はじめに
マルチノード/マルチGPU環境でllama2 7Bの事前学習を行います。
LLM開発や事前学習で大変だった部分をいくつか残しておきます。事前学習については他のチームの記事も上がると思うのでそちらを参照してください。
事前学習以外は別記事を参照
- データセット集め編
- トークナイザ作成編
- 事後学習編
環境設定
- Node数: 3
- GPU: H100*24(1ノードあたり8枚)
- 学習ライブラリ: Megaron-DeepSpeed
事前学習コード
Megatron-LM と Megatron-DeepSpeed の概要
Megatron-LMとは、LLM開発用のフレームワークです。torch.nn.Moduleを継承したMegatronModuleをbase classとしてLLMのアーキテクチャを構成し、データセットのロードやforward、backwardの計算、パラメータの更新などが実装されています。モデルの定義はGPT Model Classで行われており、いくつかの引数を与えることで、llamaやgptなどのアーキテクチャを表現することができます。
Megaron-DeepSpeedとは、Megatron-LMをforkしたもので、Megatron-LMでdeepspeedの機能を使えるようにしたものです。DeepSpeedは、Zero Redundancy Model(ZeRO) と呼ばれるGPUの割り当て量を削減する手法の実装です。モデルのoptimizer statesやモデルのパラメタ、勾配を複数のGPU間に効率的に配置/計算などを行います。 (DeepSpeedの詳しい解説については別途詳しく説明している記事があるのでそちらを参照してください。hugginfaceのdeepspeed記事)
学習コードの概要
DeepSpeedの機能を利用するには、deepspeedコマンドおよびdeepspeed configを使用します。deepspeed configの詳細についてはここを参照
学習を動かすコードはpretrain_gpt.pyでこのscriptをdeepspeedコマンドで実行します。
deepspeed $DISTRIBUTED_ARGS pretrain_gpt.py \
$GPT_ARGS \
$DATA_ARGS \
$OUTPUT_ARGS \
--distributed-backend nccl \
--save $CHECKPOINT_PATH \
--load $CHECKPOINT_PATH
学習コードの動作のため、shell scriptを修正します。以下のようにモデルサイズの定義や学習の引数、データセットなどを設定していきます。
## model定義
## GPT-3 XL 1.3B
model_size=1.3
num_layers=24
hidden_size=2048
num_attn_heads=16
global_batch_size=512
lr=2.0e-4
min_lr=1.0e-6
init_std=0.013
(省略)
## データセットのpathを指定
data_path="${data_home}/pile_text_document"
## 学習のパラメタなどの設定
megatron_options=" \
--lr-decay-tokens ${lr_decay_tokens} \
--lr-warmup-tokens ${lr_warmup_tokens} \
--micro-batch-size ${batch_size} \
--num-layers ${num_layers} \
--hidden-size ${hidden_size} \
--num-attention-heads ${num_attn_heads} \
--seq-length ${seq_len} \
--max-position-embeddings ${seq_len} \
--train-tokens ${train_tokens} \
--train-samples ${train_samples} \
--lr ${lr} \
--min-lr ${min_lr} \
--lr-decay-style ${lr_decay_style}
...
