本記事では、Tanuki-8x8Bの開発前に取り組み、Loss spikeにより断念した38BクラスのDenseモデルの事前学習時のLoss spikeについての解説記事となります。本記事ではLoss spikeの原因について考察していますが、実際にどの項目がLoss spike発生の主要因であったかの検証試験はできていないため、その点はご容赦願います。
開発経緯
Team Hatakeyamaのphase2では初期目標として、35-50BクラスのDenseモデルに1000B Token以上の事前学習の計画をしていました。学習速度を高めるために、Megatron-LM及びTransformer engine + FP8を採用をしました。
Phase 1の段階ではMegatron-DeepSpeedを使用したFP16の学習をしていたため、本手法はphase2での新規取り組みとなりました。
Loss spikeとは?
大規模言語モデルの事前学習中にしばしば勾配爆発が発生し、lossが急激に大きくなることをLoss spikeと言います。これらのスパイクは大規模言語モデルの性能を低下させ、時には事前学習を台無しにしてしまいます。
Loss spikeは現状のLLMの開発では、学習条件の設定によって一定の確率で発生してしまうものです。同時期にLLMを開発していたLLM-JPさんの取り組みでもLoss spikeの発生には言及されており、東工大さんのLLama-3-SwallowのプロジェクトにおいてもLoss spikeが発生していたことが言及されています。また本プロジェクトのphase-1においても、Loss spikeが発生したチームが多数ありました。LLMを開発している会社でもloss spikeが発生したという噂は聞きます。(結果として、Loss spikeについては100%の防止手段は確立されておらず、一定の発生確率はプロジェクトとして織り込むことも必要だと学びました。)
一方、LLama3のtechnical reportではLoss spikeはほとんど発生しなかったと述べられており、学習条件やモデル構造によりLoss spikeの発生確率は低くすることができると考えられます。
(we observed few loss spikes and did not require interventions to correct for model training divergence : Llama3 technical reportより)
38Bモデルの学習時のハイパーパラメータ
