【システム設計の面接対策】第1章 ユーザー数ゼロから数百万人へのスケールアップ 読書メモ
この記事はシステム設計の面接試験の第1章の読書メモです
1章 ユーザー数ゼロから数百万人へのスケールアップ
一人のユーザーをサポートするシステムを構築し、徐々にスケールアップし、何百万人ものユーザーにサービスを提供することを目指す。
下記はwebアプリケーション、
DB、キャッシュなどそのすべてが一つのサーバ上で動作する単一サーバの設定を図解したもの。

単一サーバーのセットアップ
設定を理解する上で、リクエストの流れとトラフィックのソースを見ていく。
リクエストの流れ
- api.のようなドメイン名でDNSにアクセス
- IPアドレスがブラウザorモバイルアプリに返される
- IPアドレスを取得すると、HTTPリクエストが直接webサーバーに送られる
- webサーバーはレンダリング用のHTMLページまたはJSONレスポンスを返す
トラフィックのソース
webアプリケーション
- サーバーサイドの言語とクライアントサイドの言語を組み合わせて使用
モバイルアプリケーション - HTTPはモバイルアプリとwebサーバー間の通信プロトコルである。データ転送のAPIレスポンス形式としてはJSONが一般的。
データベース
ユーザー数の増加に伴い、1台のサーバでは足りなくなり、web/モバイルトラフィック用とDB用の複数サーバが必要になった。web層とデータ層との分離により個別拡張が可能になる。
どちらのDBを使うのか?
RDB
- MySQL,Oracle DB, PostgreSQLなど
非RDB
- Amazon DynamoDB,HBase,Cassandra,Neo4j,CouchDBなど
- キーバリューストア、グラフストア、カラムストア、ドキュメントストアという4つのカテゴリに分類される
- 詳しくはこちら
- 下記のような場合に適しているかもしれない
- アプリケーションに超低遅延が必要な場合
- 非構造化データを扱う場合
- データのデシリアライズ、シリアライズだけが必要な場合大量のデータが必要な場合
垂直スケーリングと水平スケーリング
垂直スケーリング
- 「スケールアップ」と呼ばれ、サーバのパワー(CPU,RAMなど)を追加する作業を意味する
- ハードウェアとしての限界がある1台のサーバに無制限にCPUとメモリを追加することは不可能
- 垂直スケーリングにはフェイルオーバーや冗長性がない
- 1台のサーバーがダウンすると、webサイトやアプリケーションも一緒に完全にダウンしてしまう
- フェイルオーバー (Failover)とは、稼動中のシステムやサーバーに障害が発生した際に、自動的に待機システムに切り替える仕組み