deepspeedのcofigに当たるds_configファイルもここを参考に修正します。例えば、optimizerやzero stageの設定を行います。その他の設定項目はここ
"zero_optimization": {
"stage": ZERO_STAGE
},
今回使ったコードはここ
torchrun と deepspeed コマンドの比較
LLM学習で複数のGPUや複数のノードを活用した分散学習を行う場合、torchrunコマンドやdeepspeedコマンドが使用されます。違いに混乱したり、うまく動かず苦労したのでまとめておきます。
単一ノードのマルチGPUで学習を行う場合、torchrunコマンドを使います。マルチGPUでの学習では、GPUごとにprocessを起動する必要があります。torchrunで1つのpython scriptを実行することで指定したGPU数分のprocessが起動されます。
例えば、1ノード2GPUの場合、以下のコードの引数であるrankを0, 1として、2つのprocessを起動します。(master_addrはマルチノードでの学習に使われるもので親ノードのhost名を設定し、world_sizeは利用するGPU数となります。)
import torch.distributed as dist
import os
def setup(rank, world_size):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
dist.init_process_group(
backend='nccl',
rank=rank,
world_size=world_size
)
torchrunでは上記のようなprocess間の通信の初期化を行い、GPU数分のprocessの起動、process間の通信の管理を行います。 (実際には他のprocessで計算した値の集約や、他のprocessのwaitなどはMegatron-LM側で実装されています)
マルチノードでマルチGPUの学習を行う場合、deepspeedコマンド(実装はここ)を使います。マルチノードを使う場合、各ノードの各GPUでprocessを起動する必要があります。torchrunコマンドでは場合、ノードに跨ったprocessの起動は行えません。deepspeedコマンドでは、torchのinit_process_groupを行い、他のノードでもGPU数分のprocessを起動します。
deepspeedコマンドを使用するには以下の準備が必要です。
- 各ノードへのSSH接続: deepspeedコマンドを実行するホストから、分散学習を行う各ノードへのSSH接続が設定されている必要があります。
- master_addrの設定: master_addrには、deepspeedコマンドを実行するホストのIPアドレスまたはホスト名を設定する必要があります。ローカルホスト(localhost)は使用できません。(この辺りの設定が間違っている場合、init_process_groupで初期待ちが発生します。)
deepspeed commandでは、デフォルトでPDSH(Parallel Distributed Shell)を利用して各ノードでprocessの起動を行います。例えば、deepspeed pretrain_gpt.pyのように実行した場合、各ノードでのpsコマンドでpretrain_gpt.pyが動いていることが確認できます。