以下に示すのは初期値であり、lr、rope theta、grad clip、batch sizeについては値を途中で変更している。
- lr : 1e-4
- rope theta : 500000
- grad clip : 1.0
- sequence length : 2048
- Batch size : 2304
- Transformer engine + fp8(hybrid)
- lossにz lossも取り入れた
38BモデルのLoss spike詳細について
38Bモデルの学習開始3日後のおよそiter12,600に初めてLoss spikeが発生しました。その後、一時的にLossは正常に減少したものの、4日目には最終的に発散してしまいました(図1参照)。
この問題に対処するため、続く数日間にわたってLoss spike対策を講じながら学習を行いました。しかし、対策にもかかわらずLoss spikeは繰り返し発生し、追加の対策と学習再開を何度も試みました。
結果として、本モデルでの学習継続は困難であると判断したもののLoss spike発生がプロジェクトの初期段階であったため、新たな戦略としてUp cyclingを用いたMoE(Mixture of Experts)手法への転換を決定しました。
以下にLoss spike発生後の対応の詳細について記載します。
最初のlossの発散後に、Loss spikeが発生した前の段階からLrを下げて学習を再開するも、Loss spikeが発生しました。次に、rope thetaが高いことが原因と考え、rope thetaを500000から10000に下げて実施するもLoss spikeが発生しました。
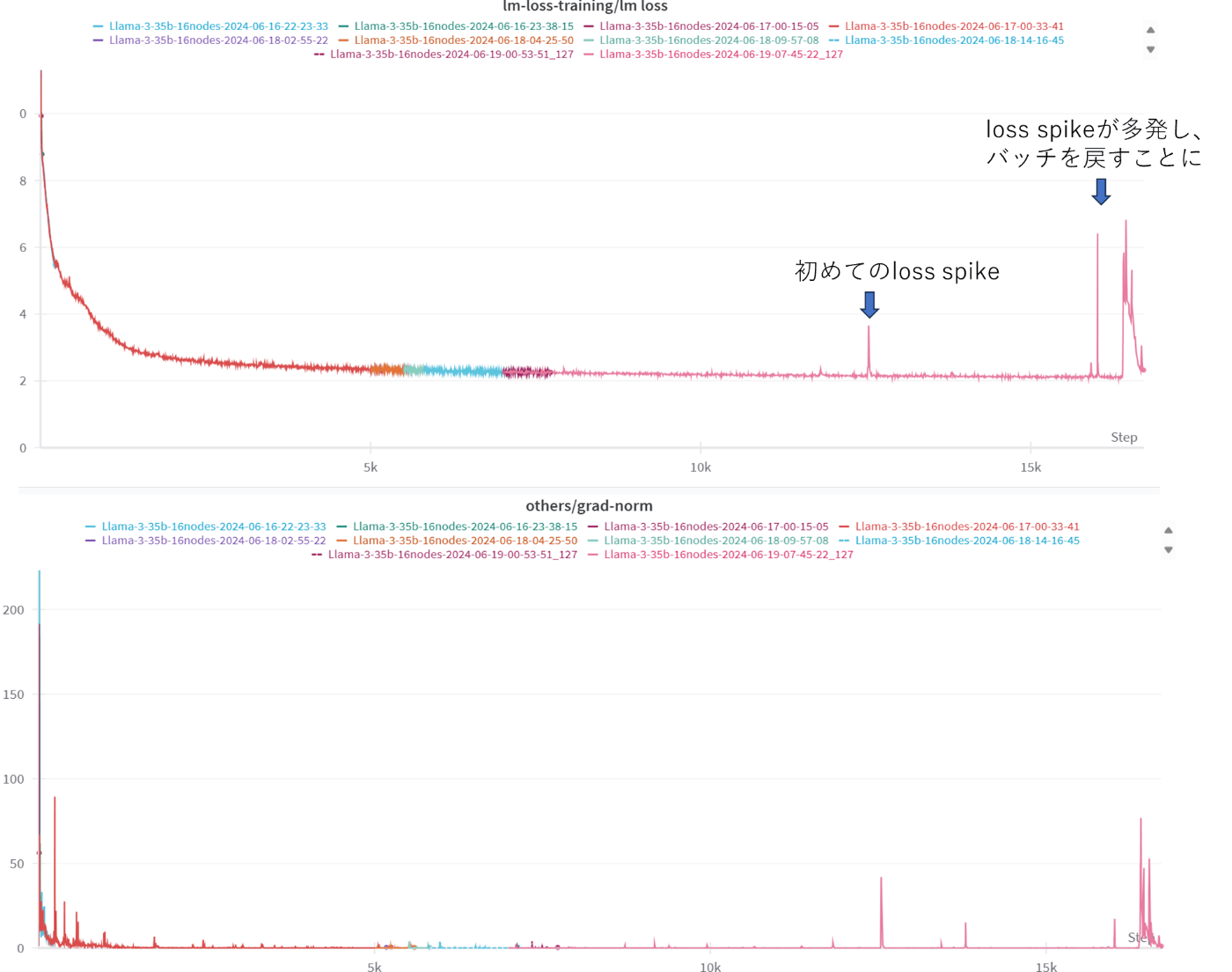
図1 学習開始後の最初のLoss spike

図2 Lr下げた条件で再開後のLoss spike
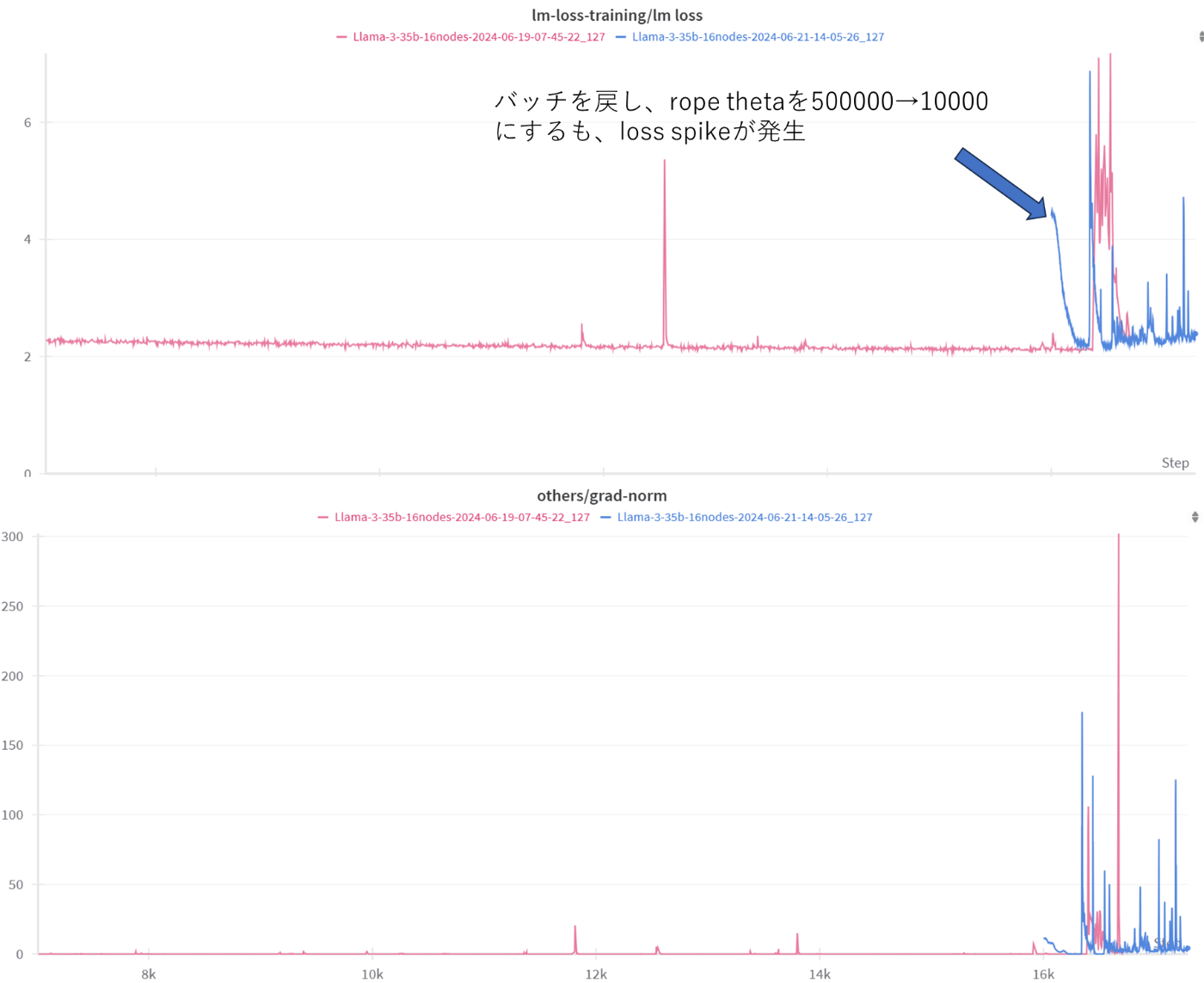
図3 rope thetaを下げた状態でのLoss spike
その後は、Loss spike後の学習再開時にはLoss spike近辺のiterをスキップする、データのノイズの影響を考えbatch sizeを4608に上げる、clip gradの値を1.0より下げることやLossの値が閾値を超えた際にbatchをスキップする等の工夫を試みることで、loss spikeによるその後のlossの増大の影響度は下げることができました(図4)。しかし、grad-normの値そものもは大きく、loss spikeそのものはなくすことができませんでした。また、これらの副作用としてlossの減少も小さくなり、学習が上手いきませんでした。

