DagsHubに入門する ~2. DagsHub+DVC~
DagsHub+DVC
はじめに
- DagsHubって?
- DagsHub+DVC ←イマココ
- DagsHub+DVC+MLflow
前回の記事でアカウント作成まで実施したので、その続きから。
成果物のリポジトリはこちら
リポジトリの初期化
まずは自動作成されたリポジトリをgit cloneする。
git clone https://dagshub.com/<user_name>/<repo_name>.git
GitHub等と似たような場所にあるあのボタンをクリックするとリポジトリのURLやクローンのコマンドが出てくる。
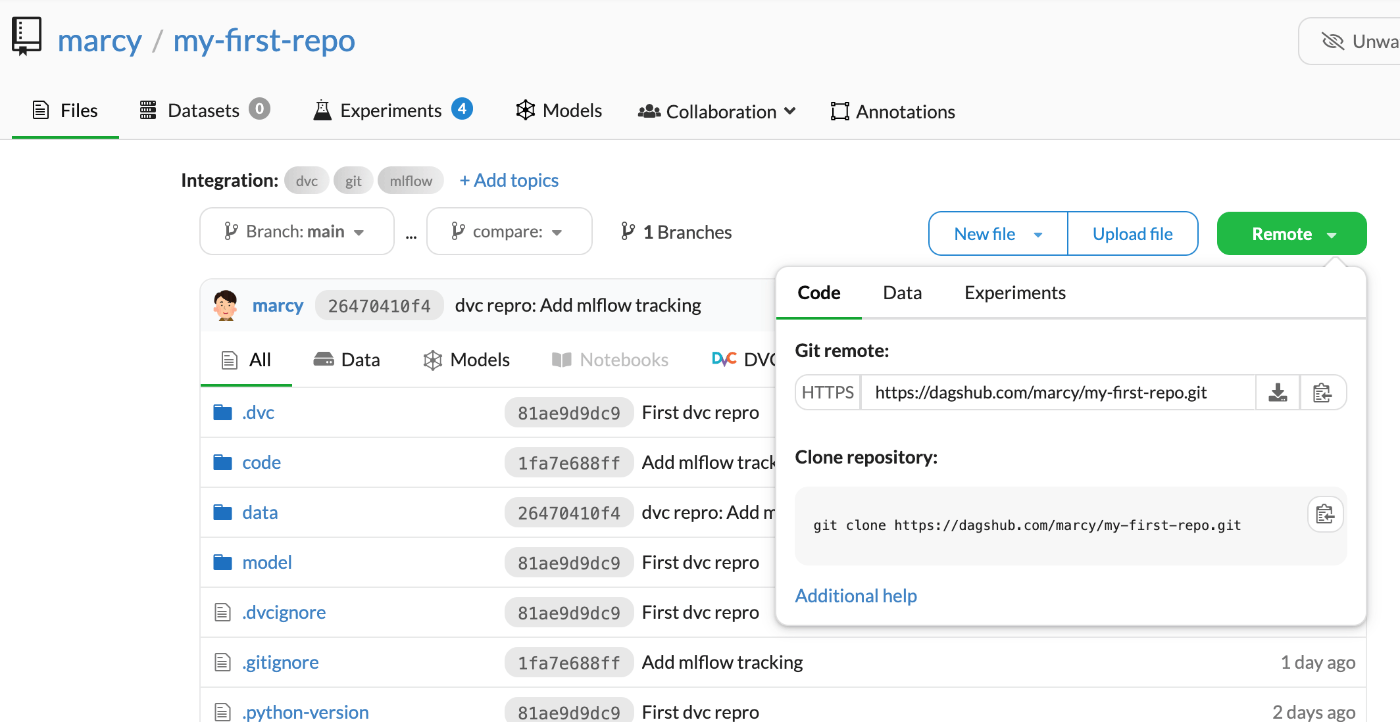
続いてREADME.mdを作成して、git pushまで実行
cd my-first-repo
echo "# my-first-repo" >> README.md
git add README.md
git commit -m "first commit"
git branch -M main
git push -u origin main
環境作成
今回はpyenv+venvでパッケージ管理をする。
pyenv local 3.11
python -m venv .venv
source ./.venv/bin/activate
venvを作成したらgitignoreも書いておく。
公式チュートリアルを参考にvenv以外もついでに追加しておく。
.venv/
__pycache__/
# /data/
/outputs/
のちのdvc addコマンドでエラーが出るため、この時点では/data/はgitignoreに含めない。
DVCの初期設定
DVCをインストールする。
pip install dvc dvc-s3
まずはDVCの初期化を実行する。
dvc init
続いてDVCのリモートリポジトリを設定する。
dvc remote add origin s3://dvc
dvc remote modify origin endpointurl https://dagshub.com/<username>/<repo-name>.s3
