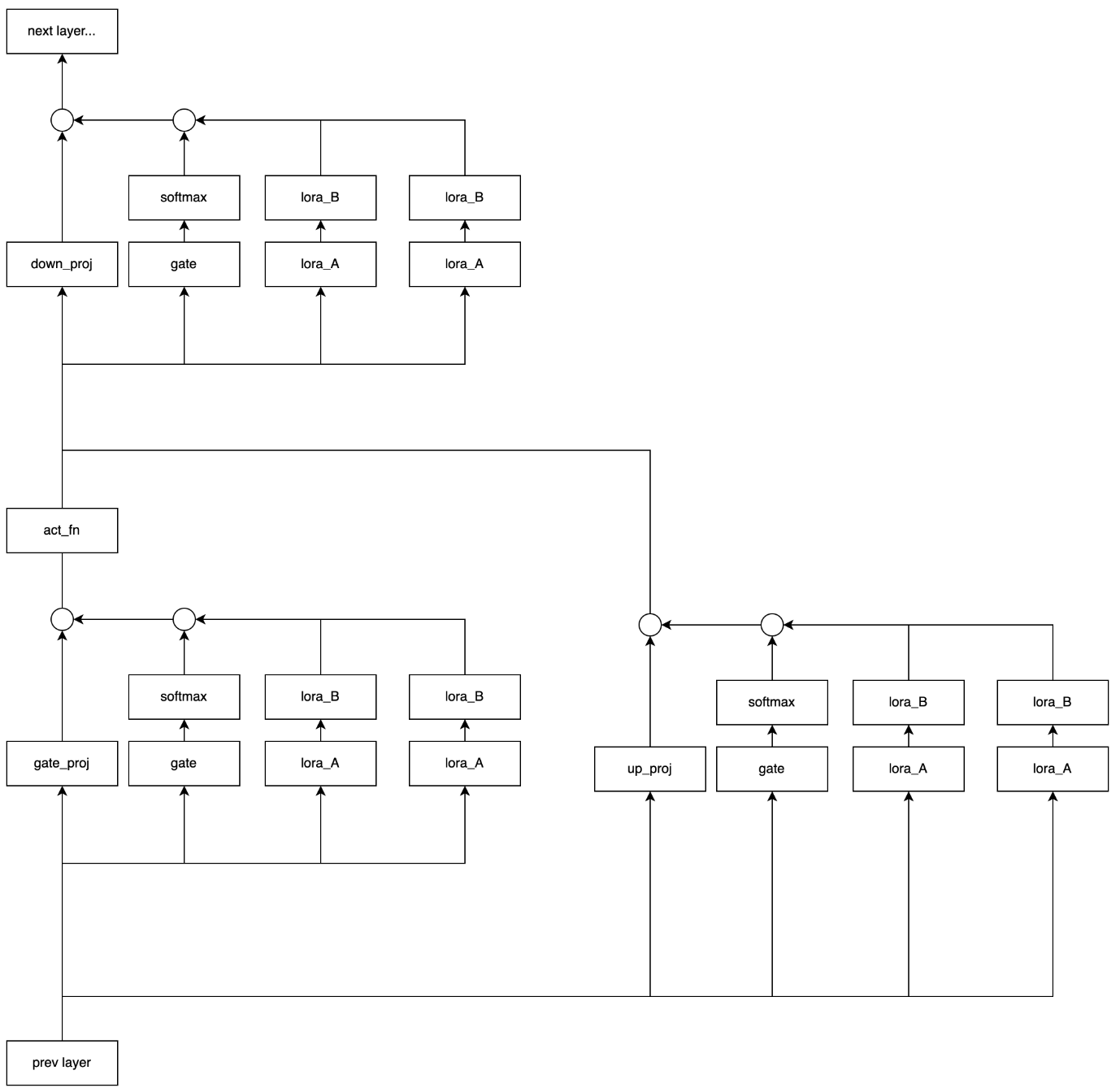
llama2のMLP層、つまりgate_proj、up_proj, down_projに対して拡張を行うと以下のようになります。
コード
huggingfaceを使い学習します。DDPやFSDP、datasetのpackingも行います。実装は上述のもの使い回します。
データセット
以下のデータセットで、合計1B tokenを学習します。expertを学習したデータの種類と同じものを使います。
- mc4_ja
- wikipedia_ja
- 青空文庫
- OpenMathInstruct
学習
マージ後のモデルは約9Bでした。gateとlm_headのみを学習します。freezeeしたことにより学習可能なパラメタは133Mです。gateのみを学習した場合や、全体を学習する場合なども試しましたが、gateとlm_headの場合が学習コストや性能面でバランスが取れていました。
lossのグラフは次のようになりました
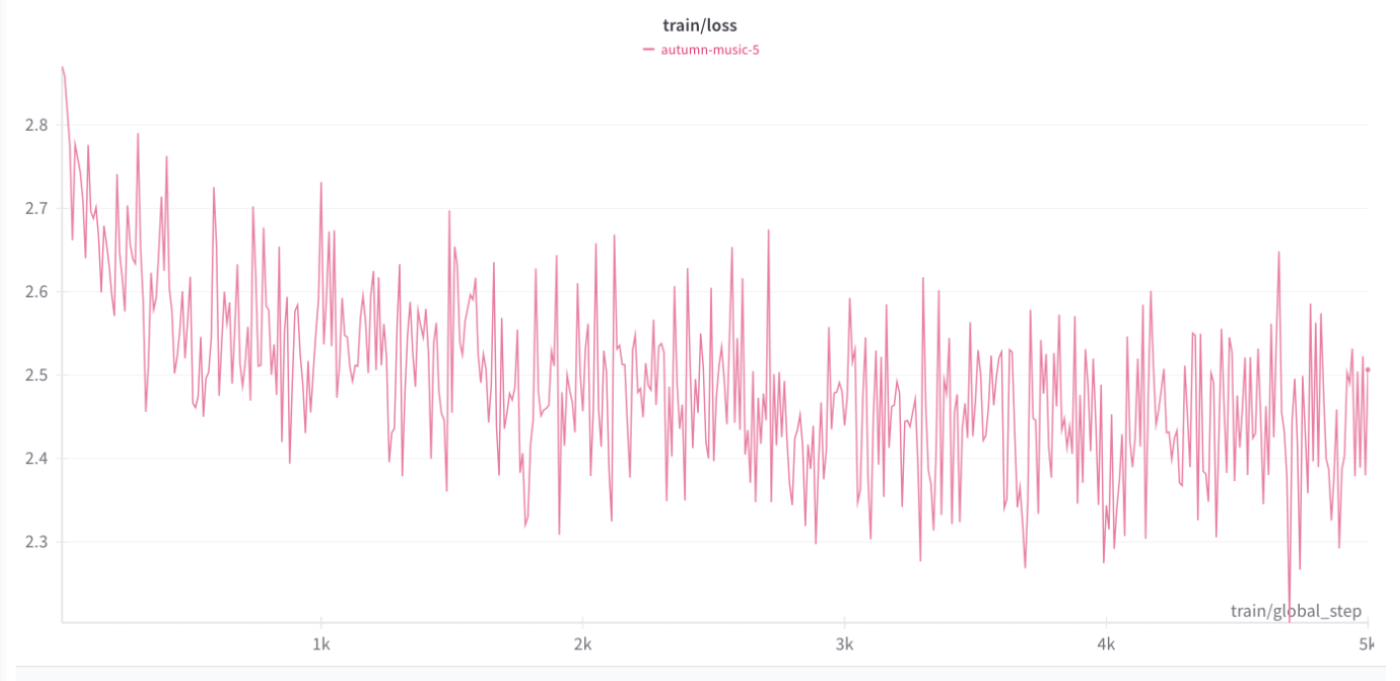