並列化手法
パラレルに関するパラメタ設定が大変だったので、並列化について簡単に触れておきます。パラレルに関しての説明はnvidiaのドキュメントがわかりやすかったです。
DP(Data Parallelism)について
DP(Data Parallelism)は、各GPUにモデルを配置し、micro batchごとに並列に学習する手法です。
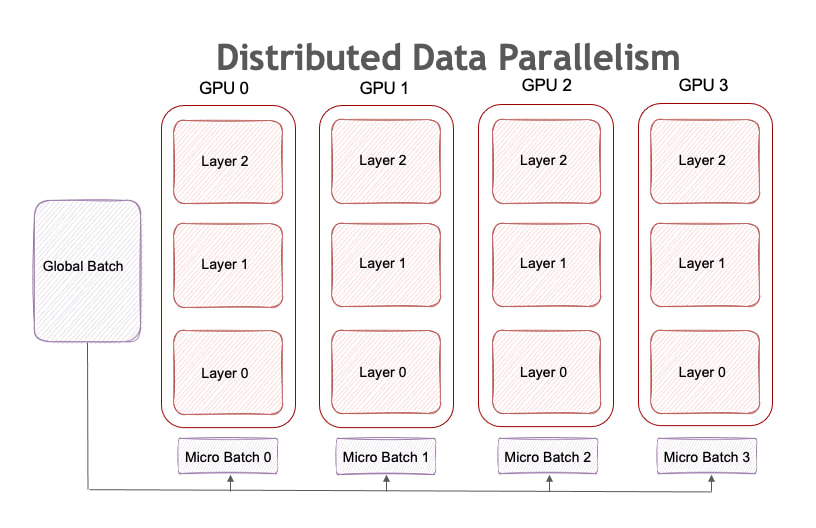
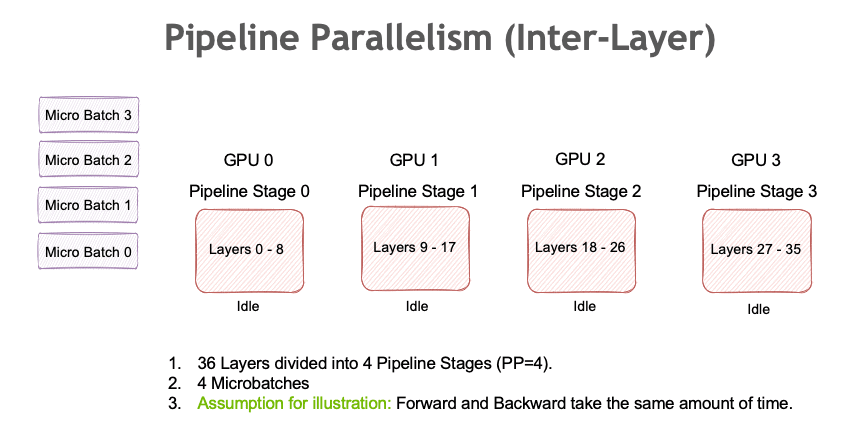
Pipeline Parallelism (PP)について
PP(Pipeline Parallelism)はモデルが1つのGPUに乗らない場合に有効です。以下の図のようにモデルのlayerを異なるGPUに配置します。
並列化手法の組み合わせと最適化
DPは単純に増やせば増やすだけ学習できるtoken数は増えますが、大きなモデルになると1GPUに乗り切らないことが多いのでPPやTPなどと組み合わせる必要があります。
PPは分割しすぎるとGPU間の通信がボトルネックとなり全体として処理するスピードは下がり学習できるtoken数は減ります。ノードを跨る分割の場合、ノード間通信による遅延が発生します。また、micro batchごとに並列に処理するのでmicro batch sizeが大きいと、あるlayerでの処理中に他のlayerでの処理がidleになり、一方で小さすぎると全体として処理するtoken数が減るので、PPと関連してmicro batch sizeも調整する必要があります。
パラメータ選定
学習率やwarmup stepsなどのhyper parameterは論文などを参考に設定します。パラレルに関するパラメタについては、24GPUでできるだけたくさんのtokenを学習できる設定を探していきます。
TPやPP、batch sizeやmicro batchサイズを調整し、token/secが最も大きいものを選定します。DPを増やすと速度が上がるなど、予想ができるものもありますが、直感と反して速度が上がる項目もあり、さまざまなパターンをとにかく試す必要がありました。
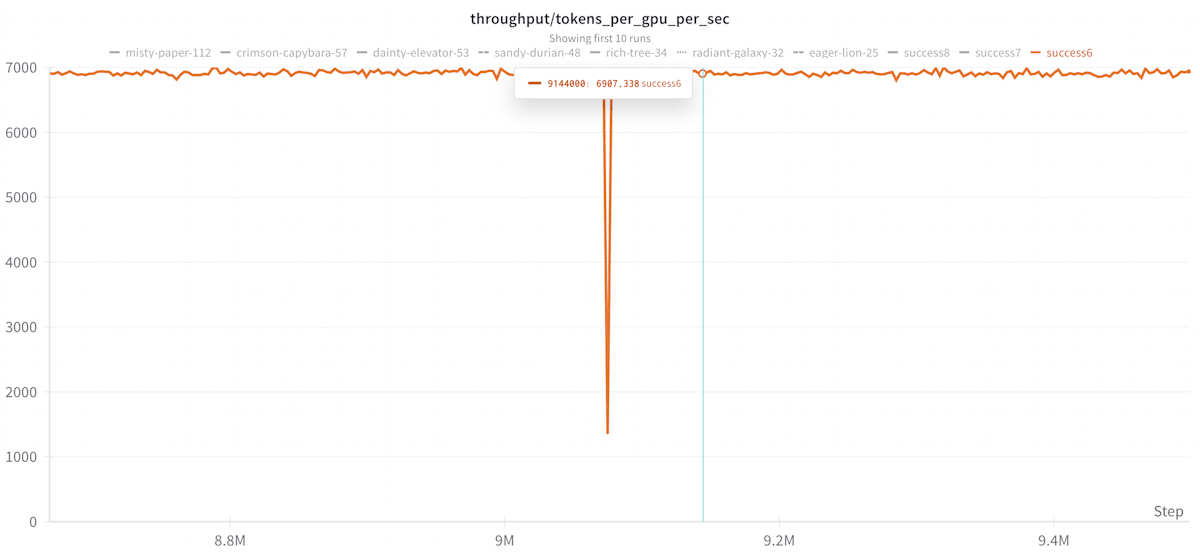
throughput/tokens_per_gpu_sec、throughput/flopsについて
DeepSpeed-Megatronでは、defaultでいくつかのthroughputを計算しておりwandbに出力されます。これらのうちthroughput/tokens_per_gpu_sec、throughput/flopsがパラメタ探索の指標として有効でした。
throughput/tokens_per_gpu_sec
パラメータ設定
探索の結果、以下の設定となりました。
mp_size=1 # Tensor Parallelismの数
pp_size=4 # Pipeline Parallelismの数
dp_size=6 # Data Parallelismの数
zero_stage=1
batch_size=2 # micro batch size
global_batch_size=1440
今回は、tokens_per_gpu_sec=6907なので、150B tokensを学習するには約10日かかる計算になります。