図4 grad clipの値を下げた状態でのloss spike
Loss spikeが発生した時に行った対処まとめ
Loss spikeが発生した際に行った対処について以下に示します。
これらを適用することで、一旦は改善したように思われることもありましたが、すぐに学習は不安定になってしまいました。学習が不安定になったモデルに対して事後で手を加えても効果の期待値は小さいと考えられます。
- spike発生前からのLrを下げての学習再開
- spike発生したiter前後のskip
- rope thetaを下げる
- Grad clipを下げる
- query_key_layer_scalingの適用(2307.06018 (arxiv.org))
- 勾配更新の際にLossが一定以上であれば更新しないようにする
Loss spikeのために検討すべきだった事項
-
アーキテクチャに関して
PFEさんの取り組みで紹介されているように、先行事例で紹介されているQK Normalization※1の適用については事前に検討すべきであった。今回参考にしたllama3やqwen等のアーキテクチャでは採用されていないことから、検証をしていませんでした。
※1 transformerのqkを正則化することでノルム自身の増大を防止する。 -
学習時のモニタリングについて
今回はLossとしてz lossも組み込んでいたが、z lossそのものの値はモニタリングをしていなかった。PFEさんの取り組みではz lossは学習の状態を確認するmetricとしても役立つと報告されており、grad normだけでなく、この値もモニタリングをすべきでした。 -
学習率について
今回採用した学習率は1e-4であり、llama3で採用された8e-5と比較してもそれほど高い値ではなかった。しかし、先行事例ではwarmupの値が大きいほど同じ学習率では学習の安定性が増すことが報告されており、llama3は8000iterかつ、我々は1000iterであった。それだけでなく、先行事例より学習率が高いほど学習の安定性が下がることが分かっているので、今回のモデルに対しての適正値をwarmupも含めて検討すべきでした。 -
Transformer engine + FP8の適用について
Transformer engine + FP8の適用は計算速度は速くなるが、先行事例では学習の安定性が低くなることが報告されている。適用に際しては特性を事前検証し十分に把握すべきでした。 -
rope thetaの値について