- 冗長性がない、とはシステムが停止することなく継続的に稼働し続けられる状態ではないということ
水平スケーリング
- 「スケールアウト」と呼ばれ、リソースのプールにさらにサーバを追加することでスケールを可能する
- リソースのプールとは、アプリケーションが利用可能な計算リソース(サーバー、ストレージ、ネットワークリソースなど)の集合を指す。
- このプールは物理的なサーバやクラウドベースのリソースなどがある
- 垂直スケーリングは限界があるため、大規模アプリには水平スケーリングが好ましい
ロードバランサ
- ロードバランサは受信したトラフィックをロードバランサ・セットで定義されたwebサーバに均等に分散させる
- ロードバランサを導入することでフェイルオーバーの問題を解決し、web層の可用性を向上させることができる。
- 一つのサーバーがオフラインになった場合すべてのトラフィックはもう一つのサーバにルーティングされる
- webサーバープールにサーバを追加するだけでロードバランサは自動的に自動的にそれらのサーバにリクエストを送信してくれる
データベースレプリケーション
- 「データベースレプリケーションは、多くのデータベース管理システムで使用されており、通常、オリジナル(マスター)とコピー(スレーブ)とはマスター/スレーブ(奴隷)の関係にある」
マスターデータベース
- 一般的に書き込み操作のみをサポートする
スレーブデータベース
- マスターデータベースからのデータのコピーを取得し、読み込み操作のみをサポートする
- 挿入、削除、更新などのデータの修正コマンドはすべてマスターデータベースに送らなければならない。
データベースレプリケーションの利点
-
パフォーマンスの向上
- マスター/スレーブ構成では、書き込みと更新はすべてのマスターノードで行われ、読み込み操作はスレーブノードで分散して行われる、
- このモデルでは、より多くのクエリを平行処理できるため、パフォーマンスが向上する
-
信頼性
- 自然災害でデータベースサーバが破壊されても、データは保全される。また、データは複数個所に分散して複製されるためデータの損失を心配する必要はない
-
高い可用性
- データを複数の場所に複製することで、データベースがオフラインになっても、別のデータベースサーバに保存されているデータにアクセスできるため、webサイトの運用を継続できる
- 例えばスレーブデータベースが一つしかなく、それがオフラインになった場合、の読み取り操作は一時的にマスターデータベースに誘導され、複数のスレーブデータベースがある場合で一つのスレーブDBで問題が発生した場合は健全なスレーブデータベースにリダイレクトされる