学習できるパラメタが少ないためか振動しているグラフとなっています。減少しているので学習は進んでいるようです。学習するデータセットのサイズや比率、routerの学習のタイミングでSFTを行うなどのデータセットの種類については、検証しきれなかったので、検討の余地が残りました。
SFTで学習
最後にSFTにより調整を行います。
データセット
以下のデータセットを1B分使いました。いくつかはたぬきチームが公開している生成データセットを使わせて頂きました。
- llm_japanese
- CoTangent
- auto-wiki-qa
- AutoGeneratedJapaneseQA
- AutoGeneratedJapaneseQA-CC
- AutoGeneratedJapaneseQA-other
- LogicalDatasetsByMixtral8x22b
学習
expertに当たる層をfreezeし学習します。モデル全体では9Bで、freezeにより学習可能なパラメタは2.41Bです。
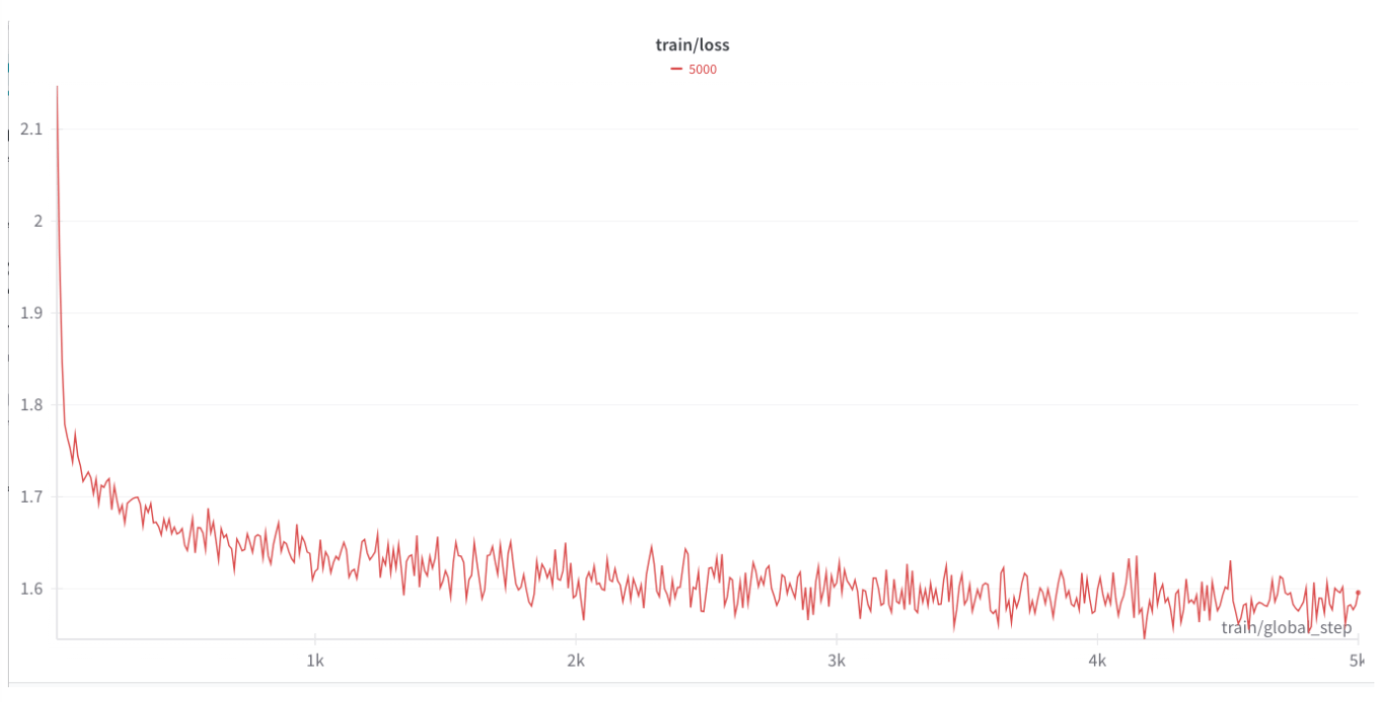
緩やかにlossが下がっており学習が行えているようです。時間の関係で十分なtoken数を学習させることができませんでした。もう少し学習を行うことでlossも下がりそうです。
所感
事後学習では、loraでexpertを作成したり、マージを行ったり、SFTを行ったりと、かなり工程の多い学習を行いました。
事後学習ではhuggingface/transformerで学習を使ったのですが、pipeline parallelismに対応しておらず、9Bのモデルは1枚のGPUにギリギリ乗り切るサイズのためbatch_sizeが挙げられず学習速度を上げることができませんでした。そのため、学習できるtoken数がかなり制限されてしまいました。huggingfaceのライブラリを用いたのは、loraやマージを行うのに都合がよかったからなのですが、ライブラリ周りの扱いやすさや環境の準備はしやすい反面、pipeline parallelismに対応していないこともあり大きいサイズのモデルを学習するのは困難でした。
![東大松尾・岩澤研究室 | LLM開発 プロジェクト[GENIAC]](https://storage.googleapis.com/zenn-user-upload/avatar/f9404760b8.jpeg)
東京大学 松尾・岩澤研究室が運営する松尾研LLMコミュニティのLLM開発プロジェクト[GENIAC] の開発記録、情報発信になります。 各種リンクはこちら linktr.ee/matsuolab_community
Discussion