最近のllamaやmistralに代表されるモデルはrope thetaを大きくとり、long contextに対応できるようにしています。しかし、今回の38Bのモデルは学習時のsequence lengthが2048であり、初期値として500000の値をとるのは値が大きく、学習を不安定にした可能性が考えられます。 -
事前検証について
上記に示すような新規項目を採用するにあたり、事前検討を十分に行う必要がありました。本来であれば小型モデルを学習させ、設定したパラメータで性能がでるかを検証すべきであったが、プロジェクトの期間を優先して実施できていない点が多くありました。モデルを大型化することで、想定外のトラブルに合うことも考えられるますが、上記の項目については、事前検証で問題の有無について確認する必要がありました。
まとめ
本資料では38Bモデルの学習時に発生したLoss spikeについて報告しました。Loss spikeには未知の要素が多く、実際に学習を行わなければ把握できない点も存在します。しかし、過去の知見を活用し、事前検証を徹底することで、本番学習の成功率を向上させることが極めて重要です。また、今回の経験から、問題発生後のリカバリが容易ではないことが明らかになりました。
PaLMの先行研究に基づき、学習を巻き戻し、Loss spike発生箇所周辺のバッチをスキップする方法を試みました。この対策により、同じ箇所での再発は防げましたが、その後の学習過程でLoss spikeが再発しました。
リカバリが容易でない主な要因として、モデルの不安定化が始まる時点を特定することが難しく、そのため、学習をどの程度巻き戻せば良いかの明確な指標がないことが挙げられます。
本課題に対する解決策の考案が、今後の事前学習の安定性向上に不可欠だと考えます。
将来展望
今後のLLM(大規模言語モデル)開発において、成功事例の共有だけでなく、事前学習の失敗に関する技術情報の公開と共有が不可欠です。加えて、loss spikeを抑制するための学術的な基礎研究の推進が重要となります。本事例がこれらの取り組みに貢献し、LLM開発コミュニティの知見向上に寄与できることを期待しています。
以上
![東大松尾・岩澤研究室 | LLM開発 プロジェクト[GENIAC]](https://storage.googleapis.com/zenn-user-upload/avatar/f9404760b8.jpeg)
東京大学 松尾・岩澤研究室が運営する松尾研LLMコミュニティのLLM開発プロジェクト[GENIAC] の開発記録、情報発信になります。 各種リンクはこちら linktr.ee/matsuolab_community
Discussion