- 例えばマスターデータベースがオフラインになった場合はスレーブデータベースが新しいマスターになるように設定される。本番システムでは、スレーブデータベースのデータが最新でない可能性があるため、新しいマスターを昇格させるためにデータ復旧スクリプトを実行し、不足するデータを更新する必要がある。マルチマスターや循環レプリケーションといった他のレプリケーション方法もあるが、これらの設定はより複雑
キャッシュ
- キャッシュとは高いレスポンスや頻繁にアクセスされるデータの結果をメモリに保存し、後続のリクエストをより迅速に処理されるようにする一時的な記憶領域
- データベースコールの実行回数を減らし、アプリケーションの性能への悪影響を軽減する
キャッシュ層
- キャッシュ層とは一時的なデータストア層で、データベースよりもはるかに高速
- この層のメリットは、システム性能の向上、DB作業負荷の軽減、キャッシュ層を単独で拡張できる、などがある
- リードスルーキャッシュ
- どのようなものか?
- webサーバはリクエストを受け取ると利用可能なレスポンスがキャッシュにあるか確認
- あればクライアントにそのデータを返す。
- なければDBに問い合わせ、レスポンスにキャッシュを保存する。
- これを繰り返す
- 例
- Memcached API
- プログラミング言語用の下記のようなAPIが提供されている
SECONDS = 1 cache.set('myKey', 'hi therer', 360 * SECONDS) cache.get('myKey) - 導入タイミングっていつ?と疑問に思ったのでchatGPT4に聞いてみためも
- DBの負荷が高い
- アプリケーションの応答が遅く、その主な要因がクエリによる負荷だった場合
- 読み出し操作が多い
- アプリケーションが読み出し操作に偏っていて、特定のデータセットに集中している場合
- DBの負荷が高い
- Memcached API
- どのようなものか?
キャッシュを使用する際の注意点
-
キャッシュを使用するタイミングの決定
- データの読み取り頻度が高く、変更頻度が低い場合
-
有効期限ポリシー
- 有効期限ポリシーを実装するのはいい方法である。
- キャッシュされたデータの有効期限が切れると、キャッシュから削除される。短くしすぎるとシステムがDBからデータを頻繁に再読み込みすることになるので短くしすぎないようにする。
-
一貫性
- データストアとキャッシュを同期させる。単一のトランザションではないため、不整合が発生することがある。 こちら を参考にする
-
障害の軽減