dvc remote modify origin --local access_key_id <token>
dvc remote modify origin --local secret_access_key <token>
このコマンド内のトークンはDagsHubのUIから確認できる。
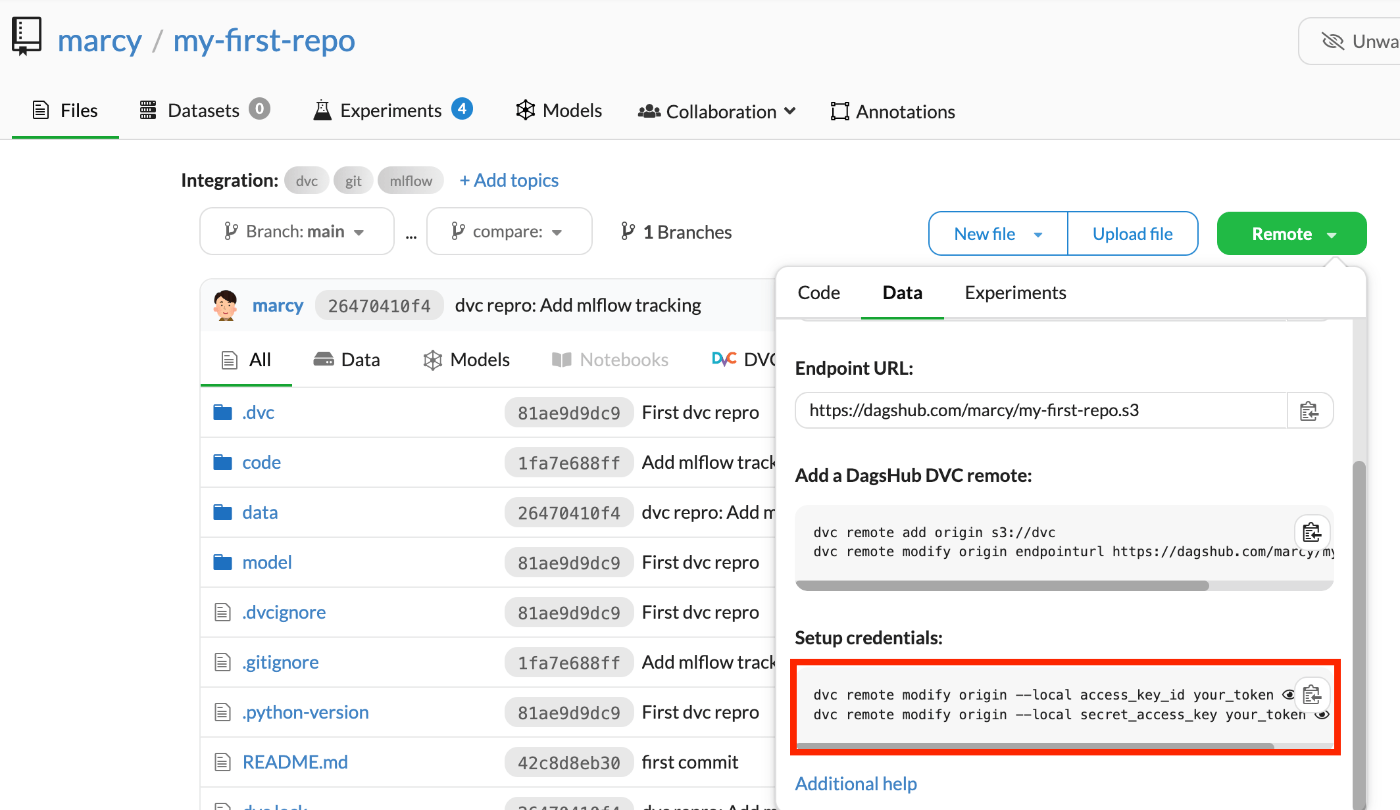
枠内右のボタンをクリックすることでトークンを含めたコマンドをそのままコピーできる。
DVCにデータの登録
DVCのデータはこちらのタイタニックを題材とした記事を参考にしている。
Kaggleからデータをダウンロードして、以下のように配置する。
- my-first-repo
- data
- raw
- train.csv
- test.csv
- gender_submission.csv
配置したデータをDVCに登録する。
dvc add data/raw/train.csv data/raw/test.csv data/raw/gender_submission.csv
パイプラインの登録
パイプライン実行用に、data/processedとcode, modelディレクトリ、dvc.yamlとcode/preprocess.py, `code/train.pyファイルを作成する。
- my-first-repo
- dvc.yaml
- data
- processed
- code
- preprocess.py
- train.py
- model
stages:
preprocess:
cmd: python code/preprocess.py data/raw/train.csv data/processed/processed_train.csv
deps:
- code/preprocess.py
- data/raw/train.csv
outs:
- data/processed/processed_train.csv
train:
cmd: python code/train.py data/processed/processed_train.csv model/model.pkl