パラメタの探索は、tp(Tensor Parallelism)は1で固定し、DeepSpped ZeROやPPでGPUに割り当てられるメモリを削減し、micro batch sizeやglobal batchを小さい値から大きくするように行いました。
今回学習するllama2 7Bは32層から構成されています。PPはモデルを複数のGPUに分割して処理するため、32を割り切れる数で、GPUに乗る最大の値として4という値を採用しました。
DeepSpeedのZeROは、メモリ消費を抑制する手法で、stageを上げるほど、モデルのパラメータや勾配が分割され、メモリ消費は抑えられます。しかし、ノードを跨る通信量が増加し、通信遅延が発生する可能性があります。今回の探索では、stage1で十分な処理速度が得られ、stage2や3では、通信遅延の影響で全体的な処理速度が低下することが確認されました。
データセット
今回使ったデータセットの構成はJetMoEを参考にしました。
JetMoE: Reaching Llama2 Performance with 0.1M Dollars
JetMoEのデータセットについて
JeTMoEでは以下の3つのフェイズに分けて学習を行います
- phase1: warmup
- phase2: stable learning rate
- phase3: decay learning rate
「phase1、phase2」では一般的な情報を持つデータセットを使い、phase3ではSFT用のデータセットなどを含む綺麗なデータセットを使います。
また学習率に関しては、「phase1,phase2」ではwarmupの後、一定の学習率で学習が進み、phase3では指数関数的に学習率を下げます。

データセットの構成について
今回は以下のような比率でデータセットを構成しました。
phase1,phase2のデータセット
全体で360GBのtext、150B tokens
mc4(ja) 30%
refinedWeb 30%
github_code 25%
open_web_math 1%
psS2o 14%
phase3
全体で40GBのtext、15B tokens
mc4(ja) 30%
refinedWeb 10%
github_code 20%
open_web_math 5%
psS2o 10%
wikipedia(ja) 5%
wikipedia(en) 2%
SFT 8%
小説(ja) 5%
データセットの前準備
学習を始めるまでの準備として、データセットのサイズや種類、ダウンロードなどありますが、それ以外にデータセットをtokenizerされた形式で保存する必要があります。(コードはここ)
この処理は計算リソースにもよりますが数時間ほどかかります。学習の検証に多くリソース割きたくなりますが、どこかで計算リソースを使いあらかじめ準備しておくと学習を始めやすいです。また、小さいサイズのデータセットも準備してあると学習の試験など行いやすいです。
データセットの関連研究
最近のモデルの事前学習では、mc4やrefinedwebなどの大規模コーパスに加えて、コードやmathのデータを混ぜることが多いようです。また、事前学習をいくつかのフェーズに分けて異なるデータセット、異なる学習率を使うケースが多いように思います。deepseek v2では段階的に学習率を下げていき、nemotron-4-430BではSFTの段階ではありますがCodeを学習した後、一般的な知識の学習を行っています。