- 単一のキャッシュサーバは潜在的な単一障害点(SPOF)を意味し、システムの一部でそれが故障するとシステム全体の動作が停止してしまう箇所。
- これを回避するため、下記2点が推奨される
- 異なるデータセンターでの複数キャッシュサーバを使用することが推奨される。
- 必要なメモリを一定の割合で過剰にプロビジョニングするメモリ使用量に伴うバッファを提供する
-
削除ポリシー
- キャッシュのエビクション
- キャッシュがいっぱいになり、アイテムを追加するリクエストがあると、既存アイテムが削除される可能性がある。
- LRU(Least-recently-used)は最も一般的なキャッシュ削除ポリシー
- LFU(First in First Out)は最初に入れたものを最初に出すというポリシー
- この辺はこちらのサイトがわかりやすかったです
- キャッシュのエビクション
コンテンツデリバリネットワーク(CDN)
- CDNは地理的に分散したサーバのネットワーク
- 静的コンテンツを配信するために使用される
- CDNサーバは、画像、動画、CSS,JacaScriptファイルなどの静的コンテンツをキャッシュする
仕組み
- ユーザーがWebサイトにアクセス
- ユーザーに最も近いCDNサーバが静的コンテンツを配信する
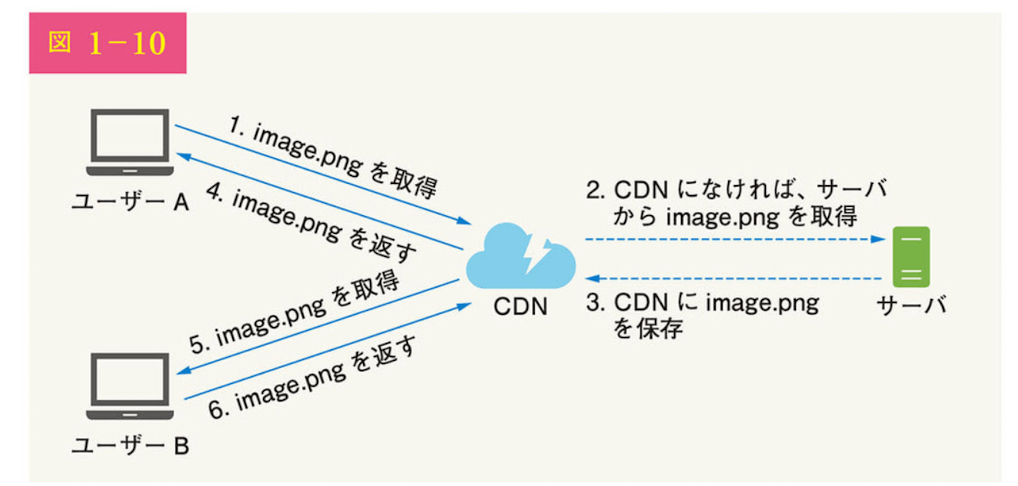
以前取得したユーザーとは別のユーザーが同じデータをリクエストして、それがCDN
にあり、TTLが執行していない限り、CDNから返される
- TTL・・・DNSにおいて、リソースレコードをキャッシュに保持してもよい時間を秒単位で示す31ビットに符号化された整数で、ゼロまたは正の値
CDNを利用する際の注意点
-
コスト
- サードパーティのプロバイダによって運営されているので、CDNへの、CDNからのデータ転送に課金される。使用頻度の低いコンテンツはキャッシュしても大きなメリットがないので、CDNからの移動を検討する必要がある
-
キャッシュの有効期限の適切な設定
- 時間制約のあるコンテンツでは、有効期限設定が重要であり、長すぎても短すぎてもいけない。
- 長すぎると新鮮でなくなる可能性があるし、短すぎると、オリジナルサーバからCDNへのコンテンツを繰り返し読み込みする可能性がある。
- 時間制約のあるコンテンツでは、有効期限設定が重要であり、長すぎても短すぎてもいけない。
-
CDNフォールバック
- CDNが故障した場合にwebサイトやアプリケーションがどのように対処するかを検討する必要がある
- 一時的に停止した場合、クライアントがその問題を検知し、オリジンサーバからリソースをリクエストできるようにする必要がある