deps:
- code/train.py
- data/processed/processed_train.csv
outs:
- model/model.pkl
import pandas as pd
import click
from sklearn.impute import SimpleImputer
def fill_missing_values(df, label, strategy):
imputer = SimpleImputer(strategy=strategy)
df[label] = imputer.fit_transform(df[[label]]).ravel()
return df
@click.command()
@click.argument('input_path')
@click.argument('output_path')
def preprocess(input_path, output_path):
# データを読み込む
df = pd.read_csv(input_path)
# 前処理の実行
df = df.drop(columns=['Name', 'Ticket', 'Cabin'])
df = fill_missing_values(df, 'Age', "median")
df = fill_missing_values(df, "Embarked", "most_frequent")
df = pd.get_dummies(df, columns=['Sex', 'Embarked'])
# 処理済みデータを保存
df.to_csv(output_path, index=False)
if __name__ == '__main__':
preprocess()
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import pickle
import click
@click.command()
@click.argument('input_path')
@click.argument('output_path')
def train(input_path, output_path):
# データの読み込み
df = pd.read_csv(input_path)
X = df.drop('Survived', axis=1)
y = df['Survived']
# 訓練データとテストデータに分割
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.2, random_state=42)
# モデルの訓練
model = RandomForestClassifier()
model.fit(X_train, y_train)
# モデルの保存
pickle.dump(model, open(output_path,'wb'))
# モデルの評価
y_pred = model.predict(X_valid)
accuracy = accuracy_score(y_valid, y_pred)
if __name__ == "__main__":
train()
足りないライブラリもインストールする。
pip install click pandas scikit-learn
パイプラインの実行
登録したDVCのパイプラインを実行する。
dvc repro
成功したら、gitでリモートにプッシュする。
git add .
git commit -m "First DVC repro"
git push
DVCもリモートにプッシュする。
dvc remote default origin
dvc push
DAGsHubを確認
Gitがプッシュされていることが確認できるとともに、DVCにデータがプッシュされていることも確認できる。
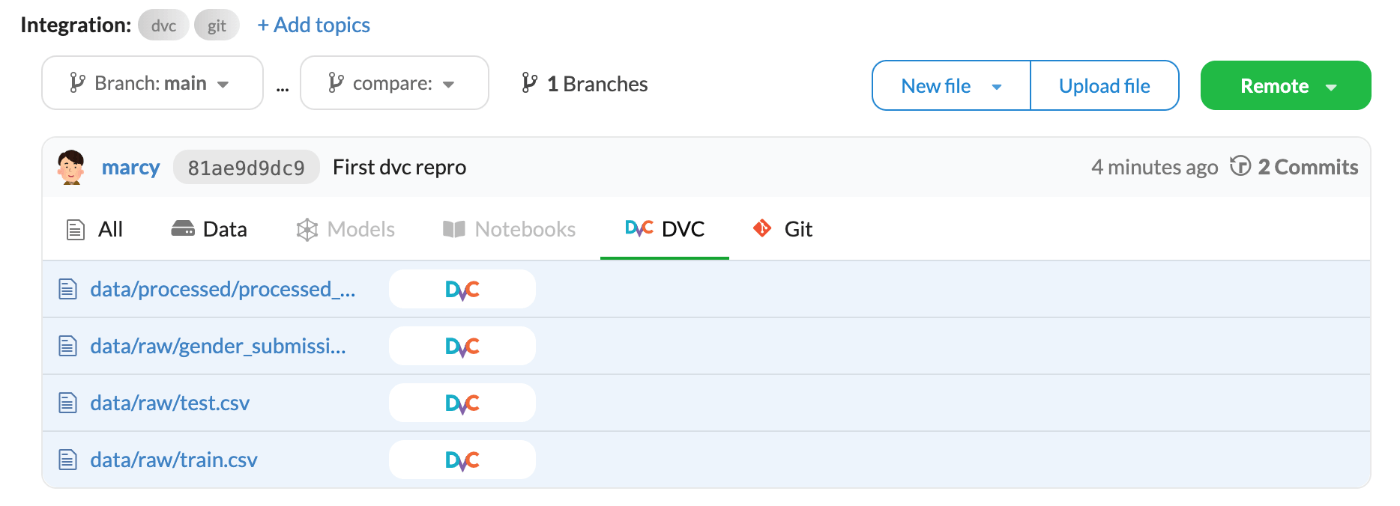
少し下にスクロールするとパイプラインのリネージュも確認できる。
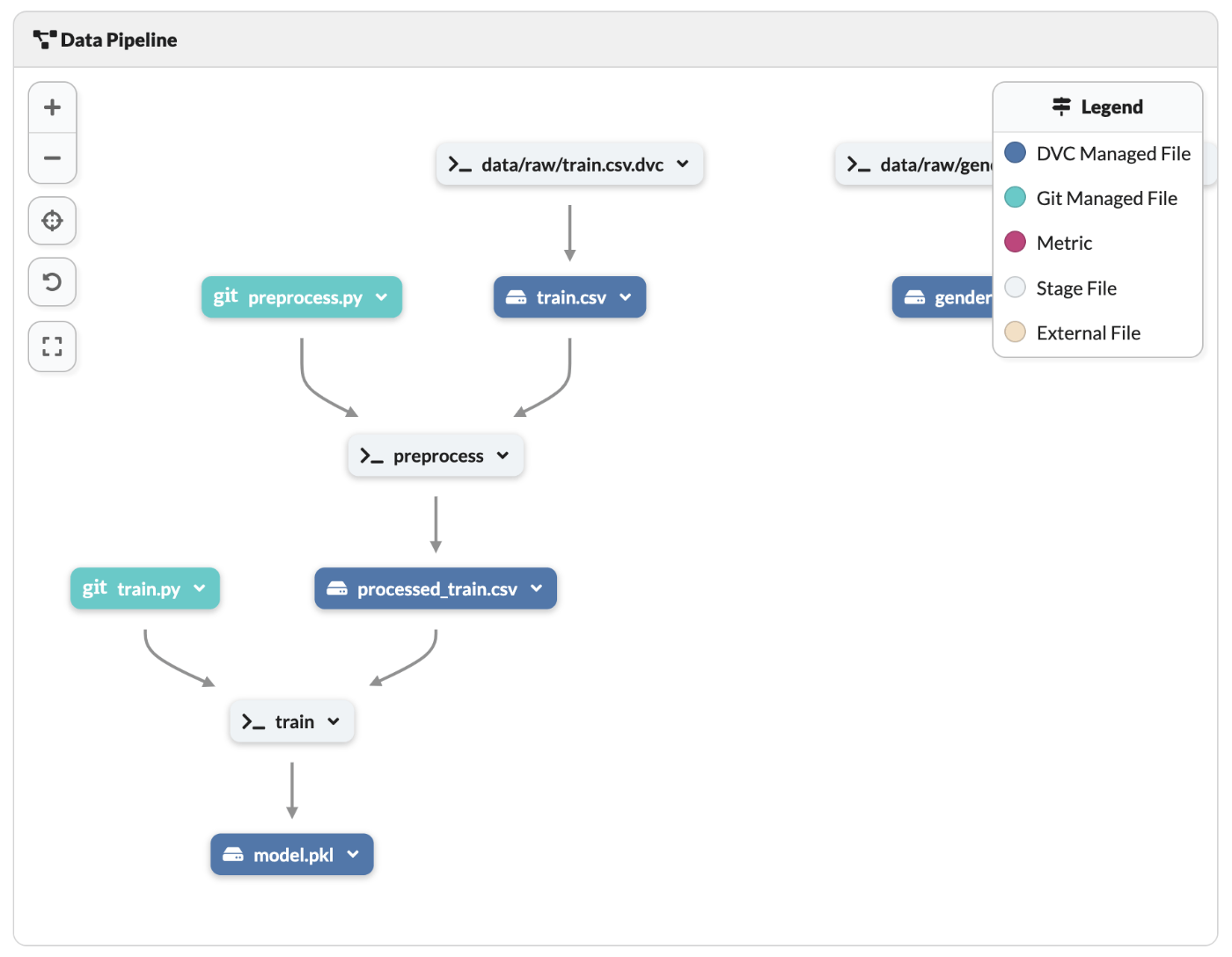
まとめ
これにてDAGsHubとDVCを用いたコードとデータのバージョン管理が完了。
次回はここにMLflowをプラスして、ML実験のトラッキングを実装していく。
Discussion