その他の準備
我々のチームの事前学習は途中でlossのスパイクが起き、色々試したのですが復旧せず、全体の半分のtokenを学習した時点から事後学習を行いました。スパイクへの対応は別途まとめようと思いますが、ここでは学習コードやデータセットの準備以外の必要な準備をまとめておきます。
wandbへの送信
学習中のlogはwandbに投げておくと楽です。deepspeedコマンドではデフォルトでいくつかの項目を保存するようになっているので、そのままの設定でも使えます。学習が止まったり、ある値が特定の閾値になった場合などにslackにアラートを飛ばせるので(参照)この辺りも設定しておくと良いです。
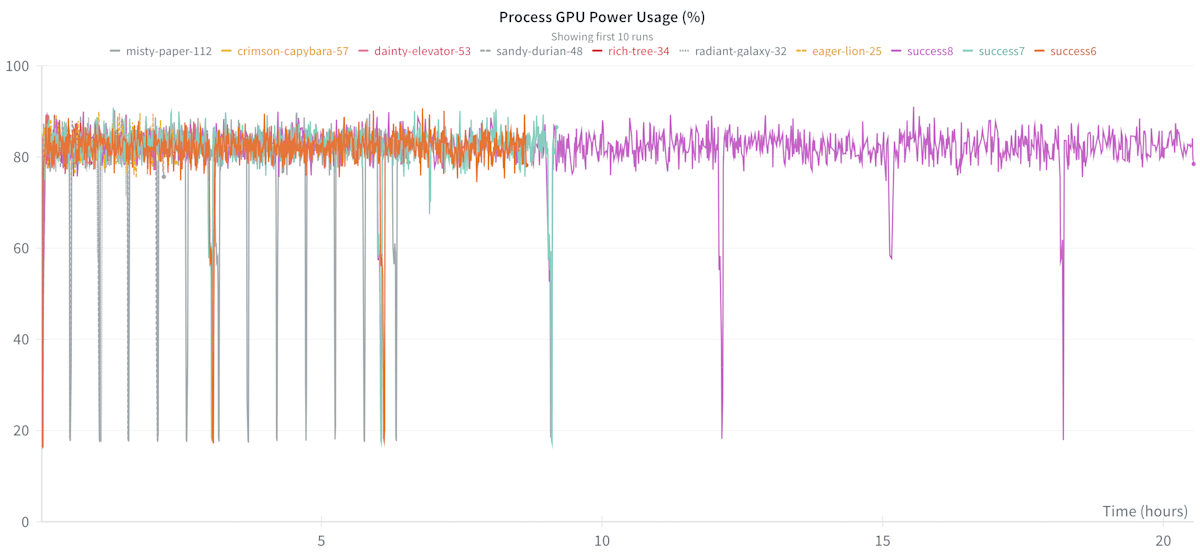
Process GPU Power Usage
GPUがどのくらい稼働しているかを表します。パラメタ調整ではできるだけ全てのGPUが休むことなく稼働できるように調整します。
Process GPU Memory Allocated
どの程度GPUメモリに割り当てられているかを表します。パラメタ調整では割当量が増える代わりに計算速度が上がるなどの設定があるのでここを見ながら調整します。
モデルの保存
モデルの保存時には各processの値を集約するため学習とは異なる計算リソースを使います。また保存が正しく行えているかなどの確認のため、本番の学習を始める前に何度か保存を試しておくのが良いです。
modelのweightに加え、optimizerのstatusも合わせて保存するので割と容量は大きくなります。llama2 7Bの場合100GB程度でした。
モデルの変換
学習したモデルはHugguingace(HF)にuploadすることが多いと思います。その際、DeepSpeedやMegatron-LMで保存したモデルをHF形式に変換する必要があります。学習を始める前に1度、モデルの変換、uploadを行っておくのが良いかと思います。
具体的にはlayer名を変更したり、PPやTP形式を1つにまとめたりなどの処理を行います。既存のモデルであればライブラリ側ですでに用意されていることが多いですが、存在しない場合もあるので、その場合は実装する必要があります。また、PP>2では対応してない場合などのケースもあるので、事前に変換まで行えていると安心です。
まとめ
事前学習に関するコード、その他の準備についてまとめました。事前学習に使うコードは、検証用の動作であればすぐさま動かせるのですが、1,2週間ほど学習を続けるとなると細かな準備や検証などが多く大変でした。
パラレルに関するパラメタ探索や、どのデータセットを使うかなどはとにかく数を試す必要があり、何を試して何を試してないかなをまとめたり、コードを管理したりする部分が大変でした。この部分はLLM開発において誰しもが通る大変な道だと思うので、ライブラリの開発やLLMによる探索など発展に期待します。
![東大松尾・岩澤研究室 | LLM開発 プロジェクト[GENIAC]](https://storage.googleapis.com/zenn-user-upload/avatar/f9404760b8.jpeg)
東京大学 松尾・岩澤研究室が運営する松尾研LLMコミュニティのLLM開発プロジェクト[GENIAC] の開発記録、情報発信になります。 各種リンクはこちら linktr.ee/matsuolab_community
Discussion