-
ファイルの無効化
- 下記のいずれかを実行することで、有効期限が切れる前にCDNからファイルを削除できる
- CDNベンダーが提供するAPIを使用してCSVオブジェクトを無効化
- オブジェクトのバージョニングを使用して、オブジェクトの異なるバージョンを提供する。オブジェクトをバージョン管理するにはURLにバージョン番号などのパラメータを追加する
- 下記のいずれかを実行することで、有効期限が切れる前にCDNからファイルを削除できる
ステートレスweb層
web層の水平スケーリングを検討する。
状態(例えばユーザーの状態データなど)をweb層の外に移す必要がある。
望ましいのは、状態データをRDBやNoSQLのような永続的なストレージに保存すること。
ステートレスweb層とは
クラスタ内の各webサーバはDBから状態データにアクセスできるような層
ステートフルアーキテクチャ
- ステートフルサーバはあるリクエストから次のリクエストまでのクライアントデータ(状態)を記憶しているが、ステートレスサーバは状態情報を保持しない。
下記はステートフルアーキテクチャの例
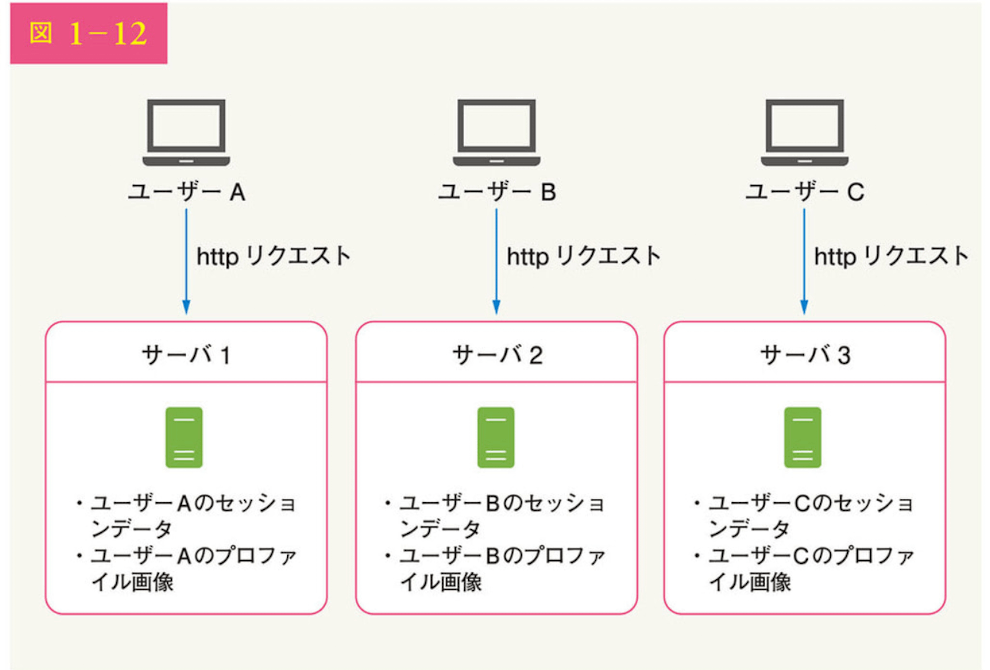
ユーザーAを認証するにはサーバ1にルーティングされなければならない。ユーザーAがサーバー2にリクエストを送ると、状態がないため認証が失敗してまうので、全りくえすとが同じサーバにルーティングされなければならなくなり、サーバの追加や削除、故障処理が困難になる。
ステートレスアーキテクチャ
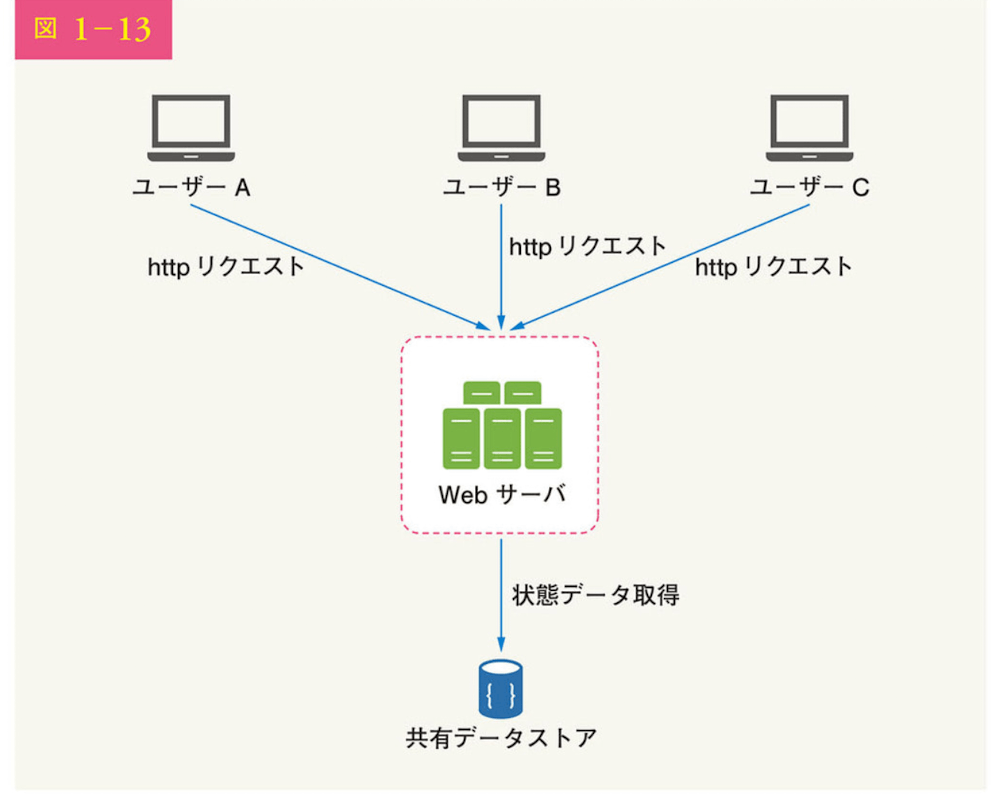
ステートレスアーキテクチャでは、ユーザーからのHTTPリクエストは任意のwebサーバに送られ、webサーバは共有データストアから状態データを取得する。
応対データは共有データストアに保存され、webサーバには残らない。
シンプルで堅牢でスケーラブルになる。
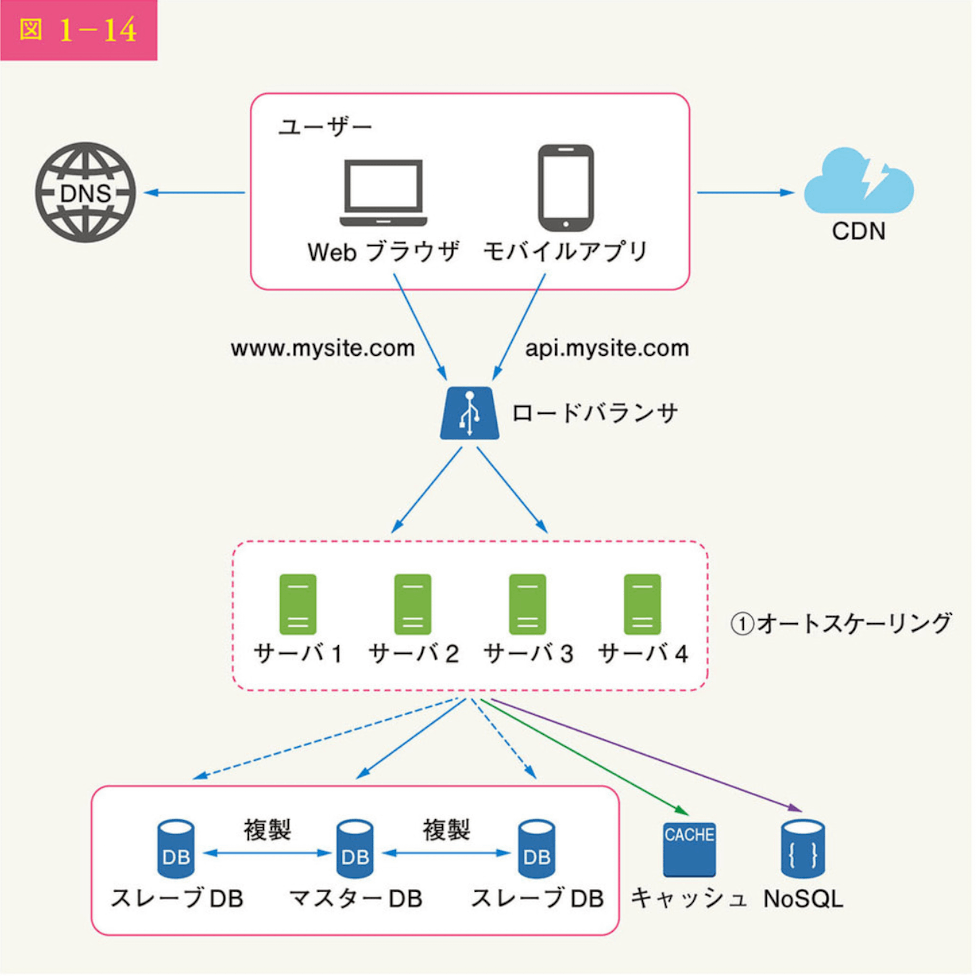
状態データをweb層あら移動し、永続データストアに保存している。
共有データストアはRDB、Memcached/Redis,NoSQLなどの可能性がある。
NoSQLは拡張が容易で選ばれる。
webサーバから状態データを取り除いた後、トラフィック負荷に応じてサーバを追加、削除することで、web層のオートスケーリングを容易に実現できる。
データセンター
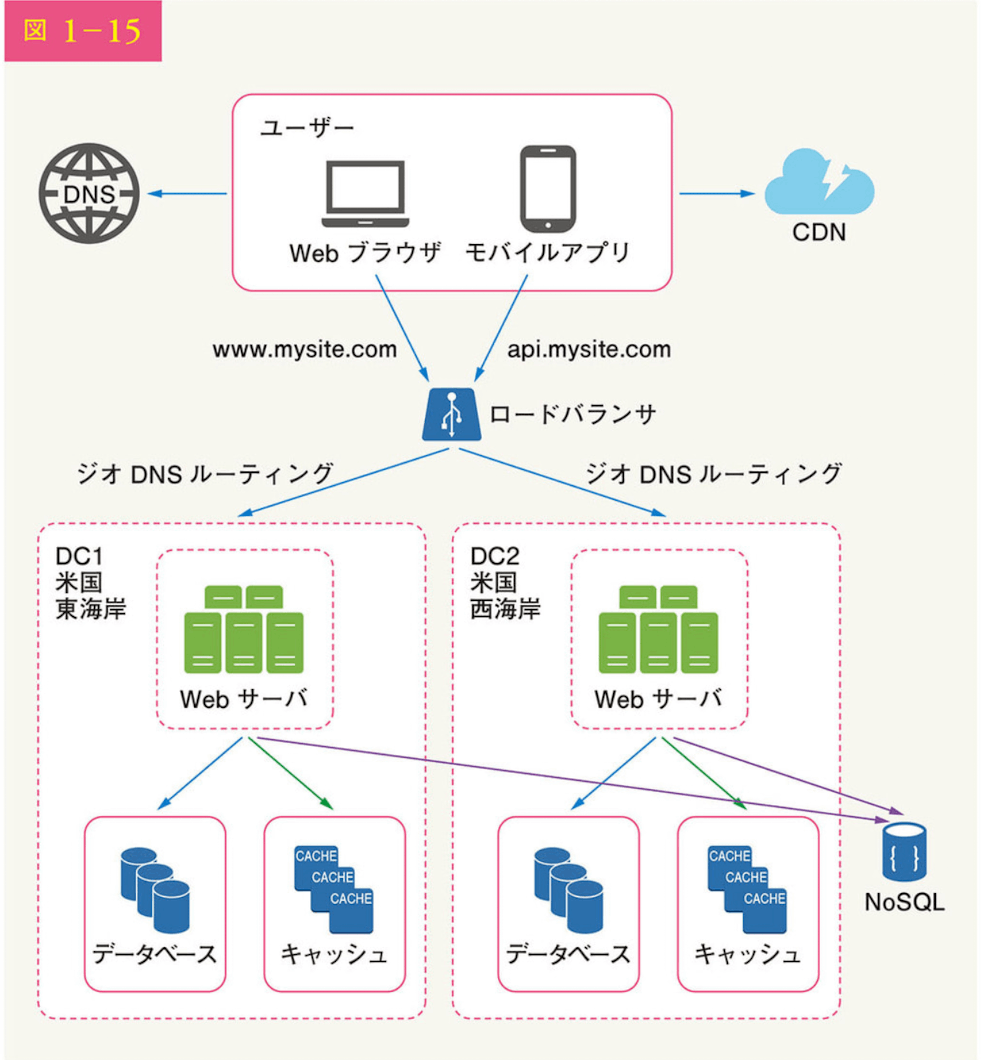
マルチデータセンター化を達成するには以下の技術的課題を解決する必要がある
-
トラフィックのリダイレクト
- トラフィックをデータセンターに誘導するために効果的なツールが必要。
- ジオDNSを使用すると、ユーザーの所在地に応じて最も近いデータセンターにトラフィックを誘導できる
- トラフィックをデータセンターに誘導するために効果的なツールが必要。
-
データの同期
- 異なる地域のユーザーは異なるローカルデータベースやキャッシュを使用するかもしれない。フェイルオーバーの場合、データが利用できないデータセンターにトラフィックがルーティングされる可能性がある。一般的な戦略は、複数のデータセンター間でデータを複製すること。こちらがNetflixの参考事例
-
テストとデプロイ
- webサイトやアプリケーションを異なるロケーションでテストすることが重要になる。
- 全てのデータセンターにおけるサービスの一貫性を維には、自動デプロイ面とツールが不可欠となる。
システムをさらに拡張するには、システムのさまざまな構成要素を切り離し、それぞれが単独で拡張できるようにする必要がある。
メッセージキューはその問題を解決するため、多くの実世界の分散システムで採用されている重要な戦略。
メッセージキュー
- メッセージキューとは、メモリに格納された耐久性のある構成要素であり、非同期通信をサポートしている。
- バッファとして機能し、非同期要求を分散させる。
メッセージキューの基本的なアーキテクチャ
- プロデューサー/パブリッシャーと呼ばれる入力サービス
- メッセージを作成し、メッセージキューに発行する
- コンシューマー/サブスクライバー
- 他のサービスやサーバは、キューに接続し、メッセージによって定義されたアクションを実行する。
- 互いに切り離されることで、メッセージキューはスケーラブルで信頼性の高いアプリケーションを構築する上で望ましいアーキテクチャになる。
特徴
- メッセージキューではプロデューサーはコンシューマーが処理できない時でも、キューにメッセージをポストできる。
- コンシューマーはプロデューサーが利用できない時でもキューからメッセージを読み出せる
- プロデューサーとコンシューマーはそれぞれ単独でスケールアップできる
- メッセージキューのサイズが大きくなれば、ワーカーを追加して処理時間を短縮できる。
- ワーカーとは、キューからメッセージを受け取り、それらのメッセージに基づいて、タスクや処理を実行するプログラムやプロセスのこと。コンシューマーとワーカーはしばしば同じ文脈で使用され、多くの場合、実質的に同じ役割を指す。
- キューがほとんどからである場合は、ワーカーの数を減らせる
- メッセージキューのサイズが大きくなれば、ワーカーを追加して処理時間を短縮できる。
サービス
- AWSのSQS
- Apache Kafka
- RabbitMQ
などがある
ログ取得、定量化、自動化
-
ログ取得
エラーログの監視はエラー特定において重要、エラーログは、サーバ単位での監視も可能だが、ツールを使って一元化し、簡単に検索、閲覧できるようにすることも可能。 -
定量化
さまざまのな種類の定量データを収集することで、ビジネス上の洞察を得たり、システムの健康状態を理解できる、- ホストレベルの定量データ: CPU、メモリ、ディスクI/Oなど
- 集計レベルの定量データ: 例えば、データベース層全体、キャッシュ層などのパフォーマンス
- 主要なビジネス指標: デイリーアクティブユーザー、リテンション、収益、その他
-
自動化
システムが大きく複雑化してくると、生産性向上のための自動化ツールを活用する必要がある。
継続的インテグレーションは良い実践。
ビルド、テスト、デプロイのプロセスなどの自動化により生産性を大幅に向上させることができる。
メッセージキューと各種ツールの追加

- メッセージキューを採用し、より疎結合で障害に強いシステムを実現するのに役立つ
- 自動化ツールが含まれている
データベースのスケーリング
データが日々増加すると、データベースはより過負荷になる。これはデータ層を拡張するタイミングである。データベースのスケーリングには大きく分けて、「垂直スケーリング」と「水平スケーリング」がある。
垂直スケーリング
- 垂直スケーリングでは、既存マシンにさらにパワー(CPU,RAM,DISK)を追加することでスケーリングする。
- DBサーバには強力なもの
- がある。
- Amazon Relational Database Service(RDS)
- 24TBのTAMを搭載したデータベースサーバがある。
- stackoverflowは毎月1000万人以上のユニークビジターを抱えていたが、一つのマスターデータベースしか持っていなかった。
- Amazon Relational Database Service(RDS)
-
垂直スケーリングの重要な欠点
- DBサーバにCPUやRAMなど追加できるが、ハードウェアには限界がある。ユーザー数が多い場合、1台のサーバでは不十分
- 単一障害点のリスクが大きい
- 垂直スケーリングはコストが高い。強力なサーバはより高価になる。
水平スケーリング
- シャーディングとも呼ばれる。
- サーバを増設する。
- 大規模なデータベースをより小さく、より管理しやすいシャードというパーツに分割する。
- 各シャードは同じスキーマを共有するが、各シャード上の実際のデータはそのシャード固有。
- スキーマを共有・・・テーブル構造やデータ型、関係性などのDB設計を共通で持つという意味だと思う
- 各シャード上の実際のデータはそのシャード固有
- 実践例として、4つのシャーディングされたDBがあるとする。
- ユーザーデータはユーザーIDに基づいて割り当てられる
- user_id%4がハッシュ関数として使用されており、その結果が0の場合、シャード0がデータの保存と補足に使用される
- シャードの中身はこのようになっている

-
考慮すべき最も需要な要素
- シャーディングキーを選択すること。(パーティションキーと呼ばれる)
- データの分散方法を決定する1つ内し複数の例で構成されている
- 上記の例で言うとuser_idはシャーディングキーということになる
- シャーディングキーはデータベースへのクエリを正しいデータベースにルーティングすることで、データの取得と修正を効率的に行えるようにする。
- シャーディングキーの最も重要な選択基準はデータを均等に分散できるキーを選択すること。
システムに複雑さと新たな課題をもたらすため、完璧なソリューションとしては程遠い。
データの再シャーディング
データの再シャーディングが必要なのは、下記。
- 急激なデータ増加により一つのシャードがそれ以上のデータを保持できなくなった場合
- データの分布が不均一なため、特定のシャードが他よりも早くシャードを使い果たす可能性がある場合
上記の課題を解決する手法として「一貫ハッシュ」がよく使われる。 -
セレブ問題
- ホットスポットキー問題とも呼ばれる
- 特定のシャードへの過度なアクセスはサーバの過負荷を引き起こすかもしれない。
- レディガガやケイティペリーなど著名人のデータが同じシャードに入ってしまうとそのシャードが読み込み処理に圧倒されることになる。
- この問題を解決するには、有名人ごとにシャードを割り当てる必要がああるかもしれない。
-
結合と非正規化
- DBが複数のサーバにまたがってシャーディングされると、ジョイン操作を行うことが難しくなる。一般的な回避策は、データベースの非正規化を行い、単一テーブルでクエリを実行できるようにすること。
数百万ユーザーとそれ以上
数百万ユーザーを超える規模の拡張にはより細かなチューニングと新たな戦略が必要だが、どのようにスケーリングするかについてのおおまかな説明は下記
- webそはステートレスに保つ
- 各階層で冗長性を確保する
- できる限りデータをキャッシュする
- 複数のデータセンターへの対応
- 静的アセットをCDNでホスティング
- シャーディングによるデータ層の閣僚
- 各サービスに階層を分割する
- システムの監視と自動化ツールの使用
Discussion